[1]
朱贺, 杨华, 尹周平 纹理表面缺陷机器视觉检测方法综述
[J]. 机械科学与技术 , 2023 , 42 (8 ): 1293 - 1315
[本文引用: 1]
ZHU He, YANG Hua, YIN Zhouping Review of machine vision detection methods for texture surface defects
[J]. Mechanical Science and Technology for Aerospace Engineering , 2023 , 42 (8 ): 1293 - 1315
[本文引用: 1]
[2]
黄梦涛, 连一鑫 基于改进Canny算子的锂电池极片表面缺陷检测
[J]. 仪器仪表学报 , 2021 , 42 (10 ): 199 - 209
[本文引用: 1]
HUANG Mengtao, LIAN Yixin Lithium battery electrode plate surface defect detection based on improved Canny operator
[J]. Chinese Journal of Scientific Instrument , 2021 , 42 (10 ): 199 - 209
[本文引用: 1]
[4]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Heideberg: Springer, 2016: 21−37.
[本文引用: 1]
[5]
LIN T, GOYAL P, GIRSHICK R, et al Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 42 (2 ): 318 - 327
[本文引用: 3]
[6]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779−788.
[本文引用: 1]
[7]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517−6525.
[8]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08) [2023-07-23]. https://arxiv. org/abs/1804.02767.
[9]
BOCHKOVSKIY A, WANG C Y, LIA O H. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23) [2023-07-25]. https://arxiv. org/abs/2004.10934.
[本文引用: 1]
[10]
刘国栋. 基于深度学习的锂电池极片表面缺陷检测方法研究[D]. 广州:广东工业大学, 2022.
[本文引用: 5]
LIU Guodong. Research on surface defect detection method of lithium battery electrode based on deep learning [D]. Guangzhou: Guangdong University of Technology, 2022.
[本文引用: 5]
[11]
葛钊明, 胡跃明 基于改进YOLOv5的锂电池极片缺陷检测
[J]. 激光杂志 , 2023 , 44 (2 ): 25 - 29
[本文引用: 5]
GE Zhaoming, HU Yueming Lithium battery electrode defect detection method based on improved YOLOv5
[J]. Laser Journal , 2023 , 44 (2 ): 25 - 29
[本文引用: 5]
[12]
董刚, 谢维成, 黄小龙, 等 深度学习小目标检测算法综述
[J]. 计算机工程与应用 , 2023 , 59 (11 ): 16 - 27
DOI:10.3778/j.issn.1002-8331.2211-0377
[本文引用: 1]
DONG Gang, XIE Weicheng, HUANG Xiaolong, et al Review of small object detection algorithms based on deep learning
[J]. Computer Engineering and Applications , 2023 , 59 (11 ): 16 - 27
DOI:10.3778/j.issn.1002-8331.2211-0377
[本文引用: 1]
[13]
张艳, 张明路, 吕晓玲, 等 深度学习小目标检测算法研究综述
[J]. 计算机工程与应用 , 2022 , 58 (15 ): 1 - 17
DOI:10.3778/j.issn.1002-8331.2112-0176
ZHANG Yan, ZHANG Minglu, LU Xiaoling, et al Review of research on small target detection based on deep learning
[J]. Computer Engineering and Applications , 2022 , 58 (15 ): 1 - 17
DOI:10.3778/j.issn.1002-8331.2112-0176
[14]
陈航. 基于深度学习的小目标检测算法研究[D]. 绵阳:西南科技大学, 2023.
CHEN Hang. Research on the small object detection algorithm based on deep learning [D]. Mianyang: Southwest University of Science and Technology, 2023.
[15]
沈翔. 基于RetinaNet的小目标检测提升方法研究[D]. 南京:南京邮电大学, 2023.
[本文引用: 1]
SHEN Xiang. Research on the improvement methods for small object detection based on RetinaNet [D]. Nanjing: Nanjing University of Posts and Telecommunications, 2023.
[本文引用: 1]
[16]
吴陈尧. 遥感图像中旋转目标检测方法的设计与实现[D]. 成都:电子科技大学, 2023.
[本文引用: 1]
WU Chenyao. Design and implementation of rotating object detection method in remote sensing images [D]. Chengdu: University of Electronic Science and Technology of China, 2023.
[本文引用: 1]
[17]
陈凯. 基于改进级联R-CNN的瓷砖表面瑕疵检测算法[D]. 杭州:浙江理工大学, 2023.
CHEN Kai. Tile surface defect detection algorithm based on improved Cascaded R-CNN [D]. Hangzhou: Zhejiang Sci-Tech University, 2023.
[18]
张锟. 高分辨率遥感图像目标检测方法研究[D]. 广州:华南理工大学, 2023.
[本文引用: 1]
ZHANG Kun. Study on objects detection algorithm in high-resolution remote sensing image [D]. Guangzhou: South China University of Technology, 2023.
[本文引用: 1]
[19]
肖进胜, 赵陶, 周剑, 等 基于上下文增强和特征提纯的小目标检测网络
[J]. 计算机研究与发展 , 2023 , 60 (2 ): 465 - 474
DOI:10.7544/issn1000-1239.202110956
[本文引用: 1]
XIAO Jinsheng, ZHAO Tao, ZHOU Jian, et al Small target detection network based on context augmentation and feature refinement
[J]. Journal of Computer Research and Development , 2023 , 60 (2 ): 465 - 474
DOI:10.7544/issn1000-1239.202110956
[本文引用: 1]
[20]
DAI J, QI H, XIONG Y, et al. Deformable convolutional networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision . Washington: IEEE, 2017: 764−773.
[本文引用: 1]
[21]
ZHU X Z, HU H, LIN S, et al. Deformable ConvNets v2: more deformable, better results [C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition . Piscataway: IEEE, 2019: 9308−9316.
[22]
WANG W, DAI J, CHEN Z, et al. InternImage: exploring large-scale vision foundation models with deformable Convolutions [EB/OL]. (2023-04-17) [2023-07-25]. https://arxiv.org/abs/2211.05778.
[本文引用: 1]
[23]
GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021 [EB/OL]. (2021-08-06) [2023-07-25]. https://arxiv.org/abs/2107.08430.
[本文引用: 1]
[24]
YANG L, ZHANG R, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks [C]// International Conference on Machine Learning . San Diego: JMLR, 2021: 11863−11874.
[本文引用: 1]
[25]
ZHANG Q L, YANG Y B. SA-Net: shuffle attention for deep convolutional neural networks [C]// IEEE International Conference on Acoustics, Speech and Signal Processing . Toronto: IEEE, 2021: 2235−2239.
[本文引用: 1]
[26]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11531−11539.
[本文引用: 1]
[27]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132−7141.
[本文引用: 1]
[28]
LI Y, YAO T, PAN Y, et al Contextual transformer networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 45 (2 ): 1489 - 1500
[本文引用: 1]
[29]
GOYAL A, BOCHKOVSKIY A, DENG J, et al. Non-deep networks [EB/OL]. (2021-10-14) [2023-07−25]. https://arxiv. org/abs/2110.07641.
[本文引用: 1]
[30]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: ICCV, 2021: 9992−10002.
[本文引用: 2]
纹理表面缺陷机器视觉检测方法综述
1
2023
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
纹理表面缺陷机器视觉检测方法综述
1
2023
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
基于改进Canny算子的锂电池极片表面缺陷检测
1
2021
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
基于改进Canny算子的锂电池极片表面缺陷检测
1
2021
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
锂电池极片缺陷特征融合与分类
1
2021
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
锂电池极片缺陷特征融合与分类
1
2021
... 目前,锂电池极片的缺陷检测方法可以分为传统方法和深度学习方法. 传统方法主要根据图像的结构和频域信息,通过增强算子提取图像特征,进而进行检测分类[1 ] . 如黄梦涛等[2 -3 ] 通过改进Canny算子,融合BoF-SURF和灰度特征,突出锂电池极片表面的缺陷,并使用支持向量机实现极片缺陷分类. 但传统方法需要复杂、针对性强的算法设计,近年来相关研究呈相对减少的趋势. ...
1
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
Focal loss for dense object detection
3
2017
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
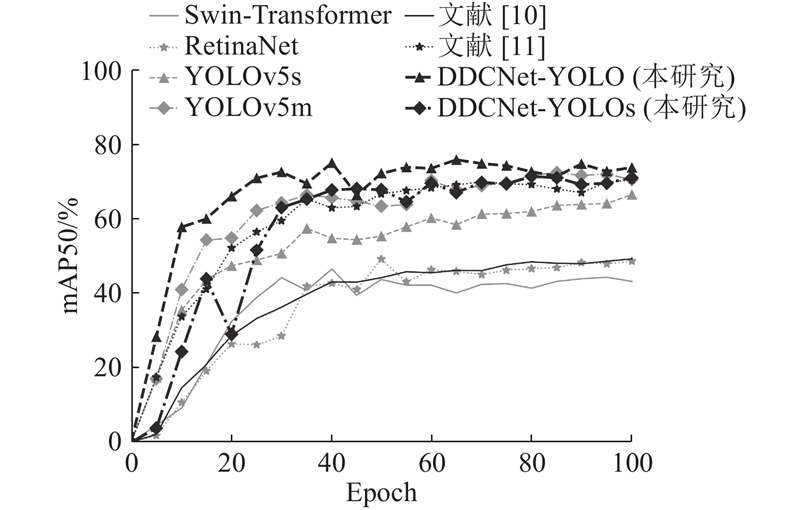
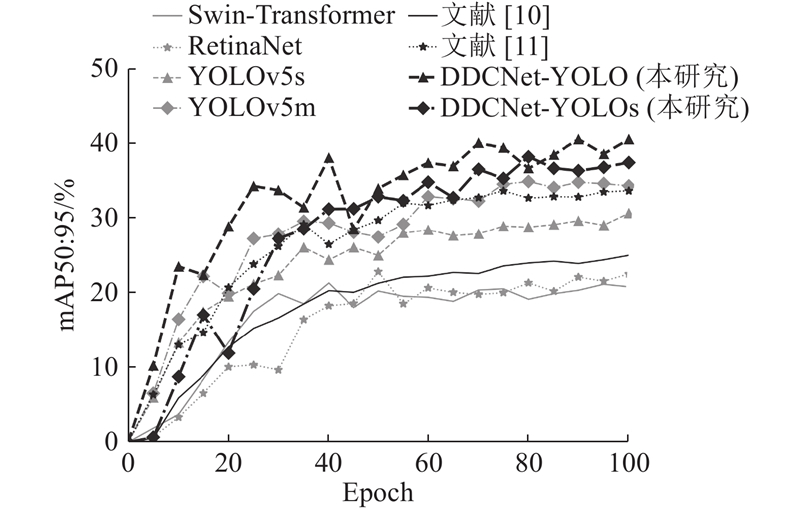
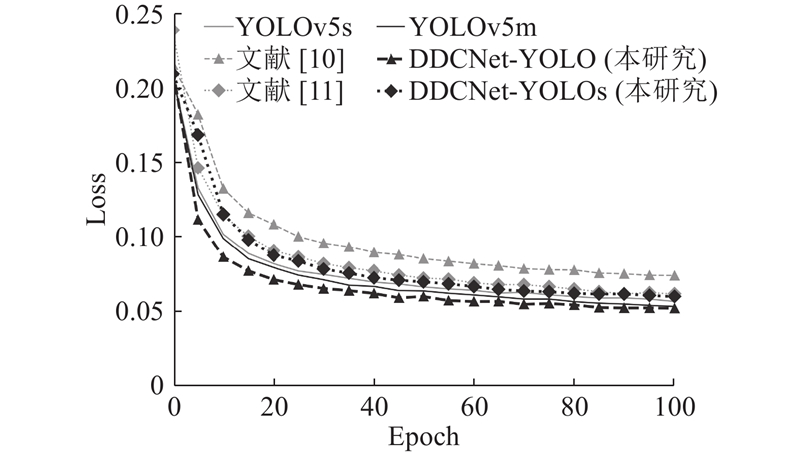
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...
1
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
1
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
5
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... [10 -11 ]研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... [10 -11 ],无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...
5
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... [10 -11 ]研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... [10 -11 ],无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...
基于改进YOLOv5的锂电池极片缺陷检测
5
2023
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... -11 ]研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... -11 ],无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...
基于改进YOLOv5的锂电池极片缺陷检测
5
2023
... 深度学习方法以其自动提取特征、鲁棒性和泛化能力强等优势得到关注. 目前主流方法根据检测方式的不同可分为单阶段网络和双阶段网络检测方法. 单阶段网络直接对特征图预测和回归,速度相较于双阶段网络更快. 因此,本任务更适合以单阶段网络进行检测. 目前,单阶段网络的代表主要有SSD[4 ] 、RetinaNet[5 ] 、YOLO[6 -9 ] 等,其中YOLO具备实时监测能力,并且检测效果较好,得到了广泛的研究与应用. 刘国栋[10 ] 基于YOLOv3网络改进,对6类分辨率为256×256的极片缺陷图片进行实验,在自建数据集上的准确率达到96%. 葛钊明等[11 ] 在YOLOv5s的基础上加入卷积注意力模块(convolutional block attention module, CBAM),并使用EIoU替代损失函数,相较于YOLOv5s,改进模型在自建数据集中对3类缺陷的mAP50提高1.2个百分点,召回率提高1.5个百分点. 整体上,相关研究普遍存在着缺陷检测类别少、图片分辨率低的不足,尤其是如刘国栋等[10 -11 ] 研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... -11 ]研究提出的模型,普遍缺少对于极片表面缺陷特点的针对性设计. ...
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... -11 ],无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...
深度学习小目标检测算法综述
1
2023
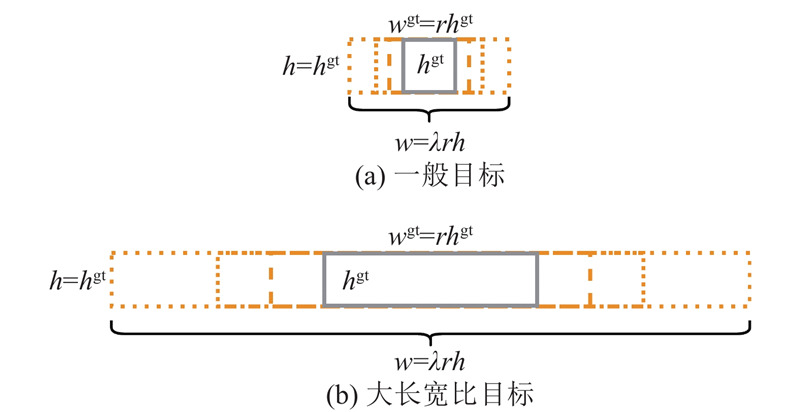
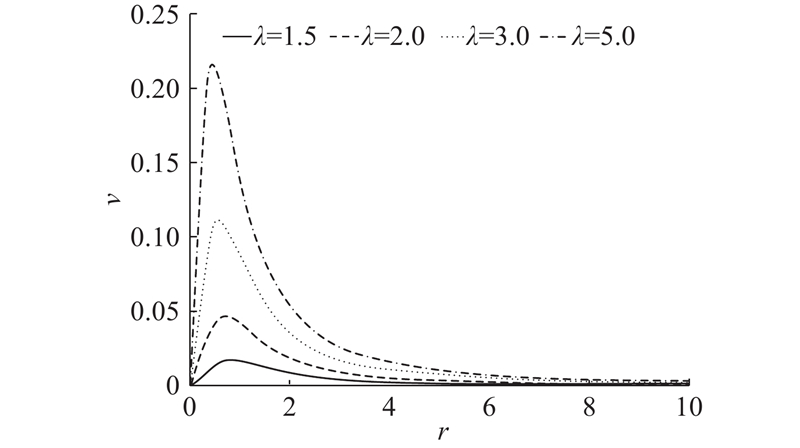
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
深度学习小目标检测算法综述
1
2023
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
1
... 对于小目标的定义方式可以分为绝对定义和相对定义,其中相对定义在实际应用中经常采纳. 相对定义是选择物体大小相对于原图的比例作为判断指标,如普遍定义目标框的长宽和图像长宽的比值小于0.1,或覆盖面积与图片面积之比小于0. 0009 的目标为小目标[12 -15 ] . 此外,也存在一些对大长宽比目标的研究[16 -18 ] ,但普遍缺乏对大长宽比目标的定量标准. 本研究对极片表面的小目标、大长宽比目标,采用更严苛的标准,即目标框的长宽和图像长宽的比值小于0. 05,或覆盖面积与图片面积之比小于0. 0003 的目标确定为小目标,同时将长宽比大于5的目标定义为大长宽比目标. ...
基于上下文增强和特征提纯的小目标检测网络
1
2023
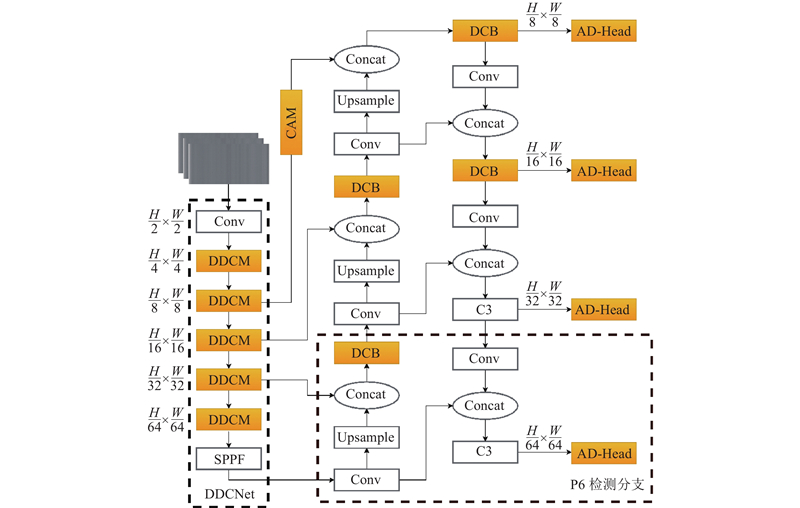
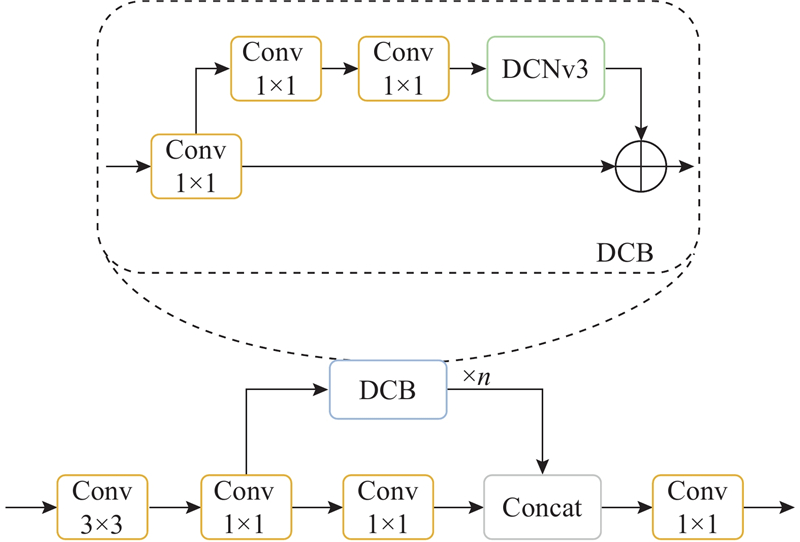
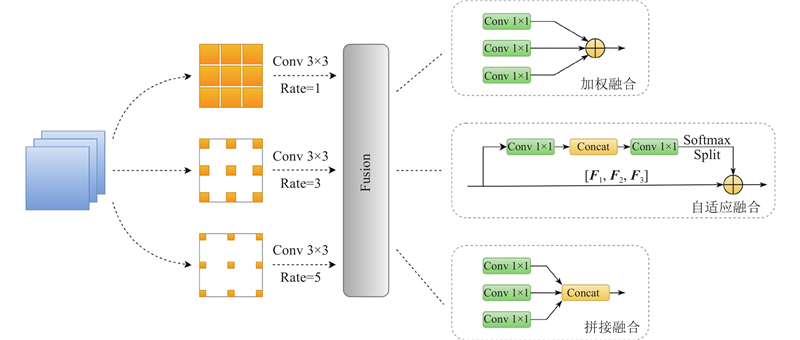
... 本研究基于YOLOv5结构,针对大长宽比目标,设计可变形卷积块(deformable convolution block,DCB),构建出可变形下采样卷积主干网络(deformable downsampling convolution network,DDCNet). 针对小目标在特征融合部分融入上下文增强模块(context augmentation module,CAM) [19 ] . 在检测头部分设计了融合注意力机制的解耦头(attention decoupled head,AD-Head). 提出RIoU(ratio-IoU)以优化不同长宽比目标的损失计算. 最终形成DDCNet-YOLO(deformable downsampling convolution network-YOLO)模型. 在考虑模型检测效率的前提下,追求更优的检测效果. ...
基于上下文增强和特征提纯的小目标检测网络
1
2023
... 本研究基于YOLOv5结构,针对大长宽比目标,设计可变形卷积块(deformable convolution block,DCB),构建出可变形下采样卷积主干网络(deformable downsampling convolution network,DDCNet). 针对小目标在特征融合部分融入上下文增强模块(context augmentation module,CAM) [19 ] . 在检测头部分设计了融合注意力机制的解耦头(attention decoupled head,AD-Head). 提出RIoU(ratio-IoU)以优化不同长宽比目标的损失计算. 最终形成DDCNet-YOLO(deformable downsampling convolution network-YOLO)模型. 在考虑模型检测效率的前提下,追求更优的检测效果. ...
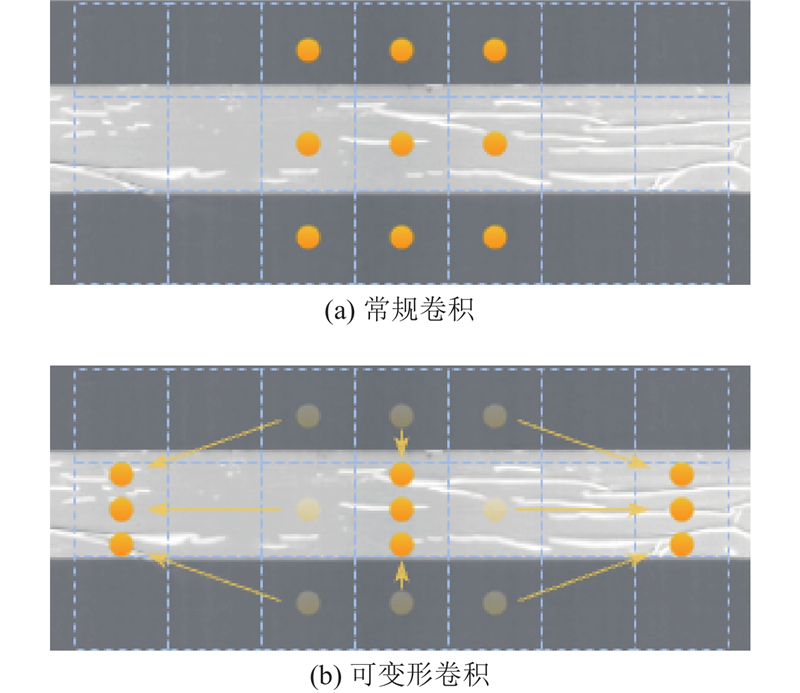
1
... DCB融入了可变形卷积的思想[20 -22 ] ,主要针对大长宽比的目标缺陷进行特征提取,如图3 所示为常规卷积和可变形卷积对极片采样位置的对比示意图. 图中,浅色部分为胶带种类缺陷. ...
1
... DCB融入了可变形卷积的思想[20 -22 ] ,主要针对大长宽比的目标缺陷进行特征提取,如图3 所示为常规卷积和可变形卷积对极片采样位置的对比示意图. 图中,浅色部分为胶带种类缺陷. ...
1
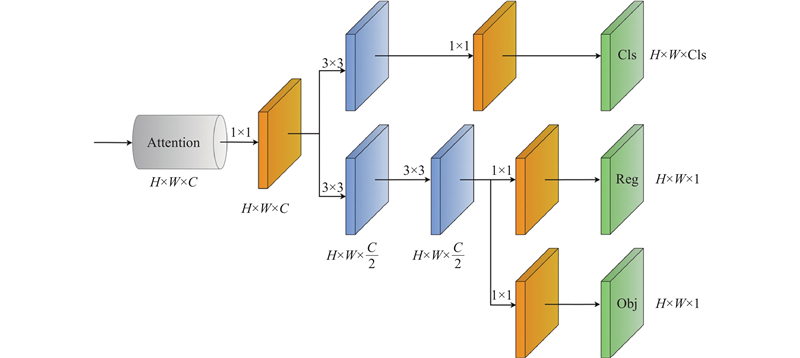
... YOLOv5在检测头中只进行了一次1×1卷积,并将分类任务和回归任务耦合. 不过,2个任务所关注的内容不同,分类聚焦于所提取特征的类别,而回归注重位置坐标和边界框参数的修正,如果共同输出可能会对检测效果产生影响. 因此,YOLOX[23 ] 提出将分类任务和回归任务解耦从而有效提高网络的检测效果. YOLOX的解耦头包含多个卷积层,会使模型增加一定参数量,因此,本研究考虑解耦头的轻量化,并融合注意力机制,设计了AD-Head,其中注意力机制的引入能够提高模型对位置和通道数的敏感性. ...
1
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
1
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
1
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
1
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
Contextual transformer networks for visual recognition
1
2022
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
1
... Comparison of six attention detection heads
Tab.3 方法 P /106 mAP50/% mAP50∶95/% baseline 7. 04 70.9 36.3 +SimAM[24 ] 7. 04 69.1 37. 0 +SA[25 ] 7. 04 69.1 37.3 +ECA[26 ] 7. 04 72.7 41.7 +SE[27 ] 7. 08 70.5 40.8 +CoT[28 ] 10. 06 70.9 37.7 +ParNet[29 ] 10.83 74.2 41.1
2.4.3. 消融实验 为了验证所提改进模块与引入方法对于模型检测性能的提升效果,进行消融实验. 实验以YOLOv5s为基础模型逐个添加改进模块及方法,分别以A~H表示模型序号,首先将主干网络替换为32倍下采样的DDCNet构成模型B,然后在模型B的基础上,添加使用ECA 注意力机制的轻量化解耦头AD-Heads组成模型C,即DDCNet-YOLOs模型. 同时对模型B依次加入CAM模块、替换DCB模块以及融入包含ParNet注意力机制的解耦头AD-Head构成模型D~F,最后添加P6分支使模型达到64倍下采样得到模型G,再在模型G基础上使用RIoU得到模型H,即DDCNet-YOLO模型,实验结果如表4 所示. ...
2
... 为了测试所提模型的性能,将所设计的DDCNet-YOLO模型和轻量化模型DDCNet-YOLOs,与经典主流深度学习方法[5 ,30 ] 以及采用深度学习方法检测锂电池极片缺陷的文献[10 -11 ] 进行实验对比. 所有实验均基于本研究所构建的锂电池极片表面缺陷数据集. 考虑到实际工业场景下工控机的性能,对比验证实验使用单张GPU进行,训练轮数为200次,实验数据如表5 所示. 表中,t 为耗时. 可以看出,基于YOLO构建的模型从精度和速度上都要优于另外2种经典网络. 其中本研究设计的轻量化DDCNet-YOLOs模型能够在参数量少于YOLOv5s模型0.51×106 的情况下,在mAP50、mAP50∶95上分别提升1.5个百分点、8.9个百分点. 对于参数更多、精度更高的YOLOv5m模型,所构建的DDCNet-YOLO模型在参数量上与其接近,但mAP50和mAP50∶95指标分别高于YOLOv5m模型3.7个百分点和3.1个百分点,同时检测速度更快,对每张图片的检测速度平均减少1.1 ms,达到26.5 ms. 同时,对比2篇针对极片表面缺陷的改进文献方法[10 -11 ] ,无论是整体的检测效果还是针对小目标和大长宽比目标的检测效果,本研究所提模型均有较大的优势. ...
... Comparative experimental results of different algorithms on lithium battery electrode dataset
Tab.5 方法 P /106 t /mAP50/ mAP50S / mAP50L / mAP50∶95/ Swin-Transformer[30 ] 37. 03 56.8 46.4 37.1 57.7 22.3 RetinaNet[5 ] 36.31 44.6 53.4 46.9 61.1 25.4 文献[10 ] 9.33 23.5 52.2 63.9 38.2 27.3 YOLOv5s 7. 04 22. 0 70.9 73.4 67.9 36.3 文献[11 ] 7. 08 24.1 70.4 72. 0 68.5 37.4 DDCNet-YOLOs 6.53 22.8 72.4 74.4 70. 0 45.2 YOLOv5m 20.89 27.6 73.4 72.6 74.3 42.6 DDCNet-YOLO 22.76 26.5 77.1 75.6 79. 0 45.7
此外,如图9 ~11 所示分别呈现了训练过程中,mAP50和mAP50∶95指标以及Loss损失在100个训练轮次内的变化情况. 可以看出,所构建的DDCNet-YOLO模型在mAP50和mAP50∶95指标上具有更快的增长速度以及更优的检测结果,同时Loss曲线体现出模型较快的收敛速度. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}