[1]
KANTAR M. Social Media Trends [R]. London: Kantar Media, 2019.
[本文引用: 3]
[2]
KAPFERER J. Rumeurs-Le plus vieux média du monde [M]// Pari: Editions du Seuil, 1987: 31−33.
[本文引用: 1]
[3]
LAROCHELLE H, ERHAN D, BENGIO Y. Zero-data learning of new tasks [C]// Proceedings of the 23rd AAAI Conference on Artificial Intelligence . Chicago: AAAI Press, 2008: 646−651 .
[本文引用: 1]
[4]
CHANG M W, RATINOV L, ROTH D, et al. Importance of semantic representation: dataless classification [C]// Proceedings of the 23rd AAAI Conference on Artificial Intelligence. Chicago: AAAI Press, 2008: 830−835.
[本文引用: 1]
[5]
LIN H, YI P, MA J, et al. Zero-shot rumor detection with propagation structure via prompt learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Washington: AAAI Press, 2023: 5213−5221.
[本文引用: 2]
[6]
SONG Y, UPADHYAY S, PENG H, et al Toward any-language zero-shot topic classification of textual documents
[J]. Artificial Intelligence , 2019 , 274 (C ): 133 - 150
[本文引用: 1]
[7]
SONG Y, UPADHYAY S, PENG H, et al. Cross-lingual dataless classification for many languages [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence . New York: AAAI Press, 2016: 2901−2907.
[本文引用: 1]
[8]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Communications of the ACM , 2020 , 63 (11 ): 139 - 44
DOI:10.1145/3422622
[本文引用: 1]
[9]
KINGMA D P, WELLING M. Auto-encoding variational bayes [C]// Proceedings of the International Conference on Learning Representations . Ithaca: ArXiv, 2014: 14−16.
[本文引用: 1]
[10]
CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations [C]// Proceedings of the International Conference on Machine Learning . [s. l. ]: PMLR, 2020: 1597−1607.
[本文引用: 1]
[11]
HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9726−9735.
[本文引用: 1]
[12]
LIANG B, CHEN Z X, GUI L, et al. Zero-shot stance detection via contrastive learning [C]// Proceedings of the ACM Web Conference. Lyon: ACM, 2022: 2738−2747.
[本文引用: 5]
[13]
VICARIO M D, QUATTROCIOCCHI W, SCALA A, et al Polarization and fake news: early warning of potential misinformation targets
[J]. ACM Transactions on the Web , 2019 , 13 (2 ): 1 - 22
[本文引用: 1]
[14]
MEEL P, VISHWAKARMA D K Fake news, rumor, information pollution in social media and web: a contemporary survey of state-of-the-arts, challenges and opportunities
[J]. Expert Systems with Applications , 2020 , 153 (1 ): 112986
[本文引用: 1]
[15]
WANG Z, GUO Y Rumor events detection enhanced by encoding sentimental information into time series division and word representations
[J]. Neurocomputing , 2020 , 397 (2 ): 224 - 243
[本文引用: 1]
[16]
KUMAR S, CARLEY K M. Tree LSTMs with convolution units to predict stance and rumor veracity in social media conversations [C]// Proceedings of the 57th annual meeting of the association for computational linguistics . Florence: ACL, 2019: 5047−5058.
[本文引用: 1]
[17]
BIAN T, XIAO X, XU T, et al. Rumor detection on social media with bi-directional graph convolutional networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI Press, 2020: 546−556.
[本文引用: 4]
[18]
ZHANG Q, LIPANI A, LIANG S, et al. Reply-aided detection of misinformation via bayesian deep learning [C]// Proceedings of the World Wide Web Conference . San Francisco: ACM, 2019: 2333−2343.
[本文引用: 1]
[19]
RIEDEL B, AUGENSTEIN I, SPITHOURAKIS G P, et al. A simple but tough-to-beat baseline for the fake news challenge stance detection task [EB/OL]. (2018−05−21). https://doi.org/10.48550/arXiv.1707.03264.
[本文引用: 1]
[20]
LU Y J, LI C T. GCAN: graph-aware co-attention networks for explainable fake news detection on social media [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [s. l. ]: ACL, 2020: 505−514.
[本文引用: 2]
[21]
RAO D, MIAO X, JIANG Z, et al. STANKER: stacking network based on level-grained attention-masked BERT for rumor detection on social media [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing . Online and Punta Cana: ACL, 2021: 3347−3363.
[本文引用: 10]
[22]
CHEN X, ZHOU F, TRAJCEVSKI G, et al Multi-view learning with distinguishable feature fusion for rumor detection
[J]. Knowledge-Based Systems , 2022 , 240 (8 ): 108085
[本文引用: 12]
[23]
XU Y, GUO J, QIU W, et al. "Comments matter and the more the better!": improving rumor detection with user comments [C]// International Conference on Trust, Security and Privacy in Computing and Communications . Wuhan: IEEE, 2022: 383−390.
[本文引用: 3]
[24]
PUSHP P K, SRIVASTAVA M M. Train once, test anywhere: zero-shot learning for text classification [EB/OL]. (2017−12−23). https://doi.org/10.48550/arXiv.1 712.05972.
[本文引用: 1]
[25]
陆恒杨, 范晨悠, 吴小俊. 面向网络社交媒体的少样本新 冠谣言检测 [J]. 中文信息学报, 2022, 36(1): 135−144.
[本文引用: 2]
LU Hengyang, FAN Chenyou, WU Xiaojun. Few-shot COVID-19 rumor detection for online social media [J]. Journal of Chinese Information Processing . 2022, 36(1): 135−144.
[本文引用: 2]
[26]
ZHOU H, MA T, RONG H, et al MDMN: multi-task and domain adaptation based multi-modal network for early rumor detection
[J]. Expert Systems with Applications , 2022 , 195 (3 ): 116517
[本文引用: 1]
[27]
RAN H, JIA C. Unsupervised cross-domain rumor detection with contrastive learning and cross-attention [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Washington: AAAI Press, 2023: 13510−13518.
[本文引用: 1]
[28]
MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence . New York: AAAI Press, 2016: 3818−3824.
[本文引用: 1]
[29]
DEVLIN J, CHANG M, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics . Minneapolis: ACL, 2019: 4171−4186.
[本文引用: 13]
[30]
BLEI D M, NG A Y, JORDAN M I Latent dirichlet allocation
[J]. Journal of Machine Learning Research , 2003 , 3 (1 ): 993 - 1022
[本文引用: 1]
[31]
MA J, GAO W, WEI Z, et al. Detect rumors using time series of social context information on microblogging websites [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . Melbourne : ACM , 2015: 1751−1754.
[本文引用: 9]
[32]
MA J, GAO W, WONG K F. Detect rumors in microblog posts using propagation structure via kernel learning [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics . Vancouver: ACL, 2017: 708−717.
[本文引用: 12]
[33]
LIU Z, WEI Z, ZHANG R Rumor detection based on convolutional neural network
[J]. Journal of Computer Applications , 2017 , 37 (11 ): 3053
[本文引用: 4]
[34]
SUJANA Y, LI J, KAO H Y. Rumor detection on twitter using multiloss hierarchical bilstm with an attenuation factor [C]// Asian Chapter of the Association for Computational Linguistics . [s. l. ]: ACL, 2020: 18−26.
[本文引用: 3]
[35]
RANI N, DAS P, BHARDWAJ A K. A hybrid deep learning model based on CNN-BiLSTM for rumor detection [C]// Proceedings of the 2021 6th International Conference on Communication and Electronics Systems . Coimbatre: IEEE, 2021: 1423−1427.
[本文引用: 3]
[36]
MA J, GAO W, JOTY S, et al An attention-based rumor detection model with tree-structured recursive neural networks
[J]. ACM Transactions on Intelligent Systems and Technology , 2020 , 11 (4 ): 1 - 28
[本文引用: 2]
[37]
TU K, CHEN C, HOU C, et al Rumor2vec: a rumor detection framework with joint text and propagation structure representation learning
[J]. Information Sciences , 2021 , 560 (1 ): 137 - 151
[本文引用: 4]
[38]
LIU Y, OTT M, GOYAL N, et al. Roberta: a robustly optimized Bert pretraining approach [C]// Proceedings of the 20th Chinese National Conference on Computational Linguistics . Huhhot: Chinese Information Processing Society of China, 2021: 1218−1227.
[本文引用: 5]
[39]
BELTAGY I, PETERS M E, COHAN A. Longformer: the long-document transformer [EB/OL]. [2020-12-02]. https://doi.org/10.48550/arXiv.2004.05150.
[本文引用: 2]
[40]
KHOO L M S, CHIEU H L, QIAN Z, et al. Interpretable rumor detection in microblogs by attending to user interactions [C]// Proceedings of the AAAI Conference on Artificial Intelligence . California: AAAI Press, 2020: 8783-8790.
[本文引用: 3]
[41]
WU Y, ZENG Y, YANG J, et al Weibo rumor recognition based on communication and stacking ensemble learning
[J]. Discrete Dynamics in Nature and Society , 2020 , 2020 : 1 - 12
[本文引用: 3]
[42]
RISCH J, KRESTEL R. Bagging bert models for robust aggression identification [C]// Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying . Marseille: ELRA, 2020: 55−61.
[本文引用: 2]
[43]
GENG Y, LIN Z, FU P, et al. Rumor detection on social media: a multi-view model using self-attention mechanism [C]// Proceedings of the Computational Science-ICCS 2019: 19th International Conference . Faro: Springer-Verlag, 2019: 339−352.
[本文引用: 3]
[44]
LI S, ZHAO Z, HU R, et al. Analogical reasoning on chinese morphological and semantic relations [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics . Melbourne: ACL, 2018: 138−143.
[本文引用: 1]
3
... 随着Web2.0时代的发展,社交媒体成为了谣言传播的主要媒介. 在谣言传播的过程[1 ] 中,旧谣言具有生命周期,因此有可能会再次出现在公众面前[2 ] ,此时针对已知信息进行训练的传统谣言检测模型可以有效应对这种情况. 然而除了旧谣言以外,未知的谣言也不能忽视. 实际上,由于公众对未知的信息更为敏感,未知的谣言更容易造成社会轰动和经济损失. 因此,在兼顾对旧谣言检测的基础上,着重针对未知谣言的检测是面向现实场景的关键任务. 不过,依赖大规模人工标注数据的模型存在以下2方面的局限性:首先,大规模人工标记数据集的成本较高;其次,模型容易依赖已知数据中的对象相关信息来做出分类,因此在现实场景中,针对未知对象的谣言检测更为困难. ...
... PT-HCL[1 ] :提出存在一种可迁移的特征类型,并设计了一个分层对比学习框架,能够帮助模型在零样本和少样本场景下的表现,利用该可迁移特征可以更好地检测标签. ...
... 如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
1
... 随着Web2.0时代的发展,社交媒体成为了谣言传播的主要媒介. 在谣言传播的过程[1 ] 中,旧谣言具有生命周期,因此有可能会再次出现在公众面前[2 ] ,此时针对已知信息进行训练的传统谣言检测模型可以有效应对这种情况. 然而除了旧谣言以外,未知的谣言也不能忽视. 实际上,由于公众对未知的信息更为敏感,未知的谣言更容易造成社会轰动和经济损失. 因此,在兼顾对旧谣言检测的基础上,着重针对未知谣言的检测是面向现实场景的关键任务. 不过,依赖大规模人工标注数据的模型存在以下2方面的局限性:首先,大规模人工标记数据集的成本较高;其次,模型容易依赖已知数据中的对象相关信息来做出分类,因此在现实场景中,针对未知对象的谣言检测更为困难. ...
1
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
1
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
2
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
... 4)零样本谣言检测. 让模型学习源数据中的相关信息和特征,再迁移应用至不同语言和领域中的谣言检测. Lin等[5 ] 提出零样本响应感知的提示学习框架RPL-*来尝试解决这个问题. 然而不同领域中的对象各有不同,从而容易导致同一类领域中不同对象的2个实例容易受到源信息的干扰. 与零样本谣言检测不同的是,零样本对象谣言检测会将实例的颗粒度细化至对象级别. ...
Toward any-language zero-shot topic classification of textual documents
1
2019
... 为了评估本研究所提出的模型的语言泛化能力,将所提模型使用中文数据集Ma-Weibo与英文数据集Twitter15分别进行2次交叉验证,并且采用与RPL-*[6 ] 相同的指标进行模型语言泛化能力的评估,分别为:准确度A 、谣言F1分数(R-F1)、非谣言F1分数(NR-F1)和Macro-F1分数. ...
1
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
Generative adversarial networks
1
2020
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
1
... 零样本学习是机器学习当中的一种问题设置,属于迁移学习的特例,最早由Larochelle等[3 ] 在2008年提出. 零样本学习的方法会将研究的重点聚焦在如何令样本和标签处于同一个语义空间当中,如文献[4 ]使用精确语义分析 (explicit semantic analysis,ESA) 表示. 同时,这种方法也可以被扩展到多语言的迁移学习中[5 -7 ] ,而在此基础上可通过表示学习的方法来进一步增强语义的表达,如生成对抗网络(generative adversarial networks,GAN)[8 ] 、变分自编码器(variational autoencoder,VAE)[9 ] 和对比学习等. 其中,对比学习可以在只有少量标注数据和大量的未标注数据的情况下,显著提高模型的性能. ...
1
... 对比学习是一种自监督学习的范式,可以通过设计代理任务和对比损失函数,使同类样本的语义表示在向量空间中彼此聚拢,而令非同类样本的语义表示在向量空间中互相疏离,便可以令模型学习到更好的语义表示,从而增强模型的稳健性. 近年来,对比学习在计算机视觉领域已经取得了较大的成功,例如SimCLR[10 ] 、MoCo[11 ] ,但在自然语言处理领域还面临着一些挑战,比如如何对文本进行有效的数据增强、如何设计合适的代理任务和对比损失函数. Liang等[12 ] 将立场特征分为无关于立场与特定于立场类别,并提出分层对比学习框架PT-HCL. 该对比学习框架在零样本或少样本场景中,能让模型有效地利用可迁移的立场特征来表示未知目标的立场. 但是,在数据增强当中容易引入不必要的噪声,从而容易导致模型学习到质量不佳的表征. ...
1
... 对比学习是一种自监督学习的范式,可以通过设计代理任务和对比损失函数,使同类样本的语义表示在向量空间中彼此聚拢,而令非同类样本的语义表示在向量空间中互相疏离,便可以令模型学习到更好的语义表示,从而增强模型的稳健性. 近年来,对比学习在计算机视觉领域已经取得了较大的成功,例如SimCLR[10 ] 、MoCo[11 ] ,但在自然语言处理领域还面临着一些挑战,比如如何对文本进行有效的数据增强、如何设计合适的代理任务和对比损失函数. Liang等[12 ] 将立场特征分为无关于立场与特定于立场类别,并提出分层对比学习框架PT-HCL. 该对比学习框架在零样本或少样本场景中,能让模型有效地利用可迁移的立场特征来表示未知目标的立场. 但是,在数据增强当中容易引入不必要的噪声,从而容易导致模型学习到质量不佳的表征. ...
5
... 对比学习是一种自监督学习的范式,可以通过设计代理任务和对比损失函数,使同类样本的语义表示在向量空间中彼此聚拢,而令非同类样本的语义表示在向量空间中互相疏离,便可以令模型学习到更好的语义表示,从而增强模型的稳健性. 近年来,对比学习在计算机视觉领域已经取得了较大的成功,例如SimCLR[10 ] 、MoCo[11 ] ,但在自然语言处理领域还面临着一些挑战,比如如何对文本进行有效的数据增强、如何设计合适的代理任务和对比损失函数. Liang等[12 ] 将立场特征分为无关于立场与特定于立场类别,并提出分层对比学习框架PT-HCL. 该对比学习框架在零样本或少样本场景中,能让模型有效地利用可迁移的立场特征来表示未知目标的立场. 但是,在数据增强当中容易引入不必要的噪声,从而容易导致模型学习到质量不佳的表征. ...
... 使用由Liang等[12 ] 提出的分层对比学习损失函数$ {{{\boldsymbol{L}}}}_{\mathrm{c}\mathrm{l}} $ $ {B}={\left\{{\boldsymbol{h}}_{i}\right\}}_{i=1}^{{N}_{{\mathrm{b}}}} $ $ {N}_{{\mathrm{b}}} $ $ {B} $
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
... Rumor detection results from Chinese training dataset to English test dataset
% Tab.5 方法 A Mac-F1 R-F1 NR-F1 PT-HCL[12 ] 49.88 48.39 57.14 39.64 ZPTHCL(本研究) 56.51 53.60 41.97 65.23 w/o cl 51.35 50.08 42.11 58.05 w/o au 53.81 53.18 47.78 58.59 w/o text 54.05 53.87 56.81 50.92
表 6 由英文训练集至中文测试集上的谣言检测结果 ...
... Rumor detection results from English training dataset to Chinese test dataset
% Tab.6 方法 A Mac-F1 R-F1 NR-F1 PT-HCL[12 ] 50.20 48.33 38.52 58.15 ZPTHCL(本研究) 54.60 50.68 36.77 64.59 w/o cl 51.40 51.33 53.18 49.48 w/o au 52.80 52.11 57.86 46.36 w/o text 48.60 48.25 52.50 44.01
如表7 所示为所提模型在数据缺乏标签的情况下的性能. 表中,ρ 为数据集数据利用率. 在训练数据利用率为5%,即训练数据只有Ma-Weibo数据集总样本的5%时,模型对其余数据的标注准确度便已达到了94.70%;当训练数据只有Ma-Weibo数据集总样本的10%、15%、20%时,模型对其余数据的标注准确度分别达到了96.74%、97.53%和98.33%. 设置相同的方法,也在数据集Weibo20、Twitter15和Twitter16上进行实验,同样可以达到较好的效果. 故此处实验验证了本研究所提模型可以在较大程度上缓解谣言检测模型训练需要大量人工标注的问题. ...
Polarization and fake news: early warning of potential misinformation targets
1
2019
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
Fake news, rumor, information pollution in social media and web: a contemporary survey of state-of-the-arts, challenges and opportunities
1
2020
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
Rumor events detection enhanced by encoding sentimental information into time series division and word representations
1
2020
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
1
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
4
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... Bi-GCN[17 ] :不仅考虑传播树的深度扩散,同时还考虑谣言检测中的分布结构. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
1
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
1
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
2
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... 对于Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 采用与以往谣言检测任务相同的评估指标[20 ] ,分别为F1分数、召回率R 、精准率P 和准确度A . 而对于零样本对象谣言数据集Zeo-Weibo而言,由于任务的特殊性,除了使用上述评估指标外,还将它们各自在不同对象数据集所得的均值作为额外的评估指标,表示为Avg-F1、Avg-R 、Avg-P 、Avg-A ,以衡量模型在多个未知对象的谣言数据集中的指标表现. 同时,F1、R 、P 和A 在同一个对象数据集所得的均值作为一个额外的评估指标,表示为Avg-Odataset. 将Avg-F1、Avg-R 、Avg-P 、Avg-A ,进行一个相加取均值的计算,所得的数值称为SCO,主要以此指标来评估模型在数据集Zeo-Weibo中的性能表现. ...
10
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... 在5个真实数据集上评估所提方法的有效性,包括Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 和基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo. 这5个数据集中都包含2个标签类别,分别为谣言和非谣言. 具体的统计信息如表1 、2 所示. 表中,N 为数据集中数据量. 其中,如表2 所示展示了基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo,其针对零样本学习任务,包含面向7个不同对象的言论,分别为中国、刘翔、北京、地震、日本、死亡和美国. Zeo-Weibo共包含1440 条数据,谣言占721条,非谣言占719条. 在对Zeo-Weibo进行实验时,仅将1个对象的数据作为测试集,而剩余的6个作为训练集和验证集,以此对所有的7个对象进行相同的实验操作. ...
... STANKER[21 ] :使用2个层级注意力掩码BERT模型作为编码器,利用对言论的评论作为辅助特征,并在低层次的注意力机制中屏蔽了微博内容和评论之间的共同注意力,再将2个LGAM-BERT模型的预测结果作为新的特征输入到一个元分类器. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... [21 ]、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... [21 ]实验所得到的数据. ...
... 对于Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 采用与以往谣言检测任务相同的评估指标[20 ] ,分别为F1分数、召回率R 、精准率P 和准确度A . 而对于零样本对象谣言数据集Zeo-Weibo而言,由于任务的特殊性,除了使用上述评估指标外,还将它们各自在不同对象数据集所得的均值作为额外的评估指标,表示为Avg-F1、Avg-R 、Avg-P 、Avg-A ,以衡量模型在多个未知对象的谣言数据集中的指标表现. 同时,F1、R 、P 和A 在同一个对象数据集所得的均值作为一个额外的评估指标,表示为Avg-Odataset. 将Avg-F1、Avg-R 、Avg-P 、Avg-A ,进行一个相加取均值的计算,所得的数值称为SCO,主要以此指标来评估模型在数据集Zeo-Weibo中的性能表现. ...
... 为了验证模型是否可以缓解谣言检测模型训练需要大量人工标注的问题,在数据集Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 和Twitter16[32 ] 中分别设置5%、10%、15%、20%的少量实例占比用于模型训练,再利用已训练好的模型对其余大量的实例进行标注. 使用F1分数、召回率、精准率、准确度作为评估指标,以展示模型在数据缺乏标签的情况下的性能. ...
... 如表3 所示为本研究模型与对比模型在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 4个数据集当中的性能表现. 表中,加粗的数值为最优的表现分数,“—”表示模型原文中并没有在对应数据集上进行实验. 根据对比可知,所提出的模型在这4个数据集当中的表现最优. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
Multi-view learning with distinguishable feature fusion for rumor detection
12
2022
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... Arc1[22 ] :通过将句子的语义表示进行维度取均后,再与句子标签的语义表示进行拼接. ...
... Arc2[22 ] :基于LSTM模型,以时间步的方式输入句子的语义表示. 最后再将网络的最后一个隐藏状态与句子标签的语义表示进行拼接. ...
... Arc3[22 ] :基于LSTM模型,以时间步的方式输入句子的语义表示并与句子标签的语义表示进行拼接,再使用最后一个隐藏层训练一个分类器来进行预测. ...
... UMLARD[22 ] :考虑用户的多个不同视图,并采用注意力网络将更全面的信息进行整合. ...
... 模型CNN[33 ] 、BiLSTM[34 ] 、CNN-BiLSTM[35 ] 、Arc1[22 ] 、Arc2[22 ] 、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... [22 ]、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... [22 ]在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
... [
22 ]
76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55 如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
... [
22 ]
74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55 如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
3
... 在现有针对谣言检测的研究中,将谣言检测视作为一个文本分类的任务,而将所要检测样本的标签类型分为谣言标签和非谣言标签. 谣言检测的任务可以用传统的机器学习方法解决,如Vicario等[13 ] 考虑用户行为的特征,或Meel等[14 ] 同时考虑社交媒体的言论及其底下的评论,将评论作为重要辅助信息;Wang等[15 ] 利用源帖子、评论的语义特征和情感特征,将它们输入到两层门控循环单元网络 (gated recurrent units,GRU) ;Kumar等[16 ] 应用基于树结构的LSTM模型再结合图卷积网络(graph convolutional network,GCN)提取特征,采用多任务学习并在树中向上传播有用的立场信号,以便在根节点进行谣言分类. Bian等[17 ] 将GCN扩展为Bi-directional GCN(Bi-GCN)探索广泛的结构谣言检测的分散性;Zhang等[18 ] 按时间顺序编码回复一个LSTM组件;Riedel等[19 ] 从新闻内容和对应评论的余弦相似性中获益,同时设置相似度的阈值以过滤那些不相关的评论;Lu等[20 ] 将用户画像放入GCAN中提取传播特征. Rao等[21 ] 基于模型融合的策略,采用2个level-grained attention masked BERT (LGAM-BERT) 模型作为基础编码器,将评论作为重要的辅助特征,并掩盖了源帖和评论帖之间在较低层的注意力. Chen[22 ] 等考虑用户的多个不同视图,并采用注意力网络来将更全面的信息进行整合. Xu等[23 ] 将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... ToBERT[23 ] :将源帖子和相关评论拼合成一个长文本,并将其重新分割成更适于BERT的短文本,再将这些短文本分别输入到BERT中得到各短文本的表征向量,最后将所有的表征向量输入到基于 LSTM 网络或Transformer层的分类器中. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
1
... 1) 零样本文本分类. Pushp等[24 ] 提出该任务,并构思了3种深度学习模型. 零样本文本分类为零样本对象谣言检测的任务提供了相应的解决方案,但上述模型在进行零样本对象谣言检测任务时,未能表现出相应的稳健性. 这是由于模型对上下文的理解能力较差,且不能较好地学习不同对象中的谣言特征. 因此,零样本文本分类能够缓解零样本对象谣言检测的问题,但现有方法在对象谣言数据集当中的表现总体欠佳. ...
2
... 2) 少样本谣言检测. 目前主要由陆恒杨等[25 ] 进行研究. 研究最初源于2019年新冠疫情的突发,当时互联网上可用数据有限,相关研究面临较大的挑战,因此,陆恒杨等[25 ] 提出采用基于元学习的深度神经网络进行新冠疫情相关的谣言检测任务. 不过,当此方法用于零样本对象谣言检测时,由于模型本身较依赖训练集与这个话题之间的强假设相关性,其在对象数据集上并不能表现出较好的检测水平. ...
... [25 ]提出采用基于元学习的深度神经网络进行新冠疫情相关的谣言检测任务. 不过,当此方法用于零样本对象谣言检测时,由于模型本身较依赖训练集与这个话题之间的强假设相关性,其在对象数据集上并不能表现出较好的检测水平. ...
2
... 2) 少样本谣言检测. 目前主要由陆恒杨等[25 ] 进行研究. 研究最初源于2019年新冠疫情的突发,当时互联网上可用数据有限,相关研究面临较大的挑战,因此,陆恒杨等[25 ] 提出采用基于元学习的深度神经网络进行新冠疫情相关的谣言检测任务. 不过,当此方法用于零样本对象谣言检测时,由于模型本身较依赖训练集与这个话题之间的强假设相关性,其在对象数据集上并不能表现出较好的检测水平. ...
... [25 ]提出采用基于元学习的深度神经网络进行新冠疫情相关的谣言检测任务. 不过,当此方法用于零样本对象谣言检测时,由于模型本身较依赖训练集与这个话题之间的强假设相关性,其在对象数据集上并不能表现出较好的检测水平. ...
MDMN: multi-task and domain adaptation based multi-modal network for early rumor detection
1
2022
... 3)跨领域谣言检测. 主要通过调整已经针对特定目标训练的分类器,使其能够有效适应并推广到相关的新目标上. Zhou等[26 ] 提出基于多任务和领域适应的多模态网络,结合文本、图像和社交上下文信息进行谣言检测. 该模型使用多任务学习提高模型的泛化能力,并使用领域适应方法缓解源领域和目标领域之间的分布差异. Ran等[27 ] 提出端到端的无监督跨领域谣言检测模型,利用对比学习和交叉注意力机制来实现跨领域特征对齐和原型对齐. 然而,跨领域的谣言检测通常是去学习如何通过设置特定的训练目标,再使其生成特定领域的谣言特征来适应相关的未知测试. 与跨目标谣言检测不同的是,零样本对象谣言检测旨在自动检测未知对象的谣言样例. ...
1
... 3)跨领域谣言检测. 主要通过调整已经针对特定目标训练的分类器,使其能够有效适应并推广到相关的新目标上. Zhou等[26 ] 提出基于多任务和领域适应的多模态网络,结合文本、图像和社交上下文信息进行谣言检测. 该模型使用多任务学习提高模型的泛化能力,并使用领域适应方法缓解源领域和目标领域之间的分布差异. Ran等[27 ] 提出端到端的无监督跨领域谣言检测模型,利用对比学习和交叉注意力机制来实现跨领域特征对齐和原型对齐. 然而,跨领域的谣言检测通常是去学习如何通过设置特定的训练目标,再使其生成特定领域的谣言特征来适应相关的未知测试. 与跨目标谣言检测不同的是,零样本对象谣言检测旨在自动检测未知对象的谣言样例. ...
1
... 根据文献[28 ],可以将社交媒体上的信息分为2类:谣言(T)和非谣言(F). 基于此分类,可以将谣言检测任务描述为学习一个函数$ {F}{ }:{ }{F}\left({{p}}_{i}\right)\to {{y}}_{i} $ y i $ {{y}}_{i}\in \left\{\mathrm{0,1}\right\} $
13
... 将区分通义掩码特征的任务设计为代理任务,为了在训练集当中找到具有通义掩码特征的样本,首先须利用训练集将模型$ \mathrm{{\rm M}} $ [29 ] 或BERT-base-chinese[29 ] 作为谣言检测模型$ {\rm M} $ $ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right]{{\boldsymbol{S}}}_{P}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right] $
... [29 ]作为谣言检测模型$ {\rm M} $ $ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right]{{\boldsymbol{S}}}_{P}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right] $
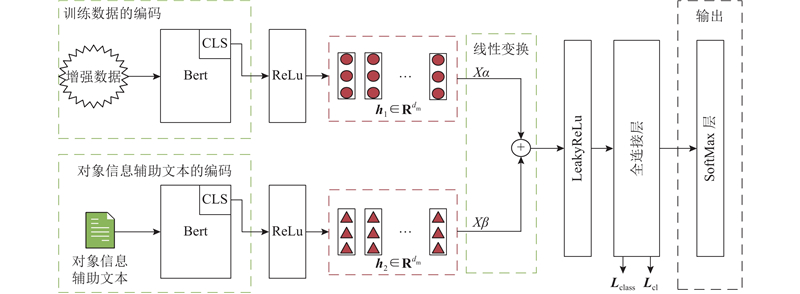
... 结合上文,使用$ {{\boldsymbol{S}}}_O $ $ {D}_{{\mathrm{s}}} $ $ {S}_{{O}}^{m-w}=\{{{\boldsymbol{S}}}_{{O}}^{1},{{\boldsymbol{S}}}_{{O}}^{2},\cdots , {{\boldsymbol{S}}}_{{O}}^{n}\} $ n 个句子. 根据源谣言数据集中语言的不同,使用BERT-base-uncase[29 ] 或BERT-base-chinese[29 ] 作为训练数据的编码器. 它采用“$ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right] {{\boldsymbol{S}}}_{{{{O}}}}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \boldsymbol{H} $ 1 . 再将$ \boldsymbol{H} $ 1 中[CLS]分词的语义向量输入至ReLU激活函数得到$ \boldsymbol{h} $ 1 ,其维度为$ {d}_{{\mathrm{m}}} $ $ {\boldsymbol{h}}_{1}\in {{{\bf{R}}}}^{{d}_{{\mathrm{m}}}} $
... [29 ]作为训练数据的编码器. 它采用“$ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right] {{\boldsymbol{S}}}_{{{{O}}}}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \boldsymbol{H} $ 1 . 再将$ \boldsymbol{H} $ 1 中[CLS]分词的语义向量输入至ReLU激活函数得到$ \boldsymbol{h} $ 1 ,其维度为$ {d}_{{\mathrm{m}}} $ $ {\boldsymbol{h}}_{1}\in {{{\bf{R}}}}^{{d}_{{\mathrm{m}}}} $
... 根据源谣言数据集中语言的不同,使用BERT-base-uncase[29 ] 或BERT-base-chinese[29 ] 作为对象信息辅助文本的编码器,它采用“$ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right]{\boldsymbol{S}}_{{O}}^{\mathrm{A}}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \boldsymbol{H} $ 2 . 再将$ \boldsymbol{H} $ 1 中[CLS]分词的语义向量输入至ReLU激活函数得到$ \boldsymbol{h}_2 $ $ {d}_{{\mathrm{m}}} $ $ {\boldsymbol{h}}_{2}\in {\mathbf{R}}^{{d}_{{\mathrm{m}}}} $ . 则对每个所属对象的样本相应输出如下: ...
... [29 ]作为对象信息辅助文本的编码器,它采用“$ \left[\mathrm{C}\mathrm{L}\mathrm{S}\right]{\boldsymbol{S}}_{{O}}^{\mathrm{A}}\left[\mathrm{S}\mathrm{E}\mathrm{P}\right] $ $ \boldsymbol{H} $ 2 . 再将$ \boldsymbol{H} $ 1 中[CLS]分词的语义向量输入至ReLU激活函数得到$ \boldsymbol{h}_2 $ $ {d}_{{\mathrm{m}}} $ $ {\boldsymbol{h}}_{2}\in {\mathbf{R}}^{{d}_{{\mathrm{m}}}} $ . 则对每个所属对象的样本相应输出如下: ...
... BERT[29 ] :由Google开发的一种预训练模型,可视作多层双向的Transformer编码器,可以根据输入文本的上下文来理解文本中的含义,并能在微调后应用于下游任务当中. ...
... 所提模型中的参数由Adam优化器进行更新,学习率初始化为2×10−5 ,根据源谣言数据集中语言的不同,使用BERT-base-uncase[29 ] 、BERT-base-chinese[29 ] 或BERT-base-multilingual-cased[29 ] 作为训练数据的编码器. 超参数$ \alpha $ $ \beta $
... [29 ]或BERT-base-multilingual-cased[29 ] 作为训练数据的编码器. 超参数$ \alpha $ $ \beta $
... [29 ]作为训练数据的编码器. 超参数$ \alpha $ $ \beta $
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
Latent dirichlet allocation
1
2003
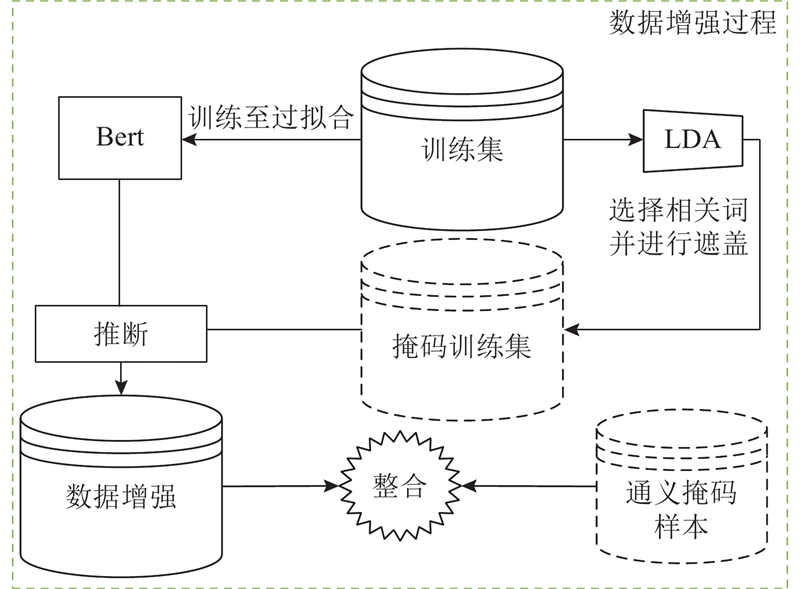
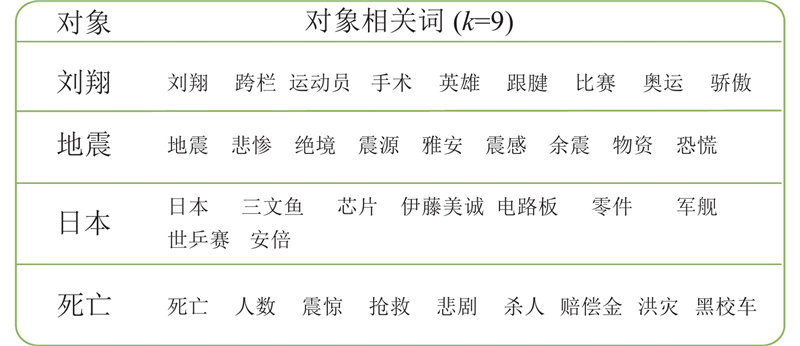
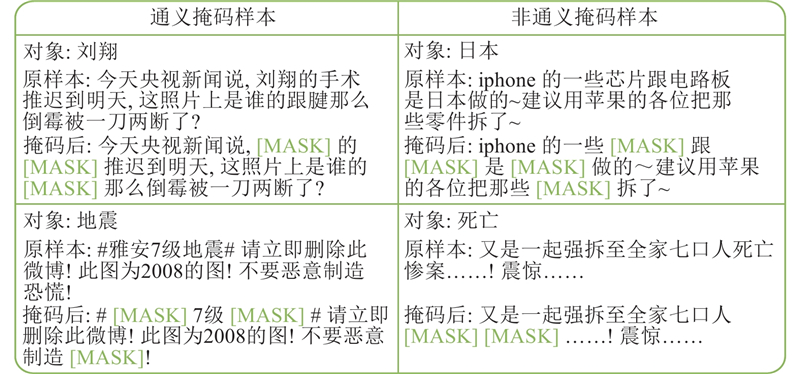
... 使用隐含狄利克雷分布(LDA)[30 ] 针对每一个对象训练集对应的对象进行相关词的选择. 具体来说,每个对象的文档可以用主题T i $ {{W}}_{g}=\{{{W}}_{1},{{W}}_{2},\cdots ,{{W}}_{f}\} $ f 个对象相关词,其中f 为人工所设置的超参数. 使用特殊的标记[MASK]来遮盖对象训练集中每个训练样本的主题相关词$ {W}_{g} $ . 使用如图3 中所示的主题相关词可以得到如图4 所示的掩码示例. ...
9
... 在5个真实数据集上评估所提方法的有效性,包括Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 和基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo. 这5个数据集中都包含2个标签类别,分别为谣言和非谣言. 具体的统计信息如表1 、2 所示. 表中,N 为数据集中数据量. 其中,如表2 所示展示了基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo,其针对零样本学习任务,包含面向7个不同对象的言论,分别为中国、刘翔、北京、地震、日本、死亡和美国. Zeo-Weibo共包含1440 条数据,谣言占721条,非谣言占719条. 在对Zeo-Weibo进行实验时,仅将1个对象的数据作为测试集,而剩余的6个作为训练集和验证集,以此对所有的7个对象进行相同的实验操作. ...
... SVM-TS[31 ] :利用内容、用户和传播模式等特征,并且考虑这些特征在谣言传播过程中的变化,通过时间序列建模技术捕捉这些特征的动态特性,再使用支持向量机的方法来进行谣言检测. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... [31 ]、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... 对于Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 采用与以往谣言检测任务相同的评估指标[20 ] ,分别为F1分数、召回率R 、精准率P 和准确度A . 而对于零样本对象谣言数据集Zeo-Weibo而言,由于任务的特殊性,除了使用上述评估指标外,还将它们各自在不同对象数据集所得的均值作为额外的评估指标,表示为Avg-F1、Avg-R 、Avg-P 、Avg-A ,以衡量模型在多个未知对象的谣言数据集中的指标表现. 同时,F1、R 、P 和A 在同一个对象数据集所得的均值作为一个额外的评估指标,表示为Avg-Odataset. 将Avg-F1、Avg-R 、Avg-P 、Avg-A ,进行一个相加取均值的计算,所得的数值称为SCO,主要以此指标来评估模型在数据集Zeo-Weibo中的性能表现. ...
... 为了验证模型是否可以缓解谣言检测模型训练需要大量人工标注的问题,在数据集Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 和Twitter16[32 ] 中分别设置5%、10%、15%、20%的少量实例占比用于模型训练,再利用已训练好的模型对其余大量的实例进行标注. 使用F1分数、召回率、精准率、准确度作为评估指标,以展示模型在数据缺乏标签的情况下的性能. ...
... 如表3 所示为本研究模型与对比模型在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 4个数据集当中的性能表现. 表中,加粗的数值为最优的表现分数,“—”表示模型原文中并没有在对应数据集上进行实验. 根据对比可知,所提出的模型在这4个数据集当中的表现最优. ...
... 如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
... [31 ]的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
12
... 在5个真实数据集上评估所提方法的有效性,包括Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 和基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo. 这5个数据集中都包含2个标签类别,分别为谣言和非谣言. 具体的统计信息如表1 、2 所示. 表中,N 为数据集中数据量. 其中,如表2 所示展示了基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo,其针对零样本学习任务,包含面向7个不同对象的言论,分别为中国、刘翔、北京、地震、日本、死亡和美国. Zeo-Weibo共包含1440 条数据,谣言占721条,非谣言占719条. 在对Zeo-Weibo进行实验时,仅将1个对象的数据作为测试集,而剩余的6个作为训练集和验证集,以此对所有的7个对象进行相同的实验操作. ...
... [32 ]和基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo. 这5个数据集中都包含2个标签类别,分别为谣言和非谣言. 具体的统计信息如表1 、2 所示. 表中,N 为数据集中数据量. 其中,如表2 所示展示了基于Ma-Weibo的零样本对象谣言数据集Zeo-Weibo,其针对零样本学习任务,包含面向7个不同对象的言论,分别为中国、刘翔、北京、地震、日本、死亡和美国. Zeo-Weibo共包含1440 条数据,谣言占721条,非谣言占719条. 在对Zeo-Weibo进行实验时,仅将1个对象的数据作为测试集,而剩余的6个作为训练集和验证集,以此对所有的7个对象进行相同的实验操作. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... [32 ]这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... 对于Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 采用与以往谣言检测任务相同的评估指标[20 ] ,分别为F1分数、召回率R 、精准率P 和准确度A . 而对于零样本对象谣言数据集Zeo-Weibo而言,由于任务的特殊性,除了使用上述评估指标外,还将它们各自在不同对象数据集所得的均值作为额外的评估指标,表示为Avg-F1、Avg-R 、Avg-P 、Avg-A ,以衡量模型在多个未知对象的谣言数据集中的指标表现. 同时,F1、R 、P 和A 在同一个对象数据集所得的均值作为一个额外的评估指标,表示为Avg-Odataset. 将Avg-F1、Avg-R 、Avg-P 、Avg-A ,进行一个相加取均值的计算,所得的数值称为SCO,主要以此指标来评估模型在数据集Zeo-Weibo中的性能表现. ...
... [32 ]采用与以往谣言检测任务相同的评估指标[20 ] ,分别为F1分数、召回率R 、精准率P 和准确度A . 而对于零样本对象谣言数据集Zeo-Weibo而言,由于任务的特殊性,除了使用上述评估指标外,还将它们各自在不同对象数据集所得的均值作为额外的评估指标,表示为Avg-F1、Avg-R 、Avg-P 、Avg-A ,以衡量模型在多个未知对象的谣言数据集中的指标表现. 同时,F1、R 、P 和A 在同一个对象数据集所得的均值作为一个额外的评估指标,表示为Avg-Odataset. 将Avg-F1、Avg-R 、Avg-P 、Avg-A ,进行一个相加取均值的计算,所得的数值称为SCO,主要以此指标来评估模型在数据集Zeo-Weibo中的性能表现. ...
... 为了验证模型是否可以缓解谣言检测模型训练需要大量人工标注的问题,在数据集Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 和Twitter16[32 ] 中分别设置5%、10%、15%、20%的少量实例占比用于模型训练,再利用已训练好的模型对其余大量的实例进行标注. 使用F1分数、召回率、精准率、准确度作为评估指标,以展示模型在数据缺乏标签的情况下的性能. ...
... [32 ]中分别设置5%、10%、15%、20%的少量实例占比用于模型训练,再利用已训练好的模型对其余大量的实例进行标注. 使用F1分数、召回率、精准率、准确度作为评估指标,以展示模型在数据缺乏标签的情况下的性能. ...
... 如表3 所示为本研究模型与对比模型在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 4个数据集当中的性能表现. 表中,加粗的数值为最优的表现分数,“—”表示模型原文中并没有在对应数据集上进行实验. 根据对比可知,所提出的模型在这4个数据集当中的表现最优. ...
... [32 ]4个数据集当中的性能表现. 表中,加粗的数值为最优的表现分数,“—”表示模型原文中并没有在对应数据集上进行实验. 根据对比可知,所提出的模型在这4个数据集当中的表现最优. ...
... 如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
... [32 ]的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
Rumor detection based on convolutional neural network
4
2017
... CNN[33 ] :使用卷积神经网络来挖掘文本的语义特征. ...
... 模型CNN[33 ] 、BiLSTM[34 ] 、CNN-BiLSTM[35 ] 、Arc1[22 ] 、Arc2[22 ] 、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
3
... BiLSTM[34 ] :使用具有衰减因子的多损失层次BiLSTM模型. ...
... 模型CNN[33 ] 、BiLSTM[34 ] 、CNN-BiLSTM[35 ] 、Arc1[22 ] 、Arc2[22 ] 、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
3
... CNN-BiLSTM[35 ] :使用Glove作为词嵌入,并将CNN与BiLSTM相结合来提取上下文信息的特征. ...
... 模型CNN[33 ] 、BiLSTM[34 ] 、CNN-BiLSTM[35 ] 、Arc1[22 ] 、Arc2[22 ] 、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...
... Results of different methods on Zeo-Weibo object rumor detection dataset
% Tab.4 方法 Avg-F1 Avg-R Avg-P Avg-A SCO CNN[33 ] 68.82 76.43 71.71 82.97 74.98 BiLSTM[34 ] 70.68 72.02 70.66 76.59 72.48 CNN-BiLSTM[35 ] 64.01 66.58 62.84 75.88 67.32 Arc1[22 ] 79.64 80.26 79.73 81.58 80.30 Arc2[22 ] 76.29 77.99 76.97 82.39 78.41 Arc3[22 ] 74.77 77.33 76.40 82.02 77.63 BERT[29 ] 85.24 87.09 83.90 85.39 85.40 PT-HCL[12 ] 85.35 85.09 86.39 84.88 85.43 ZPTHCL 87.58 87.25 88.24 87.13 87.55
如表5 所示为所提模型通过对中文数据集Ma-Weibo[31 ] 的学习,将所习得的知识迁移至英文数据集Twitter16[32 ] 的语言泛化能力. 如表6 所示为所提模型通过对英文数据集Twitter16[32 ] 的学习,将所习得的知识迁移至中文数据集Ma-Weibo[31 ] 的语言泛化能力. 可以看出,所提模型相较PT-HCL[1 ] 以及其他消融模型具有更强的语言泛化能力,但总体的性能表现还有一定的优化空间,可设计更好的对象辅助文本来对模型性能进行进一步的优化. ...
An attention-based rumor detection model with tree-structured recursive neural networks
2
2020
... Ma-RvNN[36 ] :构造传播树以表示帖子的扩散,并基于树结构的递归神经网络模型以提取特征. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
Rumor2vec: a rumor detection framework with joint text and propagation structure representation learning
4
2021
... GCNN[37 ] :使用联合图合并所有推文的传播结构以减轻稀疏性再使用网络嵌入学习联合图中节点的表示. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... [
37 ]
90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89 如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
5
... RoBERTa[38 ] :在BERT的研究基础上,对预训练的策略进行优化. 只使用MLM(masked language model)的自监督学习方法,而不采用预测下一句(next sentence prediction,NSP)的方法. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... [
38 ]
96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89 如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
... [
38 ]
92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89 如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
2
... Longformer[39 ] :使用随序列长度线性缩放的注意力机制,解决Transformer无法处理长序列的问题. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
3
... PLAN[40 ] :基于推文级别的自注意力网络,在Transformer中使用多头注意机制对推文之间的长距离交互进行建模. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
Weibo rumor recognition based on communication and stacking ensemble learning
3
2020
... Wu-Stacking[41 ] :结合传播学构建了更适合谣言识别的特征集,并将多个基础分类器的预测结果作为新的特征输入到一个元分类器中. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
2
... Bagging-BERT(2)[42 ] :通过对训练数据进行有放回的随机抽样,生成多个子数据集,然后在每个子数据集上训练一个模型,最后对所有模型的预测结果进行投票或平均的方法,来降低模型方差并提供更稳健的预测. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
3
... Geng-Ensemble[43 ] :使用3个基于RNN的学习器,为不同的词分配权重,最后通过多数表决来输出结果. ...
... 模型SVM-TS[31 ] 、Ma-RvNN[36 ] 、GCNN[37 ] 、Bi-GCN[17 ] 、BERT[29 ] 、RoBERTa[38 ] 、Longformer[39 ] 、PLAN[40 ] 、Wu-Stacking[41 ] 、Bagging-BERT(2)[42 ] 、Geng-Ensemble[43 ] 和STANKER[21 ] 在Ma-Weibo[31 ] 、Weibo20[21 ] 、Twitter15[32 ] 、Twitter16[32 ] 这4个数据集的分数表现使用对应各模型在STANKER[21 ] 实验所得到的数据. ...
... Accuracy of different methods on four rumor detection data sets
% Tab.3 方法 A Ma-Weibo Weibo20 Twitter15 Twitter16 基于机器学 SVM-TS[33 ] 88.46 89.32 73.85 76.46 基于图结 Ma-RvNN[38 ] 94.81 94.31 93.92 92.68 GCNN[37 ] 95.10 93.31 87.21 92.14 Bi-GCN[17 ] 96.12 91.12 95.96 95.15 UMLARD[22 ] 92.80 — 85.70 90.10 基于Transformer BERT[29 ] 93.03 96.21 96.67 93.20 RoBERTa[38 ] 96.03 96.11 93.56 93.69 Longformer[37 ] 90.84 95.61 90.57 90.78 PLAN[38 ] 92.26 92.56 92.13 94.23 ToBERT[23 ] 98.12 — — — 基于模型融 Wu-Stacking[41 ] 93.48 93.52 92.86 92.86 Bagging-BERT(2)[40 ] 96.67 96.68 96.50 96.50 Geng-Ensemble[43 ] 95.60 95.67 95.12 95.12 STANKER[21 ] 97.45 97.46 97.17 97.17 基于对比学 ZPTHCL 98.97 98.86 98.89 98.89
如表4 所示为所提模型与常用神经网络模型在Zeo-Weibo当中的性能. 表中,w/o cl、w/o au、w/o text分别表示不使用分层对比损失函数、不加入通义掩码样本、不使用对象信息辅助文本. 可以看出,在Avg-F1、Avg-R 、Avg-P 、Avg-A 、SCO上,ZPTHCL在多个对象数据集中,均要优于所引论文中的模型. ...
1
... 模型CNN[33 ] 、BiLSTM[34 ] 、CNN-BiLSTM[35 ] 、Arc1[22 ] 、Arc2[22 ] 、Arc3[22 ] 在Zeo-Weibo数据集当中进行对比实验. 由于源语言为中文,故选用统一的中文预训练词向量[44 ] . 变换10次随机种子并对所得分数取均值来作为实验结果. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}