

截止2021年底,中国运营公路隧道为23268座,总长度为24698.9公里,运营铁路隧道为17532座,总长度为21055公里. 事实说明,中国已经成为了实至名归的超级隧道大国[1].
近年来,诸多学者将拥有强大数据挖掘能力的深度学习算法逐步用于实现结构病害的智能识别. 例如,Savino等[12]利用GoogLeNet网络对桥梁、隧道、路面的多种病害进行自动化精确分类. Dung[13]提出基于全卷积网络(fully convolutional network,FCN)的混凝土裂缝检测方法,在自建的病害数据集上取得了较好的检测结果. Mandal等[14]基于YOLOv2网络提出路面病害检测系统,在收集的路面裂缝图像中实现了自动化识别. Cheng等[15]利用Faster Region Convolutional Neural Network (Faster RCNN) 双阶段网络实现了隧道中裂缝和渗漏水病害的高精度识别. 周中等[16]利用DeepLabv3+网络完成了实际工程中的隧道渗漏水检测任务. 彭磊等[17]将Mask RCNN网络成功应用于隧道掌子面节理的智能检测与分割.
深度学习算法虽然学习能力强大,但其高度依赖数据集质量. 比如:在简单数据集上训练得到的模型对复杂背景的图像识别精度较低. 一些学者发现,将现有的深度学习算法直接应用于隧道病害识别任务并不完全适用,须对网络进行改进以适应隧道中的复杂环境干扰以及隧道病害的多尺度特点[18-19]. 为了提高复杂环境下隧道表观病害的识别精度与速度,许多学者将改进后的网络进行应用. 薛亚东等[20]基于既有的GoogLeNet网络,提出采用新的卷积核改进inception模块和网络结构,最终得到准确率超过95%的隧道衬砌病害分类模型. Liu等[21]利用提出的图像增强算法对病害图像进行增强,然后利用Faster RCNN网络进行病害检测,发现图像增强算法有效提高了网络的病害识别精度. Zhou等[22]对YOLOv4网络进行改进,提出新的隧道病害检测算法YOLOv4-ED,并在自建的多病害数据集上进行测试,取得了较好的检测结果. Li等[23]引入自适应空间特征融合模块改进YOLOv5,提高网络对隧道病害的识别能力,并利用网络剪枝和知识蒸馏来平衡网络的检测性能和检测效率,最后实现了隧道病害的高精度检测. 王宝坤等[24]利用残差单元和注意力机制提出新型的语义分割模型SU-ResNet++,对隧道多种表观病害完成了高精度分割. Xu等[25]在Mask RCNN网络中引入路径增强特征金字塔网络,提出新型的隧道病害检测方法,实现了对隧道渗漏水和衬砌脱落2种表观病害的精确识别.
由其他研究人员的成果可以发现,基于深度学习算法的隧道衬砌表观病害识别在实际应用中已经取得了一些进展,但其依旧存在一些不足,归纳如下. 1) 缺乏全局信息. 现有的多数隧道表观病害识别算法均基于卷积神经网络,只能提取病害图像的局部信息,缺乏全局信息提取能力,导致隧道病害识别算法容易漏检一些微小病害. 2) 抗干扰能力差. 因隧道环境可能受到光照条件、尺度变化、噪声和遮挡等因素的影响,深度学习算法存在鲁棒性和泛化能力的限制,对不同条件下的病害识别效果会有所下降. 3) 隧道病害图像数量的限制. 获取大规模的隧道衬砌表观病害图像数据需要大量隧道工程作支撑,是一项具有挑战性的任务,缺乏充足的病害图像数据会限制模型的训练效果和检测性能.
针对上述不足,采用MobileViT网络作为主干特征提取网络,并加入TP Block和CA注意力机制,提出TDD-YOLO识别算法,在构建的隧道病害数据集中进行训练,以实现对隧道衬砌表观病害的精准识别.
1. 隧道表观病害检测算法
1.1. YOLOv7算法
图 1
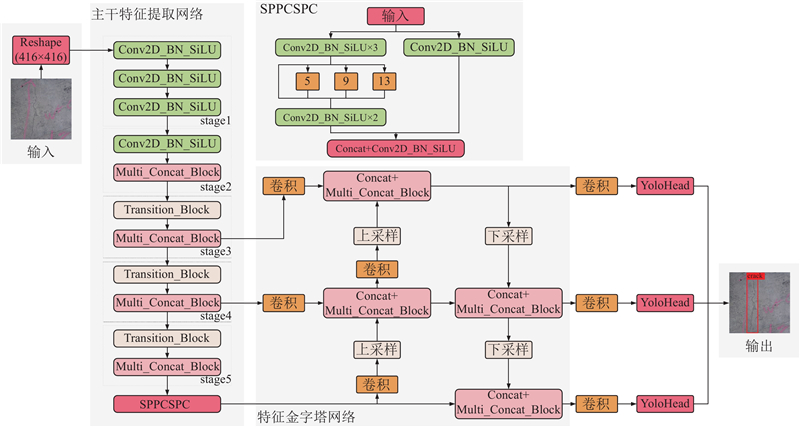
主干特征提取网络主要用于对输入的图像进行特征提取,相比于YOLOv4、YOLOv5网络,YOLOv7的主干网络连接结构更加密集,对图像的特征提取能力更强. 在图像输入至主干特征提取网络后,会经过多个卷积+标准化+激活函数(Conv2D_BN_SiLU)进行特征提取,与之前的YOLO系列网络不同,YOLOv7网络引入了多分支堆叠模块(Multi_Concat_Block)和过渡模块(Transition_Block),进一步提高了网络的识别准确度. 主干特征提取网络最终会输出3个大小分别为13×13、26×26、52×52的特征层.
特征金字塔网络会对得到的3个特征层进一步进行特征提取,并将不同shape的特征层进行特征融合,提取出更好的特征. 特征金字塔网络最终输出的3个特征层大小分别为13×13、26×26、52×52.
输出网络可对特征金字塔网络得到的3个特征层进行处理,进而预测目标的种类、置信度及位置. 该网络首先对每个特征层的3个先验框进行鉴别,判断是否包括目标及目标类型,然后调整先验框,并利用非极大抑制方法删除多余的矩形框,得到最终的预测结果.
输出网络在输出预测结果之前采用了RepConv结构(在图1中表示为卷积结构),该结构的思想取自于RepVGG网络. 在网络训练时会引入特殊的残差结构辅助训练,在进行结果预测时可将复杂的残差结构等效于一个普通的3×3卷积,既可以降低网络复杂度,又不会降低网络的预测性能.
图 2
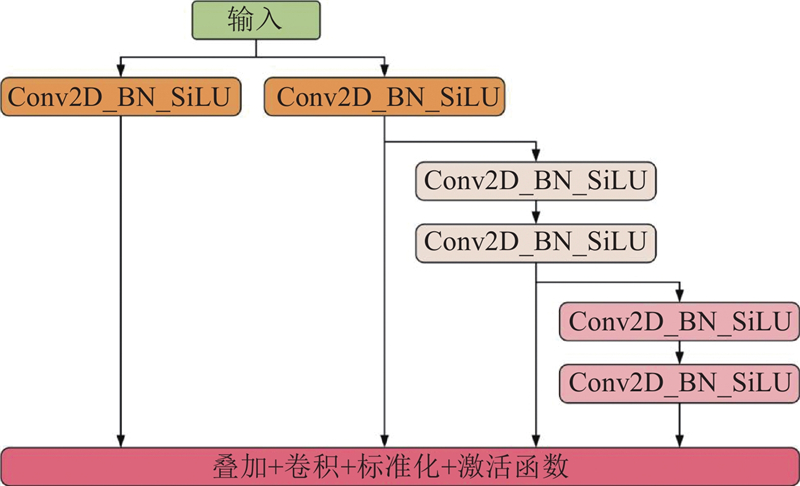
图 3
1.2. MobileViT算法
卷积神经网络(convolutional neural network,CNN)具有较强的局部感知能力,能够有效地捕捉输入数据的局部特征信息,并且在计算速度方面具有优势,但其缺点是无法提取全局特征信息[27]. Transformer系列网络能够通过自注意力机制同时获取输入序列中所有位置的信息,从而更好地捕捉全局上下文信息,但其计算资源需求较高,推理速度较慢,模型训练相对困难,这限制了transformer网络的应用. MobileViT网络[28]是2021年提出的网络,其采用CNN和transformer的混合架构,能够同时提取图像的全局特征信息和局部特征信息. 并且加入CNN后能够加速网络收敛,使网络训练过程更加稳定. MobileViT的网络结构如图4(a)所示,MobileViT Block结构如图4(b)所示,MV2结构是MobileNet网络中的Inverted Residual block结构,如图4(c)所示.
图 4
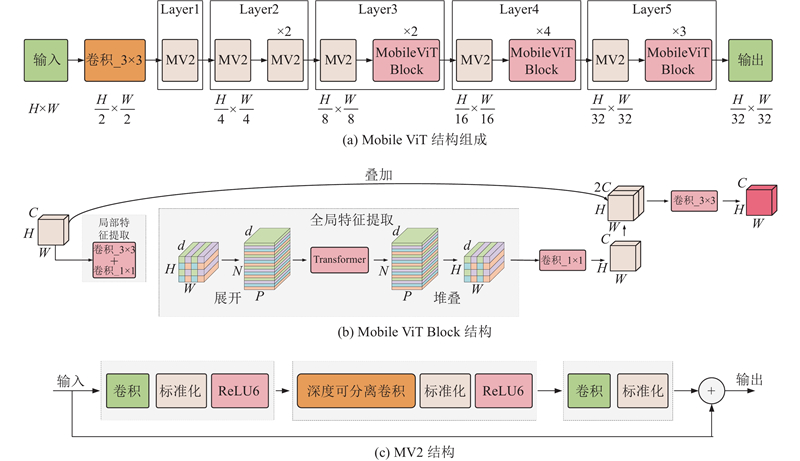
图像输入至MobileViT网络中后,会经过多个MobileViT Block结构和MV2结构进行特征提取,最后得到输出图像. 在MobileViT Block结构中,先通过一个3×3卷积和一个1×1卷积实现局部特征提取,再通过展开结构、Transformer以及堆叠结构完成全局特征提取,最后通过卷积调整通道数得到输出特征层. 其中,展开结构是将特征层划分为多个2×2大小的像素块,并将每个块中对应位置的像素关联起来,在后续的Transformer中进行自注意力操作,实现特征提取,最后在堆叠结构中还原为原来的特征层大小. 在MV2结构中,先通过常规卷积改变通道数,然后利用深度可分离卷积进行特征提取,最后利用常规卷积还原通道数.
1.3. CA注意力机制
现有的注意力机制(如CBAM、SE)采用的全局最大池化或者全局平均池化操作会损失空间信息,而Coordinate attention (CA)注意力机制[29]将位置信息嵌入到了通道注意力中,能够同时考虑通道信息和位置信息,可有效提高图像中待识别目标的权重. CA注意力机制的结构如图5所示. CA注意力模块分为2个并行阶段,输入的特征层会分别在高度方向上和宽度方向上进行全局平均池化,然后将2个并行阶段进行合并,将宽和高转置到同一个维度,然后进行堆叠,利用卷积、标准化、激活函数进行特征提取,然后再次分为2个并行阶段,利用1×1卷积调整通道数后采用Sigmoid函数获取高、宽2个方向的注意力情况,注意力情况以权重的方式表达,最后输入特征层与注意力权重相乘得到输出特征层.
图 5
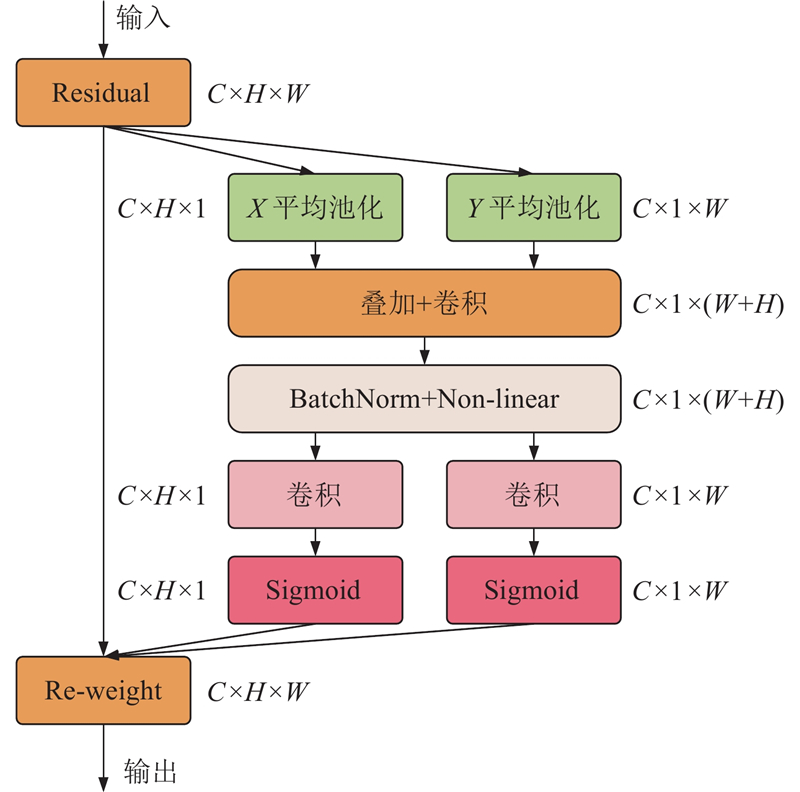
1.4. TP Block
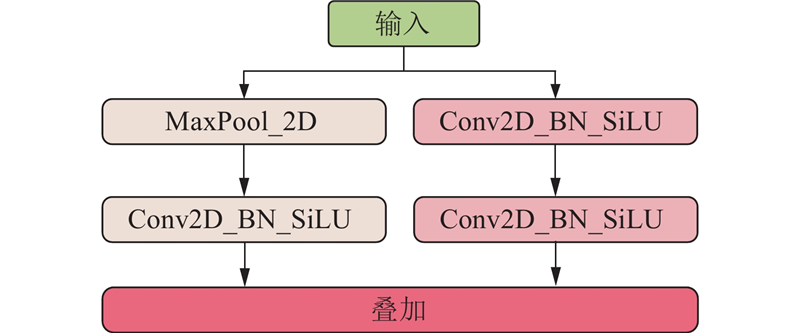
为了提高网络对病害图像特征的快速有效提取能力,基于部分卷积(partial convolution,PConv)[30]提出卷积块结构TP Block. 该结构由一个常规卷积块和一个部分卷积块组成,特征层输入之后,先经过常规卷积、标准化、激活函数进行特征提取,再经过部分卷积进行快速特征提取,最后得到输出特征层.
部分卷积只在一部分输入通道上用常规卷积进行空间特征提取,并保持其余通道不变,其计算量较小,可以快速有效地提取特征. 相较于其他算法中的常规卷积,该卷积块结构的特征提取能力更强,且特征提取的效率更高. 常规卷积和部分卷积的结构如图6所示.
图 6
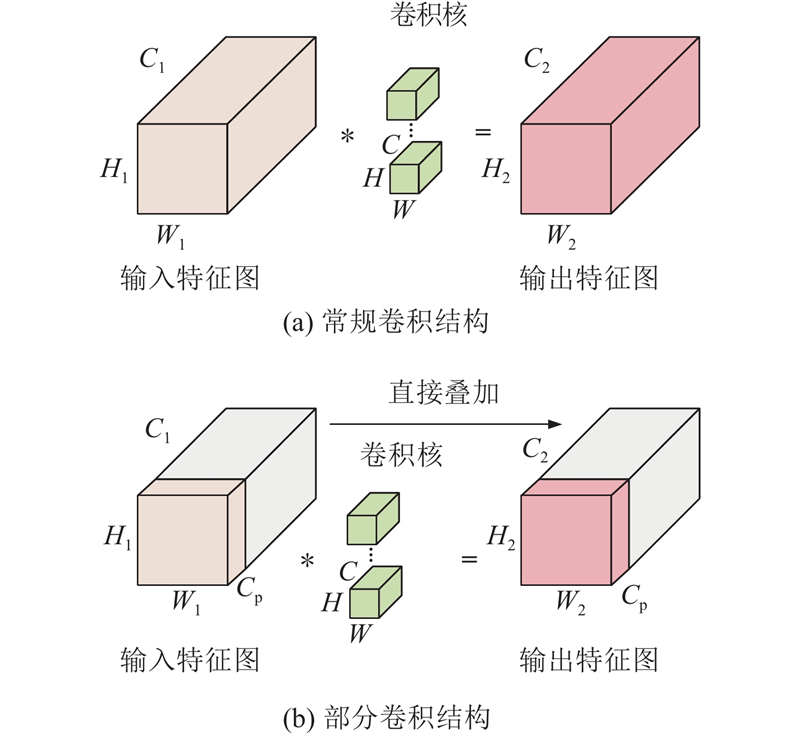
图 6 常规卷积与部分卷积结构
Fig.6 Conventional convolution and partial convolution structures
为了更清晰地说明部分卷积的优势,引入浮点运算次数(floating point operations,FLOPs)来评估两者的计算量. 假设输入特征图和输出特征图的高和宽分别为
部分卷积的浮点运算次数为
假设部分卷积的部分比率为1/4(即
1.5. TDD-YOLO算法
以YOLOv7网络为基础,采用可以提取图像全局特征信息和局部特征信息的MobileViT网络为主干特征提取网络,在特征金字塔网络的上采样和下采样操作后加入CA注意力模块,并引入新的TP Block模块,提出TDD-YOLO隧道病害检测算法. 算法结构如图7所示.
图 7
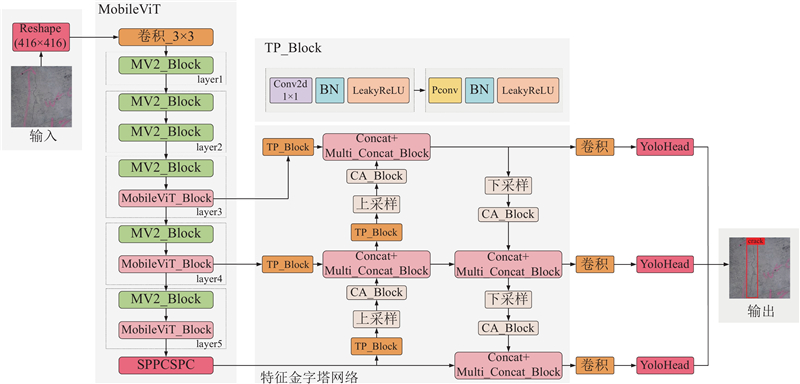
特征层S3会通过SPPCSPC模块进行特征提取,进一步扩大网络的感受野,得到特征层P3. 然后对S1、S2、P3进行特征提取和卷积降维得到特征层L1、L2、L3. 之后经过一系列卷积、上下采样、标准化、激活函数进行特征提取和特征融合,得到最后3个特征层F1、F2、F3,最后经过RepConv模块和YOLO Head模块进行解码,得到输入图像的隧道病害检测结果.
为了提高对隧道病害图像中不同大小的病害目标的检测能力,不同大小的特征层会采用不同大小的先验框,特征层尺寸越大,先验框尺寸也会相应增大,能够检测的病害目标也就越大. 3种不同大小的特征层所采用的先验框示意图如图8所示.
图 8

2. 隧道表观病害数据集
2.1. 数据集组成
图 9

图 10

根据6∶2∶2的比例,将数据集划分为训练集、验证集和测试集,每类病害图像的数量如表1所示. 表中,Ntot为数据集图像总数,Ntra、Nval、Ntex分别为训练集、验证集、测试集图像数量.
表 1 隧道病害数据集参数
Tab.1
| 病害类别 | Ntot | Ntra | Nval | Ntex |
| 裂缝 | 1102 | 742 | 180 | 180 |
| 渗漏水 | 1004 | 688 | 158 | 158 |
| 衬砌脱落 | 698 | 470 | 114 | 114 |
2.2. 数据集标注
采用LabelImg标注软件对隧道病害图像进行标注,并转换为VOC格式,以便于后续的网络训练和评估. 标注内容主要包括标注框坐标和分类信息. 标注框坐标表示了病害在图像中的位置和大小,分类信息指明了病害的类别. 如图11所示展示了部分标注图像. 图中,C表示裂缝,W表示渗漏水,L表示衬砌脱落.
图 11

3. 隧道表观病害检测实验
3.1. 实验环境
实验均通过Python3.8计算机语言和Pytorch1.10.0模块进行. 所采用系统为Windows10,GPU设备为NVIDIA GeForce RTX 3060.
3.2. 评估指标
为了评估模型对隧道多病害的检测性能,选用平均精度(average precision, AP)、平均精度均值(mean average precision, mAP)、准确率与召回率的的调和平均值(F1 score)、每秒传输帧数(v)、模型大小(MS)作为评估指标. 计算公式如下:
式中:TP为正样本被检测正确的数量,FP为负样本被检测为正样本的数量,FN为正样本未被检测为正样本的数量,正样本是标注的病害目标,负样本是无关背景;P为准确率;R为召回率;n为病害类别的数量;N为检测图片的数量;T为检测所有图片所用的总时间.
3.3. 模型训练参数
选用YOLOv7、YOLOv5、EfficientDet、Faster RCNN、SSD这5种典型的目标检测网络作为对比网络,并对所有网络在同一数据集上进行训练. 为了评估本研究构建的网络和其他4种对比网络的训练效果,每个网络的训练次数均设置为200次,以确保网络在训练过程中能够达到收敛状态. 此外,会实时记录训练误差和验证误差,防止网络出现过拟合的情况.
为了加快网络的收敛速度并节约计算资源,基于迁移学习[33]思想加载在COCO数据集上训练得到的主干网络预训练权重. 网络训练的前50次采用冻结训练,此时冻结主干网络的权重,仅对网络的其他部分进行训练和更新;后150次训练采用解冻训练,此时主干网络解冻,网络的所有权重都会进行训练和更新. 为了提高网络性能,避免网络训练震荡问题,各网络的训练批量大小均尽可能调大. 网络训练学习率采用余弦退火学习率进行衰减,首先确定学习率的最大值和最小值,然后在训练过程中按照余弦函数进行调整,避免网络陷入局部最优解. 此外,网络在训练过程中会随机采用mosaic数据增强和mixup数据增强,提高网络对复杂多变环境的适应性. 当训练完成后,在网络不发生过拟合的情况下,保留验证误差最小的权重作为最优模型权重,用于后续的实验分析. 网络训练的超参数如表2所示. 表中,L为学习率,B为批量大小,M为动量,Ls为标签平滑. 阶段1为冻结训练阶段,阶段2为解冻训练阶段.
表 2 网络训练超参数
Tab.2
| 网络 | L | B | M | Ls | |||
| 最大值 | 最小值 | 阶段1 | 阶段2 | ||||
| SSD | 6×10−4 | 6×10−6 | 16 | 8 | 0.93 | 0 | |
| Faster RCNN | 1×10−4 | 1×10−6 | 16 | 8 | 0.90 | 0 | |
| EfficientDet | 3×10−4 | 3×10−6 | 32 | 16 | 0.90 | 0 | |
| YOLOv5 | 1×10−3 | 1×10−5 | 16 | 8 | 0.94 | 0.005 | |
| YOLOv7 | 1×10−3 | 1×10−5 | 16 | 8 | 0.94 | 0.005 | |
| TDD-YOLO | 1×10−3 | 1×10−5 | 16 | 8 | 0.94 | 0.005 | |
3.4. 主干网络对比实验
为了探索不同类型的分类网络作为主干特征提取网络时的模型性能,选用目前较为流行的几个分类网络进行实验,网络类型包括卷积神经网络和Transformer系列网络. 实验所采用的超参数均一致,最后对训练模型进行测试,并选择每个模型最好的测试结果,实验结果如表3所示.
表 3 主干网络评价指标表
Tab.3
| 主干网络 | 裂缝 | 渗漏水 | 衬砌脱落 | F1/% | mAP/% | |||||
| f1/% | AP/% | f1/% | AP/% | f1/% | AP/% | |||||
| MobileNet | 74.43 | 75.54 | 74.85 | 75.74 | 65.66 | 62.33 | 71.65 | 71.20 | ||
| GhostNet | 73.64 | 73.60 | 74.12 | 75.31 | 65.32 | 60.87 | 71.03 | 69.93 | ||
| ResNet | 74.56 | 77.52 | 74.48 | 75.76 | 66.84 | 65.30 | 71.96 | 72.86 | ||
| Swin transformer | 74.48 | 76.97 | 75.03 | 78.61 | 66.91 | 64.49 | 72.14 | 73.36 | ||
| MobileViT | 75.83 | 79.58 | 76.32 | 79.62 | 68.32 | 65.24 | 73.49 | 74.81 | ||
分别采用5种分类网络作为YOLOv7的主干特征提取网络,发现MobileViT作为主干网络的裂缝和渗漏水识别准确度最高,MobileViT和ResNet作为主干网络的衬砌脱落病害识别准确度最高,但是在整体性能方面,MobileViT网络优于ResNet网络. 与MobileNet、GhostNet、ResNet、Swin Transformer这4种网络相比,MobileViT在F1上分别提高了1.84%、2.46%、1.53%、1.35%,在mAP上分别提高了3.61%、4.88%、1.95%、1.45%. 经过全面分析,MobileViT网络的性能表现最优,因此,最终选用MobileViT作为YOLOv7的主干特征提取网络.
3.5. 消融实验
为了测试所采用的MobileViT主干网络、CA注意力机制、TP Block的有效性,在构建的隧道多病害数据集上进行消融实验. 消融实验结果如表4所示. 为了更清晰地比较不同改进策略的影响,该实验评价指标采用F1、mAP、v以及MS.
表 4 网络消融实验结果表
Tab.4
| 网络 | MobileViT | CA | TP Block | F1/% | mAP/% | v/(帧·s−1) | MS/106 |
| YOLOv7 | × | × | × | 71.29 | 71.13 | 50.81 | 142.3 |
| YOLOv7+MobileViT | √ | × | × | 73.49 | 74.81 | 51.39 | 113.9 |
| YOLOv7+CA | × | √ | × | 71.55 | 71.71 | 51.43 | 142.6 |
| YOLOv7+TP Block | × | × | √ | 72.42 | 72.53 | 51.26 | 142.6 |
| YOLOv7+MobileViT+CA | √ | √ | × | 74.61 | 75.72 | 52.50 | 114.2 |
| YOLOv7+MobileViT+ TP Block | √ | × | √ | 75.16 | 75.91 | 52.79 | 114.2 |
| YOLOv7+CA+ TP Block | × | √ | √ | 74.05 | 73.60 | 52.44 | 142.9 |
| YOLOv7+MobileViT+CA+ TP Block | √ | √ | √ | 77.43 | 77.52 | 53.86 | 114.5 |
3.5.1. 单个改进的影响
为了验证3个改进策略的有效性,将其逐一应用在YOLOv7网络中进行测试. 对比可得,当采用MobileViT作为YOLOv7的主干网络时,模型的F1和mAP分别提高了2.20%和3.68%,说明MobileViT网络能够有效提取隧道病害目标的全局特征和局部特征. 当在特征金字塔网络的上采样和下采样后面加入CA注意力后,模型的F1和mAP分别提高了0.26%和0.58%,说明CA注意力模块能够有效增大隧道病害目标区域的权重,提高网络的识别精度. 在将特征金字塔网络中的卷积模块替换为本研究提出的TP Block时,模型的F1和mAP分别提高了1.13%和1.40%,说明TP Block改进策略可以在几乎不增大模型参数的情况下,有效提高模型对隧道3种表观病害的特征提取能力. 此外,单独采用3种改进策略时,每秒传输帧数均有所提高,说明3种改进策略均可以提高网络对病害图像的检测速度. 综上,单独采用3种改进策略均可以在一定程度上提高网络的特征提取能力、识别精度与速度.
3.5.2. 联合改进的影响
测试3种改进策略对模型性能的联合影响,测试结果如表4中最后3行所示. 当采用MobileViT网络和CA注意力模块时,模型的F1和mAP分别提高了3.32%和4.59%. 当采用MobileViT网络和TP Block模块时,模型的F1和mAP分别提高了3.87%和4.78%. 当采用CA注意力模块和TP Block模块时,模型的F1和mAP分别提高了2.76%和2.47%. 当同时采用3种改进策略时,模型的F1和mAP分别提高了6.14%和6.39%. 此外,在采用每一种联合改进后,网络的每秒传输帧数均有所提高,说明本研究的改进策略可以有效提高病害图像的检测速度. 由实验结果可看出,联合改进实验进一步证明了所采用的3种改进策略的有效性.
3.6. 模型对比实验
为了对所提出的TDD-YOLO网络的综合性能进行分析,对SSD、Faster RCNN、EfficientDet、YOLOv5、YOLOv7这5种网络进行训练,并在本研究构造的测试集上进行性能测试,对比实验结果如表5所示. 可以看出,TDD-YOLO模型对裂缝、渗漏水及衬砌脱落3种表观病害的识别精度最高,各项评价指标相比于其他5种模型均有不同程度的提高. 此外,TDD-YOLO模型的F1为77.43%,相较于SSD、Faster RCNN、EfficientDet、YOLOv5、YOLOv7这5种模型分别提高了15.58%、17.36%、12.19%、6.32%、6.14%;mAP为77.52%,相较于SSD、Faster RCNN、EfficientDet、YOLOv5、YOLOv7这5种模型分别提高了15.20%、14.24%、9.44%、7.44%、6.39%. 可见,所采用的3种改进策略可以有效提高网络对病害目标的特征提取能力,增强网络的病害检测性能.
表 5 6种模型的实验精度结果对比表
Tab.5
| 网络 | 裂缝 | 渗漏水 | 衬砌脱落 | F1/% | mAP/% | |||||
| f1/% | AP/% | f1/% | AP/% | f1/% | AP/% | |||||
| SSD | 69.43 | 69.97 | 71.80 | 74.00 | 44.31 | 42.98 | 61.85 | 62.32 | ||
| Faster RCNN | 64.92 | 71.54 | 70.57 | 72.21 | 44.72 | 46.08 | 60.07 | 63.28 | ||
| EfficientDet | 64.42 | 70.78 | 74.93 | 76.02 | 56.37 | 57.43 | 65.24 | 68.08 | ||
| YOLOv5 | 74.72 | 73.83 | 73.49 | 72.40 | 65.12 | 64.02 | 71.11 | 70.08 | ||
| YOLOv7 | 74.97 | 76.53 | 73.55 | 74.71 | 65.35 | 62.15 | 71.29 | 71.13 | ||
| TDD-YOLO | 80.47 | 82.28 | 79.59 | 80.58 | 71.74 | 69.71 | 77.43 | 77.52 | ||
图 12

图 12 简单明亮环境下的隧道病害图像检测结果
Fig.12 Tunnel defect image detection results in simple and bright environment
图 13

图 13 复杂昏暗环境下的隧道病害图像检测结果
Fig.13 Tunnel defect image detection results in complex and somber environment
分析图12可知,在简单明亮环境条件下,6种模型对单个病害图像的定位较准确,只有极少数会出现错检、漏检情况,而对于混合病害图像的检测,5种对比模型均出现了漏检情况. 在单病害的混合病害图像检测结果中,TDD-YOLO模型的检测置信度最高,且对病害目标的区域定位准确度最高,说明该模型在简单环境下能够区分不同的隧道表观病害,实现病害图像的高精度检测.
综上所述,在简单明亮环境和复杂昏暗环境下,本研究所提出的TDD-YOLO模型均可以区分不同类型的隧道表观病害,实现高精度检测,具有较强的鲁棒性,适用于复杂环境条件下的隧道多种衬砌表观病害检测任务.
4. 结 论
(1) 主干网络实验证明,MobileViT分类网络融合了卷积网络和transformer网络的优势,所有评价指标均优于MobileNet、GhostNet、ResNet、Swin transformer这4种网络,可用于作为主干特征提取网络.
(2) 消融实验证明,所采用的MobileViT网络、CA注意力模块、TP Block模块均有效提高了模型的F1和mAP,可以在一定程度上提高模型的病害检测性能.
(3) TDD-YOLO模型的F1分数和mAP分别为77.43%、77.52%,所有评价指标相较于SSD、Faster RCNN、EfficientDet、YOLOv5、YOLOv7这5种模型均有不同程度的提升.
(4) 对比其他检测模型,TDD-YOLO模型能够抵抗隧道复杂环境干扰,在光线较暗且有干扰的条件下依旧可以实现隧道多种表观病害的高精度检测,具有较强的鲁棒性,适用于复杂环境隧道多病害检测任务.
(5) 所采用的数据集图像数量较少,后续可进一步进行图像扩充. 后续会开发隧道病害检测平台,可与TDD-YOLO结合使用.
参考文献
中国交通隧道工程学术研究综述: 2022
[J].DOI:10.3969/j.issn.1001-7372.2022.04.001 [本文引用: 1]
Review on china's traffic tunnel engineering research: 2022
[J].DOI:10.3969/j.issn.1001-7372.2022.04.001 [本文引用: 1]
北京地铁运营隧道病害状态分析
[J].
Analysis on defects of operational metro tunnels in Beijing
[J].
Deep learning based image recognition for crack and leakage defects of metro shield tunnel
[J].DOI:10.1016/j.tust.2018.04.002 [本文引用: 1]
隧道表面图像多目标智能识别算法研究
[J].DOI:10.3969/j.issn.1001-8360.2022.09.020 [本文引用: 1]
Research on algorithm of intelligent recognition of mutiple objects of tunnel surface image
[J].DOI:10.3969/j.issn.1001-8360.2022.09.020 [本文引用: 1]
运营期盾构隧道结构病害的自动化检测与三维可视化
[J].
Automatic detection and 3D visualization of structural diseases of shield tunnel during operation
[J].
A multi-defect detection system for sewer pipelines based on StyleGAN-SDM and fusion CNN
[J].DOI:10.1016/j.conbuildmat.2021.125385 [本文引用: 1]
Faster and better: a machine learning approach to corner detection
[J].
A deep-learning-based multiple defect detection method for tunnel lining damages
[J].DOI:10.1109/ACCESS.2019.2931074
岩石岩性Mask R-CNN智能识别方法与应用研究
[J].
Investigation and application on lithology intelligent recognition method based on Mask R-CNN
[J].
Deep learning-based automatic recognition of water leakage area in shield tunnel lining
[J].DOI:10.1016/j.tust.2020.103524 [本文引用: 1]
Image-based concrete crack detection in tunnels using deep fully convolutional networks
[J].DOI:10.1016/j.conbuildmat.2019.117367 [本文引用: 1]
Automated classification of civil structure defects based on convolutional neural network
[J].DOI:10.1007/s11709-021-0725-9 [本文引用: 1]
Autonomous concrete crack detection using deep fully convolutional neural network
[J].DOI:10.1016/j.autcon.2018.11.028 [本文引用: 1]
Automated detection of sewer pipe defects in closed-circuit television images using deep learning techniques
[J].DOI:10.1016/j.autcon.2018.08.006 [本文引用: 1]
基于深度语义分割的隧道渗漏水智能识别
[J].
Automatic identification of tunnel leakage based on deep semantic segmentation
[J].
基于深度学习的隧道掌子面节理智能检测与分割
[J].
Research on intelligent detection and segmentation of rock joints tunnel face based on deep learning
[J].
运营隧道衬砌病害诊治的现状与发展
[J].DOI:10.3969/j.issn.1001-7372.2021.11.015 [本文引用: 1]
Present Status and development trend of diagnosis and treatment of tunnel lining diseases
[J].DOI:10.3969/j.issn.1001-7372.2021.11.015 [本文引用: 1]
地铁隧道结构表观病害快速检测方法与应用
[J].
Rapid detection method for surface defect for metro tunnel structure and its Application
[J].
基于深度学习的盾构隧道衬砌病害识别方法
[J].
A method of disease recognition for shield tunnel lining based on deep learning
[J].
An image enhancement algorithm to improve road tunnel crack transfer detection
[J].DOI:10.1016/j.conbuildmat.2022.128583 [本文引用: 1]
Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network
[J].DOI:10.1111/mice.12836 [本文引用: 1]
A robust real-time method for identifying hydraulic tunnel structural defects using deep learning and computer vision
[J].
Automatic defect detection and segmentation of tunnel surface using modified Mask R-CNN
[J].DOI:10.1016/j.measurement.2021.109316 [本文引用: 1]
Defect object detection algorithm for electroluminescence image defects of photovoltaic modules based on deep learning
[J].DOI:10.1002/ese3.1056 [本文引用: 1]
An improved YOLOX approach for low-light and small object detection: PPE on tunnel construction sites
[J].DOI:10.1093/jcde/qwad042 [本文引用: 1]
耦合岩石图像与锤击音频的岩性分类智能识别分析方法
[J].
Intelligent recognition and analysis method of rock lithology classification based on coupled rock images and hammering audios
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}