

随着短视频平台的用户量、视频量持续增长,信息过载问题也日益凸显. 从用户侧来说,可获取的海量信息已经远远超过了其接收处理能力,难以找到有效信息或者感兴趣内容;从平台方来说,从海量短视频中找到用户感兴趣的内容,是改善用户体验、增加用户黏性,从而避免用户流失、提升商业收益的关键. 解决此类问题的关键正在于个性化的短视频推荐引擎.
现有的面向推荐系统的深度学习算法一般以多层感知机为核心预测部件. 部分工作增加网络层数和引入复杂模型架构,如从仅具有单层神经网络的自编码器推荐(autoencoders recommendation,AutoRec)[4]发展到包含嵌入层、融合层、多残差单元层和评分层的深度交叉模型[5]. 部分工作丰富了深度神经网络中特征交叉的方式,如使用多层神经网络和输出层替代矩阵分解模型中的内积操作的神经协同过滤(neural collaborative filtering,NeuralCF)模型[6],通过让用户向量和物品向量进行更充分交叉的方式来获取有更多价值的特征组合信息;再如基于积操作的神经网络(product-based neural networks,PNN)[7]使用能够针对性获取特征之间交叉信息的乘积层来替换深度交叉模型的融合层. 部分工作将深度神经网络与注意力机制融合,如深度兴趣网络(deep interest network,DIN)[8]利用用户历史行为中的物品和候选物品的相关性计算注意力权重来提升模型的推荐性能. 部分工作使用序列推荐模型对用户行为或者用户兴趣进行建模,如在DIN的基础上引入用户行为序列层、用户兴趣抽取层和用户兴趣演化层的深度兴趣演化网络(deep interest evolution network,DIEN)[9],其具备表达时序信息的序列推荐模型,因此非常契合预测用户经过一系列行为后的下一次动作的任务需求. 部分工作基于更能挖掘数据之间关系的图神经网络[10]展开,将用户-物品的交互数据表示为图,通过对相邻节点之间消息的传播聚合进行迭代来表征图结构信息.
本研究提出用于点击率预估任务的多模态增强模型(multi-modal augmented model for click through rate, MMa4CTR),其充分挖掘短视频的视觉、声音和文本这3种模态信息与用户兴趣之间的关系,聚焦于短视频推荐的排序阶段,设计并实现基于多层感知机的点击率预估模型,预测用户对未交互过短视频的点击概率,并依据此概率进行排序、生成该用户个性化的推荐列表. 完整项目代码和原始实验数据开源网站如下:
1) MMa4CTR以用户和短视频的交互行为构建二分图,以点击行为给二分图中的边赋予权重,从而得到用于构建一套生成用户表示嵌入向量的二分加权图. 二分图中加权边的引入,有利于更好地挖掘用户点击与否的显式反馈下隐藏的兴趣,更加贴近点击率预估任务的真实业务场景. 2) MMa4CTR以用户的邻居节点模态信息和用户自身的辅助信息共同生成用户的嵌入向量,能够充分挖掘短视频的多模态信息、用户的辅助信息与用户兴趣之间的联系. 3) 短视频的多模态信息往往是高维向量,数据量膨胀会导致深度学习模型训练困难. MMa4CTR使用计算开销更小的多层感知机来预估点击率,尽可能地在保证模型推荐性能的前提下提升其训练和推理速度.
1. 相关工作
1.1. 点击率预估任务
1.2. 多模态学习
模态是事物的客观呈现形式,当所研究的对象包含多种可提取、可分析的模态时,这个对象可以被描述为多模态的(multi-modal). 从人脸识别、语音识别发展到复杂的交互式生成大模型GPT-4[14],多模态机器学习一直是热点领域.
在较为早期的工作中,视觉贝叶斯个性化排序(visual Bayesian personalized ranking,VBPR)[11]将视觉模态融入推荐系统中,利用矩阵分解来预测用户偏好,使用贝叶斯个性化排序[15]来训练模型的分析和推理,能较好地缓解冷启动问题;加入注意力的协同过滤(attentive collaborative filtering,ACF)[12]利用ResNet-152从图像和视频帧中提取模态信息用于模型训练. 但是,这2项工作都缺乏用户对不同模态偏好的建模,而多模态图卷积网络(multi-modal graph convolution network,MMGCN)[16]则改进了这一点. MMGCN在视觉、声音和文本模态下各自构建一个用户-短视频二分图,并利用邻居节点的拓扑结构来丰富每个节点表示,其能够学习到用户-短视频二分图中更高阶的连通性,其推荐性能较同时期协同过滤模型有了明显提升.
在近期的工作中,多模态主题学习(multi-modal topic learning,MTL)[17]改进了缺乏语义主题信息的特征制约推荐系统性能的问题,显式地将主题生成、推荐任务分开,利用标签、标题和封面图像这3种模态信息离线生成主题,并且根据主题来划分用户兴趣、进行推荐,该系统已经部署在腾讯快报信息流平台上. 多头多模态深度兴趣网络(multi-head multi-modal deep interest network,MMDIN)[18]在DIN模型的基础上增加了多头和多模态模块,既丰富了特征集合又增强了模型的交叉组合与拟合能力,该模型包括3个重要模块:多模态模块提取了视频封面的图像特征,扩充了模型可以学习的特征集合,从而使得模型具有更强的表达能力;注意力模块依据用户对已经交互过的视频的评分进行加权;多头残差网络模块对特征向量进行压缩后进行评分预测. MMDIN取得了优于其同时期的推荐算法的性能.
多模态自监督学习(multi-modal self-supervised learning,MMSSL)[19]认为现有的多模态推荐方法具有严重依赖大量标签信息的局限性,受到用于数据增强的自监督学习方法的启发,MMSSL利用双阶段自监督学习范式从稀疏标注的多模态数据中生成监督信号. 具体来说,MMSSL的模态感知协同关系学习能够在细粒度水平上探索用户和短视频之间的隐含关系;交叉模态依赖建模则用于探索用户的多样化兴趣. 在亚马逊和抖音数据集上,MMSSL取得了同时期多模态推荐工作中最优的性能.
1.3. 图神经网络
图神经网络凭借其捕捉用户-短视频之间高阶相关性结构的能力成为了多模态推荐的主流基础方案. 多模态知识图注意力网络(multi-modal knowledge graph attention,MMGAT)[20]是第1项将多模态知识图纳入推荐系统的工作,其模型从2个方面对多模态知识图进行建模:实体信息聚合通过聚合每个实体的邻居节点来丰富实体本身的表示;实体关系推理通过三元组评分函数来构建推理关系. MMGAT模型的另一个优势在于不需要知识图中的每个实体都有多模态信息,降低了对数据集质量的要求. 用于点击率预估的多模态超图(hypergraph click-through rate,HyperCTR)[21]改进了此前点击率预估任务中主要利用单模态内容来学习物品表示的不足,基于可以连接2个及以上节点的超边来对图模型进行增强,从而缓解每个模态下用户和短视频之间交互稀疏的问题. 精细化图卷积网络(graph-refined convolutional network,GRCN)[22]认为之前的基于用户-短视频交互图的推荐工作未能把假正样本(如用户无意中点开的视频、用户的好友转发过来的视频)的噪声剔除出去,因此设计了可以根据训练状态调整交互图结构的自适应精细化模型,其模型包括图精细化层、图卷积层和预测层,其实验结果比未剔除假正样本噪声的MMGCN模型更优.
相比于现有工作,所提出的MMa4CTR模型通过用户交互过的短视频多模态信息和用户自身的辅助信息来生成用户的嵌入表示,充分学习用户对不同模态内容的兴趣;通过对多模态特征进行交叉或者组合的方式,充分挖掘不同模态信息之间共同的潜在语义信息;计算点击率预估值的方式采用具有计算开销更小、网络架构更简易的多层感知机,能缓解多模态的高维向量带来的数据膨胀导致深度学习模型训练困难的问题,增加模型整体的可扩展度.
2. MMa4CTR模型
2.1. 定义
定义1 用户-短视频交互二分加权图. 用户和短视频之间的交互可以建模成二分图
定义2 用户的辅助信息描述. 从数据集中提取用户
定义3 短视频的多模态描述. 对于每条短视频
2.2. MMa4CTR模型整体架构
MMa4CTR模型的目标是从已有的用户-短视频交互记录中,通过分析用户辅助信息和短视频多模态信息来挖掘用户对多模态特征的兴趣,从而预测用户对一个没有交互过的短视频的点击率. 根据用户对推荐候选池中各个短视频的点击概率预估值进行排序,生成针对该用户的个性化的推荐列表.
MMa4CTR首先从用户浏览和点击记录表中构建二分加权图. 图中,用户节点的邻居为与其交互过的短视频节点,依据点击行为对图中的每条交互边进行加权,有点击则权重为1、无点击则权重为0,无交互则不存在边. 从短视频多模态数据集中提取每条视频的3种模态下的属性值,经由特征工程处理成向量长度对齐、向量数值归一化的特征矩阵. 每个用户的邻居节点的模态特征,用以生成该用户的多模态信息的嵌入;每条交互边的权重,用以生成用户多模态嵌入卷积降维操作中的卷积核. 接着,MMa4CTR将每个用户的多模态嵌入向量和其辅助信息向量进行拼接,得到各个用户的低维嵌入向量. 节点的特征经过拼接、交叉、降维处理后,MMa4CTR组合每个用户的嵌入向量和其邻居节点的特征向量以及两者间的点击关系,生成用于神经网络训练的全特征矩阵和点击标签. 模型的核心神经网络是全连接的多层感知机,其输出值经过预测层,计算出用户点击未交互过的短视频的概率,该概率即为点击率预估值.
2.3. 用户嵌入层
生成用户嵌入(embedding)向量,需要依次经过卷积操作、池化操作和拼接操作.
用户
在矩阵
2.4. 多模态信息的特征交叉与特征组合
短视频的视觉、声音和文本信息之间是高度相关的,因此MMa4CTR模型通过对每条短视频的3种模态信息进行特征交叉、特征组合的方式,来探索模态之间的相关性和其共同的潜藏语义.
将特征组合即3个模态向量分别进行两两拼接或者3项拼接;特征交叉即对3个向量分别进行两两哈达玛积运算或者3项依次进行哈达玛积运算. 计算出来的特征向量通常是高维的,MMa4CTR模型使用主成分分析算法进行降维处理. 主成分分析算法的时间复杂度为
2.5. 用于点击率预估的多层感知机
多层感知机的输入矩阵的行向量对应到二分加权图
多层感知机由3~4个全连接层构成,其具体的层数和每个全连接层上的神经元个数根据输入特征矩阵的维度自适应调整. 利用模型输出值
式中:
在反向传播的随机梯度下降步骤中,MMa4CTR模型选择了综合考虑梯度的一阶矩估计(等价于梯度均值)和二阶矩估计(等价于梯度方差)的Adam优化器来计算更新步长. 此外,MMa4CTR模型还设置了2套机制来更好地进行迭代优化:自动半衰机制和验证中断机制. 自动半衰机制是指学习率每经过5轮训练就衰减为原来的一半,这是因为在模型训练初期使用较大的学习率可以避免落入局部最优解且加快模型收敛速度,在模型训练中后期使用较小的学习率则可以更加逼近较优解的邻近区间,不会产生较大幅度的性能波动. 在验证中断机制中,如果在验证集上计算出的曲线下面积(area under the curve, AUC)过低(小于等于
图 1
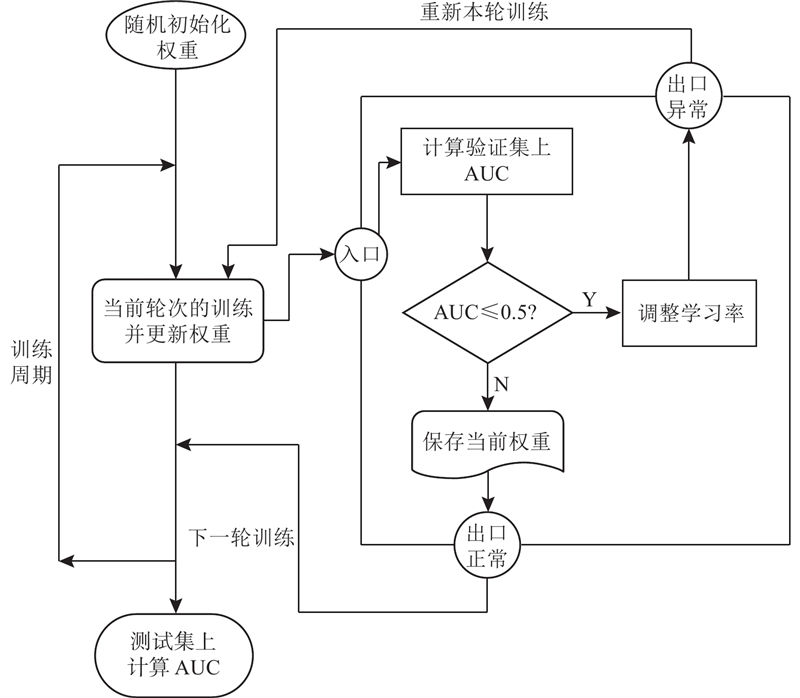
多层感知机输出层连接到预测层,预测层的输出值即为MMa4CTR模型的最终输出结果,代表发生点击的概率预估值. 预测层使用的是
分析多层感知机的时间、空间复杂度. 每个训练批次中有
3. 实验评估
3.1. 数据集
使用
3.2. 性能对比实验
3.2.1. 推荐性能对比实验
选用受试者特征曲线(receiver operating characteristic, ROC)的曲线下面积(AUC)作为评价各个模型推荐性能的指标.
微信和抖音数据集上的实验结果分别如表1、2所示. 表中,最优异的性能结果用粗体标识,次优的性能结果用下划线标识,AUC@后数字表示训练轮次,I表示MMa4CTR相较于最优基线的性能的升高幅度. 可以看出,在微信数据集上
表 1 微信数据集上的推荐性能对比
Tab.1
| 模型 | AUC@10 | AUC@20 | AUC@30 | AUC@50 |
| BPR | 0.5113 | 0.5981 | 0.6386 | 0.6716 |
| FPMC | 0.5204 | 0.6338 | 0.6761 | 0.7038 |
| NCGF | 0.6112 | 0.6159 | 0.6310 | 0.6612 |
| LightGCN | 0.5068 | 0.5663 | 0.6110 | 0.6744 |
| BERT4Rec | 0.7478 | 0.7566 | 0.7716 | 0.7714 |
| GCSAN | 0.7445 | 0.7508 | 0.7534 | 0.7834 |
| DIN | 0.832 4 | 0.843 6 | 0.849 8 | 0.849 4 |
| DIEN | 0.7972 | 0.7987 | 0.8028 | 0.8027 |
| MMa4CTR | 0.9527 | 0.9421 | 0.9406 | 0.9468 |
| I/% | 14.45 | 11.68 | 10.68 | 11.47 |
表 2 抖音数据集上的推荐性能对比
Tab.2
| 模型 | AUC@10 | AUC@20 | AUC@30 | AUC@50 |
| BPR | ||||
| FPMC | ||||
| NCGF | ||||
| LightGCN | ||||
| BERT4Rec | 0.584 4 | 0.583 4 | 0.629 5 | 0.535 9 |
| GCSAN | 0.586 9 | 0.482 9 | 0.455 0 | 0.473 6 |
| DIN | ||||
| DIEN | 0.578 8 | 0.578 7 | 0.578 7 | 0.578 7 |
| MMa4CTR | ||||
| I/% |
3.2.2. 计算性能对比实验
在计算性能对比实验中,超参数设置与推荐性能对比实验中的相同. 本实验比较各个模型的训练时间、推理时间和模型可训练的参数数目. 其在微信数据集和抖音数据集上的实验结果分别如表3、4所示. 表中,
表 3 微信数据集上的计算性能对比
Tab.3
| 模型 | Tt/s | Ti/s | N |
| BPR | 54.77 | 45 | 7 460 224 |
| FPMC | 62.43 | 48 | 19 820 544 |
| NCGF | 126.54 | 109 | 7 485 184 |
| LightGCN | 91.54 | 79 | 7 460 224 |
| BERT4Rec | 471.41 | 317 | 6 915 904 |
| GCSAN | 4756.09 | 4385 | 6 908 032 |
| DIN | 170.44 | 108 | 1 449 310 |
| DIEN | 643.73 | 243 | 1 587 847 |
| MMa4CTR | 180.78 | 17 | 29 225 |
表 4 抖音数据集上的计算性能对比实验
Tab.4
| 模型 | |||
| BPR | 619.19 | 601 | 195 060 416 |
| FPMC | 549.91 | 399 | 584 966 336 |
| NCGF | 1332.28 | 799 | 195 085 376 |
| LightGCN | 1929.59 | 1908 | 195 060 416 |
| BERT4Rec | 71639.71 | 5060 | 195 056 384 |
| GCSAN | 44006.24 | 37142 | 195 048 512 |
| DIN | 643.46 | 574 | 30 761 840 |
| DIEN | 2315.56 | 1464 | 30 900 377 |
| MMa4CTR | 163.80 | 23 | 26 025 |
3.3. 消融实验
为了研究模型结构设计对推荐性能的影响,针对用户多模态嵌入向量、多模态特征交互、验证中断与学习率自动半衰这4个重要模块设计6类变体. 其中针对多模态特征交互方式的4个变体如下:分别用3个多模态之间两两组合、3个多模态之间两两交叉、3个多模态交叉、仅使用单一的模态(无模态交互)来取代3种多模态信息拼接. 另外2个变体分别为删除用户多模态嵌入表示或者改变多模态嵌入的长度、删除验证中断机制和学习率自动半衰机制.
在消融实验中,变体模型均只改变MMa4CTR中的一个方面,其余超参数设置和架构设置如无特殊说明则和MMa4CTR保持相同设置. 训练轮次采用
1)多模态信息两两组合. 将每条短视频的视觉、声音和文本3个模态向量两两拼接,在微信数据集和抖音数据集上的实验结果如表5所示. 可以看出,不同的模态组合之间推荐性能相差较小,在微信数据集的实验中同批次下最大的AUC相对差(相对差=(最大值−最小值)/最大值)分别为
表 5 多模态信息两两组合的推荐性能
Tab.5
| 组合 | TikTok | ||||
| AUC@10 | AUC@30 | AUC@10 | AUC@30 | ||
| 视觉+声音 | |||||
| 视觉+文本 | |||||
| 声音+文本 | |||||
2) 多模态信息两两交叉.将每条短视频的视觉、声音、文本向量两两做哈达玛积,在微信数据集和抖音数据集上的实验结果如表6所示. 可以看出,不同组的模态交叉之间推荐性能相差较小,在微信数据集上的实验中同批次下最大的AUC相对差分别为
表 6 多模态信息两两交叉的推荐性能
Tab.6
| 组合 | TikTok | ||||
| AUC@10 | AUC@30 | AUC@10 | AUC@30 | ||
| 视觉+声音 | |||||
| 视觉+文本 | |||||
| 声音+文本 | |||||
3) 3种多模态信息交叉. 将每条短视频的视觉、声音、文本向量依次做哈达玛积运算,在微信数据集上,训练10轮和30轮时模型的推荐性能AUC分别为0.9512和0.9499;在抖音数据集上,训练10轮和30轮时模型的推荐性能AUC分别为0.8911和0.8942. 可以看出,在同一训练批次内,3种多模态信息交叉和组合2种方式下,在微信数据集上的实验中相对差分别为
4) 仅分别使用单一的模态. 取消掉特征工程中挖掘不同模态之间关联交互的步骤,仅使用单模态信息进行推荐. 在微信和抖音数据集上的实验结果如表7所示. 可以看出,没有经过特征工程中的交叉或者组合操作,每种模态信息单独的推荐性能,相较于MMa4CTR中采用的3种模态组合方案,在微信数据集的实验中AUC分别下降了
表 7 单一模态的推荐性能
Tab.7
| 模态 | TikTok | ||||
| AUC@10 | AUC@30 | AUC@10 | AUC@30 | ||
| 视觉 | |||||
| 声音 | |||||
| 文本 | |||||
| 平均 | |||||
5) 删除或者改变用户的多模态嵌入向量. 由用户的邻居节点的多模态信息生成的该用户的多模态嵌入向量,是挖掘用户对短视频多模态兴趣的关键. 对该步骤的消融分2种,一种是彻底不做用户的多模态嵌入,仅以userid作为唯一标识,但保留辅助信息嵌入;另一种是改变多模态嵌入的长度,用户辅助信息嵌入长度不受影响. MMa4CTR中设置的用户多模态嵌入长度为21. 在微信数据集和抖音数据集上的实验结果分别如表8所示. 表中,L为用户多模态嵌入长度. 可以看出,是否有用户多模态嵌入,对模型的推荐性能影响最大. 不生成用户的多模态嵌入,该推荐算法几乎不具有使用价值,由此可见,挖掘用户对短视频多模态兴趣的嵌入技术给推荐性能带来了质的提升. 多模态嵌入本身的长度对推荐性能影响不大的核心原因在于全连接的多层感知机所具有的全局视野,本身就能够较好地拟合向量的各个维度之间的关系,能够自适应地学习到各个维度的权重.
表 8 不同用户多模态嵌入长度的推荐性能
Tab.8
| l | TikTok | ||||
| AUC@10 | AUC@30 | AUC@10 | AUC@30 | ||
6) 禁用验证中断机制和学习率自动半衰机制. 验证中断和学习率自动半衰是MMa4CTR模型训练过程中重要的迭代优化机制. 本消融实验对比了开启和禁用这2个机制时MMa4CTR训练过程中的训练损失和验证损失下降趋势以及测试集上的推荐性能. 在微信数据集上,开启和禁用这2个机制,模型的AUC分别为0.9483和0.9016;在抖音数据集上,开启和禁用这2个机制,模型的AUC分别为0.8886和0.8769. 可以看出,禁用验证中断和学习率自动半衰这2个迭代优化机制,在微信数据集和抖音数据集上的推荐性能分别下降了
综上,用户嵌入层的用户多模态嵌入生成模块对MMa4CTR推荐性能影响最大,特征工程中挖掘模态之间彼此相关交互的交叉算子或者组合算子的影响次之. 用户多模态嵌入的维度和特征交互中采用的算子种类可以根据实际业务场景来灵活选择,在本研究的实验探索范围内,其变化对推荐性能的影响并不显著,这得益于多层感知机对任意函数的拟合能力以及全连接层对列维度的全局感知野. 从上述消融实验的结果中,可以分析出3个重要结论:1)用户多模态嵌入生成的过程能够有效挖掘不同用户对短视频多模态特征的兴趣;2)短视频的各种模态信息之间在自然语义(面向用户)和特征向量(面向模型)上均是高度相关的,采用组合或者交叉的特征交互方式能够进一步增强推荐模型学习到模态之间相关性的能力;3)验证中断机制和学习率自动半衰机制分别通过监视验证集上推荐性能来保证本轮次训练的有效性,通过训练初期使用较大学习率、训练后期使用较小学习率的策略提升了MMa4CTR的收敛性,两者共同用于MMa4CTR模型的迭代优化,小幅提升了推荐性能.
3.4. 超参数敏感性实验
MMa4CTR模型重要的超参数有
1) 训练轮次改变对模型推荐性能的影响.
超参数训练轮次等价于模型遍历训练总体空间的次数. 通常来说,如果训练轮次不足,模型会出现欠拟合,即未能学到总体空间中数据分布特点;如果训练轮次过多,则模型会表现出过拟合,即在验证集上性能优异,但是在测试集上性能表现不佳.
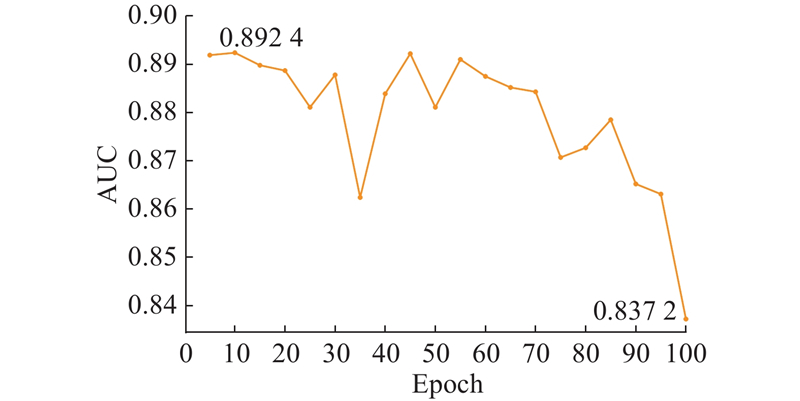
在研究训练轮次对推荐性能影响的实验中,其测试集上推理所用的权重参数取自最后一轮训练迭代后的结果,其余的超参数之类的变量均保持不变. 在微信数据集和抖音数据集上的实验结果分别如图2、3所示. 可以看出,在微信数据集和抖音数据集上各自
图 2
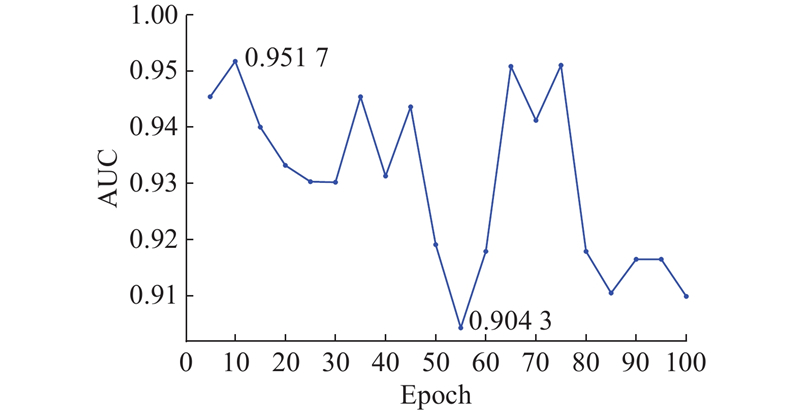
图 3
2) 学习率改变对模型推荐性能的影响.
学习率为模型训练过程中反向传播时模型参数更新的步长. 如果学习率过大,权重参数更新步长过大,则有可能导致模型性能振荡,即在较优解附近徘徊,始终进入不到较优解附近较小的邻域内;如果学习率过小,权重参数更新步长过小,则有可能导致收敛速度慢、容易陷入局部最优解的问题.
在研究学习率超参数对MMa4CTR性能影响的实验中,为了提升实验结果的可靠程度,暂且关闭了自动半衰和验证中断2套机制,即每一个训练轮次的学习率与初始值相同且不会依据验证集上计算出来的AUC对训练进行调整. 训练轮次设置为
表 9 学习率对推荐性能的影响
Tab.9
| 学习率 | TikTok | ||||
| AUC@10 | AUC@30 | AUC@10 | AUC@30 | ||
| 0.01000 | 0.5000 | 0.7433 | 0.7025 | 0.5000 | |
| 0.00500 | 0.5003 | 0.5000 | 0.8518 | 0.5000 | |
| 0.00200 | 0.9178 | 0.9329 | 0.8938 | 0.8919 | |
| 0.00100 | 0.9521 | 0.9406 | 0.8899 | 0.8843 | |
| 0.00050 | 0.9479 | 0.9435 | 0.8871 | 0.8888 | |
| 0.00020 | 0.9470 | 0.9516 | 0.8898 | 0.8867 | |
| 0.00010 | 0.9427 | 0.9485 | 0.8909 | 0.8908 | |
| 0.00005 | 0.9473 | 0.9453 | 0.8893 | 0.8924 | |
| 0.00002 | 0.9494 | 0.9426 | 0.8902 | 0.8892 | |
| 0.00001 | 0.9443 | 0.9489 | 0.8926 | 0.8890 | |
3) 批处理大小改变对模型推荐性能的影响.
批处理大小等于一次前向反向传播中训练样本空间的大小,等价于模型单次迭代中所采样的样本空间大小,代表着模型的并行化能力. 批处理大小的值设置过小,等价于每次模型迭代更新权重时的采样空间过小,过小的采样空间不能反映样本总体的数据分布特点,容易导致欠拟合、模型难以收敛,而且越小的批处理大小意味着越多的迭代次数,延长了训练时间. 反之,批处理大小的值设置过大,即采样空间过大,虽然能够一定程度上更加贴近总体分布情况,但是容易导致过拟合、模型泛化程度降低,并且要占用计算机设备更高的内存.
在研究批处理大小的实验中,除了批处理大小外,其他设置均保持不变. 训练轮次设置为
图 4
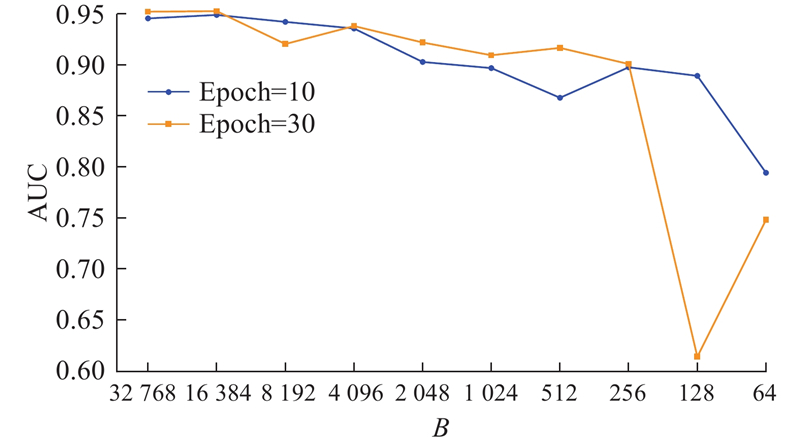
图 4 微信数据集上批处理大小对推荐性能的影响
Fig.4 Impact of batch size on rec-performance on WeChat
图 5
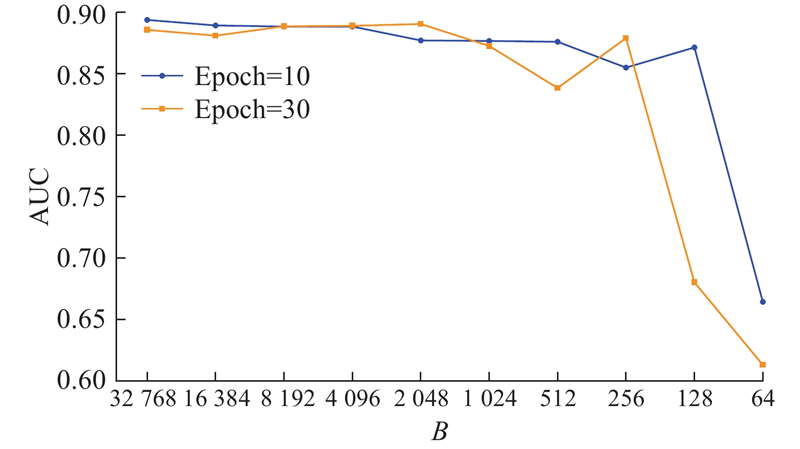
图 5 抖音数据集上批处理大小对推荐性能的影响
Fig.5 Impact of batch size on rec-performance on TikTok
4. 结 语
MMa4CTR使用多模态信息来增强推荐系统性能,以卷积操作和平均池化操作从用户的邻居短视频节点的多模态信息来生成该用户个性化的多模态嵌入表示,以拼接操作或者哈达玛积操作来挖掘每条短视频各自多模态信息的交互特征,这2个设计使得MMa4CTR能够有效挖掘用户对多模态信息的兴趣以及短视频不同模态信息中所隐藏的相同的深层次语义. MMa4CTR以最小的训练参数规模和较短的训练推理时间取得了在点击率预估任务上超越了
MMa4CTR模型具有一定的局限性. 首先,MMa4CTR所构建的用户-短视频交互二分加权图中,未包含代表用户交互短视频行为发生的真实世界时间戳特征. 在实际生产应用中,用户群体观看短视频往往是利用碎片化的通勤时间、排队时间,而在不同的时间段内,用户的心境不同可能导致其兴趣点发生一定的偏移,因此可以将用户交互路径上节点标注的时间戳加入到用户嵌入表达中,从而挖掘用户在不同时间段内的兴趣迁移,可以进一步精细化短视频推荐系统. 此外,挖掘用户交互的历史序列下潜藏的长短期兴趣已在电商推荐和外卖推荐中均取得了广泛研究,因此可以迁移思考,用户点击反馈短视频的路径下,是否也潜藏了用户的兴趣特征. 这需要将MMa4CTR中的二分加权图进一步扩充为有向图,即通过有向边来标注交互路径. 路径采样可以通过控制卷积核的大小来完成,卷积核的采样起始点和尺寸决定了在不同长度的路径中挖掘到的用户长期兴趣和短期兴趣.
参考文献
2003. Amazon. com recommendations: item-to-item collaborative filtering
[J].DOI:10.1109/MIC.2003.1167344 [本文引用: 1]
Product-based neural networks for user response prediction over multi-field categorical data
[J].
What is personalization? perspectives on the design and implementation of personalization in information systems
[J].
Multi-head multi-modal deep interest recommendation network
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}