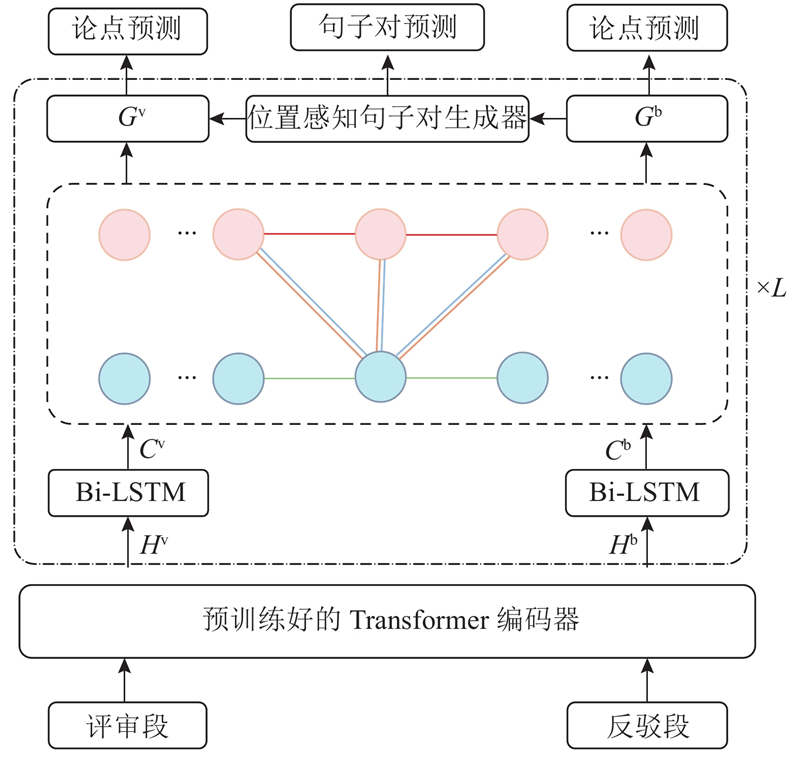
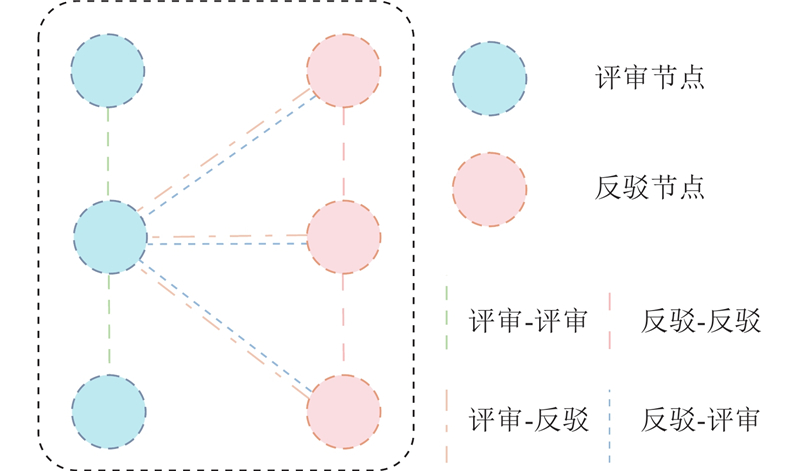
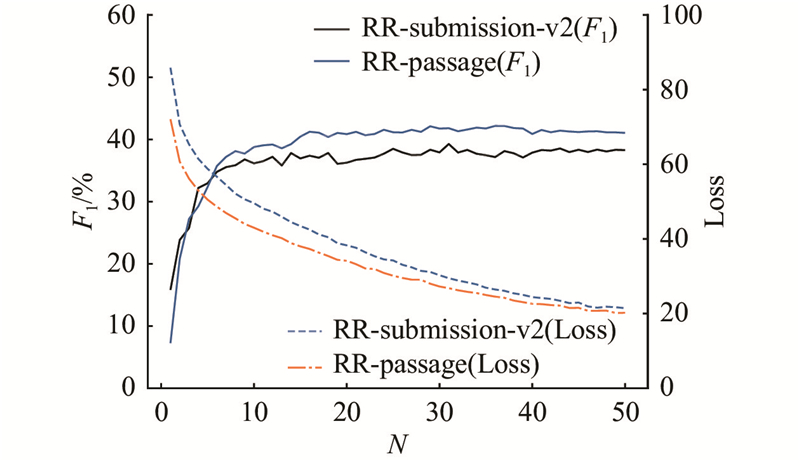
An argument pair extraction model based on heterogeneous graph convolutional neural network was proposed aiming at the issue of difficulty in capturing interactive information between review passage and rebuttal passage and neglecting to model relative positional information between sentences. Heterogeneous graphs were constructed within the review passage and rebuttal passage. Two types of nodes and four types of edges were defined. The relational graph convolutional neural network was utilized to update the representations of nodes within the graph. A position-aware sentence pair generator was introduced, and rotary position embedding was employed to model the relative positional information between sentences in review passage and rebuttal passage. Experimental evaluations on the RR-passage and RR-submission-v2 datasets demonstrate that the proposed model outperforms all baseline models. The performance of the argument pair extraction model can be enhanced by constructing heterogeneous graphs to distinguish between different types of nodes and edges and designing a position-aware sentence pair generator.
Keywords:argument mining
;
argument pair extraction
;
graph neural network
;
rotary position embedding
;
natural language processing
EGER S, DAXENBERGER J, GUREVYCH I. Neural end-to-end learning for computational argumentation mining [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL, 2017: 11-22.
KURIBAYASHI T, OUCHI H, INOUE N, et al. An empirical study of span representations in argumentation structure parsing [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 4691-4698.
MORIO G, FUJITA K. End-to-end argument mining for discussion threads based on parallel constrained pointer architecture [C]// Proceedings of the 5th Workshop on Argument Mining. Brussels: ACL, 2018: 11-21.
CHAKRABARTY T, HIDEY C, MURESAN S, et al. AMPERSAND: argument mining for PERSuAsive oNline discussions [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: ACL, 2019: 2933–2943.
CHENG L, BING L, YU Q, et al. APE: argument pair extraction from peer review and rebuttal via multi-task learning [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. [S. l. ]: ACL, 2020: 7000-7011.
CHENG L, WU T, BING L, et al. Argument pair extraction via attention-guided multi-layer multi-cross encoding [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S. l. ]: ACL, 2021: 6341-6353.
BAO J, LIANG B, SUN J, et al. Argument pair extraction with mutual guidance and inter-sentence relation graph [C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: ACL, 2021: 3923-3934.
BAO J, SUN J, ZHU Q, et al. Have my arguments been replied to? argument pair extraction as machine reading comprehension [C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin: ACL, 2022: 29-35.
WALKER V, FOERSTER D, PONCE J M, et al. Evidence types, credibility factors, and patterns or soft rules for weighing conflicting evidence: argument mining in the context of legal rules governing evidence assessment [C]// Proceedings of the 5th Workshop on Argument Mining. Brussels: ACL, 2018: 68-78.
LE D T, NGUYEN C T, NGUYEN K A. Dave the debater: a retrieval-based and generative argumentative dialogue agent [C]// Proceedings of the 5th Workshop on Argument Mining. Brussels: ACL, 2018: 121-130.
ZHANG F, LITMAN D. Using context to predict the purpose of argumentative writing revisions [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego: ACL, 2016: 1424-1430.
JI L, WEI Z, LI J, et al. Discrete argument representation learning for interactive argument pair identification [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S. l. ]: ACL, 2016: 5467-5478.
YUAN J, WEI Z, ZHAO D, et al. Leveraging argumentation knowledge graph for interactive argument pair identification [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. [S. l. ]: ACL, 2021: 2310-2319.
SHI L, GIUNCHIGLIA F, SONG R, et al. A simple contrastive learning framework for interactive argument pair identification via argument-context extraction [C]// Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi: ACL, 2022: 10027-10039.
SCHLICHTKRULL M, KIPF T N, BLOEM P, et al. Modeling relational data with graph convolutional networks [C]// The Semantic Web: 15th International Conference, Extended Semantic Web Conference. Heraklion: Springer, 2018: 593-607.
WANG K, SHEN W, YANG Y, et al. Relational graph attention network for aspect-based sentiment analysis [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S. l. ]: ACL, 2020: 3229-3238.
HU L, YANG T, SHI C, et al. Heterogeneous graph attention networks for semi-supervised short text classification [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: ACL, 2019: 4821-4830.
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st lnternational Conference on Neural lnformation Processing Systems. California: Curran Associates Inc., 2017: 6000-6010.
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics . Minneapolis: ACL, 2019: 4171-4186.
LAFFERTY J, MCCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings of the 18th International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 2001: 282-289.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}