[1]
余传明 基于深度循环神经网络的跨领域文本情感分析
[J]. 图书情报工作 , 2018 , 62 (11 ): 23 - 34
[本文引用: 1]
YU Chuanming A cross-domain text sentiment analysis based on deep recurrent neural network
[J]. Library and Information Service , 2018 , 62 (11 ): 23 - 34
[本文引用: 1]
[2]
KIPF T, WELLING M. Semi-supervised classification with graph convolutional networks [C]// The 5th International Conference on Learning Representations . Toulon: ICLR, 2017.
[本文引用: 1]
[3]
程艳芬, 吴家俊, 何凡 基于关系门控图卷积网络的方面级情感分析
[J]. 浙江大学学报: 工学版 , 2023 , 57 (3 ): 437 - 445
[本文引用: 1]
CHENG Yanfen, WU Jiajun, HE Fan Aspect level sentiment analysis based on relation gated graph convolutional network
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (3 ): 437 - 445
[本文引用: 1]
[4]
王婷, 朱小飞, 唐顾 基于知识增强的图卷积神经网络的文本分类
[J]. 浙江大学学报: 工学版 , 2022 , 56 (2 ): 322 - 328
WANG Ting, ZHU Xiaofei, TANG Gu Knowledge-enhanced graph convolutional neural networks for text classification
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (2 ): 322 - 328
[5]
夏鸿斌, 顾艳, 刘渊 面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
[J]. 中文信息学报 , 2022 , 36 (3 ): 146 - 153
[本文引用: 1]
XIA Hongbin, GU Yan, LIU Yuan Graph convolution overattention (ASGCN-AOA) model for specific aspects of sentiment analysis
[J]. Journal of Chinese Information Processing , 2022 , 36 (3 ): 146 - 153
[本文引用: 1]
[6]
ZHANG Y, QI P, MANNING C D. Graph convolution over pruned dependency trees improves relation extraction [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing . Brussels: Association for Computational Linguistics, 2018: 2205–2215.
[本文引用: 1]
[7]
王汝言, 陶中原, 赵容剑 多交互图卷积网络用于方面情感分析
[J]. 电子与信息学报 , 2022 , 44 (3 ): 1111 - 1118
[本文引用: 2]
WANG Ruyan, TAO Zhongyuan, ZHAO Rongjian Multi-interaction graph convolutional networks for aspect-level sentiment analysis
[J]. Journal of Electronics and Information Technology , 2022 , 44 (3 ): 1111 - 1118
[本文引用: 2]
[8]
ZHANG C, LI Q, SONG D. Aspect-based sentiment classification with aspect-specific graph convolutional networks [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 4568–4578.
[本文引用: 2]
[9]
SUN K, ZHANG R, MENSAH S, et al. Aspect-level sentiment analysis via convolution over dependency tree [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing . Hong Kong: Association for Computational Linguistics, 2019: 5679–5688.
[本文引用: 2]
[10]
WANG K, SHEN W, YANG Y, et al. Relational graph attention network for aspect-based sentiment analysis [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . [S.l.]: Association for Computational Linguistics, 2020: 3229–3238.
[本文引用: 2]
[11]
HE L, LEE K, LEWIS M, et al. Deep semantic role labeling: what works and what’s next [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) . Vancouver : Association for Computational Linguistics, 2017: 473−483.
[本文引用: 1]
[12]
SACHAN D S, ZHANG Y, QI P, et al. Do syntax trees help pre-trained transformers extract information? [C]// Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume . [S.l.]: Association for Computational Linguistics, 2021: 2647–2661.
[本文引用: 1]
[13]
LIU W, ZHOU P, ZHAO Z, et al. K-BERT: enabling language representation with knowledge graph [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S.l.]: AAAI, 2020: 2901−2908.
[本文引用: 1]
[14]
孙佳慧, 韩萍, 程争 基于知识迁移和注意力融合的方面级文本情感分析
[J]. 信号处理 , 2021 , 37 (8 ): 1384 - 1391
[本文引用: 1]
SUN Jiahui, HAN Ping, CHENG Zheng Aspect-level sentiment analysis based on knowledge transfer and attention fusion
[J]. Journal of Signal Processing , 2021 , 37 (8 ): 1384 - 1391
[本文引用: 1]
[15]
REN Z, ZENG G, CHEN L, et al A lexicon-enhanced attention network for aspect-level sentiment analysis
[J]. IEEE Access , 2020 , 8 : 93464 - 93471
DOI:10.1109/ACCESS.2020.2995211
[本文引用: 1]
[16]
VALLE-CRUZ D, FERNANDEZ-CORTEZ V, LÓPEZ-CHAU A, et al Does Twitter affect stock market decisions? Financial sentiment analysis during pandemics: a comparative study of the h1n1 and the covid-19 periods
[J]. Cognitive Computation , 2022 , 14 : 372 - 378
DOI:10.1007/s12559-021-09819-8
[本文引用: 1]
[17]
DISTANTE D, FARALLI S, RITTINGHAUS S, et al DomainSenticNet: an ontology and a methodology enabling domain-aware sentic computing
[J]. Cognitive Computation , 2022 , 14 : 62 - 77
DOI:10.1007/s12559-021-09825-w
[本文引用: 1]
[18]
BIAN X, FENG C, AHMAD A, et al. Targeted sentiment classification with knowledge powered attention network [C]// 2019 IEEE 31st International Conference on Tools with Artificial Intelligence . Portland: IEEE, 2019: 1073−1080.
[本文引用: 1]
[19]
CAMBRIA E, LI Y, XING F Z, et al. SenticNet 6: ensemble application of symbolic and subsymbolic ai for sentiment analysis [C]// Proceedings of the 29th ACM international conference on information and knowledge management . [S.l.]: ACM, 2020: 105−114.
[本文引用: 2]
[20]
LIANG B, SU H, GUI L, et al Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks
[J]. Knowledge-Based Systems , 2022 , 235 : 107643
DOI:10.1016/j.knosys.2021.107643
[本文引用: 1]
[21]
WANG Z, WANG H, WEN J R, et al. An inference approach to basic level of categorization [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . [S.l.]: ACM, 2015: 653−662.
[本文引用: 2]
[22]
PENNINGTON J, SOCHER R, MANNING C. GloVe: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: Association for Computational Linguistics, 2014: 1532−1543.
[本文引用: 1]
[23]
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) . Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
[本文引用: 2]
[24]
TANG D, QIN B, FENG X, et al. Effective LSTMs for target-dependent sentiment classification [C]// Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers . Osaka: The COLING 2016 Organizing Committee, 2016: 3298–3307
[本文引用: 2]
[25]
ALTINOK D. Mastering spaCy: an end-to-end practical guide to implementing NLP applications using the Python ecosystem [M]. [S.l.]: Packt Publishing, 2021.
[本文引用: 1]
[26]
QI P, ZHANG Y, ZHANG Y, et al. Stanza: a Python natural language processing toolkit for many human languages [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations . [S.l.]: Association for Computational Linguistics, 2020: 101–108.
[本文引用: 1]
[27]
DONG L, WEI F, TAN C, et al. Adaptive recursive neural network for target-dependent Twitter sentiment classification [C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) . Baltimore: Association for Computational Linguistics, 2014: 49−54.
[本文引用: 1]
[28]
PONTIKI M, GALANIS D, PAVLOPOULOS J, et al. Semeval-2014 task 4: aspect based sentiment analysis [C]// Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval-2014) . Dublin: Association for Computational Linguistics, 2014: 27−35.
[29]
PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2015 task 12: aspect based sentiment analysis [C]// Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015) . Denver: Association for Computational Linguistics, 2015: 486−495.
[30]
PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. SemEval-2016 task 5: aspect based sentiment analysis [C]// Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016) . San Diego: Association for Computational Linguistics, 2016: 19−30.
[本文引用: 1]
[31]
MA D, LI S, ZHANG X, et al. Interactive attention networks for aspect-level sentiment classification [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence . [S. l.]: AAAI, 2017: 4068–4074.
[本文引用: 1]
[32]
CHEN C, TENG Z, ZHANG Y. Inducing target-specific latent structures for aspect sentiment classification [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing . [S.l.] : Association for Computational Linguistics, 2020: 5596−5607.
[本文引用: 1]
[33]
ZHOU J, HUANG J X, HU Q V, et al SK-GCN: modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification
[J]. Knowledge-Based Systems , 2020 , 205 : 106292
DOI:10.1016/j.knosys.2020.106292
[本文引用: 1]
[34]
崔少国, 陈思奇, 杜兴 面向目标情感分析的双重图注意力网络模型
[J]. 西安电子科技大学学报 , 2023 , 50 (1 ): 137 - 148
[本文引用: 1]
CUI Shaoguo, CHEN Siqi, DU Xing Dual graph attention networks model for target sentiment analysis
[J]. Journal of Xidian University , 2023 , 50 (1 ): 137 - 148
[本文引用: 1]
[35]
XIN X, WUMAIER A, KADEER Z, et al SSEMGAT: syntactic and semantic enhanced multi-layer graph attention network for aspect-level sentiment analysis
[J]. Applied Sciences , 2023 , 13 (8 ): 5085
DOI:10.3390/app13085085
[本文引用: 1]
[36]
JIANG T, WANG Z, YANG M, et al Aspect-based sentiment analysis with dependency relation weighted graph attention
[J]. Information , 2023 , 14 (3 ): 185
DOI:10.3390/info14030185
[本文引用: 1]
[37]
谷雨影, 高美凤 融合词性与外部知识的方面级情感分析
[J]. 计算机科学与探索 , 2013 , 17 (10 ): 2488 - 2498
[本文引用: 1]
GU Yuying, GAO Meifeng Aspect-level sentiment analysis combining part-of-speech and external knowledge
[J]. Journal of Frontiers of Computer Science and Technology , 2013 , 17 (10 ): 2488 - 2498
[本文引用: 1]
[38]
BROWN T, MANN B, RYDER N, et al Language models are few-shot learners
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 1877 - 1901
[本文引用: 1]
[39]
OUYANG L, WU J, JIANG X, et al Training language models to follow instructions with human feedback
[J]. Advances in Neural Information Processing Systems , 2022 , 35 : 27730 - 27744
[本文引用: 1]
[40]
CHEN M, TWOREK J, JUN H, et al. Evaluating large language models trained on code [EB/OL]. (2021-07-14)[2023-05-22]. https://arxiv.org/pdf/2107.03374.pdf.
[本文引用: 1]
基于深度循环神经网络的跨领域文本情感分析
1
2018
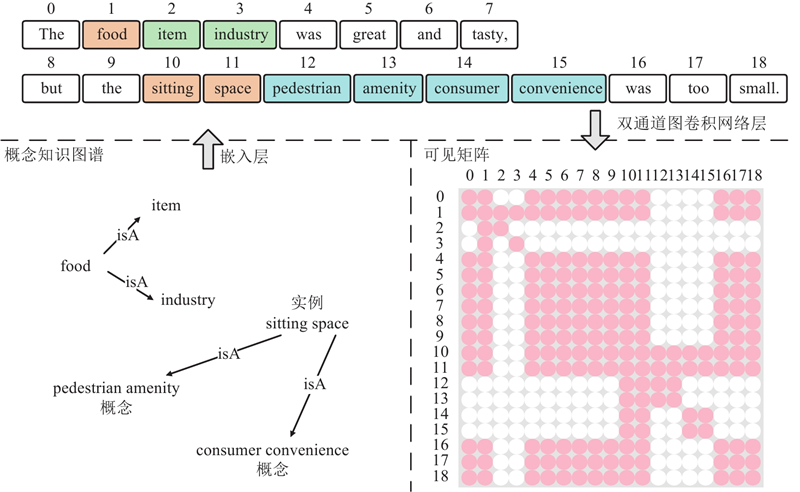
... 方面级情感分析(aspect-based sentiment analysis,ABSA)旨在对文本中给定的方面词进行情感极性分类,包括正面、中立和负面[1 ] ,是自然语言处理 (natural language processing,NLP) 领域的重要研究方向. 如“The food was great and tasty, but the sitting space was too small.”,ABSA能够将方面词 “food”和“sitting space”分别分类为积极和消极. ...
基于深度循环神经网络的跨领域文本情感分析
1
2018
... 方面级情感分析(aspect-based sentiment analysis,ABSA)旨在对文本中给定的方面词进行情感极性分类,包括正面、中立和负面[1 ] ,是自然语言处理 (natural language processing,NLP) 领域的重要研究方向. 如“The food was great and tasty, but the sitting space was too small.”,ABSA能够将方面词 “food”和“sitting space”分别分类为积极和消极. ...
1
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
基于关系门控图卷积网络的方面级情感分析
1
2023
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
基于关系门控图卷积网络的方面级情感分析
1
2023
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
基于知识增强的图卷积神经网络的文本分类
0
2022
基于知识增强的图卷积神经网络的文本分类
0
2022
面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
1
2022
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
面向特定方面情感分析的图卷积过度注意(ASGCN-AOA)模型
1
2022
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
1
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
多交互图卷积网络用于方面情感分析
2
2022
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
多交互图卷积网络用于方面情感分析
2
2022
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
2
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
2
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
2
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
... [10 ]同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
1
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
1
... 图卷积网络(graph convolutional networks,GCN) [2 ] 因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3 -5 ] . Zhang等[6 ] 证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效. 有许多成功的方法在依赖树上使用GCN模型进行方面级情感分类,如王汝言等[7 ] 利用依存树中的语法距离特征对GCN的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang等[8 ] 将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9 ] 在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang等[10 ] 提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构. 上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang等[10 ] 同时发现,现有的方法容易出现解析错误. 尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树. He等[11 ] 证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan注入语法后的Transformer性能是否提升在很大程度上取决于依存关系解析[12 ] . 这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声. ...
1
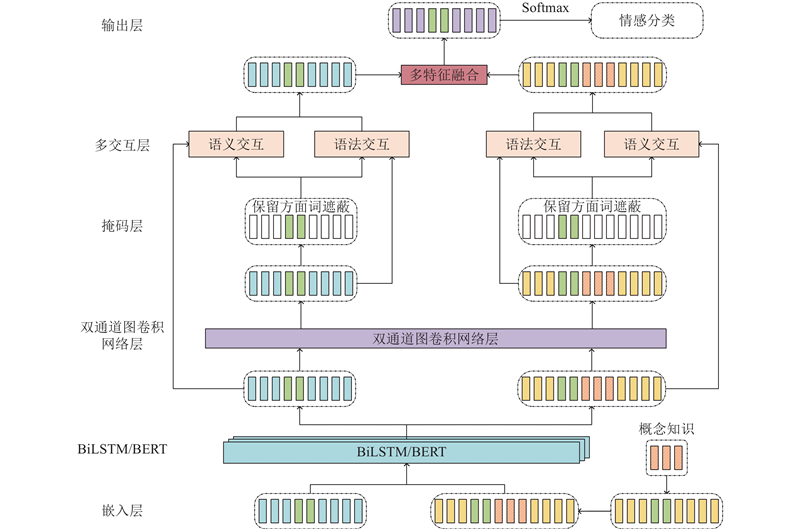
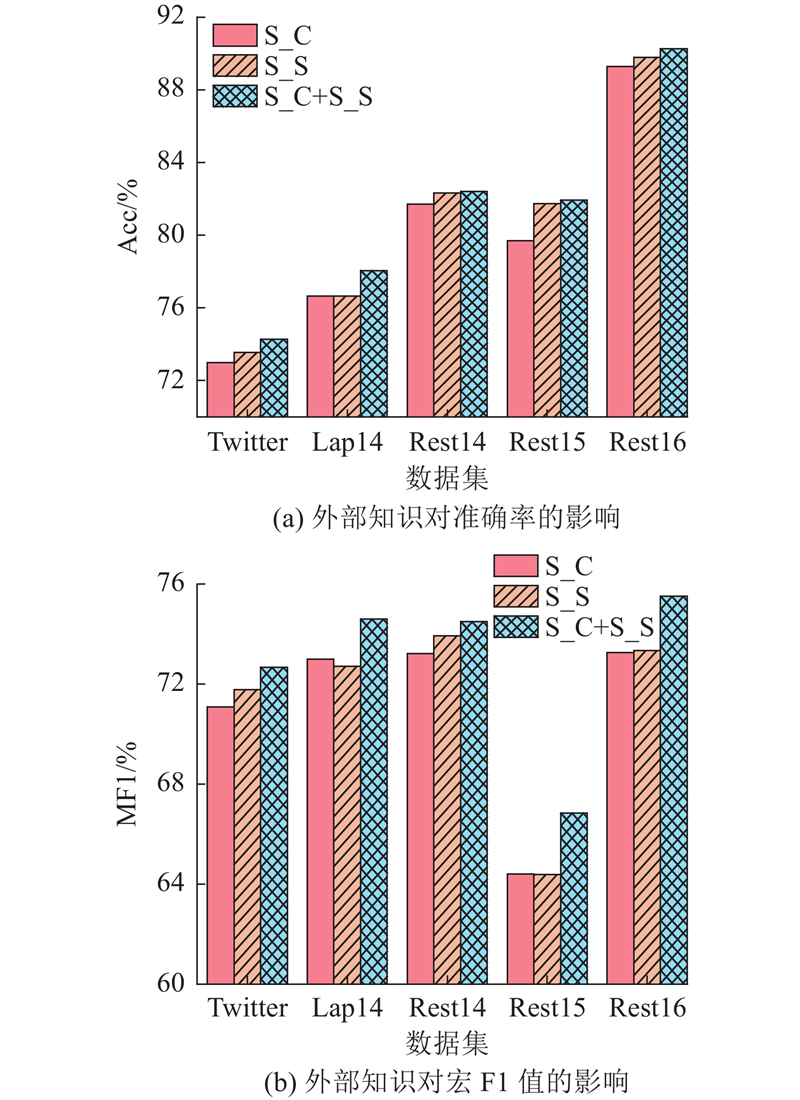
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
基于知识迁移和注意力融合的方面级文本情感分析
1
2021
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
基于知识迁移和注意力融合的方面级文本情感分析
1
2021
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
A lexicon-enhanced attention network for aspect-level sentiment analysis
1
2020
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
Does Twitter affect stock market decisions? Financial sentiment analysis during pandemics: a comparative study of the h1n1 and the covid-19 periods
1
2022
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
DomainSenticNet: an ontology and a methodology enabling domain-aware sentic computing
1
2022
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
1
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
2
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
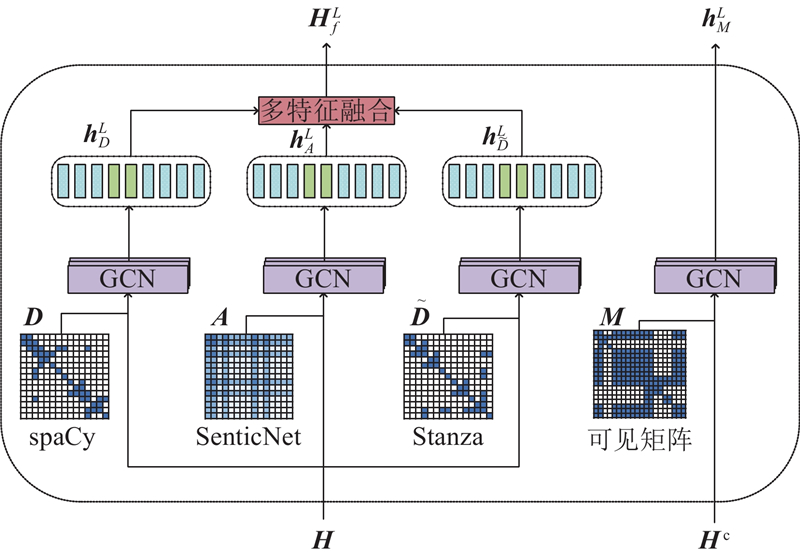
... 外部情感知识在情感分析任务中被广泛应用[19 ] ,以提升特征表示的准确性和可靠性. 为了使情感信息不对某个单独的依赖图产生影响,引入SenticNet的情感评分,使情感评分独立成图: ...
Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks
1
2022
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
2
... 尽管GCN对语法和语义进行了协同开发,但仍存在局限性:GCN通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类. 增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降. 为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13 ] . 外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14 ] . Ren等[15 ] 利用情感词典来提取句子中的情感信息进行注意力权重计算. 对比传统的情感词典,SenticNet可以更好地捕捉词汇之间的相关性[16 ] . SenticNet是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17 -19 ] . Bian等[18 ] 使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能. Liang等[20 ] 将SenticNet的情感信息与依赖树相结合,增强了文本的情感极性. Microsoft Concept Graph[21 ] 显式知识库丰富了上下文和目标的语义表示. ...
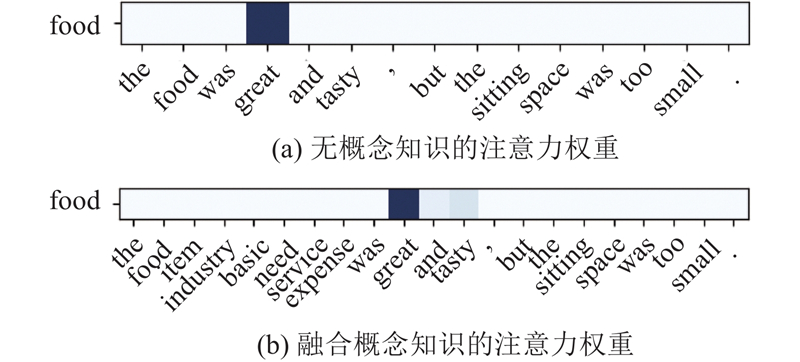
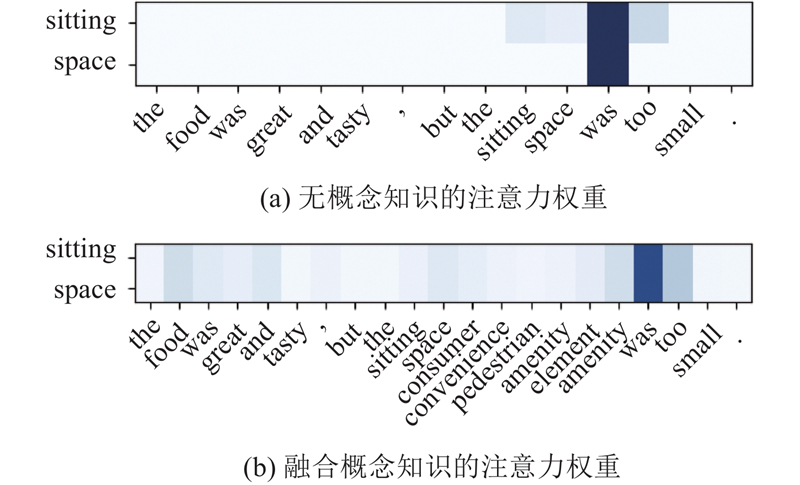
... Microsoft Concept Graph[21 ] 使用isA关系,通过概念化的方法将目标词即实例与实例的相关概念联系起来,称为单实例概念化. 本研究将k 个概念知识插入对应的方面词后,通过嵌入层可以得到表示V v 1 , v 2 , ···, v a 1v a 2v am v c 1v c 2v ck −1v ck v n −1v n H c h 1 , h 2 , ···, h n
1
... 使用GloVe[22 ] 或BERT[23 ] 预训练词典,将每个单词映射到低维实值向量空间,构建由低维实数向量组成的词向量: ...
2
... 使用GloVe[22 ] 或BERT[23 ] 预训练词典,将每个单词映射到低维实值向量空间,构建由低维实数向量组成的词向量: ...
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
2
... BiLSTM利用反向传播算法,通过句子的正反输入分别建立正向和反向的上下文依存关系,能够比单向LSTM[24 ] 提取出更多的上下文信息. BERT不再依赖传统的单向语言模型,而是采用掩码语言模型(masked language model,MLM)实现更深层次的双向语言表征. 通过将初始化的向量输入BiLSTM或BERT,提取句子中的隐藏信息,得到双向语言表征H h 1 , h 2 , ···, h n
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
1
... 为了充分利用句子单词间的依存关系,分别采用句法依赖构建工具spaCy[25 ] 和Stanza[26 ] ,为每个输入句子的构建2个不同的依赖图. 相比单个依赖图,2个依赖图可以在依存关系方面进行互补,使依赖错误问题减少. 推导出句子的2个邻接矩阵D R n×n $\tilde {\boldsymbol{D}} $ R n×n D $\tilde {\boldsymbol{D}} $
1
... 为了充分利用句子单词间的依存关系,分别采用句法依赖构建工具spaCy[25 ] 和Stanza[26 ] ,为每个输入句子的构建2个不同的依赖图. 相比单个依赖图,2个依赖图可以在依存关系方面进行互补,使依赖错误问题减少. 推导出句子的2个邻接矩阵D R n×n $\tilde {\boldsymbol{D}} $ R n×n D $\tilde {\boldsymbol{D}} $
1
... 使用Twitter、Restaurant14、Laptop14、Restaurant15、Restaurant16数据集[27 -30 ] 来验证模型有效性. 每个数据集都由1组训练模型和1组测试模型组成,每个句子都是独立的样本,其中包括评论文本、方面词以及与之相关的情绪标签. 训练集和测试集以及标签分布如表1 所示,其中N pos 、N neu 、N neg 分别为积极、中性和消极标签的数量. ...
1
... 使用Twitter、Restaurant14、Laptop14、Restaurant15、Restaurant16数据集[27 -30 ] 来验证模型有效性. 每个数据集都由1组训练模型和1组测试模型组成,每个句子都是独立的样本,其中包括评论文本、方面词以及与之相关的情绪标签. 训练集和测试集以及标签分布如表1 所示,其中N pos 、N neu 、N neg 分别为积极、中性和消极标签的数量. ...
1
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
1
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
SK-GCN: modeling syntax and knowledge via graph convolutional network for aspect-level sentiment classification
1
2020
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
面向目标情感分析的双重图注意力网络模型
1
2023
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
面向目标情感分析的双重图注意力网络模型
1
2023
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
SSEMGAT: syntactic and semantic enhanced multi-layer graph attention network for aspect-level sentiment analysis
1
2023
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
Aspect-based sentiment analysis with dependency relation weighted graph attention
1
2023
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
融合词性与外部知识的方面级情感分析
1
2013
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
融合词性与外部知识的方面级情感分析
1
2013
... 对比MDKGCN与多种情感分析方法探究方法的差异. 参与对比的其他方法如下. 1)LSTM[24 ] :使用单向的LSTM编码上下文信息,用于方面级情感分析. 2)IAN[31 ] :使用BiLSTM编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系. 3)ASGCN[8 ] :通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系. 4)kumaGCN[32 ] :将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性. 5)SKGCN[33 ] :使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力. 6)CDT[9 ] :将句子的依赖树与图神经网络结合,学习方面特征表示. 7)MI-GCN[7 ] :通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题. 8)DGAT[34 ] :利用BiLSTM提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系. 9)BERT-BASE[23 ] :使用双向Transformers网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征. 10)SSEMGAT-BERT[35 ] :引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征. 11)WGAT-BERT[36 ] :根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取. 12)MFSGC-BERT[37 ] :使用SenticNet增强句法依赖树,并输入GCN进行特征融合,以丰富情感特征. ...
Language models are few-shot learners
1
2020
... 如表6 所示,跟踪GPT-3系列大型语言模型,对Davinci[38 ] 、Text-Davinci-001[39 ] 、Code-Davinci-002[40 ] 、Text-Davinci-002、Text-Davinci-003和GPT-3.5-Turbo进行对比分析. 可以发现,尽管大语言模型的优势较为明显,但两者的参数量级不在同一水平线上. BERT拥有1.10×108 的参数量,仅为情感分析能力最强的Code-Davinci-002模型1.75×1013 参数量的0.63‰,在情感分析任务中拥有其超过85%的性能,微调后的MDKGCN-BERT更是拥有其超过88%的性能. ...
Training language models to follow instructions with human feedback
1
2022
... 如表6 所示,跟踪GPT-3系列大型语言模型,对Davinci[38 ] 、Text-Davinci-001[39 ] 、Code-Davinci-002[40 ] 、Text-Davinci-002、Text-Davinci-003和GPT-3.5-Turbo进行对比分析. 可以发现,尽管大语言模型的优势较为明显,但两者的参数量级不在同一水平线上. BERT拥有1.10×108 的参数量,仅为情感分析能力最强的Code-Davinci-002模型1.75×1013 参数量的0.63‰,在情感分析任务中拥有其超过85%的性能,微调后的MDKGCN-BERT更是拥有其超过88%的性能. ...
1
... 如表6 所示,跟踪GPT-3系列大型语言模型,对Davinci[38 ] 、Text-Davinci-001[39 ] 、Code-Davinci-002[40 ] 、Text-Davinci-002、Text-Davinci-003和GPT-3.5-Turbo进行对比分析. 可以发现,尽管大语言模型的优势较为明显,但两者的参数量级不在同一水平线上. BERT拥有1.10×108 的参数量,仅为情感分析能力最强的Code-Davinci-002模型1.75×1013 参数量的0.63‰,在情感分析任务中拥有其超过85%的性能,微调后的MDKGCN-BERT更是拥有其超过88%的性能. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}