[1]
交通运输部 2020年全国收费公路统计公报
[J]. 交通财会 , 2021 , (11 ): 93 - 96
[本文引用: 1]
Ministry of Transport 2020 national toll road statistics bulletin
[J]. Transportation Finance and Accounting , 2021 , (11 ): 93 - 96
[本文引用: 1]
[2]
徐鹏, 祝轩, 姚丁, 等 沥青路面养护智能检测与决策综述
[J]. 中南大学学报: 自然科学版 , 2021 , 52 (7 ): 2099 - 2117
[本文引用: 1]
XU Peng, ZHU Xuan, YAO Ding, et al Review on intelligent detection and decision-making of asphalt pavement maintenance
[J]. Journal of Central South University: Science and Technology , 2021 , 52 (7 ): 2099 - 2117
[本文引用: 1]
[3]
马建, 赵祥模, 贺拴海, 等 路面检测技术综述
[J]. 交通运输工程学报 , 2017 , 17 (5 ): 121 - 137
DOI:10.3969/j.issn.1671-1637.2017.05.012
[本文引用: 1]
MA Jian, ZHAO Xiang-mo, HE Shuan-hai, et al Review of pavement detection technology
[J]. Journal of Traffic and Transportation Engineering , 2017 , 17 (5 ): 121 - 137
DOI:10.3969/j.issn.1671-1637.2017.05.012
[本文引用: 1]
[4]
交通运输部公路研究院. 公路技术状况评定标准: JTG 5210-2018 [S]. 北京: 人民交通出版社, 2018: 17-21.
[本文引用: 1]
[5]
交通运输部公路研究院. 公路路面技术状况自动化检测规程: JTGT E61-2014 [S]. 北京: 人民交通出版社, 2014: 11-14.
[本文引用: 2]
[7]
翁飘, 陆彦辉, 齐宪标, 等. 基于改进的全卷积神经网络的路面裂缝分割技术[J]. 计算机工程与应用, 2019, 55(16): 235-239.
[本文引用: 2]
WENG Piao, LU Yan-hui, QI Xian-biao, et al. Pavement crack segmentation technology based on improved fully convolutional networks [J]. Computer Engineering and Applications. 2019, 55(16): 235-239.
[本文引用: 2]
[8]
赵颖. 基于卷积神经网络的沥青路面裂缝图像筛选与分割[D]. 石家庄: 石家庄铁道大学, 2021: 9-13.
ZHAO Ying. Pavement crack segmentation technology based on improved fully convolutional networks [D]. Shijiazhuang: Shijiazhuang Railway University, 2021: 9-13.
[9]
唐由之. 基于卷积神经网络的沥青路面裂缝智能识别算法研究[D]. 成都: 西南交通大学, 2021: 13-22.
[本文引用: 1]
TANG You-zhi. Research on intelligent cracks detection algorithm of asphalt pavement based on convolutional neural network [D]. Chengdu: Southwest Jiaotong University, 2021: 13-22.
[本文引用: 1]
[10]
HSIEH Y A, TSAI Y J Machine learning for crack detection: review and model performance comparison
[J]. Journal of Computing in Civil Engineering , 2021 , 34 (5 ): 04020038
[本文引用: 1]
[12]
李刚, 高振阳, 张新春, 等 改进的全局卷积网络在路面裂缝检测中的应用
[J]. 激光与光电子学进展 , 2020 , 57 (8 ): 111 - 119
[本文引用: 1]
LI Gang, GAO Zhen-yang, ZHANG Xin-chun, et al Application of improved global convolution network in pavement crack detection
[J]. Progress in Laser and Optoelectronics , 2020 , 57 (8 ): 111 - 119
[本文引用: 1]
[13]
陈泽斌, 罗文婷, 李林. 基于改进U-net模型的路面裂缝智能识别[J]. 数据采集与处理. 2020, 35(2): 260-269.
[本文引用: 1]
CHEN Ze-bin, LUO Wen-ting, LI Lin. Automatic identification of pavement crack using improved U-net model [J]. Journal of Data Acquisition and Processing, 2020, 35(2): 260-269.
[本文引用: 1]
[14]
阙云, 季雪, 蒋子平, 等. GAN数据增强下路面裂缝语义分割算法[EB/OL]. (2022-07-08) [2022-12-04]. http://doi.org/10.13229/j.cnki.jdxbgxb20220003.
[本文引用: 1]
QUE Yun, JI Xue, JIANG Zi-ping, et al. Semantic segmentation algorithm of pavement cracks based on GAN data augmentation [EB/OL]. (2022-07-08)[2022-12-04]. http://doi.org/10.13229/j.cnki.jdxbgxb20220003.
[本文引用: 1]
[15]
ZHANG A, WANGK C P, FEI Y, et al Automated pixe mmevel pavement crack detection on 3D asphalt surfaces with a recurrent neural network
[J]. Computer Aided Civil and Infrastruc Ture Engineering , 2018 , 34 (3 ): 213 - 229
[本文引用: 1]
[16]
XIANG X, ZHANG Y, SADDIK ABDULMOTALEB S Pavement crack detection network based on pyramid structure and attention mechanism
[J]. IET Image Processing , 2020 , 14 (8 ): 1580 - 1586
DOI:10.1049/iet-ipr.2019.0973
[本文引用: 1]
[17]
YANG F, LEI Z, SIJIA Y, et al Feature pyramid and hierarchical boosting network for pavement crack detection
[J]. IEEE Transactions on Intelligent Transportation Systems , 2020 , (4 ): 1525 - 1535
[本文引用: 4]
[19]
周颖, 刘彤 基于计算机视觉的混凝土裂缝识别
[J]. 同济大学学报: 自然科学版 , 2019 , 47 (9 ): 1277 - 1285
ZHOU Ying, LIU Tong Computer vision-based crack detection and measurement on concrete structure
[J]. Journal of Tongji University: Natural Science , 2019 , 47 (9 ): 1277 - 1285
[20]
孟诗乔, 张啸天, 乔甦阳, 等 基于深度学习的网格优化裂缝检测模型研究
[J]. 建筑结构学报 , 2020 , 41 (增2 ): 404 - 410
DOI:10.14006/j.jzjgxb.2020.S2.0045
MENG Shi-qiao, ZHAO Xiao-tian, QIAO Su-yang, et al Research on grid optimized crack detection model based on deep learning
[J]. Journal of Building Structures , 2020 , 41 (增2 ): 404 - 410
DOI:10.14006/j.jzjgxb.2020.S2.0045
[21]
丁威, 俞珂, 舒江鹏 基于深度学习和无人机的混凝土结构裂缝检测方法
[J]. 土木工程学报 , 2021 , 54 (增1 ): 1 - 12
[本文引用: 1]
DING Wei, YU Ke, SHU Jiang-peng Method for detecting cracks in concrete structures based on deep learning and UAV
[J]. Journal of Civil Engineering , 2021 , 54 (增1 ): 1 - 12
[本文引用: 1]
[22]
CSURKA G, PERRONNIN F An efficient approach to semantic segmentation
[J]. International Journal of Computer Vision , 2011 , 95 (2 ): 198 - 212
DOI:10.1007/s11263-010-0344-8
[本文引用: 1]
[23]
EVERINGHAM M, ESLAMI S M, GOOL L V, et al The pascal visual object classes challenge: a retrospective
[J]. International Journal of Computer Vision , 2015 , 111 (1 ): 98 - 136
DOI:10.1007/s11263-014-0733-5
[本文引用: 2]
[24]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// Computer Vision–ECCV. Zürich: SIP, 2014: 740-755.
[本文引用: 1]
[25]
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 2039-2047.
[本文引用: 1]
[26]
EISENBACH M, STRICKER R, SEICHTER D, et al. How to get pavement distress detection ready for deep learning? a systematic approach [C]// International Joint Conference on Neural Networks. Anchorage: IEEE, 2017: 2039−2047.
[本文引用: 4]
[27]
LEON B, FRANK E C, JORGE N Optimization methods for large-scale machine learning
[J]. Siam Review , 2018 , 60 (2 ): 223 - 311
[本文引用: 2]
[28]
任凤雷, 何昕, 魏仲慧, 等 基于DeepLabV3+与超像素优化的语义分割
[J]. 光学精密工程 , 2019 , 27 (12 ): 2722 - 2729
[本文引用: 1]
REN Feng-lei, HE Xin, WEI Zhong-hui Semantic segmentation based on DeepLabV3+ and super pixel optimization
[J]. Optics and Precision Engineering , 2019 , 27 (12 ): 2722 - 2729
[本文引用: 1]
[29]
于桐, 吴文瑾, 刘海江, 等 基于改进U-Net网络与联合损失函数的海南自然保护区高分辨率遥感变化检测模型
[J]. 中国环境监测 , 2021 , 37 (5 ): 194 - 200
[本文引用: 2]
YU Tong, WU Wen-jin, LIU Jiang-hai, et al Remote sensing change detection model of Hainan nature reserves based on improved U-Net and joint loss function
[J]. Environmental Monitoring in China , 2021 , 37 (5 ): 194 - 200
[本文引用: 2]
[30]
LIN T Y, GOYAL P, GIRSHICK R, et al Focal loss for dense object detection
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (2 ): 318 - 327
[本文引用: 2]
[31]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770−778.
[本文引用: 1]
[32]
SANDLER M, HOCARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510−4520.
[本文引用: 2]
[33]
张晋赫, 秦育罗, 张在岩, 等 复杂场景下农村道路裂缝分割方法
[J]. 测绘通报 , 2022 , 66 (5 ): 74 - 78
[本文引用: 1]
ZHANG Jin-he, QIN Yu-luo, ZHANG Zai-yan, et al Rural road crack segmentation method in complex scene
[J]. Bulletin of Surveying and Mapping , 2022 , 66 (5 ): 74 - 78
[本文引用: 1]
[34]
汪德佳. 基于计算机视觉方法的古建筑变形监测[D]. 北京: 北京交通大学, 2022: 67−68.
[本文引用: 1]
Wang De-jia. Deformation monitoring of ancient buildings based on computer vision methods [D]. Beijing: Beijing Jiaotong University, 2022: 67−68.
[本文引用: 1]
[35]
刘宇飞. 基于模型修正与图像处理的多尺度结构损伤识别[D]. 北京: 清华大学, 2015: 188−189.
[本文引用: 1]
LIU Yu-fei. Multi-scale structural damage assessment based on model updating and image processing [D]. Beijing: Tsinghua University, 2015: 188−189.
[本文引用: 1]
2020年全国收费公路统计公报
1
2021
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
2020年全国收费公路统计公报
1
2021
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
沥青路面养护智能检测与决策综述
1
2021
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
沥青路面养护智能检测与决策综述
1
2021
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
路面检测技术综述
1
2017
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
路面检测技术综述
1
2017
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
1
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
2
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
... 为了衡量不同语义分割模型的作用及贡献建立混淆矩阵,其中TP为模型预测是裂缝且真实值也是裂缝的像素个数、FP为模型预测是裂缝但是真实值不是裂缝的像素个数、FN为模型未预测是裂缝但是真实值是裂缝的像素个数、TN为模型未预测是裂缝且真实值的确不是裂缝的像素个数. 基于TP、 FP、 FN、 TN,采用模型评价指标包括交并比(intersection over union, IOU)、准确率Acc、召回率Re、F1分数、精确率Pr[5 ] ,其定义及计算公式如表4 所示. ...
沥青路面裂缝图像检测算法研究
1
2012
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
沥青路面裂缝图像检测算法研究
1
2012
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
2
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
2
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
1
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
1
... 截至2021年末,全国公路通车总里程达到528.07万 km,是1984年末的5.7倍,其中高速公路通车量达16.91万 km,总里程规模位居世界第一. 沥青公路凭借养护便捷、行车舒适的优点,在高速公路里程中占比超过 90% [1 -2 ] . 随着运营年限的增加,运营维护问题突显,沥青公路整体面临长期、繁重的监测诊断与维护任务. 传统的路面检查方式以人工为主,存在工作环境危险、检测效率低、过于依赖人的主观经验等问题,难以保证结果的全面与精确[3 ] . 根据现行《JTG 5210-2018 公路技术状况评定标准》[4 ] 以及《JTGT E61-2014 公路沥青路面技术状况自动化检测规程》[5 ] ,对公路技术状况的检测提出具体要求:检测评价内容包括路面损坏. 裂缝作为主要路面损坏特征,是路面技术状况检测的重点之一. 不同于普通混凝土、水泥路面图像,沥青路面图像的多纹理性、多噪点性、光强多变性,导致图像中的裂缝信息微弱,增加了自动识别技术的挑战性[6 ] . 交通运输部颁布的《交通运输科技“十三五”发展规划》中明确阐述对高速公路的智能化管理,如何实现高速公路运维的自动化、智能化是当下的研究热点[7 -9 ] . ...
Machine learning for crack detection: review and model performance comparison
1
2021
... 深度学习方法是计算机在无人工干预的情况下自主学习对象的特征. 卷积神经网络(convolutional neural network,CNN)也被证明是计算机视觉领域中先进的技术,在应用上主要分为3类[10 ] : 图像分类、目标检测、语义分割. 其中语义分割方法能够根据图像的纹理、场景和其他高层语义特征得出图像本身需要表达的信息,因此在裂缝检测中,语义分割能够在像素级别分割出裂缝的本身形态,有利于裂缝参数的量化计算[11 ] . ...
基于深度学习的图像语义分割方法综述
3
2019
... 深度学习方法是计算机在无人工干预的情况下自主学习对象的特征. 卷积神经网络(convolutional neural network,CNN)也被证明是计算机视觉领域中先进的技术,在应用上主要分为3类[10 ] : 图像分类、目标检测、语义分割. 其中语义分割方法能够根据图像的纹理、场景和其他高层语义特征得出图像本身需要表达的信息,因此在裂缝检测中,语义分割能够在像素级别分割出裂缝的本身形态,有利于裂缝参数的量化计算[11 ] . ...
... Csurka等[22 ] 提出语义分割(image semantic segmentation,ISS),目标是图像中的每个像素进行分类,并将其标记为不同的语义类别. 与传统的图像分割相比,ISS的特点是为图像中的目标加上一定的语义信息[11 ] . 在沥青路面检测中,对裂缝目标进行像素级的分割,有利于裂缝参数(长度、宽度)的计算. 常用语义分割算法的优势及存在的问题总结如表1 所示. ...
... 常用语义分割算法总结[11 ] ...
基于深度学习的图像语义分割方法综述
3
2019
... 深度学习方法是计算机在无人工干预的情况下自主学习对象的特征. 卷积神经网络(convolutional neural network,CNN)也被证明是计算机视觉领域中先进的技术,在应用上主要分为3类[10 ] : 图像分类、目标检测、语义分割. 其中语义分割方法能够根据图像的纹理、场景和其他高层语义特征得出图像本身需要表达的信息,因此在裂缝检测中,语义分割能够在像素级别分割出裂缝的本身形态,有利于裂缝参数的量化计算[11 ] . ...
... Csurka等[22 ] 提出语义分割(image semantic segmentation,ISS),目标是图像中的每个像素进行分类,并将其标记为不同的语义类别. 与传统的图像分割相比,ISS的特点是为图像中的目标加上一定的语义信息[11 ] . 在沥青路面检测中,对裂缝目标进行像素级的分割,有利于裂缝参数(长度、宽度)的计算. 常用语义分割算法的优势及存在的问题总结如表1 所示. ...
... 常用语义分割算法总结[11 ] ...
改进的全局卷积网络在路面裂缝检测中的应用
1
2020
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
改进的全局卷积网络在路面裂缝检测中的应用
1
2020
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
1
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
1
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
1
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
1
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
Automated pixe mmevel pavement crack detection on 3D asphalt surfaces with a recurrent neural network
1
2018
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
Pavement crack detection network based on pyramid structure and attention mechanism
1
2020
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
Feature pyramid and hierarchical boosting network for pavement crack detection
4
2020
... 众多学者基于语义分割地进行路面裂缝检测研究,不断提升裂缝检测精度及效率. 翁飘等[7 ] 提出改进的全卷积神经网络(fully convolutional networks, FCN),并基于自建的路面数据集对改进前后的网络分别进行测试,一定程度上提升了复杂环境下路面裂缝的检测精度. 李刚等[12 ] 提出改进轻量级全局卷积网络的路面裂缝图像分割模型,在公开路面裂缝数据集上对比测试并验证其精度. 陈泽斌等[13 ] 基于自建路面裂缝数据集,运用改进后的U-net模型实现对路面裂缝图像自动识别并验证其识别精度. 阙云等[14 ] 为了解决现有路面裂缝图像采集数量不足的问题,提出以改进型U-Net网络模型为基础的路面裂缝语义分割算法. Zhang 等[15 ] 基于提出 CrackNet-R递归神经网络(recurrent neural network, RNN)算法,并采用该算法对测试沥青路面裂缝图像进行识别. Xiang等[16 ] 提出新的路面裂缝检测方法,是基于端到端(end-to-end)、可训练的深度卷积神经网络,在公开数据集上进行训练和测试,结果表明它可以准确识别裂纹特征. Yang等[17 ] 提出用于路面裂缝检测的特征金字塔分层增强网络,运用特征金字塔融合上下文信息,可以准确识别裂缝. ...
... 选用公开沥青裂缝分割数据集 CRACK500 和 GAPS384[17 ,26 ] ,裂缝分别来自天普大学主校区沥青路面和德国沥青路面,数据集信息及示例如表2 和图1 所示. 表2 中N 为图片数量,R 为分辨率,Bit为位深度. 将原始图像及标签图划分成训练集、验证集和测试集. 如表3 所示. 由于2个数据集裂缝图像特点存在差异,为了保证测试的公平性,从2个数据集中分别挑选约60张共同作为试验测试集. ...
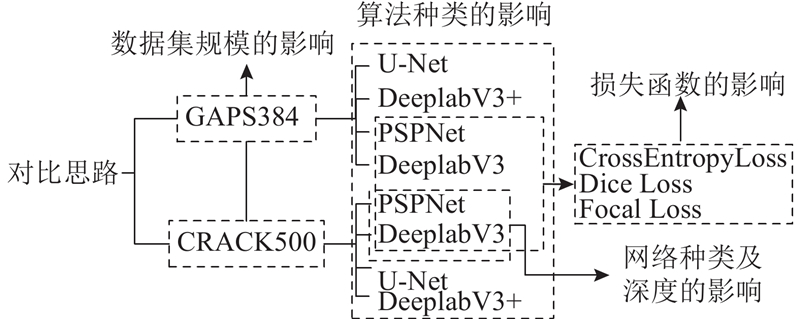
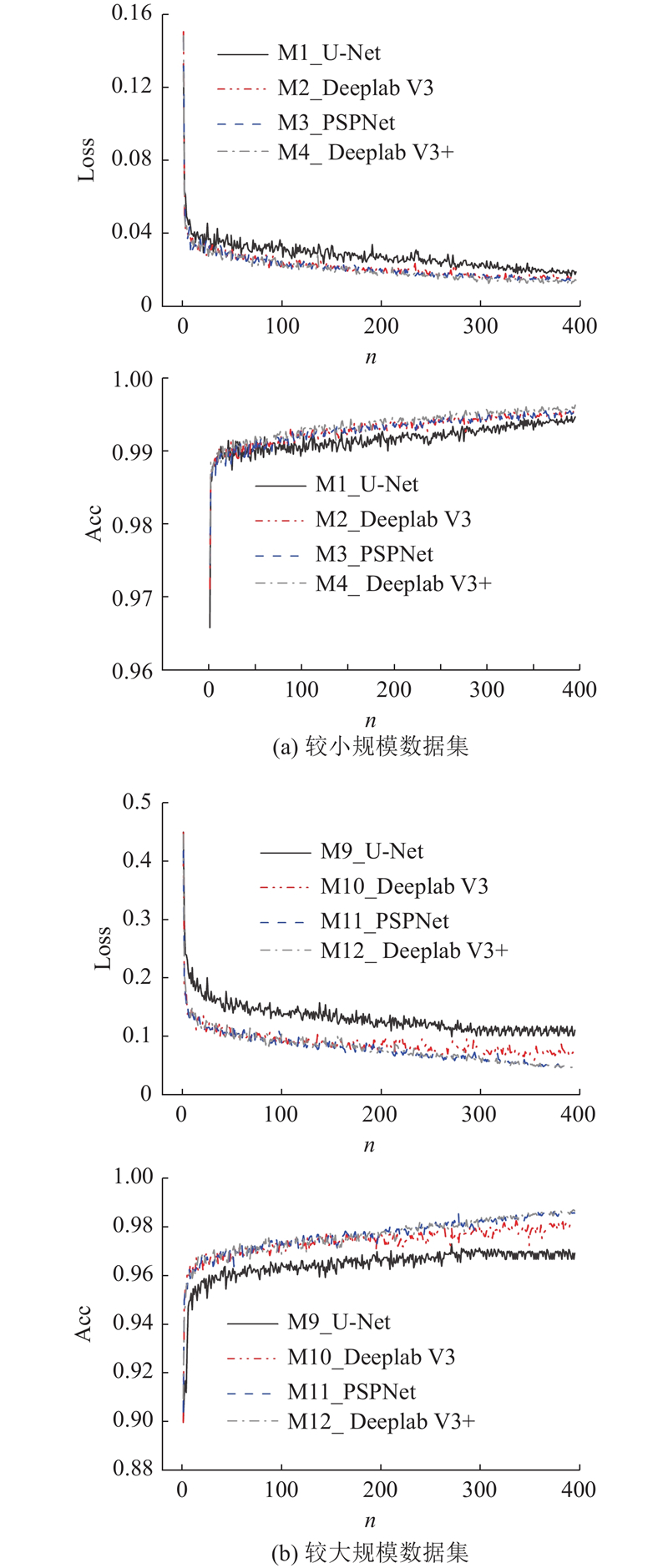
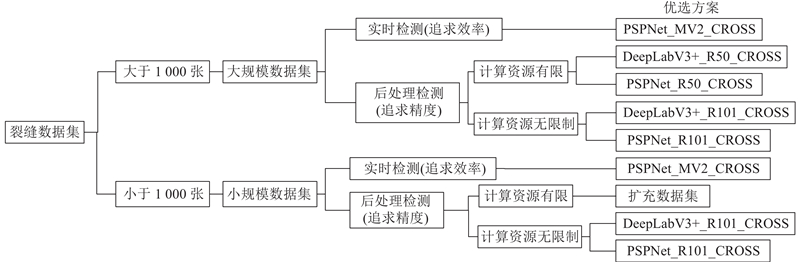
... 在训练结束后,各数据集基本信息如表5 所示. 表中加粗部分的模型为较小规模数据集. 由于分割数据集构建成本大,缺乏足够的数据量,而且不同研究所采用的数据集规模不一,需要考虑数据集规模对模型训练的影响. 将训练数据集大于1 000张的CRACK500[17 ] 作为较大规模数据集,小于1 000张的GAPS384[26 ] 作为较小规模数据集,通过分别训练及测试,考虑不同的训练因素(网络结构、损失函数),针对较大规模数据集及较小规模数据集分别提供优选方案及对应模型. ...
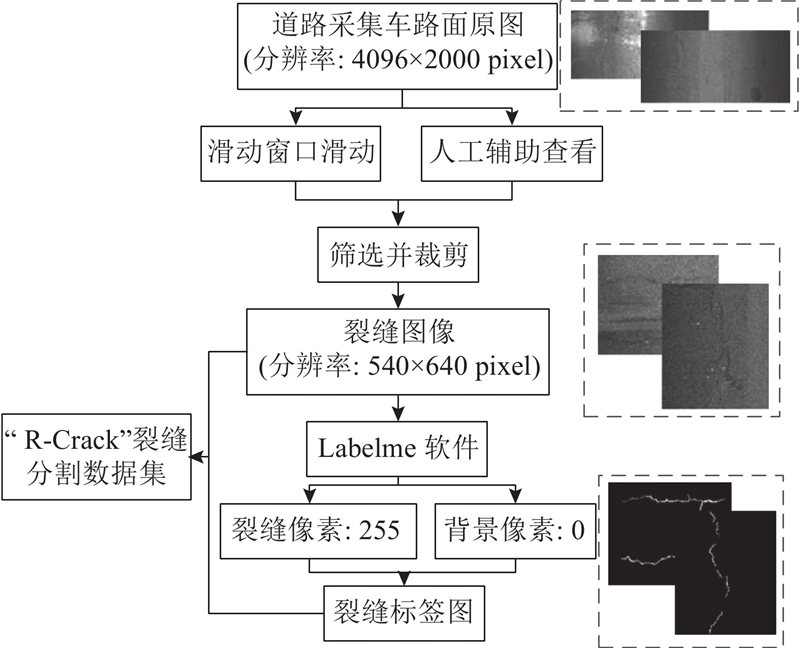
... 在语义分割模型的训练过程中,模型的训练质量与预测结果的准确率与所选数据集质量息息相关[23 ] . 公开的路面裂缝分割数据集如CRACK500、GAPS等[17 ,26 ] ,图像数量少,需要采用旋转、镜像等图像处理操作来增广数据集. 由于不同地区拍摄条件、路面环境不同,同样是沥青路面,但裂缝特征存在明显差异. 因此本文针对现有公开数据集不足的问题,结合北京六环高速公路的实际数据,制作沥青路面裂缝分割数据集R-Crack,数据集构建流程如图11 所示,收集共有路面采集车原始图像有4 479张,通过540 p×640 p(长宽分配根据实际裂缝形态确定)的滑动窗口滑动筛选并裁剪出形态不一、且包含不同特征物的裂缝,得到共 468 张清晰的裂缝图像. 通过图像标注软件Labelme制作人工标签,人工判断并选取较为准确的裂缝区域,对于裂缝的边缘像素,本着“疑有从无”的原则进行添补,得到更为精确的裂缝标签,保证检测精度. 将裂缝像素标记为255,背景像素标记为0,得到自制沥青路面裂缝数据集R-Crack,数据集标注结果如图12 所示. ...
Structural surface crack detection method based on computer vision technology
1
2018
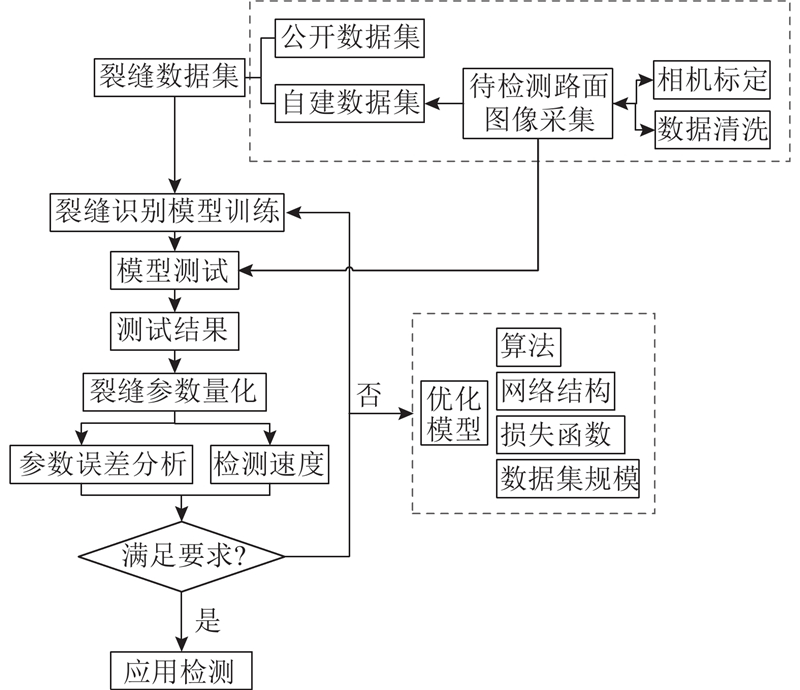
... 针对沥青路面裂缝检测的相关领域,仍存在以下问题:1)大多路面裂缝识别的研究并未区分具体路面场景,针对沥青路面研究及应用少,普通路面主要分为水泥混凝土、沥青路面,两者图像背景特征差别大,混合检测会影响自动识别结果的精度;基于语义分割的裂缝检测研究多分布在混凝土结构表面[18 -21 ] ,针对沥青路面场景下的应用研究较少. 2)缺乏公开沥青路面裂缝数据集. 训练卷积神经网络需要大量标签样本,分割数据集获取难度高,虽然已有学者开展沥青路面裂缝识别相关研究,但是公开数据集仍然较少,裂缝标签样本数据匮乏. 3)缺乏针对沥青路面裂缝智能识别及量化的整体解决方案. 对于裂缝自动识别的研究通常是基于文章中的特定数据集、网络结构开展,多数方法及模型尚未开源不便于实用,因此很难对不同研究进行复现,得到统一的性能评估. 基于裂缝提取结果,满足实际应用需求的裂缝参数自动量化研究开展较少. ...
Structural surface crack detection method based on computer vision technology
1
2018
... 针对沥青路面裂缝检测的相关领域,仍存在以下问题:1)大多路面裂缝识别的研究并未区分具体路面场景,针对沥青路面研究及应用少,普通路面主要分为水泥混凝土、沥青路面,两者图像背景特征差别大,混合检测会影响自动识别结果的精度;基于语义分割的裂缝检测研究多分布在混凝土结构表面[18 -21 ] ,针对沥青路面场景下的应用研究较少. 2)缺乏公开沥青路面裂缝数据集. 训练卷积神经网络需要大量标签样本,分割数据集获取难度高,虽然已有学者开展沥青路面裂缝识别相关研究,但是公开数据集仍然较少,裂缝标签样本数据匮乏. 3)缺乏针对沥青路面裂缝智能识别及量化的整体解决方案. 对于裂缝自动识别的研究通常是基于文章中的特定数据集、网络结构开展,多数方法及模型尚未开源不便于实用,因此很难对不同研究进行复现,得到统一的性能评估. 基于裂缝提取结果,满足实际应用需求的裂缝参数自动量化研究开展较少. ...
Research on grid optimized crack detection model based on deep learning
0
2020
Research on grid optimized crack detection model based on deep learning
0
2020
Method for detecting cracks in concrete structures based on deep learning and UAV
1
2021
... 针对沥青路面裂缝检测的相关领域,仍存在以下问题:1)大多路面裂缝识别的研究并未区分具体路面场景,针对沥青路面研究及应用少,普通路面主要分为水泥混凝土、沥青路面,两者图像背景特征差别大,混合检测会影响自动识别结果的精度;基于语义分割的裂缝检测研究多分布在混凝土结构表面[18 -21 ] ,针对沥青路面场景下的应用研究较少. 2)缺乏公开沥青路面裂缝数据集. 训练卷积神经网络需要大量标签样本,分割数据集获取难度高,虽然已有学者开展沥青路面裂缝识别相关研究,但是公开数据集仍然较少,裂缝标签样本数据匮乏. 3)缺乏针对沥青路面裂缝智能识别及量化的整体解决方案. 对于裂缝自动识别的研究通常是基于文章中的特定数据集、网络结构开展,多数方法及模型尚未开源不便于实用,因此很难对不同研究进行复现,得到统一的性能评估. 基于裂缝提取结果,满足实际应用需求的裂缝参数自动量化研究开展较少. ...
Method for detecting cracks in concrete structures based on deep learning and UAV
1
2021
... 针对沥青路面裂缝检测的相关领域,仍存在以下问题:1)大多路面裂缝识别的研究并未区分具体路面场景,针对沥青路面研究及应用少,普通路面主要分为水泥混凝土、沥青路面,两者图像背景特征差别大,混合检测会影响自动识别结果的精度;基于语义分割的裂缝检测研究多分布在混凝土结构表面[18 -21 ] ,针对沥青路面场景下的应用研究较少. 2)缺乏公开沥青路面裂缝数据集. 训练卷积神经网络需要大量标签样本,分割数据集获取难度高,虽然已有学者开展沥青路面裂缝识别相关研究,但是公开数据集仍然较少,裂缝标签样本数据匮乏. 3)缺乏针对沥青路面裂缝智能识别及量化的整体解决方案. 对于裂缝自动识别的研究通常是基于文章中的特定数据集、网络结构开展,多数方法及模型尚未开源不便于实用,因此很难对不同研究进行复现,得到统一的性能评估. 基于裂缝提取结果,满足实际应用需求的裂缝参数自动量化研究开展较少. ...
An efficient approach to semantic segmentation
1
2011
... Csurka等[22 ] 提出语义分割(image semantic segmentation,ISS),目标是图像中的每个像素进行分类,并将其标记为不同的语义类别. 与传统的图像分割相比,ISS的特点是为图像中的目标加上一定的语义信息[11 ] . 在沥青路面检测中,对裂缝目标进行像素级的分割,有利于裂缝参数(长度、宽度)的计算. 常用语义分割算法的优势及存在的问题总结如表1 所示. ...
The pascal visual object classes challenge: a retrospective
2
2015
... 对语义分割算法的统一性能评价仅在包含多类目标的公开数据集(例如PASCAL VOC2012[23 ] 、COCO[24 ] 、Cityscapes[25 ] )上开展过. 在对裂缝自动识别的众多研究中,模型的评估通常是基于特定的数据集、网络结构等开展,并且多数方法及模型尚未开源,不便于实用,因此很难对不同研究进行复现,从而得到统一的性能评估. 基于相同的实验室条件,综合考虑数据集规模、网络结构、损失函数种类的影响,开展针对沥青路面裂缝,基于开源语义分割方法的对比研究,得到一套兼顾效率与精度的沥青路面裂缝自动识别模型的优选方案. ...
... 在语义分割模型的训练过程中,模型的训练质量与预测结果的准确率与所选数据集质量息息相关[23 ] . 公开的路面裂缝分割数据集如CRACK500、GAPS等[17 ,26 ] ,图像数量少,需要采用旋转、镜像等图像处理操作来增广数据集. 由于不同地区拍摄条件、路面环境不同,同样是沥青路面,但裂缝特征存在明显差异. 因此本文针对现有公开数据集不足的问题,结合北京六环高速公路的实际数据,制作沥青路面裂缝分割数据集R-Crack,数据集构建流程如图11 所示,收集共有路面采集车原始图像有4 479张,通过540 p×640 p(长宽分配根据实际裂缝形态确定)的滑动窗口滑动筛选并裁剪出形态不一、且包含不同特征物的裂缝,得到共 468 张清晰的裂缝图像. 通过图像标注软件Labelme制作人工标签,人工判断并选取较为准确的裂缝区域,对于裂缝的边缘像素,本着“疑有从无”的原则进行添补,得到更为精确的裂缝标签,保证检测精度. 将裂缝像素标记为255,背景像素标记为0,得到自制沥青路面裂缝数据集R-Crack,数据集标注结果如图12 所示. ...
1
... 对语义分割算法的统一性能评价仅在包含多类目标的公开数据集(例如PASCAL VOC2012[23 ] 、COCO[24 ] 、Cityscapes[25 ] )上开展过. 在对裂缝自动识别的众多研究中,模型的评估通常是基于特定的数据集、网络结构等开展,并且多数方法及模型尚未开源,不便于实用,因此很难对不同研究进行复现,从而得到统一的性能评估. 基于相同的实验室条件,综合考虑数据集规模、网络结构、损失函数种类的影响,开展针对沥青路面裂缝,基于开源语义分割方法的对比研究,得到一套兼顾效率与精度的沥青路面裂缝自动识别模型的优选方案. ...
1
... 对语义分割算法的统一性能评价仅在包含多类目标的公开数据集(例如PASCAL VOC2012[23 ] 、COCO[24 ] 、Cityscapes[25 ] )上开展过. 在对裂缝自动识别的众多研究中,模型的评估通常是基于特定的数据集、网络结构等开展,并且多数方法及模型尚未开源,不便于实用,因此很难对不同研究进行复现,从而得到统一的性能评估. 基于相同的实验室条件,综合考虑数据集规模、网络结构、损失函数种类的影响,开展针对沥青路面裂缝,基于开源语义分割方法的对比研究,得到一套兼顾效率与精度的沥青路面裂缝自动识别模型的优选方案. ...
4
... 选用公开沥青裂缝分割数据集 CRACK500 和 GAPS384[17 ,26 ] ,裂缝分别来自天普大学主校区沥青路面和德国沥青路面,数据集信息及示例如表2 和图1 所示. 表2 中N 为图片数量,R 为分辨率,Bit为位深度. 将原始图像及标签图划分成训练集、验证集和测试集. 如表3 所示. 由于2个数据集裂缝图像特点存在差异,为了保证测试的公平性,从2个数据集中分别挑选约60张共同作为试验测试集. ...
... Basic information of training crack datasets
Tab.2 数据集名称 N R Bit CRACK500[26 ] 2 244 640 × 360 24 GAPS384[27 ] 509 540 × 640 24
图 1 训练裂缝数据集的示例 ...
... 在训练结束后,各数据集基本信息如表5 所示. 表中加粗部分的模型为较小规模数据集. 由于分割数据集构建成本大,缺乏足够的数据量,而且不同研究所采用的数据集规模不一,需要考虑数据集规模对模型训练的影响. 将训练数据集大于1 000张的CRACK500[17 ] 作为较大规模数据集,小于1 000张的GAPS384[26 ] 作为较小规模数据集,通过分别训练及测试,考虑不同的训练因素(网络结构、损失函数),针对较大规模数据集及较小规模数据集分别提供优选方案及对应模型. ...
... 在语义分割模型的训练过程中,模型的训练质量与预测结果的准确率与所选数据集质量息息相关[23 ] . 公开的路面裂缝分割数据集如CRACK500、GAPS等[17 ,26 ] ,图像数量少,需要采用旋转、镜像等图像处理操作来增广数据集. 由于不同地区拍摄条件、路面环境不同,同样是沥青路面,但裂缝特征存在明显差异. 因此本文针对现有公开数据集不足的问题,结合北京六环高速公路的实际数据,制作沥青路面裂缝分割数据集R-Crack,数据集构建流程如图11 所示,收集共有路面采集车原始图像有4 479张,通过540 p×640 p(长宽分配根据实际裂缝形态确定)的滑动窗口滑动筛选并裁剪出形态不一、且包含不同特征物的裂缝,得到共 468 张清晰的裂缝图像. 通过图像标注软件Labelme制作人工标签,人工判断并选取较为准确的裂缝区域,对于裂缝的边缘像素,本着“疑有从无”的原则进行添补,得到更为精确的裂缝标签,保证检测精度. 将裂缝像素标记为255,背景像素标记为0,得到自制沥青路面裂缝数据集R-Crack,数据集标注结果如图12 所示. ...
Optimization methods for large-scale machine learning
2
2018
... Basic information of training crack datasets
Tab.2 数据集名称 N R Bit CRACK500[26 ] 2 244 640 × 360 24 GAPS384[27 ] 509 540 × 640 24
图 1 训练裂缝数据集的示例 ...
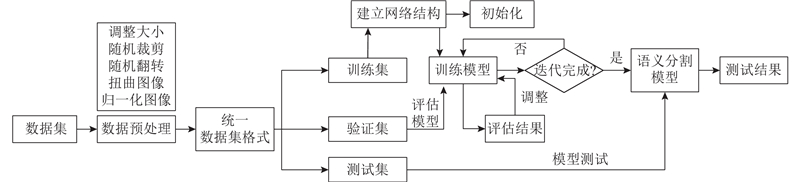
... 模型训练的硬件设备是基于实验室的Linux操作系统,采用的是PyTorch-1.9.1深度学习框架、CUDA10.2和python3.8的运行环境,在NVIDIA Tesla V100-SXM2-16GB上完成网络的训练与测试. 优化算法选择随机梯度下降法[27 ] (stochastic gradient descent, SGD)来最小化目标函数D ,批量大小(batch-size)设置为16,迭代训练共400次. 在训练过程中,学习率根据训练情况动态调整,采用Poly指数变换策略[28 ] ,使得学习率不断衰减. 在本试验中,初始学习率为0.001,控制曲线形状的权重值W 为0.9. ...
基于DeepLabV3+与超像素优化的语义分割
1
2019
... 模型训练的硬件设备是基于实验室的Linux操作系统,采用的是PyTorch-1.9.1深度学习框架、CUDA10.2和python3.8的运行环境,在NVIDIA Tesla V100-SXM2-16GB上完成网络的训练与测试. 优化算法选择随机梯度下降法[27 ] (stochastic gradient descent, SGD)来最小化目标函数D ,批量大小(batch-size)设置为16,迭代训练共400次. 在训练过程中,学习率根据训练情况动态调整,采用Poly指数变换策略[28 ] ,使得学习率不断衰减. 在本试验中,初始学习率为0.001,控制曲线形状的权重值W 为0.9. ...
基于DeepLabV3+与超像素优化的语义分割
1
2019
... 模型训练的硬件设备是基于实验室的Linux操作系统,采用的是PyTorch-1.9.1深度学习框架、CUDA10.2和python3.8的运行环境,在NVIDIA Tesla V100-SXM2-16GB上完成网络的训练与测试. 优化算法选择随机梯度下降法[27 ] (stochastic gradient descent, SGD)来最小化目标函数D ,批量大小(batch-size)设置为16,迭代训练共400次. 在训练过程中,学习率根据训练情况动态调整,采用Poly指数变换策略[28 ] ,使得学习率不断衰减. 在本试验中,初始学习率为0.001,控制曲线形状的权重值W 为0.9. ...
基于改进U-Net网络与联合损失函数的海南自然保护区高分辨率遥感变化检测模型
2
2021
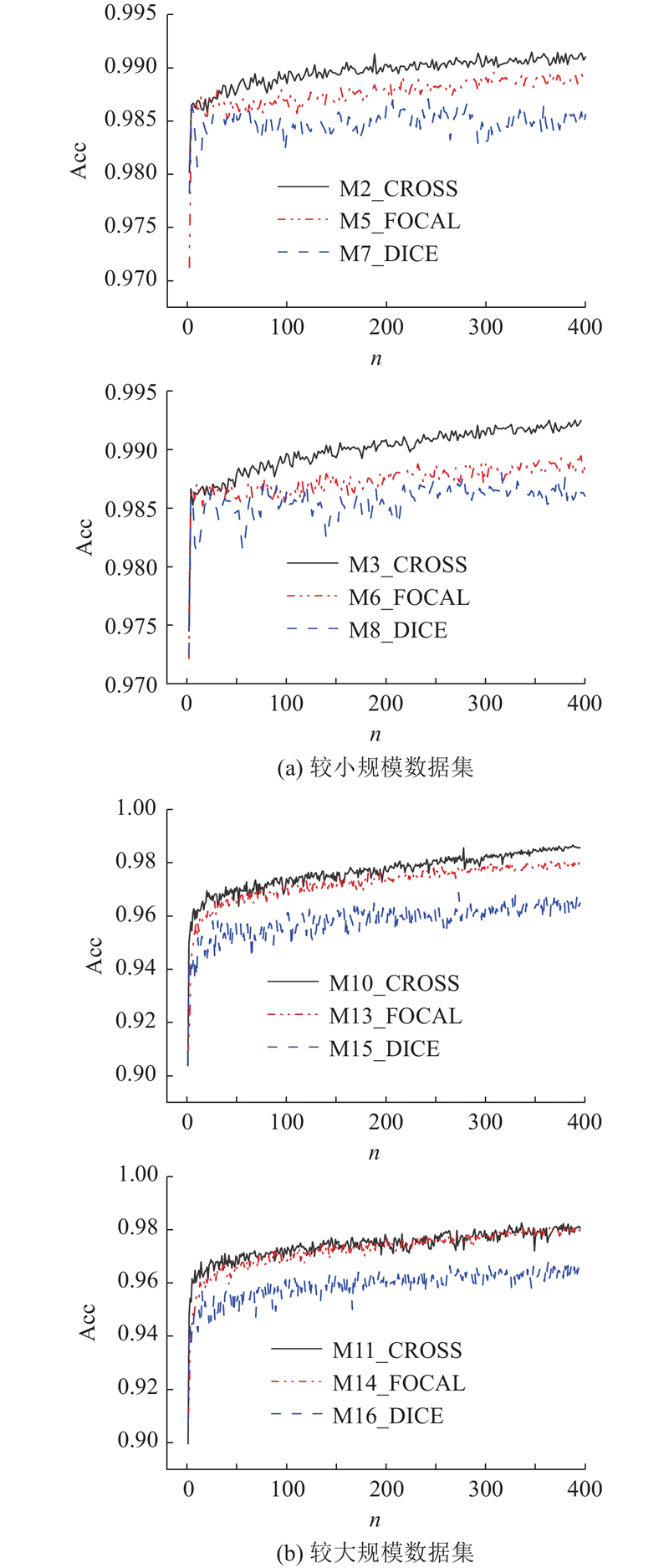
... 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果. 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
... [29 -30 ]分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
基于改进U-Net网络与联合损失函数的海南自然保护区高分辨率遥感变化检测模型
2
2021
... 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果. 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
... [29 -30 ]分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
Focal loss for dense object detection
2
2020
... 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果. 选用交叉熵(cross-entropy loss)、骰子(dice loss)、Focal损失函数(focal loss)[29 -30 ] 分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
... -30 ]分别作为模型训练的损失函数,对比训练及测试结果.交叉熵损失函数是一种主要用于度量2个概率分布间的损失函数;骰子损失函数由Dice系数衍生而来,是一种区域相关的损失函数;Focal损失函数是一种通过对交叉熵损失增加权重,在一定程度上解决正负样本分布不均衡问题的损失函数. ...
1
... 裂缝检测任务首要满足的应是模型识别精度,选择3.2节中精度更高的交叉熵损失函数作为对不同网络深度及种类影响研究中的不变量,由于较小规模数据集训练所得的模型识别精度低,因此不再进一步开展不同网络深度及种类的影响研究. ResNet[31 ] 是深度学习领域十分常用的特征提取网络,由何凯明团队于2015年提出. 它主要通过构建残差块解决了堆叠式的传统深层网络带来的模型识别准确度“退化”问题. 在裂缝自动化检测的实际应用中,大多数会使用移动或者嵌入式设备,因此对轻量级网络的研究十分必要. Google团队在2018年提出深度可分离卷积网络MobileNet V2[32 ] ,引入线性瓶颈 (linear bottleneck)和逆残差 (inverted residual)来提高网络的表征能力,在计算量与内存占用上远小于标准卷积. ...
2
... 裂缝检测任务首要满足的应是模型识别精度,选择3.2节中精度更高的交叉熵损失函数作为对不同网络深度及种类影响研究中的不变量,由于较小规模数据集训练所得的模型识别精度低,因此不再进一步开展不同网络深度及种类的影响研究. ResNet[31 ] 是深度学习领域十分常用的特征提取网络,由何凯明团队于2015年提出. 它主要通过构建残差块解决了堆叠式的传统深层网络带来的模型识别准确度“退化”问题. 在裂缝自动化检测的实际应用中,大多数会使用移动或者嵌入式设备,因此对轻量级网络的研究十分必要. Google团队在2018年提出深度可分离卷积网络MobileNet V2[32 ] ,引入线性瓶颈 (linear bottleneck)和逆残差 (inverted residual)来提高网络的表征能力,在计算量与内存占用上远小于标准卷积. ...
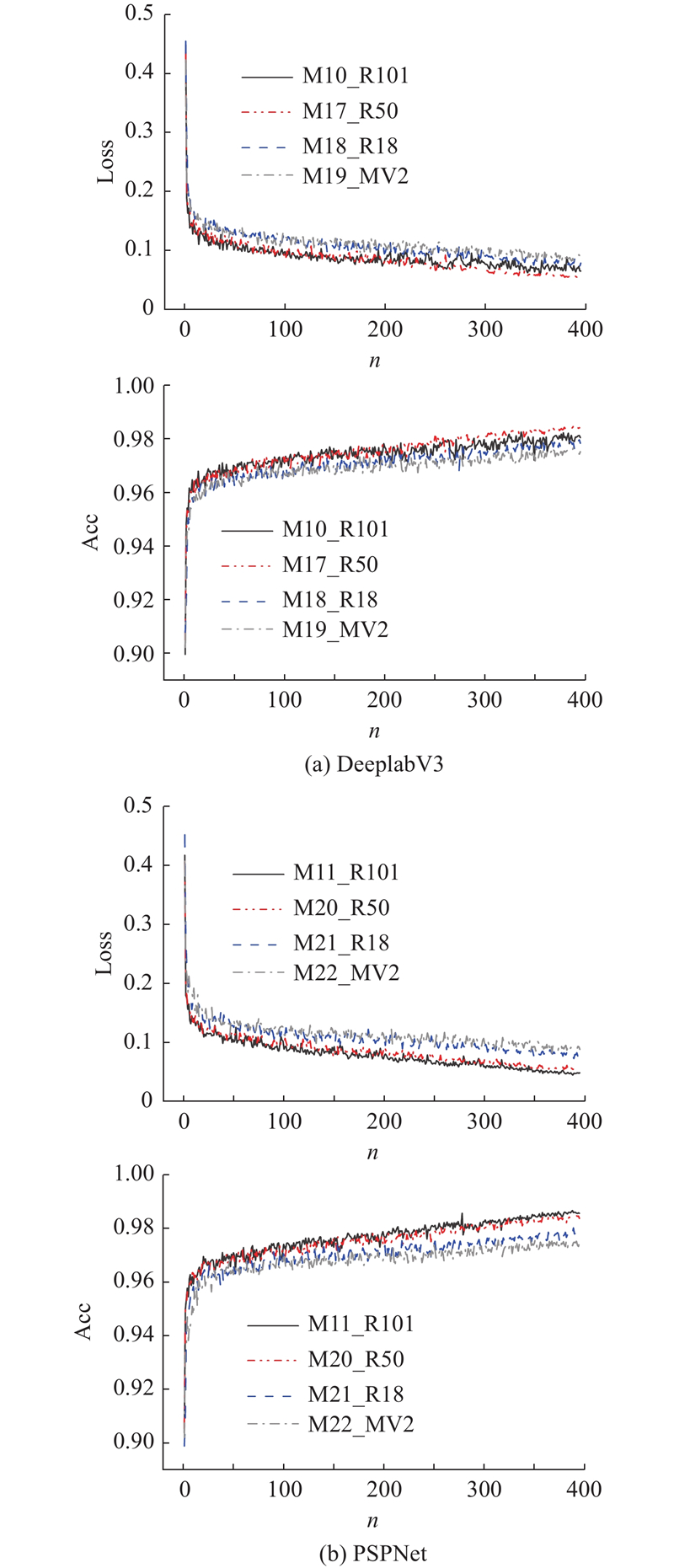
... 选用ResNet101、ResNet50、ResNet18以及更轻量化的MobileNetV2[32 -33 ] 4种网络结构开展对比研究,训练损失函数、准确率曲线如图8 所示,模型测试结果如表8 所示. 在相同的试验条件下,运用不同种类和深度的网络进行模型训练,获得不同的训练效果. 随迭代次数增加,模型18、21分别与模型10、17和模型11、20相比,训练准确率低,损失函数值高,更深的特征提取网络(ResNet50、ResNet101)能够让模型获取更好的训练效果. 原因是网络深度的增加能够增加网络的非线性映射次数,使得网络能够提取具有更好判决信息的特征,从而提升模型性能. 简单地增加网络的深度并不会自动提高模型的精度,例如模型10、17和模型11、20,分别采用50层的ResNet网络和101层ResNet网络,但准确率与损失函数值接近,训练效果相差不大. 因此在数据集数量小且条件有限的情况下,运用浅层网络例如ResNet50、ResNet18,也能达到较好的训练效果. 模型19、22与其他模型相比,训练速度最快,内存占用少. 此外,在对测试集图像的推理中,分别达到了3.50和4.56帧/s速度,远快于其他模型. 表明采用轻量级的深度可分离卷积网络MobileNetV2训练得到的模型,在损失一定精度的同时,训练时间、检测速度以及内存占用等方面均占有较大优势,能够满足实时检测的场景需求. ...
复杂场景下农村道路裂缝分割方法
1
2022
... 选用ResNet101、ResNet50、ResNet18以及更轻量化的MobileNetV2[32 -33 ] 4种网络结构开展对比研究,训练损失函数、准确率曲线如图8 所示,模型测试结果如表8 所示. 在相同的试验条件下,运用不同种类和深度的网络进行模型训练,获得不同的训练效果. 随迭代次数增加,模型18、21分别与模型10、17和模型11、20相比,训练准确率低,损失函数值高,更深的特征提取网络(ResNet50、ResNet101)能够让模型获取更好的训练效果. 原因是网络深度的增加能够增加网络的非线性映射次数,使得网络能够提取具有更好判决信息的特征,从而提升模型性能. 简单地增加网络的深度并不会自动提高模型的精度,例如模型10、17和模型11、20,分别采用50层的ResNet网络和101层ResNet网络,但准确率与损失函数值接近,训练效果相差不大. 因此在数据集数量小且条件有限的情况下,运用浅层网络例如ResNet50、ResNet18,也能达到较好的训练效果. 模型19、22与其他模型相比,训练速度最快,内存占用少. 此外,在对测试集图像的推理中,分别达到了3.50和4.56帧/s速度,远快于其他模型. 表明采用轻量级的深度可分离卷积网络MobileNetV2训练得到的模型,在损失一定精度的同时,训练时间、检测速度以及内存占用等方面均占有较大优势,能够满足实时检测的场景需求. ...
复杂场景下农村道路裂缝分割方法
1
2022
... 选用ResNet101、ResNet50、ResNet18以及更轻量化的MobileNetV2[32 -33 ] 4种网络结构开展对比研究,训练损失函数、准确率曲线如图8 所示,模型测试结果如表8 所示. 在相同的试验条件下,运用不同种类和深度的网络进行模型训练,获得不同的训练效果. 随迭代次数增加,模型18、21分别与模型10、17和模型11、20相比,训练准确率低,损失函数值高,更深的特征提取网络(ResNet50、ResNet101)能够让模型获取更好的训练效果. 原因是网络深度的增加能够增加网络的非线性映射次数,使得网络能够提取具有更好判决信息的特征,从而提升模型性能. 简单地增加网络的深度并不会自动提高模型的精度,例如模型10、17和模型11、20,分别采用50层的ResNet网络和101层ResNet网络,但准确率与损失函数值接近,训练效果相差不大. 因此在数据集数量小且条件有限的情况下,运用浅层网络例如ResNet50、ResNet18,也能达到较好的训练效果. 模型19、22与其他模型相比,训练速度最快,内存占用少. 此外,在对测试集图像的推理中,分别达到了3.50和4.56帧/s速度,远快于其他模型. 表明采用轻量级的深度可分离卷积网络MobileNetV2训练得到的模型,在损失一定精度的同时,训练时间、检测速度以及内存占用等方面均占有较大优势,能够满足实时检测的场景需求. ...
1
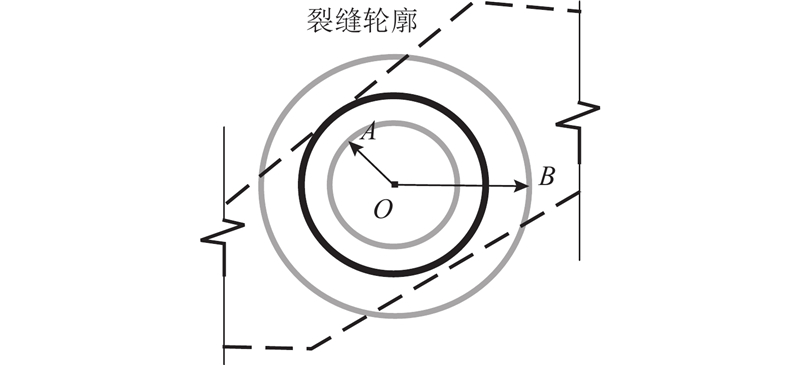
... 采用Zhang-Suen迭代算法[34 ] 得到裂缝中轴骨架如图13 (a)所示,将连通区域细化成像素的宽度如图13 (b)所示,有利于进行裂缝参数的具体量化. ...
1
... 采用Zhang-Suen迭代算法[34 ] 得到裂缝中轴骨架如图13 (a)所示,将连通区域细化成像素的宽度如图13 (b)所示,有利于进行裂缝参数的具体量化. ...
1
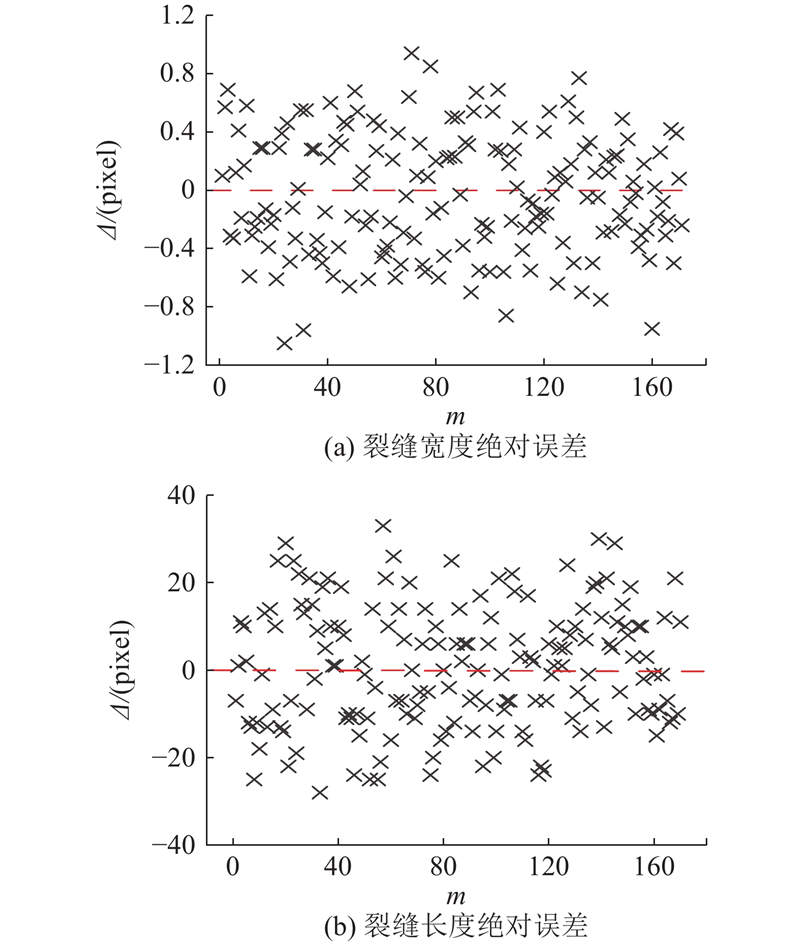
... 裂缝长度的计算参考文献[35 ]中的像素统计法,对于局部曲率大、反复折叠的裂缝,利用骨架线的像素总和计算裂缝长度,要比利用骨架线上某几个点之间的距离之和计算更为准确. ...
1
... 裂缝长度的计算参考文献[35 ]中的像素统计法,对于局部曲率大、反复折叠的裂缝,利用骨架线的像素总和计算裂缝长度,要比利用骨架线上某几个点之间的距离之和计算更为准确. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}