

迁移学习可以用来改善机器学习领域中跨域任务上的模型性能[1],当目标域标签样本较少且质量不高时,可以通过含有大量标签数据的源域作为辅助信息去训练泛化能力较强的分类器. 多数关于迁移学习的研究集中在同构场景中(源域和目标域数据分布不同但特征空间相同),不同领域数据具有不同特征空间的研究鲜见,然而不同设备数据的编码方式和标识存在差异的情况在现实应用程序中经常涉及.
有研究者提出采用异构域适应[2–5]对不同的特征空间和数据分布的领域进行知识迁移. 异构域自适应方法以目标域伪标签来帮助学习潜在子空间中的判别特征表示,提高了分类模型的准确性. 如异构领域适应中的跨域标志学习(learning cross-domain landmarks for heterogeneous domain adaptation, CDLS)[6]通过匹配跨域数据分布和减少域差异获得适当的消除域发散的特征子空间,基于广义联合分布自适应的异构跨域数据识别(recognizing heterogeneous cross-domain data via generalized joint distribution adaptation, G-JDA)[7]通过联合匹配边缘分布和条件分布以适应和分类. 由于目标域无标签样本不能得到高置信度的伪标签,上述方法容易受到误差累积的影响,造成分布偏移增加,甚至会导致负迁移. 为了避免传统硬标签分配引入虚假伪标签,基于柔性迁移网络的单源异构迁移学习方法(heterogeneous domain adaptation via soft transfer network, STN)[8]在类对齐过程中采用软标签策略. 虽然这些异构域自适应方法具有较好的适应性、泛化能力、鲁棒性和迁移效果,但是它们忽略类别预测中语义属性的重要性,而且直接利用分类器预测得到的伪标签具有不确定性,这将降低模型分类性能.
本研究提出基于伪标签细化和语义对齐的异构域自适应方法. 该方法包括3个部分:非线性特征编码器、领域鉴别器、分类器. 非线性特征编码器将用于特征变换,通过伪标签细化方法选择目标域无标签样本并赋予伪标签,被选中的样本将参与训练分类器;在语义预测空间中构造域鉴别器,充分挖掘数据的内在信息,提高模型的泛化性. 针对目标域大量无标签样本伪标签置信度较低的问题,本研究提出的具有空间相似性的伪标签细化方法将有效利用源域和目标域之间的特性和判别信息.
1. 相关工作
1.1. 半监督异构域自适应
半监督异构域自适应方法在进行异构域自适应时,目标域有少量的标记样本可用. 利用流形对齐进行异构域自适应(heterogeneous domain adaptation using manifold alignment, DAMA)[9]实现的域自适应在自适应过程中保留流形结构和标签信息;利用增强特征进行异构域自适应学习(learning with augmented features for heterogeneous domain adaptation, HFA)[10]将转换后的源特征和目标特征与原始特征和零进行参数化,并通过训练SVM将结构风险最小化. Li等[11]在训练过程中利用未标记的目标数据,将HFA扩展到半监督版本(learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation, SHFA). 域不变图像表示的有效学习(efficient learning of domain-invariant image representations, MMDT)[12]通过非对称类别无关变换学习域不变表示. 针对多个类的异构域自适应(heterogeneous domain adaptation for multiple classes, SHFR)[13]将特征映射的学习转化为压缩感知问题. 异构域自适应的半监督最优传输(semi-supervised optimal transport for heterogeneous domain adaptation, SGW)[14]学习从源到目标域特征的最优传输. 转移神经树的异构域自适应(transfer neural trees for heterogeneous domain adaptation, TNT)[15]解决特征映射和促进域自适应. 异构域自适应的同步语义对齐网络(simultaneous semantic alignment network for heterogeneous domain adaptation, SSAN)[16]利用目标域标记数据学习源域标签的语义知识. 标签引导的异构领域自适应(label-guided heterogeneous domain adaptation, LG)[17]通过增强少量标记目标域数据的应用将源域的相关知识用来解决目标域任务. 具有统计分布对齐和渐进式伪标签选择的异构域自适应(heterogeneous domain adaptation with statistical distribution alignment and progressive pseudo label selection, SDA-PPLS)[18]通过对目标域数据的伪标签细化来对齐类的条件分布.
1.2. 生成式对抗网络
生成式对抗网络GAN由2个模块构成:生成模块G和判别模块D. G接收随机的噪声z,通过z生成图片,记做 G(z). D判别图片x是否为真,它的输入为x,输出D(x)代表x为真实图片的概率. 在训练过程中,G的目标是生成与训练数据无法区分的数据,D的目标是正确地识别数据是来自训练数据还是由G生成. G和D构成动态的博弈过程. 在最理想的状态下,博弈的结果是G可以生成足以以假乱真的图片G(z),对于 D来说,它难以判定 G 生成的图片是否真实,即 D(G(z))=0.5.
当将GAN应用到语义预测空间时,由于存在源域和目标域,生成器的目的发生变化,不再是生成样本,而是扮演分类预测功能. 即在对样本进行类别预测时,使判别器无法区分样本来自哪个域. 通过不断优化语义预测空间中的对抗损失,可以将源域类别预测分布的相关知识迁移到目标域.
2. 基于伪标签细化和语义对齐的异构域自适应
将带有标签信息的源域数据表示为
如图1所示为本研究所提异构域自适应方法,使用神经网络构建2个非线性特征编码器:源编码器、目标编码器,利用源域数据训练具有监督分类损失的共享分类器. 如文献[11]所述,在训练过程中利用未标记的目标样本有助于解决异构域自适应(heterogeneous domain adaptation,HDA)问题,本研究考虑源数据和目标数据在公共特征子空间的相似性,构造空间相似性机制;通过达成共享分类器和空间相似性机制预测的一致性,为目标域未标记样本赋予伪标签. 为了减少虚假伪标签造成的偏差,受到类条件最大平均异(conditional maximum mean discrepancy,CMMD)的启发,本研究对源域和目标域每个类别的质心进行距离约束,引入自适应的系数来不断调整伪标签的重要程度. 考虑到同类的样本经过分类器输出后有相似的预测分布,将对抗性学习应用于语义预测空间,构造语义预测空间中的域鉴别器. 通过不断优化语义预测空间中的对抗损失,缩减领域之间的边缘分布差异,提高模型的分类精度. 为了更好利用目标域有标签样本,引用隐式语义[16]相关损失.
图 1
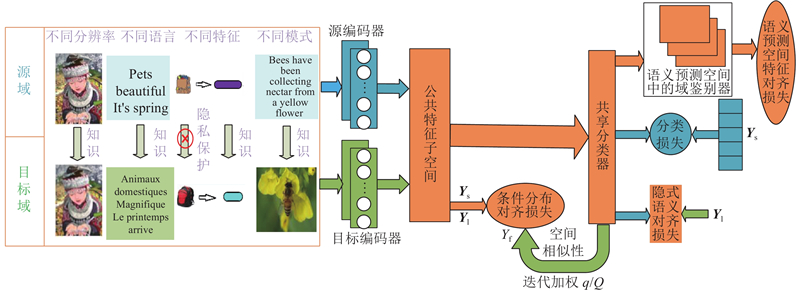
图 1 异构域自适应的网络结构图
Fig.1 Network structure diagram of heterogeneous domain adaptive
2.1. 分类器训练
利用源域数据训练具有监督分类损失
式中:
2.2. 条件分布对齐
异构域自适应研究使用源域和目标域所有类质心距离的总和来建模源域和目标域之间条件分布的差异,通过对齐源域和目标域的条件分布来学习未标记目标样本的判别表示. 目标域有大量的无标签样本,计算类质心时无法直接使用它们. 常规方法直接利用共享分类器预测的伪标签[6-7]计算目标域所有样本的类质心,由于错误分配的伪标签会导致类质心的计算出现错误,阻碍域自适应能力,产生负迁移. 为了减少伪标签的不确定性,提高伪标签的置信度,本研究设计空间相似性伪标签细化机制,为与特征空间中标签数据的类别质心呈现空间相似性的无标签样本分配伪标签. 带标签的源域中第k类的质心
式中:
式中:
图 2
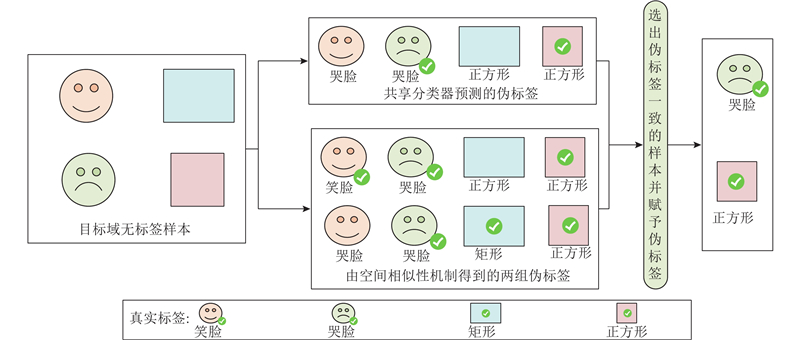
目标域中带标签的样本和得到伪标签样本的k类的质心
由式(7)得到质心组
通过最小化条件分布对齐损失,每个类别的质心将在域不变公共子特征空间中非常接近,使得源域和目标域的条件分布对齐.
2.3. 边缘分布对齐
2.3.1. 语义预测空间中的特征对齐
当域偏移严重时,通过式(8)约束仍然不足以达到期望的域自适应结果. 考虑到数据类别预测中包含的语义属性,将对抗性学习应用于语义预测空间,构造语义预测空间中的域鉴别器D,使其鉴别出样本经过分类器的类别预测后来源于哪个域,而分类器则使域鉴别器无法区分样本来自哪个域. 语义预测空间代表样本结构的信息,它们在不同的呈现方式中代表同一类. 语义预测空间中特征对齐的对抗性损失为
通过式(9)约束,目标域网络可以更好地对类边界周围的这些数据进行泛化,缩减领域之间的边缘分布差异,使模型获得显著的性能提升.
2.3.2. 隐式语义对齐
将源域第k个类别输出的概率的平均值视为第k个教师,表示为
利用有标签的目标数据,可以用软标签对目标域网络进行微调,以学习并将语义相关性从源域转移到目标域. 在学习到的软标签的监督下,进一步考虑标记目标数据的监督损失,计算式为
其中a的取值范围为[0, 1). 当源域样本预测准确率小于目标域标签样本预测准确率时,直接对有标签的目标样本进行监督训练:
2.4. 自适应权重因子
分类器
式中:Q为总共的迭代次数,q为当前迭代的索引,引入自适应权重因子后:
2.5. 总体损失函数
总体损失函数包括分类损失、条件分布对齐损失、隐式语义对齐损失和语义预测空间中的特征对齐损失. 总体损失函数的表达式为
其中超参数β、γ分别平衡了
3. 实验结果及分析
为了评估该方法在异构域自适应中的有效性,在常用的基准数据集上开展实验.
3.1. 数据集和实验细节
3.1.1. 文本到图像迁移任务
NUS-WIDE+ImageNet用于文本到图像的迁移任务,其中样本的特征类型和特征模式均不相同. NUS-WIDE包含从Flickr.com中抓取的269 648张图像的标签信息,ImageNet包含5 247个子集的3.20×106张图像. 按照文献[15]、[16]的设置,从2个数据集中选择8个公共类构建ImageNet+NUS-WIDE数据集,采用64维特征表示NUS-WIDE的标签,采用4 096维的 DeCAF6特征对图像数据进行表征. 在源域中,从NUS-WIDE中为每个类别各选择100个文本,作为带标签的数据. 在ImageNet中,为每个类别随机抽取3张图像作为带标签的目标数据,剩余的所有图像作为无标签的目标数据.
3.1.2. 图像到图像迁移任务
Office+Caltech-256 用于图像到图像的迁移任务. Office-31数据集包含来自Amazon、 Webcam和DSLR领域的一共4 652张图片,类别数为31. Caltech-256包括30 607张图像,类别数为256. 从2个数据集中选取10个重叠类构建,有4个领域分别标记为A、W、D、C. 考虑3种类型的特征表示:800维SURF特征、2 048维ResNet50特征,以及4 096维DeCAF6特征. 在源域中,所有图像都是带有标签的样本. 在目标域中,每类随机选择3张图像作为标记的目标样本,其余所有图像均设置为未标记的目标数据进行识别. 由于领域D的图像数量有限,只被作为目标域. 为了证明本研究所提方法的有效性,对模型性能分析如下. 1)同域跨异构特性迁移任务. 构造6个迁移任务:A→A、C→C、W→W,对源特征和目标特征分别采用2种设置,即SURF→DeCAF6和DeCAF6→SURF. 2)不同域跨异构特性迁移任务. 为了实现无偏评估, 对所有18个迁移任务:A→C、A→W、A→D、W→C、W→A、W→D、C→A、C→W、C→D均进行评估,对源特征和目标特征分别采用2种设置,即SURF→DeCAF6和SURF→ResNet50.
3.1.3. 文本到文本迁移任务
Multilingual Reuters Collection用于文本到文本的迁移任务,数据集共包含使用英语(English, E)、法语(French, F)、德语(German, G)、意大利语(Italian, I) 和西班牙语(Spanish, S)5种语言撰写的11 000多篇文章,类别总数为6. 将E、F、G和I作为源域,S作为目标域. 使用TF-IDF的词袋模型提取每篇文章的特征,该特征已经执行PCA降维. 在经过上述特征处理之后,来自于领域E、F、G、I和S的文章特征数分别为1 131、1 230、1 417、1 041和807. 对于源域,每个类别随机选择100篇文章作为标记样本. 对于目标域,随机选取10篇文章作为标记样本和500篇文章作为测试样本.
3.1.4. 实验设置
为了验证本研究所提方法的有效性,对模型性能进行如下分析. 1)与现有的主流方法进行分类精度对比分析. 在Office+Caltech-256 数据集中,从SURF→DeCAF6、SURF→ResNet50和DeCAF6→SURF这3个不同域跨异构特性与SVMt、NNt、MMDT[12]、G-JDA[7]、CDLS[6]、STN[8]、SSAN[16]、LG[17]和SDA-PPLS[18]等方法进行比较. 在ImageNet+NUS-WIDE数据集中,与 NNt、CDLS[6]、STN [8] 、SSAN[16]、LG[17]和SDA-PPLS[18]等方法进行比较. 在Multilingual Reuters Collection 数据集中,与SVMt、 NNt 、MMDT[12] 、SHFA[11]、 G-JDA[7]、CDLS[6]、 STN[8]、SSAN[16]、LG[17]和SDA-PPLS[18]等方法进行比较. 2)从各部分损失函数对模型的性能进行分析. 在Office+Caltech-256数据集中进行3组迁移任务,分别对条件分布对齐损失、迭代约束损失、空间相似性、隐式语义一致损失和语义预测空间中的特征对齐损失进行重点分析. 3)根据经验设置
3.2. 实验结果和性能对比分析
3.2.1. 分类精度对比分析
如表1所示为不同异构域自适应方法在 ImageNet+NUS-WIDE数据集上进行的文本到图像迁移,其中Acc为分类精度. 可以看出:与最佳监督方法NNt相比,本研究所提方法的精度提高了12.86个百分点. 本研究所提方法也在一定程度上优于表现最好的基线SSAN. 由于文本与图像的迁移任务存在异质性,即使SSAN考虑类之间的语义相关性,仍然不足以避免错误伪标签的负影响,为此须同时提高伪标签的置信度和语义预测空间中类之间的语义相关性.
表 1 不同方法在 ImageNet+NUS-WIDE数据集上进行文本到图像异构迁移的分类结果
Tab.1
| 方法 | Acc% | 方法 | Acc% | |
| NNt | 67.68 | LG | 77.54 | |
| CDLS | 70.96 | SDA-PPLS | 76.22 | |
| STN | 78.46 | 本研究 | 80.54 | |
| SSAN | 80.22 | — | — |
在图像到图像的迁移任务实验中,如表2所示为不同异构域自适应方法在同域跨特征的迁移任务的分类结果,表3、4分别为现有主流方法在跨域和浅层特征(SURF)和不同深度特征(DeCAF6和ResNet50)之间的迁移任务的分类结果. 其中AccSD为SURF→DeCAF6情况下的分类精度,AccDS为DeCAF6→SURF情况下的分类精度. 由表2~4可知,本研究所提方法在所有任务上一致地表现出最好的分类准确率. 本研究所提方法在跨域和跨特征的迁移任务中平均分类准确率为94.98%,相较于监督学习方法 NNt ,提高了6.29个百分点,此结果验证了本研究所提方法的有效性. 分析对比方法的性能不及本研究所提方法的性能的原因,1)MMDT忽略分布对齐约束. 2)CDLS 、G-JDA 和LG均直接采用目标域无标签样本的伪标签来对齐领域之间的条件分布,未考虑样本之间的空间相似度,使得到的伪标签置信度不高,可能造成有限的性能提升,甚至导致负迁移的发生. 3)SGW 在对齐源域和目标域之间的条件分布时没有利用目标域无标签样本的信息. 4)TNT 没有最小化领域之间分布的差异. 5)STN的性能超越所有使用线性特征变换的单源异构迁移学习方法,但是STN未考虑源域和目标域的语义一致性. 6)SSAN在目标域无标签样本赋予伪标签时仅考虑几何性未考虑空间相似性,且仅考虑特征语义一致性未考虑语义预测空间中的语义一致性. 7)SDA-PPLS考虑伪标签的置信度,却忽略语义预测空间中的语义一致性.
表 2 不同方法在 Office+Caltech-256数据集上进行同域跨特征迁移的分类结果
Tab.2
| 方法 | | | |||||||
| A→A | C→C | W→W | 平均值 | A→A | C→C | W→W | 平均值 | ||
| SVMt | 88.66 | 77.31 | 89.32 | 85.10 | 43.03 | 30.15 | 55.28 | 42.82 | |
| NNt | 90.00 | 79.56 | 91.42 | 86.99 | 42.82 | 31.33 | 60.87 | 45.01 | |
| MMDT | 89.30 | 80.30 | 87.30 | 85.63 | 40.50 | 30.60 | 59.10 | 43.40 | |
| G-JDA | 92.30 | 86.70 | 89.40 | 89.47 | 50.30 | 33.70 | 63.80 | 49.27 | |
| CDLS | 91.70 | 81.80 | 95.20 | 89.57 | 46.40 | 31.80 | 63.10 | 47.10 | |
| STN | 92.19 | 82.92 | 95.43 | 90.18 | 47.62 | 30.83 | 64.71 | 47.72 | |
| SSAN | 92.45 | 87.01 | 96.66 | 92.04 | 52.91 | 37.24 | 69.81 | 53.32 | |
| LG | 92.36 | 84.15 | 96.04 | 90.85 | 44.70 | 31.20 | 63.10 | 46.33 | |
| SDA-PPLS | 92.85 | 87.34 | 96.31 | 92.17 | 54.88 | 33.18 | 71.72 | 53.26 | |
| 本研究 | 93.70 | 89.03 | 97.29 | 93.34 | 54.40 | 39.09 | 72.83 | 55.44 | |
表 3 不同方法在 Office+Caltech-256数据集上进行异域跨特征迁移的分类结果(SURF→DeCAF6)
Tab.3
| 方法 | Acc% | |||||||||
| A→C | A→W | A→D | C→A | C→D | C→W | W→A | W→C | W→D | 平均值 | |
| SVMt | 79.64 | 89.34 | 92.60 | 89.13 | 92.60 | 89.34 | 89.13 | 79.64 | 92.60 | 87.68 |
| NNt | 81.03 | 91.13 | 92.99 | 89.60 | 92.99 | 91.13 | 89.60 | 81.03 | 92.99 | 88.69 |
| MMDT | 75.62 | 89.28 | 91.65 | 87.06 | 91.46 | 89.11 | 87.00 | 75.44 | 91.77 | 86.49 |
| CDLS | 78.73 | 91.57 | 94.45 | 86.34 | 90.43 | 88.60 | 87.51 | 77.30 | 92.72 | 87.52 |
| SGW | 79.88 | 90.26 | 93.43 | 89.03 | 93.43 | 90.26 | 89.02 | 79.85 | 93.43 | 88.73 |
| G-JDA | 86.60 | 94.09 | 90.67 | 92.49 | 88.62 | 92.64 | 92.28 | 84.82 | 95.87 | 90.90 |
| TNT | 85.79 | 91.26 | 92.04 | 92.35 | 92.67 | 92.98 | 92.99 | 86.28 | 94.09 | 91.17 |
| STN | 88.21 | 96.68 | 96.42 | 93.03 | 96.06 | 96.38 | 93.11 | 87.22 | 96.38 | 93.72 |
| SSAN | 88.30 | 96.31 | 97.00 | 93.16 | 97.44 | 95.87 | 93.54 | 88.18 | 97.64 | 94.17 |
| SDA-PPLS | 86.29 | 95.42 | 95.68 | 92.16 | 95.42 | 95.62 | 91.15 | 85.40 | 97.24 | 92.71 |
| 本研究 | 89.07 | 97.17 | 98.03 | 93.49 | 98.27 | 96.67 | 93.95 | 89.56 | 98.58 | 94.98 |
表 4 不同方法在 Office+Caltech-256数据集上进行异域跨特征迁移的分类结果(SURF→ ResNet50)
Tab.4
| 方法 | Acc% | |||||||||
| A→C | A→W | A→D | C→A | C→D | C→W | W→A | W→C | W→D | 平均值 | |
| SVMt | 19.99 | 78.60 | 84.37 | 34.26 | 84.37 | 78.60 | 34.26 | 19.99 | 84.37 | 57.65 |
| NNt | 20.22 | 81.51 | 84.25 | 34.81 | 84.25 | 81.51 | 34.81 | 20.22 | 84.25 | 58.43 |
| CDLS | 21.32 | 80.38 | 85.03 | 34.69 | 86.61 | 78.11 | 35.66 | 20.31 | 82.68 | 58.31 |
| STN | 21.64 | 83.77 | 85.20 | 34.16 | 86.59 | 84.21 | 35.18 | 20.71 | 83.74 | 59.47 |
| SSAN | 24.07 | 88.47 | 91.81 | 41.71 | 91.22 | 86.24 | 37.36 | 23.50 | 93.62 | 64.22 |
| 本研究 | 27.93 | 90.68 | 94.63 | 42.79 | 94.51 | 90.16 | 39.68 | 27.00 | 94.88 | 66.92 |
如表5所示为不同异构域自适应方法在Multilingual Reuters Collection 数据集上进行文本到文本迁移的分类精度. 可以得出,与监督方法NNt和SVMt相比,大多数的单源异构迁移学习方法都表现出较好的性能,此结果表明CDLS、STN、SSAN和本研究所提方法都可以在文本到文本的迁移上有效实现异构知识迁移. 本研究所提方法的平均分类准确率为 77.75%,相较于监督学习方法 NNt 和单源异构迁移学习方法 SSAN分别提升了 9.75个百分点和1.09个百分点. 结果再次验证了本研究所提方法的有效性.
表 5 不同方法在 Multilingual Reuters Collection数据集上进行文本到文本异构迁移的分类结果
Tab.5
| 方法 | Acc% | ||||
| E→S | F→S | G→S | I→S | 平均值 | |
| SVMt | 67.70 | 67.70 | 67.70 | 67.70 | 67.70 |
| NNt | 68.20 | 68.20 | 68.20 | 68.20 | 68.00 |
| NNst | 67.72 | 67.23 | 67.53 | 67.76 | 67.56 |
| MMDT | 68.21 | 65.66 | 67.24 | 67.13 | 67.06 |
| SHFA | 70.33 | 70.32 | 70.33 | 70.33 | 70.33 |
| G-JDA | 68.53 | 69.51 | 69.62 | 69.63 | 69.32 |
| CDLS | 68.36 | 68.54 | 68.61 | 68.50 | 68.50 |
| DDASL | 70.15 | 70.92 | 70.23 | 70.50 | 70.45 |
| STN | 73.82 | 74.55 | 73.71 | 74.22 | 74.08 |
| SSAN | 76.16 | 76.61 | 76.72 | 77.16 | 76.66 |
| LG | 73.21 | 71.94 | 72.53 | 66.98 | 71.17 |
| SDA-PPLS | 75.55 | 74.38 | 74.33 | 75.71 | 74.99 |
| 本研究 | 77.04 | 77.74 | 78.18 | 78.05 | 77.75 |
3.2.2. 消融实验
为了深入探究特征对齐约束、隐式语义约束、语义预测空间中的特征对齐约束以及迭代加权约束的有效性,对本研究所提方法的 5个变种进行评估. 其中PLR-SAs为消融掉空间相似性约束,PLR-SA (β=0)为消融掉条件分布对齐约束,PLR-SAst为消融掉隐式语义约束,PLR-SA (γ=0)为消融掉语义预测空间中的特征对齐约束,PLR-SA (q=Q)为消融掉迭代加权,PLR-SA:未进行消融. 如表6所示为本研究所提方法以及变种在 Office+Caltech-256 数据集上的性能. 由表可以得到1)本研究所提方法在所有任务上的性能最佳,表明上述5种约束有效. 2) 消融掉空间相似性约束的性能弱于本研究所提方法,表明空间相似性约束可以提高伪标签的置信度. 3) 消融掉条件分布对齐约束的性能最差,表明条件分布对齐约束对于跨域跨特征的知识迁移是所必需的. 4) 消融掉隐式语义约束的性能弱于本研究所提方法,表明隐式语义约束可以使目标域标签数据学习到更多的源域标签知识. 5) 消融掉语义预测空间中的特征对齐约束的性能弱于本研究所提方法,表明语义预测空间中的特征对齐约束对齐了领域的边缘分布,缩小源域和目标域之间的域差距. 6) 消融掉迭代加权的性能弱于本研究所提方法,表明迭代加权约束可以帮助提升迁移性能.
表 6 本研究所提方法在Office+Caltech-256数据集上的消融实验
Tab.6
| 方法 | Acc% | ||
| A→D | C→W | W→A | |
| PLR-SAs | 95.28 | 95.28 | 92.96 |
| PLR-SA(β=0) | 94.49 | 92.83 | 89.01 |
| PLR-SAst | 95.16 | 94.91 | 92.35 |
| PLR-SA(γ=0) | 94.88 | 95.85 | 92.56 |
| PLR-SA(q=Q) | 97.71 | 96.11 | 93.24 |
| PLR-SA | 98.03 | 96.67 | 93.95 |
3.2.3. 参数敏感性分析
为了验证本研究所提方法中参数β、γ的敏感性,实验分析Office+Caltech-256 数据集上的A→C迁移任务和Multilingual Reuters Collection数据集上的E→S迁移任务. PLR-SA 的分类精度的变化曲线如图3所示. 默认的参数设置可以实现比较高的分类准确率,表明默认的参数设置较合理;PLR-SA在所有迁移任务上使用默认参数设置均表现出优异的性能,表明PLR-SA对于不同的实验设置具有较为稳定且有效的性能.
图 3
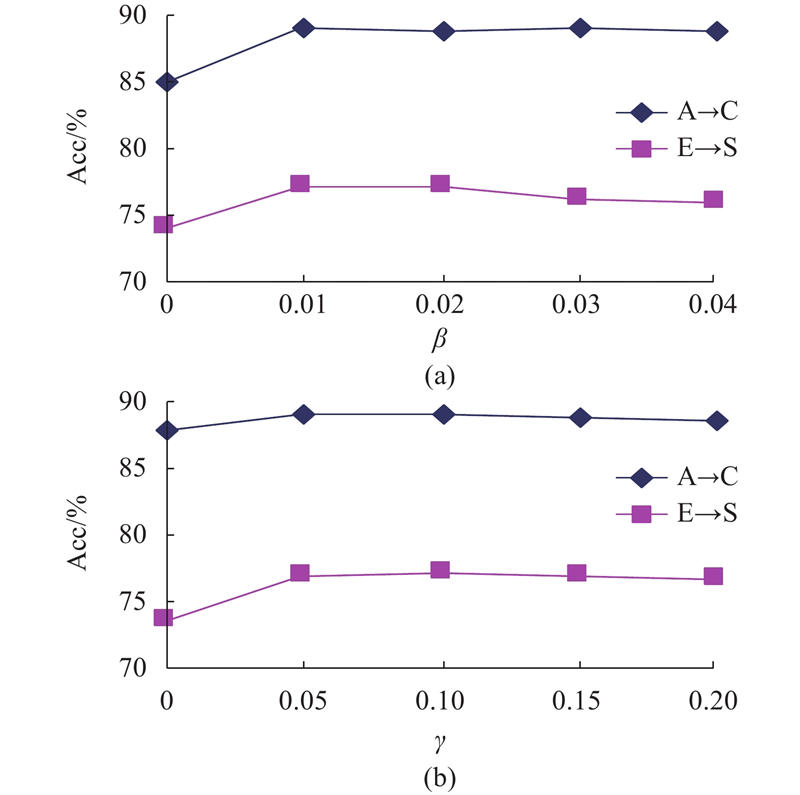
图 3 本研究所提方法在不同迁移任务上的参数敏感性分析结果
Fig.3 Results of parameter sensitivity analysis of proposed method on different migration tasks
4. 结 语
本研究提出基于伪标签细化和语义对齐的异构域自适应方法,解决了异构域间的特征和分布差异. 为了缩减领域之间条件分布差异,考虑到源数据和目标数据在公共特征子空间的相似性,提出具有空间相似度的伪标签细化方法,增强了目标域伪标签的置信度. 在缩减领域之间边缘分布的差异时,考虑到同类样本经过分类器输出后具有相似的预测分布,构造语义预测空间中的域鉴别器,将预测空间中源域的知识迁移到目标域,提高了模型的泛化性. 与多个HDA方法的仿真实验结果成功地验证了本研究所提方法优于其他HDA方法. 本文只探讨了单个异构源域场景下的迁移学习问题,没有探讨其他场景下的迁移学习问题. 下一步将考虑引入注意力机制或学习权重来自适应地融合多个源域的特征,以更好地利用源域之间的差异和相似性信息,以解决更多场景下的异构迁移问题.
参考文献
基于迁移学习与深度森林的晶圆图缺陷识别
[J].
Wafer map defect recognition based on transfer learning and deep forest
[J].
A survey on heterogeneous transfer learning
[J].DOI:10.1186/s40537-017-0089-0 [本文引用: 1]
Heterogeneous multitask metric learning across multiple domains
[J].DOI:10.1109/TNNLS.2017.2750321
Heterogeneous domain adaptation via covariance structured feature translators
[J].
Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation
[J].DOI:10.1109/TPAMI.2013.167 [本文引用: 3]
Label-guided heterogeneous domain adaptation
[J].DOI:10.1007/s11042-022-12483-1 [本文引用: 4]
Heterogeneous domain adaptation with statistical distribution alignment and progressive pseudo label selection
[J].DOI:10.1007/s10489-021-02756-x [本文引用: 4]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}