[1]
BARBOSA S, COSLEY D, SHARMA A, et al. Averaging gone wrong: using time-aware analyses to better understand behavior [C]// Proceedings of the 25th International Conference on World Wide Web. Montréal: ACM, 2016: 829-841.
[本文引用: 1]
[2]
CHAPFUWA P, TAO C, LI C, et al. Adversarial time-to-event modeling [C]// International Conference on Machine Learning . Stockholm: ACM, 2018: 735-744.
[本文引用: 3]
[3]
DU N, DAI H, TRIVEDI R, et al. Recurrent marked temporal point processes: Embedding event history to vector [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . New York: ACM, 2016: 1555-1564.
[本文引用: 2]
[4]
JANAKIRAMAN V M, MATTHEWS B, OZA N. Finding precursors to anomalous drop in airspeed during a flight's takeoff [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax: ACM, 2017: 1843-1852.
[本文引用: 2]
[5]
KINGMA D P, WELLING M. Auto-encoding variational Bayes [EB/OL] . [2023-04-27]. https://arxiv.org/abs/1312.6114.
[本文引用: 2]
[6]
BOUTTEFROY P L M, BOUZERDOUM A, PHUNG S L, et al. On the analysis of background subtraction techniques using Gaussian mixture models [C]// 2010 IEEE International Conference on Acoustics, Speech and Signal Processing . Dallas: IEEE, 2010: 4042-4045.
[本文引用: 2]
[8]
LINES J, BAGNALL A Time series classification with ensembles of elastic distance measures
[J]. Data Mining and Knowledge Discovery , 2015 , 29 (3 ): 565 - 592
DOI:10.1007/s10618-014-0361-2
[本文引用: 4]
[9]
BATISTA G E, KEOGH E J, TATAW O M, et al CID: an efficient complexity-invariant distance for time series
[J]. Data Mining and Knowledge Discovery , 2014 , 28 (3 ): 634 - 669
DOI:10.1007/s10618-013-0312-3
[本文引用: 2]
[10]
ALTHOFF T, HORVITZ E, WHITE R W, et al. Harnessing the web for population-scale physiological sensing: a case study of sleep and performance [C]// Proceedings of the 26th International Conference on World Wide Web. New York: ACM, 2017: 113-122.
[本文引用: 2]
[11]
PIERSON E, ALTHOFF T, LESKOVEC J. Modeling individual cyclic variation in human behavior [C]// Proceedings of the 2018 World Wide Web Conferenc e. Lyon: ACM, 2018: 107-116.
[本文引用: 1]
[12]
BULL J R, ROWLAND S P, SCHERWITZL E B, et al. Real-world menstrual cycle characteristics of more than 600,000 menstrual cycles [J]. NPJ Digital Medicine , 2019, 2(1): 83.
[本文引用: 2]
[13]
STEFAN A, ATHITSOS V, DAS G The move-split-merge metric for time series
[J]. IEEE Transactions on Knowledge and Data Engineering , 2012 , 25 (6 ): 1425 - 1438
[本文引用: 1]
[14]
BAYTAS I M, XIAO C, ZHANG X, et al. Patient subtyping via time-aware LSTM networks [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Halifax: ACM, 2017: 65-74.
[本文引用: 1]
[15]
BAYDOGAN M G, RUNGER G Time series representation and similarity based on local autopatterns
[J]. Data Mining and Knowledge Discovery , 2016 , 30 (2 ): 476 - 509
DOI:10.1007/s10618-015-0425-y
[本文引用: 1]
[16]
KURASHIMA T, ALTHOFF T, LESKOVEC J. Modeling interdependent and periodic real-world action sequences [C]// Proceedings of the 2018 World Wide Web Conference . Lyon: ACM, 2018: 803-812.
[本文引用: 2]
[17]
LIN J, KHADE R, LI Y Rotation-invariant similarity in time series using bag-of-patterns representation
[J]. Journal of Intelligent Information Systems , 2012 , 39 (2 ): 287 - 315
DOI:10.1007/s10844-012-0196-5
[本文引用: 1]
[18]
XU H, CHEN W, ZHAO N, et al. Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications [C]// Proceedings of the 2018 World Wide Web Conference . Lyon: ACM, 2018: 187-196.
[本文引用: 2]
[19]
RAJAN D, THIAGARAJAN J J. A generative modeling approach to limited channel ECG classification [C]// 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society . Hawaii: IEEE, 2018: 2571-2574.
[本文引用: 1]
[20]
LIU C L, HSAIO W H, TU Y C Time series classification with multivariate convolutional neural network
[J]. IEEE Transactions on Industrial Electronics , 2018 , 66 (6 ): 4788 - 4797
[本文引用: 1]
[21]
ZHANG X, GAO Y, LIN J, et al. Tapnet: multivariate time series classification with attentional prototypical network [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020, 34(4): 6845-6852.
[本文引用: 1]
[22]
SHOKOOHI-YEKTA M, CHEN Y, CAMPANA B, et al. Discovery of meaningful rules in time series [C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Sydney: ACM, 2015: 1085-1094.
[本文引用: 1]
[23]
WU T, GLEICH D F. Retrospective higher-order markov processes for user trails [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Halifax: ACM, 2017: 1185-1194.
[本文引用: 1]
[24]
BINKOWSKI M, MARTI G, DONNAT P. Autoregressive convolutional neural networks for asynchronous time series [C]// International Conference on Machine Learning . Stockholm: ACM, 2018: 580-589.
[本文引用: 1]
[25]
WANG J, WANG Z, LI J, et al. Multilevel wavelet decomposition network for interpretable time series analysis [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . London: ACM, 2018: 2437-2446.
[26]
WANG Y, GAO Z, LONG M, et al. PredRNN++: towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning [C]// International Conference on Machine Learning . Stockholm: ACM, 2018: 5123-5132.
[本文引用: 1]
[27]
ZHOU H, ZHANG S, PENG J, et al. Informer: beyond efficient transformer for long sequence time-series forecasting [C]// Proceedings of the AAAI Conference on Artificial Intelligence . [S. l. ]: AAAI, 2021, 35(12): 11106-11115.
[本文引用: 1]
[28]
ZHOU T, MA Z, WEN Q, et al. FEDformer: frequency enhanced decomposed transformer for long-term series forecasting [EB/OL]. [2023-04-27]. https://arxiv.org/abs/2201.12740.
[本文引用: 1]
[29]
YUE Z, WANG Y, DUAN J, et al. TS2Vec: towards universal representation of time series [EB/OL]. [2023-04-27]. https://arxiv.org/abs/2106.10466.
[本文引用: 1]
[30]
SHANG C, CHEN J, BI J. Discrete graph structure learning for forecasting multiple time series [EB/OL]. [2023-04-27]. https://arxiv.org/abs/2101.06861.
[本文引用: 1]
[31]
CAO D, WANG Y, DUAN J, et al Spectral temporal graph neural network for multivariate time-series forecasting
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 17766 - 17778
[本文引用: 1]
[32]
ARJOVSKY M, BOTTOU L. Towards principled methods for training generative adversarial networks [EB/OL]. [2023-04-27]. https://arxiv.org/abs/1701.04862.
[本文引用: 2]
[33]
KARRAS T, AILA T, LAINE S, et al. Progressive growing of GANs for improved quality, stability, and variation [EB/OL]. [2023-04-27]. https://arxiv.org/abs/1710.10196.
[本文引用: 2]
[34]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial nets
[J]. Advances in Neural Information Processing Systems , 2014 , 27 : 2672 - 2680
[本文引用: 1]
[35]
BAO J, CHEN D, WEN F, et al. CVAE-GAN: fine-grained image generation through asymmetric training [C]// Proceedings of the IEEE International Conference on Computer Vision . Cambridge: IEEE, 2017: 2745-2754.
[本文引用: 3]
[36]
ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier GANs [C]// International Conference on Machine Learning . Sydney: ACM, 2017: 2642-2651.
[本文引用: 1]
[37]
SOHN K, LEE H, YAN X Learning structured output representation using deep conditional generative models
[J]. Advances in Neural Information Processing Systems , 2015 , 28 : 3483 - 3491
[本文引用: 1]
[38]
MESCHEDER L, GEIGER A, NOWOZIN S. Which training methods for GANs do actually converge? [C]// International Conference on Machine Learning . Stockholm: ACM, 2018: 3481-3490.
[本文引用: 1]
[39]
GUI J, SUN Z, WEN Y, et al A review on generative adversarial networks: algorithms, theory, and applications
[J]. IEEE Transactions on Knowledge and Data Engineering , 2021 , 35 : 3313 - 3332
[本文引用: 1]
[40]
SAXENA D, CAO J Generative adversarial networks (GANs) challenges, solutions, and future directions
[J]. ACM Computing Surveys , 2021 , 54 (3 ): 1 - 42
[本文引用: 1]
[41]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1125-1134.
[本文引用: 1]
[42]
LIU M Y, TUZEL O Coupled generative adversarial networks
[J]. Advances in Neural Information Processing Systems , 2016 , 29 : 469 - 477
[本文引用: 1]
[43]
EHSANI K, MOTTAGHI R, FARHADI A. Segan: segmenting and generating the invisible [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6144-6153.
[本文引用: 1]
[44]
BALAJI Y, MIN M R, BAI B, et al. Conditional GAN with discriminative filter generation for text-to-video synthesis [C]// International Joint Conferences on Artificial Intelligence. Macao: Morgan Kaufmann, 2019, 28: 1995-2001.
[本文引用: 1]
[45]
ZHANG H, XU T, LI H, et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Honolulu: IEEE, 2017: 5907-5915.
[本文引用: 1]
[46]
JIN G, WANG Q, ZHAO X, et al. Crime-GAN: a context-based sequence generative network for crime forecasting with adversarial loss [C]// 2019 IEEE International Conference on Big Data. Los Angeles: IEEE, 2019: 1460-1469.
[本文引用: 1]
[47]
KOSARAJU V, SADEGHIAN A, MARTÍN-MARTÍN R, et al Social-bigat: multimodal trajectory forecasting using bicycle-gan and graph attention networks
[J]. Advances in Neural Information Processing Systems , 2019 , 32 : 137 - 146
[本文引用: 1]
[48]
WANG H, WANG J, WANG J, et al. GraphGAN: graph representation learning with generative adversarial nets (2017) [EB/OL]. [2023-04-27]. https://arxiv.org/abs/1711.08267.
[本文引用: 1]
[49]
BAGNALL A, LINES J, BOSTROM A, et al The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances
[J]. Data Mining and Knowledge Discovery , 2017 , 31 (3 ): 606 - 660
DOI:10.1007/s10618-016-0483-9
[本文引用: 2]
[50]
GULRAJANI I, AHMED F, ARJOVSKY M, et al Improved training of Wasserstein GANs
[J]. Advances in Neural Information Processing Systems , 2017 , 30 : 5769 - 5779
[本文引用: 1]
[51]
ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// European Conference on Computer Vision. Zurich: Springer, 2014: 818-833.
[本文引用: 1]
[52]
LIU C, HOI S C H, ZHAO P, et al. Online arima algorithms for time series prediction [C]// 30th AAAI Conference on Artificial Intelligence . Phoenix: AAAI, 2016 : 1867-1873.
[本文引用: 1]
[54]
YU H F, RAO N, DHILLON I S Temporal regularized matrix factorization for high-dimensional time series prediction
[J]. Advances in Neural Information Processing Systems , 2016 , 29 : 847 - 855
[本文引用: 1]
[55]
BERNDT D J, CLIFFORD J. Using dynamic time warping to find patterns in time series [C]// Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining . Seattle: ACM, 1994: 359-370.
[本文引用: 1]
[56]
BATISTA G E, WANG X, KEOGH E J. A complexity-invariant distance measure for time series [C]// Proceedings of the 2011 SIAM International Conference on Data Mining. Mesa: SIAM, 2011: 699-710.
[本文引用: 1]
[57]
RAKTHANMANON T, KEOGH E. Fast shapelets: a scalable algorithm for discovering time series shapelets [C]// Proceedings of the 2013 SIAM International Conference on Data Mining . Austin: SIAM, 2013: 668-676.
[本文引用: 1]
[58]
DENG H, RUNGER G, TUV E, et al A time series forest for classification and feature extraction
[J]. Information Sciences , 2013 , 239 : 142 - 153
DOI:10.1016/j.ins.2013.02.030
[本文引用: 1]
[59]
SENIN P, MALINCHIK S. Sax-VSM: interpretable time series classification using sax and vector space model [C]// 2013 IEEE 13th International Conference on Data Mining . Dallas: IEEE, 2013: 1175-1180.
[本文引用: 1]
[60]
ZHENG Y, LIU Q, CHEN E, et al. Time series classification using multi-channels deep convolutional neural networks [C]// International Conference on Web-Age Information Management. Macau: Springer, 2014: 298-310.
[本文引用: 1]
1
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
3
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
... [2 ,8 ]等. ...
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
2
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
2
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
2
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
2
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
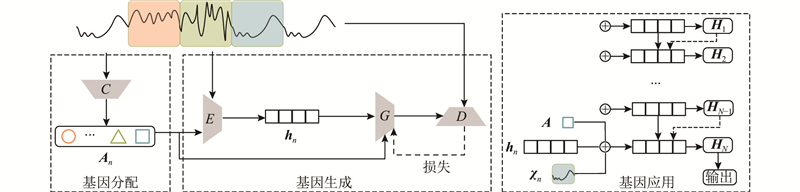
... 模型准确识别基因的性能验证. 在合成数据中,设置有监督(同质性)和无监督(轮廓系数)评价指标. 同质性指标表示它的所有子集是否只包含单个基因的数据点,轮廓系数结合内聚度和分离度2种因素,是评价聚类效果好坏的一种方式. 将GeNE的结果与几种不同的聚类算法得到的结果进行比较,包括K-means聚类、凝聚聚类(Agglomerative,Agglo)、桦树聚类(Birch clustering, Birch)、隐马尔可夫模型(HMM)[7 ] 和高斯混合模型(GMM)[6 ] . 结果如表2 所示. 表中,H 表示同质性指标,C o 为轮廓系数. K-means的表现相对优于凝聚、桦树聚类,说明距离是表示高维时间序列的重要指标. HMM和GMM的性能表明分布是建模时间序列的关键. GeNE在同质性指标和轮廓系数上都得分最高,表明分类网络 $ {\text{C}} $
HMM-based hybrid meta-clustering ensemble for temporal data
3
2014
... 近年来时间序列数据的建模引起了学术界极大的关注,因为其在金融营销和生物信息[1 -4 ] 不同领域都有着广泛的应用. 不同的时间序列演变模式反映了不同的用户行为,存在一定的规律性. 若有一种方法能够提取给定流量片段的用户行为,学习每个行为产生的流量片段情况,并捕获用户行为的转换,则可以更好地发挥时间序列的预测效果. 当前大多数的相关研究,如基于深度神经网络的模型(如long short term memory (LSTM)和variational autoencoder (VAE))[3 , 5 ] ,不能区分不同模式. 传统的混合模型(如Gaussian mixed model,GMM和hidden Markov model,HMM)[6 -7 ] 忽略了用户行为随时间产生的变化. ...
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
... 模型准确识别基因的性能验证. 在合成数据中,设置有监督(同质性)和无监督(轮廓系数)评价指标. 同质性指标表示它的所有子集是否只包含单个基因的数据点,轮廓系数结合内聚度和分离度2种因素,是评价聚类效果好坏的一种方式. 将GeNE的结果与几种不同的聚类算法得到的结果进行比较,包括K-means聚类、凝聚聚类(Agglomerative,Agglo)、桦树聚类(Birch clustering, Birch)、隐马尔可夫模型(HMM)[7 ] 和高斯混合模型(GMM)[6 ] . 结果如表2 所示. 表中,H 表示同质性指标,C o 为轮廓系数. K-means的表现相对优于凝聚、桦树聚类,说明距离是表示高维时间序列的重要指标. HMM和GMM的性能表明分布是建模时间序列的关键. GeNE在同质性指标和轮廓系数上都得分最高,表明分类网络 $ {\text{C}} $
Time series classification with ensembles of elastic distance measures
4
2015
... 本文的目的是基于时间序列的基因去估计未来事件. 传统的工作主要是根据数据值来预测事件,如动态时间扭曲[8 ] 、复杂性恒定距离[9 ] 和弹性集合[8 ] 等. 这些方法聚焦于距离测量方法并找到最近的样本,然而行为的演变在预测任务中更重要. ...
... [8 ]等. 这些方法聚焦于距离测量方法并找到最近的样本,然而行为的演变在预测任务中更重要. ...
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
... ,8 ]等. ...
CID: an efficient complexity-invariant distance for time series
2
2014
... 本文的目的是基于时间序列的基因去估计未来事件. 传统的工作主要是根据数据值来预测事件,如动态时间扭曲[8 ] 、复杂性恒定距离[9 ] 和弹性集合[8 ] 等. 这些方法聚焦于距离测量方法并找到最近的样本,然而行为的演变在预测任务中更重要. ...
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
2
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
1
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
2
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
... ,12 ]、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
The move-split-merge metric for time series
1
2012
... 时间序列建模已经应用于许多领域,如异常检测(如异常突变[2 ] 和逐渐下降[3 -4 ] )、人类行为识别(如昼夜节律和循环变化[10 -11 ] )、生物学应用(如激素循环[12 ] ). 大多数研究集中在用不同的距离度量来模拟演变数据,如动态时间扭曲[8 ,12 ] 、移动分裂合并[13 ] 、复杂度恒定距离[9 ] 和弹性集合[2 ,8 ] 等. ...
1
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
Time series representation and similarity based on local autopatterns
1
2016
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
2
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
Rotation-invariant similarity in time series using bag-of-patterns representation
1
2012
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
2
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
1
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
Time series classification with multivariate convolutional neural network
1
2018
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
1
... 一些方法侧重于通过距离进行序列聚类[10 ,14 ] ,目的是寻找到更好的度量距离的方法来建模,增强聚类性能. 本文的任务与此不同. Baydogan等[15 -16 ] 探索了基于特征的分类器,但它们是以片段重复的频率进行区分,记录重复出现片段的频率,根据生成的直方图建立分类器[17 -18 ] . 时间序列分类的深度学习算法通常是以循环神经网络(recurrent neural network,RNN)为基础,叠加卷积神经网络(convolutional neural network,CNN)层来提取时间序列特征,最后通过一个输出层进行预测. 有的是生成模型[19 ] ,有的是判别模型[20 ] ,有的是利用无标签数据进行半监督学习[21 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
1
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
Spectral temporal graph neural network for multivariate time-series forecasting
1
2020
... 基于模型的算法对每个序列拟合一个生成模型,利用模型参数的相似性来度量序列之间的相似度. 采用的参数化方法包括拟合自回归模型[22 ] 、隐马尔可夫模型[7 ,23 ] 和依赖于人工知识的内核模型[16 ] . 近来许多利用神经网络的模型被提出[24 -26 ] ,对于序列数据的深度学习方法大多集中在高级模式表示,主要思想是融合时间或空间多种因素进行建模. Informer是以transformer为基础设计的模型,用以长时间序列预测[27 ] . FEDformer 通过傅里叶变换和小波变换在频域使用注意力计算[28 ] . Yue等[29 ] 利用对比学习框架进行时间序列表征学习,假设时间上相似的片段可以视为正样本,远距离的片段可以视为负样本. Shang等[30 ] 从一组时间序列数据中学习图结构,使用图神经网络(graph neural network, GNN)进行学习. 谱时间图神经网络(StemGNN)在谱域捕获序列间相关性和时间相关性,通过图形傅里叶变换(graph Fourier transform,GFT)和离散傅里叶变换(discrete Fourier transform,DFT)框架进行有效预测[31 ] . ...
2
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
... [32 ,38 ]. ...
2
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
... [33 ],从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
Generative adversarial nets
1
2014
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
3
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
... 与上述模型不同,本文的模型使用分类器学习片段对应的基因,使用CVAE-GAN结构[35 ] 估计分布模式. 根据分布的演变情况,预测未来的事件. ...
... 基因生成部分是用来学习生成片段的基因,目的是捕获片段的分布模式. 基因生成是由对抗生成器 $ ({G} |{D} ) $ [35 ] . 该方法捕获了优于其他方法的高级分布模式(详见第2.3节). ...
1
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
Learning structured output representation using deep conditional generative models
1
2015
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
1
... 生成模型最近引起了人们的极大关注,大规模(未标记)数据上的非参数学习能力赋予了它们更多的潜力和活力. Chapfuwa等[2 ,18 ,32 -33 ] 都致力于深度生成模型的探索和发展. 由于深度结构能够捕获数据中的复杂结构,这些方法在生成更真实的样本方面比传统生成模型更加优越. 其中有2个重要主题:变分自动编码器(variational autoencoder, VAE)[5 ] 和生成对抗网络(generative adversarial network,GAN)[34 ] . VAE包含1个变分编码器网络与1个解码器/生成器网络. VAE的缺点是由于噪声和不完美的度量方法(如平方误差),生成的样本往往是模糊的[35 ] . GAN是另一种比较流行的生成模型. 它同时训练2个模型:生成样本的生成模型和区分真实样本和合成样本的鉴别模型. GAN模型在训练阶段难以收敛,由GAN生成的样本往往不自然. 利用条件约束,可以显著地提高生成样本的质量[36 -37 ] . 近年来,许多学者在寻找更好的GAN训练方法[33 ] ,从理论上更好地理解GAN的训练过程[32 ,38 ] . ...
A review on generative adversarial networks: algorithms, theory, and applications
1
2021
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
Generative adversarial networks (GANs) challenges, solutions, and future directions
1
2021
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
Coupled generative adversarial networks
1
2016
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
Social-bigat: multimodal trajectory forecasting using bicycle-gan and graph attention networks
1
2019
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
1
... GAN在各个领域都得到了相当多的关注[39 -40 ] ,包括图像翻译[41 ] 、图像生成[42 ] 、目标检测[43 ] 、视频[44 ] 和自然语言处理[45 ] . 尽管GAN在计算机视觉领域(图像和视频生成)取得了成功,但将GAN应用于时间序列数据预测仍具有挑战性. 最近,GAN已经被应用于时间序列数据的建模,其应用包括时间序列事件的生成[46 ] 、轨迹预测[47 ] 、图表示[48 ] 等. ...
The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances
2
2017
... 若距离的均值和方差接近,则这些片段更可能具有相似的分布[49 ] ,因此它们应该被识别成同一基因. ...
... 比较结果. 如表4 、5 所示为事件预测的结果. 表中,A 为准确度,P 为精确度,R 为召回率,粗体表示所有方法中能达到的最佳性能. 对于公共数据集,使用准确度作为指标,因为使用的数据有相对平衡的正/负样本比率,Bagnall等[49 ] 使用准确度作为指标. 对于真实数据集,使用精确度、召回率和F指标(F1、F0.5)作为指标. 通常,使用F0.5作为异常检测的度量,因为在减少工作量方面,精确度比召回率更重要. 所有基于最近邻的量化距离方法的性能相似,但不稳定,这可能归因于数据的特殊性,因为NN-DTW方法在INS和TMP数据集上的表现不佳. 特征提取方法在MCE和TMP数据集上有相对较高的召回率(Recall),如字典方法SAX-VSM,但精确度不高,因此不太适合不平衡的样本. 神经网络方法(MC-DCNN、LSTM)由于模型的复杂性高,在小规模数据(地震)上表现不佳,它们可能更适合处理大规模数据. 生成模型利用基因的分布模式,对行为演变进行建模,在5个真实世界的数据集上获得了更好的性能. CVAE在所有数据集上的表现都优于临近邻居方法,这得益于对时间序列反映的行为演变进行建模. ...
Improved training of Wasserstein GANs
1
2017
... 在实际中,样本和“假”样本的分布可能不会相互重叠,特别是在训练过程的初期. 鉴别器网络 $D $ $D({{\boldsymbol{\chi }}_n}{\text{)}} \to {\text{1}} $ $ D({\boldsymbol{\chi}} _n'{\text{)}} \to 0 $ . 当更新 $ G$ $ \partial L'_{{\text{GD}}}/\partial D({\boldsymbol{\chi}} _n') \to - \infty $ $ G $ $G $ [50 ] . ...
1
... 输出 . 最后一个应用层将“端到端”机制应用于下游任务(预测未来值 $ {{\boldsymbol{\chi }}_{N+1}} $ $ y $ ) , $ \varPsi $ $ {{\boldsymbol{H}}_N} $ $ \varPsi $ [51 ] 作为 $ \varPsi $
1
... 1) 整合移动平均自回归模型(autoregressive integrated moving average model, ARIMA):这是Liu等[52 ] 提出的用于时间序列预测的算法. ...
Long short-term memory
2
1997
... 2) 长短期记忆网络(long short-term memory, LSTM):这是Hochreiter等[53 ] 提出的常见的神经网络. ...
... 5) 长短期记忆网络(long short-term memory, LSTM)和多通道深度卷积神经网络(multi-channel deep convolutional neural network, MC-DCNN):这是Hochreiter等[53 ] 和Zheng等[60 ] 分别提出的2种基于深度神经网络的方法. ...
Temporal regularized matrix factorization for high-dimensional time series prediction
1
2016
... 3) 时间正则矩阵分解(temporally regularized matrix factorization, TRMF):这是Yu等[54 ] 用于时间序列预测的时间正则化矩阵分解. ...
1
... 1) 高斯距离(Euclidean distance,NN-ED)、动态时间规整(dynamic time warping,NN-DTW)和复杂度不变距离(complexity invariant distance,NN-CID):给定一个样本,利用这些方法计算它们在训练数据中的最近邻居,使用最近邻居的标签对给定的样本进行分类. 为了量化样本之间的距离,它们考虑了不同的度量标准,分别是欧氏距离、动态时间扭曲[55 ] 和复杂性不变距离[56 ] . ...
1
... 1) 高斯距离(Euclidean distance,NN-ED)、动态时间规整(dynamic time warping,NN-DTW)和复杂度不变距离(complexity invariant distance,NN-CID):给定一个样本,利用这些方法计算它们在训练数据中的最近邻居,使用最近邻居的标签对给定的样本进行分类. 为了量化样本之间的距离,它们考虑了不同的度量标准,分别是欧氏距离、动态时间扭曲[55 ] 和复杂性不变距离[56 ] . ...
1
... 2) 快速子序列(fast shapelets, FS):这是使用子序列作为特征的分类算法[57 ] . ...
A time series forest for classification and feature extraction
1
2013
... 3) 时间序列森林(time series forest,TSF):这是树状集成方法,从每个序列的间隔中获得特征[58 ] . ...
1
... 4) 向量空间模型中的符号聚合近似(symbolic aggregate approximation in vector space model, SAX-VSM):这是字典方法,它从每个序列的间隔中获得特征[59 ] . ...
1
... 5) 长短期记忆网络(long short-term memory, LSTM)和多通道深度卷积神经网络(multi-channel deep convolutional neural network, MC-DCNN):这是Hochreiter等[53 ] 和Zheng等[60 ] 分别提出的2种基于深度神经网络的方法. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}