[1]
CHEN X J, JIA S B, XIANG Y A review: knowledge reasoning over knowledge graph
[J]. Expert Systems with Applications , 2020 , 141 : 1 - 21
[本文引用: 1]
[2]
舒世泰, 李松, 郝晓红, 等 知识图谱嵌入技术研究进展
[J]. 计算机科学与探索 , 2021 , 15 (11 ): 2048 - 2062
[本文引用: 1]
SHU Shi-tai, Li Song, HAO Xiao-hong, et al Knowledge graph embedding technology: a review
[J]. Journal of Frontiers of Computer Science and Technology , 2021 , 15 (11 ): 2048 - 2062
[本文引用: 1]
[3]
刘知远, 孙茂松, 林衍凯, 等 知识表示学习研究进展
[J]. 计算机研究与发展 , 2016 , 53 (2 ): 247 - 261
[本文引用: 1]
LIU Zhi-yuan, SUN Mao-song, LIN Yan-kai, et al Research progress of knowledge representation learning
[J]. Journal of Computer Research and Development , 2016 , 53 (2 ): 247 - 261
[本文引用: 1]
[4]
BORDES A, USUNIER N, GARCÍA-DURÁN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Lake Tahoe: MITP, 2013: 2787-2795.
[本文引用: 3]
[5]
WANG Z, ZHANG J W, FENG J L, et al. Knowledge graph embedding by translating on hyperplanes [C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Québec: AAAI, 2014: 1112-1119.
[本文引用: 2]
[6]
LIN Y K, LIU Z Y, SUN M S, et al. Learning entity and relation embeddings for knowledge graph completion [C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence . Austin: AAAI, 2015: 2181-2187.
[本文引用: 2]
[7]
JI G L, HE S Z, XU L H, et al. Knowledge graph embedding via dynamic mapping matrix [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and 7th International Joint Conference on Natural Language Processing . Beijing: ACL, 2015: 687-696.
[本文引用: 3]
[8]
TransA: an adaptive approach for knowledge graph embedding [EB/OL].[2022-05-02]. http://arxiv.org/abs/1509.05490.
[本文引用: 2]
[9]
XIAO H, HUANG M L, ZHU X Y. TransG: a generative model for knowledge graph embedding [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics . Berlin: ACL, 2016: 2316-2325.
[本文引用: 1]
[10]
WANG Z, ZHANG J W, FENG J L, et al. Knowledge graph and text jointly embedding[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: ACL, 2014: 1591-1601.
[本文引用: 1]
[11]
XIE R B, LIU Z Y, JIA J, et al. Representation learning of knowledge graphs with entity descriptions [C]// Proceedings of the 30th National Conference on Artificial Intelligence. Phoenix: AAAI, 2015: 2659-2665.
[本文引用: 2]
[12]
XIE R B, LIU Z Y, SUN M S. Representation learning of knowledge graphs with hierarchical types [C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence . New York: AAAI, 2016: 2965-2971.
[本文引用: 1]
[13]
JI S X, PAN S R, ERIK C, et al A survey on knowledge graphs: representation, acquisition and applications
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2021 , 33 (2 ): 494 - 514
[本文引用: 1]
[14]
ZENG D J, LIU K, CHEN Y B, et al. Distant supervision for relation extraction via piecewise convolutional neural networks [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing . Lisbon: ACL, 2014: 1753-1762.
[本文引用: 1]
[15]
JIANG X T, WANG Q, LI P, et al. Relation extraction with multi-instance multi-label convolutional neural networks [C]// Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics . Osaka: COC, 2016: 1471-1480.
[本文引用: 1]
[16]
HAN X, YU P F, LIU Z Y, et al. Hierarchical relationextraction with coarse-to-fine grained attention [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing . Brussels: ACL, 2018: 2236-2245.
[本文引用: 1]
[17]
ZHANG N Y, DENG S M, SUN Z L, et al. Long-tail relation extraction via knowledge graph embeddings and graph convolution networks [C]// Proceedings of the 2019 Conference of the NAACL: Human Language Technologies . Minneapolis: ACL, 2019: 3016-3025.
[本文引用: 1]
[18]
TANG X, CHEN L, CUI J, et al Knowledge representation learning with entity descriptions, hierarchical types, and textual relations
[J]. Information Processing and Management , 2019 , 56 : 809 - 822
DOI:10.1016/j.ipm.2019.01.005
[本文引用: 1]
[19]
FAN M, ZHOU Q, CHANG E, et al. Transition-based knowledge graph embedding with relational mapping properties [C]// Proceedings of the 28th Pacific Asia Conference on Language, Information and Computation . Phuket: ACL, 2014: 328-337.
[本文引用: 1]
[20]
FENG J, HUANG M L, WANG M D, et al. Knowledge graph embedding by flexible translation [C]// Proceedings of the 15th International Conference on Principles of Knowledge Representation and Reasoning . Cape Town: AAAI, 2016: 557-560.
[本文引用: 1]
[21]
NICKEL M, TRESP V, KRIEGEL H. A three-way model for collective learning on multi-relational data [C]// Proceedings of the 28th International Conference on Machine Learning . Washington: ACM, 2011: 809-816.
[本文引用: 1]
[22]
YANG B S, YIH W, HE X D, et al. Embedding entities and relations for learning and inference in knowledge bases [C]// Proceedings of the 3rd International Conference on Learning Representations . San Diego: [s.n.], 2015: 1-12.
[本文引用: 1]
[23]
TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction [C]// Proceedings of the 33rd International Conference on Machine Learning . New York: IMLS, 2016: 2071-2080.
[本文引用: 1]
[24]
ZHANG Z, ZHUANG F Z, QU M, et al. Knowledge graph embedding with hierarchical relation structure [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing . Brussels: ACL, 2018: 3198-3207.
[本文引用: 1]
[25]
FENG J, HUANG M L, YANG Y, et al. GAKE: Graph aware knowledge embedding [C]// Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics . Osaka: COC, 2016: 641-651.
[本文引用: 1]
[26]
XIE R B, LIU Z Y, LUAN H B, et al. Image embodied knowledge representation learning [C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence . Melbourne: AAAI, 2017: 3140-3146.
[本文引用: 1]
[27]
TOUTANOVA K, LIN X V, YIH W T, et al. Compositional learning of embeddings for relation paths in knowledge base and text [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics . Berlin: ACL, 2016: 1434-1444.
[本文引用: 1]
[28]
夏光兵, 李瑞轩, 辜希武, 等 融合多源信息的知识表示学习
[J]. 计算机科学与探索 , 2022 , 16 (3 ): 591 - 597
[本文引用: 1]
XIA Guang-bing, LI Rui-xuan, GU Xi-wu, et al Knowledge representation learning based on multi-source information combination
[J]. Journal of Frontiers of Computer Science and Technology , 2022 , 16 (3 ): 591 - 597
[本文引用: 1]
[29]
杜文倩, 李弼程, 王瑞 融合实体描述及类型的知识图谱表示学习方法
[J]. 中文信息学报 , 2020 , 34 (7 ): 50 - 59
[本文引用: 1]
DU Wen-qing, LI Bi-cheng, WANG Rui Representation learning of knowledge graph integrating entity description and entity type
[J]. Journal of Chinese Information Processing , 2020 , 34 (7 ): 50 - 59
[本文引用: 1]
[30]
WANG P, ZHOU J JECI++: a modified joint knowledge graph embedding model for concepts and instances
[J]. Big Data Research , 2021 , 24 : 1 - 10
[本文引用: 1]
[31]
ZHAO F, XU T, JIN L J Q, et al Convolutional network embedding of text-enhanced representation for knowledge graph completion
[J]. IEEE Internet of Things Journal , 2021 , 8 (23 ): 16758 - 16769
DOI:10.1109/JIOT.2020.3039750
[本文引用: 2]
[32]
MAHDISOLTANI F, BIEGA J, SUCHANEK F. Yago3: A knowledge base from multilingual wikipedias [C]// Proceedings of the 7th Biennial Conference on Innovative Data Systems Research . Asilomar: [s. n.], 2015: 1-11.
[本文引用: 1]
[33]
DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2d knowledge graph embeddings [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence . Louisiana: AAAI, 2018: 1707-1711.
[本文引用: 2]
A review: knowledge reasoning over knowledge graph
1
2020
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
知识图谱嵌入技术研究进展
1
2021
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
知识图谱嵌入技术研究进展
1
2021
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
知识表示学习研究进展
1
2016
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
知识表示学习研究进展
1
2016
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
3
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
... TransE[4 ] 是最具代表性的翻译模型,将实体和关系嵌入到d 维向量空间中,即h r t R d R d d 维空间. 同时遵循平移原则,即h r t
... 使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1 所示,其中,N 为数量. WN18[7 ] 按照术语的语义进行分组,反映实体间的内部属性. FB15K[4 ] 包含丰富的上下文信息,具有多种数据类型. 对于YAGO3-10[32 ] 数据集进行预处理,保留超过10个与实体相关联的关系的三元组. WN18RR[33 ] 与WN18相比,消除反向关系,提供更真实的表示方法为基准. FB15K-237[31 ] 数据集通过删除反向关系从原始Freebase数据集FB15K中提取. 与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体. ...
2
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
2
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
3
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
... 使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1 所示,其中,N 为数量. WN18[7 ] 按照术语的语义进行分组,反映实体间的内部属性. FB15K[4 ] 包含丰富的上下文信息,具有多种数据类型. 对于YAGO3-10[32 ] 数据集进行预处理,保留超过10个与实体相关联的关系的三元组. WN18RR[33 ] 与WN18相比,消除反向关系,提供更真实的表示方法为基准. FB15K-237[31 ] 数据集通过删除反向关系从原始Freebase数据集FB15K中提取. 与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体. ...
2
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
1
... 知识图谱(knowledge graph, KG)[1 ] 是一种用图模型来描述知识和建立世界万物之间关系的技术方法,并且已经成为智能问答等多个人工智能领域的重要资源. KG通过三元组(头实体、关系、尾实体)的形式以保存数据. 传统的知识表示方法都是以符号逻辑为基础进行表示,易于刻画离散、显性的知识,具有较好的可解释性. 在表示过程中,有许多不能用符号来刻画连续、隐形的知识会失去鲁棒性,从而在下游任务中难以达到预期效果[2 ] . 为了解决此问题提出表示学习.该方法有效度量实体和关系的语义相关性,缓解KG中的稀疏性问题[3 ] . 已有的方法主要分为翻译模型和卷积神经网络(convolutional neural network, CNN)模型. Bordes等[4 ] 提出TransE模型,该模型将关系向量视为实体向量之间的转换,并实现向量的规范表示. 继TransE之后,研究人员提出各种其他翻译模型,如TransH[5 ] 、TransR[6 ] 、TransD[7 ] 、TransA[8 ] 和TransG[9 ] . 这些模型对KG中的内部结构信息进行表示学习,但是语义可解释性较差.基于CNN的模型增加了对复杂关系和参数规模的考虑,可以学习更多的嵌入表示. ...
1
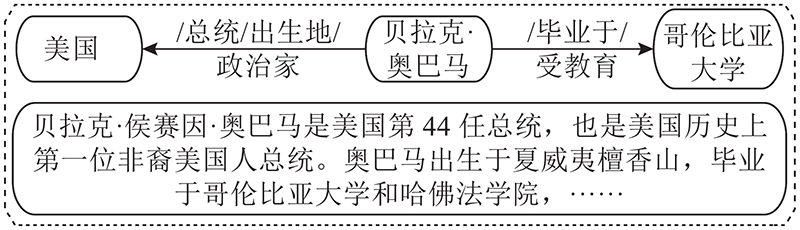
... 在大型的知识库中,如维基百科,对每个实体都有简单的文本描述,这些额外的文本信息可以有效提高知识表示能力. Wang等[10 ] 将实体和单词/短语在同一向量空间中表示,使得预测结果更准确. DKRL模型[11 ] 充分利用实体的描述信息,分别使用连续词袋模型和卷积神经网络模型对实体描述信息进行编码. 在Freebase中,层次类型包括属性、类型和域,它们都是非常重要的外部信息. TKRL模型[12 ] 充分利用知识库中的层次类型信息增强实体的表示. 以上3个模型只考虑实体描述信息和层次类型信息,忽略了关系的描述信息. ...
2
... 在大型的知识库中,如维基百科,对每个实体都有简单的文本描述,这些额外的文本信息可以有效提高知识表示能力. Wang等[10 ] 将实体和单词/短语在同一向量空间中表示,使得预测结果更准确. DKRL模型[11 ] 充分利用实体的描述信息,分别使用连续词袋模型和卷积神经网络模型对实体描述信息进行编码. 在Freebase中,层次类型包括属性、类型和域,它们都是非常重要的外部信息. TKRL模型[12 ] 充分利用知识库中的层次类型信息增强实体的表示. 以上3个模型只考虑实体描述信息和层次类型信息,忽略了关系的描述信息. ...
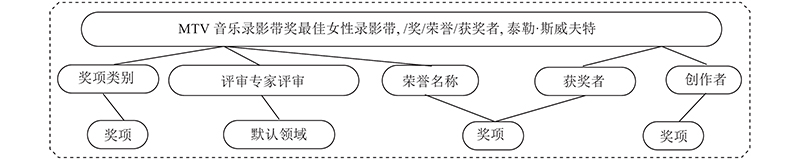
... 层次类型信息是外部信息的重要组成部分,对于知识表示学习具有重要意义. 如图3 所示,在Freebase中,同一个实体在不同场景下代表不同含义;实体的类型层次化,不同粒度的实体含义分布在不同层次的子类型上,且大多数实体具有复杂多样化的层次类型结构,一个实体可能呈现出多种层次类型,每种层次类型包含多个子层. 根据Xie等[11 ] 提出的方法,以层次类型结构l 为例,其有m 层,其中l (i ) 为l 的第i 个子类型,每个子类型l (i ) 只有一个父子类型l (i +1) ,最精确的子类型是第一层,最通用的子类型是最后一层. 即l = (l (1) , l (2) $, \cdots , $ l (m ) ). ...
1
... 在大型的知识库中,如维基百科,对每个实体都有简单的文本描述,这些额外的文本信息可以有效提高知识表示能力. Wang等[10 ] 将实体和单词/短语在同一向量空间中表示,使得预测结果更准确. DKRL模型[11 ] 充分利用实体的描述信息,分别使用连续词袋模型和卷积神经网络模型对实体描述信息进行编码. 在Freebase中,层次类型包括属性、类型和域,它们都是非常重要的外部信息. TKRL模型[12 ] 充分利用知识库中的层次类型信息增强实体的表示. 以上3个模型只考虑实体描述信息和层次类型信息,忽略了关系的描述信息. ...
A survey on knowledge graphs: representation, acquisition and applications
1
2021
... 关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键. 由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13 ] . PCNN模型[14 ] 对按实体位置划分的卷积表示段使用分段最大池化. 与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息. MIMLCNN模型[15 ] 进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择. Han等[16 ] 提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息. Zhang等[17 ] 将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取. ...
1
... 关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键. 由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13 ] . PCNN模型[14 ] 对按实体位置划分的卷积表示段使用分段最大池化. 与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息. MIMLCNN模型[15 ] 进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择. Han等[16 ] 提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息. Zhang等[17 ] 将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取. ...
1
... 关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键. 由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13 ] . PCNN模型[14 ] 对按实体位置划分的卷积表示段使用分段最大池化. 与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息. MIMLCNN模型[15 ] 进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择. Han等[16 ] 提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息. Zhang等[17 ] 将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取. ...
1
... 关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键. 由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13 ] . PCNN模型[14 ] 对按实体位置划分的卷积表示段使用分段最大池化. 与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息. MIMLCNN模型[15 ] 进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择. Han等[16 ] 提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息. Zhang等[17 ] 将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取. ...
1
... 关系抽取是从纯文本中提取未知关系事实并将关系加入到知识图谱中,是自动构建大规模KG的关键. 由于缺少标记的关系数据,远程监控(distance supervision)通过假设包含相同实体的语句在关系数据库的监督下,可以表示相同的关系,使用启发式匹配来创建训练数据[13 ] . PCNN模型[14 ] 对按实体位置划分的卷积表示段使用分段最大池化. 与CNN相比,PCNN能够更有效地捕捉实体内部的结构信息. MIMLCNN模型[15 ] 进一步将关系抽取 扩展到多标签学习中,使用跨句子最大池化进行特征选择. Han等[16 ] 提出层次选择性Attention,通过连接每层的Attention来表示捕捉关系层次的信息. Zhang等[17 ] 将图卷积神经网络(graph convolutional network, GCN)应用于知识图谱中的关系嵌入以及基于句子的关系抽取. ...
Knowledge representation learning with entity descriptions, hierarchical types, and textual relations
1
2019
... 这些方法都取得较好的实验效果,但是融合方法单一,仍存在3个问题:1) 这些方法只考虑单类外部信息,仅仅在单词上对齐,没有将三元组结构和文本信息相结合. 2) 文本描述可能从各方面表示一个实体,在给定特定关系的情况下,并非文本描述中提供的所有信息都对实体起决定作用. 3) 三元组的结构表示向量从现有的三元结构信息中学习得来,文本表示向量是从与文本语料库中相关联的信息中学习而来,需要保证这2种向量的维数一致,以提高知识表示的性能[18 ] . ...
1
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
1
... TransE模型参数少,在1-1关系中表现较好,但是在处理1-N 、N -1、N -N 等复杂关系时存在缺陷. 为了解决这一问题,TransH模型[5 ] 引入超平面机制,将h t [6 ] 将实体和关系都表示为语义空间R d R k [7 ] 对每个实体或关系使用2个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵,以向量的乘积代替矩阵,减少模型的参数规模. 以上模型都限制平移要求,导致翻译原则不灵活. TransM模型[19 ] 在计算得分函数时,为每个三元组赋一个预计算的权重,该权重反映在该关系下的实体节点的度. TransF模型[20 ] 只须保证 h r t [8 ] 为每个关系 r 引入一个对称的非负矩阵M r
1
... RESCAL模型[21 ] 用向量表示实体,用矩阵表示关系,通过自定义的得分函数捕获三元组的内部交互. DistMult模型[22 ] 通过将M r [23 ] 通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模. 上述三者都属于语义匹配模型,通过匹配实体的潜在语义和向量空间中的关系来衡量三元组的准确性. ...
1
... RESCAL模型[21 ] 用向量表示实体,用矩阵表示关系,通过自定义的得分函数捕获三元组的内部交互. DistMult模型[22 ] 通过将M r [23 ] 通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模. 上述三者都属于语义匹配模型,通过匹配实体的潜在语义和向量空间中的关系来衡量三元组的准确性. ...
1
... RESCAL模型[21 ] 用向量表示实体,用矩阵表示关系,通过自定义的得分函数捕获三元组的内部交互. DistMult模型[22 ] 通过将M r [23 ] 通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模. 上述三者都属于语义匹配模型,通过匹配实体的潜在语义和向量空间中的关系来衡量三元组的准确性. ...
1
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
1
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
1
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
1
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
融合多源信息的知识表示学习
1
2022
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
融合多源信息的知识表示学习
1
2022
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
融合实体描述及类型的知识图谱表示学习方法
1
2020
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
融合实体描述及类型的知识图谱表示学习方法
1
2020
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
JECI++: a modified joint knowledge graph embedding model for concepts and instances
1
2021
... 目前大多数研究只对三元组自身结构进行嵌入,将实体和关系表示到连续向量空间中,并定义评分函数衡量真实性. 事实上,KG中还隐含着其它丰富的信息可以提高知识表示能力,将文本描述信息、图拓扑结构、逻辑规则、关系路径、视觉信息和时序信息等外部信息与KG相结合来提高知识表示的有效性. Zhang等[24 ] 利用关系簇、关系和子关系的层次关系结构扩展现有的嵌入方法. GAKE模型[25 ] 同时使用邻居、边、路径3种上下文融入图结构信息. Guo等[26 ] 提出一种融合三元组事实和逻辑规则的联合表示学习模型,视觉信息也可以提高知识表示能力. IKRL模型[27 ] 将图像编码到实体空间,并遵循翻译原则. 夏光兵等[28 ] 通过融合实体的文本描述信息、层次类型信息和图的拓扑结构信息,充分利用三元组以外的多源异质信息来提高知识图谱各类任务的效果. 杜文倩等[29 ] 同时学习三元组信息、实体描述以及实体类型信息来处理一对多、多对多等复杂关系. Wang等[30 ] 首次将概念和实例进行联合嵌入,基于邻居信息和所属概念为实例,设计预测函数,使实例的嵌入更具表现力. ...
Convolutional network embedding of text-enhanced representation for knowledge graph completion
2
2021
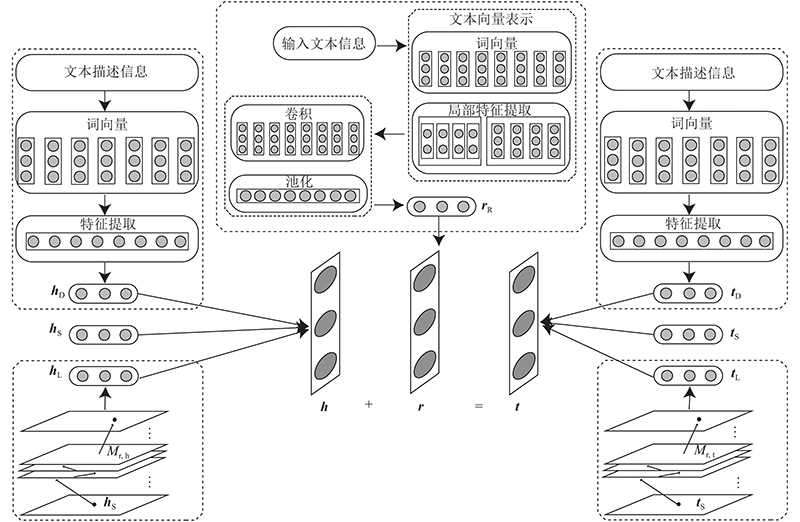
... 实体描述信息包含丰富的实体语义,可以作为KG的额外信息增强表示学习效果. 如图2 所示,文本描述信息中隐含着对三元组实体的描述,充分利用这些文本描述信息成为联合表示学习的关键. 根据Zhao等[31 ] 提出的方法,利用实体描述作为补充,并获得基于文本描述的实体表示,即h D 和t D .当获得实体所在的句子时,表示的集合为E s s 1 , s 2 $, \cdots , $ s n k ,将滑动窗口设置为1即可获得s i s i s i+k −1w 1 , w 2 $, \cdots , $ w i w i+ 1$, \cdots , $ w i+k −1
... 使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1 所示,其中,N 为数量. WN18[7 ] 按照术语的语义进行分组,反映实体间的内部属性. FB15K[4 ] 包含丰富的上下文信息,具有多种数据类型. 对于YAGO3-10[32 ] 数据集进行预处理,保留超过10个与实体相关联的关系的三元组. WN18RR[33 ] 与WN18相比,消除反向关系,提供更真实的表示方法为基准. FB15K-237[31 ] 数据集通过删除反向关系从原始Freebase数据集FB15K中提取. 与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体. ...
1
... 使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1 所示,其中,N 为数量. WN18[7 ] 按照术语的语义进行分组,反映实体间的内部属性. FB15K[4 ] 包含丰富的上下文信息,具有多种数据类型. 对于YAGO3-10[32 ] 数据集进行预处理,保留超过10个与实体相关联的关系的三元组. WN18RR[33 ] 与WN18相比,消除反向关系,提供更真实的表示方法为基准. FB15K-237[31 ] 数据集通过删除反向关系从原始Freebase数据集FB15K中提取. 与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体. ...
2
... 使用WN18、WN18RR、FB15K、FB15K-237和YAGO3-10数据集,具体的数据数量如表1 所示,其中,N 为数量. WN18[7 ] 按照术语的语义进行分组,反映实体间的内部属性. FB15K[4 ] 包含丰富的上下文信息,具有多种数据类型. 对于YAGO3-10[32 ] 数据集进行预处理,保留超过10个与实体相关联的关系的三元组. WN18RR[33 ] 与WN18相比,消除反向关系,提供更真实的表示方法为基准. FB15K-237[31 ] 数据集通过删除反向关系从原始Freebase数据集FB15K中提取. 与WN18RR和YAGO3-10相比,FB15K-237数据集更具有复杂的关系类型和更少的实体. ...
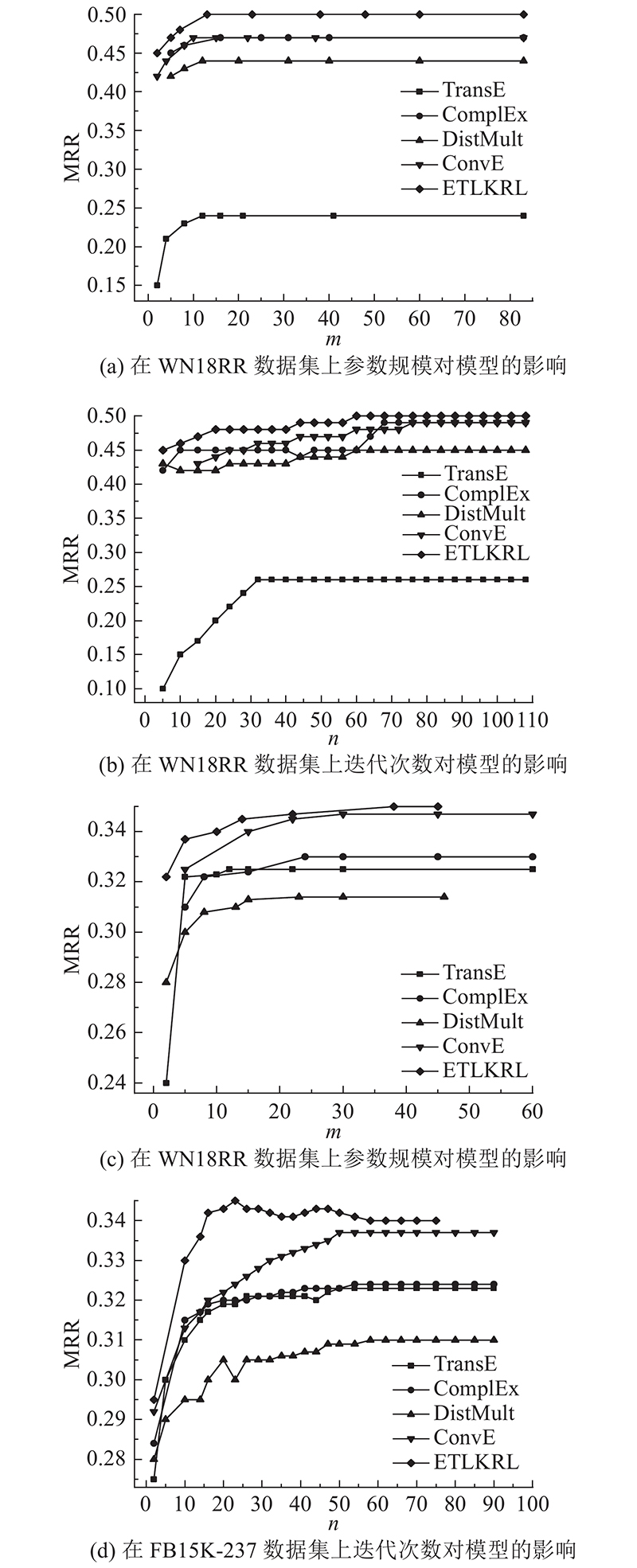
... 3)在FB15K数据集上,ETLKRL的Hits@10实验结果略低于ConvE模型[33 ] ,因为FB15K数据集的内部关系密集,结构相对复杂,ConvE模型擅长建模三重复杂结构信息. ETLKRL模型提取外部文本信息进行融合,从而略微降低结构表征学习的性能. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}