[1]
王宇, 吴智恒, 邓志文, 等 基于机器视觉的金属零件表面缺陷检测系统
[J]. 机械工程与自动化 , 2018 , (4 ): 210 - 211+214
DOI:10.3969/j.issn.1672-6413.2018.04.088
[本文引用: 1]
WANG Yu, WU Zhi-heng, DENG Zhi-wen, et al Metal component surface defect detection system based on machine vision
[J]. Mechanical Engineering and Automation , 2018 , (4 ): 210 - 211+214
DOI:10.3969/j.issn.1672-6413.2018.04.088
[本文引用: 1]
[2]
HO C C, SU E, LI P, et al Machine vision and deep learning based rubber gasket defect detection
[J]. Advances in Technology Innovation , 2020 , 5 (2 ): 76 - 83
DOI:10.46604/aiti.2020.4278
[本文引用: 1]
[3]
李璟钰, 肖俊良, 付晗, 等 基于机器视觉的导光板表面微小缺陷检测
[J]. 信息系统工程 , 2021 , (2 ): 65 - 69
[本文引用: 1]
LI Jing-yu, XIAO Jun-liang, FU Han, et al Detection of small defects on the surface of light guide plates
[J]. China CIO News , 2021 , (2 ): 65 - 69
[本文引用: 1]
[4]
戴君洁. 基于机器视觉的目标识别和表面缺陷检测研究[D]. 大理: 大理大学, 2021.
[本文引用: 1]
DAI Jun-jie. Research on object recognition and surface defect detection based on machine vision [D]. Dali: Dali University, 2021.
[本文引用: 1]
[5]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [EB/OL]. [2022-04-07]. https://arxiv.org/pdf/1512.02325.pdf.
[本文引用: 1]
[6]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[7]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[8]
GIRSHICK R. Fast R-CNN [C]// 2015 IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[9]
REN S Q, HE K M, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[10]
HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980−2988.
[本文引用: 1]
[11]
黄海新, 金鑫. 基于YOLOv4的小目标缺陷检测[J]. 电子世界, 2021(5): 146-147.
[本文引用: 1]
HUANG Hai-xin, JIN Xin. Detection of small object defect based on YOLOv4 [J]. Electronics World , 2021(5): 146-147.
[本文引用: 1]
[12]
刘聪. 基于卷积神经网络的微小零件表面缺陷检测技术研究[D]. 哈尔滨: 哈尔滨理工大学, 2019.
[本文引用: 1]
LIU Cong. Research on surface defects detection of micro parts based on convolution neural network [D]. Harbin: Harbin University of Science and Technology, 2019.
[本文引用: 1]
[13]
陈绪浩. 基于深度学习的高速连接器高精度表面缺陷检测算法研究[D]. 成都: 电子科技大学, 2021.
[本文引用: 2]
CHEN Xu-hao. Research on high precision surface defect detection algorithm of high speed connector based on deep learning [D]. Chengdu: University of Electronic Science and Technology of China, 2021.
[本文引用: 2]
[14]
代牮, 赵旭, 李连鹏, 等 基于改进YOLOv5的复杂背景红外弱小目标检测算法
[J]. 红外技术 , 2022 , 44 (5 ): 504 - 512
[本文引用: 1]
DAI Jian, ZHAO Xu, LI Lian-peng, et al Improved YOLOv5-based infrared dim-small target detection under complex background
[J]. Infrared Technology , 2022 , 44 (5 ): 504 - 512
[本文引用: 1]
[15]
HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 13708-13717.
[本文引用: 1]
[16]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [EB/OL]. [2022-04-07]. https://arxiv.org/pdf/1911.09070.pdf.
[本文引用: 1]
[17]
HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1577-1586.
[本文引用: 1]
[18]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Lake City: IEEE, 2018: 8759-8768.
[本文引用: 2]
[19]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2022-04-07]. https://arxiv.org/pdf/2004.10934.pdf.
[本文引用: 1]
[20]
GHIASI G, CUI Y, SRINIVAS A, et al. Simple copy-paste is a strong data augmentation method for instance segmentation [EB/OL]. [2022-04-07]. https://arxiv.org/pdf/2012.07177.pdf.
[本文引用: 1]
[21]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid net-works for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 2]
基于机器视觉的金属零件表面缺陷检测系统
1
2018
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
基于机器视觉的金属零件表面缺陷检测系统
1
2018
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
Machine vision and deep learning based rubber gasket defect detection
1
2020
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
基于机器视觉的导光板表面微小缺陷检测
1
2021
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
基于机器视觉的导光板表面微小缺陷检测
1
2021
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
1
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
1
... 在工业生产过程中,技术、工作条件的局限极易影响制成品的质量. 在工件的实际生产过程中,人工筛选是工件表面缺陷检测的主要方式,但这种方式存在检测结果不准确以及检测效率偏低的问题[1 ] . 为了提升工件表面缺陷的检测精度和效率,深度学习方法的研究和应用越来越具有必要性. Ho等[2 ] 利用传统机器视觉和深度学习的检测技术,开发了硅橡胶垫圈的自动光学检测系统. 该系统通过高动态范围图像捕获和图像生成技术,对缺口和残胶缺陷的预测精度分别达到100%和97%. 李璟钰等[3 ] 提出基于机器视觉的微小缺陷自动检测方法,该方法利用缺陷区域的方差特点提取缺陷大致区域,划分区域进行自适应阈值分割,通过定向阈值搜索快速确定最佳阈值. 实验结果表明,该方法能够有效地检测出细微尺寸缺陷,综合准确率达到95.72%. 戴君洁[4 ] 研究工业生产中目标物体的缺陷检测方法,选用Canny算法和形态学方法检测划痕、凹凸点,使用闭运算方法过滤不明显的独立点和痕迹,对遗留下来的明显划痕和凹凸点进行连通域区域标记. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
2
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
... 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
2
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
... 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
基于改进YOLOv5的复杂背景红外弱小目标检测算法
1
2022
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
基于改进YOLOv5的复杂背景红外弱小目标检测算法
1
2022
... 上述基于机器视觉进行缺陷检测的方法存在精确度低、检测速度慢的问题,与传统的机器学习相比,深度学习算法可以更好地提取特征,使复杂背景下不同尺度的缺陷特征检测成为可能. 深度学习模型多为以SSD[5 ] (single shot multibox detector)、YOLO[6 ] (you only look once)系列网络为代表的一阶段网络,和以R-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等网络为代表的二阶段网络. 与二阶段网络相比,一阶段网络具有推理速度快,检测能力强的优势,因此许多学者基于一阶段检测网络的结构和大小进行了研究和改进. 黄海新等[11 ] 基于YOLOv4网络提高了小物体缺陷检测的各个指标. 刘聪[12 ] 提出在检测系统中加入计算机显微视觉技术,使用基于CNN的目标检测网络对细微零件的缺陷进行检测. 陈绪浩[13 ] 提出anchor尺度自调节算法与自关注区域算法,提高了高速连接器表面缺陷检测的精确度,减少了误检. 文献[13 ]的实验证明,对于0.05~0.50 mm的微小缺陷,优化后的模型检测正确率提高到95%. 代牮等[14 ] 在YOLOv5基础上添加注意力机制,提高了算法的特征提取能力和检测效率,改进了原YOLOv5目标检测网络的损失函数和预测框的筛选方式,提高了算法对红外弱小目标检测的准确率,且漏警率、虚警率低. 上述方法虽然提高了目标检测的精度,但仍存在着高计算成本导致的检测速度慢的问题. ...
1
... 本研究在YOLOv5检测网络结构的基础上进行改进,在不显著增加计算资源的基础上,引入坐标注意力模块(coordinate attention,CA)[15 ] ,使用加权双向特征金字塔(bi-directional feature pyramid,BiFPN[16 ] )网络结构提升网络的多尺度特征融合能力,将主干网络替换为GhostNet[17 ] 模块. ...
1
... 本研究在YOLOv5检测网络结构的基础上进行改进,在不显著增加计算资源的基础上,引入坐标注意力模块(coordinate attention,CA)[15 ] ,使用加权双向特征金字塔(bi-directional feature pyramid,BiFPN[16 ] )网络结构提升网络的多尺度特征融合能力,将主干网络替换为GhostNet[17 ] 模块. ...
1
... 本研究在YOLOv5检测网络结构的基础上进行改进,在不显著增加计算资源的基础上,引入坐标注意力模块(coordinate attention,CA)[15 ] ,使用加权双向特征金字塔(bi-directional feature pyramid,BiFPN[16 ] )网络结构提升网络的多尺度特征融合能力,将主干网络替换为GhostNet[17 ] 模块. ...
2
... YOLOv5网络结构由输入端Input、主干网络Backbone、多尺度特征融合网络Neck、预测分类器Head 4个部分组成,如图1 所示. 输入端采用Mosaic数据增强、自适应锚框计算、自适应图片缩放等方法,提升了网络的检测性能. 在5.0版本官方代码中,YOLOv5的主干网络使用了Focus结构,6.0版本为了便于模型部署去除了此结构,因此6.0版本的主干网络主要由CBS (Conv+BatchNorm+SiLU)+C3+SPPF组成. YOLOv5在CSP结构基础上设计了2种CSP结构,CSP1_X结构应用于主干网络,CSP2_X结构将CSP1_X中的Resunit换成2×X 个CBS应用于Neck中;多尺度特征融合网络的网络结构沿用PANet[18 ] 的结构,自顶向下与自底向上的结构不但提取了丰富的语义特征,构造特征金字塔结构,还弥补了经过特征金字塔后丢失的目标信息. 预测分类器由3个Detect检测器组成,使用1×1卷积代替全连接层进行预测,在不同尺度的特征图上进行目标检测,3个尺度上的特征图为80×80×255、40×40×255、20×20×255,即长×宽×通道数,分别对应小、中、大目标,输出的预测结果分别对应目标框坐标、置信度和类别信息. ...
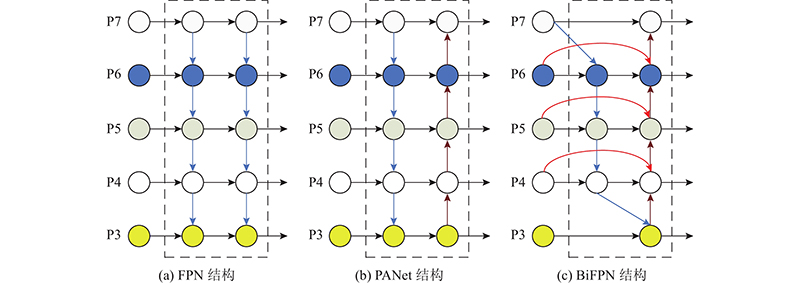
... 小目标检测一直是难点. 原因是随着卷积的深入,大物体的特征容易被保留,小目标的特征由于像素点过少常常被忽略. Lin等[21 ] 提出FPN结构,FPN的特点是可以利用经过自顶向下结构处理后的上下文信息. 对于小目标而言,FPN增加了特征映射的分辨率,即在更大的特征图上进行卷积操作,以获得更多关于小目标的有用信息. 由于FPN结构会被单向信息流限制,Liu等[18 ] 提出PANet结构,即在FPN基础上增加1条自底向上的路径,该结构证明了双向融合的有效性. ...
1
... 改进YOLOv5s网络,1)在数据增强部分使用YOLOv4[19 ] 中的Mosaic和Copy-Paste[20 ] 方法分别对数据集样本进行拼接和小目标的数量增强,使用GhostNet中的GhostBlock替换主干网络中的CSP模块,减少模型的参数量和网络计算量,在主干网络中的SPPF结构前加入坐标注意力模块,增强模型对于小目标的定位能力. 2)使用加权双向特征金字塔网络模块代替多尺度特征融合网络的PANet,进行跨尺度连接和加权特征融合,利用上下文信息提高模型的特征融合能力. 3)用Focal_Loss损失函数代替分类损失中的二元交叉熵损失函数,提升对于难样本的训练效果,用CIoU(complete intersection over union)代替定位损失中的GIoU(generalized intersection over union),使得预测框拥有更好的回归效果. ...
1
... 改进YOLOv5s网络,1)在数据增强部分使用YOLOv4[19 ] 中的Mosaic和Copy-Paste[20 ] 方法分别对数据集样本进行拼接和小目标的数量增强,使用GhostNet中的GhostBlock替换主干网络中的CSP模块,减少模型的参数量和网络计算量,在主干网络中的SPPF结构前加入坐标注意力模块,增强模型对于小目标的定位能力. 2)使用加权双向特征金字塔网络模块代替多尺度特征融合网络的PANet,进行跨尺度连接和加权特征融合,利用上下文信息提高模型的特征融合能力. 3)用Focal_Loss损失函数代替分类损失中的二元交叉熵损失函数,提升对于难样本的训练效果,用CIoU(complete intersection over union)代替定位损失中的GIoU(generalized intersection over union),使得预测框拥有更好的回归效果. ...
2
... 小目标检测一直是难点. 原因是随着卷积的深入,大物体的特征容易被保留,小目标的特征由于像素点过少常常被忽略. Lin等[21 ] 提出FPN结构,FPN的特点是可以利用经过自顶向下结构处理后的上下文信息. 对于小目标而言,FPN增加了特征映射的分辨率,即在更大的特征图上进行卷积操作,以获得更多关于小目标的有用信息. 由于FPN结构会被单向信息流限制,Liu等[18 ] 提出PANet结构,即在FPN基础上增加1条自底向上的路径,该结构证明了双向融合的有效性. ...
... 如图8 所示为包括FPN[21 ] 、PANet和BiFPN等结构的特征金字塔结构,YOLOv5中Neck部分使用的是PANet结构. 本研究使用BiFPN结构来代替PANet结构. BiFPN在PANet结构基础上进行加权双向跨尺度连接,将PANet中对特征融合贡献度较小的节点删除以简化网络结构,即那些只有1条输入边的节点,同时对于原始输入节点和输出节点处于同一水平的,增加1条额外的边,以较小的成本为代价融合更多的特征. 为了实现更优的特征融合,BiFPN将每条双向路径视为一个特征网络层,并多次重复同一层. ...













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}