

随着信息技术的迅猛发展,互联网上产生了海量的数据. 通常,这些数据存储在数据库中,并通过结构化查询语言(structured query language, SQL)之类的专门的查询语言进行查询. 但是,查询数据库需要了解数据库模式,并掌握SQL,对于普通用户而言具有一定的门槛. 在此背景下,如何通过自然语言来访问数据库中的数据成为一个热门的研究问题,而其中的关键是自然语言查询( natural language query, NLQ)翻译为SQL语句(简称为Text-to-SQL任务). 该任务已经成为了数据库和自然语言处理(natural language processing, NLP)领域的一个热门研究方向[1-2].
本研究关注金融领域的Text-to-SQL技术. 金融领域中存在大量的财务数据、股票数据,人们迫切希望能够用自然语言来查询这些数据. 与一般的领域相比,金融领域存在以下特点:1) 数据以数值型数据为主;2) 查询中数值计算非常普遍. 根据百度公司的报告[5],在商业智能报表的查询中,约80%的查询涉及到各种计算. 除了常规的求最值、求和、计数、求平均等计算外,金融领域还经常出现这样一类复杂计算,即涉及到2个或者多个元组在同一属性上取值的计算,如“国药一致2019年比2018年营业利润同比增长率是多少?”. 在文献中,这类查询称为行计算查询. 行计算查询生成SQL比较复杂. 不失一般性,假定数据库中存在一个“财务指标”表,其中包含营业利润、年份、股票名称等属性,则示例查询对应的SQL如下.
“SELECT (a.营业利润−b.营业利润) / b.营业利润
FROM (SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = “国药一致” AND 年份 = “2019”) a ,
(SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = “国药一致” AND 年份 = “2018”) b”
行计算这类查询给Text-to-SQL任务提出了挑战,现有的模型在处理这类查询时效果较差. 针对这一现状,本研究针对金融数据研究了行计算查询的Text-to-SQL任务. 由于现有数据集对金融领域,尤其是行计算的覆盖较少,本研究构造了一个针对金融领域的Text-to-SQL数据集SOFT(SQL over financial text),该数据集覆盖了金融领域的常见查询类型,包括一定数量的行计算样本. 本研究提出一个金融领域Text-to-SQL模型FinSQL,该模型采取了一种分治的方法处理行计算查询问题,即首先将一个行计算查询分解为若干个子查询,分别针对每个子查询生成SQL语句,再将子查询的SQL语句组合在一起得到原始查询的SQL语句.
1. 相关工作
已有的Text-to-SQL的研究可以分为2类:流水线方法和深度学习方法. 流水线方法的思路是将Text-to-SQL分解为多个阶段或者步骤,然后每个步骤设计相应的算法来完成. 深度学习方法将Text-to-SQL视为一个文本生成问题,用统计学习方法直接学习一个端到端的模型.
随着近年来深度学习方法在机器翻译领域取得空前的成功,越来越多的Text-to-SQL研究者把目光转向深度学习方法[10–14]. 这类方法依赖大量的训练数据,其中包括数据库模式和大量的<NLQ, SQL>对,从中学习模型,实现从NLQ到SQL的转换. 这类方法一般是端到端的,或者其中的关键部分是一个黑盒模型,从而与流水线方法形成鲜明的对比. 目前,基于统计学习的Text-to-SQL方法大都采用编码器-解码器(encoder-decoder)框架. 在这类模型中,编码器负责产生NLQ和数据库模式的表示,解码器则根据编码器得到的表示来生成SQL. 与一般机器翻译不同的是,Text-to-SQL的输入包括自然语言问题和数据库模式,模型须理解问题在数据库的哪些表和列上进行查询,触发了哪些SQL操作;此外,在生成SQL查询时要保证生成的语句满足语法规则并且语义正确. 基于深度学习的Text-to-SQL方法须解决2大问题:1) 如何对NLQ和数据库模式之类的输入信息进行编码,并将问题和数据库模式进行对齐;2) 如何利用规则或语法指导生成SQL.
研究人员提出了多个Text-to-SQL标注数据集. 早期的数据集如ATIS[15]和GeoQuery[16]较简单. 目前,使用较广泛的数据集有WikiSQL[3]和Spider[4]. WikiSQL每个数据库只包含一张表,不包含排序、分组、子查询等复杂操作,所以相对较简单. 目前,这一数据集上最优模型的准确率已经超过了90%. Spider是一个包含多个数据库的多领域数据集,覆盖了分组、排序、多表连接查询、嵌套查询等复杂操作,对模型的跨领域、生成复杂SQL的能力提出了新的要求,目前的最佳模型也不到70%的准确率. 这2个数据集都是英文数据集. 中文数据集目前有CSpider[17]和TableQA[18].
总的来说,目前Text-to-SQL任务已经取得长足进展,在一些小规模数据集上有不错的表现. 但是也存在一些不足,主要表现在:1) 一些垂直领域上的Text-to-SQL研究不够深入. 虽然WikiSQL、Spider、DuSQL等数据集覆盖了很多领域,但是每个领域的样本不够丰富,使得模型在垂直领域表现不够好; 2) 查询类型以简单查询为主,对于复杂查询覆盖不够全面,例如对于行计算查询支持不够好.
2. 金融领域Text-to-SQL数据集构建
构建一个金融领域Text-to-SQL中文数据集SOFT. 该数据集具有鲜明的领域特点,查询类型更加丰富,总体难度较高,对Text-to-SQL形成了更大的挑战.
2.1. 数据集构建
通过国泰安数据库获取了国内A股上市公司2010—2020年的多种数据,包括公司基本信息、财务指标信息、财务比率信息、股票交易信息等. 根据这些信息构建了一个上市公司财务数据库.
为了构建自然语言查询,在东方财富网、巨潮资讯网、新浪财经等财经网站上搜集了210个问题,基于这些实际问题人工构造了<NLQ, SQL>对. 在数据集构建过程中考虑了以下3个方面. 1) 对于每个表,要求提供的SQL查询覆盖到以下所有SQL关键字:SELECT、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT、JOIN、INTERSECT、EXCEPT、 UNION、NOT IN、OR、AND、EXISTS、LIKE以及嵌套查询. 2) 考虑到中文表达方式的多样化,对于每个问题,都设计了至少2种表达方式. 3) 在标注过程中团队定期对现有数据集进行检查,以确保数据集的正确性.
表 1 SOFT数据集示例
Tab.1
| 查询问题 | SQL语句 |
| 查询2019年资本公积不少于100 亿的公司的员工人数,列出公司名称和员工人数. | SELECT T1.公司名称 , T1.员工人数 FROM 公司基本信息 AS T1 JOIN 财务指标 AS T2 ON T1. 股票代码 = T2.股票代码 WHERE T2.资本公积 >= 10000000000 AND T2.年份 = "2019" |
| 查询2018年每股净资产 不低于10的公司名称. | SELECT 公司名称 FROM 公司基本信息 WHERE 股票代码 IN (SELECT 股票代码 FROM 财务比率 WHERE 每股净资产 >= 10 AND 年份 = "2018") |
| 国药一致2019年相比于2018年营业利润的同比增长率怎么样? | SELECT (a.营业利润 − b.营业利润) / b.营业利润 FROM (SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2019") a , (SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2018") b |
表 2 各数据集查询类型占比
Tab.2
| 数据集 | p/% | ||||
| 排序 | 分组 | 嵌套 | 行计算 | 列计算 | |
| WikiSQL | 0 | 0 | 0 | 0 | 0 |
| TableQA | 0 | 0 | 0 | 0 | 0 |
| Spider/CSpider | 13.1 | 14.6 | 8.3 | 0 | 0.3 |
| SOFT | 14.3 | 12.2 | 7.7 | 12.1 | 2.5 |
2.2. 现有方法在SOFT数据集上的比较
表 3 SOFT数据集模型的精确匹配率
Tab.3
| 模型 | Pre | ||||
| easy | medium | hard | extra hard | all | |
| SyntaxSQLNet | 0.514 | 0.383 | 0.296 | 0.235 | 0.340 |
| SLSQL | 0.825 | 0.677 | 0.536 | 0.495 | 0.613 |
| RYANSQL | 0.874 | 0.725 | 0.662 | 0.613 | 0.695 |
为了进一步说明这3个模型在行计算查询上的表现,以一个样本为例进行比较,如表4所示. 可以发现,3个模型都预测失败,说明现有模型在行计算查询上存在较大不足.
表 4 部分数据集模型预测结果对比
Tab.4
| 模型 | 查询问题“国药一致2019年相比于2018年营业利润的同比增长率是多少?”对应的预测结果 |
| SyntaxSQLNet | SELECT 营业利润 FROM 财务比率 WHERE 股票名称 = "terminal" AND 年份 = "terminal" |
| SLSQL | SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2019" |
| RYANSQL | SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2019" |
| 标准查询 | SELECT (a.营业利润 − b.营业利润) / b.营业利润 FROM (SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2019") a , (SELECT 营业利润 FROM 财务指标 WHERE 股票名称 = "国药一致" AND 年份 = "2018") b |
由于RYANSQL[14]是目前Text-to-SQL任务中表现最好的模型之一,本研究将以RYANSQL作为基础模型,提出面向金融数据的Text-to-SQL模型FinSQL,特别针对包含行计算类查询的金融数据查询进行优化.
3. 面向金融数据的Text-to-SQL模型
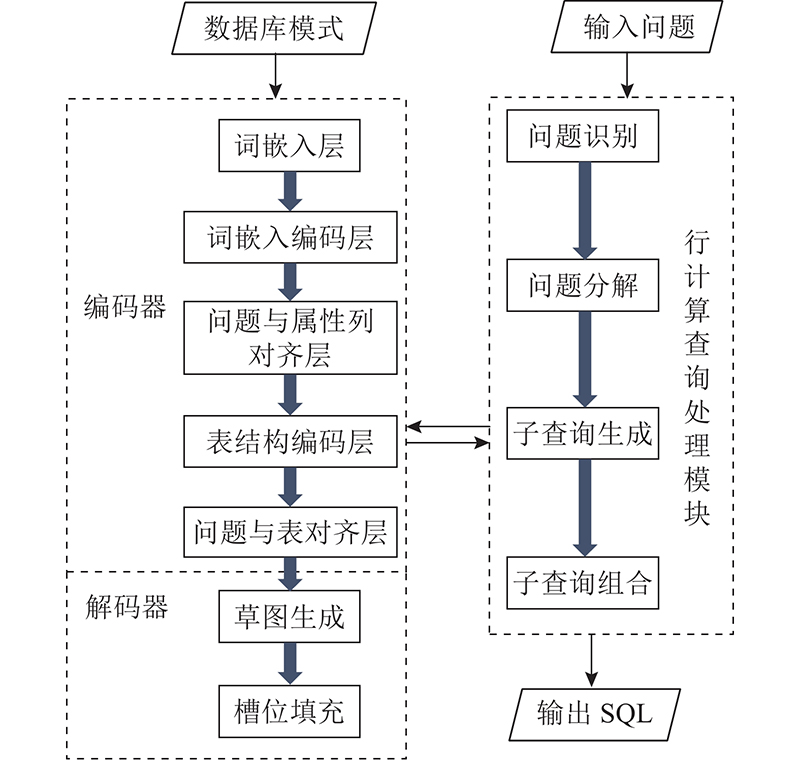
图 1
3.1. 问题描述
一个自然语言查询(NLQ)可以表示为Q={q1, q2
Text-to-SQL任务可以定义为:给定自然语言查询Q和数据库模式S,生成SQL语句sql.
很多查询须用嵌套的SQL来表达. 对于一个嵌套的SQL查询sql,用其变体形式即M(sql)={(P1, S1)
3.2. 模型概述
本研究模型FinSQL由编码器(encoder)、解码器(decoder)和行计算查询处理模块3大模块组成,其结构图如图1所示. 对于输入的自然语言查询,首先进行问题识别和问题分解,然后将子问题和数据库模式送到编码器和解码器,生成子查询SQL,将子查询进行组合得到完整的SQL. 编码器和解码器借用RYANSQL模型中的相应模块,这2个模块的构建使得模型可以处理如分组排序查询、连接查询、嵌套查询等大部分查询类型,同时也可以处理行计算查询问题所涉及的子查询问题.
3.2.1. 编码器
编码器的输入包括问题、表名和属性列名以及SQL位置码,其中SQL位置码是由上一级的语句块产生的,而最外层语句块的SQL位置码为“none”. 编码器由如下5层构成.
1) 词嵌入层:对于问题、表名和属性列名,分别获取其字符级词向量. 每个SQL位置码产生一个词向量.
2) 词嵌入编码层:使用卷积神经网络和全连接层产生问题、表名及属性名的编码,在问题和SQL位置向量的基础上产生SQL位置编码.
3) 问题与属性列的对齐层:使用注意力机制和Transformer对编码后的问题和属性列向量进行处理,目的是为了加强它们之间的对齐.
4) 表结构编码层:对属于同一表格的属性列编码,使用自注意力机制来融合属性之间的信息.
5) 问题与表的对齐层:和问题与属性列的对齐层类似,其目的是加强问题和表之间的对齐.
最后编码层输出如下:问题编码、各列编码、表编码、SQL位置编码和数据库模式编码.
3.2.2. 解码器
将编码层输出的问题编码、数据库模式编码和SQL位置编码连接,使用2个全连接层对11个变量进行预测. 这11个变量分别对应SQL语句的各基本结构,包括是否存在GROUP BY、是否存在ORDER BY、是否存在LIMIT、是否存在WHERE、是否存在HAVING、GROUP BY中的条件数量(≤3)、ORDER BY中的条件数量(≤3)、SELECT中的条件数量(≤6)、WHERE中的条件数量(≤4)、HAVING中的条件数量(≤2)、是否存在IUE(INTERSECT, UNION, EXPECT). 每个SQL语句都必须有SELECT和FROM,因此无须对它们进行预测.
在完成11个变量的预测后,即可得到一个草图(sketch).在草图的基础上,对其中的槽位(slot)进行填充,如表5所示. 表中,
表 5 各个组件可能的槽位值
Tab.5
| 组件 | 槽位 |
| FROM | ($TBL)+ |
| SELECT | $DIST( $AGG ( $DIST1 $AGG1 $COL1 $ARI $DIST2 $AGG2 $COL2 ) )+ |
| ORDER BY | (($DIST1 $AGG1 $COL1 $ARI $DIST2 $AGG2 $COL2) $ORD )* |
| GROUP BY | ($COL)* |
| LIMIT | $NUM |
| WHERE、 HAVING | ($CONJ ( $DIST1 $AGG1 $COL1 $ARI $DIST2 $AGG2 $COL2 ) $NOT $COND $VAL1|$SEL1 $VAL2|$SEL2 )* |
| INTERSECT、 UNION、 EXPECT | $SEL |
3.3. 行计算查询处理
为了处理行计算类型的查询,提出基于分治的方法,该方法遵循“问题识别-问题分解-子查询生成-结果组装”的思路.
3.3.1. 问题识别
本研究将行计算查询的识别问题视为文本分类任务,即识别一个问题是否为行计算类型的查询. 使用BERT预训练模型微调实现. BERT模型将文本中的每个字的嵌入(embedding)作为模型输入;模型输出则是输入对应的融合上下文语义信息后的向量表示. 模型输入除了字向量,还包含文本片段嵌入和位置嵌入. 文本片段嵌入用于刻画文本的全局语义信息,并与单字/词的语义信息相融合. 为了描述位置信息,BERT模型对不同位置的字/词分别附加一个不同的向量. 最后,BERT模型将字嵌入、文本片段嵌入和位置嵌入的加和作为模型输入.
对于文本分类任务,BERT模型在文本前插入一个[CLS]标记,并将该标记对应的输出向量h作为整篇文本的语义表示,输入一个softmax分类器进行分类.
3.3.2. 问题分解
这一步对行计算型查询问题进行分解. 例如,将问题“平安银行2020年相比于2019年主营业务收入同步增长多少?”分解为2个子问题. Q1:平安银行2020年主营业务收入是多少?Q2:平安银行2019年主营业务收入是多少?
一个查询问题中的不同部分对应于不同成分,有些成分是共同的,但是有些成分是并列的,根据这些成分可以将其进行分解. 例如上面例子中的成分如下所示: 平安银行(S) 2020年(X)相比于 2019年(X) 主营业务收入(S) 同步增长(R)多少?其中,下划线标出的是其中的重要成分,括号中是成分的类型, S表示共有成分,X表示独有成分,R表示计算操作成分. 在查询分解的时候,首先识别出问题中的成分,如下划线部分;然后识别成分类型,即S、X还是R;最后进行子问题求解和组合.
1) 成分识别. 本研究将成分识别视为实体识别问题. 一个金融查询包含的实体有以下类型:机构名称、时间、人物、地点、事件、指标(如主营业务收入). 为了识别这些实体,首先基于领域词典进行分词操作. 从财经网站上抽取了大量行业信息,构造了领域词典,包括领域内行业字典、财务指标字典、上市公司事件(如分红、减持)字典等. 根据这些领域字典,对文本进行分词. 使用BERT-CRF模型来进行实体识别. BERT-CRF模型[19]是在BERT模型[20]后添加一层CRF线性层. BERT可以充分地挖掘文本的语义信息,CRF可以进一步考虑实体标签间存在的依赖关系,两者结合可以有效提升序列标注的准确率. 实体识别得到的每个实体就是一个成分.
2) 成分分类. 下一步将成分分类为3种类型:共有成分(S)、独有成分(X)和计算操作成分(R). 为了完成分类,尝试2种分类方法.
第1种是启发式分类,根据一个实体的类型和在问题中的语义角色来识别. 具体来说,给定一个实体,如果在句子中不存在与其相同类型的其他实体,那么该实体是共有成分;如果2个实体E1和E2属于相同类型,而且2个实体在句子的语法分析树中的语义角色是相同的,那么这2个实体都是属于独有成分.
第2种方案是使用模型进行分类. 注意到在文本序列中某些成分之间存在相关性,于是通过双向LSTM(Bi-LSTM)模型来进行分类,其中模型的输入是实体类型构成的序列,输出是对应的成分类别构成的序列,每个实体对应一个类别.
上述得到的实体中没有包含计算操作成分. 对实际的查询进行分析,金融领域的行计算查询的计算操作一般分为以下5种类型:变化量计算(如计算增长)、变化率计算(如计算增长率)、比率计算(如计算主营业务收入占比)、求和(如计算前2个季度营收之和)、求积(如计算总市值). 而且,与其他成分不同的是,计算操作的分类须用到整个句子. 例如:“X公司2021年的销售费用相比于去年是上升了还是下降了?幅度多大?”在这个例子中,须用到前面的“上升”“下降”“幅度”来共同判断计算操作的类型.
由于一个查询只对应一个计算操作成分,用分类的思想来识别计算操作类型. 具体来说,构造了双向LSTM模型来获得问题中每个字的上下文编码,然后使用注意力机制来使得模型能够自动关注问题中的重点词汇. 注意力机制产生的编码r再输入到softmax分类器,实现计算操作的分类.
3) 问题分解. 基于问题中包含的成分和类型,可以将一个查询分解到若干个子查询. 完整的分解算法如下.
输入: 自然语言查询问题Q
输出: 分解后的子问题集合
对Q进行预处理(如停用词消除和分词)和实体识别,得到
for each oi
if oi 不是一个值也不是一个模式项(如表名、列名)
移除oi
令q0=
for each oi
if oi 是一个实体
识别oi的成分类型,记为ci
if oi为实体且ci为共有成分,或者oi是一个token
for each q∈SQ
将 oi 加入到q
elseif ci为独有成分
令q′=q0, 将 oi 加入到 q′
elseif ci为独有成分
令q′=q0, 将 oi 加入到 q′
令SQ = SQ ∪ {q′}
移除q0
返回SQ
算法的基本思想如下:将原始问题分解为若干子问题,原始问题中的共有成分和非实体在每个子问题中重复,而独有成分则分散在各个子问题中,使得一个子问题只包含一个独有成分. 例如,“X公司2021年的销售费用相比于去年是上升了还是下降了?幅度多大?”这个查询经过前4步处理后得到“X公司 2021年 销售费用 去年”. 注意,“上升”“下降”“幅度”这些词语在这一算法中没有使用,但是在其他环节中发挥了作用. 这里“X公司”是共有成分,“2021年”和“去年”是独有成分,于是分解得到2个子查询:“X公司 2020年 销售费用”和“X公司 销售费用 去年”.
3.3.3. 子查询组合
在问题分解的基础上,使用训练完成的编码器和解码器模块对子问题处理,生成对应的SQL查询,这一过程不再细述.
在产生了各个SQL子查询后,将它们组合起来,得到一个完整的SQL查询. 这里须考虑以下问题.
1) 计算操作的类型. 前面已经提到如何识别查询的计算操作类型.
2) 计算的方向. 假定sql1和sql2表示q1和q2对应的SQL语句,对于变化量计算、变化率计算和比率计算这3种计算问题来说,有2种不同的计算方向,如sql1相对于sql2的变化量,还是sql2相对于sql1的变化量. 对于这一问题,可以利用题中的线索,如“A相比于
3) 排序要求(ORDER BY)、返回行数限制(LIMIT n). 为了判别这2个子句是否存在,参考文献[12],单独构造2个分类器,根据原问题进行判别.
4) 组合规则. 根据行计算查询类型,制定了不同的组合规则,如表6所示. 其中“sql1”和“sql2”表示子问题的SQL语句,“col1”和“col2”分别表示“sql1”和“sql2”中要查询的属性列.
表 6 问题类型与组合规则
Tab.6
| 行计算问题类型 | 规则 |
| 变化问题 | select a.col1 − b.col2 from sql1 a, sql2 b |
| 变化率问题 | select (a.col1 − b.col2) / b.col2 from sql1 a, sql2 b |
| 比率问题 | select a.col1 / b.col2 from sql1 a, sql2 b |
| 求和问题 | select a.col1+b.col2 from sql1 a, sql2 b |
| 乘积问题 | select a.col1 * b.col2 from sql1 a, sql2 b |
4. 实 验
4.1. 评价指标
Text-to-SQL任务的评价指标主要包括2种:精确匹配率(exact matching accuracy)和执行准确率 (execution accuracy).
精确匹配率直接比较生成的SQL语句与标准SQL语句的结构. 为了避免顺序问题造成的误判,例如WHERE子句中条件的顺序、投影列的顺序,SQL语句被拆解成SELECT、WHERE、GROUP BY等组件,将每个组件的各成分以集合的形式表示,并依次比较对应集合. 例如,对于SELECT组件“SELECT avg (col1), max (col2), min (col1)”,首先将其表示为集合“(avg, min, col1), (max, col2)”,再与标准查询的集合进行比较. 仅当所有组件都与标准查询一致时,预测的查询才是正确的. 执行准确率比较给定数据库中2个SQL查询的执行结果,当预测查询与标准查询的执行结果一致时,认为预测查询是正确的.
精确匹配率的计算较简单,而执行准确率的计算则需要数据库实例的支持. 目前WikiSQL数据集和TableQA数据集支持2个评价指标,而Spider、CSpider仅支持精确匹配率. 本研究数据集与前文保持一致,采用精确匹配率这一评价指标.
4.2. 实验环境及参数
实验环境如下:显卡为GeForce GTX 1080Ti,内存和显存均为16 G.操作系统为Ubuntu 18.0.4,Python版本为3.6.3,Tensorflow版本为1.14.
由于硬件设备限制,本研究所采用的BERT版本为BERT-base,层数为12,隐藏层为768,注意力头为12,参数为110 M.模型训练参数设置如下:batch_size为4,learn_rate为e−5,dropout为0.5,epoch为50.
4.3. 实验结果与分析
4.3.1. 问题识别模型
表 7 问题识别实验结果
Tab.7
| 模型 | P | Re | F1 |
| FastText | 0.916 | 0.893 | 0.904 |
| TextRNN | 0.923 | 0.901 | 0.912 |
| BERT | 0.935 | 0.916 | 0.925 |
4.3.2. 问题分解
表 8 问题分解实验结果对比
Tab.8
| 模型 | P | Re | F1 |
| BiLSTM-CRF+Heu | 0.816 | 0.753 | 0.783 |
| BiLSTM-CRF+Model | 0.875 | 0.837 | 0.856 |
| BERT-CRF+Heu | 0.887 | 0.852 | 0.869 |
| BERT-CRF+Model | 0.902 | 0.873 | 0.887 |
4.3.3. 模型综合比较
为了与本研究所提模型FinSQL进行综合性能的比较,选取了2个主流的Text-to-SQL模型,分别为SLSQL和RYANSQL.实验数据集是本研究提出的Text-to-SQL金融领域数据集SOFT,其中70%用于训练,30%用于测试. 采取的评价指标是精确匹配率. 实验结果如表9所示.
表 9 Text-to-SQL模型实验结果对比
Tab.9
| 模型 | Pre | ||||
| easy | medium | hard | extra hard | all | |
| SLSQL | 0.825 | 0.677 | 0.536 | 0.495 | 0.613 |
| RYANSQL | 0.874 | 0.725 | 0.662 | 0.613 | 0.695 |
| FinSQL | 0.874 | 0.804 | 0.785 | 0.682 | 0.781 |
为了显示模型在不同难度的查询上的生成能力,按照惯例将样本分为4个级别:容易(easy)、中等(medium)、难(hard)、很难(extra hard). 划分的依据是SQL语句所包含SQL组件的数量、要查询的列的数量,以及WHERE中条件的数量. 从实验结果可知:1) 3个模型中,SLSQL的整体准确率是最低的,为0.613,它在“hard”和“extra hard”难度的数据集上的准确率分别为0.536和0.495.从预测有误的结果来看,SLSQL在处理嵌套查询、行计算查询之类的复杂查询上的能力不足. RYANSQL相比于SLSQL在整体准确率上提升了0.082,达到0.695,而且在各个难度级别上都有较大的提升. 2) 本研究提出的FinSQL模型是3个模型中整体准确率最高的,达到0.781,比RYANSQL高出0.086. 特别在后3种难度的数据集上,FinSQL相比于RYANSQL在准确率上都有不小提升.
为了进一步了解模型在行计算查询上的表现,专门抽取SOFT数据集的部分行计算查询构造一个子集SOFT-rc,分析这个数据集上的结果. 由于SLSQL和RYANSQL并不支持行计算,只显示FinSQL模型的结果,如表10所示. 可以看出,行计算查询的总体准确率为0.713,在一般难度级别上的表现令人满意. 行计算查询的难度级别都在“medium”以上,因此没有显示“easy”级别的结果.
表 10 FinSQL模型在SOFT-rc上的实验结果
Tab.10
| 难度 | Pre | 难度 | Pre | |
| medium | 0.806 | extra hard | 0.571 | |
| hard | 0.742 | all | 0.713 |
为了更好地比较不同模型对于行计算查询处理的差异,选取了一个实例进行分析,如表11所示. 从3个模型的预测结果来看,SLSQL和RYANSQL都只能生成该问题所涉及的一个子查询,无法得出完整的结果,而只有本研究模型FinSQL给出了正确的预测结果.
表 11 部分数据集模型预测结果对比
Tab.11
| 模型 | 查询问题“给出平安银行2020年与2019年主营业务收入之和. ”对应的预测结果 |
| SLSQL | SELECT 主营业务收入 FROM 财务指标 WHERE 股票名称 = "平安银行" AND 年份 = "2020" |
| RYANSQL | SELECT 主营业务收入 FROM 财务指标 WHERE 股票名称 = "平安银行" AND 年份 = "2020" |
| FinSQL | SELECT a.主营业务收入+b.主营业务收入 FROM (SELECT 主营业务收入 FROM 财务指标 WHERE 股票名称 = "平安银行" AND 年份 = "2020") a, (SELECT 主营业务收入 FROM 财务指标 WHERE 股票名称 = "平安银行" AND 年份 = "2019") b |
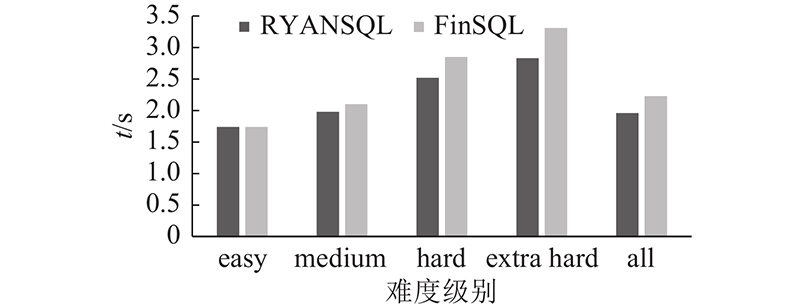
图 2
5. 结 语
本研究关注金融领域的Text-to-SQL问题,提出了一个覆盖了行计算查询之类的复杂查询的金融领域Text-to-SQL任务数据集SOFT,构建了金融领域Text-to-SQL模型FinSQL,提出了一种基于分治的方法处理行计算查询. 实验结果表明,所提出的方法大幅提升了SOFT数据集上的SQL生成的准确率,可以较好地支持行计算查询.下一步计划对较复杂的行计算查询的SQL生成继续进行优化.
参考文献
自然语言生成多表SQL查询语句技术研究
[J].DOI:10.3778/j.issn.1673-9418.1908025 [本文引用: 1]
Research on technology of generating multi-table SQL query statement by natural language
[J].DOI:10.3778/j.issn.1673-9418.1908025 [本文引用: 1]
基于深度学习的数据库自然语言接口综述
[J].DOI:10.7544/issn1000-1239.2021.20200209 [本文引用: 1]
Survey on deep learning based natural language interface to database
[J].DOI:10.7544/issn1000-1239.2021.20200209 [本文引用: 1]
Constructing an interactive natural language interface for relational databases
[J].
RYANSQL: recursively applying sketch-based slot fillings for complex Text-to-SQL in cross-domain databases
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}