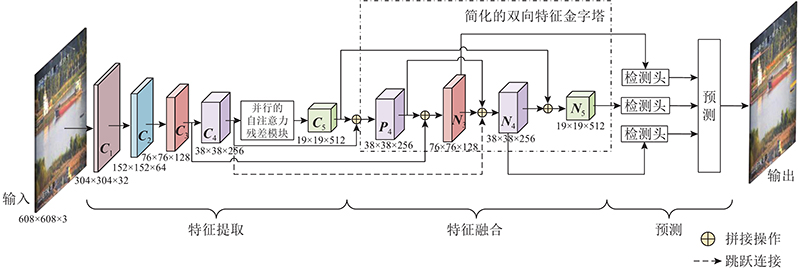
YOLOv5s分为3个部分,分别为特征提取、特征融合和预测. 在特征提取时,基线算法通过下采样操作获得多尺度特征 $ {{\boldsymbol{C}}_i},i = 3,4,5 $ . 在特征融合时,基线算法使用双向FPN结构融合多尺度特征. 双向FPN结构包含2个多尺度特征金字塔,分别为 $ {{\boldsymbol{P}}_i},i = 3,4,5 $ $ {{\boldsymbol{N}}_i},i = 3,4,5 $ . 本研究基于YOLOv5s提出MHSA-YOLO算法,整体结构如图1 所示. 对YOLOv5s的改进主要包含3个部分,分别为 PARM、跳跃连接、简化的双向特征金字塔结构. 在获取 $ {{\boldsymbol{C}}_5} $ $ {{\boldsymbol{C}}_4} $ $ {{\boldsymbol{N}}_4} $ $ {{\boldsymbol{P}}_3} $ $ {{\boldsymbol{P}}_5} $
[1]
ZHANG T W, ZHANG X L, SHI J, et al Depthwise separable convolution neural network for high-speed SAR ship detection
[J]. Remote Sensing , 2019 , 11 (21 ): 2483
DOI:10.3390/rs11212483
[本文引用: 1]
[2]
ZHANG T W, ZHANG X L Injection of traditional hand-crafted features into modern CNN-based models for SAR ship classification: what, why, where, and how
[J]. Remote Sensing , 2021 , 13 (11 ): 2091
DOI:10.3390/rs13112091
[本文引用: 1]
[3]
徐诚极, 王晓峰, 杨亚东 Attention-YOLO: 引入注意力机制的YOLO检测算法
[J]. 计算机工程与应用 , 2019 , 55 (6 ): 13 - 23
[本文引用: 1]
XU Cheng-ji, WANG Xiao-feng, YANG Ya-dong Attention-YOLO: YOLO detection algorithm that introduces attention mechanism
[J]. Computer Engineering and Applications , 2019 , 55 (6 ): 13 - 23
[本文引用: 1]
[4]
OKSUZ K, CAM B C, KALKAN S, et al Imbalance problems in object detection: a review
[J]. IEEE Transactions on Pattern Analysis Machine Intelligence , 2021 , 43 (10 ): 3388 - 3415
DOI:10.1109/TPAMI.2020.2981890
[本文引用: 1]
[6]
汤丽丹. 基于图像的无人船目标检测研究[D]. 哈尔滨: 哈尔滨工业大学, 2018.
[本文引用: 1]
TANG Li-dan. Research on object detection of USV based on images [D]. Harbin: Harbin Institute of Technology, 2018.
[本文引用: 1]
[7]
SHAO Z, WANG L, WANG Z, et al Saliency-aware convolution neural network for ship detection in surveillance video
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2020 , 30 (3 ): 781 - 794
DOI:10.1109/TCSVT.2019.2897980
[本文引用: 1]
[8]
LI H, DENG L B, YANG C, et al Enhanced YOLO v3 tiny network for real-time ship detection from visual image
[J]. IEEE Access , 2021 , 9 : 16692 - 16706
DOI:10.1109/ACCESS.2021.3053956
[本文引用: 1]
[9]
甘兴旺, 魏汉迪, 肖龙飞, 等 基于视觉的船舶环境感知数据融合算法研究
[J]. 中国造船 , 2021 , 62 (2 ): 201 - 210
DOI:10.3969/j.issn.1000-4882.2021.02.018
[本文引用: 1]
GAN Xing-wang, WEI Han-di, XIAO Long-fei, et al Research on vision-based data fusion algorithm for environment perception of ships
[J]. Shipbuilding of China , 2021 , 62 (2 ): 201 - 210
DOI:10.3969/j.issn.1000-4882.2021.02.018
[本文引用: 1]
[10]
FENG Y C, DIAO W H, SUN X, et al Towards automated ship detection and category recognition from high-resolution aerial images
[J]. Remote Sensing , 2019 , 11 (16 ): 1901
DOI:10.3390/rs11161901
[本文引用: 1]
[11]
KIM M, JEONG J, KIM S ECAP-YOLO: efficient channel attention pyramid YOLO for small object detection in aerial image
[J]. Remote Sensing , 2021 , 13 (23 ): 4851
DOI:10.3390/rs13234851
[本文引用: 1]
[12]
CHEN L Q, SHI W X, DENG D X Improved YOLOv3 based on attention mechanism for fast and accurate ship detection in optical remote sensing images
[J]. Remote Sensing , 2021 , 13 (4 ): 660
DOI:10.3390/rs13040660
[本文引用: 1]
[13]
YU J M, ZHOU G Y, ZHOU S B, et al A fast and lightweight detection network for multi-scale SAR ship detection under complex backgrounds
[J]. Remote Sensing , 2021 , 14 (1 ): 31
DOI:10.3390/rs14010031
[本文引用: 1]
[14]
LIN Z H, FENG M W, NOGUEIRA C, et al. A structured self-attentive sentence embedding [EB/OL]. [2021-09-17]. https://arxiv.org/abs/1703.03130.pdf.
[本文引用: 1]
[15]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: NIPS, 2017: 5998-6008.
[本文引用: 1]
[16]
SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 16514-16524.
[本文引用: 1]
[17]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 937-944.
[本文引用: 1]
[18]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[19]
ZHANG Y, SHENG W, JIANG J, et al Priority branches for ship detection in optical remote sensing images
[J]. Remote Sensing , 2020 , 12 (7 ): 1196
[本文引用: 1]
[20]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10781-10790.
[本文引用: 1]
[21]
SHAO Z F, WU W J, WANG Z Y, et al SeaShips: a large-scale precisely annotated dataset for ship detection
[J]. IEEE Transactions on Multimedia , 2018 , 20 (10 ): 2593 - 2604
DOI:10.1109/TMM.2018.2865686
[本文引用: 10]
[22]
ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence . New York: AAAI, 2020: 12993-13000.
[本文引用: 1]
[23]
赵玉蓉, 郭会明, 焦函, 等 融合混合域注意力的YOLOv4在船舶检测中的应用
[J]. 计算机与现代化 , 2021 , (9 ): 75 - 82
DOI:10.3969/j.issn.1006-2475.2021.09.012
[本文引用: 2]
ZHAO Yu-rong, GUO Hui-ming, JIAO Han, et al Application of YOLOv4 with mixed-domain attention in ship detection
[J]. Computer and Modernization , 2021 , (9 ): 75 - 82
DOI:10.3969/j.issn.1006-2475.2021.09.012
[本文引用: 2]
[24]
LEI S L, LU D D, QIU X L, et al SRSDD-v1.0: a high-resolution SAR rotation ship detection dataset
[J]. Remote Sensing , 2021 , 13 (24 ): 5104
DOI:10.3390/rs13245104
[本文引用: 1]
[25]
RODGER M, GUIDA R Classification-aided SAR and AIS data fusion for space-based maritime surveillance
[J]. Remote Sensing , 2020 , 13 (1 ): 104
DOI:10.3390/rs13010104
[本文引用: 1]
[26]
LIU J M, CHEN H, WANG Y Multi-source remote sensing image fusion for ship target detection and recognition
[J]. Remote Sensing , 2021 , 13 (23 ): 4852
DOI:10.3390/rs13234852
[本文引用: 1]
[27]
FAHIMEH F, HEIKKONEN J Deep learning based multi-modal fusion architectures for maritime vessel detection
[J]. Remote Sensing , 2020 , 12 (16 ): 2509
DOI:10.3390/rs12162509
[本文引用: 1]
Depthwise separable convolution neural network for high-speed SAR ship detection
1
2019
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Injection of traditional hand-crafted features into modern CNN-based models for SAR ship classification: what, why, where, and how
1
2021
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Attention-YOLO: 引入注意力机制的YOLO检测算法
1
2019
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Attention-YOLO: 引入注意力机制的YOLO检测算法
1
2019
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Imbalance problems in object detection: a review
1
2021
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
基于改进的Faster R-CNN船舶目标检测算法
1
2020
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
基于改进的Faster R-CNN船舶目标检测算法
1
2020
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
1
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
1
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Saliency-aware convolution neural network for ship detection in surveillance video
1
2020
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Enhanced YOLO v3 tiny network for real-time ship detection from visual image
1
2021
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
基于视觉的船舶环境感知数据融合算法研究
1
2021
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
基于视觉的船舶环境感知数据融合算法研究
1
2021
... 建立装备现代化、管理信息化、巡航搜救立体化的水上支持保障系统,特别是研发智能无人船舶,是我国迈向海运强国必然要求[1 -2 ] . 船舶目标检测是无人船舶应用中的关键技术. 区别于传感器探测,船舶目标检测有针对性地进行目标检测,具有较广的探测范围和较好的实时性. 随着深度神经网络在计算机视觉中的深入应用,卷积神经网络(convolutional neural network, CNN)成为目标检测的有力工具[3 -4 ] . 基于CNN的船舶目标检测算法具有自动学习船舶特征、挖掘图像信息的特点. 齐亮等[5 ] 基于Faster R-CNN利用场景窄化和层级窄化网络减少目标搜索区域,在降低算法计算开销的同时,有效抑制了大部分背景区域的干扰. 汤丽丹[6 ] 针对Faster R-CNN对小目标检测精度较低的问题,循环利用网络结构中的浅层多细节特征、深层强语义特征优化小目标检测效果. Shao等[7 ] 提出的算法融合了显著性图、深度语义特征及海岸线信息,在保证良好实时性的同时获得了较高的检测精度,但该算法对小尺度及存在明显背景干扰的船舶目标检测效果不理想. Li等[8 ] 针对大型船舶易受岸上建筑、复杂海浪和水面光线干扰的问题,在YOLOv3的基础上引入注意力模块CBAM,牺牲少量精度使算法的检测速度大幅提升,但该算法对于复杂背景下的船舶目标检测效果提升不明显,对于小尺度目标的检测效果依旧不理想. 甘兴旺等[9 ] 针对船舶目标位置预测不精准的问题,结合雷达、船舶自动识别系统(automatic identification system, AIS)数据与YOLOv3算法提出船舶环境感知数据融合算法,减少天气对检测精度的干扰,但多种数据融合在一定程度上降低了算法的检测速度. ...
Towards automated ship detection and category recognition from high-resolution aerial images
1
2019
... 虽然上述算法可以实现基于可见光图像的船舶目标检测,但是对于内河中的船舶检测存在如下挑战. 1)船舶目标多样性. 不同于远海船舶,内河船舶具有类间尺寸差异较大、纵横比较大、目标尺寸较小的特征. 现有方法大多采用预设锚框结构,无法适应所有尺寸目标[10 ] . 不仅如此,现有算法对纵横比较大的目标还存在重检问题. 此外,卷积、池化操作带来的目标特征信息损失常常导致小目标的误检、漏检问题的出现[11 -12 ] . 2)复杂背景. 相比海洋,内河的复杂背景会对船舶检测造成影响. 特别是当目标重叠、与复杂背景重叠和光线较暗、能见度较低造成的成像效果较差时,算法难以从背景中分离目标并提取目标特征信息[13 ] . ...
ECAP-YOLO: efficient channel attention pyramid YOLO for small object detection in aerial image
1
2021
... 虽然上述算法可以实现基于可见光图像的船舶目标检测,但是对于内河中的船舶检测存在如下挑战. 1)船舶目标多样性. 不同于远海船舶,内河船舶具有类间尺寸差异较大、纵横比较大、目标尺寸较小的特征. 现有方法大多采用预设锚框结构,无法适应所有尺寸目标[10 ] . 不仅如此,现有算法对纵横比较大的目标还存在重检问题. 此外,卷积、池化操作带来的目标特征信息损失常常导致小目标的误检、漏检问题的出现[11 -12 ] . 2)复杂背景. 相比海洋,内河的复杂背景会对船舶检测造成影响. 特别是当目标重叠、与复杂背景重叠和光线较暗、能见度较低造成的成像效果较差时,算法难以从背景中分离目标并提取目标特征信息[13 ] . ...
Improved YOLOv3 based on attention mechanism for fast and accurate ship detection in optical remote sensing images
1
2021
... 虽然上述算法可以实现基于可见光图像的船舶目标检测,但是对于内河中的船舶检测存在如下挑战. 1)船舶目标多样性. 不同于远海船舶,内河船舶具有类间尺寸差异较大、纵横比较大、目标尺寸较小的特征. 现有方法大多采用预设锚框结构,无法适应所有尺寸目标[10 ] . 不仅如此,现有算法对纵横比较大的目标还存在重检问题. 此外,卷积、池化操作带来的目标特征信息损失常常导致小目标的误检、漏检问题的出现[11 -12 ] . 2)复杂背景. 相比海洋,内河的复杂背景会对船舶检测造成影响. 特别是当目标重叠、与复杂背景重叠和光线较暗、能见度较低造成的成像效果较差时,算法难以从背景中分离目标并提取目标特征信息[13 ] . ...
A fast and lightweight detection network for multi-scale SAR ship detection under complex backgrounds
1
2021
... 虽然上述算法可以实现基于可见光图像的船舶目标检测,但是对于内河中的船舶检测存在如下挑战. 1)船舶目标多样性. 不同于远海船舶,内河船舶具有类间尺寸差异较大、纵横比较大、目标尺寸较小的特征. 现有方法大多采用预设锚框结构,无法适应所有尺寸目标[10 ] . 不仅如此,现有算法对纵横比较大的目标还存在重检问题. 此外,卷积、池化操作带来的目标特征信息损失常常导致小目标的误检、漏检问题的出现[11 -12 ] . 2)复杂背景. 相比海洋,内河的复杂背景会对船舶检测造成影响. 特别是当目标重叠、与复杂背景重叠和光线较暗、能见度较低造成的成像效果较差时,算法难以从背景中分离目标并提取目标特征信息[13 ] . ...
1
... 注意力机制主要根据上下文内容或像素间的相关性快速提取数据、图像中的重要特征. Lin等[14 ] 提出自注意力机制,并将其应用于双向LSTM的隐层. 自注意力机制改进了注意力机制,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性. 自Vaswani等[15 ] 提出单头自注意力和MHSA后,自注意力成为研究热点. ...
1
... 注意力机制主要根据上下文内容或像素间的相关性快速提取数据、图像中的重要特征. Lin等[14 ] 提出自注意力机制,并将其应用于双向LSTM的隐层. 自注意力机制改进了注意力机制,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性. 自Vaswani等[15 ] 提出单头自注意力和MHSA后,自注意力成为研究热点. ...
1
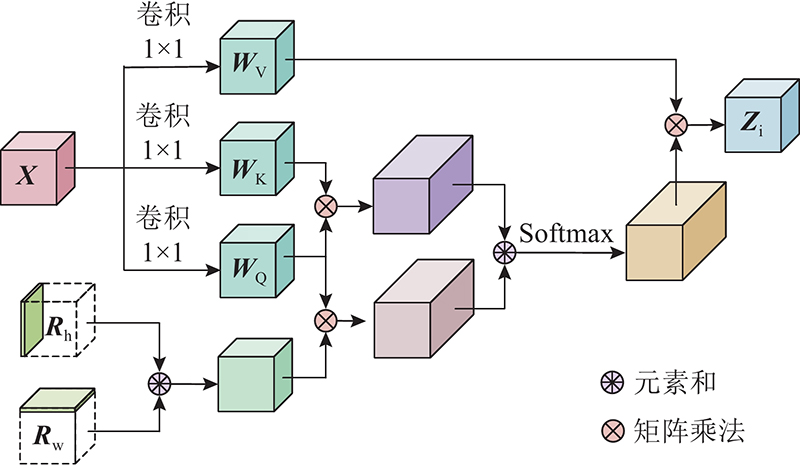
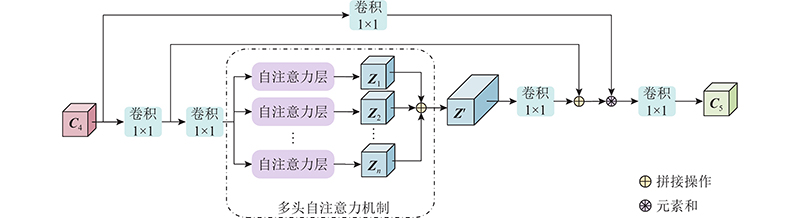
... YOLOv5的基础主干网络与特征融合部分均采用由卷积层与残差模块合并而成的模块C3,通过控制残差模块数量调整网络深度. 引入C3使网络轻量化,不仅降低了计算瓶颈和内存成本,也提高了网络特征提取与特征融合能力. 但C3对网络特征提取能力的提升有限,特别是在提取复杂背景或光线较暗的特征时,由于提取难度较大,存在漏检、误检现象. 考虑到特征层 $ {{\boldsymbol{C}}_5} $ [16 ] 结构,将基线算法中用于获取 $ {{\boldsymbol{C}}_5} $ 图2 所示的自注意力层并联而成,其中 $ {\boldsymbol{X}} $ $ {{\boldsymbol{Z}}_i},i = 1,2,\cdots,n $
1
... 残差结构有利于提升算法的特征学习能力,本研究引入MHSA的同时保持了原有C3的残差结构,构成如图3 所示的PARM结构. PARM根据特征相关性,为特征分配权重:较关键的目标特征分配较大权重,不相关背景特征分配较小权重. PARM能够强化目标、弱化背景,减少复杂背景对目标检测的干扰,特别是对小尺度目标及成像效果较差情况下的检测精度有提升效果[17 ] . PARM的计算式为 ...
1
... 在传统自上而下的FPN结构中,信息只能单向传递,网络特征的融合能力较差. 针对背景较为复杂情况下的目标特征不突出、融合性能需求高的问题,基线算法的特征融合借鉴PANet[18 ] ,在FPN基础上增加特征金字塔结构,并加入自下而上的路径聚合网络(path aggregation network,PAN)结构,形成如图4 所示的双向特征融合网络. 与FPN结构通过上采样操作实现强语义特征的传递与融合不同,加入自下而上特征金字塔的FPN结构通过下采样操作实现强定位特征的传递与融合. 双向特征金字塔聚合多层主干层的特征检测,提高了网络的特征提取能力. 特征融合部分的改进分为2步:1)删除YOLOv5中的 $ {{\boldsymbol{P}}_3} $ $ {{\boldsymbol{P}}_5} $ . 这些特征层只有1条输入边,对特征融合贡献较少. 2)在 $ {{\boldsymbol{N}}_4} $ $ {{\boldsymbol{C}}_4} $ [19 ] . 但是PAN和FPN增加了各网络层的联系,跨层融合使得网络参数与计算量增加. 如图5 所示,为了减少计算量,MHSA-YOLO参考BiFPN[20 ] 结构简化YOLOv5双向特征金字塔为 ...
Priority branches for ship detection in optical remote sensing images
1
2020
... 在传统自上而下的FPN结构中,信息只能单向传递,网络特征的融合能力较差. 针对背景较为复杂情况下的目标特征不突出、融合性能需求高的问题,基线算法的特征融合借鉴PANet[18 ] ,在FPN基础上增加特征金字塔结构,并加入自下而上的路径聚合网络(path aggregation network,PAN)结构,形成如图4 所示的双向特征融合网络. 与FPN结构通过上采样操作实现强语义特征的传递与融合不同,加入自下而上特征金字塔的FPN结构通过下采样操作实现强定位特征的传递与融合. 双向特征金字塔聚合多层主干层的特征检测,提高了网络的特征提取能力. 特征融合部分的改进分为2步:1)删除YOLOv5中的 $ {{\boldsymbol{P}}_3} $ $ {{\boldsymbol{P}}_5} $ . 这些特征层只有1条输入边,对特征融合贡献较少. 2)在 $ {{\boldsymbol{N}}_4} $ $ {{\boldsymbol{C}}_4} $ [19 ] . 但是PAN和FPN增加了各网络层的联系,跨层融合使得网络参数与计算量增加. 如图5 所示,为了减少计算量,MHSA-YOLO参考BiFPN[20 ] 结构简化YOLOv5双向特征金字塔为 ...
1
... 在传统自上而下的FPN结构中,信息只能单向传递,网络特征的融合能力较差. 针对背景较为复杂情况下的目标特征不突出、融合性能需求高的问题,基线算法的特征融合借鉴PANet[18 ] ,在FPN基础上增加特征金字塔结构,并加入自下而上的路径聚合网络(path aggregation network,PAN)结构,形成如图4 所示的双向特征融合网络. 与FPN结构通过上采样操作实现强语义特征的传递与融合不同,加入自下而上特征金字塔的FPN结构通过下采样操作实现强定位特征的传递与融合. 双向特征金字塔聚合多层主干层的特征检测,提高了网络的特征提取能力. 特征融合部分的改进分为2步:1)删除YOLOv5中的 $ {{\boldsymbol{P}}_3} $ $ {{\boldsymbol{P}}_5} $ . 这些特征层只有1条输入边,对特征融合贡献较少. 2)在 $ {{\boldsymbol{N}}_4} $ $ {{\boldsymbol{C}}_4} $ [19 ] . 但是PAN和FPN增加了各网络层的联系,跨层融合使得网络参数与计算量增加. 如图5 所示,为了减少计算量,MHSA-YOLO参考BiFPN[20 ] 结构简化YOLOv5双向特征金字塔为 ...
SeaShips: a large-scale precisely annotated dataset for ship detection
10
2018
... 采用武汉大学发布的新型大型船舶数据集Seaships[21 ] . Seaships有图片31 455张,以常见船舶类型为标签,分为1)矿石船(ore carrier,OC)、2)散货船(bulk cargo carrier, BCC)、3)普通货船(general cargo ship, GCS)、4)集装箱船(container ship, CS)、5)渔船(fishing boat, FB)、6)客船(passenger ship, PS). 每类标签的数量较平均,类间尺度相差较大. 选用公开的、主要表现内河航道与入海口中船舶的7 000张尺寸为1 920×1080的图片作为实验数据集. 实验数据集标签1)~6)的实例数分别为2 199、1 505、1 952、2 190、901、474个. 实验数据集被分为训练集、测试集、验证集,图片数分别为4 500、1 500、1 000. 将经过训练的模型在测试集中验证得到模型的平均均值精度p ma 、精度p 、正确率a 、召回率r 和其他性能参数,并基于验证集验证模型的泛化能力. MHSA-YOLO使用自适应锚框,无需根据目标尺寸设置锚框尺度. ...
... Comparison of ship detection results of different convolutional neural network
Tab.2 算法 p ma /% p a /% OC BCC GCS CS FB PS Faster(VGG16)[21 ] 90.12 89.44 90.34 90.73 90.87 88.76 90.57 Faster(ResNet18)[21 ] 90.63 90.37 89.78 90.45 90.91 87.17 88.93 Faster(ResNet50)[21 ] 91.65 92.38 90.88 92.46 92.91 89.27 90.93 Faster(ResNet101)[21 ] 92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94
实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
90.63 90.37 89.78 90.45 90.91 87.17 88.93 Faster(ResNet50)[21 ] 91.65 92.38 90.88 92.46 92.91 89.27 90.93 Faster(ResNet101)[21 ] 92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
91.65 92.38 90.88 92.46 92.91 89.27 90.93 Faster(ResNet101)[21 ] 92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
21 ]
79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
1
... 损失函数反映预测值与真实值的差异,常作为衡量模型学习质量的重要指标,损失函数越小代表预测值与真实值差异越小,也就是模型学习更充分、学习能力更强. YOLOv5中包含3种损失函数:分类损失、定位损失、置信度损失,总损失为三者加权和. 定位损失主要有4种IoU系列损失函数,YOLOv5使用的Complete IoU (CIoU)[22 ] 损失函数通过增加参数,多维度分析预测框和真实框的差异,解决了边界框宽高比的尺度问题,锚框预测效果较好. 如图6 所示为YOLOv5s与MHSA-YOLO在学习过程中的总损失曲线. 图中,L 为算法总损失值,N 为迭代次数. 在训练前期,2种算法的总损失均急速下降,但YOLOv5s下降速度更快;相比之下,加入自注意力机制后,模型损失函数下降速度减缓,MHSA-YOLO的损失函数收敛较慢、学习速度较慢. 在训练中后期,MHSA-YOLO的总损失值较小,特别是在迭代次数大于90次时. 实验结束表明,与基线算法相比,MHSA-YOLO具有更好的学习能力,学习到的目标特征更多,达到的检测效果更好. ...
融合混合域注意力的YOLOv4在船舶检测中的应用
2
2021
... Comparison of ship detection results of different convolutional neural network
Tab.2 算法 p ma /% p a /% OC BCC GCS CS FB PS Faster(VGG16)[21 ] 90.12 89.44 90.34 90.73 90.87 88.76 90.57 Faster(ResNet18)[21 ] 90.63 90.37 89.78 90.45 90.91 87.17 88.93 Faster(ResNet50)[21 ] 91.65 92.38 90.88 92.46 92.91 89.27 90.93 Faster(ResNet101)[21 ] 92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94
实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
23 ]
90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
融合混合域注意力的YOLOv4在船舶检测中的应用
2
2021
... Comparison of ship detection results of different convolutional neural network
Tab.2 算法 p ma /% p a /% OC BCC GCS CS FB PS Faster(VGG16)[21 ] 90.12 89.44 90.34 90.73 90.87 88.76 90.57 Faster(ResNet18)[21 ] 90.63 90.37 89.78 90.45 90.91 87.17 88.93 Faster(ResNet50)[21 ] 91.65 92.38 90.88 92.46 92.91 89.27 90.93 Faster(ResNet101)[21 ] 92.40 93.68 90.22 93.87 93.41 89.96 91.78 SSD300(MobileNet)[21 ] 77.66 64.77 76.69 87.43 90.77 71.00 75.32 SSD300(VGG16)[21 ] 79.37 75.03 76.66 87.66 90.71 71.79 74.35 SSD512(VGG16)[21 ] 86.73 83.99 83.00 87.08 90.81 85.85 89.65 YOLOv2 random=0[21 ] 77.51 83.01 79.36 80.60 88.90 62.70 70.48 YOLOv2 random=1[21 ] 79.06 83.16 82.07 83.21 88.31 64.74 72.89 YOLOv3[23 ] 87.00 86.00 86.20 87.10 87.10 88.00 90.00 YOLOv4[23 ] 90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94
实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
... [
23 ]
90.70 90.80 90.70 90.80 90.90 90.60 90.50 MHSA-YOLO 97.59 98.73 98.42 96.41 96.53 98.51 96.94 实验数据表明,MHSA-YOLO在整体检测精度上大幅提升(p ma =97.59%,比基于ResNet101网络的Faster提升0.051 9),解决了小目标(渔船的p a =98.51%,比YOLOv4提升0.079 1)与复杂背景下的目标(矿石船、散货船的p a >98%)检测精度较低的问题. ...
SRSDD-v1.0: a high-resolution SAR rotation ship detection dataset
1
2021
... (3)本研究的重点是提升基于可见光图像的船舶检测精度. 一方面,对于智能无人船舶,遥感图像与海事地图是其环境感知的重要依据,单一的可见光图像检测并不全面[24 -25 ] . 另一方面,检测障碍物(礁石、桥墩)和可航行区域对规划船舶行驶路线至关重要. 未来计划融合多种图像检测技术,通过多视角检测提高船舶检测的准确性和实时性[26 -27 ] ,在单个网络中实现同时检测船舶、航标、障碍物和可行驶区域. ...
Classification-aided SAR and AIS data fusion for space-based maritime surveillance
1
2020
... (3)本研究的重点是提升基于可见光图像的船舶检测精度. 一方面,对于智能无人船舶,遥感图像与海事地图是其环境感知的重要依据,单一的可见光图像检测并不全面[24 -25 ] . 另一方面,检测障碍物(礁石、桥墩)和可航行区域对规划船舶行驶路线至关重要. 未来计划融合多种图像检测技术,通过多视角检测提高船舶检测的准确性和实时性[26 -27 ] ,在单个网络中实现同时检测船舶、航标、障碍物和可行驶区域. ...
Multi-source remote sensing image fusion for ship target detection and recognition
1
2021
... (3)本研究的重点是提升基于可见光图像的船舶检测精度. 一方面,对于智能无人船舶,遥感图像与海事地图是其环境感知的重要依据,单一的可见光图像检测并不全面[24 -25 ] . 另一方面,检测障碍物(礁石、桥墩)和可航行区域对规划船舶行驶路线至关重要. 未来计划融合多种图像检测技术,通过多视角检测提高船舶检测的准确性和实时性[26 -27 ] ,在单个网络中实现同时检测船舶、航标、障碍物和可行驶区域. ...
Deep learning based multi-modal fusion architectures for maritime vessel detection
1
2020
... (3)本研究的重点是提升基于可见光图像的船舶检测精度. 一方面,对于智能无人船舶,遥感图像与海事地图是其环境感知的重要依据,单一的可见光图像检测并不全面[24 -25 ] . 另一方面,检测障碍物(礁石、桥墩)和可航行区域对规划船舶行驶路线至关重要. 未来计划融合多种图像检测技术,通过多视角检测提高船舶检测的准确性和实时性[26 -27 ] ,在单个网络中实现同时检测船舶、航标、障碍物和可行驶区域. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}