[2]
ZOU Y, DU D, CHANG B, et al Automatic weld defect detection method based on Kalman filtering for real-time radiographic inspection of spiral pipe
[J]. NDT&E International , 2015 , 72 : 1 - 9
[本文引用: 1]
[3]
BEARD M D, LOWE M J S Non-destructive testing of rock bolts using guided ultrasonic waves
[J]. International Journal of Rock Mechanics and Mining Sciences , 2003 , 40 (4 ): 527 - 536
DOI:10.1016/S1365-1609(03)00027-3
[4]
TITMAN D J Applications of thermography in non-destructive testing of structures
[J]. NDT&E International , 2001 , 34 (2 ): 149 - 154
[5]
LU Q Y, WONG C H Applications of non-destructive testing techniques for post-process control of additively manufactured parts
[J]. Virtual and Physical Prototyping , 2017 , 12 (4 ): 301 - 321
DOI:10.1080/17452759.2017.1357319
[本文引用: 1]
[6]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580-587.
[本文引用: 1]
[7]
HE K, ZHANG X, REN S, et al Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
[8]
GIRSHICK R. Fast R-CNN [J]. 2015 IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440-1448.
[本文引用: 1]
[9]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[10]
DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems . Barcelona: [s. n.], 2016: 379-387.
[本文引用: 1]
[11]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2961-2969.
[本文引用: 1]
[12]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 1]
[13]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7263-7271.
[14]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/1804.02767.pdf.
[15]
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/2004.10934v1.pdf.
[本文引用: 1]
[16]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multiBox detector [C]// European Conference on Computer Vision 2016 . [S. l.]: Springer, 2016: 21-37.
[本文引用: 1]
[17]
FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/1701.06659.pdf .
[18]
LI Z, ZHOU F. FSSD: feature fusion single shot multibox detector [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/1712.00960.pdf.
[本文引用: 1]
[19]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// 2017 IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 2]
[20]
王鹏. 基于机器视觉的钢球表面缺陷检测系统[D]. 哈尔滨: 哈尔滨理工大学, 2005.
[本文引用: 1]
WANG Peng. Surface defect detect system of steel ball based on machine vision [D]. Harbin: Harbin University of Science and Technology, 2005.
[本文引用: 1]
[21]
陈琦. 基于机器视觉的滑动轴承内表面缺陷自动检测系统的研究[D]. 镇江: 江苏大学, 2017.
[本文引用: 1]
CHEN Qi. Research on automatic detection system of inner surface defects of sliding bearing based on machine vision [D]. Zhenjiang: Jiangsu University, 2017.
[本文引用: 1]
[22]
KUNAKORNVONG P, TANGKONGKIET C, SOORAKSA P. Defect detection on air bearing surface with gray level co-occurrence matrix [C]// The 4th Joint International Conference on Information and Communication Technology, Electronic and Electrical Engineering . Chiang Rai: IEEE, 2014: 1-4.
[本文引用: 1]
[23]
DENG S, CAI W, XU Q, et al. Defect detection of bearing surfaces based on machine vision technique [C]// 2010 International Conference on Computer Application and System Modeling . Taiyuan: IEEE, 2010: V4−548−V4−554.
[本文引用: 1]
[24]
李维刚, 叶欣, 赵云涛, 等 基于改进YOLOv3算法的带钢表面缺陷检测
[J]. 电子学报 , 2020 , (7 ): 1284 - 1292
DOI:10.3969/j.issn.0372-2112.2020.07.006
[本文引用: 1]
LI Wei-gang, YE Xin, ZHAO Yun-tao, et al Strip steel surface defect detection based on improved YOLOv3 algorithm
[J]. Acta Electronica Sinica , 2020 , (7 ): 1284 - 1292
DOI:10.3969/j.issn.0372-2112.2020.07.006
[本文引用: 1]
[26]
李浪怡, 刘强, 邹一鸣, 等 基于改进YOLOv5算法的轨面缺陷检测
[J]. 五邑大学学报: 自然科学版 , 2021 , 35 (3 ): 43 - 48
[本文引用: 1]
LI Lang-yi, LIU Qiang, ZOU Yi-ming, et al Rail surface defect detection based on improved YOLOv5 algorithm
[J]. Journal of Wuyi University: Natural Science Edition , 2021 , 35 (3 ): 43 - 48
[本文引用: 1]
[27]
JIN R, NIU Q Automatic fabric defect detection based on an improved YOLOv5
[J]. Mathematical Problems in Engineering , 2021 , 7321394
[本文引用: 1]
[28]
ZHAO Z, YANG X, ZHOU Y, et al Real-time detection of particleboard surface defects based on improved YOLOV5 target detection
[J]. Scientific Reports , 2021 , 11 : 21777
DOI:10.1038/s41598-021-01084-x
[本文引用: 1]
[29]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International conference on machine learning . Lille: [s. n.], 2015: 448-456.
[本文引用: 1]
[30]
BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/1607.06450.pdf.
[本文引用: 1]
[31]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 1]
[32]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Lake City: IEEE, 2018: 8759-8768.
[本文引用: 1]
[33]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. [2021-10-08]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 1]
我国轴承制造技术的现状及其发展趋势
1
2005
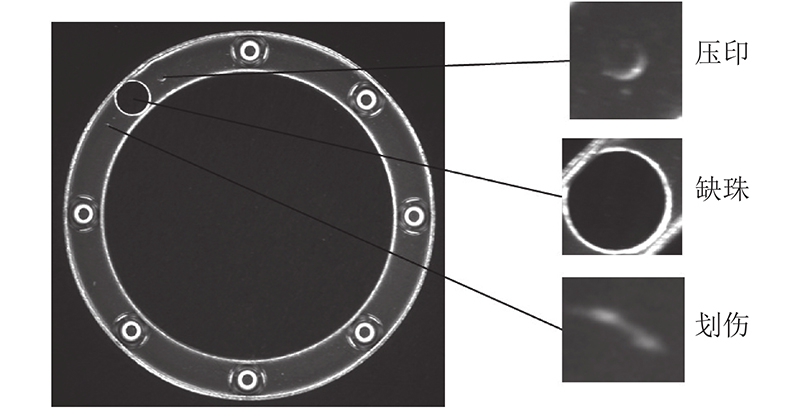
... 轴承影响机械设备的稳定性和使用寿命,它的主要作用是支撑和传递力[1 ] . 推力球轴承由座圈、轴圈和钢球保持架组成,广泛应用于减速变速装置,该类轴承运转时能够承受单面轴向载荷. 缺珠、压印、划伤是加工钢球保持架时常见的3类表面缺陷. 缺珠缺陷会导致推力球轴承受力不均,使设备无法正常工作;压印、划伤缺陷影响着推力球轴承的使用寿命;为此,人们在轴承加工过程中设置了检测环节. ...
我国轴承制造技术的现状及其发展趋势
1
2005
... 轴承影响机械设备的稳定性和使用寿命,它的主要作用是支撑和传递力[1 ] . 推力球轴承由座圈、轴圈和钢球保持架组成,广泛应用于减速变速装置,该类轴承运转时能够承受单面轴向载荷. 缺珠、压印、划伤是加工钢球保持架时常见的3类表面缺陷. 缺珠缺陷会导致推力球轴承受力不均,使设备无法正常工作;压印、划伤缺陷影响着推力球轴承的使用寿命;为此,人们在轴承加工过程中设置了检测环节. ...
Automatic weld defect detection method based on Kalman filtering for real-time radiographic inspection of spiral pipe
1
2015
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
Non-destructive testing of rock bolts using guided ultrasonic waves
0
2003
Applications of thermography in non-destructive testing of structures
0
2001
Applications of non-destructive testing techniques for post-process control of additively manufactured parts
1
2017
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
2
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
... [19 ]处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
1
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于改进YOLOv3算法的带钢表面缺陷检测
1
2020
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于改进YOLOv3算法的带钢表面缺陷检测
1
2020
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于图像融合与YOLOv3的铝型材表面缺陷检测
1
2020
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于图像融合与YOLOv3的铝型材表面缺陷检测
1
2020
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于改进YOLOv5算法的轨面缺陷检测
1
2021
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
基于改进YOLOv5算法的轨面缺陷检测
1
2021
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
Automatic fabric defect detection based on an improved YOLOv5
1
2021
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
Real-time detection of particleboard surface defects based on improved YOLOV5 target detection
1
2021
... 射线检测、超声检测、磁粉检测、热成像检测等无损检测技术[2 -5 ] 已被应用于产品表面缺陷检测,有越来越多的研究者将目光投向光学检测. 光学检测具有无接触、检测速度快、检测灵敏度高等优点. 光学检测中的热门的目标检测算法有R-CNN[6 ] 、SPP-Net[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、RFCN[10 ] 、Mask R-CNN[11 ] 、Detect-Net、Over-Feat、YOLO系列[12 -15 ] 、SSD系列[16 -18 ] 、RetinaNet[19 ] 等. 利用深度学习可以解决轴承表面缺陷成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等原因造成的检测困难问题. 王鹏[20 ] 提出改进的Canny边缘算子提取钢球表面缺陷,解决了传统边缘提取对边缘信息的平滑问题和算法抗干扰能力低的问题. 陈琦[21 ] 使用区域形态学和图像减法提取轴承内表面的缺陷特征,并使用支持向量机(support vector machines,SVM)分类器完成对缺陷的分类. Kunakornvong等[22 ] 提出变化亮度的空气轴承缺陷检测方法,利用共生矩阵使空气轴承图像免受亮度变化的干扰,通过4个识别特征定义特征参数,并根据每个识别的欧几里得距离选择的阈值进行缺陷检测. Deng等[23 ] 提出自动检测轴承表面系统,使用最小二乘拟合和环形扫描定位轴承的检测区域,通过对比度增强和低通滤波提高图像质量,应用对象检查判断是否存在缺陷,利用形状特征完成缺陷识别,最后在U-Net网络中加入注意力机制以完成磁片的表面缺陷检测. 李维刚等[24 ] 用加权K-means聚类算法优化先验框参数,通过融合浅层与深层特征,提高对带刚表面缺陷的检测精度. 张磊等[25 ] 借鉴SLAM中特征提取匹配的思想,使用K-means聚类算法优化原始图像和预处理后的图像,采用YOLOv3检测铝型材表面缺陷. 李浪怡等[26 ] 使用Ghost Bottleneck模块替换YOLOv5网络中的Bottleneck,在网络中添加SElayer注意力机制以提高模型对大目标缺陷的检测能力,实现了轨面缺陷检测. Jin等[27 ] 在YOLOv5网络的基础上引入teacher-student网络架构对模型进行蒸馏压缩,采用焦点损失函数[19 ] 处理数据不均衡的问题,提出用多任务学习策略进行织物缺陷检测. Zhao等[28 ] 结合伽马射线变换法和图像差分法处理光照不均匀的问题,在YOLOv5网络的Neck端,用深度卷积(DWConv)替换原卷积来压缩网络参数,完成了对刨花板表面缺陷的检测. ...
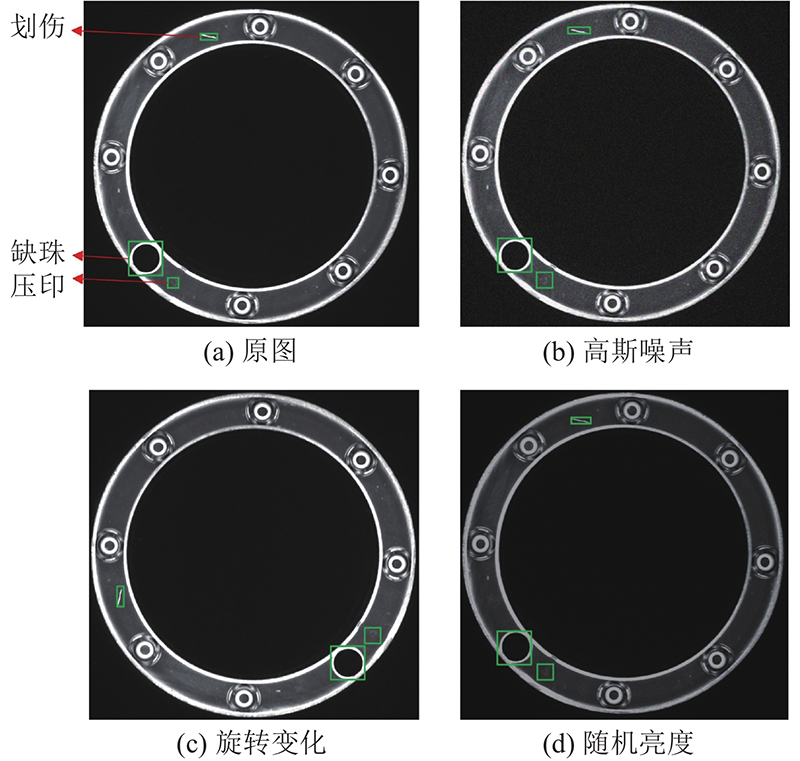
1
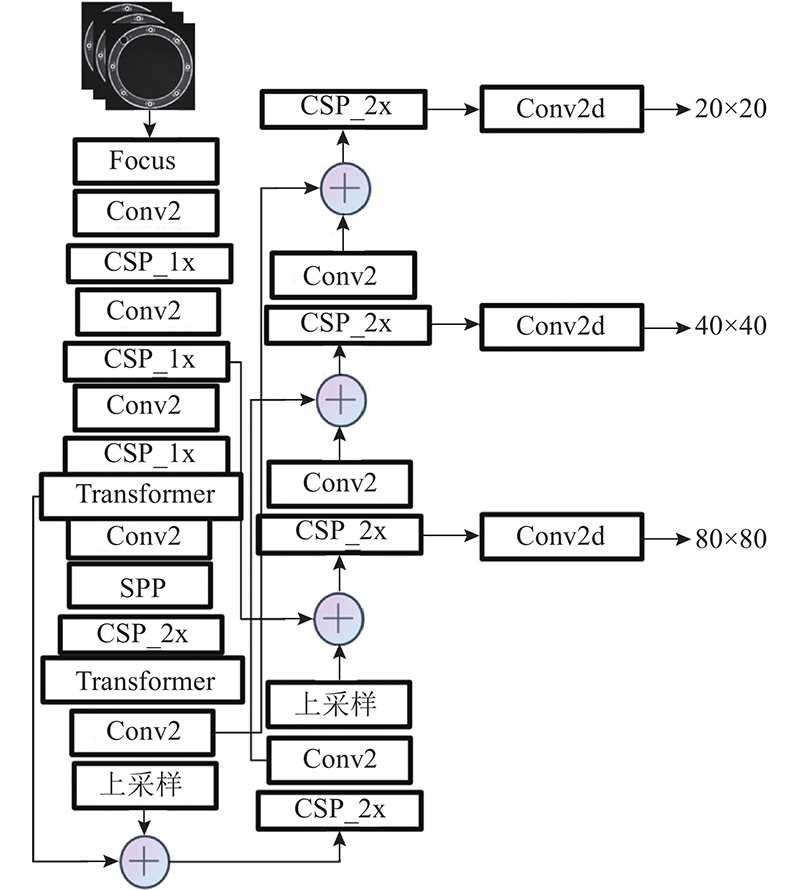
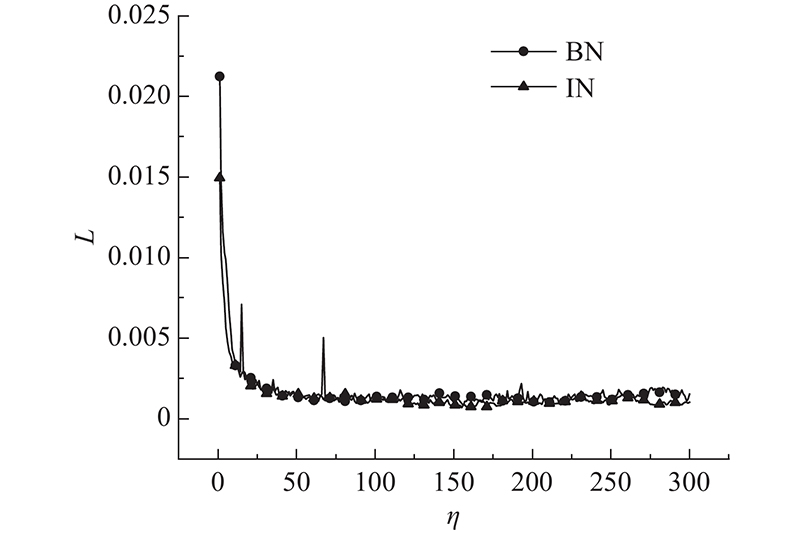
... 本研究以推力球轴承为检测对象,通过实验平台采集轴承缺陷图片,对训练集部分划伤和压印缺陷样本进行数据增强. 以YOLOv5s网络模型为网络主体,引入自动裁剪提取目标区域的图像预处理模块,在特征提取网络中添加双层改进Transformer多头自注意力机制模块,强化网络对中小目标的特征提取,使用批量归一化(batch normalization,BN)[29 ] 代替实例归一化(instance normalization, IN)[30 ] 来加快网络的收敛速度. ...
1
... 本研究以推力球轴承为检测对象,通过实验平台采集轴承缺陷图片,对训练集部分划伤和压印缺陷样本进行数据增强. 以YOLOv5s网络模型为网络主体,引入自动裁剪提取目标区域的图像预处理模块,在特征提取网络中添加双层改进Transformer多头自注意力机制模块,强化网络对中小目标的特征提取,使用批量归一化(batch normalization,BN)[29 ] 代替实例归一化(instance normalization, IN)[30 ] 来加快网络的收敛速度. ...
1
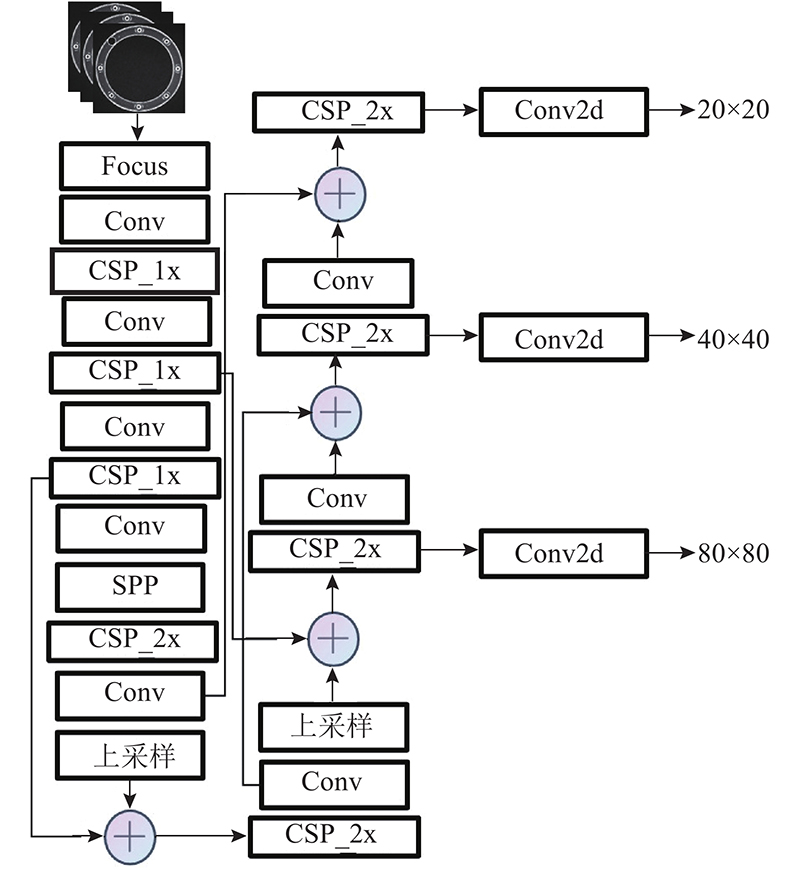
... YOLOv5由输入端、主干网络、颈部和头部组成. 1)输入端将4张图片以随机缩放、随机裁剪和随机排布的方式拼接,进行数据增强并且提升网络的训练速度. 2)经过Focus切片,进入由CSPDarkNet组成的主干网络,从输入图像中提取丰富的特征. 3)由特征金字塔网络(feature pyramid networks,FPN)[31 ] 和路径聚合网络(path aggregation network,PAN)[32 ] 结构组成的颈部不同尺度特征融合,由网络的头部输出端进行预测,输出端使用分类损失函数和回归损失函数. YOLOv5的结构如图1 所示,其中Conv模块由卷积层、归一化函数和激活函数组成,CSP_1x模块由Conv模块、残差网络模块以及卷积层组成,CSP_2x由卷积层和x 个残差网络模块组合而成. ...
1
... YOLOv5由输入端、主干网络、颈部和头部组成. 1)输入端将4张图片以随机缩放、随机裁剪和随机排布的方式拼接,进行数据增强并且提升网络的训练速度. 2)经过Focus切片,进入由CSPDarkNet组成的主干网络,从输入图像中提取丰富的特征. 3)由特征金字塔网络(feature pyramid networks,FPN)[31 ] 和路径聚合网络(path aggregation network,PAN)[32 ] 结构组成的颈部不同尺度特征融合,由网络的头部输出端进行预测,输出端使用分类损失函数和回归损失函数. YOLOv5的结构如图1 所示,其中Conv模块由卷积层、归一化函数和激活函数组成,CSP_1x模块由Conv模块、残差网络模块以及卷积层组成,CSP_2x由卷积层和x 个残差网络模块组合而成. ...
1
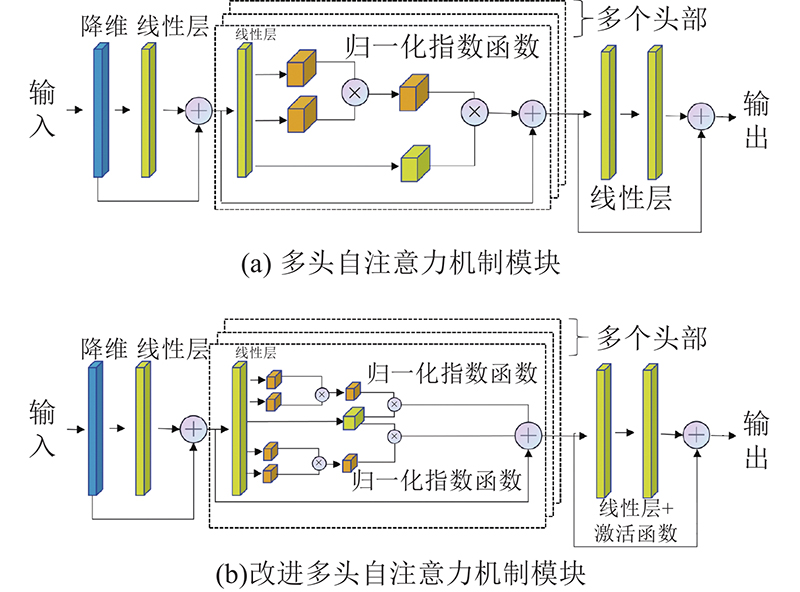
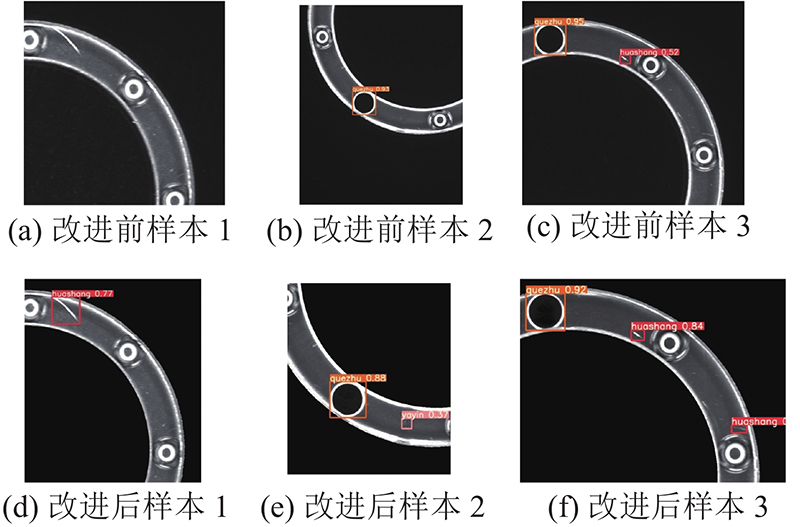
... 多头自注意力机制模块借鉴了如图3 所示的Vision Transformer[33 ] . 该研究将图像分割成9个图像块,将这些图像块的线性嵌入序列作为Transformer的输入,输入到由多头自注意力机制和多层感知机模块组成的编码器,再经过线性层和分类后输出. 虽然Transformer模块的处理速度较快,能够极大提升网络对特征的提取能力,但是Transformer模块的每个自注意力机制需要3个线形层查询(query)、键(key)、值(value)的输入. 查询、键通过点乘和归一化指数函数(SoftMax)运算计算每个通道得分,值保留着原图片各个通道的信息,将每个通道得分与值矩阵相乘得到自注意力机制模块的输出,输出中忽略了无关噪声信息而关注重点信息.多头注意力机制模块是由多个自注意力机制叠加而成的. 每个自注意力机制中的值参数极度相似,对每个头部使用不同的值会造成计算浪费,多头自注意力机制在输出前经过的2个简单的线性层对模型的表达能力提升效果不大. 如图4 所示,本研究改进Transformer模块:1)每个头部共用同一层值完成自注意力机制;2)在输出的每层线性层后添加激活函数ReLU6,提高模型的表达能力. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}