

随着智能交通技术的兴起,无人驾驶技术渐渐成为重要的研究课题,在复杂交通环境下的车辆利用深度学习算法进行实时检测,有着重要的现实意义和研究价值. 根据目标检测算法的特点可分为传统算法和深度学习算法. 传统目标检测算法是在图像上进行区域的划分,运用特征梯度直方图[1] (histogram of oriented gradients, HOG)或者尺度不变特征变换[2] (scale-invariant feature transform, SIFT)等技术对选定的区域进行特征提取,采用支持向量机[3] (SVM)或AdaBoost等模型进行分类. 基于深度学习的目标检测算法包含2个不同的分支:一种是基于区域的卷积神经网络[4] (region based convolutional neural network, R-CNN)、基于快速区域的卷积神经网络[5] (fast-RCNN)以及基于更快区域的卷积神经网络[6] 为代表的二阶段目标检测算法,在检测精度上取得一定的效果,但是检测速度却无法满足实时性需求;另一种则是以YOLO (you only look once)系列[7] 和单次多框目标检测SSD[8] 算法为代表的一阶段目标检测算法. 它们不需要生成候选框,直接将边框的定位问题转化为回归问题从而提升检测速度,但是对于小目标检测效果却表现一般.
随着广大学者对目标检测算法不断改进,小目标检测的性能不断地得到提高. 由于anchor较少导致训练不充分问题,Fu等[9] 针对SSD算法对小目标进行训练,提出反卷积单次多框检测器(deconvolution single shot multibox detector, DSSD),通过采用上采样操作得到的特征图进行预测,在反卷积操作过程中,运用跳跃连接(skip-connection)引入较低层特征图提升模型性能. Li等 [10] 提出基于特征融合多框检测器(feature fusion single shot multibox detector, FSSD),该融合方法在检测过程中可以兼顾不同尺度的信息,使得检测结果更加有效. Jeong等[11] 提出SSD的改进版算法,将基础网络替换成ResNet,检测速度只有16.6 帧/s,而且mAP达到80.8%. 李航等[12] 针对YOLO算法检测小目标精度低的问题,提出一种基于深度可分离卷积的密集连接网络(slim-densenet)特征提取模块,增强小目标的特征传递,大大提升检测精度. 小目标占图像的面积比例小,位置缺少多样性,导致小目标进行检测时的通用性较差. Chen等 [13] 提出一种Stitcher动态拼接图像或丰富小目标常规图像的方法,创建更小的对象来减少图像批处理时小目标比率的不均衡问题. 由于特征金字塔(feature pyramid networks, FPN)的多个特征层之间存在矛盾, Liu等[14] 对特征金字塔的融合方式进行改进,提出一种自适应的空间特征融合方法. 借鉴FPN的思想利用学习权重参数将不同层的特征进行融合,并对融合之后的特征图进行目标的预测. 为了弥补小目标数量较少的缺陷,Zoph等[15] 将神经网络结构搜索(neural architecture search, NAS)方法应用到目标检测的领域中,利用神经网络搜索出最优的数据增强策略,增加小目标样本的数据量以提高检测的性能. WANG T[16] 通过使用新的骨干网络和训练策略,结合预训练模型来提高小目标检测的准确性,将预先训练好的SSD网络作为骨干网络,同时采用一个轻量级的辅助网络(lightweight secondary network, LSN),弥补骨干网络在特征提取过程中的损失,为目标检测提供更复杂的轮廓信息.
本研究提出基于多尺度特征融合的方法,并且为提升特征提取的效果在基础网络框架中引入注意力机制[17] (squeeze and excitation, SE). 所提的基于多尺度融合与注意力机制的小目标车辆检测方法实验表明,用自建数据集进行测试得到的mAP高达90.2%;在公开的PASCAL VOC 2012测试集上测试得到的mAP为83.1%,相比YOLOv5算法提高了4.5%,尤其是对bird和bottle等小目标的效果有着显著提升,精度均提升了5.0%以上. 所提的基于多尺度融合与注意力机制的小目标车辆检测方法在GTX1 660 Ti PC端的检测速度可以达到25 帧/s,满足实时性的需求.
1. 结合注意力机制的多尺度信息融合方法
SSD算法的运算速度可以媲美YOLO算法,并且检测精度也丝毫不弱于Faster RCNN算法,因此在实际生活中有着广泛的应用价值. 然而算法中的Conv4_3层对特征提取的不充分导致对小目标检测精度较低,原因在于浅层特征层保留更多的原始信息,没有充分地提取深层的语义特征,而深层特征层丢失大量的细节信息,无法对小目标进行准确的表达,但是包含了更深层的语义特征. 为了结合各层特征图的优势, Conv4_3特征层(针对小目标检测)采用5支路多尺度融合技术,而对于中、大目标检测的特征层则采用2支路融合技术以提升车辆检测方法的性能. 在基础网络框架之间加入注意力机制模块,通过学习不同通道特征的重要程度来降低噪声对模型方法性能干扰使得得到的信息更加有效. 基于注意力机制模块与多尺度特征融合技术的小目标车辆检测方法的网络结构如图1所示.
图 1

图 1 基于SE模块与多尺度特征融合技术的小目标检测方法网络结构图
Fig.1 Network structure diagram of small target detection method based on SE module and multi-scale feature fusion technology
1.1. 注意力机制
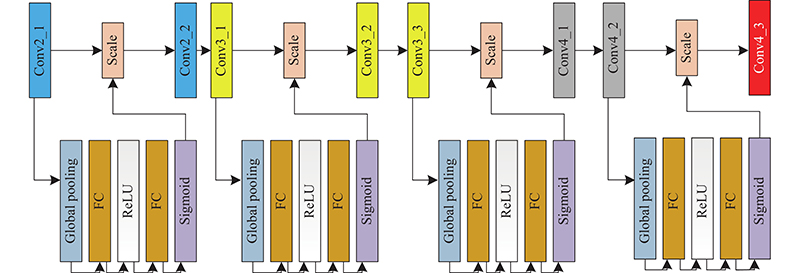
由于浅层特征经过较少的卷积运算,在特征提取过程中含有较多的噪声干扰,注意力机制可以根据关注不同通道之间的相互联系,学习到不同通道特征的重要程度,将计算出来的各通道权重值分别与原始的特征图对应通道的二维矩阵相乘,得到最终输出结果. 注意力机制作为一个独立的模块,极易与其他网络框架结合,不会改变原来网络框架. 在基础网络Conv2_1 ~ Conv4_1层增加注意力机制模块,使得模型能够在浅层特征提取过程中有效地降低噪声干扰,优化特征提取效果,具体操作如图2所示. 随着注意力机制模块的增加,提升模型对通道之间的敏感程度作为轻量级的模块,在基础层之间增加注意力机制的过程,增加一些运算量的同时考虑到性能的提升,运算时间仅仅减少了3 帧/s.
图 2
1.2. 多尺度信息融合
在传统的检测算法中,每个用于目标检测的特征图仅包含该层信息. 为了结合低层特征图的高分辨率以及深层特征图的高语义性优势,提出一种基于多尺度信息融合(multi scale information fusion, MSIF)的特征提取方法,实现不同特征图的特征信息的融合,加强层与层之间的联系,提升小目标的检测性能.
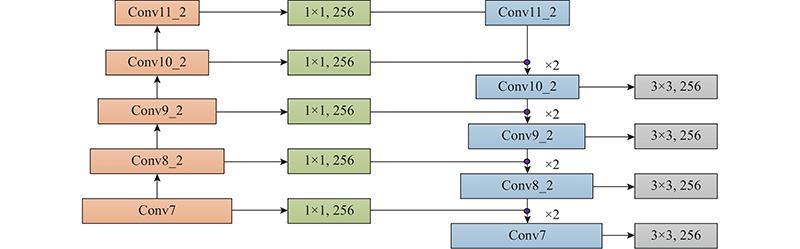
为了实现特征层的融合通过预处理将Conv7、Conv8_2、Conv9_2、Conv10_2以及Conv11_2的特征图的通道数统一转为256,然后利用双线性插值(因为考虑到待采样点周围的4个相邻的点对该采样点的相关性,使得图像在很大程度上消除锯齿现象,从而提高图像的质量)对Conv11_2做上采样操作(所谓上采样,就是将图像恢复到原图像大小,由低分辨率转变为高分辨率技术的统称),并对所得到的Conv11_2特征层与Conv10_2特征层中的对应元素进行add操作,以此作为新的Conv10_2特征层. 然后利用3×3大小的卷积核对新得到的Conv10_2进行消除上采样与add操作带来的混叠效应,再利用1×1卷积运算得到Conv10_2和Conv11_2特征图的通道数转为原网络框架中对应的通道. 分别对Conv9_2、Conv8_2、Conv7进行相同操作流程(如图3所示),最终对融合后的特征层进行定位和置信度分析.
图 3
常见的特征融合方式有concat和add,两者相似之处都是为了整合不同特征图之间的信息. 不同的是concat操作是将通道数进行合并,即描述图像的特征通道数增加,实际上每一特征图下特征的信息并没有增加. 每个通道的卷积核是独立的,concat的单个输出通道Z0为
式中:
add是每一维下的信息在增加,但是描述图像本身的维度并没有增加. add的单个输出通道Za的运算公式为
从式(1)和式(2)可以看出,add的计算量要比concat小,由于小分辨率特征图上具有的通道数会更多,造成concat计算更加复杂. 为了验证2种不同融合方式的性能差别,将2种融合方式进行实验性能的对比. concat因运算量大,导致精度上的损失,基于对性能的综合考虑,采用add操作方式进行特征融合.
由于Conv4_3特征层是用于小目标的检测,为了提升小目标的检测效果,对Conv4_3采用5支路融合,以弥补得到的Conv4_3层感受野不足的缺陷. 对于Conv4_3特征层所采用的操作流程如图4所示,通过预处理操作将Conv7、Conv8_2、Conv9_2以及Conv10_2特征层的通道数转为256,并利用上采样操作将特征图的分辨率统一转化为38×38,然后将特征图中对应元素进行add操作,作为新的Conv4_3特征层. 通过3×3大小的卷积消除融合后的Conv4_3特征层的混叠效应,利用1×1大小的卷积改变为与原Conv4_3相同的通道数. 最后将新得到的特征层分别送入2个并行的卷积神经网络实现类别和定位预测.
图 4

2. 实 验
2.1. 实验环境及参数设置
实验采用Pytorch深度学习框架,以Win10作为操作系统,其GPU型号为GTX 1 660 Ti,显存大小为40 G,处理器为Intel core i7−9700. 将视觉几何群网络(visual geometry group network, VGG)模型作为网络的初始化权重,实验的初始学习率为0.000 1,权重衰退为0.000 5,动量为0.9,每迭代5 000次保存1次训练模型,共计120 000次. 在一般情况下,如果负样本的数量远远大于正样本的数量,直接训练会导致网络过于重视负样本,从而导致训练loss的不稳定. 在网络训练时依据置信度分数对default box进行排序,挑选其中得分较高的box进行训练,控制正负样本数量比例为1∶3,其余的负样本将不会参与分类损失的loss计算. 位置误差的计算采用Smooth L1 loss损失函数,目的是为防止在训练早期锚框和真实框的偏差较大而出现梯度爆炸. 对于置信度误差则采用在分类算法中常用的softmax loss作为分类损失函数. 在6层卷积层输出的特征图中,每个n×n大小的特征图对应的有n×n个中心点,每个中心点产生k个默认框,6层中每层的每个中心点产生的k分别为4、6、6、6、4、4. 所以6层中的每层取1个特征图共产生8 732个默认检测框.
为了验证所提出的车辆检测方法的有效性,运用自建的车辆数据集和公开的PASCAL VOC 2012数据集进行训练测试. 实验采用当前目标检测算法中常用的mAP作为评价指标,mAP是所有类别的平均精度(average precision, AP)求和,是除以类别数取均值得到的. 通过计算mAP的高低来衡量模型算法的有效性,即mAP值越高,说明模型的检测性能越好,模型算法好. 计算公式为
式中: k为类别数,APj为第j类车辆平均精确率.
AP由精准率P和召回率R共同决定的. 精确率是指分类器要尽量在“更可靠”的情况下将样本预测为正样本,这意味着精确率体现模型区分负样本的能力. 召回率旨在找到实际为正的样本中多少被预测为正样本,这意味着召回率足以体现模型对于正样本的区分能力,召回率越高,则模型对正样本的区分能力越强. 精准率与召回率计算公式为
式中:TP为正确的识别出类别的车辆数,FP为错误的识别成其他类别的车辆数,FN为未被识别出来的车辆数量.
2.2. 实验结果及性能分析
2.2.1. 自建车辆数据集
本研究利用索尼FDR-AX700相机在公路上进行录制构建车辆数据集,该设备帧率高可以非常清楚的拍摄到高速行驶车辆的瞬时图像,然后对得到的视频图像进行裁剪. 由于在拍摄过程中照片存在背景单一和拍摄角度固定等问题,采用收集网络照片和数据增强手段,数据增强包括图片翻转和亮度调整等处理技术,增加场景多样性,提升模型泛化性. 最终,进行人工标注构建成标准的车辆数据集,数据集中的每张图片分辨率大小为1 080×1 920. 为了增加目标检测模型的鲁棒性,从网上收集部分图片制作成数据集. 图5为自建车辆数据集中的部分样例图. 图6可以看到,4张图中的车辆尺度不同. 本研究定义目标检测框的面积占整张图像面积比小于5%的物体为小目标(S),面积占比大于5%且小于30%的物体为中目标(M),其余则为大目标(L). 自建数据集中共含有目标车辆9 671,其中小目标车辆数为含有3 120,中目标数辆为2 928,大目标数量为3 623,按照9∶1的比例将自建数据集划分为训练集和测试集.
图 5

图 6

在Pytorch框架下利用传统SSD方法进行测试,得到的mAP为78.5%,小目标的AP仅为65.6%. 在相同的实验环境下分别采用CenterNet[18] 、YOLOv4[19] 和YOLOv5[20] 方法对自建数据集中的小、中、大目标进行验证. 从表1中看出,提出的注意力机制与多尺度融合方法的mAP达到90.2%,均高于其他目标检测方法. 小目标的mAP比YOLOv5算法提高了9.7%,提升效果较为显著. CenterNet方法性能最差,mAP仅为73.5%,而YOLOv5无论是检测速度,还是对小、中、大目标的精度均比YOLOv4有着一定的提升,而且mAP比YOLOv4增加了6.4%. 实验表明,所提方法对小目标检测性能的提升有着一定的优势. 通过实验数据探究add与concat两者之间在速度和精度上的区别,实验结果得出add的运算速度接近concat方法的2倍, concat由于计算量大导致精度损失了7.8%. 而本文方法的mAP达到88.5%,比SSD+FPN方法提高了3.4%,MSIF和FPN主要区别在于对Conv4_3单独融合5条支路. 卷积神经网络通过逐层抽象的方式来提取目标特征,使得高层网络的感受野比较大,语义信息表征能力强,但是特征图的分辨率低;低层网络的感受野比较小,分辨率较高,细节信息表征能力强,但是语义信息表征能力弱. 将深层语义信息和用于小目标检测的Conv4_3层进行5支路的融合,通过增加高层的语义信息,丰富预测回归位置框和分类任务,最终所提出的SSD+MSIF中的小目标的AP达到81.2%,比传统的SSD+FPN高出6.6%,表明多尺度信息融合方法对小目标检测的有效性. 在多层特征信息融合方法的基础上增加SE模块,使得本文提出车辆检测方法的mAP达到90.2%,与不加注意力机制模块相比,各类均提升约2%左右,表明在基础网络中引入SE注意力机制模块对实验性能的提升是有效的.
表 1 自建车辆数据集各方法测试结果
Tab.1
| 方法 | mAP/% | AP/% | ||
| 小目标 | 中目标 | 大目标 | ||
| CenterNet | 73.5 | 52.3 | 82.1 | 86.1 |
| SSD | 78.5 | 65.6 | 88.2 | 81.7 |
| YOLOv4 | 79.3 | 67.2 | 83.2 | 87.5 |
| YOLOv5 | 85.7 | 74.8 | 86.8 | 95.5 |
| OURS | 90.2 | 83.5 | 91.2 | 95.9 |
表2中不同方法的检测速度进行测试,实验结果表明,MSIF比传统的FPN方法检测速度略低. 在MSIF算法中的Conv7、 Conv8_2、 Conv9_2、Conv10_2与Conv4_3进行多尺度特征融合时消耗一定计算量,检测速度仅为28 帧/s,在加入SE注意力机制模块之后,检测速度为25 帧/s,算法的检测精度有一定的提升,尤其是小目标车辆检测性能提升显著. 为了探究不同深度的语义信息对小目标检测的Conv4_3特征层的差异,将 Conv4_3特征层分别进行3支路、4支路、5支路以及6支路的融合实验,实验结果如表3所示. 从表中可以清晰的看出,5支路的检测性能要优于3、4支路融合效果,检测速度也能达到28帧/s,表明过深的深度语义信息对小目标检测的浅层特征是有所帮助的,然而对于6支路融合的实验性能却不如五支路融合后的效果好,速度也减少了3 帧/s,这是因为将1 × 1大小特征图上采样到38 × 38大小时,只能携带较少的信息,对性能没有明显提升,同时出于实时性的考虑,最终采用五支路融合. 图7为所提的方法与传统SSD的测试效果对比图,从图中可以看出,所提出的小目标车辆检测方法可以将图中小目标有效的检测出来,而且置信度较之前也有提升.
表 2 自建车辆数据集各类方法测试性能对比
Tab.2
| 方法 | mAP/% | AP /% | v/(frame·s−1) | ||
| 小目标 | 中目标 | 大目标 | |||
| SSD+FPN | 85.1 | 74.6 | 87.3 | 93.4 | 32.0 |
| SSD+MSIF | 88.5 | 81.2 | 90.1 | 94.2 | 28.0 |
| SSD+MSIF+SE | 90.2 | 83.5 | 91.2 | 95.9 | 25.0 |
表 3 Conv4_3层不同融合方式性能对比
Tab.3
| 融合方式 | mAP/% | v/(frame·s−1) |
| 3支路融合 | 86.4 | 31 |
| 4支路融合 | 87.2 | 30 |
| 5支路融合 | 88.5 | 28 |
| 6支路融合 | 88.6 | 25 |
图 7

图 7 SSD与所提方法测试结果对比图
Fig.7 Comparison diagram of SSD and proposed method test results
2.2.2. PASCAL
VOC 数据集 为了进一步验证所提提检测方法的鲁棒性,采用PASCAL VOC 2012数据集对所提方法进行训练,并利用PASCAL VOC 2012中的测试集进行验证. 该数据集总共包含20类,分别为aeroplane、bird、bicycle、boat、bus、car、cat、bottle、chair、cow、diningtable、dog、sofa、horse、motorbike、person 、potted,、plant、train,、sheep以及tvmonitor,其中除了person类数量比较多之外,剩下各类样本数量相对较少. 在相同实验配置环境和数据集的条件下,通过对表4中不同方法进行实验,得到对应的检测性能数据,实验性能结果如表4所示. 从表中可以看出,SSD、 DSSD、基于残差网络和改进特征金字塔的目标检测算法[21] (residual and pyramid-single shot multibox detector, RP-SSD)以及FSSD算法的mAP相差不大,所提方法的mAP比传统的SSD算法提高了6.4%,对于小目标bird和bottle等类检测精度增加效果显著,并且其余类别精度也有所增加. 所提方法与RP-SSD算法相比,在mAP上提高了4.6%;对于数据集中的bird类的检测精度也提升了10.6%、bottle的检测精度提升了13.6%. 客观上反映出所提算法对其他目标的检测有着很好的泛化性和鲁棒性. 与YOLOv5算法相比,所提方法的mAP提升了6.5%. 结果表明,所提方法对小目标检测的效果良好,对性能的提升是有效的.
表 4 各类方法在PASCAL VOC数据测试中的AP值
Tab.4
| 算法模型 | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow |
| FasterRcnn | 84.9 | 79.8 | 79.8 | 74.3 | 53.9 | 77.5 | 75.9 | 88.5 | 45.6 | 77.1 |
| CenterNet | 81.0 | 75.0 | 66.0 | 52.0 | 43.0 | 78.0 | 80.0 | 87.0 | 59.0 | 72.0 |
| SSD | 83.1 | 84.7 | 74.0 | 69.6 | 49.5 | 85.4 | 86.2 | 85.2 | 60.4 | 81.5 |
| RP-SSD | 88 | 83.8 | 74.8 | 73.2 | 48.9 | 83.9 | 86.8 | 91.0 | 63.2 | 81.9 |
| DSSD | 83.6 | 85.2 | 74.5 | 70.1 | 50.4 | 85.6 | 86.7 | 85.6 | 61.0 | 82.1 |
| FSSD | 84.9 | 86.4 | 74.8 | 63.3 | 50.6 | 84.6 | 87.9 | 86.9 | 63.1 | 83.2 |
| YOLOv4 | 83.6 | 84.0 | 73.8 | 59.2 | 72.2 | 91.0 | 90.0 | 70.7 | 60.9 | 64.9 |
| YOLOv5 | 84.2 | 87.6 | 65.9 | 63.3 | 77.0 | 80.2 | 91.5 | 83.7 | 66.5 | 66.4 |
| OURS | 89.8 | 89.8 | 85.4 | 75.5 | 61.5 | 82.5 | 87.5 | 90.5 | 73.9 | 95.6 |
| 算法模型 | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
| FasterRcnn | 55.3 | 86.9 | 81.7 | 80.9 | 79.6 | 40.1 | 72.6 | 60.9 | 81.2 | 61.5 |
| CenterNet | 54.0 | 81.0 | 70.0 | 68.0 | 74.0 | 41.0 | 71.0 | 58.0 | 82.0 | 70.0 |
| SSD | 75.1 | 82.0 | 85.9 | 85.3 | 77.7 | 49.6 | 76.1 | 80.0 | 87.4 | 74.4 |
| RP-SSD | 76.3 | 81.2 | 85.3 | 84.6 | 79.3 | 63.5 | 78.9 | 83.4 | 87.9 | 73.9 |
| DSSD | 75.4 | 82.5 | 86.2 | 85.4 | 78.6 | 51.2 | 75.9 | 80.5 | 86.7 | 75.1 |
| FSSD | 76.8 | 83.1 | 85.0 | 83.2 | 77.3 | 57.9 | 78.4 | 82.1 | 86.5 | 73.2 |
| YOLOv4 | 67.3 | 89.6 | 77.4 | 65.2 | 86.0 | 47.7 | 77.4 | 72.3 | 82.6 | 83.3 |
| YOLOv5 | 59.8 | 82.8 | 86.6 | 83.1 | 85.4 | 56.4 | 70.3 | 62.9 | 87.9 | 90.8 |
| OURS | 78.4 | 90.7 | 89.5 | 82.1 | 75.6 | 63.1 | 81.5 | 93.9 | 89.7 | 85.9 |
图8为选取PASCAL VOC 2012部分测试数据集的原图以及采用传统SSD算法与所提小目标检测算法的检测效果对比图. 从图中可以看出,所提方法可以有效地将图中bird和bottle等小目标识别出来. 实验结果表明,采用多尺度信息融合方法的网络结构对于小目标的检测更加敏感,而且能够与小目标产生很好的拟合,在满足实时性的同时也提升了模型的检测性能.
图 8

图 8 SSD算法与本文方法对小目标的检测结果对比图
Fig.8 Comparison of detection results of SSD algorithm and method for small targets
2.2.3. 检测速度
为了验证所提方法的检测速度性能,将所提方法与其他方法的检测速度进行对比,结果数据如表5所示. 可以看出,所提方法的检测速度为25 帧/s,与传统的SSD方法相比,检测速度降低了21 帧/s,检测精度显著提升了17.5%,满足实时性需求的同时对小目标的检测更加鲁棒. 所提检测方法比Faster Rcnn算法的检测速度增加了18 帧/s,并且mAP也有明显提升. 所提方法的检测速度不如YOLOv4与YOLOv5算法,但是mAP却分别提升了8.1%和6.5%. 所提算法与RP-SSD目标检测算法进行对比,在实验中所使用显卡在显然不如对方的情况下,仍能够满足实时性的需求,而且mAP比RP-SSD算法提升了4.7%.
表 5 各类方法在PASCAL VOC数据性能对比结果
Tab.5
| 方法 | 显卡型号 | 基础网络框架 | mAP/% | v/(frame·s−1) |
| Faster Rcnn | Titan X | VGG-16 | 70.4 | 7.0 |
| YOLOv4 | 1060 Ti | CSPDarknet53 | 75.0 | 35.0 |
| YOLOv5 | 1060 Ti | FOCUS+CSP | 76.6 | 38.0 |
| SSD | Titan X | VGG-16 | 75.6 | 46.0 |
| RP-SSD | 1080 Ti | VGG-16 | 78.4 | 32.0 |
| OURS | 1060 Ti | VGG-16 | 83.1 | 25.0 |
3. 结 语
为了使浅层特征图提取效果对小目标检测更加有效,本研究采用多尺度信息融合方法将浅层与深层特征图的信息进行融合. 在基础网络框架中引入注意力机制模块,有效地降低噪声干扰,使得提取的信息更加有效,从而提升检测的性能. 实验结果表明,所提方法在自建数据集中的mAP提升了11.7%,其中小目标的精度比较于传统SSD方法提升了17.9%,表明本研究基于多尺度融合与注意力机制的方法对于小目标的检测性能提升效果显著,在PASCAL VOC 2012数据集上的mAP达到83.1%,比目前主流的YOLOv5提升了6.5%. 显卡性能在GTX 1660 Ti上的检测速度达到了25 帧/s,可以满足实时性需求.
参考文献
Predicting the effects of coding non-synonymous variants on protein function using the SIFT algorithm
[J].
Practical selection of SVM parameters and noise estimation for SVM regression
[J].DOI:10.1016/S0893-6080(03)00169-2 [本文引用: 1]
Faster r-cnn: towards real-time object detection with region proposal networks
[J].
基于深度卷积神经网络的小目标检测算法
[J].DOI:10.3969/j.issn.1007-130X.2020.04.011 [本文引用: 1]
A small object detection algorithm based on deep convolutional neural network
[J].DOI:10.3969/j.issn.1007-130X.2020.04.011 [本文引用: 1]
基于残差网络和改进特征金字塔的油田作业现场目标检测算法
[J].DOI:10.3969/j.issn.1671-1815.2020.11.035 [本文引用: 1]
Field object detection for oilfield operation based on residual network and improved feature pyramid networks
[J].DOI:10.3969/j.issn.1671-1815.2020.11.035 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}