

随着我国机动车保有量的不断上升,道路交通供需矛盾日益加剧. 尤其在交叉口场景中,路口各转向交通流在不同时段呈现不均衡的分布,容易导致拥堵,同时造成车道资源浪费. 为了解决这个问题,可变导向车道技术应运而生,其将车道作为可变的空间资源,根据各转向交通流的需求进行动态分配,以提升道路空间资源的使用率. 在单路口可变导向车道场景中,传统控制方法可以有效缓解转向不均衡问题,但随着可变导向车道的数量增加,多路口间的车流变化更复杂,传统方法的可预设性难度增加,无法有效协调控制多个路口的可变导向车道,因此,如何使多路口可变导向车道之间的协作更为高效成为新的问题. 本研究提出基于多智能体强化学习的多路口可变导向车道协同控制方法,可以根据环境反馈来学习和调整策略,并考虑多个可变导向车道间的联动进而提高多个路口的通行能力.
1. 相关工作
交叉口的交通流状况在时间和空间维度是动态变化的. 例如,在早晚高峰时段,交叉口的各转向车流呈现明显的规律性变化,存在不同导向车道车辆排队长度严重失衡的问题. 针对该问题,为了提高交叉口的通行能力,解决城市道路拥堵问题,一些交通研究者对可变导向车道转向的动态控制方法开展研究,主要集中在传统控制方法、智能控制方法和强化学习方法3个方面.
1.1. 传统控制方法
传统的可变车道控制方法研究采用基于经验或者历史数据规律的方法预先设置控制方案,对路口可变导向车道转向进行规则设计. Wong等[1]基于经验提出了用于交叉口车道优化的信号相位一体的集成设计;Golub等[2-3]从可变导向车道的设置条件的经验规则出发,提出交叉口可变导向车道转向控制模型. 相较于基于专家经验,通过挖掘路口历史数据提取的交通流变化特征与实际交通转向需求的匹配度更高. 赵靖等[4]综合考虑单路口实时交通因素,对预实施方案进行评估,部署具体的车道功能和信号配时切换方案,但对预方案须进行反复试算且准确度不高. 聂磊等[5-6]根据目标路口关联的多个道路约束条件进行整数非线性规划模型的优化,实现单路口优化后关键流量比最小. 常玉林等[7-8]综合关键交叉口和下游相邻交叉口的路况实现关联控制模型. 上述工作仅考虑关键路口对单个相邻路口的影响,而没有对关联路口进行综合优化方案设计. Yao等[9]提出基于采集的数据规律协调设计多个交叉口可变标志和相应信号组的控制方法,更好地减少车辆平均延迟.
上述通过经验或者总结历史数据规律,对可变转向车道转向规则进行预先设置的方法,在一定程度上适应规律性交通状态变化的需求,但是难以动态地适应供需快速变化的道路交通情况和突发异常交通流.
1.2. 智能控制方法
可变导向车道智能控制方法研究基于实时采集的各种交通流数据进行智能决策,提高对交叉口实时交通流变化的适应程度. 一些工作利用采集的道路实时交通流数据,例如各转向车道的空间占有率[10]、通过视频检测获取的车流量、速度、队列长度等特征[11],动态决策可变导向车道切换策略,但其对后续的交通流变化适应性不好. 结合实时采集的交通流数据和预测模型,He等[12]对各转向交通流进行预测以作为判别车道方向切换的依据,最大程度地减少交叉口平均延误时间. 许佳佳等[13]将以最小二乘动态加权融合算法为核心的短时交通流预测模型,与以模糊数据理论和神经网络系统理论为核心的交通状态预测模型相结合,实现可变导向车道转向的自动控制;蔡建荣等[14]构建混合整数双层规划模型,采用粒子群算法进行求解,实现基于预测模型的可变车道总体行驶时间最小的目标.
以上相关研究工作具有2个局限:1)主要应用于单路口可变导向车道转向的智能控制决策;2)基于预测的智能算法主要基于历史和实时数据,无法快速更新规则以适应交通流的动态变化.
1.3. 强化学习方法
近年来,强化学习技术快速发展,其对环境的先验知识要求低,在复杂的非线性系统中能够取得良好的学习优化性能,因此适用于复杂多变的多路口可变导向车道智能控制场景. 在多路口协同控制问题中,交通信号优化研究已广泛使用强化学习方法. Wei等[15]将深度强化学习与交通信号控制问题结合,分别定义了状态、动作空间及奖励函数,使用DQN(Deep Q-Network)模型进行学习,在合成与真实的数据集中进行广泛的实验,证明了强化学习方法的优越性. 在大范围交通信号控制领域和智能驾驶领域,Chu等[16]采用多智能体强化学习技术将联合Q值定义为局部Q值的加权和,通过最小化单个Q值的加权和与全局Q值之间的差异,来确保单个智能体能够考虑到其他智能体的学习过程,实现大范围交通信号的自动控制. Wang等[17]提出不同的智能体在每一轮学习后通过交换策略以达到零和博弈,以此为基础实现自动驾驶车辆的信号控制策略,并设计了将个人效率与整体效率相结合的奖励方式,实现相关交通参与者的全局最优. 在多路口协同控制场景中,交通信号在时间维度对交通状况进行优化,智能可变导向车道作为空间维度的调控手段,上述2个方向均适合采用强化学习方法开展全局优化研究.
2. 可变导向车道协同控制方法
2.1. 整体架构
本研究基于多智能体强化学习提出了多路口可变导向车道协同控制方法(multi-intersection variable-direction lanes cooperative control algorithm, BASE). 该方法主要包括多智能体强化学习模型、全局奖励分解算法和优先级经验回放算法. 整体架构如图1所示.
其中,本研究提出的多智能体强化学习模型基于QMIX算法[18]的值函数分解算法构建. QMIX算法采用集中式训练、分布式执行的策略,在训练时利用全局奖励函数优化联合动作值函数来达到多智能体协同控制的效果,而每个智能体则从联合动作值函数中构造和提取相应的局部策略,不仅可以通过中心化训练处理环境非平稳性带来的问题,而且通过联合动作值函数反向传播学习到每个智能体的局部“最佳”策略,从而实现多智能体去中心化执行.
全局奖励分解算法对值函数分解算法中的全局奖励分配方式进行改进,对全局值函数和单个智能体值函数之间施加约束,在某些复杂场景下全局最优联合动作可能需要智能体做出一些牺牲个体利益的行为. 针对这一问题,本研究将全局奖励分解成两部分,一部分为基本奖励,通过QMIX混合网络实现对不同智能体的特异性分配;另一部分为绩效奖励,根据智能体的状态分级分配给每个智能体,使单个智能体能够在最大化全局奖励的同时兼顾自身的奖励,实现全局奖励的二次分配.
在优先级经验回放算法中,针对随机采样出的经验质量参差不齐,导致训练效率低、算法收敛速度慢的问题,采用值函数分解算法中的联合价值函数计算误差,并结合抽取次数来计算样本的优先级,加速算法收敛.
图 1
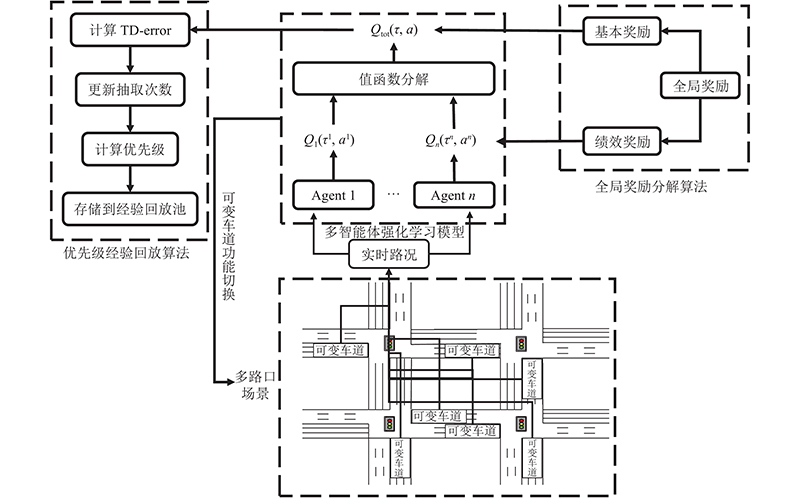
图 1 多路口可变导向车道协同控制方法整体架构
Fig.1 Architecture of cooperative control method of multi-intersection variable-direction lanes
2.2. 多智能体强化学习模型
基于值函数分解的多智能体强化学习模型如图2所示.
图 2
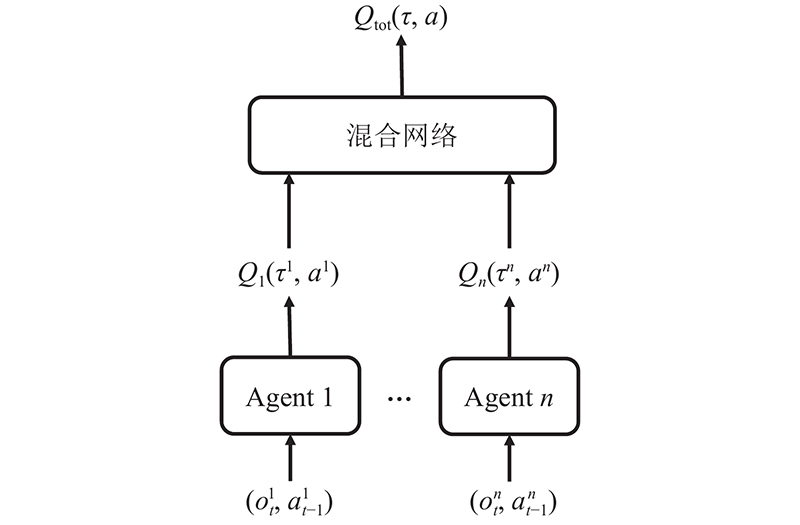
在值分解网络(value-decomposition networks,VDN)算法[19]的基础上,将原来的线性映射换为非线性映射,并通过引入超网络将额外的全局状态信息加入到映射过程,提高算法性能. 利用每个智能体当前观测状态
在多路口可变导向车道场景中,对涉及的状态空间、动作空间及奖励函数等要素进行定义. 为了使输入的状态更符合实际、更丰富,采用各方向车道的排队长度、车辆平均等待时间、平均延误时间比作为指标. 此外为了准确描述车辆的位置分布,对可变导向车道区域进行离散化编码,得到车辆映射矩阵,如图3所示. 车道被划分为大小相同的矩形网格,网格覆盖了整个路段,网格中每个格子代表一辆车的存在状态,值为1表示该格子处车辆存在,0表示车辆不存在. 相比于直接将交叉口图像信息作为输入,这种方式能够压缩数据维度,去除冗余信息,从而加快训练速度.
图 3
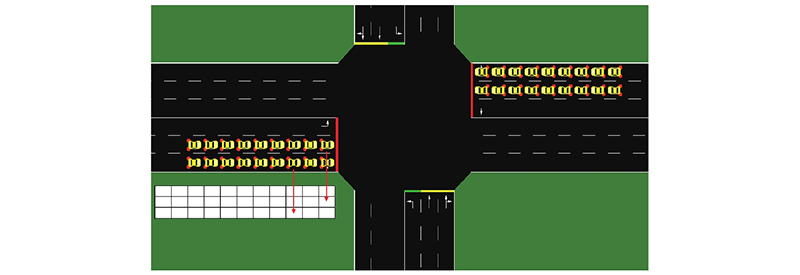
在多路口场景下状态空间表达式如下:
式中:
在可变导向车道场景中,主要研究应用较多的直左可变导向车道,不考虑右转方向,因此动作空间为左转或直行.
全局奖励函数定义为以下指标的加权和.
1) 所有车道上车辆的平均排队长度
2)所有车道上车辆的平均延误时间比
式中:
3)所有车道上车辆的平均等待时间
4)所有车道上在上一动作之后驶离当前车道的平均车辆数
5)所有车道上在上一动作之后驶离当前车道的车辆平均速度
式中:
对以上不同的交通指标分配相应权重,最后计算全局奖励:
式中:
2.3. 全局奖励分解算法
将全局奖励
图 4
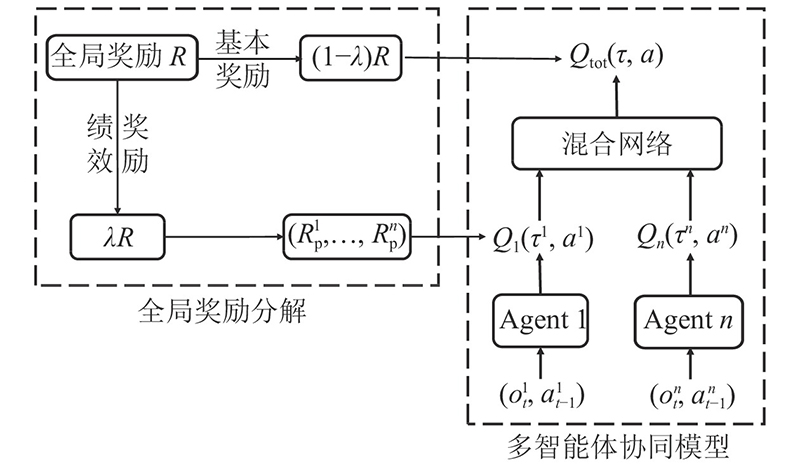
全局奖励分解函数如下:
采用传统混合网络方法将基本奖励分配给各智能体. 绩效奖励则用来激励区域协同控制过程中贡献较大的智能体. 每个智能体在当前时间获得的绩效奖励表达式如下:
式中:
在绩效奖励
2.4. 优先级经验回放算法
在单智能体强化学习中,为了解决训练过程中抽取到的训练样本质量参差不齐的问题,提出优先级经验回放算法[20],采用时序差分方法 (temporal difference,TD)衡量样本重要性,将误差较大的样本设为高优先级,抽取优先级高的样本进行训练,以提高学习效率.
在基于值函数分解算法的多智能体强化学习中,可以使用联合价值函数来计算TD误差,进而将其用于优先级的计算. 为了实现优先级经验回放算法,须对目标网络损失
式中:
使用
式中:
3. 实验结果和分析
为了验证协同控制算法在多路口可变导向车道场景的有效性,将协同控制BASE算法与定时控制(fixed-time control, FT)、传统多路口自适应控制算法(traditional adaptive control algorithm for multi-intersection,MTAC)、单智能体强化学习自适应算法(DQN)、多智能体强化学习自适应算法(QMIX)等方法进行比较,分析各算法在数据集中的性能表现,包括算法层面的奖励值,交通层面的平均排队长度、平均延误时间比、平均等待时间和平均旅行时间指标.
3.1. 实验设置
本研究实验设备配置如下:CPU为AMD 2.10 GHz,内存为16 GB,操作系统为Windows 10(64位). 基于微观交通仿真平台SUMO v1.7.0进行仿真实验,利用SUMO中提供的Traci(Traffic Control
如图5所示,实验环境包括4个交叉口,共24条路段,路段编号1~9设有可变导向车道,共有9条. 设有可变导向车道的路段共由5条车道组成:固定左转、可变左转/直行、直行、直行和右转车道. 路段编号10~24为常规路段,共有15条,路段采用常规固定三车道配置. 各交叉口信号周期一致.
图 5
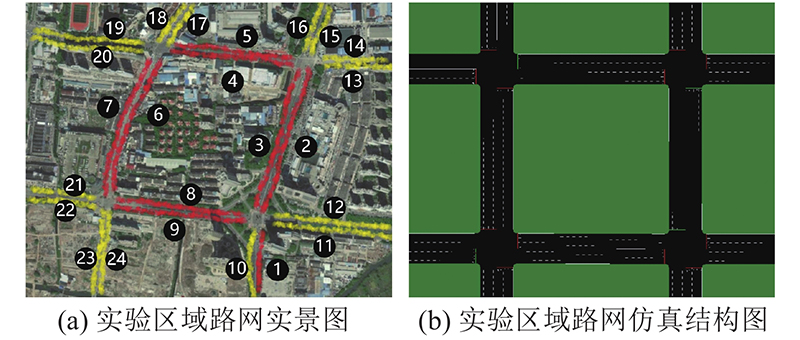
实验数据集采集自台州市泰隆街、路桥大道(东)、月河北街、腾达路等路段的过车抓拍数据,如上下游路段编码、抓拍时间、车道编号、车牌号码等. 抓拍时间范围为2019年5月23日—2019年7月26日,共有2689802条记录,将7月23日的67216条数据作为测试集,其余2622586条数据作为训练样本.
本实验在市区内路口采集交通流数据,车辆类型主要包括小汽车、旅行车、公交车和大型客车. 将实际采集得到的车辆类型和数量输入仿真系统,分别是小汽车2 417592辆次、旅行车156 008辆次、公交车91089辆次和大型客车25113辆次,占总流量的比例分别为89.88%、5.80%、3.39%、0.93%. 在仿真系统计算过程中,为了标准化路口车辆位置信息,将其转化为离散化编码的车辆位置矩阵,作为强化学习模型的量化输入. 另外,基于换算标准将实际输入的车辆类型及数量换算成标准小汽车,在仿真系统中设置各车型对应标准小汽车的当量换算系数分别为:旅行车为1.2,公交车和大型客车为2.0.
为了保证对比算法的公平性,强化学习算法的网络结构及超参数设定相同. 折扣因子的值为0.95,学习率取值为0.001,贪婪策略ε取值为0.05,记忆库大小为1000,每次更新的采样数为32,模型更新步长为5个信号周期,为了提高算法稳定性采用延迟更新目标网络,将目标网络权重替换步长设为30个信号周期,采用RMSProp (root mean square prop)算法作为更新算法. 除了以上相同的参数,本研究BASE算法中设定全局奖励分解的权重λ=0.4. 本研究将排队长度作为衡量不平衡交通流下的道路交通疏导效率的指标,设置了32种权重值组合方案. 在模型训练和测试的过程中,计算累计的车辆排队长度,对每一种方案进行100次的实验,结果取平均得到平均排队长度. 平均排队长度越小说明交通疏导效果越好,综合3200次实验的结果,确定本实验设定的全局奖励函数中各个影响因素的权重,
3.2. 实验分析
3.2.1. 性能表现
图 6
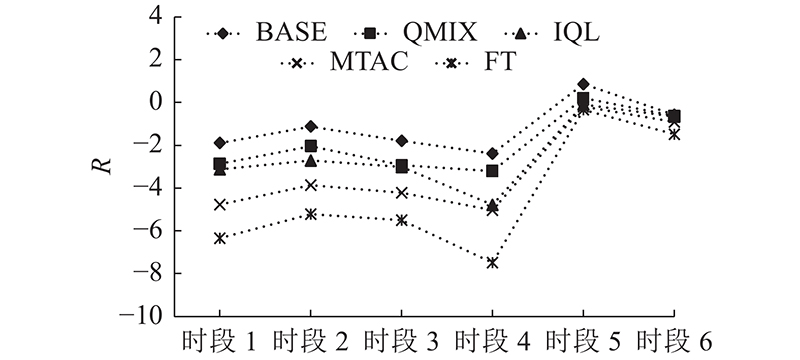
图 6 测试集中算法奖励指标对比结果
Fig.6 Comparison results of algorithm reward indicators in test set
图 7
在图6中,BASE算法在多个时段的数据集中的性能表现均优于其他算法的,并且BASE算法在早晚高峰时段相比平峰时段具有显著的领先.
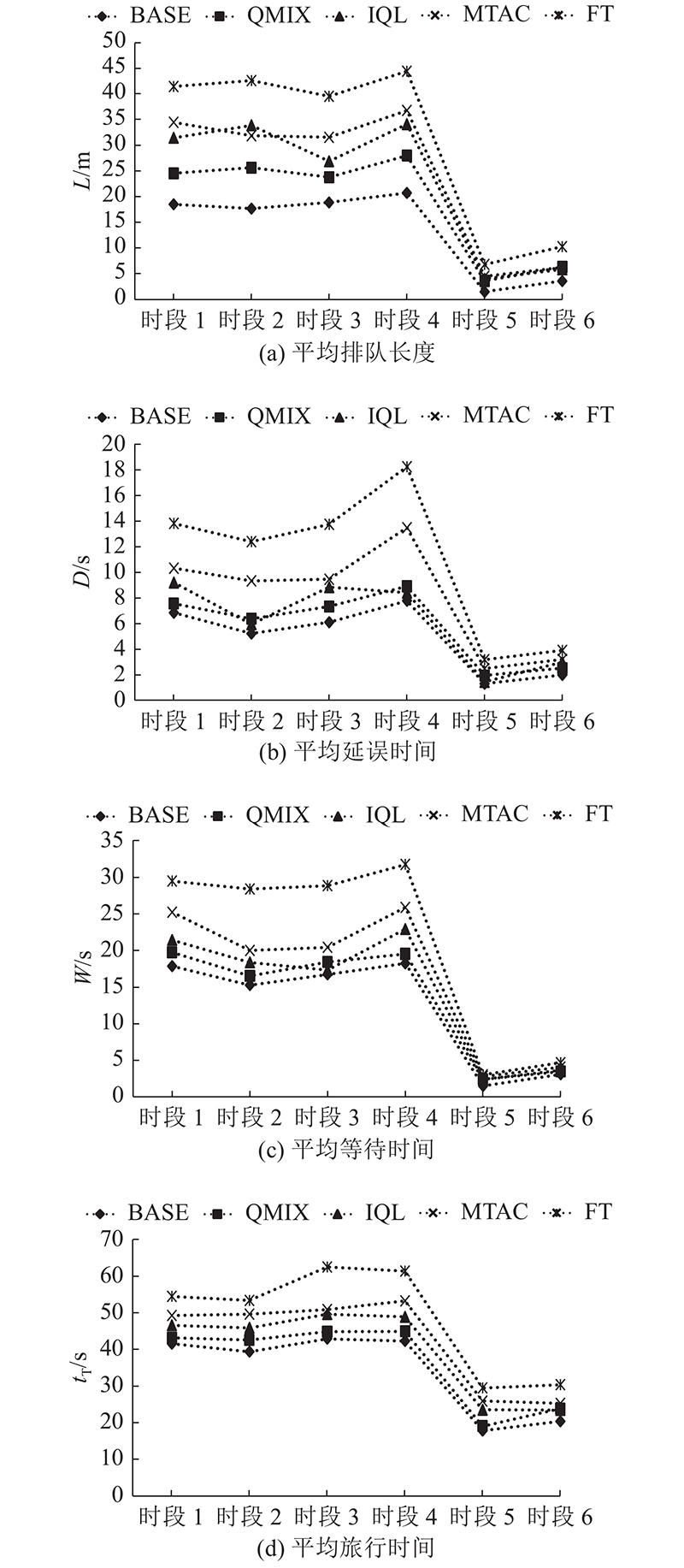
如图7(a)所示,相较其他算法,BASE算法在早晚高峰时段的平均排队长度指标降低了25.76%~54.97%,在平峰时段的指标降低了49.00%~70.67%,表明BASE算法在拥堵场景和通畅场景都具有较好的性能.如图7(b)所示,相比其他算法,BASE算法的平均延误时间降低了15.54%~55.09%. 在平峰时段5、6的测试集下,路网中流量较小,对可变导向车道功能需求较弱,各算法性能较接近,本研究算法(BASE)性能仍保持微弱领先.如图7(c)所示,相较其他算法,BASE算法的平均等待时间降低了9.28%~42.39%,并且在高峰时段比如时段3,交通状态较为拥堵,IQL算法的平均等待时间在这一数据集上的表现要略优于QMIX算法的,而改进后的本研究算法仍能保持性能领先,进一步证明了改进算法的有效性..如图7(d)所示,平均旅行时间相较其他算法降低了6.44%~29.93%,在6个时段的测试集下表现稳定,始终具有较好的性能.
本研究算法的最佳性能表现验证了针对多路口可变导向车道场景对多智能体协同算法进行的改进:全局奖励分解,本研究所提算法相较于QMIX算法智能体能够更好地学习策略.
3.2.2. 训练过程性能
通过将BASE算法与QMIX算法进行比较,测试训练过程性能指标,其中算法平均累计的奖励值指标对比如图8所示.图中,E为迭代次数.
训练过程中各交通指标变化如图9所示,平均排队长度、平均延误时间、平均等待时间和平均旅行时间等交通指标随着算法模型的训练进程而产生变化. 随着训练次数的增加,各指标显著降低,交通状态逐渐优化,2个多智能体协同算法均能够收敛. 同时根据各交通指标在训练过程中的下降趋势及最终收敛的状态,可以发现应用了全局奖励分解与优先级经验回放算法的BASE算法具有更加快速的收敛效果,并且具有较好的优化性能,能够有效适应多路口场景的交通流,实现局部路网的交通状态优化.
图 8
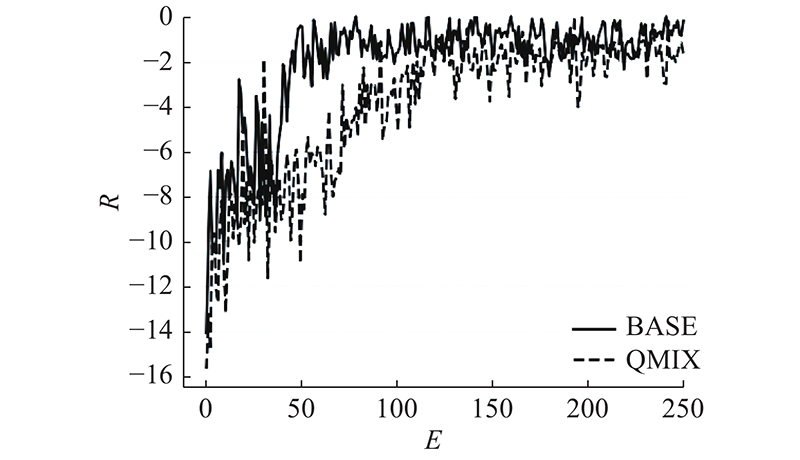
图 8 多智能体强化学习算法训练过程奖励指标对比
Fig.8 Comparison of reward indicators in training process of multi-agent reinforcement learning algorithm
图 9
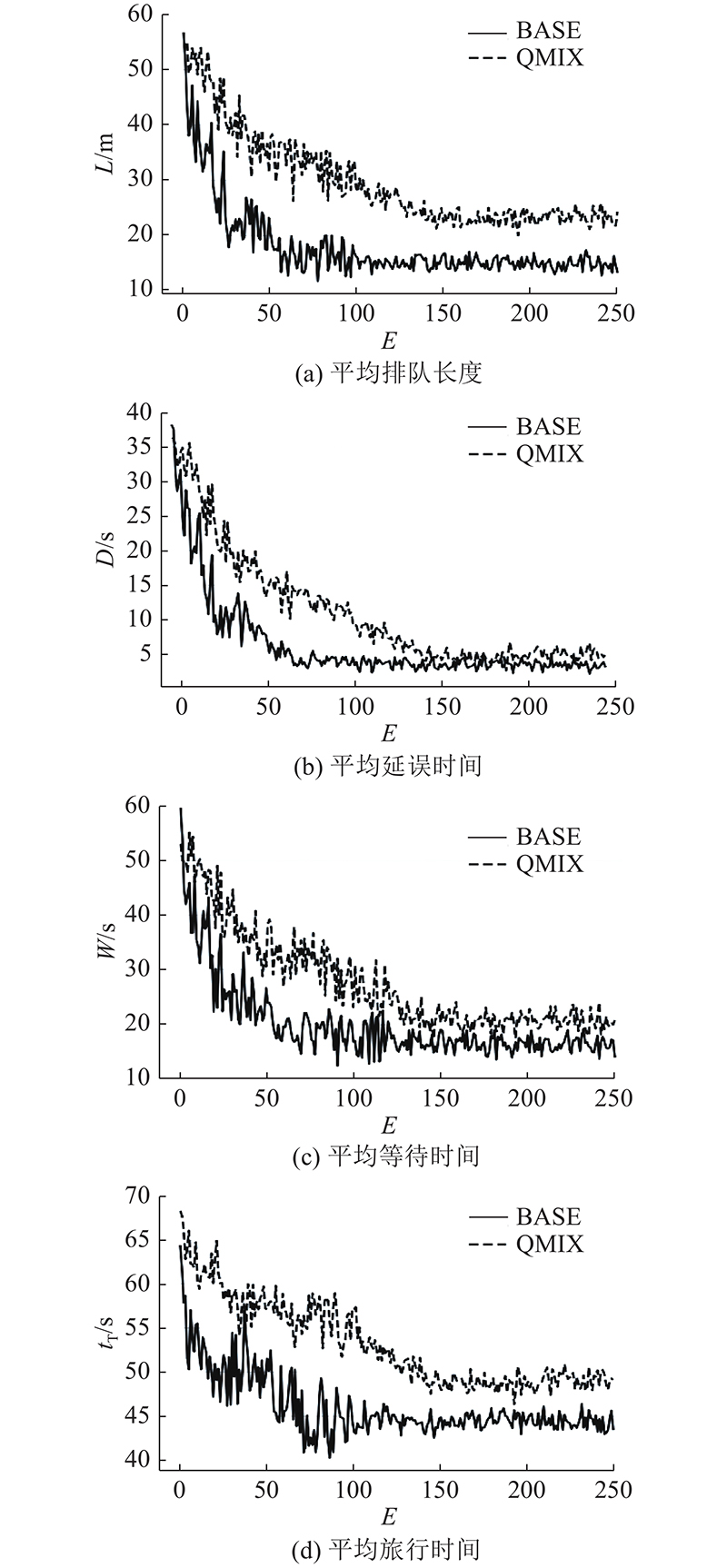
图 9 多智能体强化学习算法训练过程中交通指标对比
Fig.9 Comparison of traffic indicators during training of multi-agent reinforcement learning algorithm
4. 结 语
本研究提出一种基于多智能体强化学习的多路口可变导向车道协同控制方法. 该方法通过全局奖励分解算法提升在拥堵场景下的性能,并通过优先级经验回放算法提升学习效率,实现对多路口可变导向车道的协同控制. 与其他控制方法相比,该方法在降低平均排队长度、平均延误时间、平均旅行时间等方面具有更好的效果,同时收敛速度更快.
后续工作包括将算法与交通信号控制结合,在时间和空间2个维度进行联合优化,以进一步提高多路口场景的通行能力.
参考文献
Lane-based optimization of signal timings for isolated junctions
[J].DOI:10.1016/S0191-2615(01)00045-5 [本文引用: 1]
Perceived costs and benefits of reversible lanes in phoenix, Arizona
[J].
信号交叉口转向可变车道长度研究
[J].
Length of signal intersection turn variable lane
[J].
交叉口可变车道最佳车道功能及信号转变方法
[J].
Optimal switching method for lane assignment and signal control for variable lanes at intersections
[J].
基于车道等饱和度的交叉口车道功能优化模型
[J].
A novel model for optimization of lane allocation at isolated intersection
[J].
基于车道的交叉口车道功能和信号相位优化模型
[J].
A lane-based optimization model for lane function and signal phase at intersection
[J].
拥堵条件下考虑相邻路口的可变导向车道自适应控制
[J].
An adaptive control of variable lane considering adjacent intersections under congested condition
[J].
Modeling and control of variable approach lanes on an arterial road: a case study of Dalian
[J].DOI:10.1139/cjce-2017-0432 [本文引用: 1]
基于短时交通状态预测的交叉口导向车道智能转换系统
[J].
Intersection-oriented lane intelligent conversion system based on short term traffic state prediction
[J].
考虑通行能力折减的可变车道优化
[J].
Optimization of variable lane considering reduction of capacity
[J].
Multi-agent deep reinforcement learning for large-scale traffic signal control
[J].
Harmonious lane changing via deep reinforcement learning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}