[1]
ZUBIAGA A, AKER A, BONTCHEVA K, et al Detection and resolution of rumours in social media: a survey
[J]. ACM Computing Surveys (CSUR) , 2018 , 51 (2 ): 1 - 36
[本文引用: 1]
[2]
新浪微博虚假消息辟谣官方账号. 2020年度微博辟谣数据报告[EB/OL]. (2020-02-07) [2021-11-05]. https://weibo.com/1866405545/K0QaImwsK.
[本文引用: 2]
[3]
MA J, GAO W, WEI Z, et al. Detect rumors using time series of social context information on microblogging websites [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . Melbourne: CIKM, 2015.
[本文引用: 3]
[4]
ZHAO Z, RESNICK P, MEI Q. Enquiring minds: early detection of rumors in social media from enquiry posts [C]// Proceedings of the 24th International Conference on World Wide Web . New York: WWW, 2015.
[本文引用: 2]
[5]
张仰森, 彭媛媛, 段宇翔, 等 基于评论异常度的新浪微博谣言识别方法
[J]. 自动化学报 , 2020 , 46 (8 ): 1689 - 1702
[本文引用: 1]
ZHANG Yang-sen, PENG Yuan-yuan, DUAN Yu-xiang, et al The method of Sina Weibo rumor detecting based on comment abnormality
[J]. Acta Automatica Sinica , 2020 , 46 (8 ): 1689 - 1702
[本文引用: 1]
[7]
CAI G, BI M, LIU J. A novel rumor detection method based on labeled cascade propagation tree [C]// Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery . Guilin: ICNC-FSKD, 2017.
[本文引用: 1]
[8]
MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks [C]// International Joint Conference on Artificial Intelligence . New York: IJCAI, 2016.
[本文引用: 6]
[9]
WANG Z, GUO Y, WANG J, et al Rumor events detection from chinese microblogs via sentiments enhancement
[J]. IEEE Access , 2019 , 7 : 103000 - 103018
DOI:10.1109/ACCESS.2019.2928044
[本文引用: 4]
[10]
尹鹏博, 潘伟民, 彭成, 等 基于用户特征分析的微博谣言早期检测研究
[J]. 情报杂志 , 2020 , 39 (7 ): 81 - 86
DOI:10.3969/j.issn.1002-1965.2020.07.014
[本文引用: 2]
YIN Peng-bo, PAN Wei-min, PENG Cheng, et al Research on early detection of Weibo rumors based on user characteristics analysis
[J]. Journal of Intelligence , 2020 , 39 (7 ): 81 - 86
DOI:10.3969/j.issn.1002-1965.2020.07.014
[本文引用: 2]
[11]
SONG C, YANG C, CHEN H, et al CED: credible early detection of social media rumors
[J]. IEEE Transactions on Knowledge and Data Engineering , 2019 , 33 (8 ): 3035 - 3047
[本文引用: 4]
[12]
刘政, 卫志华, 张韧弦 基于卷积神经网络的谣言检测
[J]. 计算机应用 , 2017 , 37 (11 ): 3053 - 3056
[本文引用: 2]
LIU Zheng, WEI Zhi-hua, ZHANG Ren-xian Rumor detection based on convolutional neural network
[J]. Journal of Computer Applications , 2017 , 37 (11 ): 3053 - 3056
[本文引用: 2]
[13]
胡斗, 卫玲蔚, 周薇, 等 一种基于多关系传播树的谣言检测方法
[J]. 计算机研究与发展 , 2021 , 58 (7 ): 1395 - 1411
DOI:10.7544/issn1000-1239.2021.20200810
[本文引用: 1]
HU Dou, WEI Ling-wei, ZHOU Wei, et al A rumor detection approach based on multi-relational propagation tree
[J]. Journal of Computer Research and Development , 2021 , 58 (7 ): 1395 - 1411
DOI:10.7544/issn1000-1239.2021.20200810
[本文引用: 1]
[14]
WU Z, PI D, CHEN J, et al Rumor detection based on propagation graph neural network with attention mechanism
[J]. Expert Systems with Applications , 2020 , 158 : 113595
DOI:10.1016/j.eswa.2020.113595
[本文引用: 1]
[16]
YANG X, LYU Y, TIAN T, et al. Rumor detection on social media with graph structured adversarial learning [C]// Proceedings of the 29th International Conference on International Joint Conferences on Artificial Intelligence . Montreal: IJCAI, 2021.
[本文引用: 1]
[17]
HU L, YANG T, SHI C, et al. Heterogeneous graph attention networks for semi-supervised short text classification [C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: EMNLP-IJCNLP, 2019.
[本文引用: 1]
[18]
YAO L, MAO C, LUO Y. Graph convolutional networks for text classification [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New Orleans: AAAI, 2019.
[本文引用: 4]
[19]
LIU X, YOU X, ZHANG X, et al. Tensor graph convolutional networks for text classification [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020.
[本文引用: 1]
[20]
ZHANG Y, YU X, CUI Z, et al. Every document owns its structure: inductive text classification via graph neural networks [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics .[s.l.]:ACL, 2020.
[本文引用: 12]
[21]
LI Y, TARLOW D, BROCKSCHMIDT M, et al. Gated graph sequence neural networks [C]// Proceedings of the 4th International Conference on Learning Representations . Puerto Rico: ICLR, 2016.
[本文引用: 6]
[23]
KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: EMNLP, 2014.
[本文引用: 2]
[24]
SHU K, CUI L, WANG S, et al. dEFEND: explainable fake news detection [C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Anchorage: KDD, 2019.
[本文引用: 2]
[25]
BIAN T, XIAO X, XU T, et al. Rumor detection on social media with bi-directional graph convolutional networks [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020.
[本文引用: 2]
[26]
YUAN C, MA Q, ZHOU W, et al. Jointly embedding the local and global relations of heterogeneous graph for rumor detection [C]// 2019 IEEE International Conference on Data Mining . Newark: ICDM, 2019.
[本文引用: 2]
Detection and resolution of rumours in social media: a survey
1
2018
... 当前,人们从社交媒体上获取的信息比从传统媒体(如电视、报纸)上获取的更多,人们倾向于相信来自社交媒体的信息,这也导致他们更容易受到谣言的侵害. 谣言指的是在发布时未经证实的信息,谣言会不同程度地引起焦虑和恐慌,并且公众很难区分已证实的信息和谣言[1 ] . 为了减少谣言的危害,微博在2010年11月就成立了微博辟谣平台,以人工检验的方式识别谣言. 《2020年度微博辟谣数据报告》[2 ] 显示,该平台2020年辟谣3172条,平均每天辟谣不到9条,处理一条谣言平均用时11.09 h,由此可见,人工辟谣效率不高且存在一定的滞后性. 因此,实现高效、自动的微博谣言检测变得尤为重要. ...
2
... 当前,人们从社交媒体上获取的信息比从传统媒体(如电视、报纸)上获取的更多,人们倾向于相信来自社交媒体的信息,这也导致他们更容易受到谣言的侵害. 谣言指的是在发布时未经证实的信息,谣言会不同程度地引起焦虑和恐慌,并且公众很难区分已证实的信息和谣言[1 ] . 为了减少谣言的危害,微博在2010年11月就成立了微博辟谣平台,以人工检验的方式识别谣言. 《2020年度微博辟谣数据报告》[2 ] 显示,该平台2020年辟谣3172条,平均每天辟谣不到9条,处理一条谣言平均用时11.09 h,由此可见,人工辟谣效率不高且存在一定的滞后性. 因此,实现高效、自动的微博谣言检测变得尤为重要. ...
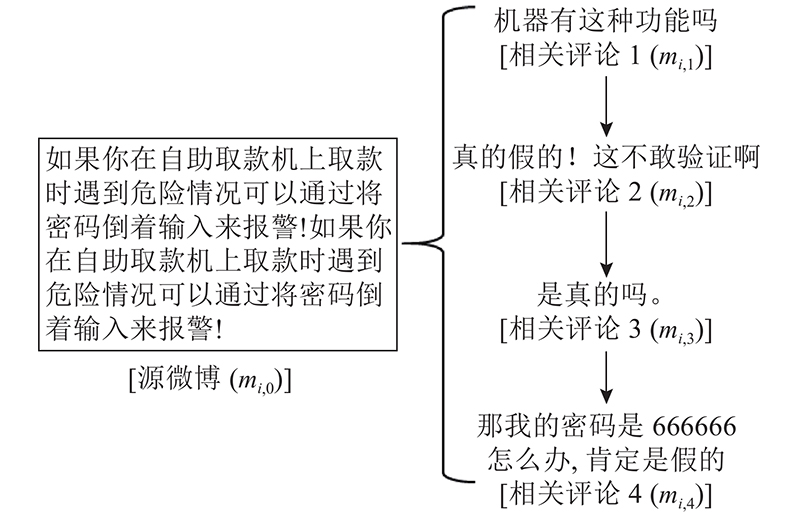
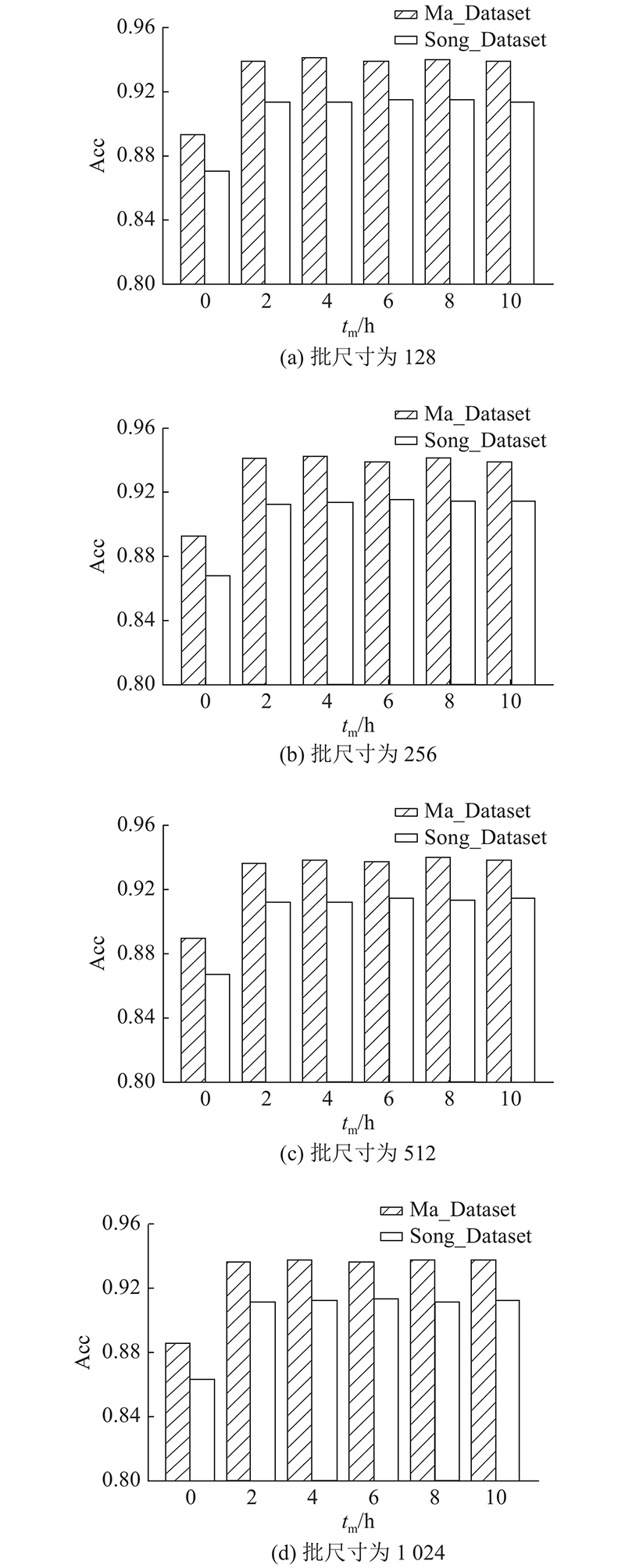
... 鉴于人工检测一条谣言信息的平均用时为11.09 h[2 ] ,将微博评论利用时间控制在11.09 h内. 如表2 所示为微博谣言事件“林依晨郑元畅相恋”的部分评论. 表中,t m 为微博发出后的时间. 可以看出,在该微博发出后,从第1~5 h的评论和第1~10 h的评论中获取的信息是极其相似的,说明极有可能仅使用前5 h的评论信息便能获得跟前10 h评论信息相近的实验效果. 为此,本研究基于微博发出后10 h内的评论数据,以每2 h为分隔,通过实验结果确定评论利用的最佳时间,以此解决使用大量评论数据导致的方法训练效率较低的问题,实现谣言早期检测. ...
3
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
2
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
基于评论异常度的新浪微博谣言识别方法
1
2020
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
基于评论异常度的新浪微博谣言识别方法
1
2020
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
基于LDA和随机森林的微博谣言识别研究: 以2016年雾霾谣言为例
1
2019
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
基于LDA和随机森林的微博谣言识别研究: 以2016年雾霾谣言为例
1
2019
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
1
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
6
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [8 ]使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
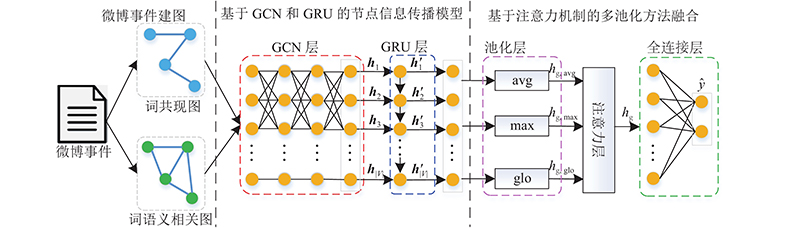
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... 本研究软件环境:Python3.6+TensorFlow1.14,硬件环境:CPU: Intel Xeon Gold 5218,内存:64 G,显卡:NVIDIA GeForce RTX 2080Ti. 实验采用公开的微博数据集Ma_Dataset[8 ] 和Song_Dataset[11 ] ,2个数据集的详细信息如表1 所示. 表中,n u 、n e 、n r 、n t 、n c 分别为用户数、事件数、谣言事件数、非谣言事件数、评论数. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
Rumor events detection from chinese microblogs via sentiments enhancement
4
2019
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [9 ]建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... GRU由 Cho 等[9 ] 基于LSTM提出. LSTM通过输入门、遗忘门和输出门分别控制输入值、记忆值和输出值,而GRU只有2个门,更新门和重置门,因此比标准的LSTM模型要简单. 利用GRU更新节点状态过程如下: ...
基于用户特征分析的微博谣言早期检测研究
2
2020
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [10 ]利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
基于用户特征分析的微博谣言早期检测研究
2
2020
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [10 ]利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
CED: credible early detection of social media rumors
4
2019
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [11 ]将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... 本研究软件环境:Python3.6+TensorFlow1.14,硬件环境:CPU: Intel Xeon Gold 5218,内存:64 G,显卡:NVIDIA GeForce RTX 2080Ti. 实验采用公开的微博数据集Ma_Dataset[8 ] 和Song_Dataset[11 ] ,2个数据集的详细信息如表1 所示. 表中,n u 、n e 、n r 、n t 、n c 分别为用户数、事件数、谣言事件数、非谣言事件数、评论数. ...
基于卷积神经网络的谣言检测
2
2017
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [12 ]将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
基于卷积神经网络的谣言检测
2
2017
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
... [12 ]将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
一种基于多关系传播树的谣言检测方法
1
2021
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
一种基于多关系传播树的谣言检测方法
1
2021
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
Rumor detection based on propagation graph neural network with attention mechanism
1
2020
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
融合源信息和门控图神经网络的谣言检测研究
1
2021
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
融合源信息和门控图神经网络的谣言检测研究
1
2021
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
1
... 考虑到人工识别谣言成本高昂,近年来,学者开始逐渐关注基于传统机器学习和基于深度学习的自动化谣言检测方法. 基于机器学习的方法主要集中在特征选择和抽取[3 -5 ] 、方法选择和优化[6 -7 ] 这两方面. 但是,由于机器学习方法普遍面临最优特征选择困难、检测精度不高的不足,越来越多的学者开始使用循环神经网络(recurrent neural network, RNN)[8 ] 、门控循环单元(gate recurrent unit, GRU)[9 ] 、长短期记忆网络(long short term memory, LSTM)[10 ] 、卷积神经网络(convolutional neural network, CNN)[11 -12 ] 等深度学习方法进行谣言检测. Ma等[8 ] 使用RNN来捕获评论的上下文信息随时间的变化,实现了快速准确的谣言检测. Wang等[9 ] 建立情感词典并使用双层GRU获取微博的细粒度情感表达. 尹鹏博等[10 ] 利用微博用户的历史行为特征,使用LSTM实现谣言早期检测. Song等[11 ] 将所有转发信息视为一个序列,并通过CNN实现可信早期检测研究. 刘政等[12 ] 将微博内容句向量化,并使用CNN来获取深层特征. 胡斗等[13 ] 建立多关系图卷积网络获取源节点和关键传播节点在传播中的潜在影响力. Wu等[14 ] 基于传播结构建立全局信息传播图神经网络,并引入注意力机制动态调整各节点的权重. 杨延杰等[15 ] 建立融合门控机制和源信息的传播图卷积网络,增强源信息的影响力. Yang等[16 ] 通过用户、帖子和用户评论的关系建立图卷积网络(graph convolutional network, GCN),利用图对抗框架学习独特结构特征. ...
1
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
4
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
... [18 ]的方法实现半监督学习的谣言检测. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
1
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
12
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
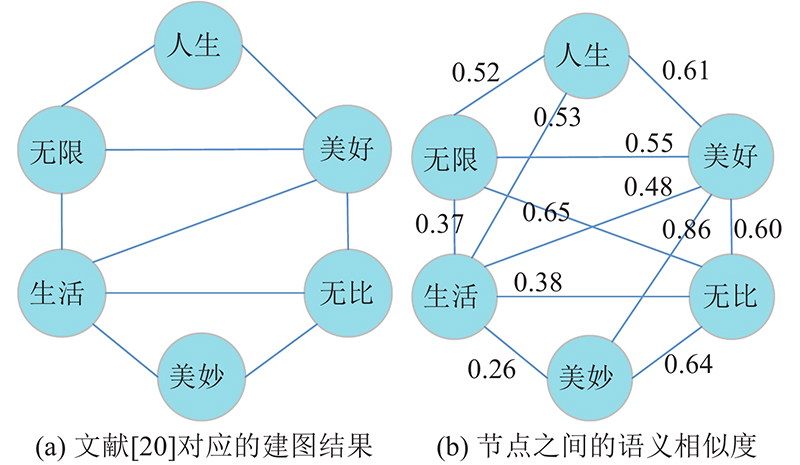
... Zhang等[20 ] 通过词的共现关系构建单词图,但该方法忽略了词之间的语义关系且没有区分不同词之间的权重大小. 以语句“人生无限美好生活无限美妙”为例,如图3 (a)所示为Zhang等[20 ] 方法对应的建图结果,如图3 (b)所示为使用Word2Vector词向量和余弦相似度得到的不同节点之间的语义相似度. 由图3 (a)可知,“人生”和“生活”、“无限”和“无比”、“美好”和“美妙”之间不存在连接关系,但图3 (b)显示这3对词之间均具有较强的语义相关性. 可以看出,Zhang等[20 ] 仅以窗口大小确定节点对应的邻居节点,且将所有连边权重同等对待,难以准确表达相距较远的词语之间的语义关系. ...
... [20 ]方法对应的建图结果,如图3 (b)所示为使用Word2Vector词向量和余弦相似度得到的不同节点之间的语义相似度. 由图3 (a)可知,“人生”和“生活”、“无限”和“无比”、“美好”和“美妙”之间不存在连接关系,但图3 (b)显示这3对词之间均具有较强的语义相关性. 可以看出,Zhang等[20 ] 仅以窗口大小确定节点对应的邻居节点,且将所有连边权重同等对待,难以准确表达相距较远的词语之间的语义关系. ...
... [20 ]仅以窗口大小确定节点对应的邻居节点,且将所有连边权重同等对待,难以准确表达相距较远的词语之间的语义关系. ...
... 文献[20 ]建图方法面临问题举例 ...
... Example of problems in graph construction of reference [20 ] ...
... 为了解决上述问题,本研究基于每个微博事件对应的微博源文和相关评论构成的语句,通过在词共现邻接矩阵Ψ Φ [20 ] 方法类似,Ψ
... 给定GRU输出节点向量H L +1$ {\boldsymbol{h}}_k' $ k ≤|V |),Zhang等[20 -21 ] 通过使用固定的池化方法降低节点向量维度,难以有效融合不同池化方法的优势. 为此,本研究引入注意力机制,通过融合平均池、最大池、全局池[21 ] 函数获得最终图级向量表示,有效利用不同节点在图中的作用,具体如下: ...
... 为了验证基于语义相关性的建图方法的有效性,将基于词共现性(word co-occurrence, WC)邻接矩阵的建图方法[20 ] 和本研究建图方法进行对比. 这里将WC方法中的滑动窗口大小设定为3,并将本研究建图方法按照语义相关性阈值th划分为如表3 所示的6种不同情况. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
6
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... 本研究提出了基于图卷积网络的归纳式谣言检测方法−归纳式图卷积网络 (inductive graph convolutional network,IGCN). 如图2 所示,首先针对微博谣言数据集中的每个微博事件,以源微博和其评论中出现的词语为节点,利用词共现性和词语义相关性建图;然后,提出基于GCN和GRU的归纳式节点信息传播模型,经过GCN层和GRU层获得微博事件节点信息交互后的向量表达;最后,使用注意力机制融合不同池化方法(最大池、平均池、全局池[21 ] )的优势在池化层得到微博事件的最终图级向量表达,将其输入到全连接层中,通过计算损失函数值实现模型训练参数优化,完成谣言检测. ...
... 给定GRU输出节点向量H L +1$ {\boldsymbol{h}}_k' $ k ≤|V |),Zhang等[20 -21 ] 通过使用固定的池化方法降低节点向量维度,难以有效融合不同池化方法的优势. 为此,本研究引入注意力机制,通过融合平均池、最大池、全局池[21 ] 函数获得最终图级向量表示,有效利用不同节点在图中的作用,具体如下: ...
... [21 ]函数获得最终图级向量表示,有效利用不同节点在图中的作用,具体如下: ...
... 为了验证基于注意力机制的多池化方法融合的有效性,首先使用基于语义相关性的建图方法对数据集中每个微博事件单独建图,然后利用本研究提出的基于GCN和GRU的信息传播模型获得图中不同节点向量表达,最后分别使用平均池化方法(AVG)、最大池化方法(MAX)、全局池化方法(GLO)[21 ] 以及本研究池化方法(MIX)获取微博事件对应的最终图级向量. 将式(23)作为损失函数并进行训练后,得到不同批尺寸情况下上述池化方法对应的Acc,结果如图6 所示. 可以看出,当批尺寸分别为128、256、512、1024时,在2个数据集中,MIX方法均表现最好,在Ma_Dataset中该方法比表现次优方法对应的Acc分别高出0.004、0.001、0.004、0.002,而在Song_Dataset中对应的Acc分别高出0.005、0.006、0.006、0.008. 当批尺寸为128时,MIX方法能够获得最大Acc,对应数据集Ma_Dataset和Song_Dataset结果分别为0.949和0.925,充分证明了本研究基于注意力机制的多池化方法融合策略在获取最终图级向量表达方面的有效性. ...
基于图卷积网络的谣言鉴别研究
8
2021
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... GCN是CNN的推广,可以直接对图进行卷积操作. 给定图G ={V ,E ,A V 为G 中节点集合(节点数量为n );E 为G 中边的集合;A A R n ×n [22 ] : ...
... 基于GCN的文本分类方法依靠邻接矩阵更新节点状态信息[22 ] ,而邻接矩阵仅描述节点的邻居信息,缺乏对文本中连续上下文语义的表达. 鉴于GRU能够自动学习连续节点的上下文信息,将其与GCN结合,提出新的信息传播模型以实现图中节点向量信息的有效交互. 针对微博事件Ei ,首先抽取Ei 中所有词语V ={v j v j V 中第j 个词语)并利用Word2Vector模型构建词向量H 1 (H 1 由h j h j v j Ψ Φ l 层(1<l ≤L )节点状态H l H l $ {\boldsymbol{h}}_j^l $ $ {\boldsymbol{h}}_j^l $ j 在第l 层的状态向量): ...
... 式中:k ≥2, $ {\boldsymbol{h}}_1' $ h 1 . 可以看出,本研究所提出的基于GCN和GRU的信息传播模型以每个微博事件中的词向量为输入,通过利用词共现性邻接矩阵和词语义相关性邻接矩阵有效融合词语的连续上下文信息和非连续语义相关信息. 与米源等[22 ] 不同的是,本研究针对每个微博事件建立词共现图和词语义相关图,因此可以从大量训练样本数据中学习有用规则以实现对未知微博事件的谣言检测,避免了米源等[22 ] 的研究中测试数据必须参与训练导致模型无法推广到一般任务的问题. ...
... [22 ]的研究中测试数据必须参与训练导致模型无法推广到一般任务的问题. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
基于图卷积网络的谣言鉴别研究
8
2021
... 上述基于CNN和RNN的方法主要关注局部特征,忽略了非连续单词之间的信息交互. 为此,Hu等[17 ] 集成附加信息,提出异构图注意力网络(heterogeneous graph attention networks, HGAT)来解决短文本标记数据稀疏问题.Yao等[18 ] 基于单词共现和文档-单词关系建图,利用图卷积网络实现词和文档嵌入表达的学习. Liu等[19 ] 构造文本图张量来描述语义、句法和顺序上下文信息,通过GCN实现信息图内传播和图间传播. Zhang等[20 ] 利用Li等[21 ] 提出的模型有效实现了新词的归纳学习与上下文单词关系的捕捉. 米源等[22 ] 利用Yao等[18 ] 的方法实现半监督学习的谣言检测. ...
... 但是,现有方法仍面临以下问题:1) Zhang等[20 ] 仅使用词共现建图,忽略了词语语义关系的影响,且固定的池化方法难以有效融合不同节点的特征信息;2) 米源等[22 ] 将所有微博事件建立为一个整图,忽略了同一个词在不同微博事件中的不同作用;且仅通过GCN融合邻居节点信息,缺乏对连续上下文语义的利用;3) 现有微博谣言检测方法使用大量评论信息[8 -9 , 11 ] ,检测效率不高. 因此,本研究提出基于GCN的归纳式微博谣言检测新方法.本研究创新点如下:1) 为每个微博事件单独建图,以词为节点,词的共现性和语义相关性作为节点之间的边,在此基础上提出基于GCN和GRU的节点信息传播模型;2) 在输出层使用注意力机制融合平均池、最大池、全局池[21 ] 方法以获得最终的图级向量,避免传统固定池化方法难以有效捕获节点特征信息的不足;3) 为了提高微博谣言检测效率,研究评论时间对于谣言检测效率的影响,获得用于模型训练的最佳评论时间阈值,兼顾谣言检测准确率和效率. ...
... GCN是CNN的推广,可以直接对图进行卷积操作. 给定图G ={V ,E ,A V 为G 中节点集合(节点数量为n );E 为G 中边的集合;A A R n ×n [22 ] : ...
... 基于GCN的文本分类方法依靠邻接矩阵更新节点状态信息[22 ] ,而邻接矩阵仅描述节点的邻居信息,缺乏对文本中连续上下文语义的表达. 鉴于GRU能够自动学习连续节点的上下文信息,将其与GCN结合,提出新的信息传播模型以实现图中节点向量信息的有效交互. 针对微博事件Ei ,首先抽取Ei 中所有词语V ={v j v j V 中第j 个词语)并利用Word2Vector模型构建词向量H 1 (H 1 由h j h j v j Ψ Φ l 层(1<l ≤L )节点状态H l H l $ {\boldsymbol{h}}_j^l $ $ {\boldsymbol{h}}_j^l $ j 在第l 层的状态向量): ...
... 式中:k ≥2, $ {\boldsymbol{h}}_1' $ h 1 . 可以看出,本研究所提出的基于GCN和GRU的信息传播模型以每个微博事件中的词向量为输入,通过利用词共现性邻接矩阵和词语义相关性邻接矩阵有效融合词语的连续上下文信息和非连续语义相关信息. 与米源等[22 ] 不同的是,本研究针对每个微博事件建立词共现图和词语义相关图,因此可以从大量训练样本数据中学习有用规则以实现对未知微博事件的谣言检测,避免了米源等[22 ] 的研究中测试数据必须参与训练导致模型无法推广到一般任务的问题. ...
... [22 ]的研究中测试数据必须参与训练导致模型无法推广到一般任务的问题. ...
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
2
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
2
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
2
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...
2
... 为了进一步验证本研究方法在微博谣言检测方面的有效性,将本研究方法与最先进的基线方法进行对比,这些方法可以分为:1) 机器学习方法,包括决策树排名(decision tree ranking, DT-Rank)[4 ] 和使用时间序列信息的支持向量机(support vector machine using time series information, SVM-TS)[3 ] ;2) 非图神经网络深度学习方法,包括基于卷积神经网络的文本分类(text classification via convolutional neural networks, Text-CNN)[23 ] 、双层GRU(GRU-2)[8 ] 和可解释虚假新闻检测(explainable fake news detection,dEFEND)[24 ] ;3) 图神经网络深度学习方法,包括基于图卷积网络的文本分类(text classification via convolutional graph networks, Text-GCN)[18 , 22 ] 、双向图卷积网络(bi-directional graph convolutional networks, Bi-GCN)[25 ] 、全局-局部注意力网络(global-local attention networks, GLAN)[26 ] 和基于图神经网络的归纳文本分类(inductive text classification via graph neural networks,TextING)[20 ] ,相关实验设定如表4 所示. 公平起见,深度学习方法未说明的设定与本研究方法的相同. ...
... Parameter settings of different methods for comparisons
Tab.4 对比方法 实验设定 DT-Rank[4 ] 所选特征包括来源可信度、来源身份、来源多样性、来源地址、语言态度、事件传播特征,特征选择方法为信息增益. SVM-TS[3 ] 所选特征为内容特征、用户特征和传播特征,核函数为RBF. Text-CNN[23 ] 卷积核尺寸分别等于3、4、5,卷积核数量为256. GRU-2[8 ] GRU层数为2,词典大小为5 000. dEFEND[24 ] 注意力层维度为100,共注意力层潜在维度为200. Text-GCN[18 , 22 ] GCN层数为2. Bi-GCN[25 ] 模型早停忍耐批次为10. GLAN[26 ] 卷积核尺寸分别等于3、4、5,卷积核数量为100. TextING[20 ] 滑动窗口大小为3.
在此基础上计算不同方法对应的Acc、Pre、Rec及F 1 ,结果如表5 所示. 可以看出,传统方法SVM-TS表现优于DT-Rank. 与SVM-TS相比,本研究对应的Acc、Pre、Rec及F 1 在Ma_Dataset中依次分别提升了0.117、0.125、0.12、0.123,在Song_Dataset中依次分别提升了0.177、0.174、0.161、0.167. 与传统机器学习方法相比,非图神经网络深度学习方法对应的Acc、Pre、Rec及F 1 普遍偏高. 其中,dEFEND表现最佳,对应的Acc、F 1 在Ma_Dataset中分别为0.917、0.920,在Song_Dataset中分别为0.881、0.885. 进一步发现,图神经网络方法表现明显优于其他方法,这可能是因为此类方法在谣言检测时能有效利用长距离非连续单词的语义交互信息. 在Ma_Dataset和Song_Dataset中,与dEFEND相比,本研究方法的Acc分别提升了0.029、0.042,F 1 分别提升了0.021、0.038;与 TextING相比,Acc分别提升0.008、0.011,F 1 分别提升0.001和0.013,验证了基于语义相关性的微博建图方法以及基于注意力机制的多池化方法融合策略在提升微博谣言检测表现上的有效性. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}