

随着楼宇自控系统的普及,大量建筑运行数据被保留下来,促进了基于数据驱动的建筑负荷预测技术的发展[4]. 与基于物理建模的方法相比,基于数据驱动的技术拥有精度高和建模便捷的优势,具有极大的应用前景[5]. 目前大多数基于数据驱动的建筑负荷预测研究聚焦于点预测(给出负荷预测值). 例如,孙超等[6]使用改进的反向传播(back propagation,BP)神经网络对建筑用电负荷进行预测. Fan等[7]比较了多种数据驱动算法(多元线性回归、随机森林、极端梯度提升、深度神经网络、支持向量回归等)在建筑冷负荷预测中的性能,结果发现极端梯度提升算法的性能最佳. 实际中,由于数据噪声、极端工况、模型本身的局限性等原因,点预测的结果往往存在不确定性,从而降低了基于点预测的优化控制[8]和故障诊断[9]的可靠性.
针对上述问题,研究人员提出使用预测区间估计方法来描述点预测的不确定性. 预测区间被定义为某一范围,实际负荷将以一定概率落在该范围内. 预测区间越窄,表明负荷点预测结果越可靠. 目前的建筑负荷预测区间估计方法大致可以分为3类:残差分布假设法、回归建模法和残差聚类法. 残差分布假设法通过对模型残差的统计分布进行假设来估计模型预测值的残差范围. 标准正态分布[10-12]和零均值拉普拉斯分布[13]是该领域最常用的2种分布假设. 由于负荷特征和模型类型各异,较难对残差分布进行准确假设,因此该方法的可靠性较差. 而回归建模法和残差聚类法不需要对模型残差的统计分布进行任何假设,具有更高的可靠性. 回归建模法通过构建模型输入和预测区间上下限之间的函数关系,从而估计模型的预测区间. Quan等[14-15]使用神经网络来学习模型输入和预测区间上下限之间的函数关系,并用于估计电力负荷预测区间. Xu等[16]使用分位数回归技术估计递归神经网络的预测区间,并将其应用于住宅建筑电耗预测区间的估计. 残差聚类法使用聚类技术对模型残差进行分组,并根据不同分组内的残差分位数估计模型的预测区间. Zhang等[9]通过聚类得到某办公建筑冷负荷预测模型在不同输入组合下的残差分布,然后根据不同残差分布下的分位数估计模型的预测区间. 和回归建模法相比,残差聚类法编程难度更低,计算效率更高. 此外,回归建模会引入新的模型不确定性,因此残差聚类法的可靠性也更高. 但是,目前的研究在残差聚类时假设不同输入对模型预测残差的影响程度相同,这一假设在实际中并不合理. 例如,Zhang等[4]发现历史负荷对建筑负荷预测结果的影响显著大于室外气象参数的. 即使历史负荷和室外气象参数变化程度相同,模型残差的变化程度也是不同的. 传统的残差聚类法将这类残差划分到一组,从而导致残差聚类不合理. 因此,在残差聚类时须考虑模型输入对预测结果的贡献程度,从而获得更合理的残差分组,提高区间估计的可靠性和准确性.
综上所述,本研究提出基于加权残差聚类的建筑负荷预测区间估计方法,并在深圳某建筑1 a的运行数据集上进行验证. 相较于前人的方法,本研究使用了Shapley additive explanations (SHAP)量化模型输入的贡献程度,并基于得到的贡献程度对模型输入进行加权聚类,旨在得到更可靠的残差聚类和区间估计结果. 该方法不对残差的统计分布进行任何假设,理论上适用于所有数据驱动的建筑负荷预测模型.
1. 建筑负荷预测区间估计方法
1.1. 方法流程图
如图1所示,本研究提出的基于加权残差聚类的预测区间估计方法主要包括3个步骤:模型训练和解释、模型残差聚类和预测区间估计. 模型训练和解释旨在利用训练数据训练一个建筑负荷预测模型,然后使用SHAP方法对模型输入的重要程度进行解释,最后根据得到的模型输入重要程度对训练集中的模型输入进行加权. 模型残差聚类旨在使用k-means算法对加权后的模型输入进行聚类,并借助基于核密度估计的方法剔除异常残差,从而得到不同输入组合下的残差分布. 预测区间估计旨在使用训练得到的模型对建筑负荷进行实时预测,然后根据加权后的模型输入找到最匹配的残差分布,并通过计算残差分位数得到模型预测结果的预测区间.
图 1
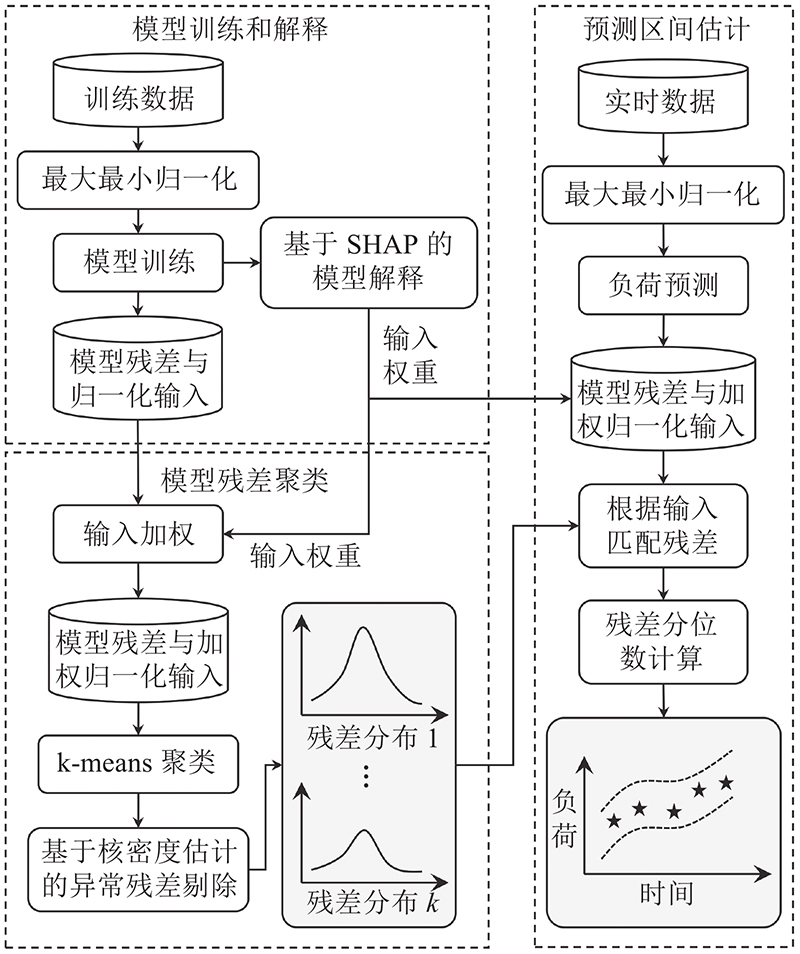
1.2. 模型训练和解释
建筑负荷预测模型输入变量的取值范围差别很大,加大了模型训练的难度和时间[17]. 因此,在模型训练前须对模型输入和输出进行最大最小归一化,将所有变量缩放至[0,1.0].
常用的建筑负荷预测黑箱算法有人工神经网络、支持向量回归、随机森林、极端梯度提升(extreme gradient boosting, XGBoost)等. 其中,XGBoost是一种基于boosting的集成学习算法. 其核心思想为递进地训练多个树模型,每个树模型拟合前一个树模型的预测误差,最终将各个树模型的输出线性相加得到最终的预测值. 目前,XGBoost已经被证明是以上几种算法中精度最高的[18]. 因此,本研究采用该算法对建筑负荷进行预测.
研究表明不同输入对模型预测结果影响各异[19],可以用敏感性分析[4]、SHAP[20]和local interpretable model-agnostic explanations(LIME)[21]等方法进行解释. 敏感性分析只能对模型全局预测性能进行解释,由于忽略了模型局部预测性能,其准确性比SHAP和LIME更低. 此外,根据Främling等[22]的研究,对于回归任务,SHAP比LIME的准确性更高,后者在某些输入的解释上出现了显著错误. 因此,本研究采用SHAP对模型进行解释. 该方法不仅适用于XGBoost,也可以解释其他数据驱动模型输入对输出的重要程度,因此本研究提出的方法具有通用性.
Shapley一词最早源自博弈论,通常被用作评估每个玩家在博弈游戏中对该游戏的贡献程度. SHAP的原理和Shapley类似,旨在评估每个模型输入对模型输出的贡献程度. 该方法使用了加性特征归因思想,即假设模型输出都是输入的线性相加[23]. 原始模型的解释模型如下:
式中:g(∙)为解释模型;
式中:N为所有简化输入的集合,S为N的子集,fx(S)为模型输入为S时原始模型的输出.
SHAP值能够反映单次预测中每个输入对输出的贡献,其绝对值越大,表示贡献越大. 计算某变量在所有样本上SHAP值的绝对值,取其平均值,便得到了该变量的全局SHAP 值.
1.3. 模型残差聚类
模型残差为实际负荷与模型预测负荷之差:
式中:e为模型残差,y为实际负荷,
模型预测负荷取决于模型输入. 由此可知,模型残差与模型输入之间存在强相关性,不同模型输入下的模型残差分布会存在显著差异[9]. 因此,为了得到更可靠的残差分布,在进行输入聚类前须根据其SHAP值进行加权,在加权后,贡献大的输入在聚类时将产生更大的作用. 表达式如下:
式中:
在对输入进行加权后,使用k-means算法对输入进行聚类. k-means算法是目前最经典的聚类算法之一,具有收敛快和易于编程的优点. 该算法会首先随机选择k个样本点作为初始聚类中心,然后计算每个样本点到各聚类中心的欧氏距离并将该样本点划分到距离最近的聚类中心,当所有样本点都被划分完毕后,重新计算每个类中样本点的平均值作为新的聚类中心,重复以上步骤直到聚类中心不再改变.
由于数据噪声、数据异常和未知工况等原因,可能会出现部分残差偏大,从而导致预测区间过大. 因此,须对异常残差进行识别和剔除. 本研究使用基于核密度估计的异常残差剔除方法[24]:
式中:P(·)为某残差簇内残差的概率密度分布函数,n为某残差簇内的残差总个数,ei为某残差簇内第i个残差,b为带宽,K(∙)为核函数.
核密度估计是一种非参数的变量概率密度分布函数估计算法. 通常,如果某个残差出现的概率很低,可以认为是异常残差,须进行剔除. 残差概率密度的阈值通常为概率密度函数最大值Pmax乘上一个缩放因子. 若某残差出现的概率低于该阈值,则将被识别为异常残差并剔除.
1.4. 预测区间估计
预测区间估计旨在估计一个区间范围,使得实际负荷落在该范围内的概率等于某一个给定的名义置信水平(prediction interval nominal confidence,PINC).
本研究采用以下步骤估计某次预测的预测区间:1)对本次预测的输入进行最大最小归一化及加权;2)计算加权归一化输入与残差簇中心之间的欧氏距离,得到与该输入距离最近的残差簇;3)计算预测区间的上下限[9]. 上下限表达式如下:
式中:U和L分别为预测区间的上下界,
1.5. 评价指标
平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)、决定系数(coefficient of determination,R2)和均方根误差的变异系数(coefficient of variation of root mean squared error,CV-RMSE)是4个常见的黑箱模型精度评价指标. MAE、RMSE和CV-RMSE越小,模型预测值与实际值越接近. R2越接近1,模型预测值与实际值越接近. 表达式分别如下:
式中:
预测区间覆盖概率(prediction interval coverage probability,PICP)和平均覆盖误差(average coverage error,ACE)是最常见的预测区间性能评价指标[9]. PICP指实际值落在预测区间内的真实概率,值越大,实测值落在预测区间的概率越大. ACE指PICP与PINC之差,值越接近0,实际值落在预测区间内的概率越接近理想值.
式中:q为实际值的个数;ci表示第i个实际值是否落在预测区间内,0表示否,1表示是.
2. 验证结果与分析
2.1. 数据概况
采用深圳某办公建筑1 a的冷负荷数据集(采样间隔10 min)对提出的方法进行验证. 该数据集包含6个变量(月份M、时刻H、周几W、室外温度Tout、室外湿度RHout和建筑冷负荷CL)从2016年1月1日—2016年12月31日共310 766个测量值. 按85∶15的比例将数据集随机划分为训练集和测试集,并采用最大最小归一化对训练集和测试集的数据进行归一化. 训练集用于模型训练和残差聚类,测试集用于性能验证.
2.2. XGBoost模型训练结果
月份、时刻和周几分别反映了建筑冷负荷的季节性规律、日内规律和周内规律,室外温度和室外湿度是冷负荷的重要影响因素,历史冷负荷反映了建筑热惯性. 以上变量是当前建筑冷负荷预测中最常用的输入变量[25]. 因此,本研究采用月份、时刻、周几、室外温度、室外湿度、前1 h冷负荷(CL1)和前2 h冷负荷(CL2)作为模型输入.
为了得到最优的模型结构,首先须优化XGBoost算法的超参数. 本研究中涉及的超参数包括树的最大深度dmax、学习率l、树的特征采集比例p1、训练样本占比p2和树的个数Ntree. 采用交叉验证和网格搜索在训练集上对以上超参数进行寻优,寻优范围和结果如表1所示.
表 1 XGBoost超参数寻优结果
Tab.1
| 超参数 | 寻优范围 | 最优值 |
| dmax | 2.0, 3.0, 4.0, 5.0 | 5.0 |
| l | 0.2, 0.4, 0.6, 0.8, 1.0 | 0.2 |
| p1 | 0.2, 0.4, 0.6, 0.8, 1.0 | 0.8 |
| p2 | 0.2, 0.4, 0.6, 0.8, 1.0 | 1.0 |
| Ntree | 50.0, 100.0, 150.0, 200.0 | 100.0 |
表 2 XGBoost模型在训练集和测试集上的精度
Tab.2
| 数据集 | MAE/kW | RMSE/kW | R2 | CV-RMSE/% |
| 训练集 | 321.44 | 531.52 | 0.94 | 15.93 |
| 测试集 | 366.15 | 616.83 | 0.92 | 15.74 |
2.3. 基于SHAP的模型解释结果
利用SHAP方法对XGBoost模型输入的重要程度进行量化. 如图2所示为模型输入在所有样本上的SHAP值的分布,如表3所示为所有样本点下的归一化全局SHAP值
图 2
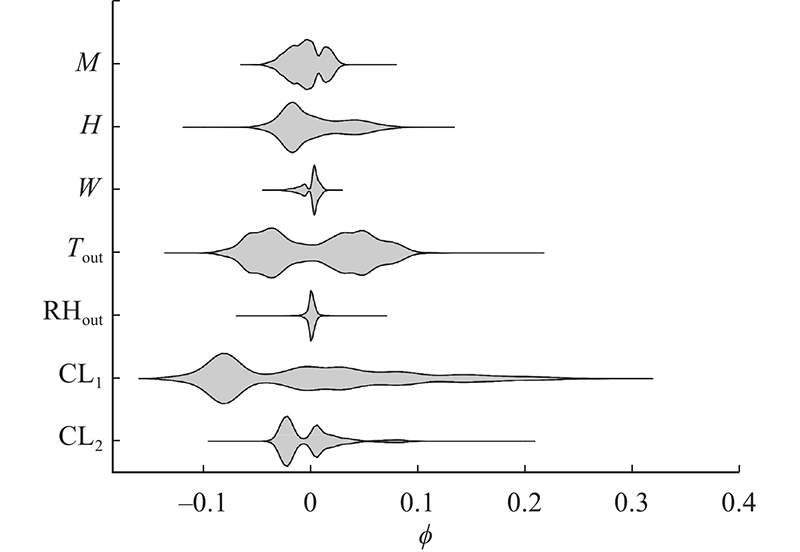
图 2 模型输入的局部SHAP值小提琴图
Fig.2 Violin plots of local SHAP values for each model input
表 3 模型输入的归一化全局SHAP值和XGBoost特征重要性
Tab.3
| 变量 | | I |
| M | 0.04 | 0.02 |
| H | 0.13 | 0.04 |
| W | 0.04 | 0.01 |
| Tout | 0.23 | 0.08 |
| RHout | 0.01 | 0.01 |
| CL1 | 0.39 | 0.54 |
| CL2 | 0.12 | 0.30 |
2.4. 预测区间估计结果
基于表3中各输入的全局SHAP值对归一化后的输入进行加权,然后采用k-means算法对训练集上的残差进行聚类. 为了得到最优的k值,对不同k值下的预测区间估计效果进行比选. 如表4所示为k值分别为2~10,名义置信水平分别为10%~90%(间隔10%)时ACE绝对值的平均值与传统方法[9](不进行输入加权)的ACE绝对值的平均值的对比. 表中,
表 4 不同k值下的ACE绝对值的平均值
Tab.4
| k | | |
| 本研究方法 | 传统方法 | |
| 2 | 2.37 | 2.77 |
| 3 | 1.87 | 2.63 |
| 4 | 2.08 | 2.93 |
| 5 | 2.10 | 2.71 |
| 6 | 2.23 | 2.58 |
| 7 | 2.50 | 2.64 |
| 8 | 2.34 | 2.40 |
| 9 | 2.48 | 2.41 |
| 10 | 2.82 | 2.27 |
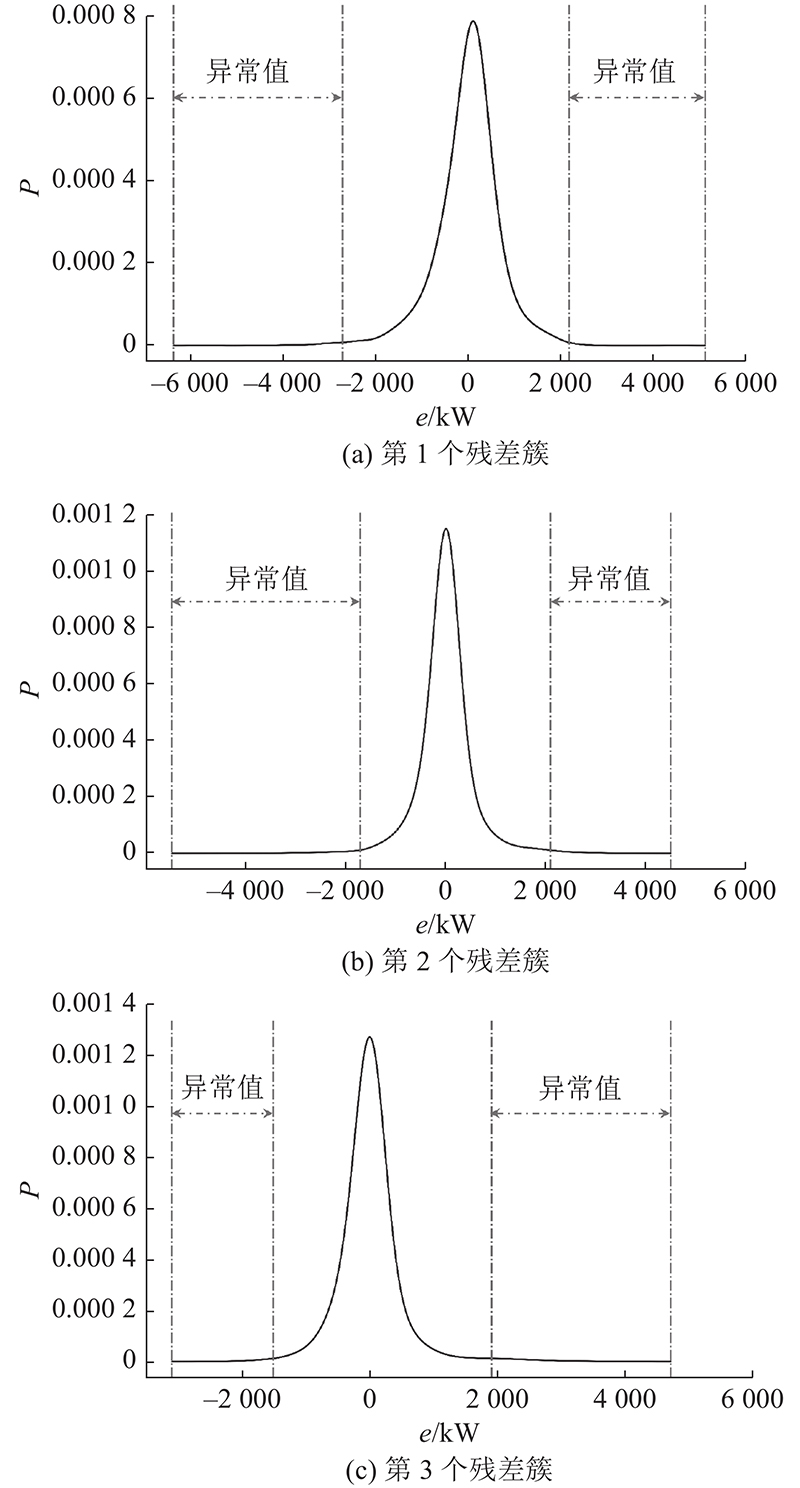
当k=3时,各个残差簇的残差分布如图3所示,其中核密度估计的带宽为200,异常值阈值的缩放因子为0.01. 图中e为预测残差,P为概率密度. 可以看出,不同残差簇中的残差分布各不相同,第1、2、3个残差簇的残差分布范围分别为−2 724.13~2 178.70、−1 710.28~2 095.28、−1515.51~1 904.56 kW.
图 3
当k=3时,不同PINC下测试集上的PICP和ACE如表5所示. 可以看出,本研究中提出的预测区间估计方法得到的PICP与PINC十分接近,表明本研究提出的方法十分可靠.
表 5 不同名义置信水平下的预测区间估计性能(k = 3)
Tab.5
| PINC/% | PICP/% | ACE/% |
| 10 | 9.75 | −0.25 |
| 20 | 19.55 | −0.45 |
| 30 | 29.33 | −0.67 |
| 40 | 38.36 | −1.64 |
| 50 | 47.78 | −2.22 |
| 60 | 57.11 | −2.89 |
| 70 | 67.17 | −2.83 |
| 80 | 76.99 | −3.01 |
| 90 | 87.11 | −2.89 |
当PINC=80%、90%时,某典型日的预测区间曲线如图4所示. 可以看出,该预测模型在负荷较低时的不确定性较小(预测区间较小),在负荷较高时的不确定性较大(预测区间较大). 表明本研究提出的方法可以自适应地学习到不同输入下负荷预测模型的不确定性大小.
图 4
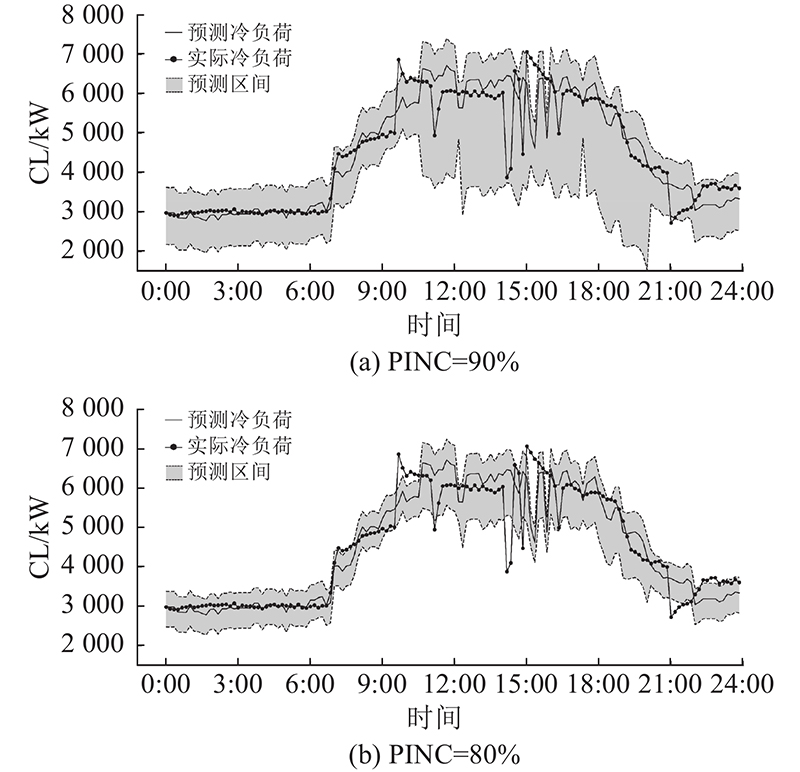
图 4 某典型日的实际负荷曲线、预测负荷曲线及估计得到的预测区间(PINC=80%、90%)
Fig.4 Illustration of actual load curve, predicted load curve and estimated prediction intervals on a typical day (PINC=80% and 90%)
3. 结 论
(1)与传统不对输入进行加权的方法相比,本研究方法可以显著提升预测区间估计的精度. 不对输入进行加权,则ACE绝对值的平均值的最优值为2.27%. 而进行加权后,ACE绝对值的平均值的最优值为1.87%.
(2)在不同输入情况下,模型预测残差的分布存在显著差异. 该方法共得到了3个残差簇,残差簇内的残差分布范围分别为−2 724.13~2 178.70、−1 710.28~2 095.28、−1 515.51~1 904.56 kW,三者存在显著差异.
(3)该方法能够根据模型工况的变化,自适应地估计建筑负荷预测模型的预测不确定性大小. 结果表明,当负荷较低时XGBoost模型的不确定性较小(预测区间较小),当负荷较高时XGBoost模型的不确定性较大(预测区间较大).
(4)该方法不基于任何残差分布假设,可以用于估计任何数据驱动的建筑负荷预测模型的不确定性. 虽然本研究仅采用了目前最为主流的XGBoost算法对该方法进行了验证,但是理论上如果将XGBoost算法换成其他数据驱动算法,该方法依然适用.
后续工作将围绕更精细化的残差聚类展开,例如可以借鉴分层聚类的思想,先根据时间变量对残差进行分组,然后再根据剩余变量依次对残差进行聚类. 此外,还将进一步论证该预测区间估计方法在本领域其他预测任务上的性能(例如风力发电量和能源价格),并探究该方法在建筑能源系统优化运行和故障诊断中的应用.
参考文献
我国城市建筑碳达峰与碳中和路径探讨
[J].
Discussion on paths of carbon peak and carbon neutrality of urban buildings in China
[J].
A hybrid deep learning-based method for short-term building energy load prediction combined with an interpretation process
[J].DOI:10.1016/j.enbuild.2020.110301 [本文引用: 3]
Energy prediction techniques for large-scale buildings towards a sustainable built environment: a review
[J].DOI:10.1016/j.enbuild.2020.110238 [本文引用: 1]
改进BP神经网络的楼宇负荷预测
[J].
Research on building load forecasting based on improved BP neural network
[J].
A short-term building cooling load prediction method using deep learning algorithms
[J].DOI:10.1016/j.apenergy.2017.03.064 [本文引用: 1]
Robust optimization based optimal chiller loading under cooling demand uncertainty
[J].DOI:10.1016/j.applthermaleng.2018.11.122 [本文引用: 1]
A generic prediction interval estimation method for quantifying the uncertainties in ultra-short-term building cooling load prediction
[J].DOI:10.1016/j.applthermaleng.2020.115261 [本文引用: 6]
Using ensemble weather predictions in district heating operation and load forecasting
[J].DOI:10.1016/j.apenergy.2017.02.066 [本文引用: 1]
A very short-term probabilistic prediction interval forecaster for reducing load uncertainty level in smart grids
[J].
Hybrid Kalman filters for very short-term load forecasting and prediction interval estimation
[J].DOI:10.1109/TPWRS.2013.2264488 [本文引用: 1]
An improved cooling load prediction method for buildings with the estimation of prediction intervals
[J].DOI:10.1016/j.proeng.2017.09.967 [本文引用: 1]
Uncertainty handling using neural network-based prediction intervals for electrical load forecasting
[J].DOI:10.1016/j.energy.2014.06.104 [本文引用: 1]
A novel hybrid interval prediction approach based on modified lower upper bound estimation in combination with multi-objective salp swarm algorithm for short-term load forecasting
[J].DOI:10.3390/en11061561 [本文引用: 1]
A hybrid data mining approach for anomaly detection and evaluation in residential buildings energy data
[J].DOI:10.1016/j.enbuild.2020.109864 [本文引用: 1]
Adaptive learning based data-driven models for predicting hourly building energy use
[J].DOI:10.1016/j.enbuild.2017.10.054 [本文引用: 1]
Building thermal load prediction through shallow machine learning and deep learning
[J].DOI:10.1016/j.apenergy.2020.114683 [本文引用: 1]
Effect of input variables on cooling load prediction accuracy of an office building
[J].DOI:10.1016/j.applthermaleng.2017.09.007 [本文引用: 1]
EnergyStar++: towards more accurate and explanatory building energy benchmarking
[J].DOI:10.1016/j.apenergy.2020.115413 [本文引用: 1]
A novel methodology to explain and evaluate data-driven building energy performance models based on interpretable machine learning
[J].DOI:10.1016/j.apenergy.2018.11.081 [本文引用: 1]
An improved association rule mining-based method for revealing operational problems of building heating, ventilation and air conditioning (HVAC) systems
[J].DOI:10.1016/j.apenergy.2019.113492 [本文引用: 1]
A systematic feature selection procedure for short-term data-driven building energy forecasting model development
[J].DOI:10.1016/j.enbuild.2018.11.010 [本文引用: 1]
Validation of calibrated energy models: common errors
[J].DOI:10.3390/en10101587 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}