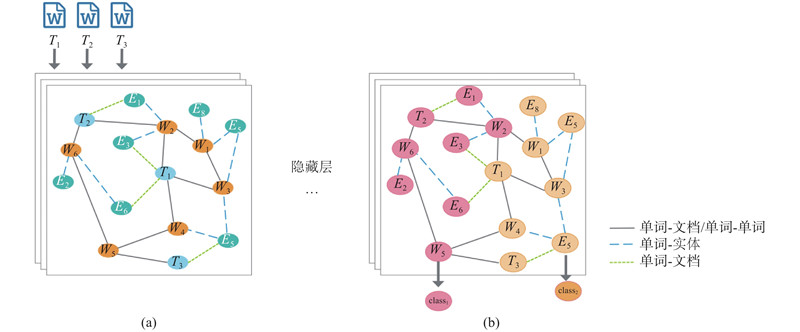
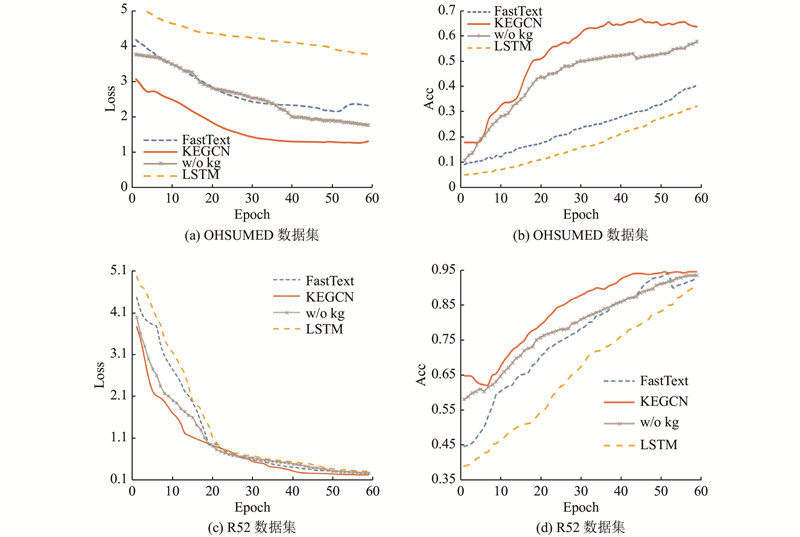
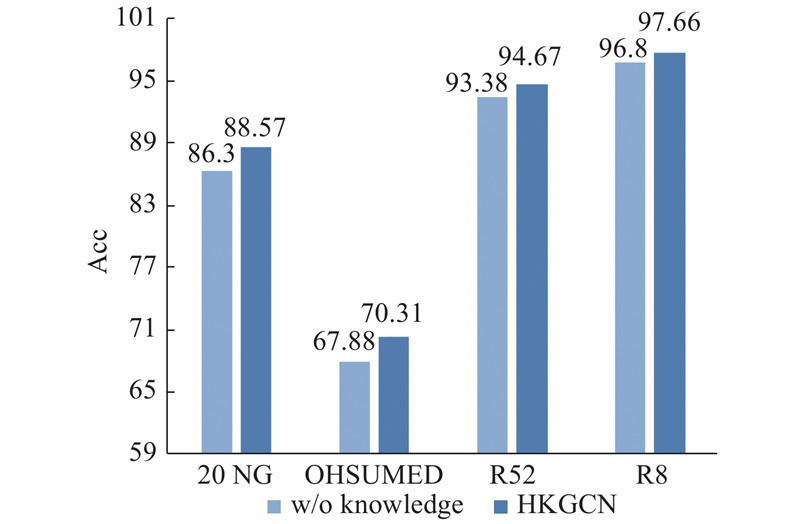
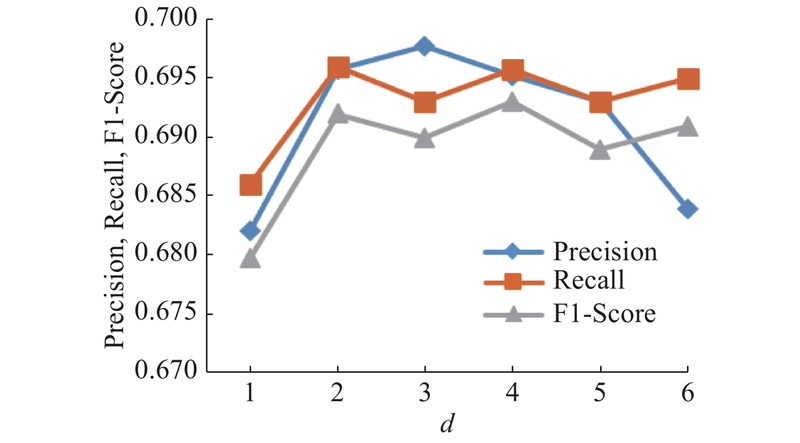
A new knowledge-enhanced graph convolutional neural network (KEGCN) classification model was proposed aiming at the problem of text classification. In the KEGCN model, firstly a text graph containing word nodes, document nodes, and external entity nodes was constructed on the entire text set. Different similarity calculation methods were used between different types of nodes. After the text graph was constructed, it was input into the two-layer graph convolutional network to learn the representation of the node and classified. The KEGCN model introduced external knowledge to compose the graph, and captured the long-distance discontinuous global semantic information, and was the first work to introduce knowledge information into the graph convolution network for classification tasks. Text classification experiments were conducted on four large-scale real data sets, 20NG, OHSUMED, R52 and R8, and results showed that the classification accuracy of the KEGCN network model was better than that of all baseline models. Results show that integrating knowledge information into the graph convolutional neural network is conducive to learning more accurate text representations and improving the accuracy of text classification.
Keywords:knowledge embedding
;
graph convolutional network
;
neural network
;
text classification
;
natural language processing
YAO L, MAO C, LUO Y. Graph convolutional networks for text classification[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019, 33(1): 7370-7377.
WANG S I, MANNING C D. Baselines and bigrams: simple, good sentiment and topic classification[C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island: ACL, 2012: 90-94.
KIM Y. Convolutional neural networks for sentence classification[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: EMNLP, 2014: 1746–1751.
LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. NewYork: IJCAI, 2016: 2873–2879.
VATEEKUL P, KUBAT M. Fast induction of multiple decision trees in text categorization from large scale, imbalanced, and multi-label data[C]// 2009 IEEE International Conference on Data Mining Workshops. Miami, FL: IEEE, 2009: 320-325.
LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. NewYork: IJCAI, 2016: 2873-2879.
ZHAO Z, WU Y. Attention-based convolutional neural networks for sentence classification[C]// Proceeding of the 17th Annual Conference of the International Speech Communication Association. San Francisco: INTER SPEECH, 2016: 705-709.
XUE W, ZHOU W, LI T, et al. MTNA: a neural multi-task model for aspect category classification and aspect term extraction on restaurant reviews[C]// Proceedings of the 8th International Joint Conference on Natural Language Processing. Taipei: IJCNLP, 2017: 151-156.
HAMILTON W L, YING R, LESKOVEC J. Inductive representation learning on large graphs[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: NIPS, 2017: 1025-1035.
BOJANOWSKI P, GRAVE E, JOULIN A, et al. Bag of tricks for efficient text classification[C]// Association for Computational Linguistics. Valencia : ACL, 2017: 427-431.
SHEN D, WANG G, WANG W, et al. Baseline needs more love: on simple word-embedding-based models and associated pooling mechanisms[EB/OL]. (2018-05-24). https://arxiv.org/abs/1805.09843.
RAGESH R, SELLAMANICKAM S, IYER A, et al. Hetegcn: heterogeneous graph convolutional networks for text classification[C]// Proceedings of the 14th ACM International Conference on Web Search and Data Mining. Queensland: WSDM, 2021: 860-868.
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: EMNLP, 2014: 1532-1543.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}