[1]
LI L, JIANG R, HE Z B, et al Trajectory data-based traffic flow studies: a revisit
[J]. Transportation Research Part C , 2020 , 114 : 225 - 240
DOI:10.1016/j.trc.2020.02.016
[本文引用: 1]
[2]
YAO J, TAN C, TANG K An optimization model for arterial coordination control based on sampled vehicle trajectories: the stream model
[J]. Transportation Research Part C , 2019 , 109 : 211 - 232
DOI:10.1016/j.trc.2019.10.014
[本文引用: 1]
[3]
WANG L, ABDEL-ATY M, MA W J, et al Quasi-vehicle-trajectory-based real-time safety analysis for expressways
[J]. Transportation Research Part C , 2019 , 103 : 30 - 38
DOI:10.1016/j.trc.2019.04.003
[本文引用: 1]
[4]
XIEK, OZBAY K, YANG H, et al Mining automatically extracted vehicle trajectory data for proactive safety analytics
[J]. Transportation Research Part C , 2019 , 106 : 61 - 72
DOI:10.1016/j.trc.2019.07.004
[本文引用: 1]
[5]
LIU J, HAN K, CHEN X, et al Spatial-temporal inference of urban traffic emissions based on taxi trajectories and multi-source urban data
[J]. Transportation Research Part C , 2019 , 106 : 145 - 165
DOI:10.1016/j.trc.2019.07.005
[本文引用: 1]
[6]
HU J, PARK B B, LEE Y J Coordinated transit signal priority supporting transit progression under connected vehicle technology
[J]. Transportation Research Part C , 2015 , 55 : 393 - 408
DOI:10.1016/j.trc.2014.12.005
[本文引用: 1]
[7]
HU J, PARK B B, LEE Y J Transit signal priority accommodating conflicting requests under connected vehicles technology
[J]. Transportation Research Part C , 2016 , 69 : 173 - 192
DOI:10.1016/j.trc.2016.06.001
[8]
TRUONG L T, CURRIE G, WALLANCE M, et al Coordinated transit signal priority model considering stochastic bus arrival time
[J]. IEEE Transactions on Intelligent Transportation Systems , 2019 , 20 (4 ): 1269 - 1277
DOI:10.1109/TITS.2018.2844199
[9]
KIM H, CHENG Y, CHANG G Variable signal progression bands for transit vehicles under dwell time uncertainty and traffic queues
[J]. IEEE Transactions on Intelligent Transportation Systems , 2019 , 20 (1 ): 109 - 122
DOI:10.1109/TITS.2018.2801567
[本文引用: 1]
[10]
WU W, HEAD L, YAN S H, et al Development and evaluation of bus lanes with intermittent and dynamic priority in connected vehicle environment
[J]. Journal of Intelligent Transportation Systems , 2018 , 22 (4 ): 301 - 310
DOI:10.1080/15472450.2017.1313704
[本文引用: 1]
[11]
BERREBI S J, HANS E, CHIABAUT N, et al Comparing bus holding methods with and without real-time predictions
[J]. Transportation Research Part C , 2018 , 87 : 197 - 211
DOI:10.1016/j.trc.2017.07.012
[本文引用: 1]
[12]
LIM B, ZOHREN S. Time series forecasting with deep learning: a survey [EB/OL]. [2020-09-27]. https://arxiv.org/abs/2004.13408.
[本文引用: 1]
[14]
CHO K, VAN MERRIUENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing . Doha: [s.n.], 2014: 1724–1734.
[本文引用: 2]
[15]
CHO K, VAN MERRIUENBOER B, BAHDANAU D. On the properties of neural machine translation: encoder-decoder approaches [EB/OL]. [2020-10-01]. https://arxiv.org/abs/1409.1259.
[本文引用: 1]
[16]
SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]// Proceedings of the 2014 Advances in Neural Information Processing Systems . Montreal: [s.n.], 2014: 3104–3112.
[本文引用: 1]
[17]
WANG S, CAO J, CHEN H, et al SeqST-GAN: Seq2Seq generative adversarial nets for multi-step urban crowd flow prediction
[J]. ACM Transactions on Spatial Algorithms and Systems (TSAS) , 2020 , 6 (4 ): 1 - 24
URL
[本文引用: 2]
[18]
QIN Y, SONG D, CHEN H, et al. A dual-stage attention-based recurrent neural network for time series prediction[C]// Proceedings of 26th International Joint Conference on Artificial Intelligence. Melbourne: [s.n.], 2017: 2627-2633.
[本文引用: 2]
[19]
KIM B D, KANG C M, KIM J, et al. Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network[C]// Proceedings of the IEEE 20th International Conference on Intelligent Transportation Systems (ITSC) . Yokohama: [s.n.], 2017: 399-404.
[本文引用: 2]
[20]
PARK SH, KIM B D, KANG C M, et al. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture[C]// Proceedings of 2018 IEEE Intelligent Vehicles Symposium (IV) , Changshu: [s.n.], 2018: 1672-1678.
[本文引用: 1]
[21]
MESSAOUD K, YAHIAOUI I, VERROUST-BLONDET A, et al Attention based vehicle trajectory prediction
[J]. IEEE Transactions on Intelligent Vehicles , 2020 , 6 (1 ): 175 - 185
URL
[本文引用: 1]
[22]
SEN R, YU H F, DHILLON I S. Think globally, act locally: a deep neural network approach to high-dimensional time series forecasting[C]// Proceedings of Advances in Neural Information Processing Systems (NIPS) . Vancouver: [s.n.], 2019: 4837-4846.
[本文引用: 2]
[23]
BOX G, JENKIN G. Time Series analysis: forecasting and control [M]. San Francisco: Holden-Day, 1970.
[本文引用: 1]
[24]
BRAHIM-BELHOUARI S, BERMAK A Gaussian process for nonstationary time series prediction
[J]. Computational Stats and Data Analysis , 2004 , 47 (4 ): 705 - 712
DOI:10.1016/j.csda.2004.02.006
[本文引用: 1]
[25]
AARON VAN DEN O, DIELEMAN S, ZEN H, et al. Wavenet: a generative model for raw audio [EB/OL]. [2020-10-01]. https://arxiv.org/abs/1609.03499.
[本文引用: 2]
[26]
SORDONI A, BENGIO Y, VAHABI H, et al. A hierarchical recurrent encoder-decoder for generative context-aware query suggestion[C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management . Melbourne: [s.n.], 2015: 553-562.
[本文引用: 2]
[27]
LOSHCILOV I, HUTTER F. Decoupled weight decay regularization[C]// Proceedings of 7th International Conference on Learning Representations . New Orleans: [s.n.], 2019.
[本文引用: 1]
[28]
KINGMA D, BA J. Adam: a method for stochastic optimization[C]// Proceedings of 3rd International Conference on Learning Representations . San Diego: [s.n.], 2015.
[本文引用: 1]
[29]
DONG H Z, ZHAO C X, FU F J Sharing bus lanes: a new lanes multiplexing-based method using a dynamic time slice policy
[J]. Transport , 2018 , 1 - 38
URL
[本文引用: 1]
[30]
BAHDANAU D, KYUNGHYUN C K, BENGIO Y. Neural machine translation by jointly learning to align and translate[C]// Proceedings of 3rd International Conference on Learning Representations . San Diego: [s.n.], 2015.
[本文引用: 1]
[31]
HOU L, XIN L, LI E S, et al Interactive trajectory prediction of surrounding road users for autonomous driving using structural-LSTM network
[J]. IEEE Transactions on Intelligent Transportation Systems , 2019 , 21 (11 ): 4615 - 4625
URL
[本文引用: 1]
[32]
DAI S, LI L, LI Z Modeling vehicle interactions via modified LSTM models for trajectory prediction
[J]. IEEE Access , 2019 , 7 : 38287 - 38296
DOI:10.1109/ACCESS.2019.2907000
[本文引用: 1]
Trajectory data-based traffic flow studies: a revisit
1
2020
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
An optimization model for arterial coordination control based on sampled vehicle trajectories: the stream model
1
2019
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Quasi-vehicle-trajectory-based real-time safety analysis for expressways
1
2019
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Mining automatically extracted vehicle trajectory data for proactive safety analytics
1
2019
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Spatial-temporal inference of urban traffic emissions based on taxi trajectories and multi-source urban data
1
2019
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Coordinated transit signal priority supporting transit progression under connected vehicle technology
1
2015
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Transit signal priority accommodating conflicting requests under connected vehicles technology
0
2016
Coordinated transit signal priority model considering stochastic bus arrival time
0
2019
Variable signal progression bands for transit vehicles under dwell time uncertainty and traffic queues
1
2019
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Development and evaluation of bus lanes with intermittent and dynamic priority in connected vehicle environment
1
2018
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
Comparing bus holding methods with and without real-time predictions
1
2018
... 近些年,车辆轨迹越来越受到研究者的关注并应用到智能交通系统研究的各个方面,如交通流模型[1 ] 、交通信号控制[2 ] 、交通流状态估计[3 ] 、交通安全和车辆排放估计[4 -5 ] 等. 在公交优先控制系统中,控制系统依据公交车辆到达交叉口停车线的时间优化和选择优先控制策略[6 -9 ] . 得益于车联网技术的支持,间歇式公交专用道条件下的公交优先控制可以有效提升道路的通行能力[10 ] . 在此环境下,公交优先控制须实时预测公交车辆的位置和对应的到达时间即轨迹为控制策略的制定和优化提供充足的时间和更详细的车辆状态信息. 另外,在公交车调度管理的车辆间距控制中,加入轨迹预测后的结果比无轨迹预测条件下的结果更好[11 ] . 因此,公交车辆轨迹预测有助于提升智能公共交通系统的效率. 虽然公交专用道可以减少公交车在使用时间内受道路交通流的干扰,但是在公交车辆轨迹预测时仍须考虑到前方车辆、公交站台通行能力、行人过街等多种因素的影响. 近年来,公交车辆GPS轨迹数据已经逐渐成为一种普遍、连续和可靠的数据源;另外,深度学习在处理复杂任务方面取得了显著成就,为研究公交车辆轨迹预测提供了新的方法和条件,因此须考虑采用最新方法研究公交车辆轨迹预测问题. ...
1
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
Long short-term memory
1
1997
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
2
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
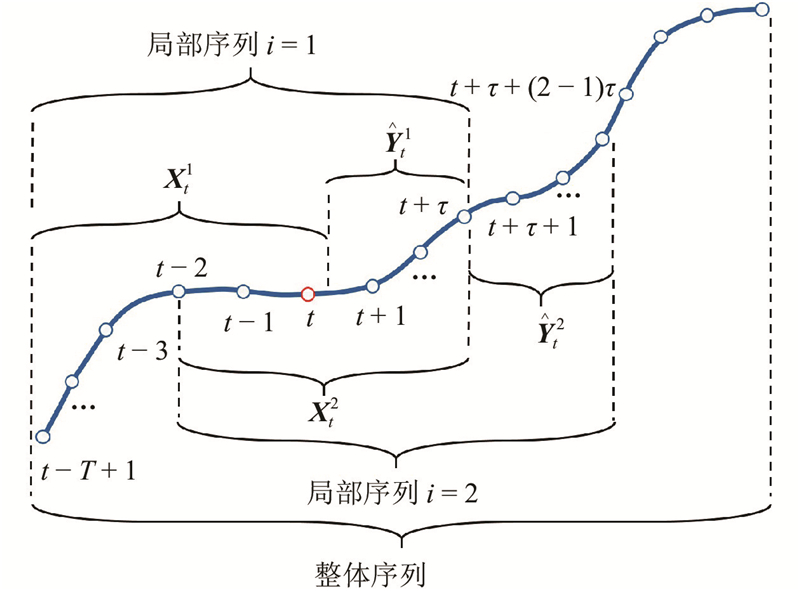
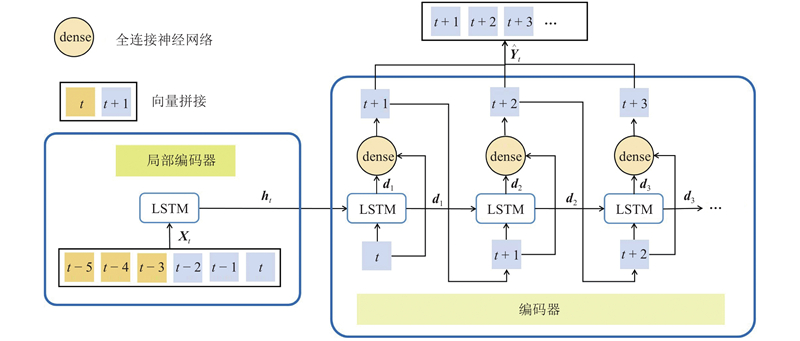
... 公交车辆通过整体路段会持续相对较长的时间. 为了避免随着序列长度的增加,多步Seq2Seq预测的效果下降[14 ] ,借鉴WaveNet[25 ] 的循环结构,单层循环编码器-解码器结构可以依照输入的顺序循环调用局部序列预测的编码器-解码器结构预测每一个局部的较短序列,直到获得最终的整体轨迹,如图3 所示. 在顺序预测过程中,设置第 $i$ ${\boldsymbol{X}}_t^i$ $i - 1$ ${\boldsymbol{X}}_t^{i - 1}$ ${\hat{\boldsymbol{Y}}}_t^{i - 1}$ ${\boldsymbol{X}}_t^i = $ $ \left[ {{x_{t + \left( {i - 2} \right)\tau + T - \tau +1}}, \;\cdots,\; {x_{t + \left( {i - 2} \right)\tau }},\;{{\hat y}_{t + \left( {i - 2} \right)\tau + 1}},\; \cdots ,\;{{\hat y}_{t + \left( {i - 2} \right)\tau + \tau }}} \right]\in$ ${{\bf{R}}^T} $ $\tau < T$ . ...
1
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
1
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
SeqST-GAN: Seq2Seq generative adversarial nets for multi-step urban crowd flow prediction
2
2020
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
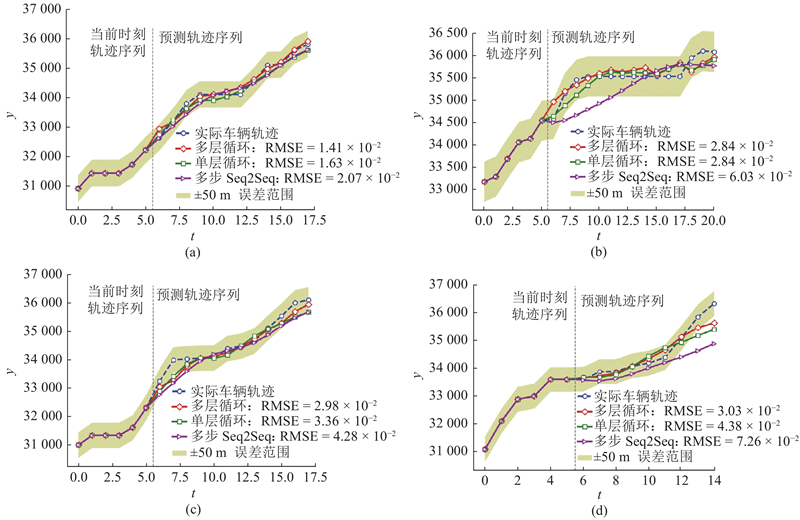
... (2)预测的准确度受到轨迹复杂程度的影响,轨迹所处的环境越复杂,预测准确度越低. 另外,简单提升网络规模不能够显著增加预测准确度. 受到Seq2Seq翻译的启发,预测框架应引入注意力机制[18 , 30 ] ;还可以引入对抗神经网络[17 ] ,使得预测准确度进一步提升. ...
2
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
... (2)预测的准确度受到轨迹复杂程度的影响,轨迹所处的环境越复杂,预测准确度越低. 另外,简单提升网络规模不能够显著增加预测准确度. 受到Seq2Seq翻译的启发,预测框架应引入注意力机制[18 , 30 ] ;还可以引入对抗神经网络[17 ] ,使得预测准确度进一步提升. ...
2
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
1
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
Attention based vehicle trajectory prediction
1
2020
... 车辆轨迹同时包含车辆的时间和空间特征,可以将其视为特殊的时间序列. 在各种可用的深度神经网络架构中,循环神经网络(recurrent neural network,RNN)被广泛应用于分析时间序列[12 ] . 基于长短期记忆(long short-term memory,LSTM)[13 ] 或门控循环单元(gate recurrent unit,GRU)[14 ] 的编码器-解码器结构在从序列到序列(Seq2Seq)翻译[15 -16 ] 方面较突出,因此被应用到时间序列的Seq2Seq预测[17 -18 ] . 目前,在自动驾驶车辆轨迹预测的研究中,编码器-解码器结构已经被应用于高精地图的轨迹Seq2Seq预测[19 -21 ] . 但是自动驾驶应用于公交车辆还须较长的一段时间,另外公交车已经普遍装有较高精度的GPS设备,易于获取车辆轨迹的GPS大数据,为公交车辆轨迹预测采用深度学习的方法提供了研究和应用基础. ...
2
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
... [22 ]. 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
1
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
Gaussian process for nonstationary time series prediction
1
2004
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
2
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
... 公交车辆通过整体路段会持续相对较长的时间. 为了避免随着序列长度的增加,多步Seq2Seq预测的效果下降[14 ] ,借鉴WaveNet[25 ] 的循环结构,单层循环编码器-解码器结构可以依照输入的顺序循环调用局部序列预测的编码器-解码器结构预测每一个局部的较短序列,直到获得最终的整体轨迹,如图3 所示. 在顺序预测过程中,设置第 $i$ ${\boldsymbol{X}}_t^i$ $i - 1$ ${\boldsymbol{X}}_t^{i - 1}$ ${\hat{\boldsymbol{Y}}}_t^{i - 1}$ ${\boldsymbol{X}}_t^i = $ $ \left[ {{x_{t + \left( {i - 2} \right)\tau + T - \tau +1}}, \;\cdots,\; {x_{t + \left( {i - 2} \right)\tau }},\;{{\hat y}_{t + \left( {i - 2} \right)\tau + 1}},\; \cdots ,\;{{\hat y}_{t + \left( {i - 2} \right)\tau + \tau }}} \right]\in$ ${{\bf{R}}^T} $ $\tau < T$ . ...
2
... 在公交专用道的环境下,当目标车辆到达路段上游时,公交轨迹预测任务是在车辆到达路段上游时,按照设定的时间步长,预测车辆到达下游停车线的所有GPS坐标组成的轨迹序列. 考虑到目标公交车辆受到外部环境因素影响进而导致未来轨迹序列到达停车线的时刻即轨迹序列的长度和序列中对应时刻的坐标都具有不确定性,提出将复杂的未来时间段的整体轨迹划分为多个相对简单的局部轨迹序列,再通过预测所有局部序列进而组成整体预测轨迹. 此时,公交车辆轨迹是由局部轨迹时间序列按照时间顺序组成的高维时间序列[22 ] . 传统时间序列预测方法主要有AR、ARIMA[23 ] 和高斯过程[24 ] 等. 在预测车辆轨迹时,由于局限于独立序列的训练和预测,以上模型难于扩展和应用到任意车辆轨迹的高维时间序列和适用于大数据进行训练[22 ] . 因此,选择RNN构建解码器-编码器网络来建立公交车辆轨迹的当前时段序列和预测序列的非线性映射关系以应对轨迹的高维时间序列预测. 车辆轨迹预测问题可以视作:运用RNN建立高维时间序列中从目标车辆当前时间段内的轨迹序列到未来时间段的预测轨迹序列的非线性映射,并通过训练后的RNN实现车辆轨迹的Seq2Seq预测. 目前基于RNN的编码器-解码器结构可以用于轨迹的短时预测[19 -20 ] . 为了应对高维时间序列,首先借鉴WaveNet[25 ] 的循环结构,运用RNN建立单层的循环解码器-编码器结构. 其次考虑到局部序列之间的顺序记忆关系[26 ] ,引入多层循环结构. 最后运用杭州公交专用道的公交车辆GPS轨迹数据对建立的模型进行训练和预测结果的对比分析. ...
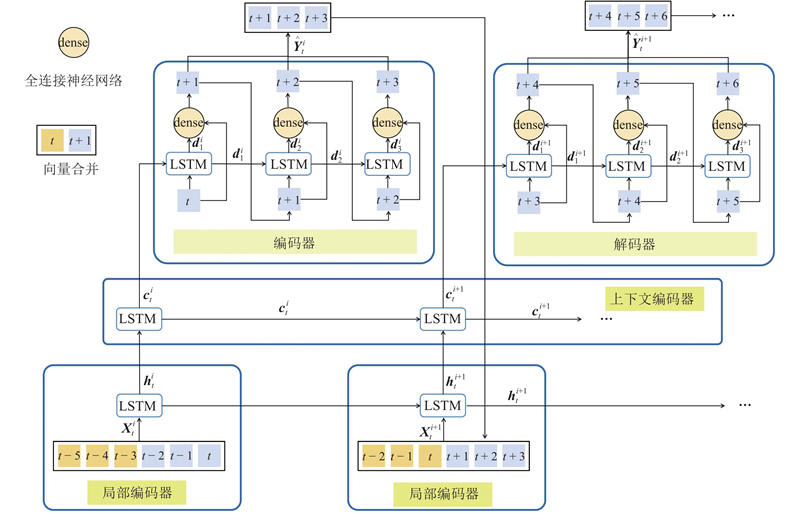
... 多层循环编码器-解码器结构[26 ] 可以划分为局部编码器,上下文编码器(context-encoder)和解码器,如图4 所示. 不同于单层结构,多层结构中的上下文编码层可以利用RNN将局部编码层的隐层信息在预测全过程中传递. 多层结构的局部编码器与单层结构相同,将局部隐层状态 ${\boldsymbol{h}}_t^i$ ${\boldsymbol{c}}_t^i$
1
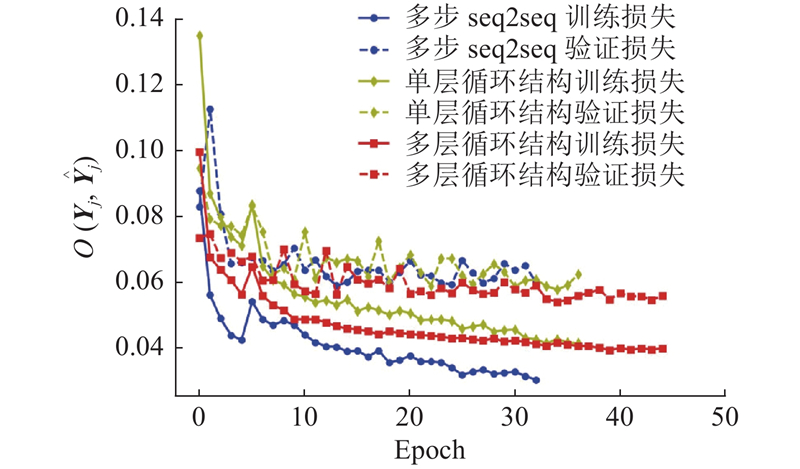
... 以上2种结构采用余弦退火和热重启[27 ] 以及Adam[28 ] 优化器进行训练. 同时为了强制约束预测和加快收敛速度,训练过程使用Teacher forcing策略. 训练的学习率从0.001开始. Teacher forcing策略的参数设置为0.1. 所提出的2种结构均是光滑且可微的,因此可以通过以均方误差为目标函数的标准反向传播来学习参数: ...
1
... 以上2种结构采用余弦退火和热重启[27 ] 以及Adam[28 ] 优化器进行训练. 同时为了强制约束预测和加快收敛速度,训练过程使用Teacher forcing策略. 训练的学习率从0.001开始. Teacher forcing策略的参数设置为0.1. 所提出的2种结构均是光滑且可微的,因此可以通过以均方误差为目标函数的标准反向传播来学习参数: ...
Sharing bus lanes: a new lanes multiplexing-based method using a dynamic time slice policy
1
2018
... (1)所提出的高维时间序列方法虽然提升了整体序列的复杂度,但是避免了预测步长相对较长的影响. 利用同一个循环结构可以对不同的轨迹序列进行预测并得到较好的结果,提升了预测模型的适用能力. 该方法正被进一步应用到公交优先控制的研究[29 ] 中. ...
1
... (2)预测的准确度受到轨迹复杂程度的影响,轨迹所处的环境越复杂,预测准确度越低. 另外,简单提升网络规模不能够显著增加预测准确度. 受到Seq2Seq翻译的启发,预测框架应引入注意力机制[18 , 30 ] ;还可以引入对抗神经网络[17 ] ,使得预测准确度进一步提升. ...
Interactive trajectory prediction of surrounding road users for autonomous driving using structural-LSTM network
1
2019
... (3)在预测时以单个公交车辆轨迹为目标,忽略其与前后公交车辆的关联关系,下一步研究应结合目标轨迹周边车辆轨迹进行预测[31 -32 ] . ...
Modeling vehicle interactions via modified LSTM models for trajectory prediction
1
2019
... (3)在预测时以单个公交车辆轨迹为目标,忽略其与前后公交车辆的关联关系,下一步研究应结合目标轨迹周边车辆轨迹进行预测[31 -32 ] . ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}