|
|
|
| Scalable traffic image auto-annotation method based on contrastive learning |
Yue HOU( ),Qianhui LI,Peng YUAN,Xin ZHANG,Tiantian WANG,Ziwei HAO ),Qianhui LI,Peng YUAN,Xin ZHANG,Tiantian WANG,Ziwei HAO |
| School of Electronics and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China |
|
|
|
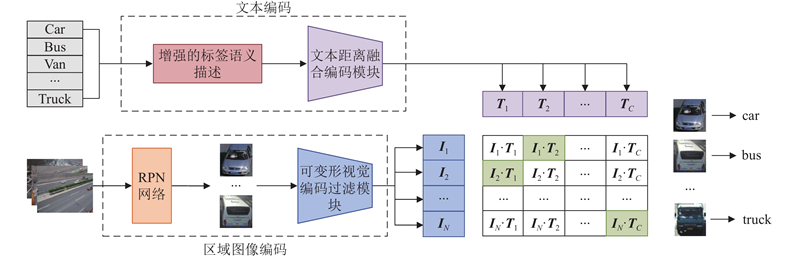
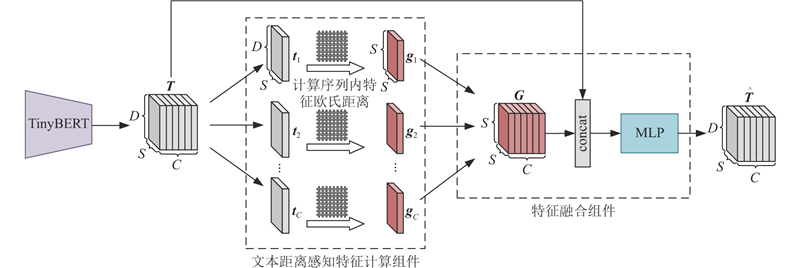
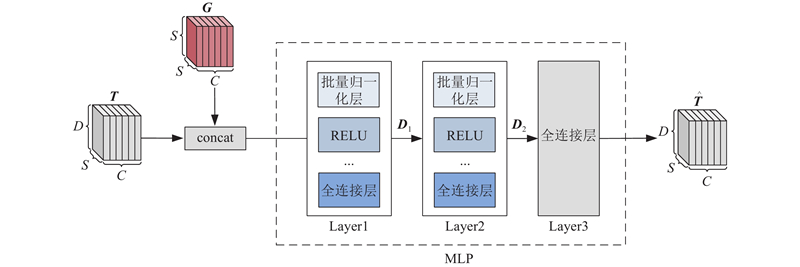
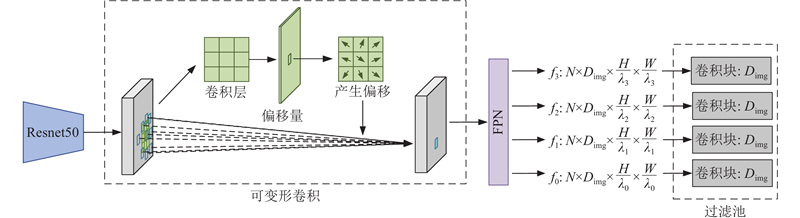
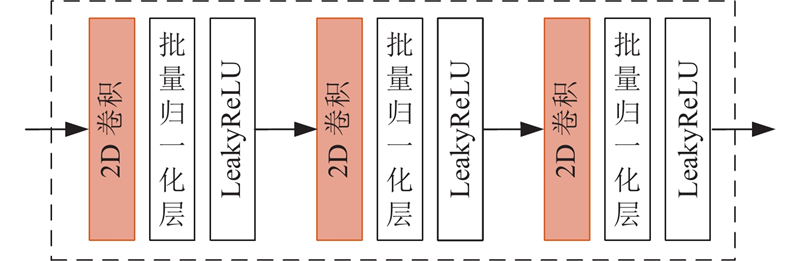
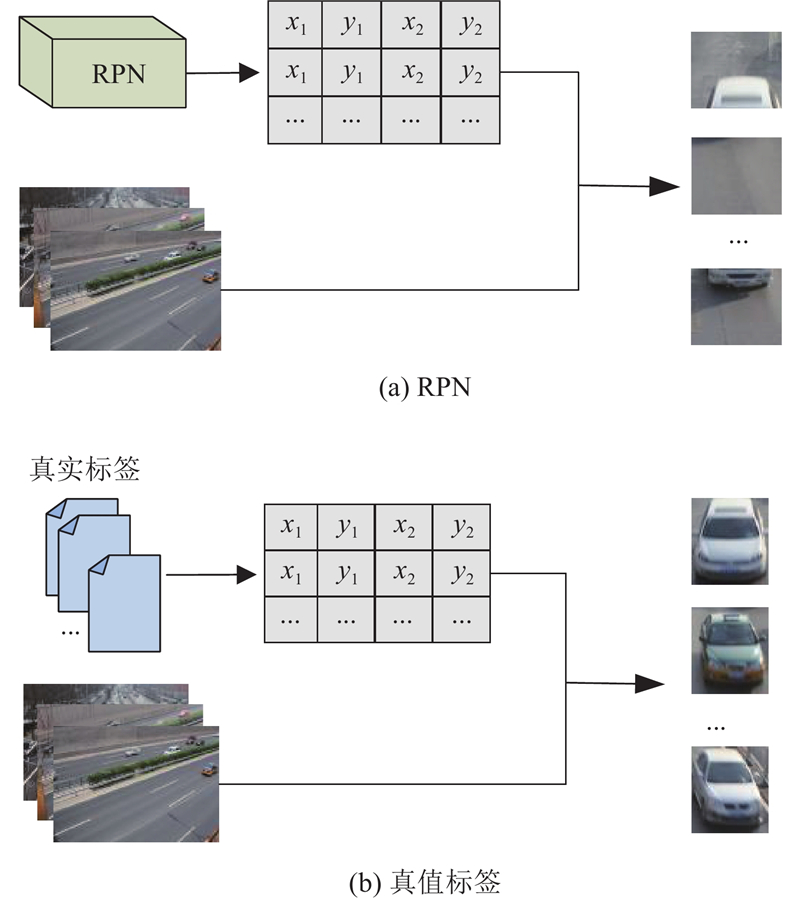
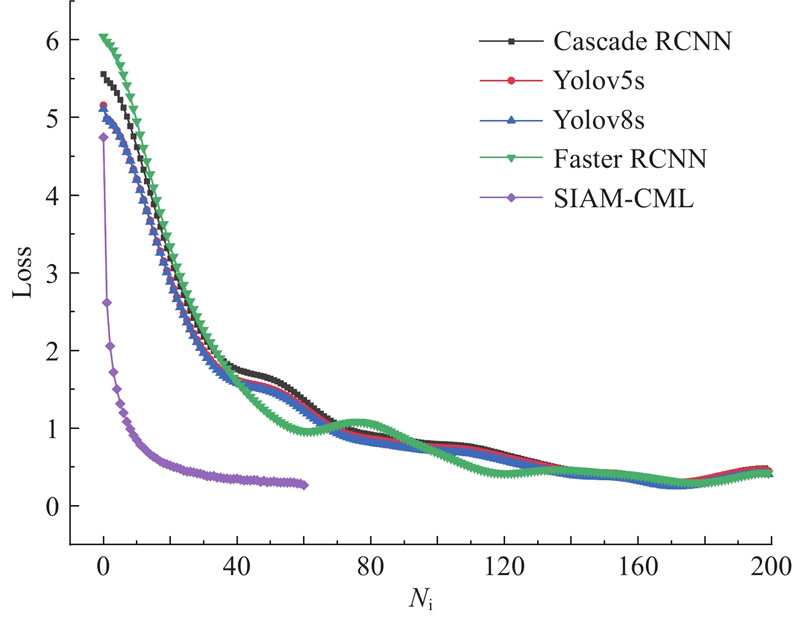
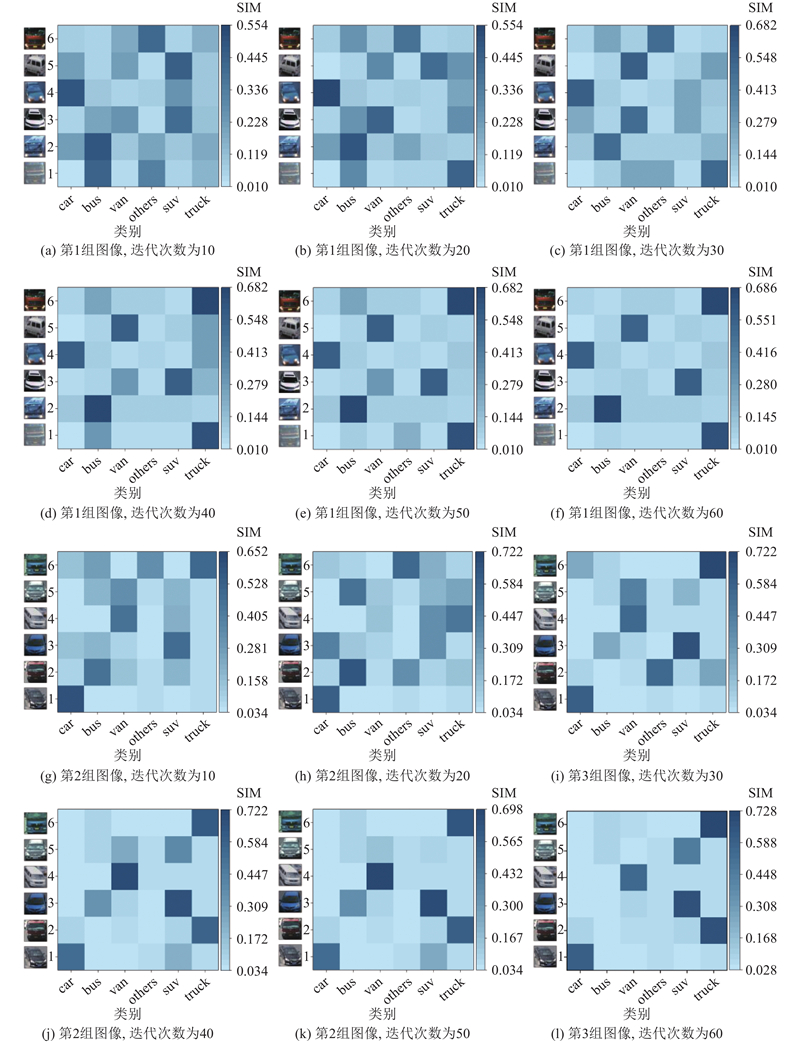
Abstract An expandable automatic annotation method for traffic images based on cross-modal contrastive learning was proposed aiming at the problems of non-scalable annotation categories and low accuracy in existing automatic annotation methods for traffic images. Dual-modal data comprising text and images were adopted as the research subjects, and the similarity relationships between modalities were captured through contrastive learning. An inter-modal feature enhancement strategy was employed to optimize the effective alignment of cross-modal data. A text-distance fusion encoding module was proposed in the text feature extraction stage, which enhanced the local feature representation capability of text sequences by constructing a distance-aware feature fusion component. A deformable filtering convolution structure was designed for image feature extraction, which effectively enhanced the recognition of irregular objects while filtering out noise information. The original loss structure was improved by establishing a combined contrastive loss function to enhance the discriminative ability between positive and negative cross-modal samples. The experimental results demonstrate that the proposed model achieves an improvement of 5.3% and 4.8% in mAP0.5 and mAP0.5:0.95 respectively on the BIT vehicle dataset compared with other models of similar scale, exhibiting superior performance in the automatic annotation of traffic images.
|
|
Received: 19 August 2024
Published: 28 July 2025
|
|
|
| Fund: 国家自然科学基金资助项目(62063014, 62363020);甘肃省自然科学基金资助项目(22JR5RA365). |
基于对比学习的可扩展交通图像自动标注方法
针对现有交通图像自动标注方法标注类别不可扩展、精度低的问题,提出基于模态间对比学习的可扩展交通图像自动标注方法. 该方法以文本和图像双模态数据为研究对象,通过对比学习捕获模态间特征的相似关系,采用模态间特征增强策略优化跨模态数据的有效对齐. 在文本特征提取阶段,提出文本距离融合编码模块,通过构建距离感知特征融合组件,增强文本序列的局部特征表达能力. 在图像特征提取阶段,设计可变形过滤卷积结构,在增强不规则目标识别能力的同时,有效过滤噪声信息. 建立组合对比损失函数,改进原有的损失结构,提升模态间正、负样本的区分度. 实验结果表明,相较于同类规模的其他模型,所提模型在BIT车辆数据集上的mAP0.5和mAP0.5:0.95分别提升了5.3%、4.8%,在交通图像自动标注方面,表现更优.
关键词:
图像标注,
对比学习,
双模态,
类别可扩展,
交通视频图像
|
|
| [1] |
马艳春, 刘永坚, 解庆, 等 自动图像标注技术综述[J]. 计算机研究与发展, 2020, 57 (11): 2348- 2374
MA Yanchun, LIU Yongjian, XIE Qing, et al Review of automatic image annotation technology[J]. Journal of Computer Research and Development, 2020, 57 (11): 2348- 2374
|
|
|
| [2] |
史先进, 曹爽, 张重生, 等 基于锚点的字符级甲骨图像自动标注算法研究[J]. 电子学报, 2021, 49 (10): 2020- 2031
SHI Xianjin, CAO Shuang, ZHANG Chongsheng, et al Research on automatic annotation algorithm for character-level oracle-bone images based on anchor points[J]. Acta Electronica Sinica, 2021, 49 (10): 2020- 2031
|
|
|
| [3] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587.
|
|
|
| [4] |
GIRSHICK R. Fast r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448.
|
|
|
| [5] |
REN S, HE K, GIRSHICK R, et al Faster r-cnn: towards real-time object detection with region proposal networks[J]. Transactions on Pattern Analysis and Machine Intelligence, 2016, 39 (6): 1137- 1149
|
|
|
| [6] |
HE K, GKIOXARI G, DOLLÁR P, et al. Mask r-cnn [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2961-2969.
|
|
|
| [7] |
CAI Z, VASCONCELOS N. Cascade r-cnn: delving into high quality object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6154-6162.
|
|
|
| [8] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2016: 779-788.
|
|
|
| [9] |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7263-7271.
|
|
|
| [10] |
REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. (2018-04-08) [2024-08-15]. https://arxiv.org/abs/1804.02767.
|
|
|
| [11] |
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 7464-7475.
|
|
|
| [12] |
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37.
|
|
|
| [13] |
谢禹, 李玉俊, 董文生 基于SSD神经网络的图像自动标注及应用研究[J]. 信息技术与标准化, 2020, (4): 38- 42
XIE Yu, LI Yujun, DONG Wensheng Automatic image annotation and applied research based on SSD deep neural network[J]. Information Technology and Standardization, 2020, (4): 38- 42
|
|
|
| [14] |
乔人杰, 蔡成涛 对鱼眼图像的FastSAM多点标注算法[J]. 哈尔滨工程大学学报, 2024, 45 (8): 1427- 1433
QIAO Renjie, CAI Chengtao Research on FastSAM multi-point annotation algorithm for fisheye images[J]. Journal of Harbin Engineering University, 2024, 45 (8): 1427- 1433
|
|
|
| [15] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning. Vienna: PMLR, 2021: 8748-8763.
|
|
|
| [16] |
ZHONG Y, YANG J, ZHANG P, et al. Regionclip: region-based language-image pretraining [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 16793-16803.
|
|
|
| [17] |
YANG J, LI C, ZHANG P, et al. Unified contrastive learning in image-text-label space [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 19163-19173.
|
|
|
| [18] |
JIAO X, YIN Y, SHANG L, et al. Tinybert: distilling bert for natural language understanding [EB/OL]. (2020-10-16) [2024-08-15]. https://arxiv.org/abs/1909.10351.
|
|
|
| [19] |
DONG Z, WU Y, PEI M, et al Vehicle type classification using a semisupervised convolutional neural network[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16 (4): 2247- 2256
doi: 10.1109/TITS.2015.2402438
|
|
|
| [20] |
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection [EB/OL]. (2020-04-23)[2024-08-15]. https://arxiv.org/abs/1909.10351.
|
|
|
| [21] |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]//European Conference on Computer Vision. Cham: Springer, 2020: 213-229.
|
|
|
| [22] |
ULTRALYTICS. YOLOv5 [EB/OL]. (2021-04-15)[2024-08-15]. https://github.com/ultralytics/yolov5.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|