|
|
|
| Gradient sparsification compression approach to reducing communication in distributed training |
Shi-da CHEN1,2( ),Qiang LIU1,2,*(),Liang HAN3 ),Qiang LIU1,2,*(),Liang HAN3 |
1. School of Microelectronics, Tianjin University, Tianjin 300072, China
2. Tianjin Key Laboratory of Imaging and Sensing Microelectronic Technology, Tianjin 300072, China
3. Alibaba Group, Sunnyvale 94085, USA |
|
|
|
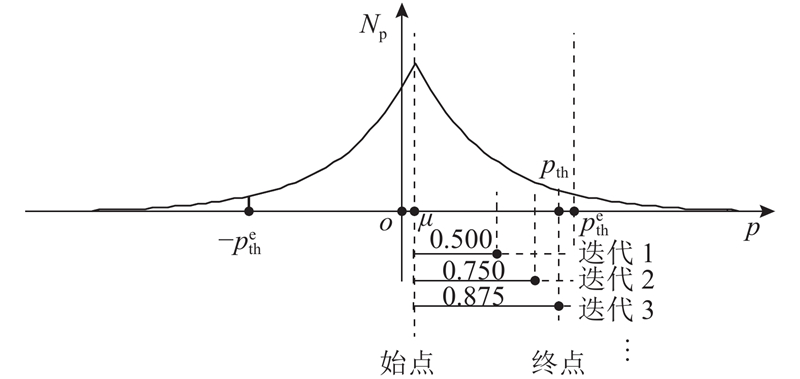
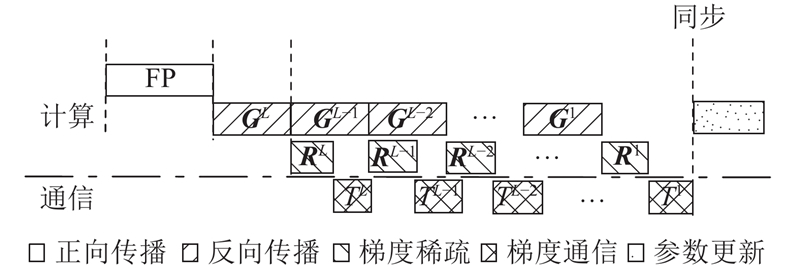
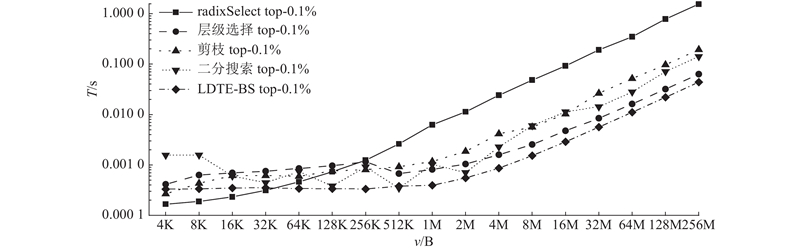
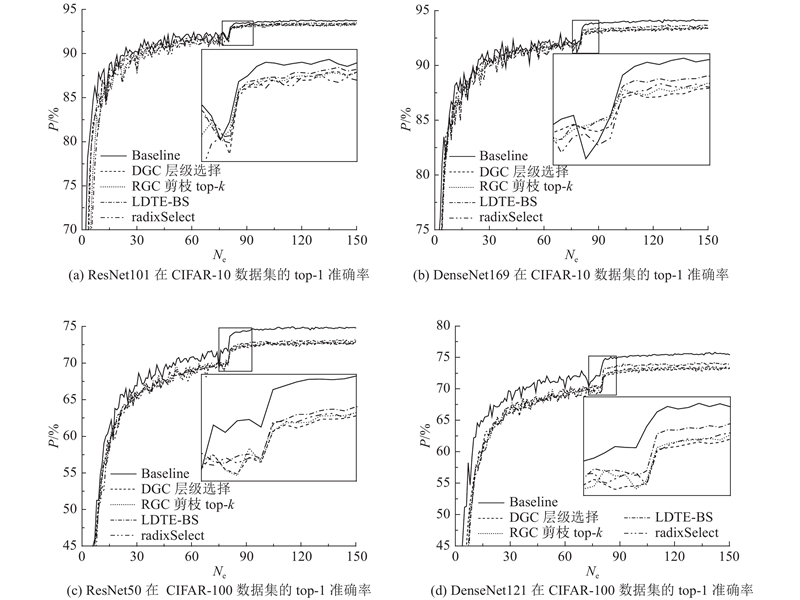
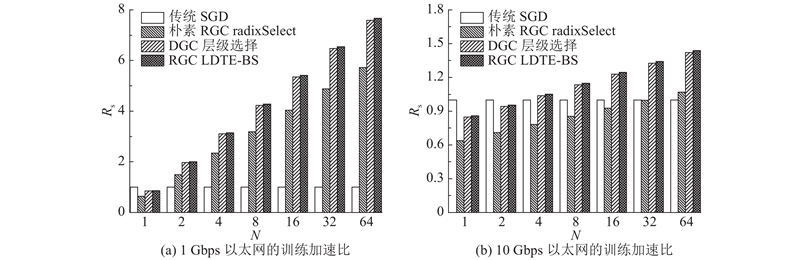
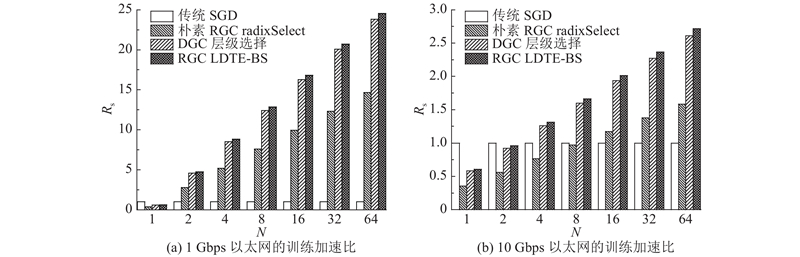
Abstract The existing gradient sparsification compression technology still has the problem of large time consumption in practical applications. To solve this problem, a low-complex and high-speed approach based on the residual gradient compression algorithm in distributed training was proposed, to select the communication-set of the top-k sparse gradient. Firstly, the Wasserstein distance was used to determine that the characteristics of the gradient distribution conformed to the Laplacian distribution. Secondly, the key points were determined by the area relationship of the Laplacian distribution curve, and the feature parameters were simplified by maximum likelihood estimation. Finally, the sparse gradient top-k threshold was estimated and corrected by the binary search algorithm. The proposed approach avoided the instability of random sampling methods and some complex operations like data sorting. The CIFAR-10 and CIFAR-100 datasets were used to train the deep neural network for image classification on GPU platform in order to evaluate the effectiveness of the proposed approach. Results show that this approach accelerated the training process up to 1.62 and 1.3 times, compared with the radixSelect and the hierarchical selection methods under the same training accuracy.
|
|
Received: 06 July 2020
Published: 09 March 2021
|
|
|
| Fund: 国家自然科学基金资助项目(61974102);阿里巴巴创新研究项目 |
|
Corresponding Authors:
Qiang LIU
E-mail: shida_chen@tju.edu.cn;qiangliu@tju.edu.cn
|
降低分布式训练通信的梯度稀疏压缩方法
针对现有的梯度稀疏压缩技术在实际应用中面临时间开销大的问题,基于分布式训练中残差梯度压缩算法提出低复杂度、能快速选取top-k稀疏梯度通信集的方法. 采用Wasserstein距离确定梯度分布特征符合Laplacian分布;利用Laplacian分布曲线面积关系确定关键点,并通过最大似然估计简化特征参数;估计稀疏梯度top-k阈值,并结合二分搜索对阈值修正. 该方法避免了现有随机抽样方法的不稳定性和数据排序之类的复杂操作. 为了评估所提方法的有效性,在图形处理器(GPU)平台采用CIFAR-10和CIFAR-100数据集对图像分类深度神经网络进行训练. 结果显示,与radixSelect和层级选择方法相比,在达到相同训练精度的情况下,本研究方法最高分别实现了1.62、1.30倍的加速.
关键词:
深度神经网络,
分布式训练,
残差梯度压缩,
top-k阈值,
分布估计,
二分搜索
|
|
| [1] |
TANENBAUM A S, VAN STEEN M. Distributed systems: principles and paradigms [M]. New York: Prentice-Hall, 2007: 17-24.
|
|
|
| [2] |
DEAN J, CORRADO G, MONGA R, et al. Large scale distributed deep networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems: Volume 1. Lake Tahoe: Curran Associates, 2012: 1223-1231.
|
|
|
| [3] |
XU H, HO C Y, ABDELMONIEM A M, et al. Compressed communication for distributed deep learning: survey and quantitative evaluation [EB/OL]. [2020-4-13]. https: //repository. kaust. edu. sa/handle/10754/662495.
|
|
|
| [4] |
FANG J, FU H, YANG G, et al RedSync: reducing synchronization bandwidth for distributed deep learning training system[J]. Journal of Parallel and Distributed Computing, 2019, 133: 30- 39
doi: 10.1016/j.jpdc.2019.05.016
|
|
|
| [5] |
CHEN C Y, CHOI J, BRAND D, et al. Adacomp: adaptive residual gradient compression for data-parallel distributed training [C]// 32nd AAAI Conference on Artificial Intelligence. New Orleans: AAAI press, 2018: 2827-2835.
|
|
|
| [6] |
AJI A F, HEAFIELD K. Sparse communication for distributed gradient descent [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics (ACL), 2017: 440–445.
|
|
|
| [7] |
LIN Y, HAN S, MAO H, et al. Deep gradient compression: reducing the communication bandwidth for distributed training [EB/OL]. [2017-12-5]. https: //arxiv. org/abs/1712.01887.
|
|
|
| [8] |
SUN H, SHAO Y, JIANG J, et al. Sparse gradient compression for distributed SGD [C]// International Conference on Database Systems for Advanced Applications. Chiang Mai: Springer, 2019: 139-155.
|
|
|
| [9] |
SATTLER F, WIEDEMANN S, MüLLER K R, et al. Sparse binary compression: towards distributed deep learning with minimal communication [C]// 2019 International Joint Conference on Neural Networks (IJCNN). Budapest: IEEE, 2019: 1-8.
|
|
|
| [10] |
STICH S U, CORDONNIER J B, JAGGI M. Sparsified SGD with memory [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal: Curran Associates, 2018: 4452-4463.
|
|
|
| [11] |
ALISTARH D, HOEFLER T, JOHANSSON M, et al. The convergence of sparsified gradient methods [C]// Proceedings of the Thirty-second International Conference on Neural Information Processing Systems. Montreal: Curran Associates, 2018: 5977-5987.
|
|
|
| [12] |
DUTTA A, BERGOU E H, ABDELMONIEM A M, et al. On the discrepancy between the theoretical analysis and practical implementations of compressed communication for distributed deep learning [EB/OL]. [2019-11-19]. https: //arxiv. org/abs/1911.08250.
|
|
|
| [13] |
STROM N. Scalable distributed DNN training using commodity GPU cloud computing [C]// 16th Annual Conference of the International Speech Communication Association. Dresden: International Speech Communication Association, 2015: 1488-1492.
|
|
|
| [14] |
ALABI T, BLANCHARD J D, GORDON B, et al Fast k-selection algorithms for graphics processing units[J]. Journal of Experimental Algorithmics, 2012, 17 (4): 1- 29
|
|
|
| [15] |
WEN W, XU C, YAN F, et al. Terngrad: ternary gradients to reduce communication in distributed deep learning [C]// Proceedings of the Thirty-first International Conference on Neural Information Processing Systems. Long Beach: Curran Associates, 2017: 1508-1518.
|
|
|
| [16] |
BERNSTEIN J, WANG Y X, AZIZZADENESHELI K, et al. signSGD: compressed optimisation for non-convex problems [C]// Proceedings of the International Conference on Machine Learning, Stockholm: International Machine Learning Society , 2018: 894-918.
|
|
|
| [17] |
HE L, ZHENG S, CHEN W, et al OptQuant: distributed training of neural networks with optimized quantization mechanisms[J]. Neurocomputing, 2019, 340: 233- 244
doi: 10.1016/j.neucom.2019.02.049
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|