| Computer Technology and Image Processing |
|


|
|
|
| Object detection enhanced context model |
Chen-bin ZHENG1( ),Yong ZHANG1,*(),Hang HU2,Ying-rui WU1,Guang-jing HUANG3 ),Yong ZHANG1,*(),Hang HU2,Ying-rui WU1,Guang-jing HUANG3 |
1. School of Instrumetation and Optoelectronic Engineering, Beihang University, Beijing 100191, China
2. Unit 66133 of PLA, Beijing 100144, China
3. School of Aeronautic Science and Engineering, Beihang University, Beijing 100191, China |
|
|
|
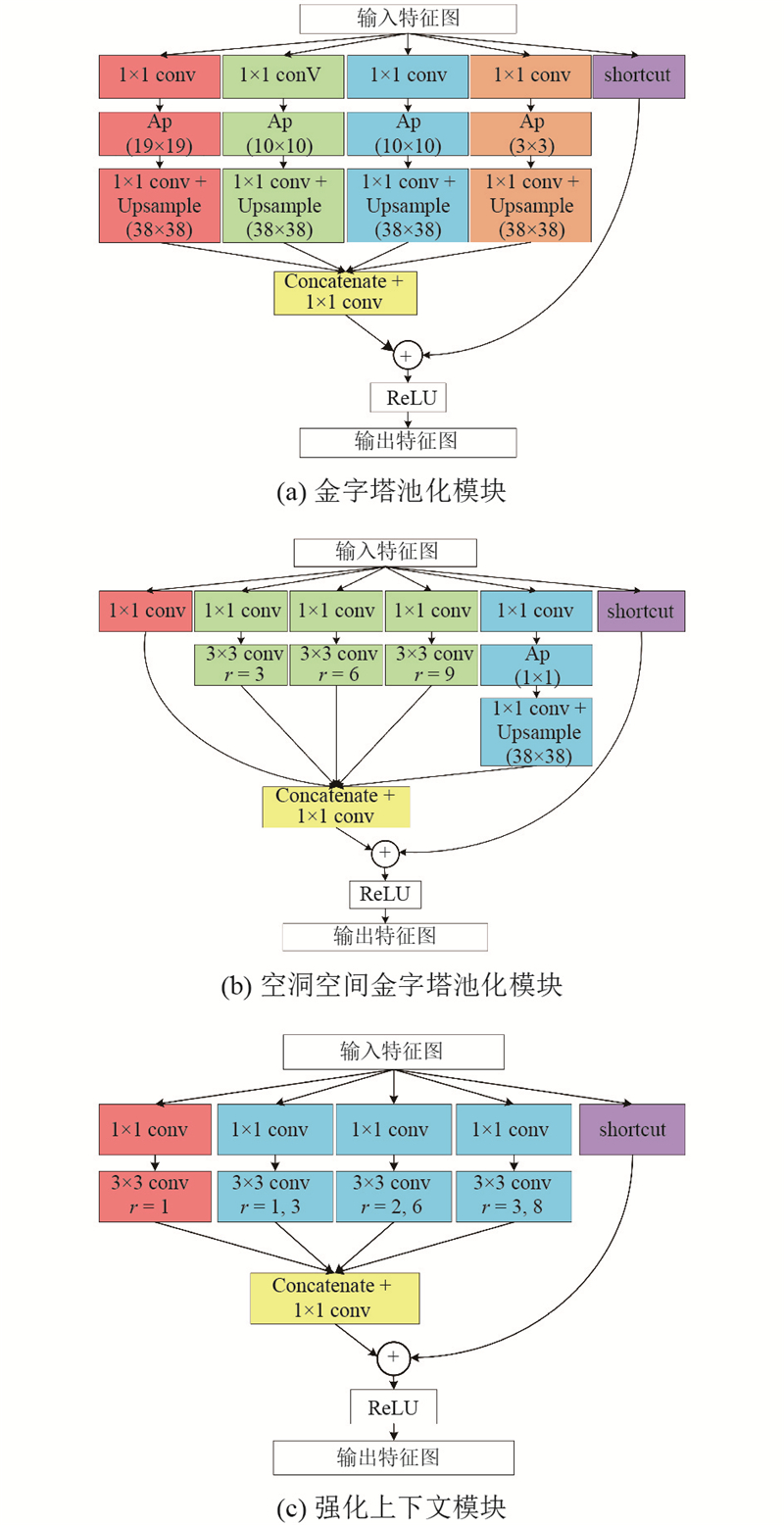
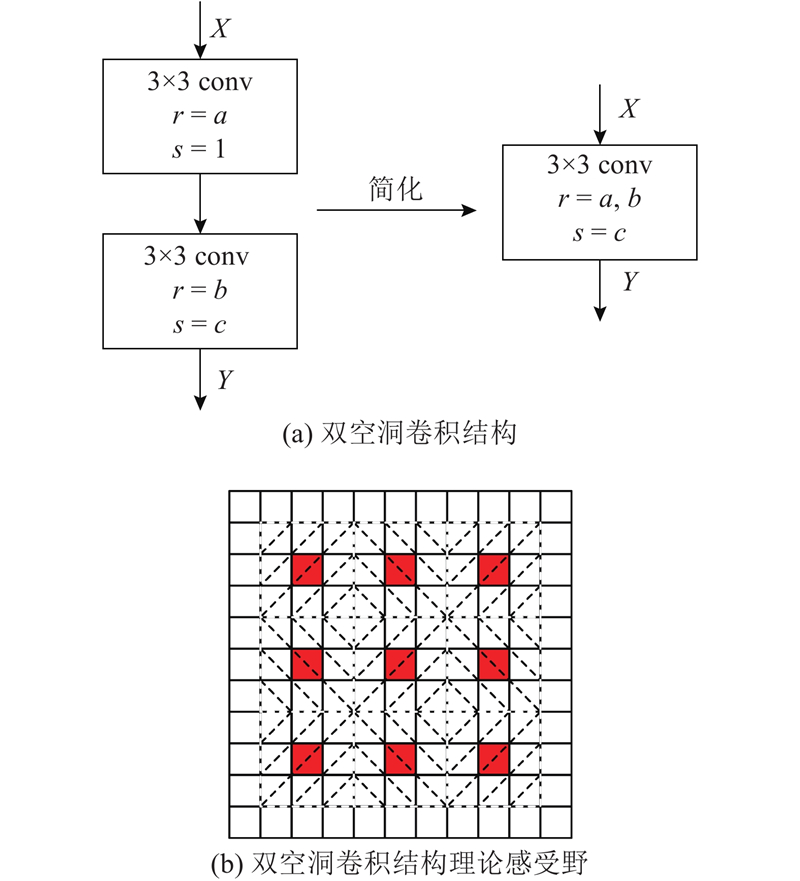
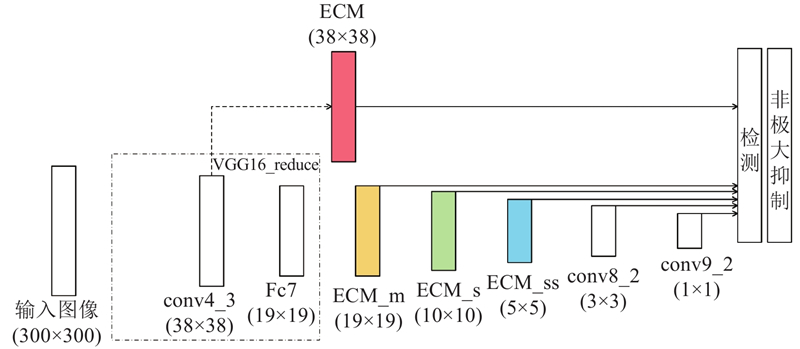
Abstract Double-atrous convolution structure was used in enhanced context module (ECM) of the enhanced context model to reduce parameters while expanding effective receptive field to enhance context information of shallow layers, and ECM flexibly acted on middle shallow prediction layers with less damage to original SSD, forming enhanced context model net (ECMNet). Using input image with size of 300×300, ECMNet obtained mean average precision of 80.52% on PASCAL VOC2007 test set, and achieved 73.5 frames per second on 1080Ti. The experimental results show that ECMNet can effectively enhance context information and achieves a better trade-off in parameter, speed and accuracy, which is superior to many state-of-the-art object detectors.
|
|
Received: 01 March 2019
Published: 05 March 2020
|
|
|
|
Corresponding Authors:
Yong ZHANG
E-mail: 13171087@buaa.edu.cn;06952@buaa.edu.cn
|
目标检测强化上下文模型
强化上下文模型中的强化上下文模块(ECM)利用双空洞卷积结构,在节省参数量的同时,通过扩大有效感受野来强化浅层上下文信息,并在较少破坏原始SSD网络的基础上灵活作用于网络中浅预测层,形成强化上下文模型网络(ECMNet). 当输入图像大小为300×300时,在PASCAL VOC2007测试集上,ECMNet获得的均值平均精度为80.52%,在1080Ti上的速度为73.5 帧/s. 实验结果表明,ECMNet能有效强化上下文信息,并在参数量、速度和精度上达到较优权衡,优于许多先进的目标检测器.
关键词:
目标检测,
上下文信息,
有效感受野,
强化上下文模块(ECM),
一阶段目标检测器
|
|
| [1] |
LIU S T, HUANG D, WANG Y H. Receptive field block net for accurate and fast object detection [C] // European Conference on Computer Vision. Munich: Springer, 2018: 404-418.
|
|
|
| [2] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C] // European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37.
|
|
|
| [3] |
LUO W J, LI Y J, URTASUN R, et al. Understanding the effective receptive field in deep convolutional neural networks [C] // Neural Information Processing Systems. Barcelona: [s. n.], 2016: 4898-4906.
|
|
|
| [4] |
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C] // Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 936-944.
|
|
|
| [5] |
JEONG J, PARK H, KWAK N. Enhancement of SSD by concatenating feature maps for object detection [EB/OL]. (2017-05-26)[2019-02-26]. https://arxiv.xilesou.top/abs/1705.09587.
|
|
|
| [6] |
LI Z X, ZHOU F Q. FSSD: feature fusion single shot multibox detector [EB/OL]. (2018-05-17)[2019-02-26]. https://arxiv.org/abs/1712.00960.
|
|
|
| [7] |
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39 (4): 640- 651
|
|
|
| [8] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R Segnet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (12): 2481- 2495
doi: 10.1109/TPAMI.2016.2644615
|
|
|
| [9] |
ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network [C] // Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6230-6239.
|
|
|
| [10] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (4): 834- 848
|
|
|
| [11] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-12-25)[2019-02-26]. https://arxiv.org/abs/1706.05587.
|
|
|
| [12] |
FU C, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector [EB/OL]. (2017-01-23)[2019-02-26]. https://arxiv.org/abs/1701.06659.
|
|
|
| [13] |
WANDELL B A, WINAWER J Computational neuroimaging and population receptive fields[J]. Trends in Cognitive Sciences, 2015, 19 (6): 349- 357
doi: 10.1016/j.tics.2015.03.009
|
|
|
| [14] |
REDMON J, FARHADI A. Farhadi. YOLO9000: better, faster, stronger [C] // Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 7263-7271.
|
|
|
| [15] |
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-04-08)[2019-02-26]. https://arxiv.org/abs/1804.02767.
|
|
|
| [16] |
HE K M, ZHANG X Y, REN S Q, et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification [C] // International Conference on Computer Vision. Santiago: IEEE, 2015: 1026-1034.
|
|
|
| [17] |
EVERINGHAM M, GOOL L V, WILLIAMS C K I, et al The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88 (2): 303- 338
doi: 10.1007/s11263-009-0275-4
|
|
|
| [18] |
HUANG J, RATHOD V, SUN C, M, et al. Speed/accuracy trade-offs for modern convolutional object detectors [C] // Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 3296-3297.
|
|
|
| [19] |
REN S Q, HE K M, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149
doi: 10.1109/TPAMI.2016.2577031
|
|
|
| [20] |
BELL S, ZITNICK C L, BALA K, et al. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks [C] // Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2874-2883.
|
|
|
| [21] |
DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks [C] // Neural Information Processing Systems. Barcelona: [s. n.], 2016: 379-387.
|
|
|
| [22] |
ZHU Y S, ZHAO C Y, WANG J Q, et al. CoupleNet: coupling global structure with local parts for object detection [C] // International Conference on Computer Vision. Venice: IEEE, 2017: 4146-4154.
|
|
|
| [23] |
SHEN Z Q, LIU Z, LI J G, et al. DSOD: learning deeply supervised object detectors from scratch [C] // International Conference on Computer Vision. Venice: IEEE, 2017: 1937-1945.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|