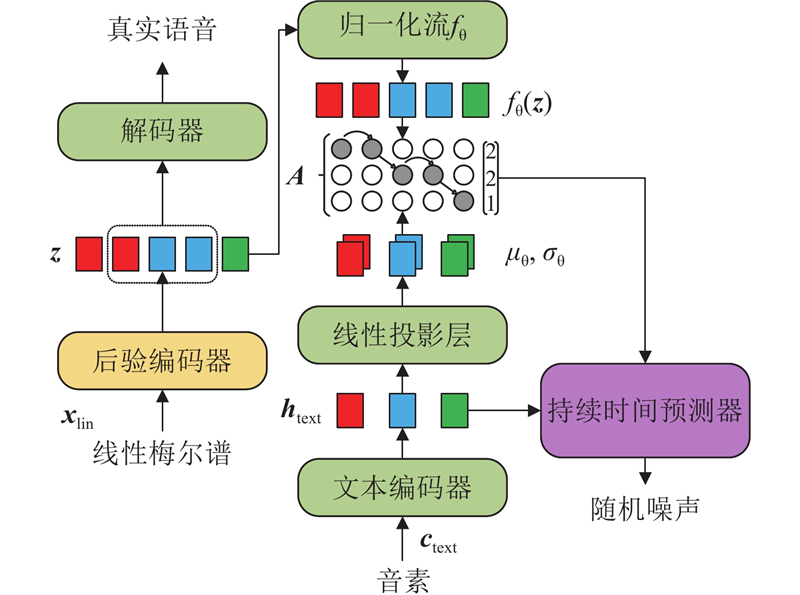
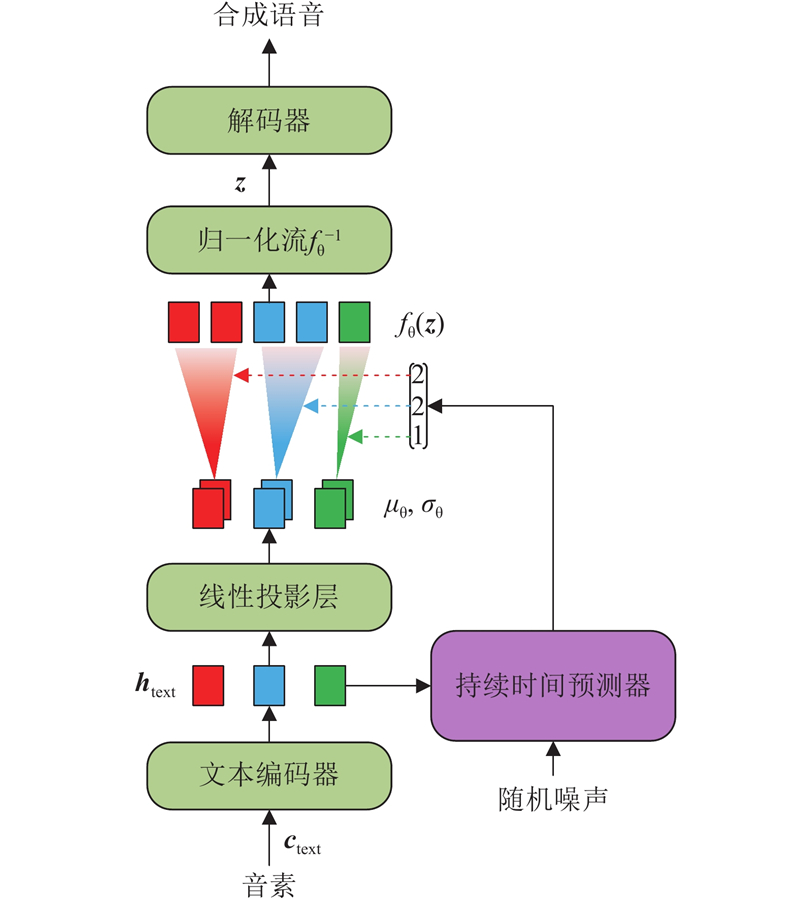
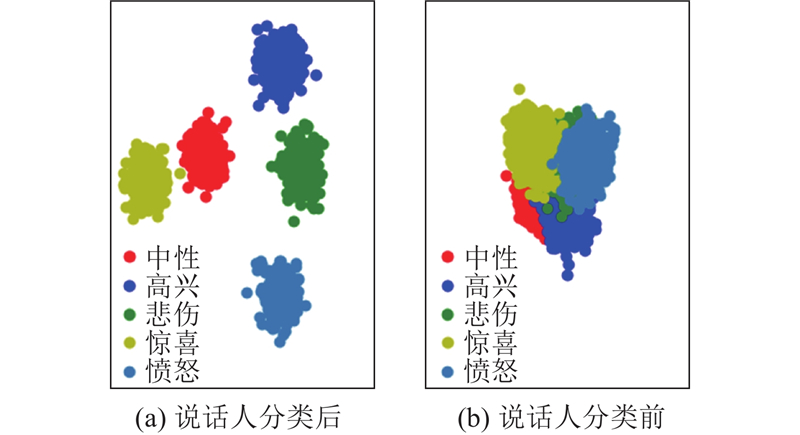
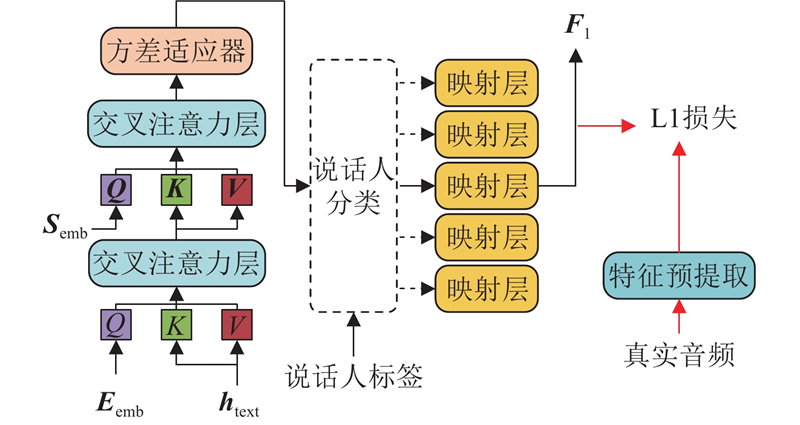
| 计算机技术、控制工程 |
|

|
|
|
| 基于特征映射模型的情感语音合成方法 |
罗杰( ),杨鉴*() ),杨鉴*() |
| 云南大学 信息学院,云南 昆明 650504 |
|
| Emotional speech synthesis approach via feature mapping model |
| Jie LUO(),Jian YANG*() |
| School of Information Science and Engineering, Yunnan University, Kunming 650504, China |
| 1 |
TAN X, QIN T, SOONG F, et al. A survey on neural speech synthesis [EB/OL]. (2021–07–23)[2025–05–31]. https://arxiv.org/pdf/2106.15561.
|
| 2 |
TRIANTAFYLLOPOULOS A, SCHULLER B W. Expressivity and speech synthesis [EB/OL]. (2025–04–10)[2025–05–31]. https://arxiv.org/pdf/2404.19363.
|
| 3 |
TRIANTAFYLLOPOULOS A, SCHULLER B W, İYMEN G, et al An overview of affective speech synthesis and conversion in the deep learning era[J]. Proceedings of the IEEE, 2023, 111 (10): 1355- 1381
doi: 10.1109/JPROC.2023.3250266
|
| 4 |
PARK H J, KIM J S, SHIN W, et al. DEX-TTS: diffusion-based EXpressive text-to-speech with style modeling on time variability [EB/OL]. (2024–06–27)[2025–05–31]. https://arxiv.org/pdf/2406.19135.
|
| 5 |
TANG H, ZHANG X, WANG J, et al. EmoMix: emotion mixing via diffusion models for emotional speech synthesis [C]// Proceedings of the INTERSPEECH 2023. Dublin: International Speech Communication Association, 2023: 12–16.
|
| 6 |
CHEN Z, LI X, AI Z, et al. StyleFusion TTS: multimodal style-control and enhanced feature fusion for zero-shot text-to-speech synthesis [C]// Pattern Recognition and Computer Vision. Singapore: Springer, 2024: 263–277.
|
| 7 |
LEI Y, YANG S, ZHU X, et al Cross-speaker emotion transfer through information perturbation in emotional speech synthesis[J]. IEEE Signal Processing Letters, 2022, 29: 1948- 1952
doi: 10.1109/LSP.2022.3203888
|
| 8 |
LI Y A, HAN C, MESGARANI N StyleTTS: a style-based generative model for natural and diverse text-to-speech synthesis[J]. IEEE Journal of Selected Topics in Signal Processing, 2025, 19 (1): 283- 296
doi: 10.1109/JSTSP.2025.3530171
|
| 9 |
XU Y, CHEN H, YU J, et al. SECap: speech emotion captioning with large language model [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI Press, 2024, 38(17): 19323–19331.
|
| 10 |
HSU W N, BOLTE B, TSAI Y H, et al HuBERT: self-supervised speech representation learning by masked prediction of hidden units[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3451- 3460
doi: 10.1109/TASLP.2021.3122291
|
| 11 |
BOTT T, LUX F, VU N T. Controlling emotion in text-to-speech with natural language prompts [C]// Proceedings of the Interspeech 2024. Kos: International Speech Communication Association, 2024: 1795–1799.
|
| 12 |
INOUE S, ZHOU K, WANG S, et al. Hierarchical emotion prediction and control in text-to-speech synthesis [C]// Proceedings of the ICASSP 2024. Seoul: IEEE, 2024: 10601–10605.
|
| 13 |
INOUE S, ZHOU K, WANG S, et al. Fine-grained quantitative emotion editing for speech generation [C]// Proceedings of the Asia Pacific Signal and Information Processing Association Annual Summit and Conference. Macau: IEEE, 2025: 1–6.
|
| 14 |
GAO X, ZHANG C, CHEN Y, et al. Emo-DPO: controllable emotional speech synthesis through direct preference optimization [C]// Proceedings of the ICASSP 2025. Hyderabad: IEEE, 2025: 1–5.
|
| 15 |
SHI H, WANG J, ZHANG X, et al. RSET: remapping-based sorting method forEmotion transfer speech synthesis [C]// Web and Big Data. Jinhua: Springer, 2024: 90–104.
|
| 16 |
KIM J, KONG J, SON J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech [C]// Proceedings of the 38th International Conference on Machine Learning. [S.l.]: PMLR, 2021: 5530–5540.
|
| 17 |
REZENDE D, MOHAMED S. Variational inference with normalizing flows [C]// Proceedings of the 32nd International Conference on Machine Learning. Lille: PMLR, 2015: 1530–1538.
|
| 18 |
KIM J, KIM S, KONG J, et al. Glow-TTS: a generative flow for text-to-speech via monotonic alignment search [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. [S.l.]: Curran Associates Inc., 2020: 8067–8077.
|
| 19 |
ZHOU K, SISMAN B, LIU R, et al Emotional voice conversion: theory, databases and ESD[J]. Speech Communication, 2022, 137: 1- 18
doi: 10.1016/j.specom.2021.11.006
|
| 20 |
WANG H, GUO P, ZHOU P, et al. MLCA-AVSR: multi-layer cross attention fusion based audio-visual speech recognition [C]// Proceedings of the ICASSP 2024. Seoul: IEEE, 2024: 8150–8154.
|
| 21 |
REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. (2022–08–08)[2025–05–31]. https://arxiv.org/pdf/2006.04558.
|
| 22 |
ZUO S, ZHANG Q, LIANG C, et al. MoEBERT: from BERT to mixture-of-experts via importance-guided adaptation [C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle: Association for Computational Linguistics, 2022: 1610–1623.
|
| 23 |
VARSHAVSKY-HASSID M, HIRSCH R, COHEN R, et al. On the semantic latent space of diffusion-based text-to-speech models [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Bangkok: Association for Computational Linguistics, 2024, 2: 246–255.
|
| 24 |
QI T, ZHENG W, LU C, et al. PAVITS: exploring prosody-aware VITS for end-to-end emotional voice conversion [C]// Proceedings of the ICASSP 2024. Seoul: IEEE, 2024: 12697–12701.
|
| 25 |
ZHAO W, YANG Z An emotion speech synthesis method based on VITS[J]. Applied Sciences, 2023, 13 (4): 2225
doi: 10.3390/app13042225
|
| 26 |
KONG J, PARK J, KIM B, et al. VITS2: improving quality and efficiency of single-stage text-to-speech with adversarial learning and architecture design [C]// Proceedings of the INTERSPEECH 2023. Dublin: International Speech Communication Association, 2023: 4374–4378.
|
| 27 |
BAEVSKI A, ZHOU H, MOHAMED A, et al. wav2vec 2.0: a framework for self-supervised learning of speech representations [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver: [s.n.], 2020: 12449–12460
|
| 28 |
RADFORD A, KIM J W, XU T, et al. Robust speech recognition via large-scale weak supervision [C]// Proceedings of the 40th International Conference on Machine Learning. [S.l.]: PMLR, 2023: 28495–28518.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|