[1]
TAN X, QIN T, SOONG F, et al. A survey on neural speech synthesis [EB/OL]. (2021–07–23)[2025–05–31]. https://arxiv.org/pdf/2106.15561.
[本文引用: 1]
[2]
TRIANTAFYLLOPOULOS A, SCHULLER B W. Expressivity and speech synthesis [EB/OL]. (2025–04–10)[2025–05–31]. https://arxiv.org/pdf/2404.19363.
[本文引用: 1]
[3]
TRIANTAFYLLOPOULOS A, SCHULLER B W, İYMEN G, et al An overview of affective speech synthesis and conversion in the deep learning era
[J]. Proceedings of the IEEE , 2023 , 111 (10 ): 1355 - 1381
DOI:10.1109/JPROC.2023.3250266
[本文引用: 2]
[4]
PARK H J, KIM J S, SHIN W, et al. DEX-TTS: diffusion-based EXpressive text-to-speech with style modeling on time variability [EB/OL]. (2024–06–27)[2025–05–31]. https://arxiv.org/pdf/2406.19135.
[本文引用: 1]
[5]
TANG H, ZHANG X, WANG J, et al. EmoMix: emotion mixing via diffusion models for emotional speech synthesis [C]// Proceedings of the INTERSPEECH 2023 . Dublin: International Speech Communication Association, 2023: 12–16.
[本文引用: 1]
[6]
CHEN Z, LI X, AI Z, et al. StyleFusion TTS: multimodal style-control and enhanced feature fusion for zero-shot text-to-speech synthesis [C]// Pattern Recognition and Computer Vision . Singapore: Springer, 2024: 263–277.
[本文引用: 1]
[7]
LEI Y, YANG S, ZHU X, et al Cross-speaker emotion transfer through information perturbation in emotional speech synthesis
[J]. IEEE Signal Processing Letters , 2022 , 29 : 1948 - 1952
DOI:10.1109/LSP.2022.3203888
[本文引用: 1]
[8]
LI Y A, HAN C, MESGARANI N StyleTTS: a style-based generative model for natural and diverse text-to-speech synthesis
[J]. IEEE Journal of Selected Topics in Signal Processing , 2025 , 19 (1 ): 283 - 296
DOI:10.1109/JSTSP.2025.3530171
[本文引用: 1]
[9]
XU Y, CHEN H, YU J, et al. SECap: speech emotion captioning with large language model [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI Press, 2024, 38(17): 19323–19331.
[本文引用: 1]
[10]
HSU W N, BOLTE B, TSAI Y H, et al HuBERT: self-supervised speech representation learning by masked prediction of hidden units
[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 2021 , 29 : 3451 - 3460
DOI:10.1109/TASLP.2021.3122291
[本文引用: 1]
[11]
BOTT T, LUX F, VU N T. Controlling emotion in text-to-speech with natural language prompts [C]// Proceedings of the Interspeech 2024 . Kos: International Speech Communication Association, 2024: 1795–1799.
[本文引用: 1]
[12]
INOUE S, ZHOU K, WANG S, et al. Hierarchical emotion prediction and control in text-to-speech synthesis [C]// Proceedings of the ICASSP 2024 . Seoul: IEEE, 2024: 10601–10605.
[13]
INOUE S, ZHOU K, WANG S, et al. Fine-grained quantitative emotion editing for speech generation [C]// Proceedings of the Asia Pacific Signal and Information Processing Association Annual Summit and Conference . Macau: IEEE, 2025: 1–6.
[本文引用: 1]
[14]
GAO X, ZHANG C, CHEN Y, et al. Emo-DPO: controllable emotional speech synthesis through direct preference optimization [C]// Proceedings of the ICASSP 2025 . Hyderabad: IEEE, 2025: 1–5.
[本文引用: 1]
[15]
SHI H, WANG J, ZHANG X, et al. RSET: remapping-based sorting method forEmotion transfer speech synthesis [C]// Web and Big Data . Jinhua: Springer, 2024: 90–104.
[本文引用: 1]
[16]
KIM J, KONG J, SON J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech [C]// Proceedings of the 38th International Conference on Machine Learning . [S.l.]: PMLR, 2021: 5530–5540.
[本文引用: 1]
[17]
REZENDE D, MOHAMED S. Variational inference with normalizing flows [C]// Proceedings of the 32nd International Conference on Machine Learning . Lille: PMLR, 2015: 1530–1538.
[本文引用: 1]
[18]
KIM J, KIM S, KONG J, et al. Glow-TTS: a generative flow for text-to-speech via monotonic alignment search [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . [S.l.]: Curran Associates Inc., 2020: 8067–8077.
[本文引用: 1]
[20]
WANG H, GUO P, ZHOU P, et al. MLCA-AVSR: multi-layer cross attention fusion based audio-visual speech recognition [C]// Proceedings of the ICASSP 2024 . Seoul: IEEE, 2024: 8150–8154.
[本文引用: 1]
[21]
REN Y, HU C, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. (2022–08–08)[2025–05–31]. https://arxiv.org/pdf/2006.04558.
[本文引用: 1]
[22]
ZUO S, ZHANG Q, LIANG C, et al. MoEBERT: from BERT to mixture-of-experts via importance-guided adaptation [C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Seattle: Association for Computational Linguistics, 2022: 1610–1623.
[本文引用: 1]
[23]
VARSHAVSKY-HASSID M, HIRSCH R, COHEN R, et al. On the semantic latent space of diffusion-based text-to-speech models [C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics . Bangkok: Association for Computational Linguistics, 2024, 2: 246–255.
[本文引用: 1]
[24]
QI T, ZHENG W, LU C, et al. PAVITS: exploring prosody-aware VITS for end-to-end emotional voice conversion [C]// Proceedings of the ICASSP 2024 . Seoul: IEEE, 2024: 12697–12701.
[本文引用: 1]
[25]
ZHAO W, YANG Z An emotion speech synthesis method based on VITS
[J]. Applied Sciences , 2023 , 13 (4 ): 2225
DOI:10.3390/app13042225
[本文引用: 1]
[26]
KONG J, PARK J, KIM B, et al. VITS2: improving quality and efficiency of single-stage text-to-speech with adversarial learning and architecture design [C]// Proceedings of the INTERSPEECH 2023 . Dublin: International Speech Communication Association, 2023: 4374–4378.
[本文引用: 1]
[27]
BAEVSKI A, ZHOU H, MOHAMED A, et al. wav2vec 2.0: a framework for self-supervised learning of speech representations [C]// Proceedings of the 34th International Conference on Neural Information Processing Systems . Vancouver: [s.n.], 2020: 12449–12460
[本文引用: 1]
[28]
RADFORD A, KIM J W, XU T, et al. Robust speech recognition via large-scale weak supervision [C]// Proceedings of the 40th International Conference on Machine Learning . [S.l.]: PMLR, 2023: 28495–28518.
[本文引用: 1]
[29]
MA Z, ZHENG Z, YE J, et al. emotion2vec: self-supervised pre-training for speech emotion representation [C]// Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024 . Bangkok: Association for Computational Linguistics, 2024: 15747–15760.
[本文引用: 1]
1
... 情感语音合成须实现相同文本下的不同语音变体,即对同一文本生成不同情感特征,以合成表达不同情感的语音[1 ] . 这要求情感语音合成依据情感实现文本到语音的一对多映射,稀缺的情感语音样本使得这种映射关系难以通过广泛的样本学习实现. 使用深度神经网络对文本到语音的映射关系进行有效建模是情感语音合成的挑战,亦是研究热点. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
An overview of affective speech synthesis and conversion in the deep learning era
2
2023
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
... [3 ]也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
Cross-speaker emotion transfer through information perturbation in emotional speech synthesis
1
2022
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
StyleTTS: a style-based generative model for natural and diverse text-to-speech synthesis
1
2025
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
HuBERT: self-supervised speech representation learning by masked prediction of hidden units
1
2021
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
... 在情感语音合成研究早期,研究者从已有的情感音频中获取情感特征[2 ] 来规避对于广泛样本的需求,该类方法被称为基于参考的方法[3 ] . 例如,Park 等[4 ] 提出的DEX-TTS将语音转换为梅尔谱作为参考,并从中提取情感特征来控制语音合成. Tang等[5 ] 提出的EmoMix使用语音情感识别模型的识别特征指导情感音频的生成. 该类方法从音频中获取情感信息,可以详细描述情感在语音中的细致表达. 音频中除了情感信息,还包含其他相互耦合的信息,这使得合成语音易受参考语音的影响. 为此,基于参考的方法要对音频进行信息解耦[6 -7 ] . 针对该问题,Li等[8 ] 提出的StyleTTS直接从参考音频中获取更为丰富的说话人信息,以此来避免解耦处理. Xu等[9 ] 提出的SECap使用HuBERT[10 ] 对参考音频进行情感信息提取,以此实现对语音情感的细致描述. 随着情感语音合成的不断发展,基于标签的方法[3 ] 也得到广泛应用. 与基于参考的方法不同,该方法依据标签或文本提示生成情感特征[11 -13 ] . 如Gao等[14 ] 提出的Emo-DPO根据给定的标签生成包含情感信息的文本编码,并进一步地合成情感语音. 这类方法的情感特征依据文本内容生成,不受参考音频的限制,但生成的情感特征较为粗糙,导致合成的情感语音质量降低. 基于码本的方法在情感语音合成方向上取得了新的成果. 基于码本的方法将音频处理为特征向量并存储为码本,依据标签或参考音频从码本中选择合适的向量作为情感特征. 该方法既保证了情感特征包含充分的细节信息,又避免了由于信息混杂带来的特征解耦问题. 如Shi等[15 ] 提出的RSET对情感音频进行特征提取并排序以获得码本,之后依据参考音频选择合适的码本作为情感特征. 该方法提取的码本均基于已有的情感音频,存在明显的局限性. ...
1
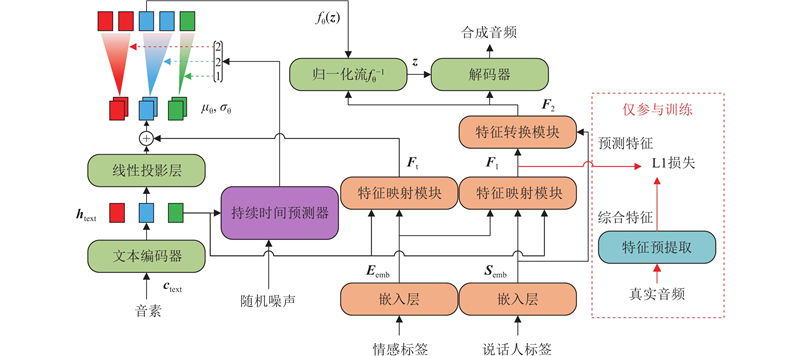
... 本研究针对文本变化导致情感表达粗糙、语音质量下降的问题,提出基于特征映射模型的情感语音合成方法. 一方面,从情感音频中提取合适的综合特征;另一方面,学习不同特征之间的映射关系并应用于情感语音合成. 本研究1)应用机器学习中的主成分分析(principal component analysis, PCA)与线性判别分析(linear discriminant analysis, LDA),从情感音频中提取包含情感与说话人音色信息的综合特征. 2)构建特征映射模块,学习文本、情感、说话人特征到综合特征的映射关系,形成通用映射范式. 3)构建基于U-Net结构的特征转换模块,将具体特征进一步转换为抽象特征以适应具有时序性的文本特征. 4)采用经过改进的VITS[16 ] 实现情感语音合成,在保证合成语音质量的同时充分表达情感. ...
1
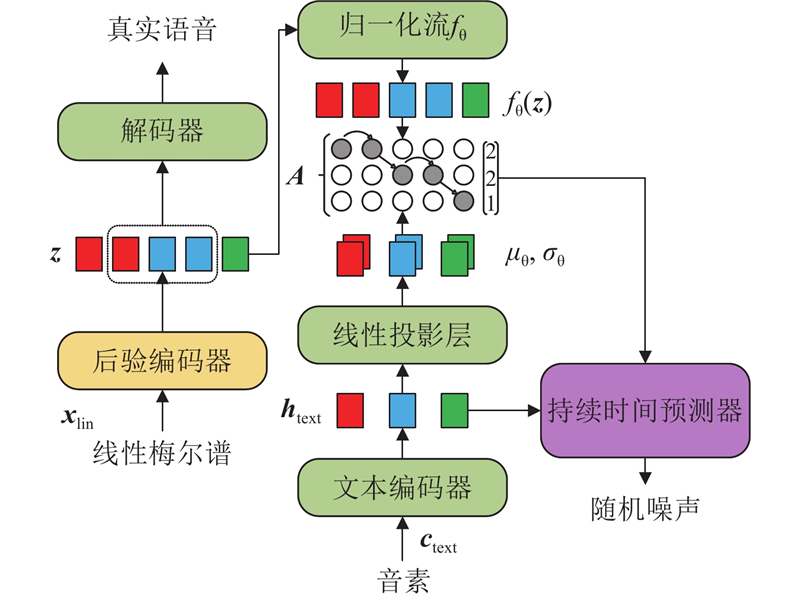
... 采用VITS作为情感语音合成的基线系统. VITS使用基于归一化流[17 ] 的合成方法,该方法期望通过获得数据的最大似然估计来近似实际后验概率分布. 如图1 所示,在VITS的训练过程中,模型将真实音频的梅尔谱通过后验编码器转换为遵循简单正态概率分布的后验特征$ {\boldsymbol{z}} $ $ {\boldsymbol{c}}_{\text{text}} $ $ \boldsymbol{A} $
1
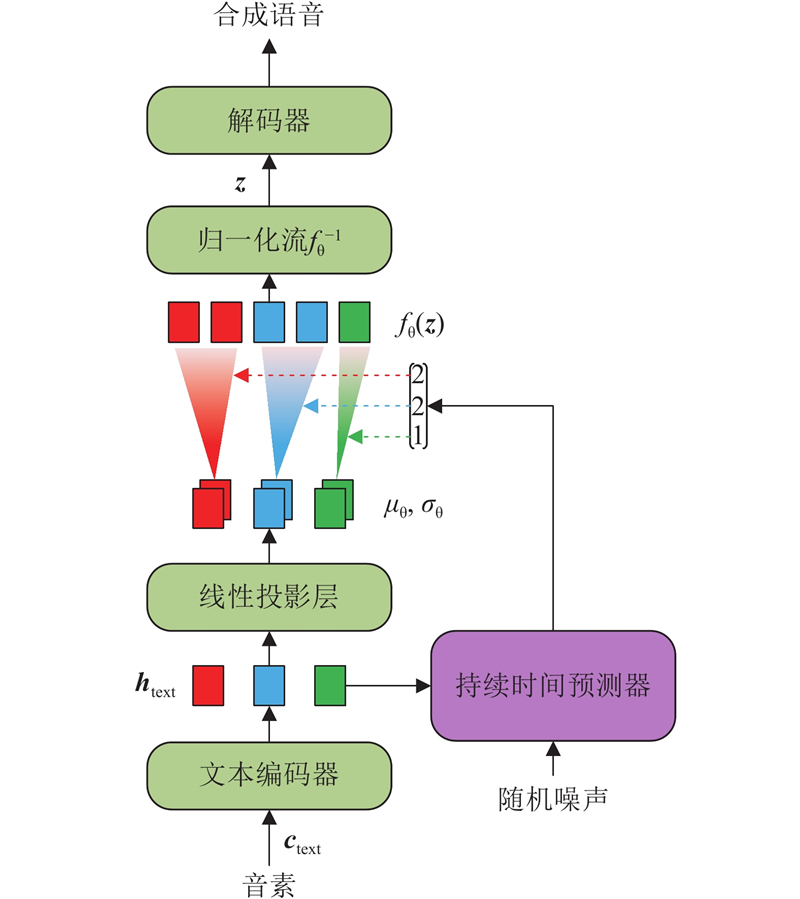
... 在训练过程中,$ \boldsymbol{A} $ $ {f}_{\text{θ}}({\boldsymbol{z}}) $ $ {\mu }_{\text{θ}} $ $ {\sigma }_{\text{θ}} $ [18 ] (monotonic alignment search, MAS)逐步得到,并由此训练持续时间预测器. 在如图2 所示的推理过程中,A $ {\mu }_{\text{θ}} $ $ {\sigma }_{\text{θ}} $
Emotional voice conversion: theory, databases and ESD
1
2022
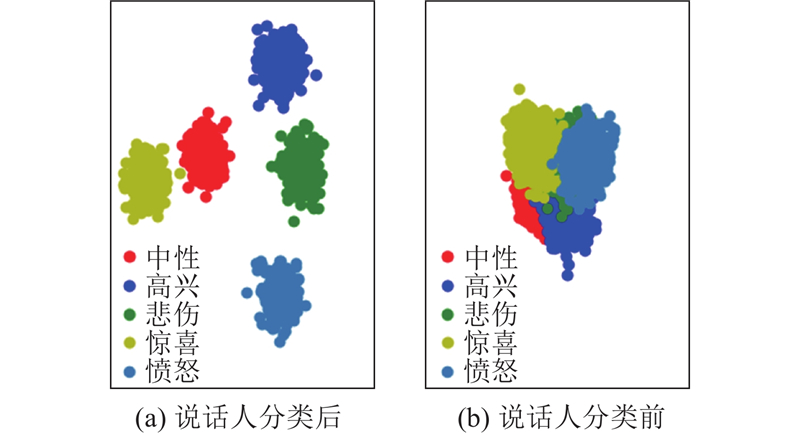
... 使用开源的OpenSmile工具包提取音频特征,获得包括基频、音高、音强、响度、梅尔倒谱系数等多个基本特征,对各项基本特征应用诸如微分、最大值、最小值等函数得到1 750维的附加特征. 由于音频中多种信息相互耦合,经过OpenSmile处理得到的附加特征只描述音频相关属性,包含情感、说话人音色、发音习惯等信息,须进行特征过滤处理. 过大的特征维度会大幅度增加模型参数量,也容易导致在学习不同特征之间的映射关系时损失难以收敛;特征维度过小又使得特征中的信息丢失而失去作用. 为了平衡模型参数量与特征信息量,选择将综合特征维度设定为1 024维. 使用PCA对附加特征进行过滤降维处理,使处理后的细节特征各维分量相互独立以保留最多的信息量. 由于PCA无法彻底过滤冗余信息,参考StyleTTS的处理方法,从音频特征中直接获取情感与说话人音色信息以有效利用其中的冗余信息. 经过PCA处理的细节特征包含情感信息与说话人信息,但PCA不具有分类能力,这使得处理后的特征在特征空间中混杂分布,不利于模型训练. 使用LDA为细节特征补充分类信息以加强不同情感特征的区分度. 为了降低冗余信息的干扰,强化LDA的分类效果,使用经过PCA处理后的1 024维特征作为基础进行LDA分类处理. 仅以情感为类别进行分类时,同一说话人的情感聚类区域相互重叠,分类效果较差. 故在分类时将数据集按照说话人分类为多个子集,之后将每个子集按照情感类别进行LDA分类,以此分离不同情感的聚类区域. ESD数据集[19 ] 中10个英语子集的分类处理可视化结果如图3 所示. 可以看出,经过说话人分类后的LDA特征具有更好的分类能力. LDA从原始特征中抽取具有分类能力的分类特征,但不保留包含信息的细节特征. 使用PCA处理得到包含具体信息的细节特征,使用LDA处理得到具有显著分类能力的分类特征,再将二者组合得到作为学习样本的综合特征. 基于LDA的分类特性,最大分类维度为4维,故PCA的细节特征维度选择为1 020维. 从参考音频中提取综合特征的处理流程如图4 所示. ...
1
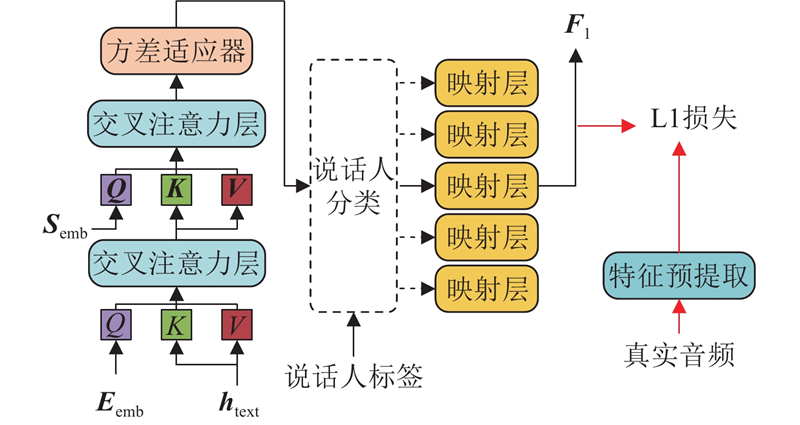
... 在获得合适的综合特征之后,须完成文本、情感以及说话人音色到综合特征的映射关系的学习拟合. 本研究构建如图5 所示的特征映射模块. 在语音当中,文本、情感、说话人音色等特征之间相互关联、相互影响,单一特征的变化会影响其他特征在语音中的表达,故在学习映射关系之前须重构输入特征之间的相互联系. 文本特征具有时序性,情感与说话人音色特征不具有时序性,三者处于不同特征空间. 参考多模态语音识别领域的融合方法[20 ] ,通过交叉注意力机制将3项特征转换到同一特征空间并使其相互关联. 在注意力计算过程中,文本特征$ {{\boldsymbol{h}}}_{\text{text}} $ K V $ {{\boldsymbol{E}}}_{\text{emb}} $ Q $ {{\boldsymbol{S}}}_{\text{emb}} $ [21 ] 的方差适应器结构及大语言模型常用的MoE结构[22 ] ,在保证模块具备足够的学习拟合能力的同时避免模型过于复杂. 在特征映射模块中,方差适应器作为共享模块加入与说话人数量相当的映射层作为专用模块,每个映射层均由4个全连接层组成. 由共享模块对融合特征中与说话人音色无关的共性特征进行初步处理,得到预处理特征. 预处理特征依据说话人标签送入对应的专用模块,并根据与说话人音色相关的差异特征进行映射转换,最终获得预测特征$ {{\boldsymbol{F}}}_{1} $ . 通过这种方式,原本由单一模块对包含多个说话人的映射关系的学习拟合任务被分解为多个子任务,不同的映射层学习拟合单一说话人的映射关系,提高了模块对复杂映射关系的学习拟合能力. 为了尽可能降低$ {{\boldsymbol{F}}}_{1} $ $ {{\boldsymbol{F}}}_{1} $
1
... 在获得合适的综合特征之后,须完成文本、情感以及说话人音色到综合特征的映射关系的学习拟合. 本研究构建如图5 所示的特征映射模块. 在语音当中,文本、情感、说话人音色等特征之间相互关联、相互影响,单一特征的变化会影响其他特征在语音中的表达,故在学习映射关系之前须重构输入特征之间的相互联系. 文本特征具有时序性,情感与说话人音色特征不具有时序性,三者处于不同特征空间. 参考多模态语音识别领域的融合方法[20 ] ,通过交叉注意力机制将3项特征转换到同一特征空间并使其相互关联. 在注意力计算过程中,文本特征$ {{\boldsymbol{h}}}_{\text{text}} $ K V $ {{\boldsymbol{E}}}_{\text{emb}} $ Q $ {{\boldsymbol{S}}}_{\text{emb}} $ [21 ] 的方差适应器结构及大语言模型常用的MoE结构[22 ] ,在保证模块具备足够的学习拟合能力的同时避免模型过于复杂. 在特征映射模块中,方差适应器作为共享模块加入与说话人数量相当的映射层作为专用模块,每个映射层均由4个全连接层组成. 由共享模块对融合特征中与说话人音色无关的共性特征进行初步处理,得到预处理特征. 预处理特征依据说话人标签送入对应的专用模块,并根据与说话人音色相关的差异特征进行映射转换,最终获得预测特征$ {{\boldsymbol{F}}}_{1} $ . 通过这种方式,原本由单一模块对包含多个说话人的映射关系的学习拟合任务被分解为多个子任务,不同的映射层学习拟合单一说话人的映射关系,提高了模块对复杂映射关系的学习拟合能力. 为了尽可能降低$ {{\boldsymbol{F}}}_{1} $ $ {{\boldsymbol{F}}}_{1} $
1
... 在获得合适的综合特征之后,须完成文本、情感以及说话人音色到综合特征的映射关系的学习拟合. 本研究构建如图5 所示的特征映射模块. 在语音当中,文本、情感、说话人音色等特征之间相互关联、相互影响,单一特征的变化会影响其他特征在语音中的表达,故在学习映射关系之前须重构输入特征之间的相互联系. 文本特征具有时序性,情感与说话人音色特征不具有时序性,三者处于不同特征空间. 参考多模态语音识别领域的融合方法[20 ] ,通过交叉注意力机制将3项特征转换到同一特征空间并使其相互关联. 在注意力计算过程中,文本特征$ {{\boldsymbol{h}}}_{\text{text}} $ K V $ {{\boldsymbol{E}}}_{\text{emb}} $ Q $ {{\boldsymbol{S}}}_{\text{emb}} $ [21 ] 的方差适应器结构及大语言模型常用的MoE结构[22 ] ,在保证模块具备足够的学习拟合能力的同时避免模型过于复杂. 在特征映射模块中,方差适应器作为共享模块加入与说话人数量相当的映射层作为专用模块,每个映射层均由4个全连接层组成. 由共享模块对融合特征中与说话人音色无关的共性特征进行初步处理,得到预处理特征. 预处理特征依据说话人标签送入对应的专用模块,并根据与说话人音色相关的差异特征进行映射转换,最终获得预测特征$ {{\boldsymbol{F}}}_{1} $ . 通过这种方式,原本由单一模块对包含多个说话人的映射关系的学习拟合任务被分解为多个子任务,不同的映射层学习拟合单一说话人的映射关系,提高了模块对复杂映射关系的学习拟合能力. 为了尽可能降低$ {{\boldsymbol{F}}}_{1} $ $ {{\boldsymbol{F}}}_{1} $
1
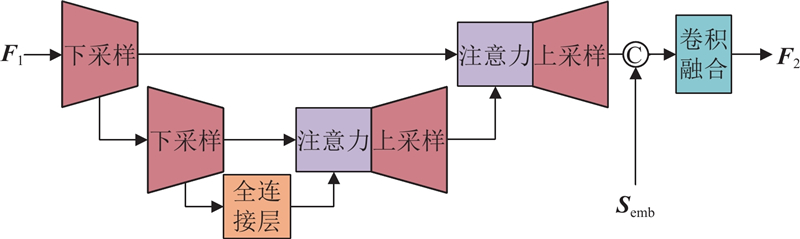
... 特征映射模块依据学习到的映射关系将各项抽象特征转换为具体的、可理解的综合特征,但基线模型本身的文本特征属于具有时序性的抽象特征,与不具有时序性的综合特征不适配. 如果将综合特征直接加入基线模型,抽象特征与具体特征之间会产生冲突并损失信息,导致合成语音质量下降. 参考改进U-Net结构的方法[23 ] ,构建基于U-Net网络结构的特征转换模块作为过渡模块. 通过该模块,具体的综合特征将被转换为适应于基线模型的抽象特征,以此避免特征之间产生冲突. ...
1
... 为了验证基于特征映射模型的情感语音合成方法的有效性以及该方法与其他情感语音合成方法[24 -25 ] 的性能差异,将改进后的模型FM_VITS同基线模型VITS、VITS2[26 ] 以及基于参考语音方法的VITS情感语音合成模型AR_VITS,在语音合成质量、情感表达以及文本泛化能力方面进行比较. VITS与VITS2仅使用情感标签控制合成语音情感;AR_VITS使用预训练的wave2vec2[27 ] 从参考音频中提取情感特征并指导VITS合成情感语音. 开展消融实验,验证不同模块对FM_VITS模型性能的影响. 使用ESD情感语音数据集作为实验数据集以训练和测试各模型. 该数据集分为中文和英文数据子集,每个子集包含10位说话人,每位说话人录制1 750条包括开心、愤怒、惊讶、伤心以及中性情感在内的情感语音. 受限于情感表达需要,ESD数据集的情感语音时长较短,平均每条语音的文本约为6个单词长度. 为了验证模型在多说话人条件下的情感语音合成能力,同时控制模型参数量以及数据集的建模复杂度,使用编号为0012、0013的男性说话人数据子集以及编号为0017、0018、0019的女性说话人数据子集作为训练集与验证集. 单说话人条件下的实验使用0019数据子集. 各模型的训练均使用具有24 GB显存的NVIDIA显卡,进行批大小为52、共计1200 轮次的训练. ...
An emotion speech synthesis method based on VITS
1
2023
... 为了验证基于特征映射模型的情感语音合成方法的有效性以及该方法与其他情感语音合成方法[24 -25 ] 的性能差异,将改进后的模型FM_VITS同基线模型VITS、VITS2[26 ] 以及基于参考语音方法的VITS情感语音合成模型AR_VITS,在语音合成质量、情感表达以及文本泛化能力方面进行比较. VITS与VITS2仅使用情感标签控制合成语音情感;AR_VITS使用预训练的wave2vec2[27 ] 从参考音频中提取情感特征并指导VITS合成情感语音. 开展消融实验,验证不同模块对FM_VITS模型性能的影响. 使用ESD情感语音数据集作为实验数据集以训练和测试各模型. 该数据集分为中文和英文数据子集,每个子集包含10位说话人,每位说话人录制1 750条包括开心、愤怒、惊讶、伤心以及中性情感在内的情感语音. 受限于情感表达需要,ESD数据集的情感语音时长较短,平均每条语音的文本约为6个单词长度. 为了验证模型在多说话人条件下的情感语音合成能力,同时控制模型参数量以及数据集的建模复杂度,使用编号为0012、0013的男性说话人数据子集以及编号为0017、0018、0019的女性说话人数据子集作为训练集与验证集. 单说话人条件下的实验使用0019数据子集. 各模型的训练均使用具有24 GB显存的NVIDIA显卡,进行批大小为52、共计1200 轮次的训练. ...
1
... 为了验证基于特征映射模型的情感语音合成方法的有效性以及该方法与其他情感语音合成方法[24 -25 ] 的性能差异,将改进后的模型FM_VITS同基线模型VITS、VITS2[26 ] 以及基于参考语音方法的VITS情感语音合成模型AR_VITS,在语音合成质量、情感表达以及文本泛化能力方面进行比较. VITS与VITS2仅使用情感标签控制合成语音情感;AR_VITS使用预训练的wave2vec2[27 ] 从参考音频中提取情感特征并指导VITS合成情感语音. 开展消融实验,验证不同模块对FM_VITS模型性能的影响. 使用ESD情感语音数据集作为实验数据集以训练和测试各模型. 该数据集分为中文和英文数据子集,每个子集包含10位说话人,每位说话人录制1 750条包括开心、愤怒、惊讶、伤心以及中性情感在内的情感语音. 受限于情感表达需要,ESD数据集的情感语音时长较短,平均每条语音的文本约为6个单词长度. 为了验证模型在多说话人条件下的情感语音合成能力,同时控制模型参数量以及数据集的建模复杂度,使用编号为0012、0013的男性说话人数据子集以及编号为0017、0018、0019的女性说话人数据子集作为训练集与验证集. 单说话人条件下的实验使用0019数据子集. 各模型的训练均使用具有24 GB显存的NVIDIA显卡,进行批大小为52、共计1200 轮次的训练. ...
1
... 为了验证基于特征映射模型的情感语音合成方法的有效性以及该方法与其他情感语音合成方法[24 -25 ] 的性能差异,将改进后的模型FM_VITS同基线模型VITS、VITS2[26 ] 以及基于参考语音方法的VITS情感语音合成模型AR_VITS,在语音合成质量、情感表达以及文本泛化能力方面进行比较. VITS与VITS2仅使用情感标签控制合成语音情感;AR_VITS使用预训练的wave2vec2[27 ] 从参考音频中提取情感特征并指导VITS合成情感语音. 开展消融实验,验证不同模块对FM_VITS模型性能的影响. 使用ESD情感语音数据集作为实验数据集以训练和测试各模型. 该数据集分为中文和英文数据子集,每个子集包含10位说话人,每位说话人录制1 750条包括开心、愤怒、惊讶、伤心以及中性情感在内的情感语音. 受限于情感表达需要,ESD数据集的情感语音时长较短,平均每条语音的文本约为6个单词长度. 为了验证模型在多说话人条件下的情感语音合成能力,同时控制模型参数量以及数据集的建模复杂度,使用编号为0012、0013的男性说话人数据子集以及编号为0017、0018、0019的女性说话人数据子集作为训练集与验证集. 单说话人条件下的实验使用0019数据子集. 各模型的训练均使用具有24 GB显存的NVIDIA显卡,进行批大小为52、共计1200 轮次的训练. ...
1
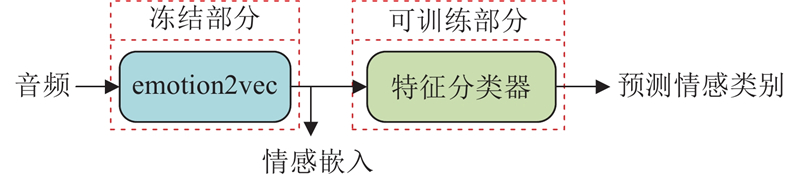
... 使用的客观指标包括实时因子RTF、词错误率WER、情感分类准确率ECA以及情感嵌入余弦相似度EECS. RTF用于评价模型的语音合成速度,WER用于评价语音合成质量,ECA和EECS用于评价合成语音的情感表达能力与情感细节还原程度. WER使用预训练的Whisper模型[28 ] 进行语音识别,并计算识别结果中出现单词错误的概率. EECS和ECA以预训练的emotion2vec[29 ] 为基础,加入基于全连接层的特征分类器,构建如图8 所示的情感识别分类器. 使用ESD数据集训练情感识别分类器,识别准确率为92%. 使用该分类器获得合成语音的ECA以及合成语音与真实语音的情感嵌入,计算二者的余弦相似度得到EECS. ...
1
... 使用的客观指标包括实时因子RTF、词错误率WER、情感分类准确率ECA以及情感嵌入余弦相似度EECS. RTF用于评价模型的语音合成速度,WER用于评价语音合成质量,ECA和EECS用于评价合成语音的情感表达能力与情感细节还原程度. WER使用预训练的Whisper模型[28 ] 进行语音识别,并计算识别结果中出现单词错误的概率. EECS和ECA以预训练的emotion2vec[29 ] 为基础,加入基于全连接层的特征分类器,构建如图8 所示的情感识别分类器. 使用ESD数据集训练情感识别分类器,识别准确率为92%. 使用该分类器获得合成语音的ECA以及合成语音与真实语音的情感嵌入,计算二者的余弦相似度得到EECS. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}