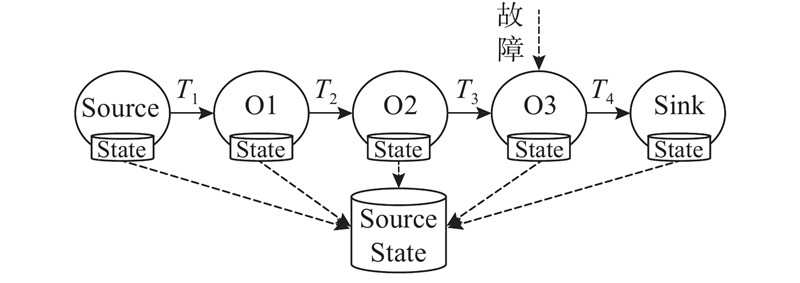
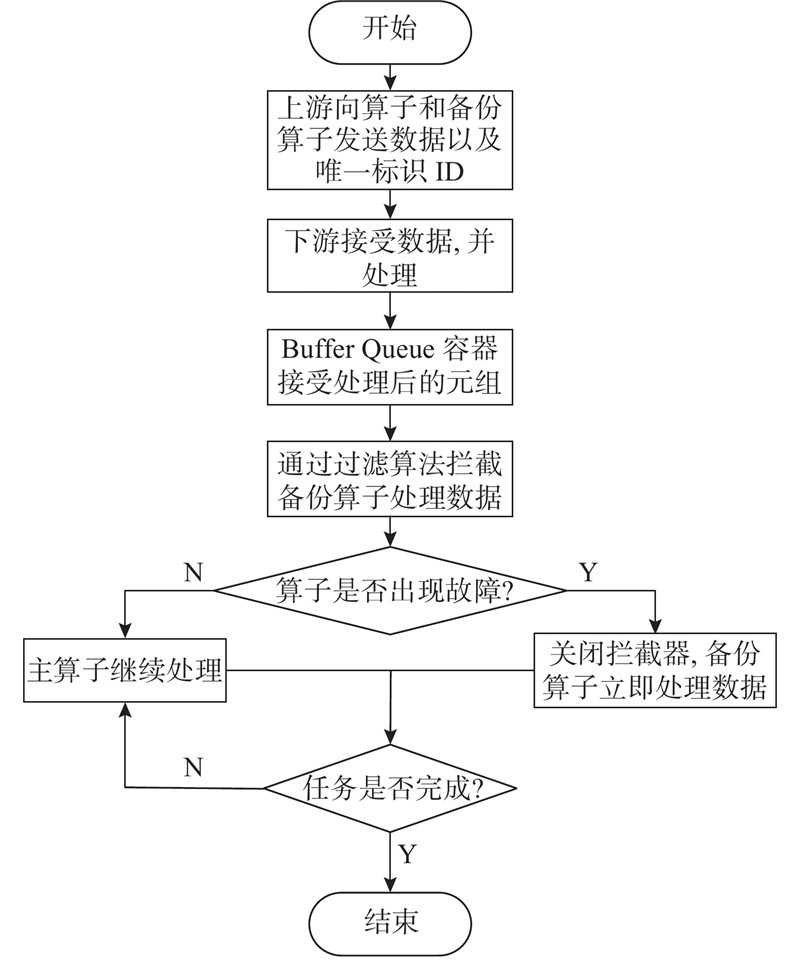
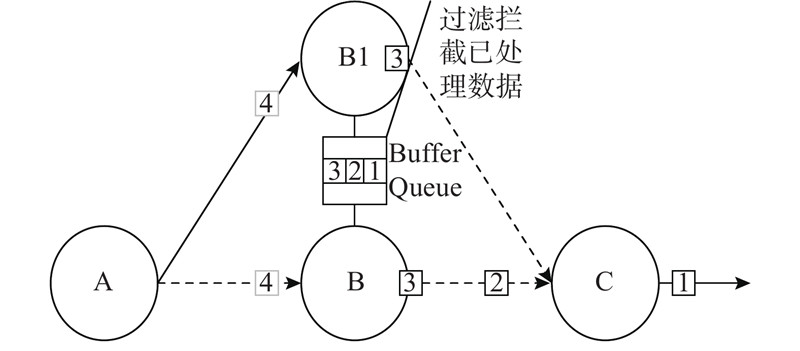
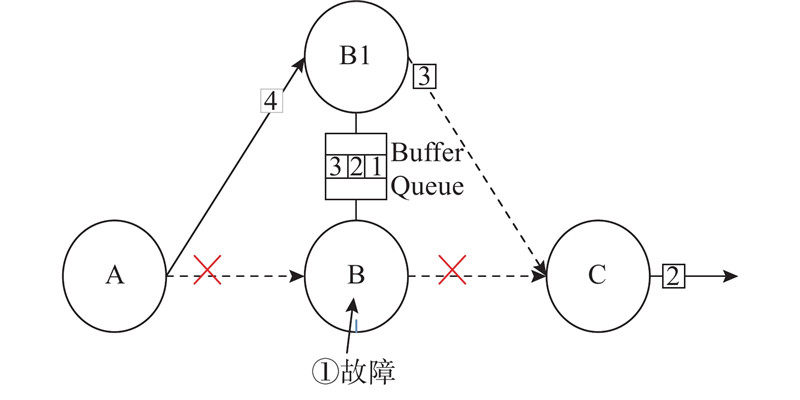
| 计算机与控制工程 |
|


|
|
|
| 面向Flink流处理框架的主动备份容错优化 |
刘广轩1,2,3( ),黄山1,2,3,*(),胡佳丽1,2,3,段晓东1,2,3 ),黄山1,2,3,*(),胡佳丽1,2,3,段晓东1,2,3 |
1. 大连民族大学 计算机科学与工程学院,辽宁 大连 116600
2. 大数据应用技术国家民委重点实验室,辽宁 大连 116600
3. 大连市民族文化数字技术重点实验室,辽宁 大连 116600 |
|
| Fault tolerant optimization of active backup for Flink stream processing framework |
| Guang-xuan LIU1,2,3(),Shan HUANG1,2,3,*(),Jia-li HU1,2,3,Xiao-dong DUAN1,2,3 |
1. College of Computer Science and Technology, Dalian Minzu University, Dalian 116600, China
2. State Ethnic Affairs Commission Key Laboratory of Big Data Applied Technology, Dalian 116600, China
3. Dalian Key Laboratory of Digital Technology for National Culture , Dalian 116600, China |
引用本文:
刘广轩,黄山,胡佳丽,段晓东. 面向Flink流处理框架的主动备份容错优化[J]. 浙江大学学报(工学版), 2022, 56(2): 297-305.
Guang-xuan LIU,Shan HUANG,Jia-li HU,Xiao-dong DUAN. Fault tolerant optimization of active backup for Flink stream processing framework. Journal of ZheJiang University (Engineering Science), 2022, 56(2): 297-305.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2022.02.010
或
https://www.zjujournals.com/eng/CN/Y2022/V56/I2/297
|
| 1 |
DEAN J, GHEMAWAT S MapReduce: a flexible data processing tool[J]. Communications of the ACM, 2010, 53 (1): 72- 77
doi: 10.1145/1629175.1629198
|
| 2 |
ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al Spark: cluster computing with working sets[J]. HotCloud, 2010, 10: 95
|
| 3 |
KATSIFODIMOS A, SCHELTER S. Apache Flink: stream analytics at scale [C]// IEEE International Conference on Cloud Engineering Workshop. Berlin: IC2EW, 2016: 28-38.
|
| 4 |
CHINTAPALLI S, DAGIT D, EVANS B, et al. Benchmarking streaming computation engines: storm, flink and spark streaming [C]// 2016 IEEE International Parallel and Distributed Processing Symposium Worshops. Chicago: IPDPSW, 2016: 1789-1792.
|
| 5 |
CHANDY K M, LAMPORT L Distributed snapshots: determining global states of a distributed system[J]. ACM Transactions on Computer Systems, 2016, 3 (1): 63- 75
|
| 6 |
BALAZINSKA M, BALAKRISHNAN H, MADDEN S R, et al Fault-tolerance in the Borealis distributed stream processing system[J]. ACM Transactions on Database Systems, 2008, 33 (1): 81- 124
|
| 7 |
HWANG J H, CETINTEMEL U, ZDONIK S. Fast and highly-available stream processing over wide area networks [C]// 2008 IEEE 24th International Conference on Data Engineering. Cancun: ICDE, 2008: 804-813.
|
| 8 |
HEINZE T, ZIA M, KRAHN R, et al. An adaptive replication scheme for elastic data stream processing systems [C]// Proceedings of the 9th ACM International Conference on Distributed Event-based Systems. Oslo: DEBS, 2015 : 150-161.
|
| 9 |
CHANDRAMOULI B, GOLDSTEIN J Shrink: prescribing resiliency solutions for streaming[J]. Proceedings of the VLDB Endowment, 2017, 10 (5): 505- 516
|
| 10 |
BENOIT A, RAINA S K, ROBERT Y Efficient checkpoint/verification patterns[J]. International Journal of High Performance Computing Applications, 2017, 31 (1): 52- 65
doi: 10.1177/1094342015594531
|
| 11 |
AKBER S M A , CHEN H , WANG Y , et al. Minimizing overheads of checkpoints in distributed stream processing systems [C]// 2018 IEEE 7th International Conference on Cloud Networking. Tokyo: CloudNet, 2018: 1-4.
|
| 12 |
ZHUANG Y, WEI X, LI H, et al. An optimal checkpointing model with online OCI adjustment for stream processing applications [C]// International Conference on Computer Communication and Networks. Hangzhou: ICCCN, 2018: 1-9.
|
| 13 |
LOMBARDI F, ANIELLO L, BONOMI S, et al Elastic symbiotic scaling of operators and resources in stream processing systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29 (99): 572- 585
|
| 14 |
刘智亮. 面向流数据处理的动态自适应检查点机制研究[D]. 吉林: 吉林大学, 2017.
LIU Zhi-liang . Research on adaptive checkpoint mechanism for large-scale streaming data processing [D]. Jilin: Jilin University, 2017.
|
| 15 |
郭文鹏, 赵宇海, 王国仁, 等 面向Flink迭代计算的高效容错处理技术[J]. 计算机学报, 2020, 43 (11): 2101- 2118
GUO Wen-peng, ZHAO Yu-hai, WANG Guo-ren, et al Efficient fault-tolerant processing technology for Flink iterative computing[J]. Chinese Journal of Computers, 2020, 43 (11): 2101- 2118
doi: 10.11897/SP.J.1016.2020.02101
|
| 16 |
HAN D Z, CHEN X G, LEI Y X, et al Real-time data analysis system based on Spark Streaming and its application[J]. Journal of Computer Applications, 2017, 37 (5): 1263- 1269
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|