

然而,Flink现有的架构设计使得在复杂拓扑下单个Task失败就能使所有Task重新部署,耗时可能会持续几分钟,导致作业的输出断流,降低了业务处理的实时性与稳定性. 本研究针对这一问题开展研究,提出基于缓存队列的主动备份容错模型,然后提出缓存队列数据过滤算法,优化了主动备份处理效率. 最后在Flink上实现了本研究提出的优化策略,并通过实验验证容错优化机制的有效性.
1. 相关研究
现有的流处理引擎容错策略分为2大类,一类是主动备份,一类是被动备份.
主动备份策略是指对任务的一种热备份,在一些流处理系统中较为常见且实现过程较简单. 主节点和从节点之间通过网络通信,在正常情况下,主机处于工作状态,从机处于等待状态,两者通过监听心跳感知状态变化,当发现主节点出现异常,从节点立刻代替主节点,完成主节点的任务. 主动备份策略可以使得备份任务在出现故障后实现实时恢复,故障的出现基本不会影响整个应用,保障了系统的稳定性. 然而,这种策略会使得任务在备份时计算多次,使得处理效率降低. 关于主动备份的优化,Balazinska 等[6]提出延迟、处理和纠正 (delay, process, and correct,DPC)模型,是基于主动备份的流处理容错方法,在保证了低处理延迟的基础上,容忍多个同时发生的故障以及恢复期间发生的任何进一步故障,同时还保证了最终结果的一致性. Hwang等[7]提出在主动备份时管理备份副本的算法,系统中的任何副本都可以使用上游副本中最先到达的数据,该系统实现了低延迟处理以并保证了服务器和网络问题的鲁棒性.
被动备份[8]的主要思想是将每个任务的自身最新状态定期备份到内存或外部存储介质中,当发生故障后,应用可以在该介质处进行任务的恢复. Flink的基于检查点机制的容错方法是一种被动备份的思想,检查点机制在大多数情况下可以提高系统的效率,而且在生产环境中已经被广泛应用,但是该机制仍存在以下问题:一是检查点频率对系统处理效率以及中央处理器(central processing unit,CPU)使用的影响,二是从检查点处恢复会带来一定的卷回开销,造成系统资源的浪费以及处理效率的低下. 针对以上问题,较多文献以检查点为突破口进行相关的优化,其中Chandramouli等 [9]通过实验证明Flink检查点间隔越大,带来的处理延迟越小并且CPU的使用率越低,但与此同时故障恢复会带来一定的损耗.
现如今大多数处理引擎将优化目标放在了检查点上面. Benoit等[10]对一些无法立刻检测到的潜在错误提出平衡算法,使得检查点和其验证达到最佳平衡状态. Akber等[11]根据任务的失败率决定检查点间隔以优化应用的处理效率. Zhuang等[12]提出流处理系统最优检查点模型,通过该模型可以求解出左右检查点间隔参数. Lombardi等[13]提出了分散的因果检查点容错技术,在不影响恢复效率的情况下显著降低了基于检查点的方法运行时的开销. 刘智亮[14]提出面向流式应用负载动态变化,支持在线自适应调节间隔的检查点机制. 郭文鹏等[15]等结合Flink系统的迭代数据流模型,进一步提出基于头尾检查点的悲观迭代容错机制,该容错机制以非阻塞的方式编写检查点,充分结合Flink迭代数据流的特点,将可变数据集的检查点注入迭代流本身. 通过设计迭代感知,简化系统架构,降低检查点成本和故障恢复时间. 目前生产环境中使用的流处理系统所采用的容错策略大多亦是基于传统流计算容错方法的混合与改进. Apache Storm通过周期性地发送Checkpoint 消息,让所有算子进行状态备份. 并且,在元组级别,使用acker线程追踪由源头发送的元组信息组成的元组树及确认消息,通过比对这两方面信息,保证元组不会丢失. 失败的元组会由源头进行重放重新处理. Spark Streaming[16]采取离散化的编程模型,将流应用映射成一系列的微批处理. 它定期将算子的状态和数据信息保存在弹性分布式数据集(resilient distributed datasets,RDD)中. 如果RDD 中某个分区发生故障,可以通过其他机器并行计算从而加速恢复. Apache Flink[17]基于栅栏模型实现了轻量级的异步检查点机制,结合支持稳定存储的数据源可以保证元组被系统正确处理,是检查点结合上游备份的容错策略.
不论是基于传统的主动备份、被动备份、上游备份策略,还是基于检查点的卷回恢复机制,单一、静态的容错机制难以满足不同应用场景的实际需求.
2. 问题归纳
2.1. Flink的容错策略介绍
实时大数据处理系统须提供容错机制,以保证系统可以应对如进程失败、节点宕机或网络中断等故障. Flink将故障分为Task failover与Master failover两大类分别处理.
Master failover指的是JobManager出现故障,此时TaskManager可以正常运行. 针对这种情况,Flink须将所有任务重新执行.
Task Failover指的是单个Task由于某种原因(如用户程序逻辑存在逻辑上的错误、Task自动退出或者TaskManager因为系统环境的问题出错退出)而执行失败的故障. 表现为Master还在,但是某一个Task失联,最终通过下游的Task抛出异常. 针对这种情况,Flink提供了3种恢复模式. 1) Restart-all恢复模式. 该恢复模式是基于Flink提供的一种基于检查点(Checkpoint)的故障恢复机制实现的,该机制存在仅一次(exactly-once)和至少一次(at-least-once)这2种语义下做快照的方式,使Task只须从上一个Checkpoint处进行恢复重新运行即可. 2) Restart-individual恢复模式. 在该模式下,某Task出现故障后,仅须重启该Task即可,然而此模式仅适用于各个Task之间没有数据传输的情况,应用范围较小,本研究不作重点讨论. 3) Restart-Region模式. 该模式将Flink批处理作业图中Task以Pipeline方式传输的子图称为一个Region,从而将整个Flink执行图分为多个Region,那么出现故障后,只须重启该Region部分的Task即可. 该模式仅适用于批处理作业,不是本研究重点.
2.2. Flink容错策略存在的问题
Restart-all基于Checkpoint的全局卷回恢复的形式来重启整个任务,这种策略会带来一定的恢复代价与资源的浪费. 任务重启需要大量的时间,并且任务在恢复时只能从上一个Checkpoint处进行恢复,即存在任务重复计算的情况. 假设现有某Flink Job的StreamGraph如图1所示. 图中,T1、T2、T3、T4为各个算子之间传输的平均时间. 若在某一时刻算子O3所在节点出现故障导致Flink Job从上一次Checkpoint处恢复,此时任务恢复到故障之前的所需时间为
图 1

式中:
式中:n为故障位置与上一次成功的Checkpoint保存的偏移量相差的轮数. 由于Checkpoint存储在内存或外部存储引擎中,制作Checkpoint时将会有输入/输出(input/output,I/O)以及CPU消耗,所以Checkpoint的间隔也会对Flink的处理时延以及故障恢复的时间产生影响. Checkpoint设置的间隔越小就会给Flink带来越高的处理时延,而间隔越大在任务出错后故障恢复的时间也会越大. 因此,Checkpoint的间隔应针对任务的出发点不同进行调整.
2.3. 优化目标
一些应用(如金融系统、实时计算、网络监控)要求系统在规定的时间内完成数据分析的任务,因此在这些实时计算任务中,除了系统自身故障、网络波动和处理逻辑之外,计算超时也会被判定为整体作业的失败,即发生故障. 如表1所示为数据清洗实时处理系统的日志信息,该系统要求任务在每日的8:00准时接受前端数据,并通过Flink进行数据处理,要求必须在8:10之前完成任务并发送给下一个组件处理.
表 1 Flink任务日志信息
Tab.1
| 日期 | 开始时间 | 故障次数 | 完成时间 | 完成 |
| 1.7 | 8:00 | 0 | 8:08:20 | 是 |
| 1.8 | 8:00 | 1 | 8:09:10 | 是 |
| 1.9 | 8:00 | 2 | 8:10:02 | 否 |
| 1.10 | 8:00 | 3 | 8:10:23 | 否 |
| 1.11 | 8:00 | 1 | 8:09:08 | 是 |
由表1可以发现,流处理框架,如Flink,在进行实时处理面对任务故障问题时表现出不够实时性,常常须消耗一定的时间去进行故障恢复,从而导致任务失败(如表中日期1.10和日期1.11),导致整体效率变低,造成任务失败. 同时,底层处理组件keyGroup的数目限制(必须是2的幂次)导致Flink任务存在木桶效应,整体任务受到短板节点的影响,会出现如表2所示的,即使扩大并行度(测试案例为并行度从8扩大到12)也不会提升甚至会降低任务吞吐量的情况. 表中,P表示总的并行度,K1表示分配了1个KeyGruop的并行度数量,K2表示分配了2个KeyGroup的并行度数量,T表示任务每分钟的吞吐量. 当并行度为12时,将有4个subtask去处理2个KeyGroup数据,将会造成整个任务的瓶颈. 在有一定额外空闲资源的情况下,由于木桶效应的存在,Flink对资源的合理利用要求较高,若利用不好或者资源没有达到一定量的需求,整体效率无法提升,即存在对空闲资源利用不合理的情况.
表 2 增加并行度对吞吐量的影响
Tab.2
| P | K1 | K2 | T |
| 8 | 8 | 0 | 2000 |
| 12 | 8 | 4 | 1923 |
| 16 | 16 | 0 | 4335 |
根据前文概述,相对其他流处理系统,Flink的处理效率较高. 但是,Flink难以提供高效的故障恢复机制,主要原因是当某节点出现故障后,在该节点恢复时必须进行全局重启,重载与重播带来的巨大时间消耗对于一些线上业务来说是难以接受的. 同时,底层组件的数目限制导致Flink常常出现耗费资源却无法提升效率的情况,因此结合上述问题,本研究针对流处理系统提出的优化目标如下:1) 当系统中某一个任务出现故障时,无须全局重启任务,且故障节点能瞬时恢复;2) 非故障Task正常为线上提供服务;3) 故障恢复后不影响整体任务的最终结果,即不会在失败的组件中丢失任何信息,且能保证数据全部被处理且仅处理一次;4) 充分利用空闲资源去解决上述目标.
3. 基于缓存队列的容错策略
3.1. 缓存队列容错策略介绍与实现
缓存队列的容错策略(buffer queue backup strategy, BQBS)采纳主动备份的快速恢复的思想,同时对主动备份带来的重复计算的问题进行优化. 本研究提出的BQBS策略将会大幅提升Flink任务在出现故障后的恢复效率. 该策略以Flink Job的某个task为基础,流程如图2所示.
图 2
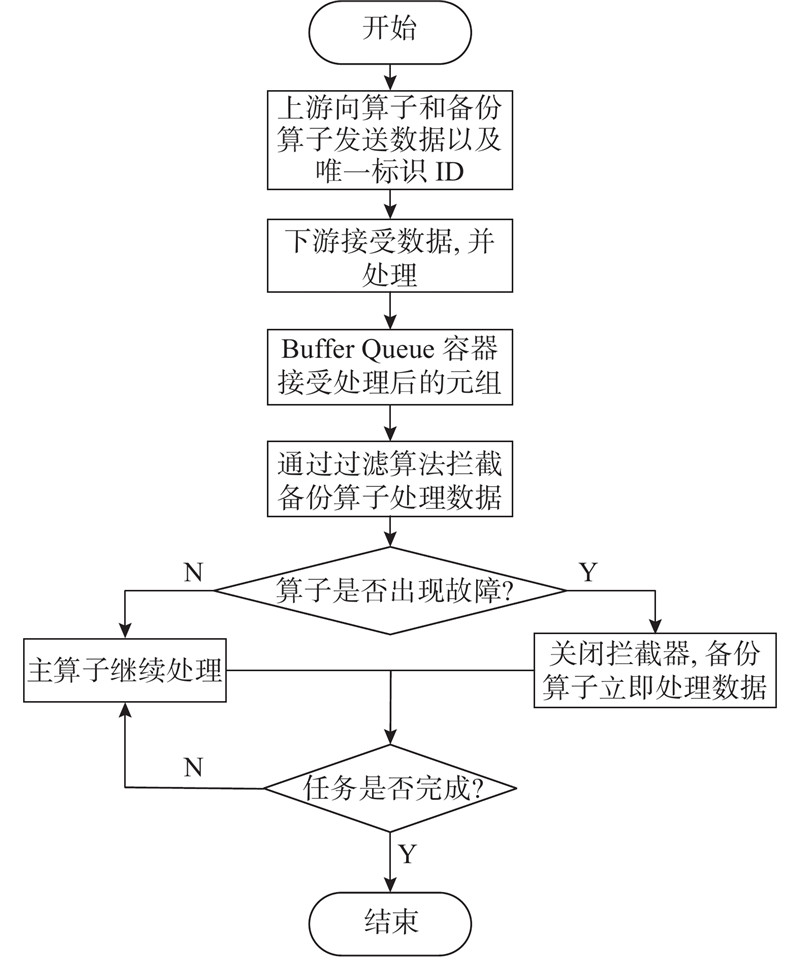
1)在数据流准备进入须备份的Task之前须进行预处理操作,为数据流中的每条数据元组添加唯一标识ID. 2)上游算子利用空闲资源将数据流传输到主算子以及其备份算子中,并保证备份算子与主算子同时接受到相同的数据. 3)在Task与其备份算子Task1之间设置内存级别的Buffer Queue组件,其最大优势是可以快速读写数据,并在该Queue中缓存Task已经处理或正在处理元组的ID以及对应的数据信息. 4)在Task出现故障后,JobManager立刻感知Task心跳超时,产生故障信息,将发生故障的元组ID发送给备份算子. 5)备份算子在接受到故障信息以及元组ID后,重新在Buffer Queue中检索并拾起该ID对应的数据,激活备份算子与下游算子之间的数据传输通道,该算子此时可以做相应的逻辑处理,主从节点身份进行互换.
步骤1)对上游的中间结果添加一个唯一表示ID,该ID在故障恢复中相当于一个索引的作用,可以使备份算子立刻查找到故障数据. 在步骤2)中,上游算子的数据利用空闲资源进行并行传输,即T主算子与备份算子会同时接受相同数据并且处理逻辑完全相同. 为了保证不同时出现故障,两者会运行在不同的节点中. 在步骤3)中Buffer Queue在对Flink任务容错性能提升的前提下还可以通过其自身的缓存与过滤重复元组的功能保证任务数据处理仅一次的语义. 其中过滤算法如下所示.
算法1 Buffer Queue的过滤算法
输入:任务拓扑,添加Tuple ID的流数据,最大缓存值MAX_MEMORY.
输出:无.
1. if Buffer Queue.containskey (TupleID)
2. ACTION=“FILTER”
3. else
4. Buffer Queue.EnQueue (TupleID)
5. ACTION=“ADD”
6. end if
7. if operator.ACTION=“ADD”
8. operator做逻辑运算
9. else if
10. operator.ACTION=“FILTER”
11. operator不做逻辑运算
12. End if
13. If Buffer Queue.Memory
14. Buffer Queue.ClearQueue()
15. end if
16. end
根据算法1,Buffer Queue作为关键组件,会按顺序缓存处理过的数据及其ID,若Buffer Queue中没有当前数据的ID,Buffer Queue会将对应的数据信息以及其ID加入队列中,发出“ACTION=ADD”的信号;若Buffer Queue中存在该TupleID,则会发出“ACTION=FILTER”信号. 当前主算子和备份算子在做运算之前时,都会对ACTION进行取值验证,当ACTION的值为“ADD”时,主算子将会执行相应的逻辑,当接受到“FILTER”时,主算子不会做处理,也就不会存在重复计算导致的高资源消耗问题,也可以保证结果的准确性. 当主算子出现故障时,主算子与下游失去通信,不会接受到新元组,而备份算子始终接受下游算子的数据信息. 按照算法1,备份算子接受到的ACTION将会是“ADD”,因此会做相应处理. Buffer Queue的大小并不是无限制的,会受到最大容量MAX_MEMORY的限制,当超出该上限时,则执行队列的FIFO规则,新的元组将替换旧的元组. Flink使用算法1可以提升上游传输故障恢复效率,如图3所示,当上游算子A处理完数据后,信息同时发送给主算子B和备份算子B1,Buffer Queue 中缓存了主算子B已经处理或正在处理的数据ID。当备份算子B1准备处理数据时,会在Buffer Queue中检测,如果存在该TupleID,则对备份算子要处理的数据进行拦截,备份算子就不会继续处理该数据。
图 3
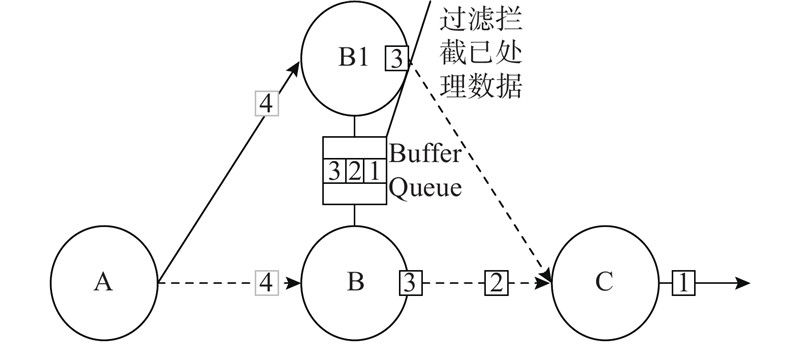
图 3 正常情况下缓存队列的拦截作用
Fig.3 Interception function of Buffer Queue under normal circumstances
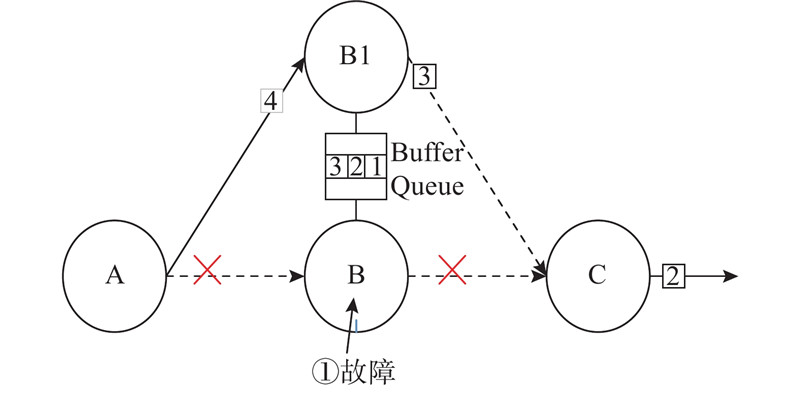
如图4所示,当上游算子A与B的数据传输出现故障后,下游算子A不再向B发送数据,A与备份算子B1的传输通信保持正常,此时Buffer Queue中并没有B1中的数据信息,因此就会缓存来自备份算子B1中的数据,并开启拦截器,B1与下游算子的channel被激活,可以达到瞬时恢复的效果.
图 4
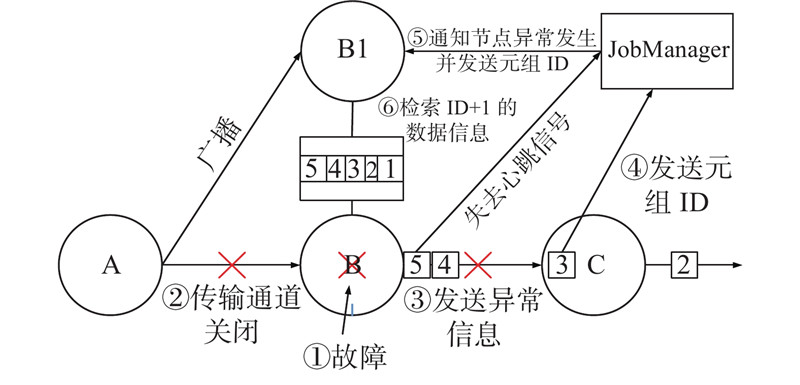
当算子自身出现故障后,根据本研究提出的算子自身故障恢复算法进行处理,具体步骤如下所示.
算法2 算子自身故障恢复算法
输入:任务拓扑,operator B注入进程级别的故障,operator B的上游operator A,算子B的下游operator C,算子B的备份算子B1
输出:无
1. operator A与operator B的Channel关闭
2. operator B向operator C发送Exception
3. operator C向JobManager发送当Cache中最大的 TupleID
4. JobManager向备份算子operator B1发送接收到的 TupleID 并且设置operator B1的ACTION=“ADD”
5. TupleID=TupleID+1
6. 在 Buffer Queue中查找TupleID对应的算子信息
7. y = 当前Buffer Queue中最大的元组ID
8. for i=TupleID to y
9. operator B1做对应TupleID的逻辑运算
10. End for
如图5所示,当主算子B出现故障后,JobManager会通过心跳超时感知程序异常,与此同时,不论是逻辑错误还是进程级别的故障,Flink本身算子的上下游都会感知到连接状态的变化,即算子的上下游都会感知到故障的发生. 此时,算子的下游C会从当前算子Cache中找出最大的元组ID发送给JobManager,因为进入到算子C的数据都是被算子B成功处理后的数据,同时Flink中每个算子都有一个Cache用来缓存待处理算子,若从算子C的Cache中取出最大的元组ID,该ID就是算子B在发生故障前最后一个正确处理的算子. 同时为了让备份算子感知错误,在主算子出现故障后,JobManager会收集当前出现故障数据的元组ID,并将ID发送给备份算子,当备份算子接受到ID后,会从Buffer Queue中检索ID+1对应的数据信息. 选择元组ID+1的原因是,当前ID对应的数据元组已经被主算子处理,如图中ID=3的算子此时已经进入下游算子C,程序在运行到元组ID=4的算子时发生故障,因此,当备份算子接受到算子ID后,须在Buffer Queue中检索ID+1的元组信息. 当备份算子检索到信息后,拾起数据开始继续做处理,此时主、从算子身份互换,之前的备份算子立即切换成为主算子.
图 5
3.2. 效率评估
所提出的策略关键在于解决了Flink无法充分利用空闲资源以及出现故障后延迟的问题. 根据前文提出的木桶效应以及式(4)可以得出,在一定程度上扩大Flink任务的并行度也无法提升整体效率,因此本研究充分利用空闲资源,将资源利用在算子备份以及Buffer Queue维护上.
本研究重点解决了Flink自身故障恢复后带来的重载延迟,即在整体恢复时延中去掉了
若备份算子到下游算子传输延迟为Tbd,则此时算子整体的时延为
实际中,该策略还会带来一定的网络通信消耗,但是这部分的消耗与Flink原本的消耗基本相似,因此在式(4)中不进行估计.
4. 实验结果与分析
4.1. 实验环境
表 3 Flink集群硬件配置信息
Tab.3
| 硬件 | 配置信息 |
| 处理器 | Intel i7-8700 CPU @ 3.20 GHz |
| CPU核心数 | 6核 |
| 主频 | 3.2 GHz |
| 内存 | 64 GB |
| 硬盘 | 100 GB SSD |
表 4 Flink集群软件配置信息
Tab.4
| 软件名 | 版本号 | 软件名 | 版本号 | |
| Centos OS | 7.4.1 | Java | 1.8.0 | |
| Flink | 1.8.0 | Kafka | 0.10.1.0 | |
| Hadoop | 2.7.5 | Flume | 1.7.0 |
选择问答网站的用户回答信息作为数据集,该数据集是一个嵌套JSON,包含用户信息、点赞数、收藏数、评论数. 对该数据进行数据清洗,根据点赞数来为评论添加等级信息. 首先使用Kafka对数据进行采集,从Redis中获取到点赞与等级之间的映射关系,再使用Flink对数据进行抽取、转换、加载,在完成数据解析后,将数据写入到Kafka的另一个topic中,最终使用Flume将数据进行分类落盘存储到HDFS中. 本实验所有计算的并行度为8,每个TaskManager所拥有的slot数为8,根据需求使用Flink中的Source、Connect、FlatMap、Filter、Map、Sink算子进行运算.
4.2. 评估标准
主要选择10、50、100万3个不同数据量的信息进行对比. 主要选取处理时延、吞吐量、故障恢复时间作为评估标准.
1)处理时延对比分析. 时延(latency)指从数据输入至计算引擎中被处理开始到最终输出的时间,单位为毫秒. 处理时延反映了一个系统的实时性能,延迟越低用户体验越好,时延表达式如下:
式中:
2)故障恢复时间对比分析. 故障恢复时间(recovery time)指前文所说的重载与重播时间,即故障发生开始到任务恢复到上一次数据源处理的位置所需的时间.
3)CPU利用率分析. CPU利用率指一段时间内CPU的使用量,本研究实验通过CPU利用率来验证计算资源占用情况.
4)内存使用率分析. 本研究通过实验对比Flink-RestartAll与Flink-BQBS在处理任务时的内存使用率.
表 5 Flink任务故障平均恢复时间
Tab.5
| 算子 | TR/s | 算子 | TR/s | |
| Source | 45 | Filter | 67 | |
| Connet | 65 | Map | 53 | |
| FlatMap | 71 | Sink | 39 |
在第1个实验中,对FlatMap算子使用本研究策略,在不同规模的数据下产生的处理时延对比如表6所示,其中Flink的Checkpoint间隔设置为30 s. 可以看出,本研究所提算法对数据处理的延迟产生的影响较小,尤其当数据量在100万以下时,与Flink原来的处理延迟没有太大差别;当数据量超过100万时,使用本研究所提出的策略后处理时间会比Flink原本的略高,约会产生4%的额外时延,原因是上游算子进行2次分发带来的延迟会随着数据量的增大而逐渐增大.
表 6 不同数据量下平均处理延迟对比
Tab.6
| 数据量/万 | 处理时延/s | |
| Flink-RestartAll | Flink-BQBS | |
| 10 | 82.0 | 84.5 |
| 50 | 170.0 | 176.0 |
| 100 | 355.0 | 369.0 |
| 200 | 723.0 | 739.0 |
在第2个实验中,分别对Flink-RestartAll与本研究提出的Flink-BQBS分4次对FlatMap所在节点随机注入进程级故障,2个模式的任务恢复结果如表7所示. 在Flink-RestartAll模式下每发生一次故障,平均恢复时间约为70 s,其中任务重载时间约为30 s,根据前文公式推算,本研究提出的BQBS策略可以避免任务的重载,且重播时间也会缩短,当第1次出现故障时,平均故障恢复时间为31 s,效果提升了56.3%,在第2次出现故障后恢复时间与Flink基于Checkpoint的全局卷回策略第1次发生故障的恢复时间大致相同,平均为73 s. 当第4次出现故障后,恢复时间约为157 s,也远好于同等故障下Flink-RestartAll的累计故障恢复时间.
表 7 不同恢复方式下平均恢复时间对比
Tab.7
| 故障次数 | Flink-RestartAll累计 重启时间/s | Flink BQBS故障 恢复时间/s |
| 1 | 71 | 31 |
| 2 | 150 | 73 |
| 3 | 210 | 113 |
| 4 | 290 | 157 |
本研究所提出的Flink-BQBS出现的在不同故障次数下恢复时间产生差异的原因是,本研究策略中故障恢复后导致的主从节点互换会使得下一次故障后的从节点与主节点之间接受的数据偏移量有所差距,在下一次出现故障后总会在算子重播上花费一些时间,且平均时间约为30 s.
在第3个实验中,分别对比Flink正常运行的情况下以及出现故障时系统的CPU利用率. 在正常情况下,本研究策略与Flink的CPU利用率基本相似,在出现故障时,本研究提出的算法会导致更高的CPU利用率,大致会消耗8%的CPU,出现这个的原因是因为下游算子频繁的广播数据到下游的操作会导致系统花费一定的资源.
在第4个实验中,对比了Flink-RestartAll与Flink-BQBS的内存使用率. 在任务正常运行情况下,Flink-RestartAll将会占用40.01%的内存,Flink-BQBS会占用42.70%的内存,本研究提出的算法内存使用率高的原因是在算法流程中主算子接受的数据会被缓存到缓存队列中,而缓存队列是基于内存的,存储的数据与缓存队列自身都会占用系统的内存.
根据实验,得出Flink的Restart-all恢复策略与本研究提出的基于Buffer Queue的恢复策略的对比信息,如表8所示. 表中,ηn、ηf分别为CPU正常、故障利用率,δ为内存使用率.
综上,本研究策略能在占用较低资源的情况下保证算子在出现故障后迅速恢复,并且能够在该任务出现3次及以下故障时,比Flink默认的恢复策略效率更高,恢复时间更短,系统稳定性得到了进一步提升.
表 8 Flink-RestartAll与Flink-BQBS对比信息
Tab.8
| 对比算法 | 恢复模式 | TR/s | ηn/% | ηf/% | δ/% |
| Flink-RestartAll | 全局卷回 | 71 | 62.0 | 76 | 40.01 |
| Flink-BQBS | 单点恢复 | 31 | 62.5 | 82 | 42.70 |
5. 结 语
针对Flink任务出现故障后因全局卷回策略造成流处理作业恢复效率低的问题,提出基于缓存队列的主动备份容错策略(BQBS),该策略主要借鉴了主动备份将任务从故障处快速恢复的思想以解决Flink容错效率低的问题. 该策略对主动备份中存在的备份节点重复计算的问题做了相应的优化,结合缓存队列提出一种过滤算法,实现了对重复数据过滤的功能,该算法可以提升Flink在发生上游传输故障时的恢复效率. 同时为了解决Flink算子自身故障恢复问题,提出算子自身故障恢复算法,该算法会借鉴Flink的JobManager发出的信号以及下游算子缓存的数据信息将故障发生时的数据发送给备份算子,当备份算子接收到数据后,实现即时恢复的效果. 通过对比Flink的Restart-all恢复模式与提出的Flink-BQBS恢复模式在发生故障下的任务重启时间,验证了Flink-BQBS能够在算子出现故障后快速恢复,从实验结果中得出,Flink-BQBS在任务出现故障后重启的时间缩短为Flink Restart-all恢复模式的1/6.
未来将在以下几个方面继续进行优化:1)将算法与Flink的Restart-individual和Restart-all这2种模式结合,进一步提升Flink在批流融合下的容错性能;2)进一步优化算法以降低额外资源消耗.
参考文献
MapReduce: a flexible data processing tool
[J].DOI:10.1145/1629175.1629198 [本文引用: 1]
Spark: cluster computing with working sets
[J].
Distributed snapshots: determining global states of a distributed system
[J].
Fault-tolerance in the Borealis distributed stream processing system
[J].
Shrink: prescribing resiliency solutions for streaming
[J].
Efficient checkpoint/verification patterns
[J].DOI:10.1177/1094342015594531 [本文引用: 1]
Elastic symbiotic scaling of operators and resources in stream processing systems
[J].
面向Flink迭代计算的高效容错处理技术
[J].DOI:10.11897/SP.J.1016.2020.02101 [本文引用: 1]
Efficient fault-tolerant processing technology for Flink iterative computing
[J].DOI:10.11897/SP.J.1016.2020.02101 [本文引用: 1]
Real-time data analysis system based on Spark Streaming and its application
[J].
State management in Apache Flink: consistent stateful distributed stream processing
[J].DOI:10.14778/3137765.3137777 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}