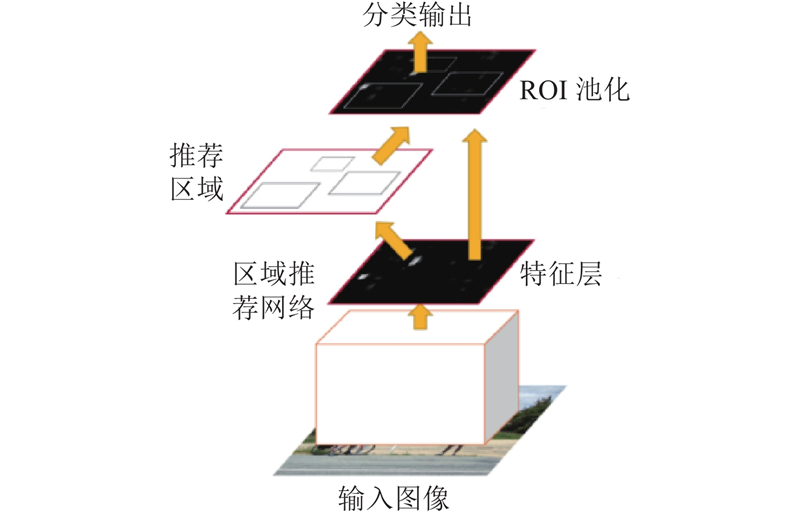
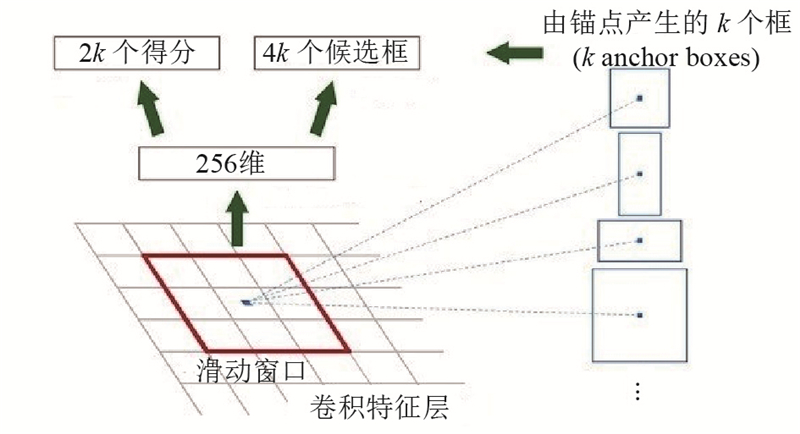
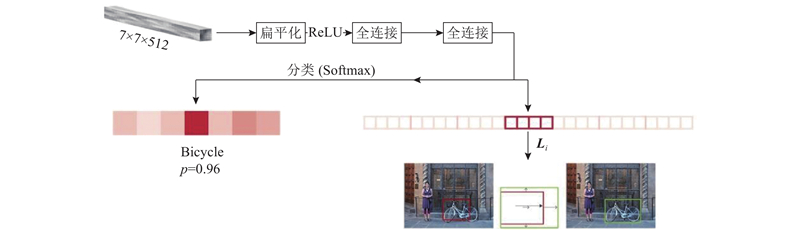
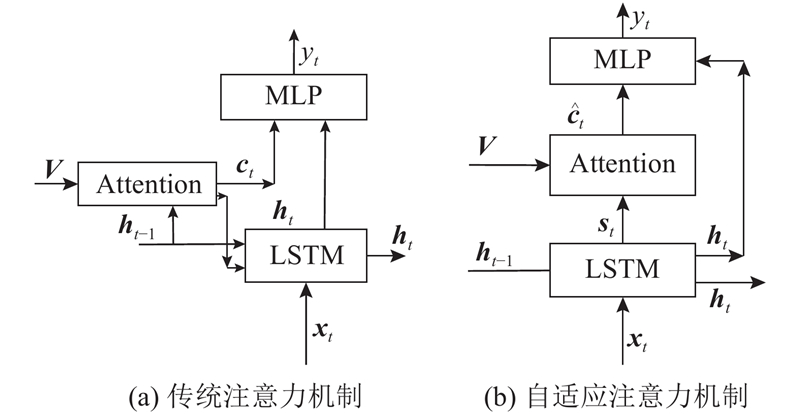
| 计算机技术、信息工程 |
|


|
|
|
| 基于全局?局部特征和自适应注意力机制的图像语义描述算法 |
赵小虎1,2( ),尹良飞1,2(),赵成龙1,2 ),尹良飞1,2(),赵成龙1,2 |
1. 中国矿业大学 矿山互联网应用技术国家地方联合工程实验室,江苏 徐州 221008
2. 中国矿业大学 信息与控制工程学院,江苏 徐州 221116 |
|
| Image captioning based on global-local feature and adaptive-attention |
| Xiao-hu ZHAO1,2(),Liang-fei YIN1,2(),Cheng-long ZHAO1,2 |
1. National and Local Joint Engineering Laboratory of Internet Application Technology on Mine, China University of Mining and Technology, Xuzhou 221008, China
2. School of Information and Control Engineering, China University of Mining and Technology, Xuzhou 221116, China |
| 1 |
FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images [C] // International Conference on Computer Vision. Heraklion: Springer, 2010: 15-29.
|
| 2 |
MAO J, XU W, YANG Y, et al. Deep captioning with multimodal recurrent neural networks(m-RNN) [EB/OL]. [2014-12-20]. https://arxiv.org/abs/1412.6632.
|
| 3 |
VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator [C] // IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3156-3164.
|
| 4 |
WU Q, SHEN C, LIU L, et al What value do explicit high level concepts have in vision to language problems[J]. Computer Science, 2016, 12 (1): 1640- 1649
|
| 5 |
ZHOU L, XU C, KOCH P, et al. Watch what you just said: image captioning with text-conditional attention [C] // Proceedings of the on Thematic Workshops of ACM Multimedia. [S.l]: Association for Computing Machinery, 2017: 305-313.
|
| 6 |
RENNIE S J, MARCHERET E, ROUEH Y, et al. Self-critical sequence training for image captioning [C] // IEEE Conference on Computer Vision and Pattern Recognition. Maryland: IEEE, 2017: 1179-1195.
|
| 7 |
SIMONYAN K, ZISSERMAN A Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014, 32 (2): 67- 85
|
| 8 |
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39 (6): 1137- 1149
|
| 9 |
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Computer Science. Lille: IMLS, 2015: 2048-2057.
|
| 10 |
FANG H, GUPTA S, IANDOLA F, et al. From captions to visual concepts and back [C] // IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1473-1482.
|
| 11 |
DONAHUE J, HENDRICKS L A, ROHRBACH M, et al Long-term recurrent convolutional networks for visual recognition and description[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39 (4): 677- 691
|
| 12 |
WU Q, SHEN C, WANG P, et al Image captioning and visual question answering based on attributes and external knowledge[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (6): 1367- 1381
|
| 13 |
YAO T, PAN Y, LI Y, et al. Boosting image captioning with attributes [C]// IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 4904- 4912.
|
| 14 |
YOU Q, JIN H, WANG Z, et al. Image captioning with semantic attention [C] // IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4651- 4659.
|
| 15 |
JIN J, FU K, CUI R, et al Aligning where to see and what to tell: image caption with region-based attention and scene factorization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39 (12): 2321- 2334
|
| 16 |
YANG Z, YUAN Y, WU Y, et al. Encode, review, and decode: reviewer module for caption generation [C] // International Conference on Neural Image Processing System. Barcelona: [s. n.], 2016.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|