| 计算机与控制工程 |
|


|
|
|
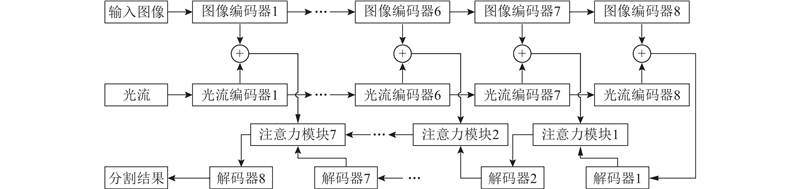
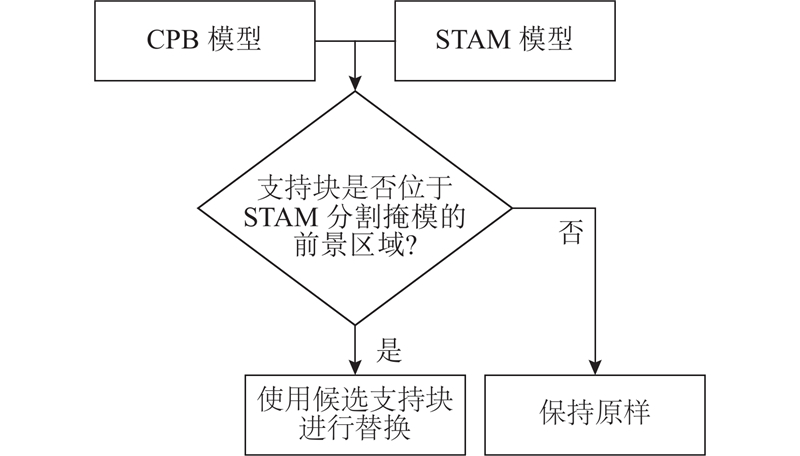
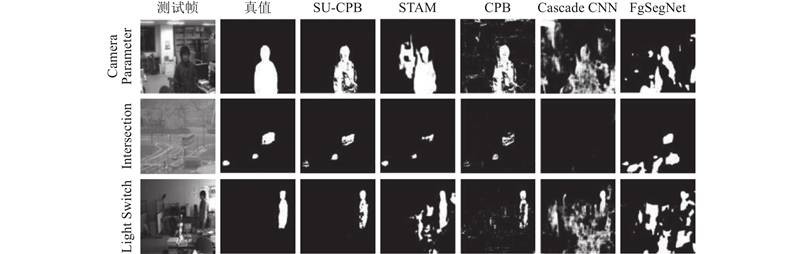
| 动态背景下基于自更新像素共现的前景分割 |
梁栋1( ),刘昕宇1,潘家兴1,孙涵1,周文俊2,金子俊一2 ),刘昕宇1,潘家兴1,孙涵1,周文俊2,金子俊一2 |
1. 南京航空航天大学 计算机科学与技术学院,江苏 南京 211100
2. 北海道大学 大学院信息科学研究科,北海道 札幌 220-0004 |
|
| Foreground segmentation under dynamic background based on self-updating co-occurrence pixel |
| Dong LIANG1(),Xin-yu LIU1,Jia-xing PAN1,Han SUN1,Wen-jun ZHOU2,Shun’ichi KANEKO2 |
1. College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautic, Nanjing 211100, China
2. Graduate School of Information Science and Technology, Hokkaido University, Sapporo 220-0004, Japan |
引用本文:
梁栋,刘昕宇,潘家兴,孙涵,周文俊,金子俊一. 动态背景下基于自更新像素共现的前景分割[J]. 浙江大学学报(工学版), 2020, 54(12): 2405-2413.
Dong LIANG,Xin-yu LIU,Jia-xing PAN,Han SUN,Wen-jun ZHOU,Shun’ichi KANEKO. Foreground segmentation under dynamic background based on self-updating co-occurrence pixel. Journal of ZheJiang University (Engineering Science), 2020, 54(12): 2405-2413.
链接本文:
http://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2020.12.015
或
http://www.zjujournals.com/eng/CN/Y2020/V54/I12/2405
|
| 1 |
VACAVANT A, CHATUAU T, WILHELM A, et al. A benchmark dataset for outdoor foreground/background extraction[C]// Asian Conference on Computer Vision. [S. l.]: Springer, 2012: 291-300.
|
| 2 |
STAUFFER C, GRIMSON W E L. Adaptive background mixture models for real-time tracking [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 1999: 246-252.
|
| 3 |
ELGAMMAL A, DURAISWAMI R, HARWOOD D, et al Background and foreground modeling using nonparametric kernel density estimation for visual surveillance[J]. Proceedings of the IEEE, 2002, 90 (7): 1151- 1163
doi: 10.1109/JPROC.2002.801448
|
| 4 |
JODOIN P M, MIGNOTTE M, KONRAD J Statistical background subtraction using spatial cues[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2007, 17 (12): 1758- 1763
doi: 10.1109/TCSVT.2007.906935
|
| 5 |
BARNICH O, DROOGENBROECK M V ViBe: a universal background subtraction algorithm for video sequences[J]. IEEE Transactions on Image Processing, 2011, 20 (6): 1709- 1724
doi: 10.1109/TIP.2010.2101613
|
| 6 |
ST-CHARLES P L, BILODEAU G A, BERGEVIN R SuBSENSE: a universal change detection method with local adaptive sensitivity[J]. IEEE Transactions on Image Processing, 2014, 24 (1): 359- 373
|
| 7 |
LIANG D, KANEKO S, HASHIMOTO M, et al Co-occurrence probability-based pixel pairs background model for robust object detection in dynamic scenes[J]. Pattern Recognition, 2015, 48 (4): 1374- 1390
doi: 10.1016/j.patcog.2014.10.020
|
| 8 |
MARTINS I, CARVALHO P, CORTE-REAL, et al BMOG: boosted Gaussian mixture model with controlled complexity for background subtraction[J]. Pattern Analysis and Applications, 2018, 21 (3): 641- 654
doi: 10.1007/s10044-018-0699-y
|
| 9 |
BRAHAM M, DROOGENBROECK M V. Deep background subtraction with scene-specific convolutional neural networks [C]// 2016 International Conference on Systems, Signals and Image Processing. [S. l.]: IEEE, 2016.
|
| 10 |
BABAEE M, DINH D T, RIGOLL G. A deep convolutional neural network for background subtraction [EB/OL]. [2019-09-30]. https://arxiv.org/pdf/1702.01731.pdf.
|
| 11 |
SHI G, HUANG T, DONG W, et al Robust foreground estimation via structured gaussian scale mixture modeling[J]. IEEE Transactions on Image Processing, 2018, 27 (10): 4810- 4824
doi: 10.1109/TIP.2018.2845123
|
| 12 |
WANG Y, LUO Z, JODOIN P, et al Interactive deep learning method for segmenting moving objects[J]. Pattern Recognition Letters, 2017, 96: 66- 75
|
| 13 |
ZHAO C, CHAM T, REN X, et al. Background subtraction based on deep pixel distribution learning [C]// 2018 IEEE International Conference on Multimedia and Expo. [S. l.]: IEEE, 2018: 1-6.
|
| 14 |
LIM L A, KELES H Y Foreground segmentation using convolutional neural networks for multiscale feature encoding[J]. Pattern Recognition Letters, 2018, 112: 256- 262
doi: 10.1016/j.patrec.2018.08.002
|
| 15 |
LIM L A, KELES H Y Learning multi-scale features for foreground segmentation[J]. Pattern Analysis and Applications, 2019, 23 (3): 1369- 1380
|
| 16 |
QIU M, LI X A fully convolutional encoder-decoder spatial-temporal network for real-time background subtraction[J]. IEEE Access, 2019, 7: 85949- 85958
|
| 17 |
ZHOU W, KANEKO S, LIANG D, et al Background subtraction based on co-occurrence pixel-block pairs for robust object detection in dynamic scenes[J]. IIEEJ Transactions on Image Electronics and Visual Computing, 2018, 5 (2): 146- 159
|
| 18 |
ZHOU W, KANEKO S, HASHIMOTO M, et al. A co-occurrence background model with hypothesis on degradation modification for object detection in strong background changes [C]// 2018 24th International Conference on Pattern Recognition. [S. l.]: IEEE, 2018: 1743-1748.
|
| 19 |
ZHOU W, KANEKO S, HASHIMOTO M, et al Foreground detection based on co-occurrence background model with hypothesis on degradation modi?cation in dynamic scenes[J]. Signal Processing, 2019, 160: 66- 79
doi: 10.1016/j.sigpro.2019.02.021
|
| 20 |
ZHOU W, KANEKO S, SATOH Y, et al. Co-occurrence based foreground detection with hypothesis on degradation modification in severe imaging conditions [C] // Proceedings of JSPE Semestrial Meeting 2018 JSPE Autumn Conference. [S. l.]: JSPE, 2018: 624-625.
|
| 21 |
ZHAO X, SATOH Y, TAKAUJI H, et al Object detection based on a robust and accurate statistical multi-point-pair model[J]. Pattern Recognition, 2011, 44 (6): 1296- 1311
doi: 10.1016/j.patcog.2010.11.022
|
| 22 |
LIANG D, PAN J, SUN H, et al Spatio-temporal attention model for foreground detection in cross-scene surveillance videos[J]. Sensors, 2019, 19 (23): 5142
doi: 10.3390/s19235142
|
| 23 |
LAROCHELLE H, HINTON G. Learning to combine foveal glimpses with a third-order boltzmann machine [C]// Advances in Neural Information Processing Systems 23: Conference on Neural Information Processing Systems A Meeting Held December. [S. l.]: Curran Associates Inc, 2010: 1243–1251.
|
| 24 |
KIM J, LEE S, KWAK D, et al. Multimodal residual learning for visual QA [C]// Neural Information Processing Systems. [S. l.]: MIT Press, 2016: 361-369.
|
| 25 |
MNIH V, HEESS N, GRAVES A. Recurrent models of visual attention [C]// Neural Information Processing Systems. [S. l.]: MIT Press, 2014, 2: 2204-2212.
|
| 26 |
XU K, BA J, KIROS R, et al Show, attend and tell: neural image caption generation with visual attention[J]. International Conference on Machine Learning, 2015, 3: 2048- 2057
|
| 27 |
LI H, XIONG P, AN J, et al. Pyramid attention network for semantic segmentation [EB/OL]. [2019-09-30]. https://arxiv.org/pdf/1805.10180.pdf.
|
| 28 |
Liu C. Beyond pixels: exploring new representations and applications for motion analysis [D]. Cambridge: MIT, 2009.
|
| 29 |
GOYRTTE N, JODOIN P M, PORIKLI F, et al. Changedetection. net: a new change detection benchmark dataset [C]// 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. [S. l.]: IEEE, 2012: 1-8.
|
| 30 |
TOYAMMA K, KRUMM J, BRUMITT B, et al. Wallflower: principles and practice of background maintenance [C]// Proceedings of the Seventh IEEE International Conference on computer vision. [S. l.]: IEEE, 1999: 255-261.
|
| 31 |
Laboratory for image and media understanding [DB/OL]. [2019-09-30]. http://limu.ait.kyushu-u.ac.jp/dataset/en/.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|