| 计算机技术 |
|


|
|
|
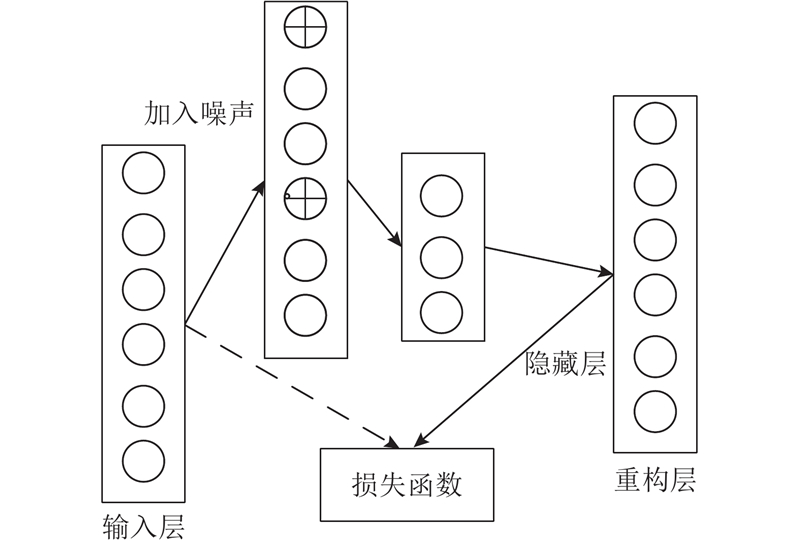
| 基于传播概率矩阵的异构信息网络表示学习 |
赵廷廷( ),王喆*(),卢奕南 ),王喆*(),卢奕南 |
| 吉林大学 计算机科学与技术学院 符号计算与知识工程教育部重点实验室,吉林 长春 130012 |
|
| Heterogeneous information network representation learning based on transition probability matrix (HINtpm) |
| Ting-ting ZHAO(),zhe WANG*(),Yi-nan LU |
| College of Computer Science and Technology, Key Laboratory of Symbolic Computation and Knowledge Engineering, Ministry of Education, Jilin University, Changchun 130012, China |
| 1 |
涂存超, 杨成, 刘知远, 等 网络表示学习综述[J]. 中国科学: 信息科学, 2017, 47 (8): 980- 996
TU Cun-Chao, YANG Cheng, LIU Zhi-Yuan, at el Network representation learning: an overview[J]. SCIENTIA SINICA: Informations, 2017, 47 (8): 980- 996
|
| 2 |
ROWEIS S T, SAUL L K Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290 (5500): 2323- 2326
doi: 10.1126/science.290.5500.2323
|
| 3 |
COX T F, COX M A A. Multidimensional scaling [M]. Boca Raton: CRC Press, 2000: 123–141.
|
| 4 |
BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering [C] // Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic. Cambridge: MIT Press, 2001: 585–591.
|
| 5 |
CHEN M, YANG Q, TANG X O. Directed graph embedding [C] // Proceedings of the 20th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc, 2007: 2707–2712.
|
| 6 |
NALLAPATI R, COHEN W W. Link-PLSA-LDA: a new unsupervised model for topics and influence of blogs [C] // Proceedings of the 2nd International Conference on Weblogs and Social Media. Seattle: AAAI, 2008: 84–92.
|
| 7 |
CHANG J, BLEI D M. Relational topic models for document networks [C] // Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Cambridge: JMLR, 2009: 81–88.
|
| 8 |
LE T M V, LAUW H W. Probabilistic latent document network embedding [C] // Proceedings of the 2014 International Conference on Data Mining. Washington: IEEE Computer Society, 2014: 270–279.
|
| 9 |
WARD C K Word2Vec[J]. Natural Language Engineering, 2016, 23 (1): 155- 162
doi: 10.1017/S1351324916000334
|
| 10 |
TANG J, QU M, WANG M, et al. Line: large-scale information network embedding [C] // Proceedings of the 24th International Conference on World Wide Web. Florence: WWW, 2015: 1067–1077
|
| 11 |
WANG D, CUI P, ZHU W. Structural deep network embedding [C] // Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 1225–1234
|
| 12 |
TANG J, QU M, MEI Q. PTE: predictive text embedding through large-scale heterogeneous text networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 1165–1174.
|
| 13 |
CAO S S, LU W, XU Q K. GraRep: learning graph representations with global structural information [C] // ACM International on Conference on Information and Knowledge Management. Melbourne: ACM, 2015: 891–900.
|
| 14 |
YANG J, LESKOVEC J. Overlapping community detection at scale: a nonnegative matrix factorization approach [C] // Proceedings of the 6th ACM International Conference on Web Search and Data Mining. Rome: ACM, 2013: 587–596
|
| 15 |
LEY M. The DBLP Computer science bibliography: evolution, research issues, perspectives [C] // String Processing and Information Retrieval, International Symposium. Portugal: SPIRE, 2002: 1–10.
|
| 16 |
TANG J, ZHANG J, YAO L M, et al. ArnetMiner: extraction and mining of academic social networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas: SIGKDD, 2008: 990–998.
|
| 17 |
CHANG S Y, HAN W, TANG J L, et al. Heterogeneous network embedding via deep architectures [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 119–128.
|
| 18 |
JI M, HAN J W, DANILEVSKY M. Ranking-based classification of heterogeneous information networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego: ACM, 2011: 1298–1306.
|
| 19 |
DONG Y, CHAWLA N V, SWAMI A. Metapath2vec: Scalable representation learning for heterogeneous networks [C] // Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Nova Scotia: ACM, 2017: 135–144.
|
| 20 |
PEROZZI B, ALRFOU R, SKIENA S. DeepWalk: online learning of social representations [C]// ACM Sigkdd International Conference on Knowledge Discovery & Data Mining. New York: SIGKDD, 2014: 701-710.
|
| 21 |
GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks [C] // ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: SIGKDD, 2016: 855–864.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|