

随着电子商务的快速发展和移动终端的普及,越来越多的人倾向于在网上购买商品;这种购物方式因具有方便、快捷、灵活等优势而被大家所喜爱,网上购物已然成为人们日常生活中购买商品的主要方式之一. 其中,服装商品在电子商务市场中占有较高比重,销售额呈逐年增长趋势[1]. 当前,用户主要通过电子商务平台的文字检索引擎来对服装进行检索. 这种服装检索方式首先需要卖家对服装进行人工拍照分类,上传至电商平台后台管理系统,然后用户在输入框中输入与服装有关的文字,最后系统返回与之匹配的服装列表. 服装分类是服装检索过程中的一个重要环节,完成服装拍照后对图片进行分类,目的是方便服装管理和缩小检索范围. 服装图像分类是一项艰巨而富有挑战性的任务:在信息化时代,服装商品众多,服装图像的数量庞大,增长速度非常快,通过人眼分辨数量如此庞大的服装图像,速度较慢、效率低,而且用眼疲劳会导致图像被错误分类的可能性变高,人工分类存在主观性误差.
为了解决服装图像人工分类的弊端,研究人员探索了基于图像内容的服装分类方法,并取得了一定的研究成果. 基于图像内容的方法主要利用图像处理技术提取图像特征用于描述服装,常用的图像特征包括局部二值模式(local binary pattern,LBP)[2]、尺度不变特征变换(scale invariant feature transform,SIFT)[3]、方向梯度直方图(histogram of oriented gradient,HOG)[4]等. Bossard等[5]通过提取融合HOG、LBP等特征,将融合特征输入至支持向量机(SVM)、随机森林、迁移森林等分类器进行分类,得出的分类准确率分别为35.05%、38.29%和41.36%. Huo等[6]提出了一种基于SIFT、HOG和颜色特征的民族服装分类方法,平均分类准确率为87.6%. Surakarin等[7]提出了一种基于加速鲁棒特征和纹理特征的服装款式分类方法,利用LBP纹理特征的同时融合加速鲁棒特征,以增强抗干扰能力,平均分类准确率为64.29%. 吴苗苗等[8]提出了一种基于部件检测与HOG、LBP、颜色直方图等底层特征的服装图像分类方法. 服装图像分类的难点在于分类类别属于细粒度,区分难度大,且图像存在较多噪声,如形变、光照变化、尺度缩放等,上述服装图像分类方法的准确率普遍较低,分类效果较差,且依赖特征设计人员的经验,有时还需要额外的人体检测算法.
近年来,深度学习的卷积神经网络在图像处理领域取得了广泛关注,其无需人工设计特征,在诸多领域里超越了基于图像内容的传统方法;众多基于卷积神经网络的服装分类方法应运而生. Liu等[9]提出了一种基于全局卷积特征和局部关键点特征的服装分类方法,该方法通过加入局部信息来提高分类效果. Dong等[10]提出了一种基于VGG-Net模型和空间池化金字塔(spatial pyramid pooling,SPP)的服装分类方法,该方法加入了池化金字塔,解决了服装图像输入尺度需要固定的问题. 包青平等[11]提出了一种基于度量学习的服装分类方法,该网络结构与AlexNet类似,并在训练模型时加入了三元组损失函数. 张振焕等[12]提出了一种基于残差网络的服装分类方法,该方法采用残差网络作为基础网络,取得了不错的效果. 厉智等[13]提出了一种基于卷积神经网络的服装图像分类检索方法,该研究对传统图像方法和卷积神经网络方法进行实验,验证了通常情况下卷积神经网络的分类效果更好. 上述研究针对服装图像分类,从多个方向进行了改进,如融合关键点信息、修改损失函数等,但特征信息丰富度低、尺度单一的问题依然存在.
本文针对服装图像分类特征尺度单一、信息丰富度低以及分类效果一般的问题,进行3个方面的改进:1)选择较新颖且分类准确率高的卷积神经网络作为基础模型;2)在模型中嵌入注意力机制模块来增强有用特征图,减弱无用特征图;3)提出一种多尺度深度可分离卷积以增强模型提取特征的能力,进一步提高分类效果.
1. 多尺度SE-Xinception服装图像分类
卷积神经网络(CNN)是一种目前非常常见的深度学习网络,主要被应用于图像分类、目标识别和图像分割等领域,其原理源于生物视觉机制.生物识别物体的过程是大脑对视觉信息一步步抽象分析的过程. 例如,识别一只猫的过程如下:首先大脑通过视觉获得边缘、曲线、边界等信息;然后对这些信息进行拼接、抽象,得到猫的整体形状;再对整体信息进一步抽象;最后识别为猫. 卷积神经网络用于模拟大脑视觉对图像信息的分层抽象过程,通过对图像像素数值进行一系列线性或非线性的映射来表示抽象过程,以像素值的矩阵表示图像特征,因此,映射深度越深的图像特征越抽象. 卷积神经网络的最基本架构由卷积层、池化层、全连接层组成. 2012年,Krizhevsky等[14]提出的AlexNet网络模型在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)图像分类比赛中取得第一名,错误率比使用传统图像分类算法的第二名低约10%. 这是卷积神经网络首次展示其在图像分类上的惊人表现,AlexNet网络模型创新性地采用ReLU激活函数,加快了模型的收敛速度. 2015年,Simonyan等[15]提出了使用较小
1.1. Xception模型简介
本研究分类模型的框架基于Xception模型构建,如图1所示,该框架由3个主要部分组成,分别是输入层、中层以及输出层.
图 1
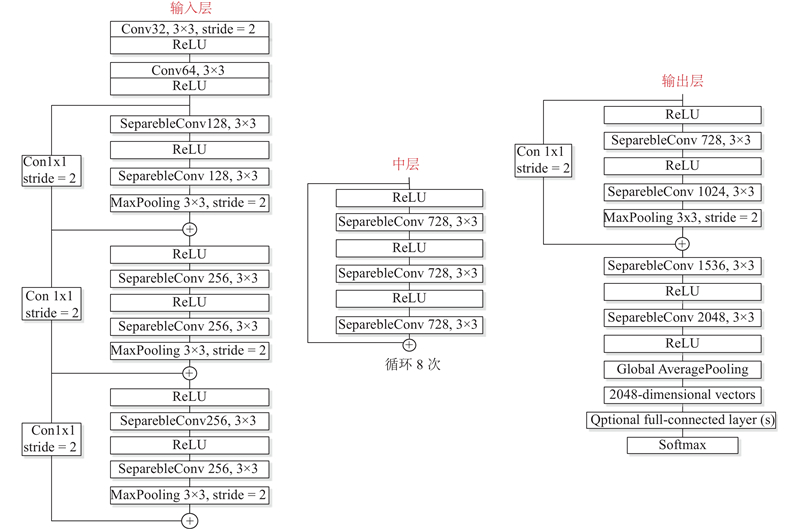
图 1 Xception模型的主要网络模块示意图
Fig.1 Diagram of main network module of Xception model
通常标准卷积操作将特征图的空间相关性和通道间相关性一并处理,使下一层特征图融合····空间信息和通道信息. 深度可分离卷积则将空间和通道信息处理过程完全分开,其结构如图2所示. 1)Depthwise卷积将每个输入特征通道单独卷积,假设输入特征图数量为a,卷积核大小为
图 2
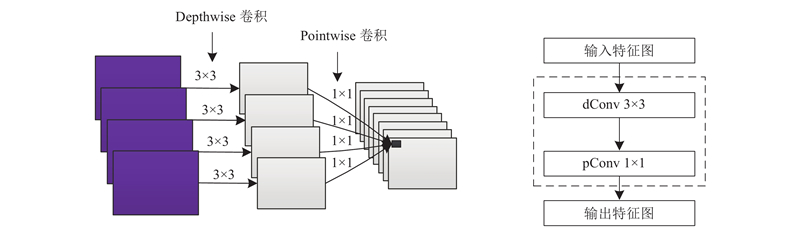
Xception模型在InceptionV3的基础上进行改进,其深度可分离卷积可以在保留较高准确率的情况下减少大量的模型参数和计算量. 虽然深度可分离卷积减少了参数量,但是Xception模型的总参数量与InceptionV3相差不大,主要原因为Xception模型旨在提高分类效果,在网络其他位置增加了参数量. Xception模型与常用模型在ImageNet数据集上的分类准确率结果[18]如下:VGG-16、ResNet-152、InceptionV3以及Xception的准确率分别为71.5%、77.0%、78.2%、79.0%.
1.2. SE-Net模型简介
SE-Net(Squeeze-and-Excitation Networks)模型由Momenta公司研发团队(WMW)的高级研发工程师Hu等[19]首次提出,该网络获得了2017年ILSVRC挑战赛Image Classification任务的冠军. SE-Net模型并不是一个全新、完整的CNN网络模型,而是一种子结构,可嵌入至其他网络模型中.
SE-Net模型的结构流程如图3所示,主要包含3个重要的步骤,分别是Squeeze(挤压)、Excitation(激励)以及Reweight(重标定). 假定某个卷积后的特征图大小为
图 3
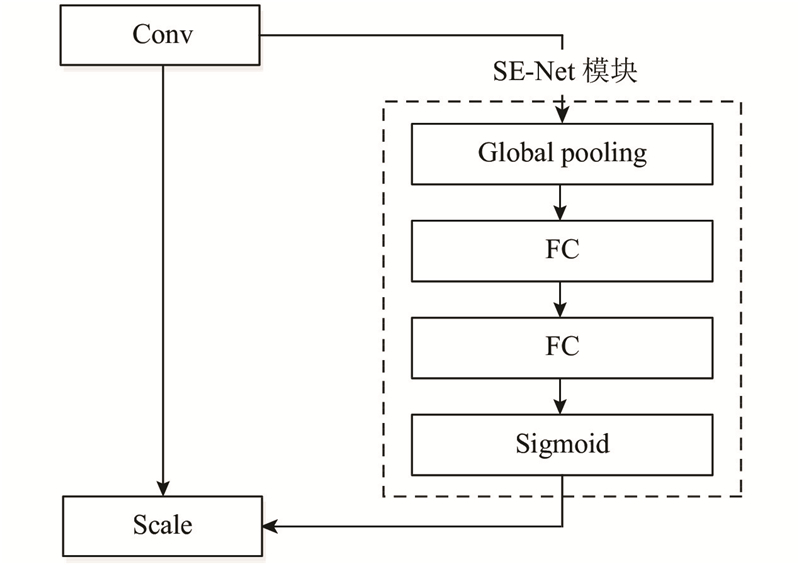
1)Squeeze特征压缩. 将c个输入二维特征图经过Global pooling处理转化为实数,得到包含c个实数的一维特征向量,Squeeze计算公式如下:
式中:
2)Excitation特征激励. 首先经过上阶段处理后得到具有c个实数的一维特征向量;然后连接2个全连接层和一个Relu层学习权重参数:将第一个全连接层的输出进行一定比例的缩放,将第二个全连接层的输出大小设置为原通道数;最后连接Sigmoid函数生成通道权重. Excitation计算公式如下:
式中:
3)Reweight特征重标定. 将Excitation输出看作是经过自主学习后的特征权重,将特征权重与原特征图逐通道相乘加权,完成整个特征重标定过程,Reweight公式如下:
式中:
1.3. 多尺度深度分离卷积
为了进一步提升Xception模型的分类精度,对深度可分离卷积进行改进工作,提出一种多尺度深度可分离卷积. 原深度可分离卷积的Depthwise卷积通常使用
多尺度深度可分离卷积的具体过程如图4所示,分为3个部分.
图 4
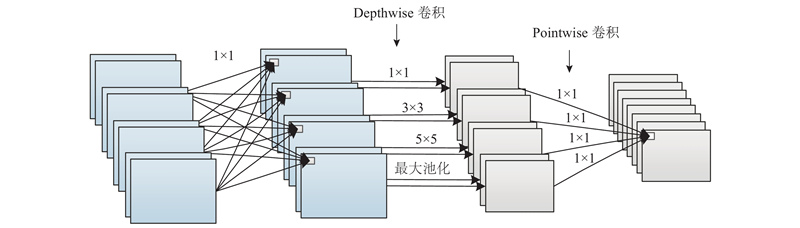
图 4 多尺度深度可分离卷积的结构图
Fig.4 Architecture of multi-scale depth separable convolution
1)特征降维. 利用
2)多尺度的Dethwise卷积. 将上阶段获得的4种数量的特征图进行Depthwise卷积,对应的卷积核大小分别为
式中:
3)Pointwise卷积. 此部分与原深度可分离卷积相同,即将多尺度特征通过
式中:
与深度分离卷积相比,所提出的多尺度深度分离卷积主要在最前面增加了一个降维压缩卷积,并将Dethwise卷积的单一卷积核修改为多尺度卷积核,因此增加了部分的参数量和计算量.
1.4. 多尺度SE-Xception模型
多尺度SE-Xception模型结构与Xception模型大体上一致,整体结构如表1所示. 首先,保持前2层标准卷积不变;然后,将Conv_3 ~ Conv_9层中所有的深度分离卷积替换为多尺度深度分离卷积. 同时,在Conv_8和Conv_9层的Relu与多尺度分离卷积之间嵌入SE-Net模块;最后,保留原全局均值池化层GAP_10与全连接层FC_11.
表 1 多尺度SE-Xception模型的整体框架
Tab.1
| 层级序号 | 残差链接 | 循环 | 卷积操作 | 输出尺寸 |
| Conv_1 | − | − | Conv 32,3×3,stride = 2 | 111×111×32 |
| Conv_2 | − | − | Conv 64,3×3 | 109×109×64 |
| Conv_3 | Conv 1×1,stride = 2 | − | 多尺度深度可分离卷积 128 多尺度深度可分离卷积 128 最大池化 3×3,stride = 2,padding=1 | 55×55×128 |
| Conv_4 | Conv 1×1,stride = 2 | − | 多尺度深度可分离卷积 256 多尺度深度可分离卷积 256 最大池化 3×3,stride = 2,padding=1 | 28×28×256 |
| Conv_5 | Conv 1×1,stride = 2 | − | 多尺度深度可分离卷积 728 多尺度深度可分离卷积 728 最大池化 3×3,stride = 2,padding=1 | 14×14×728 |
| Conv_6_x | 直连 | ×8 | 多尺度深度可分离卷积 728 多尺度深度可分离卷积 728 多尺度深度可分离卷积 728 | 14×14×728 |
| Conv_7 | Conv 1×1,stride = 2 | − | 多尺度深度可分离卷积 728 多尺度深度可分离卷积 1024 最大池化 3×3,stride = 2,padding=1 | 7×7×1 024 |
| Conv_8 | − | − | 多尺度深度可分离卷积 1536 SE-Net模块 | 7×7×1 024 |
| Conv_9 | − | − | 多尺度深度可分离卷积 2048 SE-Net模块 | 7×7×2 048 |
| GAP_10 | − | − | 全局均值池化 | 1×1×2 048 |
| FC_11 | − | − | 全连接层 | 1×1×7 |
2. 实验及结果分析
2.1. 实验数据集
本实验使用2种场景复杂程度不同的公开服装数据集,分别是ACS与DeepFashion数据集. ACS数据集由文献[5]首次公开,主要用于服装图像分类领域,其中的图像主要来源于日常生活. DeepFashion数据集由香港中文大学提供,包含多个子集,适用于服装图像的分类、检索、关键点检测等,其中的图像主要来源于电商平台.
ACS数据集如图5(a)所示,服装所处场景复杂度较高,含有各种各样的环境(室内、室外),同时图像中含有较多的噪声、形变、遮挡以及光线变化等. 该数据集包含blouses、jacket、long dress、suit、T-shirt等15个服装类别,每种类别的服装图像数量差距较大,例如:Long dress含有12 622张,Polo shirt仅有976张,服装图像总数为89 484张,并已对大部分服装的位置区域进行了裁剪预处理. 本研究从ACS数据集的所有服装类别中选取7类作为实验类别,分别为coat、long dress、suit、sweater、T-shirt、uniform以及vest,共36 989张图像,每类随机选取500张作为测试集,剩余图像作为训练集. 7类服装均属于粗粒度类别,且图像数量相对均衡。调整实验类别的原因如下:1)数量不均衡会导致模型预测结果偏向数量较多的类别;2)本研究针对整幅服装图像进行分类,不宜进行细粒度划分,否则容易影响分类准确率.
图 5

图 5 ACS数据集与DeepFashion数据集示例图
Fig.5 Sample graph of ACS dataset and DeepFashion dataset
DeepFashion数据集如图5(b)所示,服装所处场景复杂度较低,背景多为纯色,服装出现形变和遮挡的情况较少,并且每件服装包含多个角度的图像,部分服装进行了服装位置的裁剪. 数据集总共包含80多万张服装图像. 本研究选取其中一个子集作为实验数据集. 同样为了避免类别数量不平衡和细粒度类别对模型的影响,本研究设置9个服装类别,共22 846张图像.
2.2. 实验准备
实验环境的相关设置如下:工作站操作系统为Windows 10,12 G显存Nvidia GeForce GTX 1080Ti显卡一块,CPU为Intel(R)Xeon(R)E5-2620 v4,python版本3.6.3,深度学习框架安装pytorch 1.0.0,TensorFlow版本为1.12.0. 为了方便实验模型可视化与实验对比,另外安装tensorboradX可视化工具.
实验使用GPU加快模型计算速度,减少训练时间,选择小批次带动量参数的随机梯度下降法(stochastic gradient descent,SGD)作为模型参数优化器(Optimizer),动量参数为0.9;损失函数采用交叉熵损失(Cross entropy loss);训练周期(Epoch)为50次;每批次(Batchsize)训练的图像数量为32张;学习率更新采用固定周期缩减策略,将初始学习率设置为0.01,当训练周期大于30时,学习率缩小为原来的1/10,即30个周期后的学习率为0.001;为了扩大数据集并增强模型泛化能力,在训练模型时,使用3种数据增强方法:1)统一调整图像尺寸为
2.3. 实验结果与分析
为了验证所提出的SE-Xception多尺度分离卷积模型的有效性,将此模型与常用于服装图像分类的CNN分类模型VGGNet、ResNet以及Xception作对比分析. 在ACS数据集上使每个模型从头开始训练参数,直至收敛,并且确保各个模型在相同条件下完成训练. 在模型训练过程中,训练集每迭代完成1个周期,对测试数据集进行1次测试,输出并记录分类准确率,以便直观地监控模型在迭代过程中的分类性能变化情况.
图 6
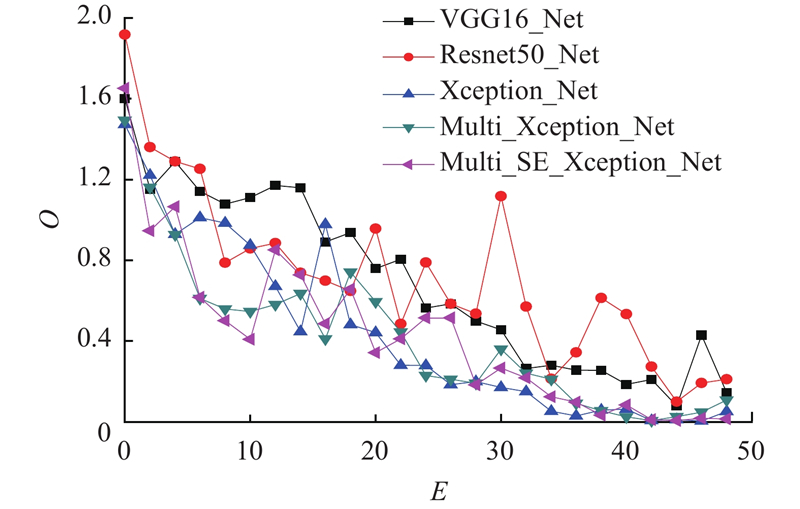
图 6 不同模型在ACS数据集上的损失变化曲线对比
Fig.6 Comparison of loss change curves of different models on ACS dataset
如图7所示为不同模型在ACS数据集上的准确率变化情况,R为分类准确率. 可知,在前30个迭代周期内,所有模型的准确率曲线波动幅度都比较大,整体呈上升趋势;当训练至30个周期后,学习率调整为0.001,各模型的准确率开始有了明显的提高,而且渐渐趋于稳定. 各曲线收敛后,从图中可以观察到2个比较明显的高度差. 第一个位于VGG模型曲线与Xception模型曲线之间,准确率相差约4.82%;第二个位于Xceotion模型曲线与多尺度SE-Xception模型曲线之间,准确率相差约3.69%.
图 7
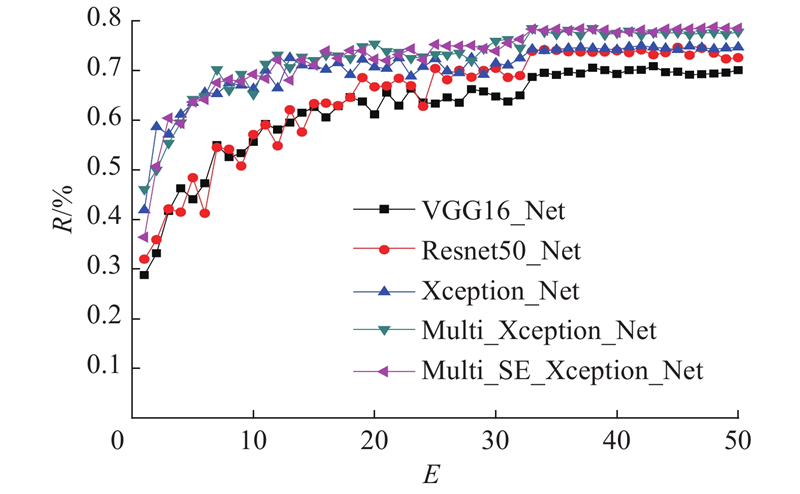
图 7 不同模型在ACS数据集上的准确率变化曲线对比
Fig.7 Comparison of accuracy rate change curves of different models on ACS datasets
第一个高度差产生的原因如下:1)Xception模型本身是一种比较新颖、优秀的深度卷积模型,结构中的深度可分离卷积有效地提高了分类准确率;2)Xception模型吸收了其他经典模型的优点,例如:采用
为了对比不同组合的卷积核对服装图像分类效果的影响,进行5组对比实验,分类结果如表2所示. 实验结果显示:1)分类准确率整体上随着卷积核尺度的增加呈上升趋势;2)当单个
表 2 不同组合的卷积核实验结果对比
Tab.2
| 卷积核组合 | R/% |
| | 74.65 |
| | 76.12 |
| | 75.70 |
| | 75.58 |
| | 78.34 |
为了进一步分析多尺度SE-Xception模型的场景适用性和应用范围,增加场景复杂度较低的Deepfashion服装数据集进行对比实验,结果如表3所示. 表中,RDF为对Deepfashion数据集分类准确率,RACS为对ACS数据集分类准确率,RDEC为从简单场景转向复杂场景所下降的准确率. 实验结果显示:1)在DeepFashion和ACS数据集上,多尺度SE-Xception模型的分类准确率分别高出Xception模型1.46%和3.69%;2)当服装场景复杂度从低转向高时,Xception模型和多尺度SE-Xception模型的准确率均出现不同程度的下降,分别下降了1.80%和4.03%. 实验结果证明:本文模型不论在简单场景或是在复杂场景中,都能够提高服装图像的分类准确率,具有普适性;本文模型的分类准确率更加稳定,能够在复杂场景下保持较高的准确率.
表 3 Xception模型与多尺度SE-Xception模型在不同数据集上的实验结果对比
Tab.3
| CNN模型 | RDF | RACS | RDEC |
| Xception_Net | 78.68 | 74.65 | 4.03 |
| Multi_SE_Xception_Net | 80.14 | 78.34 | 1.80 |
不同模型的分类准确率对比结果如表4所示. 实验结果显示:VGG-16模型在测试集上的分类准确率最低,平均准确率为69.82%;多尺度SE-Xception模型的分类准确率最高,平均准确率为78.34%. 可知,提出的多尺度SE-Xception服装图像分类模型是一种性能优良的网络模型.
表 4 不同模型在ACS数据集上的平均分类准确率对比
Tab.4
| CNN模型 | R/% |
| VGG16_Net | 69.82 |
| Resnet50_Net | 73.53 |
| Xception_Net | 74.65 |
| Multi_Xception_Net | 77.58 |
| Multi_SE_Xception_Net | 78.34 |
3. 结 语
本文提出了一种多尺度SE-Xception服装图像分类算法. 在ACS数据集上的实验结果表明,相比于其他常用模型,多尺度SE-Xception模型的分类效果最好,损失值的下降速度和收敛速度相对较快;在模型中嵌入SE-Net能够提升一定的准确率,使模型更加稳定. 实验结果表明,卷积核尺度数量与分类准确率正相关,多尺度深度可分离卷积的效果优于单尺度. 关于不同场景复杂度的实验结果表明,多尺度SE-Xception模型在复杂度较高的场景下能够保持较高的分类准确率,具有良好的鲁棒性.所提模型的结构相比于Xception模型更加复杂,增加了一定的参数量和计算量,如何减少参数量和计算量有待进一步研究.
参考文献
Distinctive image features from scale-invari-ant keypoints
[J].DOI:10.1023/B:VISI.0000029664.99615.94 [本文引用: 1]
款式特征描述符的服装图像细粒度分类方法
[J].DOI:10.3724/SP.J.1089.2019.17380 [本文引用: 1]
Fine-grained clothing image classification by style feature description
[J].DOI:10.3724/SP.J.1089.2019.17380 [本文引用: 1]
基于度量学习的服装图像分类和检索
[J].DOI:10.3969/j.issn.1000-386x.2017.04.043 [本文引用: 1]
Clothing image classification and retrieval based on metric learning
[J].DOI:10.3969/j.issn.1000-386x.2017.04.043 [本文引用: 1]
基于残差的优化卷积神经网络服装分类算法
[J].DOI:10.3969/j.issn.1007-130X.2018.02.023 [本文引用: 1]
An optimized clothing classification algorithm based on residual convolutional neural network
[J].DOI:10.3969/j.issn.1007-130X.2018.02.023 [本文引用: 1]
基于深度卷积神经网络的服装图像分类检索算法
[J].DOI:10.3969/j.issn.1000-3428.2016.11.053 [本文引用: 1]
Clothing image classification and retrieval algorithm based on deep convolutional neural network
[J].DOI:10.3969/j.issn.1000-3428.2016.11.053 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}