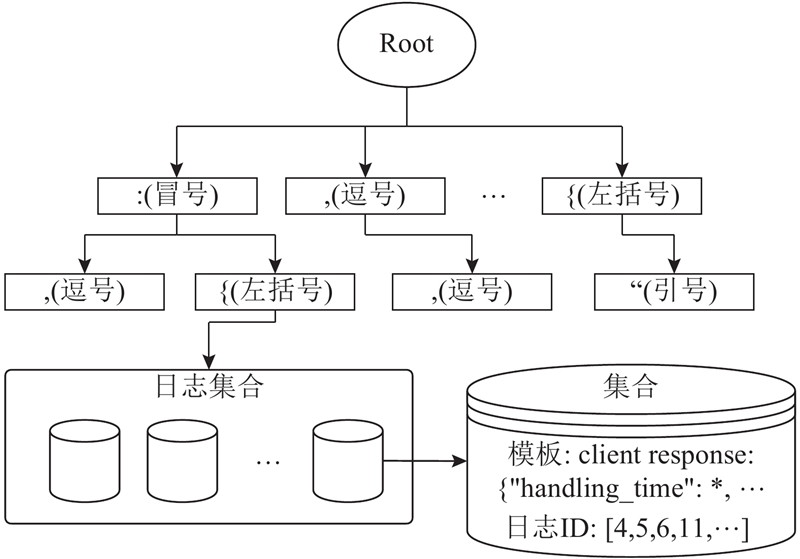
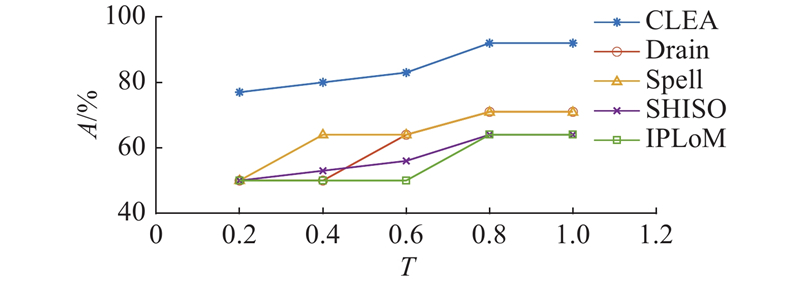
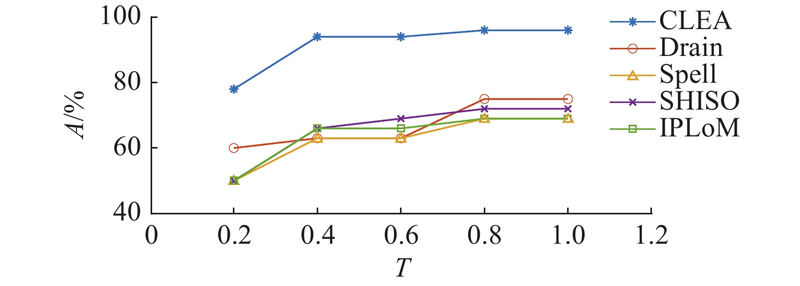
| 计算机技术 |
|


|
|
|
| 复合型日志的模板提取方法 |
吴其( ),黄小红,马严(),丛群 ),黄小红,马严(),丛群 |
1. 北京邮电大学 网络技术研究院 信息网络中心,北京 100876
2. 北京网瑞达科技有限公司,北京 100876 |
|
| A template extraction method for composite log |
| Qi WU(),Xiao-hong HUANG,Yan MA(),Qun CONG |
1. Information Network Center, Institute of Network Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China
2. Beijing Wrdtech Co. Ltd, Beijing 100876, China |
引用本文:
吴其,黄小红,马严,丛群. 复合型日志的模板提取方法[J]. 浙江大学学报(工学版), 2020, 54(8): 1557-1561.
Qi WU,Xiao-hong HUANG,Yan MA,Qun CONG. A template extraction method for composite log. Journal of ZheJiang University (Engineering Science), 2020, 54(8): 1557-1561.
链接本文:
http://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2020.08.014
或
http://www.zjujournals.com/eng/CN/Y2020/V54/I8/1557
|
| 1 |
崔元, 张琢 基于大规模网络日志的模板提取研究[J]. 计算机科学, 2017, (Suppl.2): 458- 462
CUI Yuan, ZHANG Zhuo Research on template extraction based on large-scale network log[J]. Computer Science, 2017, (Suppl.2): 458- 462
|
| 2 |
范惊. 高精度的程序日志解析技术研究[D]. 上海: 上海交通大学, 2013.
FAN Jing. Research on high precision program log analysis technology [D]. Shanghai: Shanghai Jiaotong University, 2013.
|
| 3 |
张晓箐. 基于海量日志消息的软件系统异常检测技术研究与实现[D]. 西安: 西安电子科技大学, 2015.
ZHANG Xiao-jing. Research and implementation of software system anomaly detection technology based on massive log messages [D]. Xi’an: Xidian University, 2015.
|
| 4 |
KOBAYASHI S, FUKUDA K, ESAKI H. Towards an NLP-based log template generation algorithm for system log analysis [C]// Proceedings of the 9th International Conference on Future Internet Technologies. Tokyo: ACM, 2014: 11.
|
| 5 |
MIZUTANI M. Incremental mining of system log format [C]// Services Computing (SCC), 2013 IEEE International Conference on Santa Clara, CA, USA. Santa Clara: IEEE, 2013: 595-602.
|
| 6 |
SHIMA K. Length matters: clustering system log messages using length of words [J/OL]. [2019-09-20]. https://arxiv.org/abs/1611.03213.
|
| 7 |
DU M, LI F. Spell: streaming parsing of system event logs [C]// Data Mining (ICDM), 2016 IEEE 16th International Conference on Barcelona, Spain. Barcelona: IEEE, 2016: 859-864.
|
| 8 |
HE P, ZHU J, ZHENG Z, et al. Drain: an online log parsing approach with fixed depth tree [C]// Web Services (ICWS), 2017 IEEE International Conference on Honolulu, HI, USA.Honolulu: IEEE, 2017: 33-40.
|
| 9 |
MESSAOUDI S, PANICHELLA A, BIANCULLI D, et al. A search-based approach for accurate identification of log message formats [C]// Proceedings of the 26th IEEE/ACM International Conference on Program Comprehension (ICPC’18). Gothenburg: ACM, 2018.
|
| 10 |
ZHANG S, MENG W, BU J, et al. Syslog processing for switch failure diagnosis and prediction in datacenter networks [C]// Quality of Service (IWQoS), 2017 IEEE/ACM 25th International Symposium on Vilanovai la Geltru, Spain. Vilanovai la Geltru: IEEE, 2017: 1-10.
|
| 11 |
POGGI N, MUTHUSAMY V, CARRERA D, et al. Business process mining from e-commerce web logs [C]// Business Process Management. Springer, Berlin, Heidelberg∶LNCS, 2013: 65-80.
|
| 12 |
LOU J G, FU Q, YANG S, et al. Mining program workflow from interleaved traces [C]// Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington DC: ACM, 2010: 613-622.
|
| 13 |
MAKANJU A, ZINCIR-HEYWOOD A N, MILIOS E E A lightweight algorithm for message type extraction in system application logs[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 24 (11): 1921- 1936
|
| 14 |
TANG L, LI T. LogTree: a framework for generating system events from raw textual logs [C]// 2010 IEEE International Conference on Data Mining. Sydney: IEEE, 2010: 491-500.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|