

随着互联网规模的不断发展,网络空间中产生的日志也日益增加. 网络上的日志产生自不同的软件,各个软件使用不同的代码,由不同的开发人员编写. 相同种类日志的格式可能大相径庭,但相同种类日志包含的内容大部分具有相似的特征[1],如常见的网络地址转换(network address translation,NAT)日志均含源IP、源端口、目的IP、目的端口等固定字段. 通常人们会通过书写正则表达式的方式对日志信息进行简单格式化,但依赖于手动书写的正则表达式极大限制了系统可以处理的日志类型[2-3],由此催生出许多自动生成日志模板的方法,这些方法可以从大量日志中总结出普遍的日志模板. 通过生成日志模板,可以较轻松地对海量日志数据进行数据处理或信息提取.
目前针对自动提取日志模板的研究较多,主要是通过设计各类算法,对已获取到的日志进行分类提取. Kobayashi等[4]提出基于自然语言处理(natural language processing,NLP)的日志模板生成算法. 算法将大量数据进行解析生成词性模板,通过词性分析将符合指定条件的词语作为模板词. Mizutani[5]提出基于N-Gram的模板生成算法,虽然也须对一些数据进行预先处理,但它可以对新写入的数据进行实时分析,然后动态调整原本已经生成的模板库. Shima[6]将单词的长度作为特征,来区别模板词和变量词,认为若模板词词语相同,长度也相同,直接对比长度向量的相似度即可,这样的操作能加快处理速度,但是却显著降低提取精度. Spell算法是Du等[7]提出的基于最长公共子序列(longest common subsequence,LCS)的日志模板提取方法,处理速度较快,能处理实时日志. Drain算法是He等[8]提出的基于固定深度索引树的日志模板提取算法,通过构建定深树加快日志的索引速度,使用欧几里得距离对日志进行分类,实现快速且准确的日志模板提取. MoLFI算法[9]基于NSGA-II遗传算法来提取日志模板,处理速度相较于前面2种算法稍慢,只能用作非实时算法,对已接收到的固定量的日志进行处理.
以上算法在理论上已经可以高速且高精度地提取日志模板,但它们无法处理复合型日志. 复合型日志是日志中包含Json或Key-Value类型数据的日志. 复合型日志的字段位置可能改变,此时所有的模板提取算法都会将这个Json字符串提取成一个变量词,导致其中的真正变量词糅杂在一起,无法进行进一步的分析. 复合型日志里面包含日志的关键数据,解析错误将导致后续操作的错误率更大.
针对上述问题,本研究提出针对复合型日志的自动模板提取算法,命名为CLEA(composite-log extraction algorithm),该方法改进简单共有词算法,向算法中引入差异度以增强算法对模板中不同词语的敏感度,通过对日志中的特殊符号(包括空格)进行统计,将日志按统计结果分类. 使用Drain的提取算法对每类日志进行模板提取,集合所有类别的模板,使用改进的共有词算法求得所有模板相互之间的相似度,设计BMerge算法对相似的模板进行融合,最终提取出模板.
1. 算法设计
改进的简单共有词主要用于计算2个模板之间的相似度;建立符号索引用于将日志进行预分类,减小处理难度;模板的聚合是从各个日志集群中聚合出最初的模板;模板的提取是将这些聚合出的模板进行去重或合并操作,得到最终的结果.
1.1. 改进简单共有词
简单共有词是文本相似度计算方法,通过计算2条日志共有词的总字数除以最长文档字符数来评估他们的相似度. 简单共有词方法基于共有词的个数来计算相似度,实际上是统计词频的算法. 相较于其他的文本相似度算法,比如编辑距离算法或余弦相似度算法,简单共有词的优点主要如下∶ 1)是基于词频的算法,在处理复合型日志方面没有障碍; 2)没有较复杂的计算过程,可以有效提升速度[10-12]. 不过,按照原本的简单共有词算法计算,相似度会过度接近,有时2个模板之间相同的部分远远大于不同的部分,因此须放大差异处的权重,以保证算法对模板微小差异的敏感性. 设2个模板的词语集合分别为A、B,它们之间的相同的词语为集合X:
原有的相似度算法为
式(2)只计算2个模板的相似度,若一个模板的单词是另外一个模板的单词的子集,则式(2)无法区分这样的2个集合. 引入带系数的差异度可以解决这个问题:
式中:Snew 为新相似度;a为动态系数,取值范围为(0, 1.0).
1.2. 建立符号索引
为了降低日志的密度、加快日志的搜索速度和简化日志处理,对日志进行索引. 将日志的符号结构提取出来,如图1所示,对每条日志进行归类.
图 1
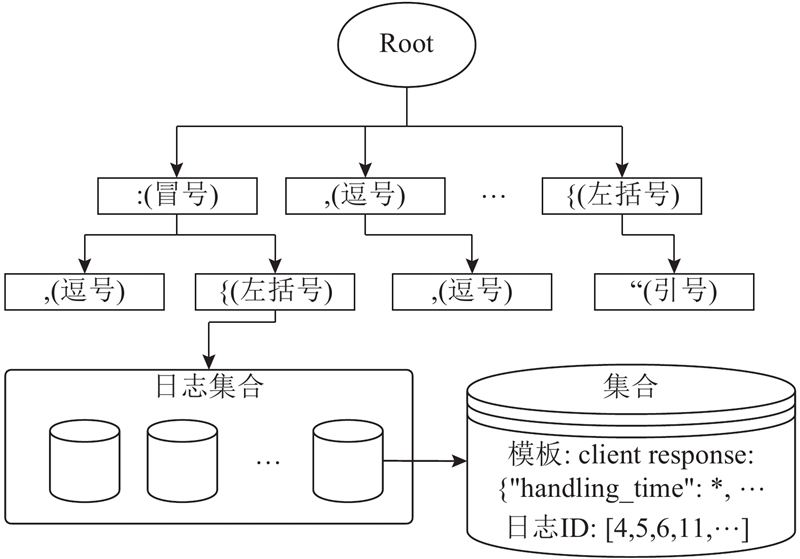
图 1 CLEA算法日志分类树结构示例
Fig.1 Log classification tree structure example of CLEA algorithm
在日志进入到系统之后,须经过如下处理:1)删除所有文字信息,仅保留标点架构;2)若该条语句没有标点,则分入“*”集群(图中未标出),否则设当前为Root集群;3)按照每条日志各自的标点查找对应标点的子集群,设置当前集群为该子集群,并删除第1个标点;4)若还有剩余标点,则重复步骤3)继续寻找;5)直到没有剩余的标点或达到索引树的最大高度位置,停止查找;6)将日志归入该集群. 索引树的最大高度应随所处理日志的类型进行相应更改,以得到最佳的算法表现.
1.3. 模板的聚合
通过日志分类树的分类,得到粗略分类的日志,然后使用Drain的聚合算法[8]对日志进行处理. 从Drain算法中将定深树(fix-depth tree,FDT)除去,使用算法的主体来处理接收到的日志.
为了能够区分复合字段之间的微小差距,可以使用2种方式:1)提高相似度的阈值,减小被判定为相同模板的概率;2)通过增加不同点的权重来增加模板之间的相似度差距.
本研究选用增加权重的方式来解决这个问题,相似度公式如下:
式中:
在得到相似度后,将相近相似度的日志归入同一集群(在线上运行时则归入已有集群或新建集群). 若该集群为新建集群,对其进行模板提取,在同一集群中的同一位置如果均为相同的词语,则作为模板词,若为不同的词语则作为变量词. 最终得到许多被细划分的日志集群.
1.4. 模板的提取
在得到划分好的日志模板集群后,须从2个近似的模板中提取出其中的Json或Key-Value字段,并得到其中的子模板信息.
将每个集群最终生成的模板拆解成单词,以词为单位,计算模板
在求得概率后,使用改进过的简单共有词算法对集群中的模板两两计算相似度
BMerge算法如下.
输入:日志模板
输出:无
1. function BMerge (
2. for all
3. if
4. RemoveFromBoth(
5. else if
6. RemoveFromLong(
7. end if
8. end for
9. end function
2. 实 验
2.1. 实验环境
利用实验验证本研究所提出的日志模板提取方法,主机配置如表1所示. 实验日志来源于北京邮电大学日志系统所收集的复合型日志,类型涵盖DNS、DHCP、Dataflow等,日志总时间跨度约为1 d,日志总体积约为22 G. 另有部分日志来源于华为的交换机日志,也均为复合型日志.
表 1 验证CLEA日志模板提取算法的实验环境
Tab.1
| 项目 | 配置 |
| OS | CentOS release 6.8 (Final) |
| CPU | Intel (R) Xeon(R) CPU 5110 |
| 内存 | 8 G(4 × 2 G DDR2 667 MHz) |
| 固态硬盘 | Samsung 850 EVO SATA III 120 GB |
| 机械硬盘 | Seagate 2 TB SATA3 64 MB Cache |
| 网卡 | Intel e1000e 1000 Mbps Full Duplex |
2.2. 符号集群划分
Drain算法采用提前划分日志集群的算法,即按照单词和单条日志的总长度来划分. 本研究所提算法,按照符号来划分。对比2种方法的准确度. 假设被正确划分到同一个集群的日志个数为RN,总的日志条数为TN,则准确度的定义如下:
对所有日志进行处理和统计,结果如表2所示. 可以看出,与Drain算法相比,CLEA算法已经有了一定的提升. 总的看来,在预处理阶段,CLEA算法处理复合型日志的准确率比Drain算法高约10%. 本研究设置的CLEA的树最大深度为20,Drain算法FDT的最大深度为3,计算结果均为总数据的平均值.
表 2 CLEA与Drain算法对不同日志划分的准确率
Tab.2
| 算法 | A/% | |||
| DNS | DHCP | Dataflow | Huawei | |
| CLEA | 34 | 45 | 40 | 55 |
| Drain | 27 | 35 | 31 | 40 |
2.3. 模板提取
在线上运行时日志是呈流的形式不断产生的,因此除了算法处理的准确率之外,算法的处理效率也十分重要,处理速度慢,会导致日志的堆积[13]. 本研究统计不同算法对相同数量的日志集进行处理所需的时间t,结果如表3所示 .可以看出,IPLoM是离线算法,因此处理速度相较于在线算法会有所欠缺. 在在线处理算法中,SHISO在处理速度上稍慢,因为SHISO算法计算单词的相似度,算法复杂度急剧增长. Spell算法基于最长公共子序列计算相似度,优化对部分模板的处理准确度,但是也增加了对日志的诸多重复处理. CLEA具有最好的表现,一方面是因为使用树状图将日志进行集群划分,使巨大的数据集可以被划分成小部分处理,另一方面是因为算法直接对单词进行对比,实时生成模板,减少不必要的重复计算.
表 3 多种日志模板提取算法对不同日志的处理时间
Tab.3
| 算法 | t/s | |||
| DNS | DHCP | Dataflow | Huawei | |
| CLEA | 31.81 | 45.43 | 2.55 | 27.70 |
| IPLoM | 50.88 | 73.67 | 5.17 | 34.03 |
| SHISO | 1 957.14 | 2 879.23 | 75.10 | 1 292.95 |
| Spell | 236.44 | 311.58 | 23.49 | 94.64 |
| Drain | 35.17 | 51.01 | 3.01 | 29.78 |
图 2

图 2 多种日志模板提取算法对DNS日志解析的准确度
Fig.2 Accuracy of multiple log template extraction algorithms to DNS log
图 3
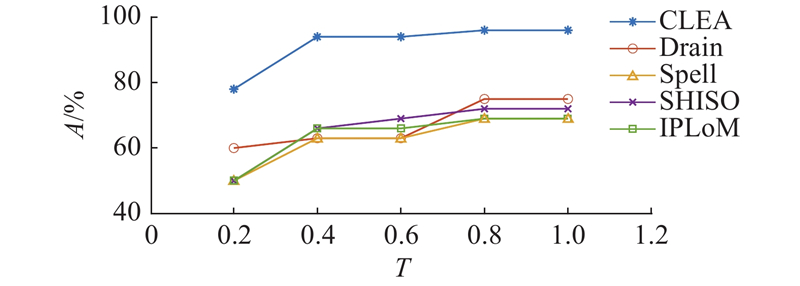
图 3 多种日志模板提取算法对华为交换机日志解析的准确度
Fig.3 Accuracy of multiple log template extraction algorithms to Huawei switch log
表 4 多种日志模板算法对不同日志的最终准确率
Tab.4
| 算法 | A/% | |||
| DNS | DHCP | Dataflow | Huawei | |
| CLEA | 92 | 100 | 88 | 96 |
| IPLoM | 64 | 80 | 18 | 69 |
| SHISO | 64 | 80 | 25 | 72 |
| Spell | 71 | 90 | 11 | 69 |
| Drain | 71 | 80 | 18 | 75 |
3. 结 语
针对目前存在的日志模板提取算法无法准确处理复合型日志的问题,提出针对复合型日志的自动模板提取算法. 该方法利用复合型日志符号相似和词频差别的特征,结合BMerge合并算法加快处理速度,对日志模板进行多次提取合并,实现对复合型日志的正确处理,并提取出复合型日志的普遍结构,以解析其中详细的字段信息. 经实验验证,该方法具有较高的效率和准确率,能快速准确地对复合型日志进行处理. 目前可以利用CLEA算法对复合型日志进行有效处理,但CLEA算法在处理普通日志时准确率相较于其他算法略低,未来还须针对算法处理普通日志的问题进行研究改进.
参考文献
基于大规模网络日志的模板提取研究
[J].
Research on template extraction based on large-scale network log
[J].
A lightweight algorithm for message type extraction in system application logs
[J].
Uilog: improving log-based fault diagnosis by log analysis
[J].DOI:10.1007/s11390-016-1678-7 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}