

1. 相关工作
近年来,研究人员对生产调度和机器维护的问题进行了大量研究. 单机调度问题的研究在生产作业调度中较为基础,有助于揭示更深层次的问题. 在相关领域,Hajej等[3-4]根据生产计划制定定期预防性维护策略以应对机器的劣化效应影响. Zhang等[5]将机器维护分为事后维护、更换和预防性维护,其中预防性也是学者更多关注的方面. Sun等[6]研究了考虑恒定劣化速率和维护的单机调度问题并证明了问题是多项式时间可解的. 对调度与维护一体化的问题模型而言,使用以遗传算法为基础的启发式算法求解的应用研究比较广泛[7-8],也有学者侧重于这一集成模型本身[9-10]的分析. 在相关研究中,研究人员通过建立单机调度和基于劣化状态的多种维修决策模型[11],并应用基于遗传算法的智能优化方法求解这一联合决策. 局限性在于缺少对车间实时运行状态的模拟和仿真,且优化目标局限于最小化总完工时间,没有全面考虑生产过程中消耗的成本和其他约束. 对于此类NP难问题,当建模复杂度增加时,求解难度呈指数类型增长,深度强化学习方法(deep reinforcement learning, DRL)更加擅长处理高维复杂问题和求解精细控制的调度策略,但该方法对所提出的这类复杂问题的应用研究还比较少见.
基于文献研究综述的背景和现状,本研究的主要创新点如下:1)针对具有劣化效应和维护决策的单机问题提出三阶段机器状态模型. 机器在正常状态运行一定时间后开始劣化,继而进入故障状态. 2)建立数学模型,设计DRL环境及算法框架,以最小化总成本为优化目标并考虑多种约束. 3)探索和对比几种不同DRL算法对该集成调度问题的适用性和优化效果. 4)与集成预测性维护的优先调度策略进行对比,验证所提出的DRL模型和框架的有效性和优越性.
2. 问题描述和建模
2.1. 条件和假设
目前,在生产调度和维护集成问题的模型中,通常用机器运行时间表示劣化程度或将机器的劣化过程视为离散多阶段的,状态的转换遵循一定的概率分布[19-20]. 随着数字化生产技术的发展,机器运行状态的监测成为可能,本研究提出的三阶段单机器状态模型可以描述为:n个独立的作业被安排在一台机器上处理,机器在初始状态M0具有初始健康状态值h0,劣化效应发生点h1和失效点h2,用于分隔机器运行状态所处的阶段. 在加工过程中,机器状态值会随加工时间的增加而降低,当状态低于h1时劣化效应开始发生,作业在机器上的加工时间逐渐延长. 当机器状态下降到h2时,除非进行维护操作恢复状态,否则机器将持续处于不可用状态. 机器劣化效应过程如图1所示.
图 1
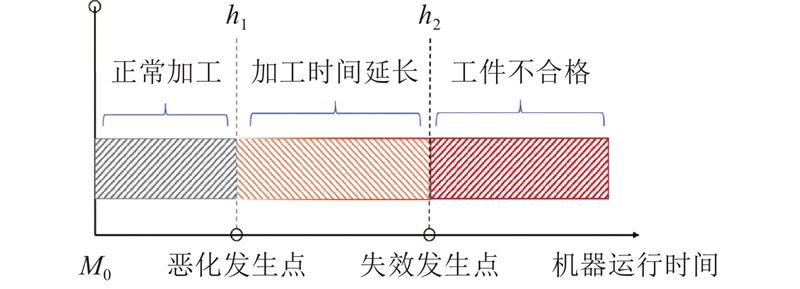
机器的维护操作策略分为小修(partial maintenance, PM)和大修(complete maintenance, CM)2种. 小修可以恢复一定的状态值,成本更低且花费时间更短,大修可以一次性恢复更多的机器状态,但维护成本更高,维护时间也更长. 在问题中须考虑合理分配作业在机器上的排列顺序,同时安排适时的维护决策,防止机器进入失效状态,并尽可能降低完工时的总成本. 该问题的基本假设总结如下:
1)机器同时只能处理一个作业,每个作业只处理一次,加工过程不能中断.
2)机器和作业在0时刻开始时均已准备就绪.
3)机器的初始健康值h0、劣化点h1和故障点h2是基于机器状态检测和产品质量分析所得并已知的,在每次调度开始时初始化.
4)机器进入劣化状态时加工时间延长,但不会发生故障. 进入故障状态后无法继续运行.
5)忽略机器的启停时间和作业更换时间.
2.2. 模型建立
该综合优化问题总目标是最小化生产成本,包括因交付延迟而造成的收益损失成本、机器加工的运行成本和机器的维护成本. 所考虑的针对作业集合
式中:n为作业总数,j表示作业在集合J中的索引,i表示作业Jj在调度序列中的索引,式(1)~(3)表示每个工件Jj必须安排在调度序列中的某一个位置,且序列中每个位置i只能同时有一个作业;xij为表示序列i位置是否有作业Jj被安排的0-1变量;mi为执行第i项作业前的维护决策变量. 状态转移过程如图2所示.
图 2

生产过程中的总优化目标期望是使生产过程中的各项成本之和达到最优或近优值,目标函数为
式中:DTi表示作业的延迟时间成本;PTi表示作业的加工时间成本;CPM、CCM为2种维护的成本;α为交付延迟的成本系数,β为机器运行的成本系数,控制交付延迟和设备运行成本的权重;N1和N2分别表示2种维护的操作总数.
目标函数的约束条件如下:
式中:Mi为机器当前健康状态,pi为当前作业预计加工时间,σ为劣化效应因子,si、ei、di分别为当前作业的开始、结束和交付时间,tPM、tCM表示2种维修的时间,mi为维修状态指示. 式(6)表示,当机器的健康状态值高于h1时,作业的实际处理时间与预计时间相同,当机器的状态低于h1后,作业的实际处理时间线性增加. 式(7)、(8)表示队列中作业的开始和结束时间,若不进行维护,队列中作业Ji在上一个作业Ji−1结束后开始,否则等待维护完成后开始. 通过式(9)计算作业Ji的延迟时间.
式中:MPi为机器完成作业消耗的健康值,RPM、RCM为修复量. 式(10)、(11)为机器状态更新方法,表示机器状态值随作业Ji加工时间相应减少,如进行作业Ji之前决策变量mi≠0,即须进行维护,机器状态将得到相应恢复. 式(12)约束机器健康值不低于故障点h2.
式中:N1、N2分别为2种维护的计数,δPM、δCM为作业Ji加工之前进行维护决策的0-1变量. 式(13)、(14)计算了维护计数. 根据以上约束,构建了考虑机器劣化效应的单机器任务调度和维护一体化决策求解的数学模型.
3. 算法设计描述
3.1. 方法选择
将调度决策与环境的交互过程描述为马尔可夫决策过程(Markovian decision process, MDP):
最优值
应用DRL方法的关键是训练智能体(Agent)与环境交互,使Agent以从环境中获得的观测值和奖励为指导做出最佳决策. Agent与环境的交互模式结构如图3所示.
图 3
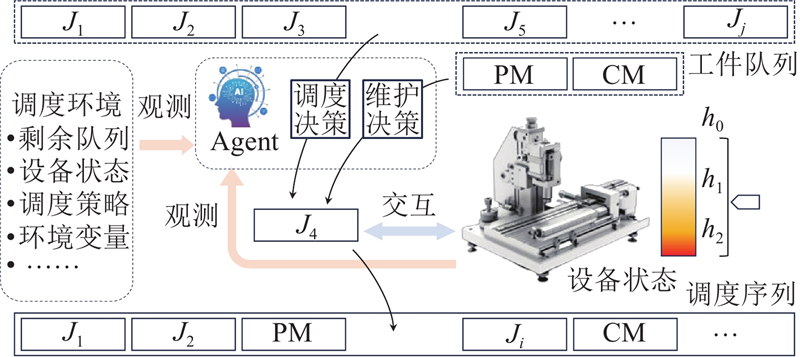
3.2. 状态和动作空间设计
状态空间在DRL中指示当前模型的状态,是Agent感知环境的窗口,设计时须充分考虑车间的各种动态特征,准确表达每个时刻系统的状态. 在建立的模拟车间生产调度系统的仿真模型中,仿真时间基于事件推进,在每一时刻t返回环境状态,为Agent下一动作决策提供信息. 在状态空间中:用1维浮点数表示仿真钟当前时刻t;用6维列表表示作业加工状态,包括已完成的任务数nC、剩余任务数nB、剩余任务集合B的总剩余加工时间
对观测空间进行归一化处理,将不同尺度的特征统一在[0, 1.0]区间内,避免某些大尺度变量主导学习过程,优化收敛速度和稳定性. 对具有明确上下限的变量使用Min-Max方法归一化,对时间相关无法明确上限的变量使用对数缩放的方法归一化. 处理后的状态空间可以表示为
在动作空间中引入优先级调度规则(PDR)启发Agent的任务调度动作,使7种适用的PDR调度动作与2种维护动作共同构成动作空间
表 1 动作空间描述
Tab.1
| 符号 | 动作 | 描述 | 数学形式 |
| a1 | SPT | 最短加工时间优先 | |
| a2 | LPT | 最长加工时间优先 | |
| a3 | EDD | 最早交付期优先 | |
| a4 | FCFS | 最早到达时间优先 | |
| a5 | MST | 最小松弛时间 | |
| a6 | CR | 最小临界比率 | |
| a7 | MDD | 修正交付时间优先 | |
| a8 | PM | 执行不完全维护 | |
| a9 | CM | 执行完全维护 |
3.3. 奖励函数设计
奖励函数设计须引导Agent评价动作的好坏,减少作业延迟和运行时间、避免过度维护或损坏、平衡长期与短期成本,实现成本最优化.
每次决策与环境交互产生的单步总成本为
式中:C为单步各项成本,α、β分别为拖期和加工成本系数. 单步成本包括任务延迟成本和机器运行成本,运行成本分为加工成本和维护成本. 完成任务的基础奖励为固定值1,促进Agent优先完成调度任务. 为了防止数值波动使计算出现偏向性,对奖励函数进行归一化处理:
式中:rt为单步决策从环境中获得的奖励值,当执行调度动作时rt是固定奖励减去作业加工成本和延迟成本惩罚之和,执行维护动作时rt是产生维护成本的惩罚;NScale为奖励缩放尺度,合理设置该值可将单步奖励控制在[0, 1.0].
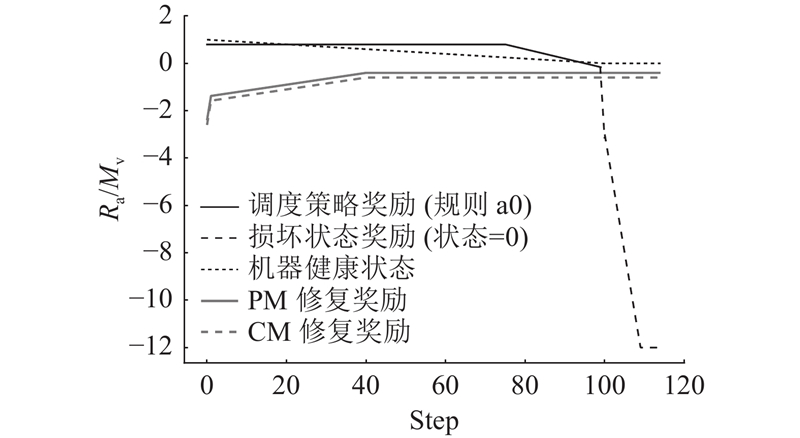
将机器健康状态大于h1时进行维护视为过度维护,机器状态低于阈值T而继续执行调度视为增加损坏风险,分别施加[0,−1.0]范围内的线性惩罚. 当过度维护超出边界条件时,给予较大的惩罚M1并随维修计数rc递增,当损坏没有及时进行修复时,给予较大的惩罚M2并随损坏计数bc递增. 以上边界惩罚可以表示为
以上边界惩罚将引导Agent做出与机器状态相关的合理决策,并阻止陷入错误的动作循环.
在所有任务完成后计算全局总成本并获得全局收益rglobal,鼓励Agent探索更有利于整体效益的方案:
单步奖励用于引导局部高效决策,全局奖励引导Agent关注全局收益,避免短视. 在该DRL模型中,奖励函数可以表示为
图 4
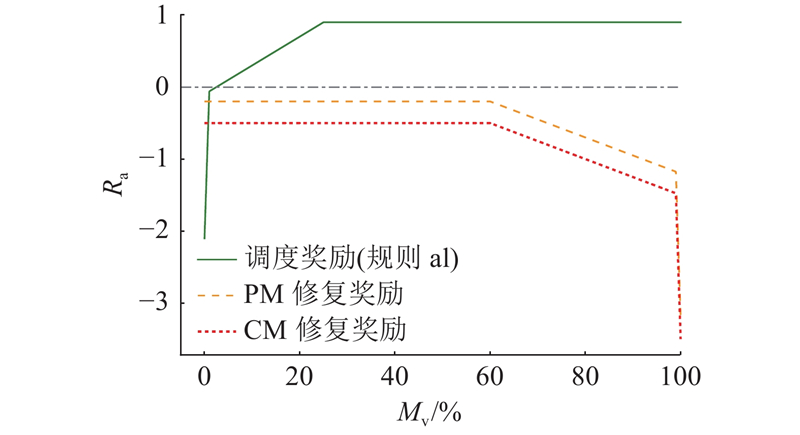
图 5
3.4. 算法结构和流程
由于问题模型的强离散属性,在DRL方法中选取了DQN、A2C和PPO这3种解决离散型车间调度问题的经典算法,用于评估所建立的DRL模型框架的适用性和运行效果,并分别讨论几种算法对所述模型的求解质量.
为了保证算法性能的平衡,在3种算法中均使用全连接层架构的神经网络(MLP),输入层节点数为观测空间维度11,隐藏层数为2,每层节点数为256,输出层节点数为动作空间维度9,神经网络的优化器使用Adam方法,激活函数使用ReLu方法. 如图6所示为提出的DRL网络交互结构.
图 6
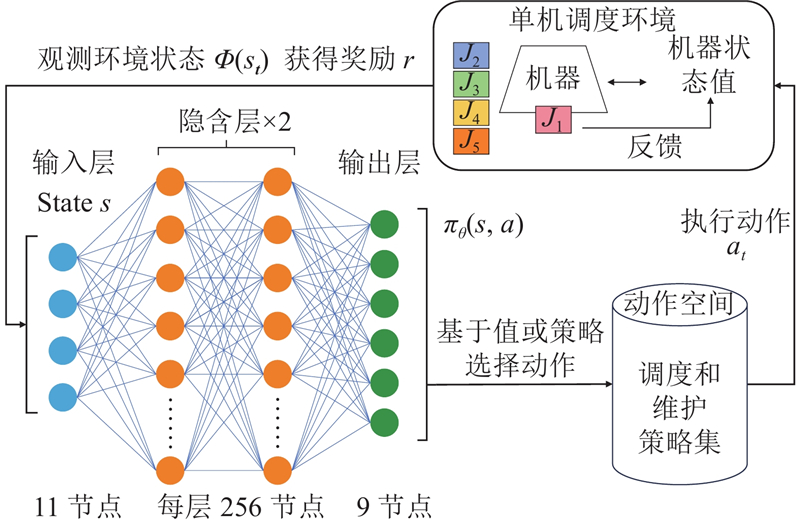
Agent从环境中感知当前状态的特征并输入神经网络,通过计算动作的Q值或策略选择概率,输出作业调度或机器维护动作选择的预测值,并根据动作交互和改变调度环境.
问题模型仿真环境和DRL框架基于Python语言和Pytorch神经网络框架编码和实现,使用OpenAI gym包装,增强环境的兼容性和扩展性.
算法的训练过程如下:每个回合开始时重置环境,Agent获得观察状态S0,在调度期间安排作业和维护决策. 当队列中的所有任务完成后,重置环境并开始下一回合. 对持续超出边界的情况除边界惩罚外还设置了环境截断条件,防止策略陷入不良状态. 当步数达到最大时,训练过程结束,输出经过训练的模型,并使用该模型进行测试,输出总成本最小的调度方案. 提出的DRL算法框架和运行流程如图7所示.
图 7
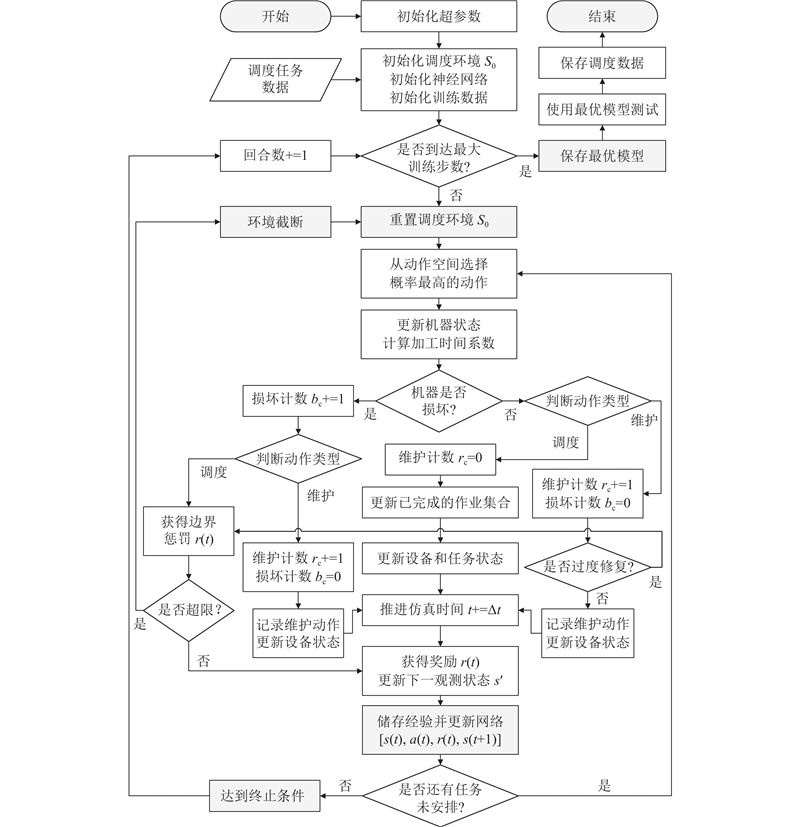
在DQN算法中使用递减的
式中:P为[0,1.0]内的随机数,
在PPO和A2C算法中,由于网络结构和算法实现原理的差异,通过控制广义优势估计(GAE)权衡偏差与方差的折中系数、控制策略熵在损失函数中的权重系数、平衡策略损失和值函数损失的权重系数,分别控制探索中的策略梯度更新、探索的随机性和策略更新的稳定性.
4. 数值实验分析
4.1. 实验算例设计和基准
研究提出的考虑劣化效应和维护决策的单机一体化调度问题具有模型特殊性,未检索到标准数据集作为测试基准,因此通过控制作业的特定参数生成随机的数据实例.
实验规模分别设置为10、20、30、50、80、100和150. 这些规模涵盖了无需维护、可选维护、必须适时维护否则机器将损坏的多种情形. 待加工作业数据中,每个作业的处理时间pj按照
为了验证算法的有效性,基于目前广泛使用的优先调度规则结合基于机器状态的预测性维护(PMMC)方法[25],提出使用调度规则与预防性维护相结合的调度-维护(R-M)集成优化方法,并将其优化结果作为比较基准. 令DRL算法动作空间中7种调度规则分别与维护策略组合,当机器状态值低于阈值T时随机执行维护动作. T分别设置为40、50、60、70.
表 2 R-M集成优化策略下的成本均值和标准差
Tab.2
| 规模 | SPT-M | LPT-M | FCFS-M | EDD-M | |||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||||
| 10 | 200.0 | 0.0 | 258.0 | 0.0 | 192.0 | 0.0 | 227.0 | 0.0 | |||
| 20 | 10.2 | 108.8 | 27.1 | 82.1 | |||||||
| 30 | 58.1 | 110.3 | 113.1 | 143.8 | |||||||
| 50 | 157.5 | 212.7 | 291.3 | 229.9 | |||||||
| 80 | 450.4 | 752.1 | 597.9 | 665.6 | |||||||
| 100 | 553.8 | 856.8 | 886.7 | ||||||||
| 150 | |||||||||||
| 规模 | MST-M | CR-M | MDD-M | 基准 | |||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||||
| 10 | 197.0 | 0.0 | 226.0 | 0.0 | 191.0 | 0.0 | 191.0 | 0.0 | |||
| 20 | 20.6 | 27.7 | 973.8 | 22.5 | 973.8 | 22.5 | |||||
| 30 | 73.2 | 109.5 | 102.9 | 102.9 | |||||||
| 50 | 307.3 | 191.6 | 172.1 | 172.1 | |||||||
| 80 | 687.8 | 519.0 | 494.0 | 494.0 | |||||||
| 100 | 937.2 | 800.7 | 766.8 | 766.8 | |||||||
| 150 | |||||||||||
表 3 R-M集成优化策略下的成本最小值
Tab.3
| 规模 | Min | ||||||
| SPT-M | LPT-M | EDD-M | FCFS-M | MST-M | CR-M | MDD-M | |
| 10 | 200 | 258 | 192 | 227 | 197 | 226 | 191 |
| 20 | 956 | 904 | |||||
| 30 | 2017 | 1939 | |||||
| 50 | |||||||
| 80 | |||||||
| 100 | |||||||
4.2. 算法和环境参数设定
仿真环境中必要的参数设置如表4中所示. 其中奖励归一化缩放参数NScale的取值根据各项成本系数、维护成本、单步平均成本等估计值测定,使奖励函数范围在[0, 1.0].
表 4 环境参数设置
Tab.4
| 环境参数 | 描述 | 值 |
| n | 工件数量规模 | 10, 20, 30, 50, 80, 100, 150 |
| pj | 工件j的加工时间 | Discrete U (1, 10) |
| dj | 工件j的交付时间 | pj +Discrete U (n, 3n) |
| α | 延迟交付的成本系数 | 1 |
| β | 机器损耗的成本系数 | 5 |
| M0 | 机器初始状态值 | 100 |
| tCM, tPM | CM 和 PM 的时间 | 20, 10 |
| CCM, CPM | CM 和 PM 的成本 | 60, 40 |
| Cbroke | 损坏的额外修复成本 | 100 |
| NScale | 奖励值归一化尺度 | 100 |
| h1, h2 | 劣化和失效效应点 | 60, 0 |
| σ | 劣化效应因子 | 0.05 |
| M1, M2 | 超出边界状态的惩罚基数 | 2, 2 |
在DRL算法的调试过程中,对3种算法的超参数进行调优. 分析学习率、经验池、批量、网络更新频率、折扣因子γ和探索率ε等参数的影响. 综合考虑各种参数对模型训练的增益,确定对模型训练较稳定且对不同规模适应度较好的参数组合,并选择相近的超参数进行实验,以更好地衡量不同算法之间的性能差异和优化效果. 详细设置如表5所示,并针对不同算例规模适配相应的训练步长.
表 5 DRL算法超参数设置
Tab.5
| 超参数 | DQN算法 | PPO算法 | A2C算法 |
| 最大训练步长 | 1.6×107 | 1.6×107 | 1.6×107 |
| 批量大小 | 256 | 256 | − |
| 环境交互时间步 | − | 256 | |
| 隐藏层节点数 | 2×256 | 2×256 | 2×256 |
| 回放池大小 | 1×107 | − | − |
| 网络同步频率 | 1×104 | − | − |
| 学习率 | 1×10−4 | 1×10−4 | 1×10−4 |
| 折扣因子 γ | 0.99 | 0.99 | 0.99 |
| 初始探索率 | 0.01 | − | 0.01 |
| λ(GAE) | − | 0.95 | 0.95 |
| 熵正则化系数 | − | 0.05 | 0.05 |
| 初始探索率 | 1 | − | − |
| 探索衰减率 | 0.99 | − | − |
| 最小探索率 | 0.001 | − | − |
4.3. 学习和优化效果评价
根据生成的数据集和设定的算法参数,使用3种DRL算法分别对不同规模的实例进行20次独立训练,训练中产生各种规模下的最优模型,使用训练好的模型进行数值测试和保存结果,每次运行完成后销毁调用的对象并释放内存,以确保每次实验的独立性.
图 8
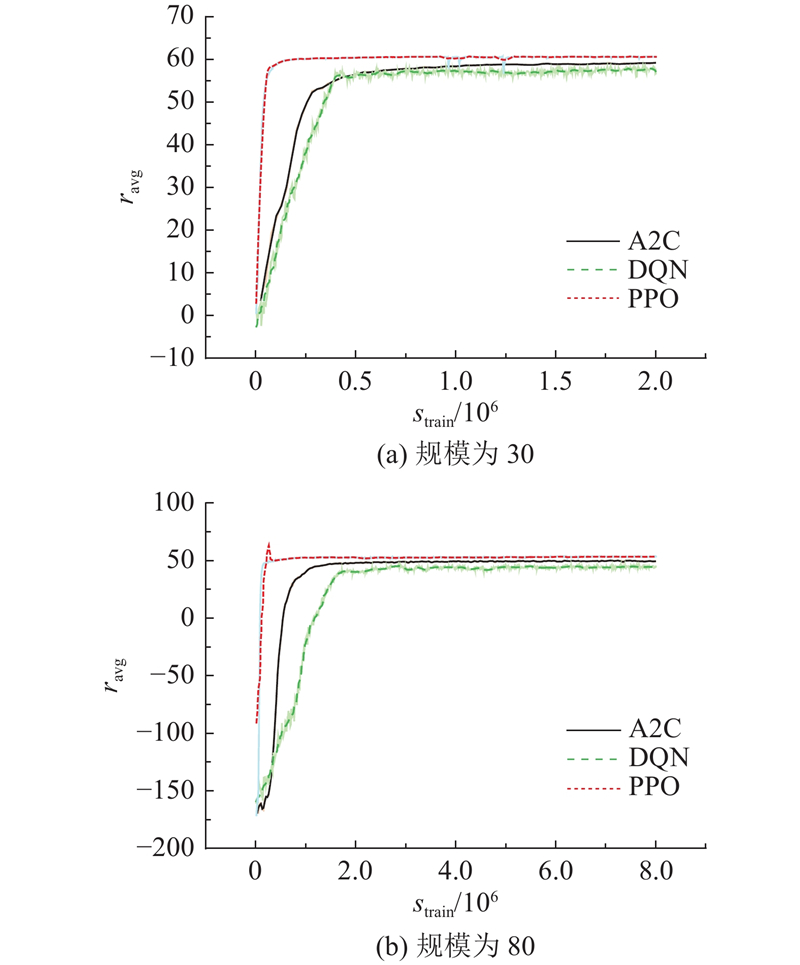
图 8 规模对回合平均奖励的影响曲线
Fig.8 Influence curves of scale on average reward of episode
图 9
规模为80算例下的训练速度曲线如图10所示. 其中,FPS为每步交互所需时间. 可以看出,DQN算法在前期的探索和积累经验阶段具有较快的速度,随着经验学习的开始,环境渲染速度(每秒交互的步数)开始下降. 最终的计算速度为A2C较快,DQN和PPO较低. 其余规模下的计算速度趋势相同.
图 10
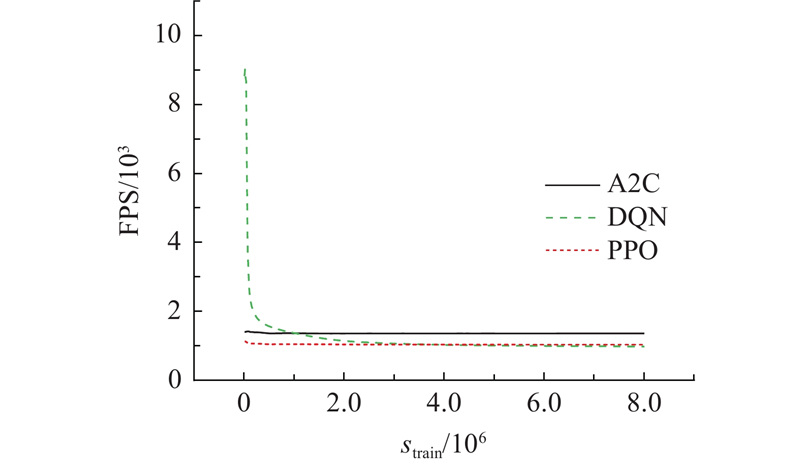
所有规模下的训练奖励和时间如表6所示,从训练时间对比可以看出,A2C具有相对较高的计算效率,DQN和PPO算法计算速度相近,但DQN速度略慢.
表 6 DRL算法训练性能比较
Tab.6
| 规模 | 算法 | 时间步/106 | 平均FPS | 训练时长/h |
| 10 | A2C | 1 | 0.18 | |
| DQN | 1 | 0.27 | ||
| PPO | 1 | 0.24 | ||
| 20 | A2C | 2 | 0.37 | |
| DQN | 2 | 0.54 | ||
| PPO | 2 | 0.50 | ||
| 30 | A2C | 2 | 0.38 | |
| DQN | 2 | 0.54 | ||
| PPO | 2 | 0.51 | ||
| 50 | A2C | 4 | 0.79 | |
| DQN | 4 | 1.11 | ||
| PPO | 4 | 1.05 | ||
| 80 | A2C | 8 | 1.63 | |
| DQN | 8 | 2.27 | ||
| PPO | 8 | 2.15 | ||
| 100 | A2C | 8 | 1.66 | |
| DQN | 8 | 2.31 | ||
| PPO | 8 | 2.19 | ||
| 150 | A2C | 16 | 3.51 | |
| DQN | 16 | 4.68 | ||
| PPO | 16 | 4.33 |
优化数值结果分析表明,3种DRL算法在数值优化效果上均优于R-M集成策略给出的基准,尽管A2C在计算效率中表现出一定的优势,但其对数值的优化效果不如DQN和PPO. PPO算法在数值优化效果上对比其他算法具有明显优势,DQN算法在训练过程中则没有表现出特别优势,且在规模为50的训练中出现了学习不稳定和难收敛的状况. 经过分析可能原因是这一规模下奖励函数出现了部分奖励数值重叠,使基于值的DQN算法难以从数值变化中分辨和学习经验.
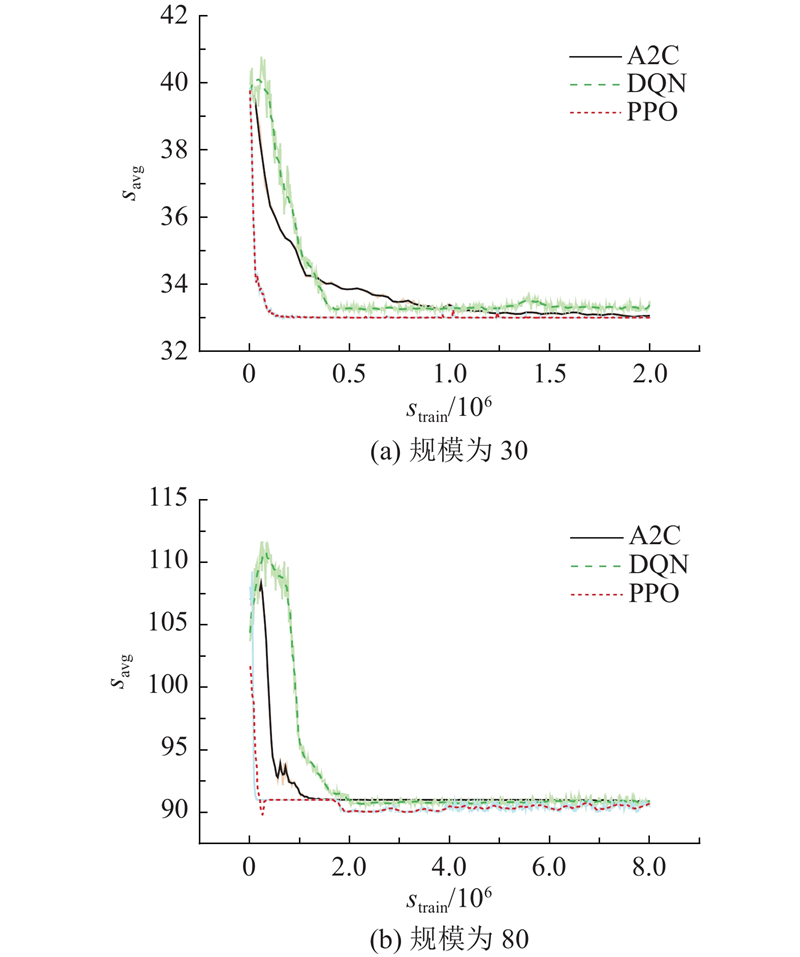
调度总成本优化效果差距随着作业数量的增加更加明显,证明了DRL算法在处理较大规模作业时可以借助其数值敏感性和神经网络在对高维和复杂问题的求解能力上获得更大优势. DRL算法优化后的调度总成本的平均值和标准差记录于表7.
表 7 DRL方法的成本优化均值和标准差
Tab.7
| 规模 | 基准 | A2C | DQN | PPO | |||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||||
| 10 | 191.0 | 0.0 | 191.4 | 1.0 | 217.8 | 61.7 | 192.5 | 14.8 | |||
| 20 | 973.8 | 22.5 | 908.0 | 9.5 | 925.6 | 47.6 | 901.5 | 6.1 | |||
| 30 | 102.9 | 20.1 | 109.0 | 6.6 | |||||||
| 50 | 172.1 | 41.1 | 19.0 | ||||||||
| 80 | 494.0 | 65.1 | 480.4 | 40.3 | |||||||
| 100 | 766.8 | 172.2 | 708.4 | 119.5 | |||||||
| 150 | 270.0 | 275.1 | |||||||||
DRL方法和R-M集成优化策略平均优化结果的优化效果对比如图11所示,数值越小越好. 其中,Cost表示优化成本.
图 11
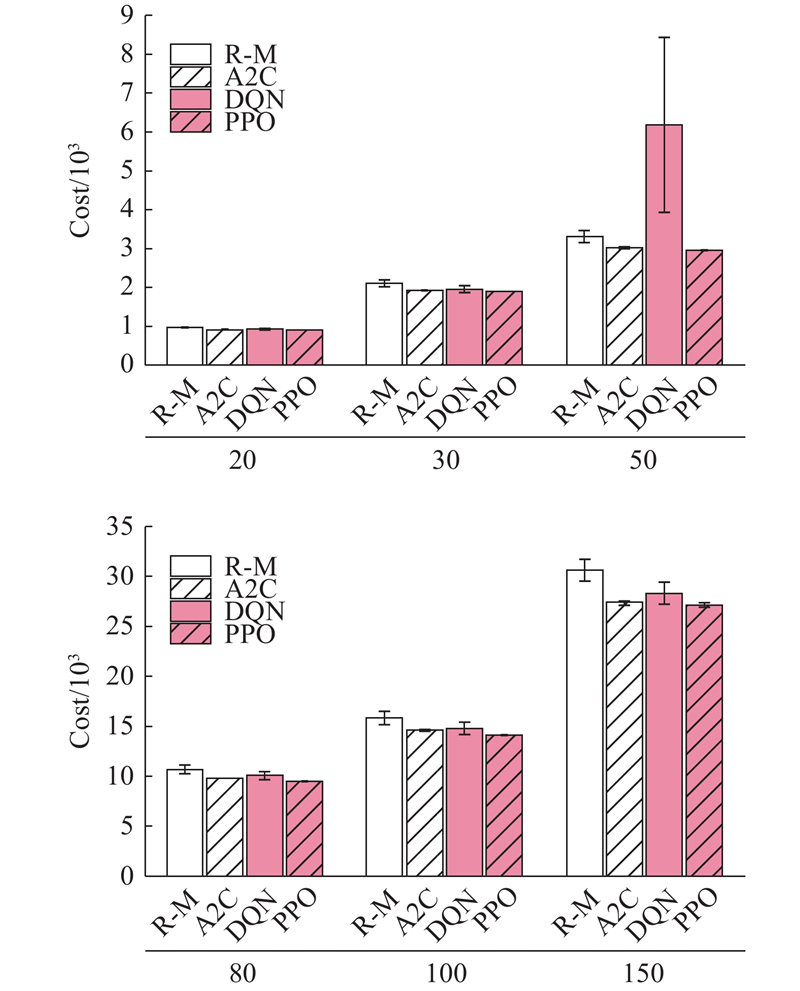
图 11 不同算法的成本优化结果对比
Fig.11 Comparison of optimization cost results of different algorithms
如表8所示记录了7种算例规模下3种DRL算法与R-M集成优化策略方法计算得到的最优结果比较.
表 8 DRL方法优化的最优值
Tab.8
| 规模 | Min | |||
| R-M | DQN | A2C | PPO | |
| 10 | 191.0 | 191.0 | 191.0 | 191.0 |
| 20 | 904.0 | 895.0 | 901.0 | 900.0 |
| 30 | ||||
| 50 | ||||
| 80 | ||||
| 100 | ||||
| 150 | ||||
为了系统地评估DRL方法的性能,定义成本节约百分比(PCS)作为性能指标,表示与其他优化策略相比选定方法节约的成本百分比,用于比较DRL方法与R-M策略. PCS计算公式为
式中:Cl表示R-M集成策略优化后的最低成本,CDRL表示DRL方法的成本.
当作业调度规模较小时,所提出的DRL方法获得与R-M集成优化策略相近的结果. 随着作业数量的增加,所提出的DRL算法在实验中显示出更好的性能,当作业数量大于30时,PPO算法对比均值的PCS超过12%,对比最优值的PCS超过1%. 相比之下,DQN算法在规模为50的算例中的表现不够稳定,存在较大偏差,无法作为稳健的优化方法进行应用. A2C算法在均值优化效果上也达到约10%,但在对最优值的探索能力上优势不明显.
综上所述,在所提出的DRL框架下,PPO算法比其他策略具有更好的计算准确性和适应能力,可以作为效果较好的算法进行应用. 该评估指标下3种DRL算法的均值和最优值的成本节约性能对比如表9所示. 其中,
表 9 DRL方法的成本优化效果
Tab.9
| 规模 | A2C | DQN | PPO | |||||
| 10 | −0.23 | 0.00 | −12.31 | 0.00 | −0.78 | 0.00 | ||
| 20 | 7.25 | 1.01 | 5.21 | 0.33 | 8.01 | 0.44 | ||
| 30 | 9.53 | 3.25 | 7.98 | 2.76 | 11.88 | 3.25 | ||
| 50 | 10.00 | −0.27 | −46.41 | −9.44 | 12.73 | 0.98 | ||
| 80 | 9.57 | −0.59 | 6.25 | −0.76 | 12.38 | 1.03 | ||
| 100 | 8.33 | −1.27 | 6.96 | 0.87 | 12.43 | 1.53 | ||
| 150 | 12.00 | 2.90 | 8.33 | 3.61 | 12.83 | 3.45 | ||
为了进一步验证所提出的DRL方法的有效性以及与各集成优化方法之间存在的显著差异,采用Friedman检验来评估实验数据,分别以最优值和平均值作为响应,计算这些策略之间的秩和并进行排序,如表10所示. 2个指标下的p值均小于0.05,表明结果是可信的. 综合来看,在各种DRL方法中,PPO算法具有最好的优化效果和相对出色的稳健性.
表 10 不同方法的Friedman 检验排序结果
Tab.10
| 规模 | 方法 | Min | Mean | |||
| 中位数 | 秩和 | 中位数 | 秩和 | |||
| 7 | PPO | 10 | 10 | |||
| 7 | MDD-M | 15 | 24 | |||
| 7 | A2C | 18 | 14 | |||
| 7 | DQN | 36 | 31 | |||
| 7 | SPT-M | 37 | 36 | |||
| 7 | CR-M | 41 | 42 | |||
| 7 | EDD-M | 45 | 44 | |||
| 7 | MST-M | 52 | 52 | |||
| 7 | FCFS-M | 61 | 62 | |||
| p1=0.00 | p2=0.00 | |||||
在R-M集成优化策略中,修正交付时间优先调度规则与预防性维护的集成优化策略(MDD-M)的优化效果中排在最前. 总体来看,DRL框架下的算法与R-M策略相比均具有优势,特别是经过训练之后的模型调度结果波动更小,能够减少调度的不稳定性.
4.4. 学习特性分析
当作业规模较少时,DRL方法与R-M策略得到相近的调度结果,当任务数量增加时,DRL能够通过环境交互识别高维特征,得到更好的解决方案. 以PPO算法对规模为50算例的优化结果为例,最优方案下的机器状态变化曲线、每步交互的成本数值分析和作业调度甘特图如图12所示. 从机器健康状态变化曲线中可以看出,算法倾向于在机器即将或刚到达劣化效应点时即采取成本和时间更少的PM维护策略维持机器健康状态. 从单步交互的成本分析中可以看出,Agent倾向于优先安排更多不发生延期的作业以维持更低的总成本,因此调度前期成本以机器运行成本和维护成本为主,当后续作业开始发生延期,单步成本以延期成本为主. 成本变化规律符合Agent选择更加节约时间的PM维护动作以尽可能减少后续作业延期的策略. 从单机作业调度甘特图中可以看出,Agent在前期优先选择加工时间适中的高成本作业,当接近交付时间时密集选择加工时间最短的任务以尽可能减少更多的作业延期,这一规律符合最小化成本的要求和预期.
图 12
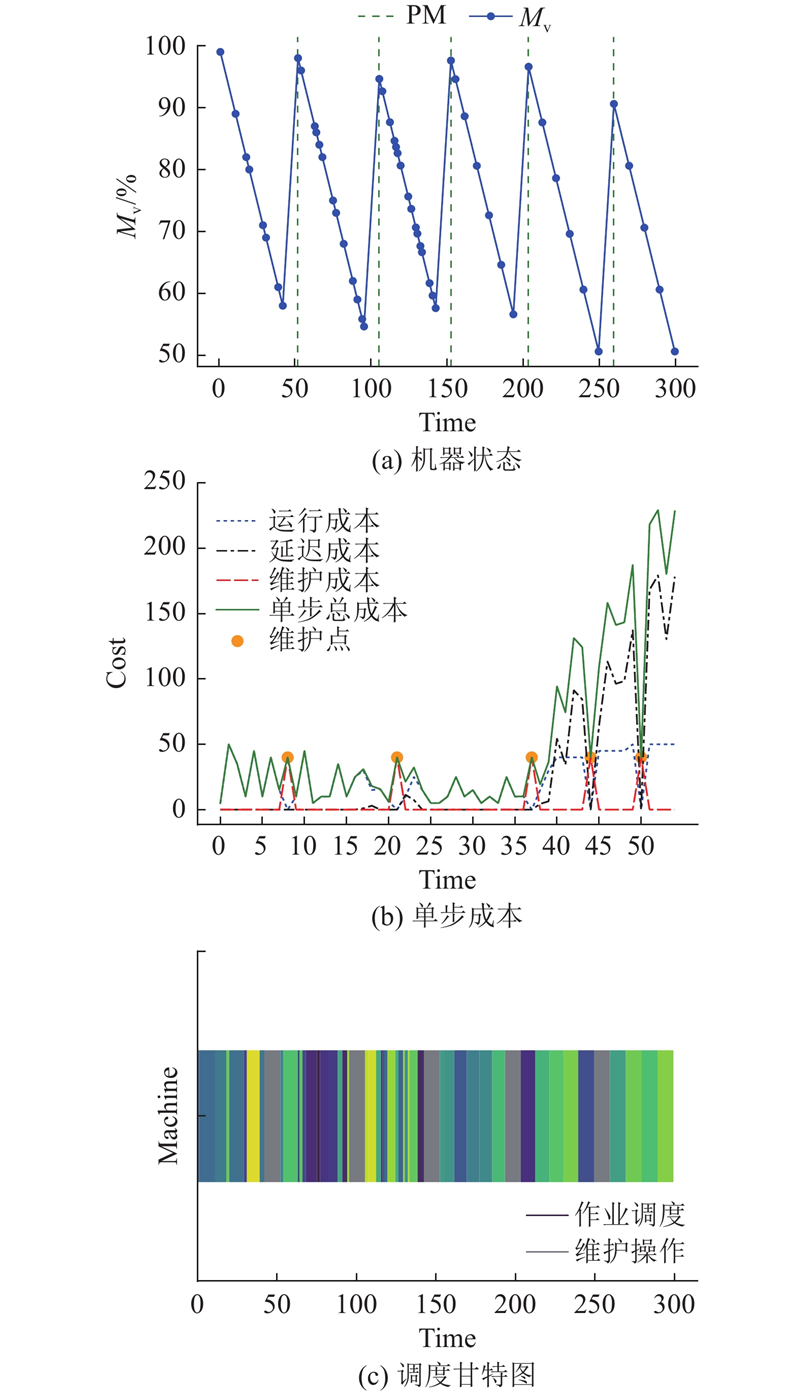
以上调度规律与调度环境的设计密切相关,在当前环境状态下,每次动作交互都会增加后续结果的不确定性. 如果在前期采取了错误的调度策略浪费了过多时间,则后续作业的交付时间会随之延迟而导致获得更高的成本惩罚.
DRL算法通过感知环境信息,在不断变化实际生产环境的环境中给出更优的调度解决方案. 算法给出的调度策略也揭示了在生产中须保持机器健康状态以应对交付期密集型的任务. 由此可见DRL在作业调度领域具有一定的意义.
此外,从调度规则的动作记录中可以看出,尽管MDD-M策略在R-M组合策略中具有绝对优势,但DRL算法的通用决策能力并未受到影响. 算法对多种调度规则进行了有效组合,从而获得综合效果更好的调度结果. 最优方案下的调度动作记录如下:a3 a3 a7 a3 a6 a3 a3 a7 PM a3 a3 a7 a3 a3 a7 a3 a7 a5 a5 a7 a7 PM a7 a7 a7 a1 a1 a7 a7 a7 a7 a1 a7 a1 a7 a7 a1 PM a1 a1 a7 a7 a7 a7 PM a4 a7 a1 a7 a1 PM a2 a6 a2 a6.
5. 结 语
研究考虑机器劣化效应和维护决策的集成的单机调度问题,设计以最低总成本为优化目标的数学模型,构建模型的DRL框架. 多种规模下的数值仿真实验证明了该框架能够充分表达不同调度策略对成本优化和Agent学习决策的影响,能够有效平衡生产调度与设备维护的一体化决策,证明了框架设计的合理性. 以R-M集成优化策略为基准的实验优化结果对比证明了该DRL模型的求解优势,特别是PPO算法在总成本的优化中取得了明显更优的结果.
本研究的局限性在于,DRL的训练效果在一定程度上依赖超参数的选择和奖励函数的设计. 实际的生产环境比构建的问题模型更加复杂,须在生产系统中进行更复杂的特征提取和精密建模,使DRL更好地应用于实际生产环境.
目前对问题模型的研究以单机生产和维护一体化调度为基础,可进一步改进DRL算法模型和奖励函数的结构设计以期取得更好的优化结果. 此外,也将继续探索更多复杂场景下的DRL一体化调度优化应用并进一步研究劣化效应模型对集成优化问题的影响.
参考文献
Energy saving in single-machine scheduling management: an improved multi-objective model based on discrete artificial bee colony algorithm
[J].DOI:10.3390/sym14030561 [本文引用: 1]
An improved genetic algorithm for the flexible job shop scheduling problem with multiple time constraints
[J].DOI:10.1016/j.swevo.2020.100664 [本文引用: 1]
Joint optimization of capacity, production and maintenance planning of leased machines
[J].DOI:10.1007/s10845-018-1450-7 [本文引用: 1]
A branch and bound algorithm to minimize the single machine maximum tardiness problem under effects of learning and deterioration with setup times
[J].DOI:10.1051/ro/2015026 [本文引用: 1]
Integrated optimization on production scheduling and imperfect preventive maintenance considering multi-degradation and learning-forgetting effects
[J].DOI:10.1007/s10696-021-09410-1 [本文引用: 1]
Single-machine scheduling with deteriorating effects and machine maintenance
[J].DOI:10.1080/00207543.2019.1566675 [本文引用: 1]
Integrated production and maintenance scheduling for a single degrading machine with deterioration-based failures
[J].DOI:10.1016/j.cie.2020.106432 [本文引用: 1]
The method of production scheduling with uncertainties using the ants colony optimisation
[J].
基于多目标混合殖民竞争算法的设备维护与车间调度集成优化
[J].DOI:10.3969/j.issn.1004-132X.2015.11.010 [本文引用: 1]
Integrated optimization of equipment maintenance and shop scheduling problem based on multi-objective hybrid imperialist competitive algorithm
[J].DOI:10.3969/j.issn.1004-132X.2015.11.010 [本文引用: 1]
流水车间调度与视情维修的联合决策
[J].
The joint decision and optimization of flow-shop scheduling and condition based maintenance
[J].
考虑劣化状态的单机调度与维修决策集成模型
[J].
Integrated model of single-machine scheduling and maintenance decision for degrading state systems
[J].
考虑系统时变效应与预防性维护的平行机调度
[J].
A parallel-machine scheduling problem with time-changing effect and preventive maintenance
[J].
带退化效应多态生产系统调度与维护集成优化
[J].
Integrated optimization of scheduling and maintenance in multi-state production systems with deterioration effects
[J].
Joint optimization of preventive maintenance and production scheduling for multi-state production systems based on reinforcement learning
[J].DOI:10.1016/j.ress.2021.107713 [本文引用: 1]
Opportunistic maintenance modeling for series production systems based on bottleneck by considering energy consumption and market demand
[J].DOI:10.1080/21681015.2023.2234377 [本文引用: 1]
基于2种周期维护类型和序列准备时间的单机调度
[J].
Single machine scheduling based on two types of periodic maintenance and sequence-dependent setup times
[J].
Integrated control policy of production and preventive maintenance for a deteriorating manufacturing system
[J].DOI:10.1016/j.cie.2018.02.026 [本文引用: 1]
Reinforcement learning-based and parametric production-maintenance control policies for a deteriorating manufacturing system
[J].
Human-level control through deep reinforcement learning
[J].DOI:10.1038/nature14236 [本文引用: 1]
Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning
[J].DOI:10.1016/j.asoc.2020.106208 [本文引用: 1]
Deep reinforcement learning for dynamic scheduling of a flexible job shop
[J].DOI:10.1080/00207543.2022.2058432
Research on adaptive job shop scheduling problems based on dueling double DQN
[J].DOI:10.1109/ACCESS.2020.3029868 [本文引用: 1]
Predictive maintenance system for production lines in manufacturing: a machine learning approach using IoT data in real-time
[J].DOI:10.1016/j.eswa.2021.114598 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}