式中:当$ s=2、4、8 $ $ \mathrm{s}\mathrm{i}\mathrm{z}\mathrm{e}_s $ $ 1/2、1/4、1/8 $ $ \mathrm{s}\mathrm{p}\mathrm{l}\mathrm{i}\mathrm{t}\left(\cdot \right) $ $ {\boldsymbol{x}}_{\mathrm{e}}^{\prime} $ $ {\boldsymbol{x}}_{0,s}^{\prime} $ $ {\boldsymbol{x}}_{\mathrm{e},s}^{\prime} $ . 二者包含的子特征图可以表示为$ {\boldsymbol{x}}_{0,s}^{\prime}=\left\{{\boldsymbol{x}}_{0,s}^{\prime}\left(1\right), \right. \left.{\boldsymbol{x}}_{0,s}^{\prime}\left(2\right),\cdots ,{\boldsymbol{x}}_{0,s}^{\prime} \left({P}_{s}\right)\right\}\in {\mathbf{R}}^{C\times \left(H/s\right)\times \left(W/s\right)} $ $ \;\;\;\;{\boldsymbol{x}}_{\mathrm{e},s}^{\prime}=\left\{{\boldsymbol{x}}_{\mathrm{e},s}^{\prime}\left(1\right), \right. \left. {\boldsymbol{x}}_{\mathrm{e},s}^{\prime}\left(2\right),\cdots , {\boldsymbol{x}}_{\mathrm{e},s}^{\prime}\left({P}_{s}\right)\right\}\in {\mathbf{R}}^{C\times \left(H/s\right)\times \left(W/s\right)} $ $ s=2 $ $ {P}_{2}=4 $ $ s=4 $ $ {P}_{4}=16 $ $ s=8 $ $ {P}_{8}=64 $ . 将特征图$ {\boldsymbol{x}}_{0}^{\prime} $ $ {\boldsymbol{x}}_{\mathrm{e}}^{\prime} $ $ {\boldsymbol{x}}_{0,s}^{\prime}、{\boldsymbol{x}}_{\mathrm{e},s}^{\prime} $ $ {\boldsymbol{x}}_{0,s}^{\prime}、{\boldsymbol{x}}_{\mathrm{e},s}^{\prime} $ $ \mathrm{R}\mathrm{e}\mathrm{s}\mathrm{h}\mathrm{a}\mathrm{p}\mathrm{e}\left(\cdot \right) $
式中:$ \mathrm{R}\mathrm{e}\mathrm{s}\mathrm{h}\mathrm{a}\mathrm{p}\mathrm{e}\left(\cdot \right) $ $ {\boldsymbol{v}}_{0,s}^{\prime} $ $ {\boldsymbol{v}}_{\mathrm{e},s}^{\prime} $ $ {\boldsymbol{v}}_{0,s}^{\prime}=\left\{{\boldsymbol{v}}_{0,s}^{\prime}\left(1\right),{\boldsymbol{v}}_{0,s}^{\prime}\left(2\right),\cdots , {\boldsymbol{v}}_{0,s}^{\prime} \left({P}_{s}\right)\right\} \in {\mathbf{R}}^{C\times \left(N/{s}^{2}\right)} $ $\;\;\;\;{\boldsymbol{v}}_{\mathrm{e},s}^{\prime}=\left\{{\boldsymbol{v}}_{\mathrm{e},s}^{\prime}\left(1\right),{\boldsymbol{v}}_{\mathrm{e},s}^{\prime}\left(2\right),\cdots , {\boldsymbol{v}}_{\mathrm{e},s}^{\prime} \left({P}_{s}\right)\right\}\in {\mathbf{R}}^{C\times \left(N/{s}^{2}\right)} $ $ N=H\times W $ $ C\times H\times W $ $ C\times N $ . 得到2幅子特征图的向量$ {\boldsymbol{v}}_{0,s}^{\prime}、{\boldsymbol{v}}_{\mathrm{e},s}^{\prime} $ $ {\boldsymbol{v}}_{0,s}^{\prime}、{\boldsymbol{v}}_{\mathrm{e},s}^{\prime} $
[1]
WANG W, WANG X, YANG W, et al Unsupervised face detection in the dark
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (1 ): 1250 - 1266
DOI:10.1109/TPAMI.2022.3152562
[本文引用: 1]
[2]
TENG S, HU X, DENG P, et al Motion planning for autonomous driving: the state of the art and future perspectives
[J]. IEEE Transactions on Intelligent Vehicles , 2023 , 8 (6 ): 3692 - 3711
DOI:10.1109/TIV.2023.3274536
[本文引用: 1]
[3]
WANG S, CHEN M A LiDAR multi-object detection algorithm for autonomous driving
[J]. Applied Sciences , 2023 , 13 (23 ): 12747
DOI:10.3390/app132312747
[本文引用: 1]
[4]
YI A, ANANTRASIRICHAI N A comprehensive study of object tracking in low-light environments
[J]. Sensors , 2024 , 24 (13 ): 4359
DOI:10.3390/s24134359
[本文引用: 1]
[5]
PIZER S M, AMBURN E P, AUSTIN J D, et al Adaptive histogram equalization and its variations
[J]. Computer Vision, Graphics, and Image Processing , 1987 , 39 (3 ): 355 - 368
DOI:10.1016/S0734-189X(87)80186-X
[本文引用: 1]
[6]
RAHMAN S, RAHMAN M M, ABDULLAH-AL-WADUD M, et al An adaptive gamma correction for image enhancement
[J]. EURASIP Journal on Image and Video Processing , 2016 , (1 ): 35
[本文引用: 1]
[7]
LV W, ZHAO Y, CHANG Q, et al. RT-DETRv2: improved baseline with bag-of-freebies for real-time detection Transformer [EB/OL]. (2024-07-24) [2025-07-16]. https://arxiv.org/abs/2407.17140.
[本文引用: 4]
[8]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 2]
[9]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980–2988.
[本文引用: 2]
[10]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999–3007.
[本文引用: 3]
[11]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 21–37.
[本文引用: 1]
[12]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[13]
江泽涛, 施道权, 雷晓春, 等 一种基于Night-YOLOX的低照度目标检测方法
[J]. 电子学报 , 2023 , 51 (10 ): 2821 - 2830
DOI:10.12263/DZXB.20221396
[本文引用: 1]
JIANG Zetao, SHI Daoquan, LEI Xiaochun, et al A low-illumination object detection method based on night-YOLOX
[J]. Acta Electronica Sinica , 2023 , 51 (10 ): 2821 - 2830
DOI:10.12263/DZXB.20221396
[本文引用: 1]
[14]
LIU Y, LI S, ZHOU L, et al Dark-YOLO: a low-light object detection algorithm integrating multiple attention mechanisms
[J]. Applied Sciences , 2025 , 15 (9 ): 5170
DOI:10.3390/app15095170
[本文引用: 1]
[15]
PENG D, DING W, ZHEN T A novel low light object detection method based on the YOLOv5 fusion feature enhancement
[J]. Scientific Reports , 2024 , 14 : 4486
DOI:10.1038/s41598-024-54428-8
[本文引用: 1]
[16]
QIN Q, CHANG K, HUANG M, et al. DENet: detection-driven enhancement network for object detection under adverse weather conditions [C]// Proceedings of the Asian Conference on Computer Vision . Macao: Springer, 2023: 491–507.
[本文引用: 4]
[17]
HUI Y, WANG J, LI B WSA-YOLO: weak-supervised and adaptive object detection in the low-light environment for YOLOv7
[J]. IEEE Transactions on Instrumentation and Measurement , 2024 , 73 : 2507012
[本文引用: 5]
[18]
YIN X, YU Z, FEI Z, et al. PE-YOLO: pyramid enhancement network for dark object detection [C]// Proceedings of the 32nd International Conference on Artificial Neural Networks . Heraklion: Springer, 2023: 163–174.
[本文引用: 5]
[19]
江泽涛, 李慧, 雷晓春, 等 一种基于SAM-MSFF网络的低照度目标检测方法
[J]. 电子学报 , 2024 , 52 (1 ): 81 - 93
DOI:10.12263/DZXB.20220666
[本文引用: 1]
JIANG Zetao, LI Hui, LEI Xiaochun, et al A low-light object detection method based on SAM-MSFF network
[J]. Acta Electronica Sinica , 2024 , 52 (1 ): 81 - 93
DOI:10.12263/DZXB.20220666
[本文引用: 1]
[20]
ZHOU R, LI P, ZHANG M, et al A low-light image enhancement algorithm incorporating cross-mixed attention and receptive field expansion mechanism
[J]. IEEE Access , 2024 , 12 : 45773 - 45784
DOI:10.1109/ACCESS.2024.3381514
[本文引用: 1]
[21]
ZHOU W, CHEN Z. Deep multi-scale features learning for distorted image quality assessment [C]// Proceedings of the IEEE International Symposium on Circuits and Systems . Daegu: IEEE, 2021: 1–5.
[本文引用: 1]
[22]
GUO H, BIN Y, HOU Y, et al. IQMA network: image quality multi-scale assessment network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Nashville: IEEE, 2021: 443–452.
[本文引用: 1]
[23]
LIU Y, WANG L, CHENG J, et al Multiscale feature interactive network for multifocus image fusion
[J]. IEEE Transactions on Instrumentation and Measurement , 2021 , 70 : 5019316
[本文引用: 1]
[24]
ZHANG Y, GUO W, WU C, et al FANet: an arbitrary direction remote sensing object detection network based on feature fusion and angle classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 5608811
[本文引用: 1]
[25]
ZHAO W, KANG Y, CHEN H, et al Adaptively attentional feature fusion oriented to multiscale object detection in remote sensing images
[J]. IEEE Transactions on Instrumentation and Measurement , 2023 , 72 : 5008111
[本文引用: 1]
[26]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Conference on Neural Information Processing Systems . Long Beach: Curran Associates Inc, 2017: 6000–6010.
[本文引用: 1]
[27]
JIANG J, XIA N, YU X A feature matching and compensation method based on importance weighting for occluded human pose estimation
[J]. Journal of King Saud University-Computer and Information Sciences , 2024 , 36 (5 ): 102061
DOI:10.1016/j.jksuci.2024.102061
[本文引用: 1]
[28]
LOH Y P, CHAN C S Getting to know low-light images with the Exclusively Dark dataset
[J]. Computer Vision and Image Understanding , 2019 , 178 : 30 - 42
DOI:10.1016/j.cviu.2018.10.010
[本文引用: 1]
[29]
YU F, CHEN H, WANG X, et al. BDD100K: a diverse driving dataset for heterogeneous multitask learning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2633–2642.
[本文引用: 1]
[30]
WEN L, DU D, CAI Z, et al UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking
[J]. Computer Vision and Image Understanding , 2020 , 193 : 102907
DOI:10.1016/j.cviu.2020.102907
[本文引用: 1]
[31]
CHEN H, CHEN K, DING G, et al. YOLOv10: real-time end-to-end object detection [C]// Proceedings of the 38th International Conference on Neural Information Processing Systems . Vancouver: Curran Associates Inc, 2024: 107984–108011.
[本文引用: 3]
[32]
KHANAM R, HUSSAIN M. YOLOv11: an overview of the key architectural enhancements [EB/OL]. (2024-10-14) [2025-07-16]. https://arxiv.org/abs/1911.11907.
[本文引用: 4]
[33]
TIAN Y, YE Q, DOERMANN D. YOLOv12: attention-centric real-time object detectors [EB/OL]. (2025-02-18) [2025-07-16]. https://arxiv.org/abs/2407.17140.
[本文引用: 4]
[34]
CUI Z, LI K, GU L, et al. You only need 90K parameters to adapt light: a light weight transformer for image enhancement and exposure correction [C]// Proceedings of the British Machine Vision Conference . London: BMVA Press, 2022: 21–24.
[本文引用: 5]
[35]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . Zurich: Springer, 2014: 740–755.
[本文引用: 1]
[36]
YANG W, YUAN Y, REN W, et al Advancing image understanding in poor visibility environments: a collective benchmark study
[J]. IEEE Transactions on Image Processing , 2020 , 29 : 5737 - 5752
DOI:10.1109/TIP.2020.2981922
[本文引用: 1]
Unsupervised face detection in the dark
1
2023
... 低照度场景下的目标检测是计算机视觉领域中的重要任务,其目的是在低光照环境下的图像或视频中准确定位并识别出感兴趣的目标,相关技术在人脸检测[1 ] 、自动驾驶[2 ] 、监控视频分析[3 ] 等诸多领域得到了广泛应用. 低照度图像中目标细节丢失严重,且目标和黑暗背景之间的对比度较低,使得检测器出现漏检或误检的情况,从而导致目标检测精度严重下降[4 ] . 特别是在自动驾驶领域,对夜间车辆行驶过程中目标的检测能力直接关系到道路交通和人民生命与财产安全. ...
Motion planning for autonomous driving: the state of the art and future perspectives
1
2023
... 低照度场景下的目标检测是计算机视觉领域中的重要任务,其目的是在低光照环境下的图像或视频中准确定位并识别出感兴趣的目标,相关技术在人脸检测[1 ] 、自动驾驶[2 ] 、监控视频分析[3 ] 等诸多领域得到了广泛应用. 低照度图像中目标细节丢失严重,且目标和黑暗背景之间的对比度较低,使得检测器出现漏检或误检的情况,从而导致目标检测精度严重下降[4 ] . 特别是在自动驾驶领域,对夜间车辆行驶过程中目标的检测能力直接关系到道路交通和人民生命与财产安全. ...
A LiDAR multi-object detection algorithm for autonomous driving
1
2023
... 低照度场景下的目标检测是计算机视觉领域中的重要任务,其目的是在低光照环境下的图像或视频中准确定位并识别出感兴趣的目标,相关技术在人脸检测[1 ] 、自动驾驶[2 ] 、监控视频分析[3 ] 等诸多领域得到了广泛应用. 低照度图像中目标细节丢失严重,且目标和黑暗背景之间的对比度较低,使得检测器出现漏检或误检的情况,从而导致目标检测精度严重下降[4 ] . 特别是在自动驾驶领域,对夜间车辆行驶过程中目标的检测能力直接关系到道路交通和人民生命与财产安全. ...
A comprehensive study of object tracking in low-light environments
1
2024
... 低照度场景下的目标检测是计算机视觉领域中的重要任务,其目的是在低光照环境下的图像或视频中准确定位并识别出感兴趣的目标,相关技术在人脸检测[1 ] 、自动驾驶[2 ] 、监控视频分析[3 ] 等诸多领域得到了广泛应用. 低照度图像中目标细节丢失严重,且目标和黑暗背景之间的对比度较低,使得检测器出现漏检或误检的情况,从而导致目标检测精度严重下降[4 ] . 特别是在自动驾驶领域,对夜间车辆行驶过程中目标的检测能力直接关系到道路交通和人民生命与财产安全. ...
Adaptive histogram equalization and its variations
1
1987
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
An adaptive gamma correction for image enhancement
1
2016
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
4
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
Faster R-CNN: towards real-time object detection with region proposal networks
2
2017
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
2
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
3
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
1
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
1
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
一种基于Night-YOLOX的低照度目标检测方法
1
2023
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
一种基于Night-YOLOX的低照度目标检测方法
1
2023
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
Dark-YOLO: a low-light object detection algorithm integrating multiple attention mechanisms
1
2025
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
A novel low light object detection method based on the YOLOv5 fusion feature enhancement
1
2024
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
4
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection performance of different networks with same detector
Tab.7 方法 mAP/% FPS/(帧·s−1 ) DENet[16 ] +YOLOv12 80.7 91.3 IAT[34 ] +YOLOv12 81.5 87.5 PE[18 ] +YOLOv12 82.6 89.4 WSA[17 ] +YOLOv12 83.1 85.6 本研究方法+YOLOv12 83.4 85.1
2.5. 可视化成果展示 为了验证所提DEM和MSFE网络的有效性,根据不同网络模型的权重生成热力图,如图5 所示. 原始图像亮度不足,目标细节被阴影淹没,目标与背景之间的对比度较低,难以分辨. DEM通过细节增强,提升了全局亮度,并放大了目标与背景间的差异. MSFE网络进一步增强了对低级特征的提取能力,使特征图包含更丰富的目标信息,关注到了更远、更暗的物体,从而显著提升了图像的特征表达能力. ...
WSA-YOLO: weak-supervised and adaptive object detection in the low-light environment for YOLOv7
5
2024
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
... Detection performance of different networks with same detector
Tab.7 方法 mAP/% FPS/(帧·s−1 ) DENet[16 ] +YOLOv12 80.7 91.3 IAT[34 ] +YOLOv12 81.5 87.5 PE[18 ] +YOLOv12 82.6 89.4 WSA[17 ] +YOLOv12 83.1 85.6 本研究方法+YOLOv12 83.4 85.1
2.5. 可视化成果展示 为了验证所提DEM和MSFE网络的有效性,根据不同网络模型的权重生成热力图,如图5 所示. 原始图像亮度不足,目标细节被阴影淹没,目标与背景之间的对比度较低,难以分辨. DEM通过细节增强,提升了全局亮度,并放大了目标与背景间的差异. MSFE网络进一步增强了对低级特征的提取能力,使特征图包含更丰富的目标信息,关注到了更远、更暗的物体,从而显著提升了图像的特征表达能力. ...
5
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
... Detection performance of different networks with same detector
Tab.7 方法 mAP/% FPS/(帧·s−1 ) DENet[16 ] +YOLOv12 80.7 91.3 IAT[34 ] +YOLOv12 81.5 87.5 PE[18 ] +YOLOv12 82.6 89.4 WSA[17 ] +YOLOv12 83.1 85.6 本研究方法+YOLOv12 83.4 85.1
2.5. 可视化成果展示 为了验证所提DEM和MSFE网络的有效性,根据不同网络模型的权重生成热力图,如图5 所示. 原始图像亮度不足,目标细节被阴影淹没,目标与背景之间的对比度较低,难以分辨. DEM通过细节增强,提升了全局亮度,并放大了目标与背景间的差异. MSFE网络进一步增强了对低级特征的提取能力,使特征图包含更丰富的目标信息,关注到了更远、更暗的物体,从而显著提升了图像的特征表达能力. ...
一种基于SAM-MSFF网络的低照度目标检测方法
1
2024
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
一种基于SAM-MSFF网络的低照度目标检测方法
1
2024
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
A low-light image enhancement algorithm incorporating cross-mixed attention and receptive field expansion mechanism
1
2024
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
1
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
1
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
Multiscale feature interactive network for multifocus image fusion
1
2021
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
FANet: an arbitrary direction remote sensing object detection network based on feature fusion and angle classification
1
2023
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
Adaptively attentional feature fusion oriented to multiscale object detection in remote sensing images
1
2023
... 低照度目标检测方法一般分为传统方法、深度学习方法2大类. 传统的低照度图像处理方法包括直方图均衡化[5 ] 、伽马校正[6 ] 等,在复杂任务中效果有限. 目前,主流方法依托深度学习技术,主要分为基于Transformer的方法和双阶段、单阶段目标检测方法3种. 在基于Transformer的算法中,RT-DETR [7 ] 虽然兼具实时性和准确性,但是在弱光环境下的检测能力不足. 双阶段算法的代表有Faster R-CNN[8 ] 和Mask R-CNN[9 ] 等,单阶段算法的代表有RetinaNet[10 ] 、SSD[11 ] 、YOLO[12 ] . 相较于双阶段算法,单阶段算法虽然精度略低,但是检测速度快,适用于实时检测设备. 由于低照度下目标细节隐藏于黑暗背景,难以被常规检测器捕捉,为了兼顾检测精度和速度,学者们针对YOLO目标检测器进行改进. 改进方法主要分为2类,其中一种是优化现有网络以增强其对低照度图像的适应性,通常通过调整网络结构(如增加特征提取模块[13 ] )、优化层次结构或引入注意力机制来提升对目标区域的关注度并抑制背景干扰[14 -15 ] . 这些方法尽管有效,但是存在局限性:修改网络结构可能会降低模型的泛化能力,增加过拟合风险. 此外,改进网络需要大量低照度数据的支持,而数据的获取和标注成本较高,且分布可能存在偏差,从而限制了此类方法的实际应用. 另一种方法是通过前馈网络来增强低照度图像. Qin等[16 ] 提出用于目标检测的检测驱动增强网络,从低频、高频2个角度捕获暗图像中的潜在信息. Hui等[17 ] 为了减小低光照和正常光图像在低级语义上的差异,将图像分解为反射率图和光照图并分别进行增强,有效利用弱光和正常光的特征相关性,增强了图像亮度并抑制了噪声. Yin等[18 ] 提出金字塔暗图像增强网络,通过拉普拉斯金字塔将图像分解为不同分辨率的4个分量,分别从低频和细节信息2个角度对4个分量结果进行处理,实现了对暗图像的细节增强. 江泽涛等[19 ] 提出空间感知注意力机制,增强目标特征并抑制黑暗背景,通过多感受野增强模块扩展特征感受野,再对不同感受野特征进行分组加权. Zhou等[20 ] 结合交叉混合注意力和接受域扩展机制,从多尺度照明和感受野扩展2个方向,在通道、空间2个维度上过滤信息,以增强图像亮度,减少弱光图像增强过程的负面影响,并通过增强感受野来强化细节信息. 为了增强低照度图像中的特征,许多学者在网络模型中采用多尺度特征融合策略. Zhou等[21 ] 提出空间金字塔池化和特征金字塔网络来优化图像质量. Guo等[22 ] 基于生成对抗网络提出特征金字塔双分支多尺度结构,重建失真图像中目标的边缘纹理. Liu等[23 ] 提出新型的多尺度特征交互网络,将原图像分割为聚焦区域和散焦区域,同时设计多尺度特征融合、注意力上采样模块,解决多焦点图像融合质量低的问题. Zhang等[24 ] 提出加强连接金字塔网络,更改深层和浅层的横向连接结构,并应用跳跃连接操作,以丰富特征语义信息. Zhao等[25 ] 在YOLOX中引入多尺度注意力特征融合网络,扩展感知场并聚合上下文信息,以生成富含语义的特征图. 尽管上述研究都使用先增强后检测的方法和多尺度特征融合策略来弥补部分信息缺失的问题,但是未对目标的关键信息进行重要性加权,限制了网络对关键特征的学习. ...
1
... 提出的低照度目标检测方法通过对两阶段特征图的相似性匹配来强化目标特征. 如图2 所示,其中B 、C 、H 、W 分别为图像的批次、通道数、高度和宽度;细节增强模块由细节捕获分支(detail capture branch, DCB)和对比度强化分支(contrast enhancement branch, CEB)组成. 受Inception结构[26 ] 的启发,设计的DCB由核大小为3、5、9的平均池化(average pooling, AP)函数和最大池化(maximum pooling, MP)函数组成,其中不同大小的池化核用于多尺度地捕捉局部信息. 核大小为3和5的池化操作用于捕捉较小的局部纹理细节和边缘信息, 而核大小为9的池化操作能够捕捉更大范围的全局信息,如目标整体轮廓和背景信息. 大小为9的池化核的感受野显著更大,能够提供更多互补的特征信息,使特征表达更丰富. 平均池化用于捕捉特征的整体趋势,在保留背景信息的同时去除了冗余信息;最大池化用于突出边缘、纹理和其他重要的细节信息. 对核大小相同的最大池化和平均池化的输出结果进行矩阵相加操作以整合特征信息,使模型的特征表达更完整. 然后,在生成的每个尺度的特征图末尾使用上采样操作,使其恢复到统一尺寸. 最后,通过拼接3种具有丰富低频信息的特征图,再由$ \operatorname{Conv}_{1,1}(\cdot) $ $ {\boldsymbol{x}_{{\rm{DCB}}}} \in {{\bf{R}}^{C \times H \times W}} $ . 对于输入图像$ {\boldsymbol{x}}_{0}\in {\mathbf{R}}^{C\times H\times W} $
A feature matching and compensation method based on importance weighting for occluded human pose estimation
1
2024
... 由于输入图像质量较差、照度不均,且目标的细节纹理、边缘轮廓等信息难以被充分提取,受文献[27 ]的启发,提出多尺度低级特征提取(MLFE)模块,通过多级卷积、多尺度特征融合和层次化特征提取,增强低级特征的表达能力. 其中,不同大小的卷积核用于捕捉局部细节,结合浅层特征提取和矩阵相加操作,能够强化边缘和纹理信息. 多尺度特征融合确保低级特征在深层网络中被保留并被有效利用,以解决低照度场景下目标细节丢失的问题;浅层特征提取保留了更多原图细节,为后续处理提供了丰富信息. 将MLFE模块应用于特征提取模块的前3个阶段,多尺度地提取特征图的低级细节信息. 然后,将MLFE模块的输出特征图与上采样后尺寸相同的特征图进行拼接,以补偿丢失的细节信息. 由于前3层特征图的感受野依次减小,MLFE模块应用3种尺度的卷积核(3、5、7),以实现多尺度特征提取. $ {\boldsymbol{x}}_{j} $ $ {\boldsymbol{z}}_{j} $
Getting to know low-light images with the Exclusively Dark dataset
1
2019
... 为了验证所提方法的有效性,使其能够应用于实际道路场景下的目标检测,使用公开的低照度目标检测数据集ExDark[28 ] 和自建数据集进行评估. ExDark数据集包含从弱光到黄昏条件的低照度图像,图像中因光照不足导致目标细节丢失且对比度较低. 该数据集共有7 356张图像,涵盖12类目标,包括自行车652张、船679张、瓶子547张、公交车527张、汽车636张、猫735张、椅子648张、杯子519张、狗801张、摩托车501张、行人606张和桌子505张. ...
1
... 自建数据集源自2个自动驾驶数据集,通过抽取样本构建而成. 一是BDD100K数据集[29 ] ,包含总时长超过105 h的高清视频,涵盖各种天气、道路类型和交通情况,并提供了10万张目标边界框图像. 从中抽取1万张背景光照条件为昏暗至黑暗的图像,选取汽车、公交车、自行车、摩托车、行人、货车6类目标. 二是多目标检测与跟踪基准数据集UA-DETRAC[30 ] ,包含训练集83 791张和测试集56 340张图像. 从中抽取1 000张夜间图像,包含汽车、公交车、货车3类目标;将这些图像与BDD100K的1万张图像组合,按8∶1∶1的比例划分为训练集、验证集和测试集. 选择平均精度(AP)来评估模型性能,并对低照度数据集中的所有种类的平均精度加和求平均,作为最终的平均精度均值(mAP);使用每秒帧数(FPS)指标来衡量检测时间成本;分别使用每秒浮点运算次数(FLOPs)和参数量(N p )来衡量计算复杂度和模型大小. ...
UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking
1
2020
... 自建数据集源自2个自动驾驶数据集,通过抽取样本构建而成. 一是BDD100K数据集[29 ] ,包含总时长超过105 h的高清视频,涵盖各种天气、道路类型和交通情况,并提供了10万张目标边界框图像. 从中抽取1万张背景光照条件为昏暗至黑暗的图像,选取汽车、公交车、自行车、摩托车、行人、货车6类目标. 二是多目标检测与跟踪基准数据集UA-DETRAC[30 ] ,包含训练集83 791张和测试集56 340张图像. 从中抽取1 000张夜间图像,包含汽车、公交车、货车3类目标;将这些图像与BDD100K的1万张图像组合,按8∶1∶1的比例划分为训练集、验证集和测试集. 选择平均精度(AP)来评估模型性能,并对低照度数据集中的所有种类的平均精度加和求平均,作为最终的平均精度均值(mAP);使用每秒帧数(FPS)指标来衡量检测时间成本;分别使用每秒浮点运算次数(FLOPs)和参数量(N p )来衡量计算复杂度和模型大小. ...
3
... 在真实低照度数据集ExDark和自建数据集上,对提出的低照度目标检测算法与该领域中的经典算法、最新优化算法进行对比实验. 其中双阶段目标检测网络的代表包括Faster R-CNN、Mask R-CNN,单阶段目标检测网络包括RetinaNet、YOLOv10[31 ] 、YOLOv11[32 ] 、YOLOv12[33 ] ;基于Transformer的目标检测算法有RT-DETR;在最新优化算法中,选择DENet、PE-YOLO、IAT[34 ] 以及WSA-YOLO. 对于上述所有算法,首先在ExDark数据集上进行对比试验,采用mAP指标衡量模型精度,并采用FPS检测和衡量时间成本,实验结果如表1 所示. 所提算法结合了YOLOv12目标检测器,取得了最高mAP值83.4%. 其次,在更有挑战性的自建数据集上,选取表1 中目标检测性能较好的单阶段、双阶段算法以及YOLO系列和最新优化算法进行测试,如表2 所示. 由于自建数据集中目标形状相对复杂,部分目标存在遮挡、模糊等情况,精度有所下降,但是所提算法依然取得了最高精度80.4%,从而验证了其有效性. 性能提升的原因包括:1)所提方法中的细节增强模块捕捉图像中物体的细节,增强了目标与黑暗背景间的对比度;2)多尺度特征提取网络依据图像感受野大小的不同,采用不同尺度的卷积核进行特征提取,并实现了多尺度特征融合;3)多尺度特征相似性匹配网络通过对比原特征图和增强特征图的相似性来对图像中的关键目标进行重要性加权. 因此,所提方法的性能比对比算法有所提升. 但是相应地,此方法的复杂度相对较高,模型的检测速度有所减慢;其FPS在ExDark数据集上为85.0帧/s,在自建数据集上为77.6帧/s. 相比于实时性最好的优化算法DENet,FPS下降了6.0~9.1帧/s;相较于精度次优的算法WSA-YOLO,FPS下降了0.8~2.2帧/s. 虽然检测速度有所下降,但是仍然满足实时性要求. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
4
... 在真实低照度数据集ExDark和自建数据集上,对提出的低照度目标检测算法与该领域中的经典算法、最新优化算法进行对比实验. 其中双阶段目标检测网络的代表包括Faster R-CNN、Mask R-CNN,单阶段目标检测网络包括RetinaNet、YOLOv10[31 ] 、YOLOv11[32 ] 、YOLOv12[33 ] ;基于Transformer的目标检测算法有RT-DETR;在最新优化算法中,选择DENet、PE-YOLO、IAT[34 ] 以及WSA-YOLO. 对于上述所有算法,首先在ExDark数据集上进行对比试验,采用mAP指标衡量模型精度,并采用FPS检测和衡量时间成本,实验结果如表1 所示. 所提算法结合了YOLOv12目标检测器,取得了最高mAP值83.4%. 其次,在更有挑战性的自建数据集上,选取表1 中目标检测性能较好的单阶段、双阶段算法以及YOLO系列和最新优化算法进行测试,如表2 所示. 由于自建数据集中目标形状相对复杂,部分目标存在遮挡、模糊等情况,精度有所下降,但是所提算法依然取得了最高精度80.4%,从而验证了其有效性. 性能提升的原因包括:1)所提方法中的细节增强模块捕捉图像中物体的细节,增强了目标与黑暗背景间的对比度;2)多尺度特征提取网络依据图像感受野大小的不同,采用不同尺度的卷积核进行特征提取,并实现了多尺度特征融合;3)多尺度特征相似性匹配网络通过对比原特征图和增强特征图的相似性来对图像中的关键目标进行重要性加权. 因此,所提方法的性能比对比算法有所提升. 但是相应地,此方法的复杂度相对较高,模型的检测速度有所减慢;其FPS在ExDark数据集上为85.0帧/s,在自建数据集上为77.6帧/s. 相比于实时性最好的优化算法DENet,FPS下降了6.0~9.1帧/s;相较于精度次优的算法WSA-YOLO,FPS下降了0.8~2.2帧/s. 虽然检测速度有所下降,但是仍然满足实时性要求. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
4
... 在真实低照度数据集ExDark和自建数据集上,对提出的低照度目标检测算法与该领域中的经典算法、最新优化算法进行对比实验. 其中双阶段目标检测网络的代表包括Faster R-CNN、Mask R-CNN,单阶段目标检测网络包括RetinaNet、YOLOv10[31 ] 、YOLOv11[32 ] 、YOLOv12[33 ] ;基于Transformer的目标检测算法有RT-DETR;在最新优化算法中,选择DENet、PE-YOLO、IAT[34 ] 以及WSA-YOLO. 对于上述所有算法,首先在ExDark数据集上进行对比试验,采用mAP指标衡量模型精度,并采用FPS检测和衡量时间成本,实验结果如表1 所示. 所提算法结合了YOLOv12目标检测器,取得了最高mAP值83.4%. 其次,在更有挑战性的自建数据集上,选取表1 中目标检测性能较好的单阶段、双阶段算法以及YOLO系列和最新优化算法进行测试,如表2 所示. 由于自建数据集中目标形状相对复杂,部分目标存在遮挡、模糊等情况,精度有所下降,但是所提算法依然取得了最高精度80.4%,从而验证了其有效性. 性能提升的原因包括:1)所提方法中的细节增强模块捕捉图像中物体的细节,增强了目标与黑暗背景间的对比度;2)多尺度特征提取网络依据图像感受野大小的不同,采用不同尺度的卷积核进行特征提取,并实现了多尺度特征融合;3)多尺度特征相似性匹配网络通过对比原特征图和增强特征图的相似性来对图像中的关键目标进行重要性加权. 因此,所提方法的性能比对比算法有所提升. 但是相应地,此方法的复杂度相对较高,模型的检测速度有所减慢;其FPS在ExDark数据集上为85.0帧/s,在自建数据集上为77.6帧/s. 相比于实时性最好的优化算法DENet,FPS下降了6.0~9.1帧/s;相较于精度次优的算法WSA-YOLO,FPS下降了0.8~2.2帧/s. 虽然检测速度有所下降,但是仍然满足实时性要求. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
5
... 在真实低照度数据集ExDark和自建数据集上,对提出的低照度目标检测算法与该领域中的经典算法、最新优化算法进行对比实验. 其中双阶段目标检测网络的代表包括Faster R-CNN、Mask R-CNN,单阶段目标检测网络包括RetinaNet、YOLOv10[31 ] 、YOLOv11[32 ] 、YOLOv12[33 ] ;基于Transformer的目标检测算法有RT-DETR;在最新优化算法中,选择DENet、PE-YOLO、IAT[34 ] 以及WSA-YOLO. 对于上述所有算法,首先在ExDark数据集上进行对比试验,采用mAP指标衡量模型精度,并采用FPS检测和衡量时间成本,实验结果如表1 所示. 所提算法结合了YOLOv12目标检测器,取得了最高mAP值83.4%. 其次,在更有挑战性的自建数据集上,选取表1 中目标检测性能较好的单阶段、双阶段算法以及YOLO系列和最新优化算法进行测试,如表2 所示. 由于自建数据集中目标形状相对复杂,部分目标存在遮挡、模糊等情况,精度有所下降,但是所提算法依然取得了最高精度80.4%,从而验证了其有效性. 性能提升的原因包括:1)所提方法中的细节增强模块捕捉图像中物体的细节,增强了目标与黑暗背景间的对比度;2)多尺度特征提取网络依据图像感受野大小的不同,采用不同尺度的卷积核进行特征提取,并实现了多尺度特征融合;3)多尺度特征相似性匹配网络通过对比原特征图和增强特征图的相似性来对图像中的关键目标进行重要性加权. 因此,所提方法的性能比对比算法有所提升. 但是相应地,此方法的复杂度相对较高,模型的检测速度有所减慢;其FPS在ExDark数据集上为85.0帧/s,在自建数据集上为77.6帧/s. 相比于实时性最好的优化算法DENet,FPS下降了6.0~9.1帧/s;相较于精度次优的算法WSA-YOLO,FPS下降了0.8~2.2帧/s. 虽然检测速度有所下降,但是仍然满足实时性要求. ...
... Comparison of detection accuracy and speed of proposed method, classical algorithms and latest optimized algorithms on ExDark dataset
Tab.1 方法 AP/% mAP/% FPS/−1 ) 自行车 船 瓶子 公交车 汽车 猫 椅子 杯子 狗 摩托车 行人 桌子 Faster R-CNN[8 ] 83.0 72.3 74.6 85.0 82.6 78.6 77.2 81.6 81.0 82.7 81.3 72.0 79.3 71.1 Mask R-CNN[9 ] 87.4 74.4 78.1 87.9 83.1 80.2 80.6 81.0 78.3 76.6 83.2 70.6 80.2 68.5 RetinaNet [10 ] 84.5 73.2 72.7 86.5 80.8 76.8 76.8 75.9 73.4 78.3 76.6 67.1 76.9 74.6 YOLOv10[31 ] 85.2 76.4 82.7 87.4 80.9 75.9 75.3 79.2 82.5 82.3 80.6 74.6 79.8 93.7 YOLOv11[32 ] 87.6 76.9 82.4 87.5 81.2 76.3 77.0 80.9 81.9 79.6 81.0 74.4 80.5 92.7 YOLOv12[33 ] 88.7 76.8 82.0 88.1 81.9 76.0 77.3 81.2 82.4 82.9 81.4 74.7 81.1 91.5 RT-DETR[7 ] 85.1 76.6 81.4 87.0 81.2 75.6 81.3 81.8 82.2 82.8 83.7 70.9 80.8 84.0 DENet[16 ] 85.6 75.2 77.8 84.4 83.5 77.9 78.7 79.5 80.6 83.5 82.3 74.0 80.3 94.1 IAT[34 ] 86.5 75.6 77.4 88.7 83.2 79.6 81.1 80.5 77.6 83.1 80.3 76.4 80.9 88.8 PE-YOLO[18 ] 88.7 75.4 79.8 90.6 83.9 77.8 82.5 82.4 78.7 82.5 80.8 73.4 81.4 91.2 WSA-YOLO[17 ] 88.0 78.8 81.3 92.6 84.6 78.5 80.3 80.9 80.7 84.3 81.9 77.1 82.4 87.2 本研究方法 89.3 81.5 82.6 94.2 86.1 77.6 79.6 82.0 82.9 84.5 83.1 74.2 83.4 85.0
表 2 所提方法与最新优化算法在自建数据集上的检测精度与速度对比 ...
... Comparison of detection accuracy and speed of proposed method and latest optimized algorithms on self-built dataset
Tab.2 方法 AP/% mAP/% FPS/−1 ) 自行车 公交车 汽车 货车 摩托车 行人 RetinaNet [10 ] 76.1 77.6 66.5 64.2 68.8 68.2 70.2 66.0 YOLOv10[31 ] 76.6 79.2 69.1 68.9 73.7 72.9 73.4 82.6 YOLOv11[32 ] 77.3 81.4 69.7 69.3 73.6 73.0 74.0 81.5 YOLOv12[33 ] 79.0 83.1 76.3 75.7 72.0 77.4 77.1 80.3 RT-DETR[7 ] 78.9 80.3 71.9 72.6 71.2 69.9 74.1 76.2 DENet[16 ] 78.7 80.7 74.9 74.3 72.7 74.8 76.0 83.6 IAT[34 ] 81.2 82.6 77.8 76.6 73.9 74.9 77.8 79.4 PE-YOLO[18 ] 80.7 82.4 77.9 79.2 76.4 79.5 79.3 79.9 WSA-YOLO[17 ] 81.6 83.4 79.2 79.3 76.5 78.9 79.8 78.4 本研究方法 82.3 84.0 79.4 77.9 78.6 80.2 80.4 77.6
为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
... Detection accuracy comparison of different algorithms on COCO and DarkFace datasets
Tab.3 方法 COCO数据集 DarkFace数据集 mAP/% FPS/(帧·s−1 ) mAP/% FPS/(帧·s−1 ) YOLOv11[32 ] 54.0 102.6 69.8 79.6 YOLOv12[33 ] 54.4 99.0 71.2 89.3 RT-DETR[7 ] 54.7 90.8 70.7 75.2 IAT[34 ] 54.9 94.8 70.8 86.3 PE-YOLO[18 ] 55.8 98.1 71.8 78.2 WSA-YOLO[17 ] 56.1 96.7 72.4 76.6 本研究方法 56.3 94.1 74.0 75.9
2.4. 消融实验 为了验证各模块的作用,进行消融实验,结果如表4 所示. 首先,将输入图像经过DEM处理后与原图像拼接,并调整通道数,将其输入检测器. 结果显示,加入DEM后模型精度提升了0.8个百分点,证明DEM增强了目标细节特征. 其次,将DEM增强后的图像与原图同时输入MSFE网络,对网络输出的特征图进行拼接并调整通道数后输入检测器. 结果显示,加入MSFE网络后,检测精度在DEM的基础上提升了0.3个百分点,表明MSFE网络有效提取了更多的低级特征. 最后,加入MFSM网络,通过相似度计算对目标特征进行重要性加权和融合处理,将融合后的特征输入检测器. 结果显示,加入MFSM网络后精度进一步提升了1.2个百分点,验证了特征相似性匹配和关键信息加权显著提高了低照度目标检测的准确性. 实验表明,DEM和MSFE、MFSM网络均对模型性能产生了积极作用,但是同时增加了模型大小和复杂度. ...
... Detection performance of different networks with same detector
Tab.7 方法 mAP/% FPS/(帧·s−1 ) DENet[16 ] +YOLOv12 80.7 91.3 IAT[34 ] +YOLOv12 81.5 87.5 PE[18 ] +YOLOv12 82.6 89.4 WSA[17 ] +YOLOv12 83.1 85.6 本研究方法+YOLOv12 83.4 85.1
2.5. 可视化成果展示 为了验证所提DEM和MSFE网络的有效性,根据不同网络模型的权重生成热力图,如图5 所示. 原始图像亮度不足,目标细节被阴影淹没,目标与背景之间的对比度较低,难以分辨. DEM通过细节增强,提升了全局亮度,并放大了目标与背景间的差异. MSFE网络进一步增强了对低级特征的提取能力,使特征图包含更丰富的目标信息,关注到了更远、更暗的物体,从而显著提升了图像的特征表达能力. ...
1
... 为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...
Advancing image understanding in poor visibility environments: a collective benchmark study
1
2020
... 为了验证所提网络的泛化能力,开展交叉数据集验证实验. 除了真实低照度数据集ExDark和自建夜间数据集外,采用常规目标检测数据集COCO[35 ] 和低照度检测数据集DarkFace[36 ] 进行对比实验. 选用经典单阶段目标检测网络YOLOv11、YOLOv12、基于Transformer的实时检测网络RT-DETR及最新优化算法作为对比算法,结果如表3 所示. 所提网络在2个低照度数据集上均取得了良好的检测精度,略高于对比算法. 然而,在COCO数据集上精度提升幅度较小,仅在YOLOv12的基础上提升了1.9个百分点,而在DarkFace数据集上提升了2.8个百分点. 原因在于设计的细节增强模块和多尺度特征提取网络主要优化了夜间低对比度图像,对正常照度的白天图像提升效果有限. 这些结果验证了算法在低照度目标检测上的泛化能力. ...


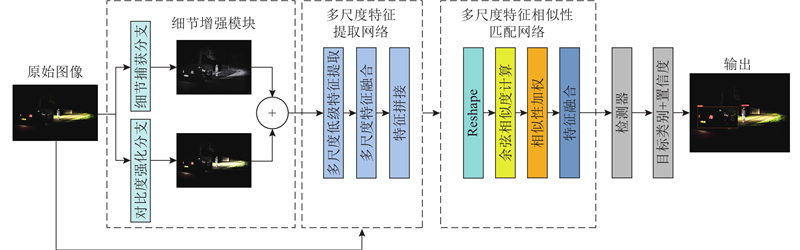
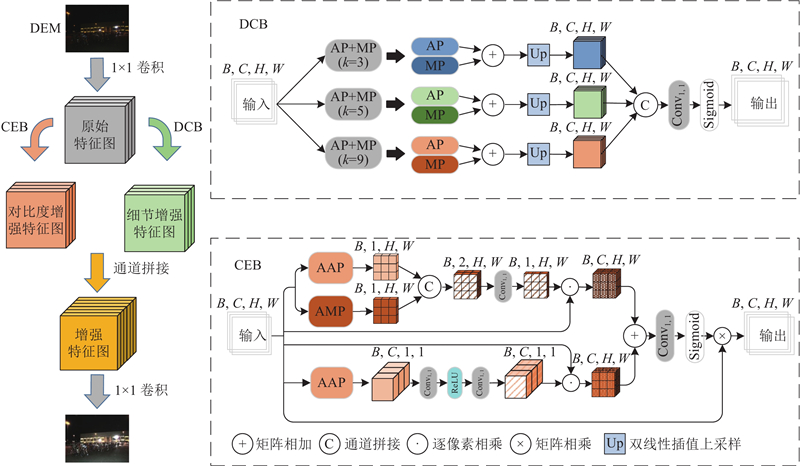
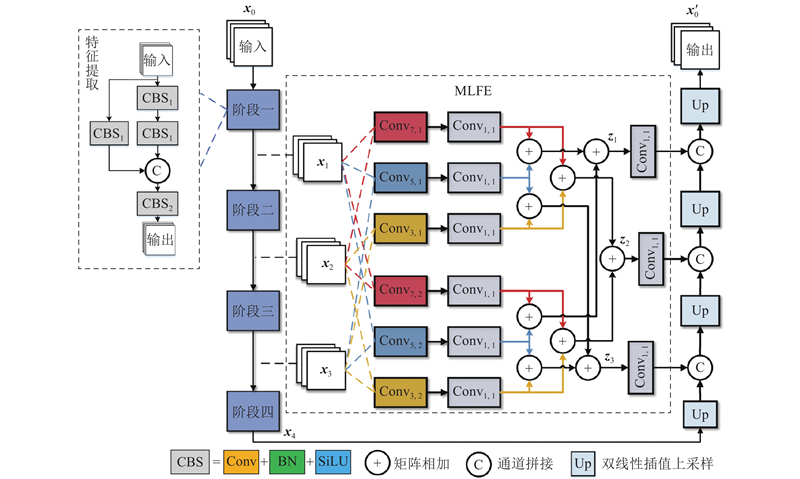
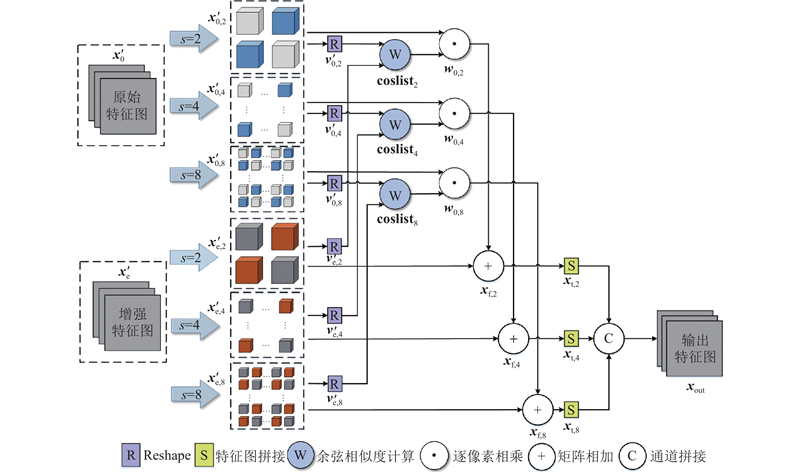

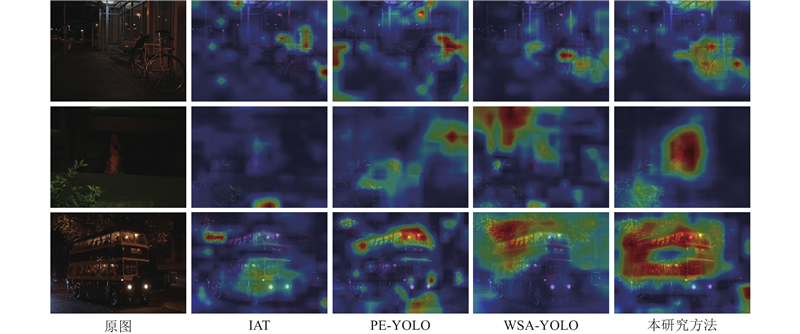


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}