式中:$n \in \{1,2, \cdots ,{N_i}\}$ $i$ $n$ $K_{i,n}^{\rm{q}}$ $K_{i,n}^{\rm{k}} $ $S_{i,n}^{\rm{q}}$ $S_{i,n}^{\rm{k}} $ $P_{i,n}^{\rm{q}}$ $P_{i,n}^{\rm{k}} $ $ {{\bf{head}}_{i,n,j}} $ $j \in \{1, 2, \cdots ,{h_i}\}$ h i i 个阶段性大模块的多头注意力机制的head总数;${\boldsymbol{x}}_{i,n,j}^{\rm{q}} \in{{\bf{R}}^{H_{i,n}^{\rm{q}}{{W}}_{i,n}^{\rm{q}} \times {{C_{i,n}^{\rm{k}}} \mathord{\left/ {\vphantom {{C_{i,n}^{\rm{k}}} {{h_i}}}} \right. }{{h_i}}}}}$ ${\boldsymbol{x}}_{i,n,j}^{\rm{k}} \in {{\bf{R}}^{H_{i,n}^{\rm{k}}{{W}}_{i,n}^{\rm{k}} \times {{C_{i,n}^{\rm{k}}} \mathord{\left/ {\vphantom {{C_{i,n}^{\rm{k}}} {{h_i}}}} \right. } {{h_i}}}}}$ $\;\;{\boldsymbol{x}}_{i,n,j}^{\rm{v}} \in{{\bf{R}}^{H_{i,n}^{\rm{k}}{{W}}_{i,n}^{\rm{k}} \times {{C_{i,n}^{\rm{v}}} \mathord{\left/ {\vphantom {{C_{i,n}^{\rm{v}}} {{h_i}}}} \right. } {{h_i}}}}}$ $ \;\;{\boldsymbol{x}}_{i,n}^{\rm{q}} $ ${\boldsymbol{x}}_{i,n}^{\rm{k}}$ ${\boldsymbol{x}}_{i,n}^{\rm{v}}$ $j$ $ {\boldsymbol{x}}_{i,n}^{\rm{MHSA}} $ ${{\boldsymbol{W}}_0} \in {{\bf{R}}^{C_{i,n}^{\rm{v}} \times C_{i,n}^{\rm{k}}}}$ ${{\boldsymbol{W}}_1} \in {{\bf{R}}^{C_{i,n}^{\rm{k}} \times C_{i,n}^{\rm{ff}}}}$ ${{\boldsymbol{b}}_1} \in {{\bf{R}}^{C_{i,n}^{\rm{ff}}}}$ ${{\boldsymbol{W}}_2} \in {{\bf{R}}^{C_{i,n}^{\rm{ff}} \times C_{i,n}^{\rm{k}}}}$ ${{\boldsymbol{b}}_2} \in {{\bf{R}}^{C_{i,n}^{\rm{k}}}}$ $ C_{i,n}^{\rm{ff}} $
[1]
LIONG S T, GAN Y, SEE J, et al. Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition [C]// Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition . Lille: IEEE, 2019: 1–5.
[本文引用: 4]
[2]
PORTER S, TEN BRINKE L Reading between the lies: identifying concealed and falsified emotions in universal facial expressions
[J]. Psychological Science , 2008 , 19 (5 ): 508 - 514
DOI:10.1111/j.1467-9280.2008.02116.x
[本文引用: 1]
[3]
ZHAO G, PIETIKAINEN M Dynamic texture recognition using local binary patterns with an application to facial expressions
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2007 , 29 (6 ): 915 - 928
DOI:10.1109/TPAMI.2007.1110
[本文引用: 2]
[4]
OJALA T, PIETIKAINEN M, MAENPAA T Multiresolution gray-scale and rotation invariant texture classification with local binary patterns
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2002 , 24 (7 ): 971 - 987
DOI:10.1109/TPAMI.2002.1017623
[本文引用: 1]
[5]
CHAUDHRY R, RAVICHANDRAN A, HAGER G, et al. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 1932–1939.
[本文引用: 1]
[6]
LIU Y, ZHANG J, YAN W, et al A main directional mean optical flow feature for spontaneous micro-expression recognition
[J]. IEEE Transactions on Affective Computing , 2016 , 7 (4 ): 299 - 310
DOI:10.1109/TAFFC.2015.2485205
[本文引用: 1]
[7]
LIONG S T, SEE J, WONG K, et al Less is more: micro-expression recognition from video using apex frame
[J]. Signal Processing: Image Communication , 2018 , 62 : 82 - 92
DOI:10.1016/j.image.2017.11.006
[本文引用: 2]
[8]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Long Beach: Curran Associates Inc, 2017: 6000–6010.
[本文引用: 1]
[10]
XIA B, WANG W, WANG S, et al. Learning from macro-expression: a micro-expression recognition framework [C]// Proceedings of the 28th ACM International Conference on Multimedia . Seattle: ACM, 2020: 2936–2944.
[本文引用: 2]
[11]
XIA B, WANG S. Micro-expression recognition enhanced by macro-expression from spatial-temporal domain [C]// Proceedings of the 30th International Joint Conference on Artificial Intelligence . Montreal: IJCAI, 2021: 1186–1193.
[本文引用: 2]
[12]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 3]
[13]
GAN Y S, LIONG S T, YAU W, et al OFF-ApexNet on micro-expression recognition system
[J]. Signal Processing: Image Communication , 2019 , 74 : 129 - 139
DOI:10.1016/j.image.2019.02.005
[本文引用: 1]
[14]
KHOR H Q, SEE J, LIONG S T, et al. Dual-stream shallow networks for facial micro-expression recognition [C]// Proceedings of the IEEE International Conference on Image Processing . Taipei: IEEE, 2019: 36–40.
[本文引用: 1]
[15]
CHEN B, LIU K, XU Y, et al Block division convolutional network with implicit deep features augmentation for micro-expression recognition
[J]. IEEE Transactions on Multimedia , 2023 , 25 : 1345 - 1358
DOI:10.1109/TMM.2022.3141616
[本文引用: 2]
[16]
DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2016: 2758–2766.
[本文引用: 1]
[18]
ZHANG L, HONG X, ARANDJELOVIĆ O, et al Short and long range relation based spatio-temporal Transformer for micro-expression recognition
[J]. IEEE Transactions on Affective Computing , 2022 , 13 (4 ): 1973 - 1985
DOI:10.1109/TAFFC.2022.3213509
[本文引用: 2]
[20]
FAN Y, JIA M, ZHANG Y, et al. Micro-expression recognition using pre-trained model and Transformer [C]// Proceedings of the IEEE 4th International Conference on Civil Aviation Safety and Information Technology . Dali: IEEE, 2022: 1404–1408.
[本文引用: 1]
[21]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03) [2025-08-05]. https://arxiv.org/abs/2010.11929.
[本文引用: 3]
[23]
ZHOU H, HUANG S, XU Y IncepTR: micro-expression recognition integrating inception-CBAM and vision Transformer
[J]. Multimedia Systems , 2023 , 29 (6 ): 3863 - 3876
DOI:10.1007/s00530-023-01164-0
[本文引用: 2]
[24]
WOO S, PARK J, LEE J Y, et al: CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
[本文引用: 1]
[25]
SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1–9.
[本文引用: 1]
[26]
XUE F, WANG Q, GUO G. TransFER: learning relation-aware facial expression representations with Transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3581–3590.
[本文引用: 1]
[27]
张波, 武瑀繁 基于双分支轻量化网络的微表情识别算法
[J]. 激光与光电子学进展 , 2024 , 61 (14 ): 1437001
[本文引用: 3]
ZHANG Bo, WU Yufan Microexpression recognition algorithm based on a two-branch lightweight network
[J]. Laser & Optoelectronics Progress , 2024 , 61 (14 ): 1437001
[本文引用: 3]
[28]
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4510–4520.
[本文引用: 1]
[29]
NGUYEN X, DUONG C, LI X, et al. Micron-BERT: BERT-based facial micro-expression recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 1482–1492.
[本文引用: 2]
[30]
BAO H, DONG L, PIAO S, et al. BEiT: BERT pre-training of image Transformers [EB/OL]. (2022-09-03) [2025-08-05]. https://arxiv.org/abs/2106.08254.
[本文引用: 1]
[31]
MITCHELL T M. The need for biases in learning generalizations [R]. New Jersey: Rutgers University, 1980.
[本文引用: 1]
[32]
WU H, XIAO B, CODELLA N, et al. CvT: introducing convolutions to vision Transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 22–31.
[本文引用: 1]
[33]
SHREVE M, GODAVARTHY S, GOLDGOF D, et al. Macro- and micro-expression spotting in long videos using spatio-temporal strain [C]// Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognitio n. Santa Barbara: IEEE, 2011: 51–56.
[本文引用: 1]
[35]
GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation [C]// Proceedings of the International Conference on Machine Learning . Lille: JMLR, 2015: 1180–1189.
[本文引用: 1]
[36]
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the International Conference on Machine Learning . Lille: JMLR, 2015: 448–456.
[本文引用: 1]
[37]
SIFRE L, MALLAT S. Rigid-motion scattering for texture classification [EB/OL]. (2014-03-07) [2025-08-05]. https://arxiv.org/abs/1403.1687.
[本文引用: 1]
[38]
LI X, PFISTER T, HUANG X, et al. A spontaneous micro-expression database: inducement, collection and baseline [C]// Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition . Shanghai: IEEE, 2013: 1–6.
[本文引用: 1]
[39]
YAN W, LI X, WANG S, et al CASME II: an improved spontaneous micro-expression database and the baseline evaluation
[J]. PLoS One , 2014 , 9 (1 ): e86041
DOI:10.1371/journal.pone.0086041
[本文引用: 1]
[40]
DAVISON A K, LANSLEY C, COSTEN N, et al SAMM: a spontaneous micro-facial movement dataset
[J]. IEEE Transactions on Affective Computing , 2018 , 9 (1 ): 116 - 129
DOI:10.1109/TAFFC.2016.2573832
[本文引用: 1]
[41]
FU R, HU Q, DONG X, et al. Axiom-based Grad-CAM: towards accurate visualization and explanation of CNNs [C]// Proceedings of the British Machine Vision Conference . [S.l.]: BMVA, 2020: 146.
[本文引用: 1]
[42]
ROSENBERG E L. Introduction: the study of spontaneous facial expressions in psychology [M]// What the face reveals: basic and applied studies of spontaneous expression using the facial action coding system (FACS) (2nd edition) . New York: Oxford University Press, 2005: 3–18.
[本文引用: 1]
4
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
... 式中:${\varepsilon _{xx}}$ ${\varepsilon _{yy}}$ ${\varepsilon _{xy}}$ ${\varepsilon _{yx}}$ [1 ] 可以表示为所有应变分量的平方和的平方根: ...
... Performance comparison of proposed method and existing methods
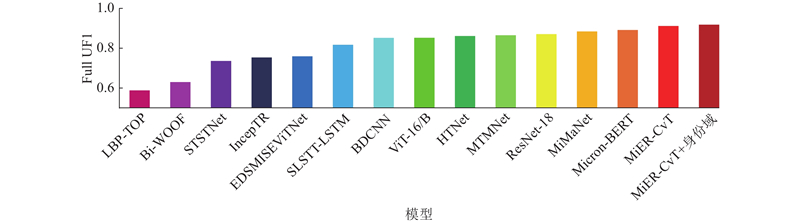
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
Reading between the lies: identifying concealed and falsified emotions in universal facial expressions
1
2008
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
Dynamic texture recognition using local binary patterns with an application to facial expressions
2
2007
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
Multiresolution gray-scale and rotation invariant texture classification with local binary patterns
1
2002
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
1
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
A main directional mean optical flow feature for spontaneous micro-expression recognition
1
2016
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
Less is more: micro-expression recognition from video using apex frame
2
2018
... 微表情通常分为高兴、愤怒、惊讶、悲伤、厌恶和恐惧6种,其持续时间一般只有0.04~0.2 s,远远短于宏表情的0.75~2 s[1 ] . 此外,微表情涉及的脸部区域更小,相关的脸部肌肉运动幅度也非常小[2 ] . 这些特点大大提高了微表情的识别难度. 研究人员最早使用手工特征进行微表情识别,包括外观特征和几何特征2大类. 在基于外观特征的方法中,局部二值模式-三正交平面(local binary pattern-three orthogonal planes, LBP-TOP)算子[3 ] 通过编码时空维度的局部二值模式[4 ] ,能够较好地提取微表情的纹理信息,因此被广泛使用. 在基于几何特征的方法中,光流跟踪是微表情识别的研究热点. 在光流方向直方图(histogram of oriented optical flow, HOOF)[5 ] 的基础上,主方向平均光流(main directional mean optical flow, MDMO)方法[6 ] 选取每个感兴趣区域(region of interest, ROI)中数量最多的光流方向组作为微表情的特征. Liong等[7 ] 以峰值帧与起始帧之间的光应变为全局权重,设计新的双加权方向光流(bi-weighted oriented optical flow, Bi-WOOF)特征,同时证明了峰值帧中蕴含的信息能够在很大程度上表示整个微表情的特征. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
1
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
Micro-attention for micro-expression recognition
1
2020
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
2
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
2
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
3
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
... Comparison of model complexity and performance
Tab.3 模型 N p /MFLOPs/G Full UF1 ViT-16/B[21 ] 86.6 17.6 0.8512 ResNet-18[12 ] 11.7 1.8 0.8696 EDSMISEViTNet[27 ] 3.9 — 0.7587 MiER-CvT 7.5 0.1 0.9102
2.5. 网络结构对比实验 设计并对比具有不同网络结构的模型,在MEGC 2019数据集上的UF1和UAR值如表4 所示. 可以看出,得益于多阶段卷积嵌入层在特征富集和尺度缩小方面的设计,三阶段模型的识别效果明显比单阶段和双阶段模型更好. 此外,表4 中第9行的模型效果远不如第1行,说明大步长的大卷积核在增强模型的微表情识别能力中起到了重要作用. 然而,卷积Transformer层数的增加几乎不会提高模型对微表情的识别能力,甚至会导致能力的衰退,且增大后2个阶段性大模块的嵌入维度只会略微提高微表情的识别效果. 因此,综合考虑模型的准确度和复杂度,将表4 中第1行的配置作为MiER-CvT的网络结构. ...
OFF-ApexNet on micro-expression recognition system
1
2019
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
1
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
Block division convolutional network with implicit deep features augmentation for micro-expression recognition
2
2023
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
1
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
基于改进3D ResNet18的多模态微表情识别
1
2025
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
基于改进3D ResNet18的多模态微表情识别
1
2025
... 目前,基于深度学习的微表情识别方法发展迅猛,主要包含基于卷积神经网络(CNN)和基于Transformer[8 ] 的2类方法. 其中,CNN具有局部性、平移不变性、隐性位置编码和高效计算等特点,在有限的训练资源下也能表现出较好的性能. Wang等[9 ] 在残差结构中添加微注意力模块,同时利用宏表情数据集进行迁移学习. 基于CNN的微表情识别方法MTMNet[10 ] 和MiMaNet [11 ] 以ResNet-18[12 ] 为主干网络,借助宏表情训练的模型来指导微表情模型训练. 为了从光流信息中自动提取有用的微表情特征,Liong团队提出神经网络OFF-ApexNet[13 ] 和STSTNet[1 ] ,前者将峰值帧与起始帧在X 和Y 方向上的光流分别输入网络后拼接为1个特征向量,后者将2个方向的光流与光应变作为整体并输入CNN来提取特征. 此外,讨论了光流值、光流强度、光应变以及灰度值等不同组合的输入对识别结果的影响[14 ] . BDCNN[15 ] 综合考虑峰值帧的X 方向光流、Y 方向光流、光应变和FlowNet[16 ] 光流特征图,在块划分后依靠4个子网络分别提取4种输入的特征,最后拼接在一起用于微表情的识别. 梁岩等[17 ] 提出基于3D ResNet-18模型的多模态微表情分类识别框架,该框架集成了三维注意力机制、参数精简策略和多尺度上下文感知策略. ...
Short and long range relation based spatio-temporal Transformer for micro-expression recognition
2
2022
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
Long short-term memory
1
1997
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
3
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
... Comparison of model complexity and performance
Tab.3 模型 N p /MFLOPs/G Full UF1 ViT-16/B[21 ] 86.6 17.6 0.8512 ResNet-18[12 ] 11.7 1.8 0.8696 EDSMISEViTNet[27 ] 3.9 — 0.7587 MiER-CvT 7.5 0.1 0.9102
2.5. 网络结构对比实验 设计并对比具有不同网络结构的模型,在MEGC 2019数据集上的UF1和UAR值如表4 所示. 可以看出,得益于多阶段卷积嵌入层在特征富集和尺度缩小方面的设计,三阶段模型的识别效果明显比单阶段和双阶段模型更好. 此外,表4 中第9行的模型效果远不如第1行,说明大步长的大卷积核在增强模型的微表情识别能力中起到了重要作用. 然而,卷积Transformer层数的增加几乎不会提高模型对微表情的识别能力,甚至会导致能力的衰退,且增大后2个阶段性大模块的嵌入维度只会略微提高微表情的识别效果. 因此,综合考虑模型的准确度和复杂度,将表4 中第1行的配置作为MiER-CvT的网络结构. ...
HTNet for micro-expression recognition
2
2024
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
IncepTR: micro-expression recognition integrating inception-CBAM and vision Transformer
2
2023
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
基于双分支轻量化网络的微表情识别算法
3
2024
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
... Comparison of model complexity and performance
Tab.3 模型 N p /MFLOPs/G Full UF1 ViT-16/B[21 ] 86.6 17.6 0.8512 ResNet-18[12 ] 11.7 1.8 0.8696 EDSMISEViTNet[27 ] 3.9 — 0.7587 MiER-CvT 7.5 0.1 0.9102
2.5. 网络结构对比实验 设计并对比具有不同网络结构的模型,在MEGC 2019数据集上的UF1和UAR值如表4 所示. 可以看出,得益于多阶段卷积嵌入层在特征富集和尺度缩小方面的设计,三阶段模型的识别效果明显比单阶段和双阶段模型更好. 此外,表4 中第9行的模型效果远不如第1行,说明大步长的大卷积核在增强模型的微表情识别能力中起到了重要作用. 然而,卷积Transformer层数的增加几乎不会提高模型对微表情的识别能力,甚至会导致能力的衰退,且增大后2个阶段性大模块的嵌入维度只会略微提高微表情的识别效果. 因此,综合考虑模型的准确度和复杂度,将表4 中第1行的配置作为MiER-CvT的网络结构. ...
基于双分支轻量化网络的微表情识别算法
3
2024
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
... Comparison of model complexity and performance
Tab.3 模型 N p /MFLOPs/G Full UF1 ViT-16/B[21 ] 86.6 17.6 0.8512 ResNet-18[12 ] 11.7 1.8 0.8696 EDSMISEViTNet[27 ] 3.9 — 0.7587 MiER-CvT 7.5 0.1 0.9102
2.5. 网络结构对比实验 设计并对比具有不同网络结构的模型,在MEGC 2019数据集上的UF1和UAR值如表4 所示. 可以看出,得益于多阶段卷积嵌入层在特征富集和尺度缩小方面的设计,三阶段模型的识别效果明显比单阶段和双阶段模型更好. 此外,表4 中第9行的模型效果远不如第1行,说明大步长的大卷积核在增强模型的微表情识别能力中起到了重要作用. 然而,卷积Transformer层数的增加几乎不会提高模型对微表情的识别能力,甚至会导致能力的衰退,且增大后2个阶段性大模块的嵌入维度只会略微提高微表情的识别效果. 因此,综合考虑模型的准确度和复杂度,将表4 中第1行的配置作为MiER-CvT的网络结构. ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
2
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
... Performance comparison of proposed method and existing methods
Tab.2 方法 Full SMIC CASME Ⅱ SAMM UF1 UAR UF1 UAR UF1 UAR UF1 UAR LBP-TOP[3 ] 0.5882 0.5785 0.2000 0.5280 0.7026 0.7429 0.3954 0.4102 Bi-WOOF[7 ] 0.6296 0.6227 0.5727 0.5829 0.7805 0.8026 0.5211 0.5139 STSTNet[1 ] 0.7353 0.7605 0.6801 0.7013 0.8382 0.8686 0.6588 0.6810 IncepTR[23 ] 0.7530 0.7460 0.6550 0.6500 0.9110 0.8960 0.6910 0.6940 EDSMISEViTNet[27 ] 0.7587 0.7736 0.7372 0.7139 0.8521 0.8461 0.7216 0.6781 SLSTT-LSTM[18 ] 0.8160 0.7900 0.7400 0.7200 0.9010 0.8850 0.7150 0.6430 BDCNN[15 ] 0.8509 0.8500 0.7859 0.7869 0.9501 0.9516 0.8186 0.7994 ViT-16/B[21 ] 0.8512 0.8397 0.8044 0.7994 0.9220 0.9137 0.8142 0.7847 HTNet[22 ] 0.8603 0.8475 0.8049 0.7905 0.9532 0.9516 0.8131 0.8124 MTMNet[10 ] 0.8640 0.8570 0.8640 0.8610 0.8700 0.8720 0.8250 0.8190 ResNet-18[12 ] 0.8696 0.8724 0.7918 0.7982 0.9594 0.9612 0.8820 0.8549 MiMaNet[11 ] 0.8830 0.8760 0.8730 0.8670 0.8810 0.8810 0.8960 0.8840 Micron-BERT[29 ] 0.8903 0.8842 — — — — — — MiER-CvT 0.9102 0.9102 0.8512 0.8547 0.9858 0.9858 0.9080 0.8936 MiER-CvT+身份域 0.9171 0.9192 0.8546 0.8601 0.9928 0.9896 0.9177 0.9064
图 5 所提方法与现有方法在MEGC 2019数据集上的性能对比 ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
1
... 与CNN不同,Transformer更关注事物的整体面貌,能够较好地建模全局关联性. 基于长短程关系的时空Transformer (short and long range relation based spatio-temporal Transformer, SLSTT)[18 ] 将Transformer作为特征提取器,从光流序列中获取有用的空间模式,然后借助长短期记忆(long short-term memory, LSTM)网络[19 ] 进行时空融合. Fan等[20 ] 使用预训练的视觉Transformer (vision Transformer, ViT)[21 ] 来识别微表情,其分类准确率较CNN模型显著提升. Wang等[22 ] 提出HTNet,基于Transformer,先对微表情峰值帧的光流信息进行细粒度的特征提取,然后融合局部的细粒度特征形成粗粒度特征,再从粗粒度特征中提取微表情的全局特征. Zhou等[23 ] 提出双分支网络IncepTR,将拼接了卷积块注意力模块(convolutional block attention module, CBAM)[24 ] 的Inception网络[25 ] 与使用多头自注意力丢弃(multi-head self-attention dropping, MSAD)[26 ] 的ViT网络进行相似度对比和特征融合,对微表情的光流信息实现了多尺度分析. 张波等[27 ] 为MobileViT网络[28 ] 设计MI模块,并通过通道注意力和空间注意力模块分别提取微表情的时间特征和空间特征,提出双流模型EDSMISEViTNet. Micron-BERT[29 ] 在双向图像Transformer编码器表示(bidirectional encoder representation from image Transformers, BEiT)[30 ] 的基础上添加针对微表情的对角线微注意力(diagonal micro-attention, DMA)和感兴趣块(patch of interest, PoI)模块,能够捕捉到更细致的特征变化. 然而,Transformer模型缺乏归纳偏置[31 ] ,通常依靠大参数量来提高模型的能力上限,这往往意味着高昂的训练成本. 微表情作为一种特殊的生理反应,其样本采集和标注工作必须由专业的人员和设备来完成,需要花费大量的时间和精力,导致微表情的数据量匮乏,不利于Transformer模型的训练. 尽管可以在预训练权重的基础上进行微调,但是过少的样本仍然很难实现全参数的最优解. 此外,大参数量也带来了较高的运行成本,难以满足微表情识别任务的实际应用需求. ...
1
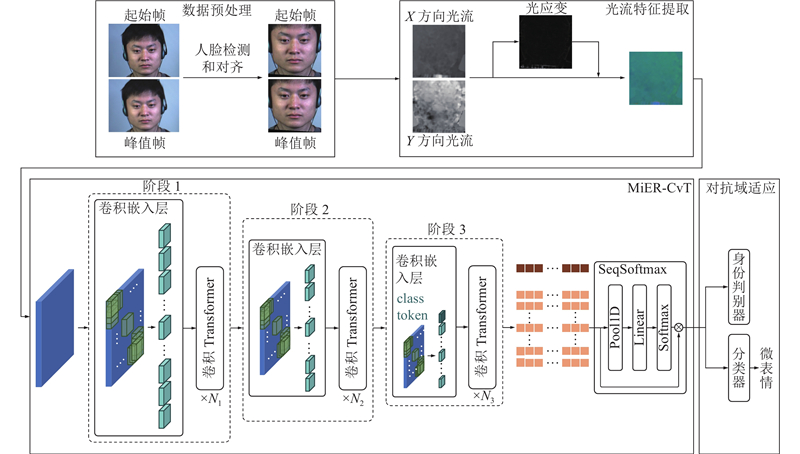
... 为了更好地解决上述问题,提出基于光流和卷积视觉Transformer (convolutional vision Transformer, CvT)[32 ] 的轻量级微表情识别方法,以微表情的峰值帧光流信息作为模型输入,提供简洁可靠的时空特征;设计基于身份域的对抗域适应方法,强化模型的训练过程,减少微表情特征中的无用信息;构建轻型的CNN-Transformer混合模型MiER-CvT,充分发挥2种结构的长处,提高模型的微表情识别性能,同时保持较低的参数量和计算量. ...
1
... 所提方法的整体框架如图1 所示. 首先,对输入的视频序列进行人脸检测和对齐等预处理,得到方向和姿态统一的人脸区域. 其次,估计起始帧与峰值帧之间的光流,进一步计算光应变[33 ] ,将两者拼接后送入MiER-CvT,并通过身份判别器抑制模型学习个人的私有特征,最终由分类器输出微表情识别结果. ...
Farneback光流法在短临预报中的应用
1
2018
... 光流(optical flow, OF)是空间运动物体投影在二维平面上的像素运动的瞬时速度[34 ] . 其基于相邻帧之间的像素变化估计物体的运动信息,通常利用灰度值的变化来描述像素的位移模式. ...
Farneback光流法在短临预报中的应用
1
2018
... 光流(optical flow, OF)是空间运动物体投影在二维平面上的像素运动的瞬时速度[34 ] . 其基于相邻帧之间的像素变化估计物体的运动信息,通常利用灰度值的变化来描述像素的位移模式. ...
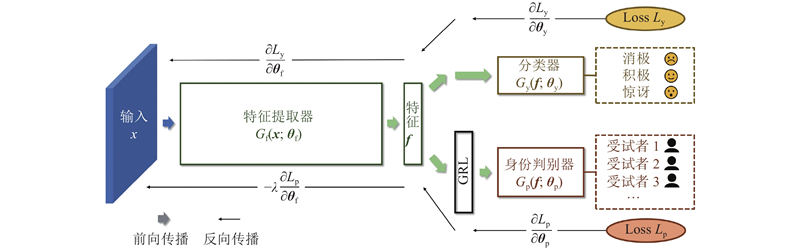
1
... 为了实现常规流程的模型训练,在特征提取器和身份判别器之间加入梯度反转层(gradient reversal layer, GRL)[35 ] . GRL定义了伪函数${R_\lambda }\left( {\boldsymbol{x}} \right)$
1
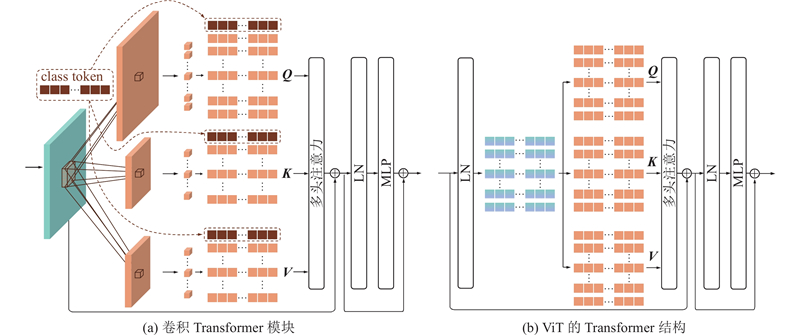
... 卷积Transformer模块结构与ViT的Transformer结构基本类似,但是使用内嵌有批归一化(batch normalization, BN)[36 ] 的深度可分离卷积(depthwise separable convolution, DSC)[37 ] ,取代将输入转变为查询(query)、键(key)和值(value)的全连接线性层,以增强模型的局部表征能力,如图4 所示. ...
1
... 卷积Transformer模块结构与ViT的Transformer结构基本类似,但是使用内嵌有批归一化(batch normalization, BN)[36 ] 的深度可分离卷积(depthwise separable convolution, DSC)[37 ] ,取代将输入转变为查询(query)、键(key)和值(value)的全连接线性层,以增强模型的局部表征能力,如图4 所示. ...
1
... 实验数据集来自2019年人脸微表情挑战赛(facial micro-expression grand challenge 2019, MEGC 2019),由SMIC[38 ] 、CASME Ⅱ[39 ] 和SAMM[40 ] 3个公共的自发微表情数据集整理合并而成,筛选出其中可靠性较高的样本,并将微表情的种类统一划分为消极、积极和惊讶3个大类,具体的样本分布情况如表1 所示. 其中,Full表示全数据集MEGC 2019;CASME Ⅱ和SAMM数据集标注了峰值帧的位置;SMIC数据集没有提供峰值帧的信息,因此选择起始帧与结束帧的中间位置作为每个微表情样本的峰值帧. ...
CASME II: an improved spontaneous micro-expression database and the baseline evaluation
1
2014
... 实验数据集来自2019年人脸微表情挑战赛(facial micro-expression grand challenge 2019, MEGC 2019),由SMIC[38 ] 、CASME Ⅱ[39 ] 和SAMM[40 ] 3个公共的自发微表情数据集整理合并而成,筛选出其中可靠性较高的样本,并将微表情的种类统一划分为消极、积极和惊讶3个大类,具体的样本分布情况如表1 所示. 其中,Full表示全数据集MEGC 2019;CASME Ⅱ和SAMM数据集标注了峰值帧的位置;SMIC数据集没有提供峰值帧的信息,因此选择起始帧与结束帧的中间位置作为每个微表情样本的峰值帧. ...
SAMM: a spontaneous micro-facial movement dataset
1
2018
... 实验数据集来自2019年人脸微表情挑战赛(facial micro-expression grand challenge 2019, MEGC 2019),由SMIC[38 ] 、CASME Ⅱ[39 ] 和SAMM[40 ] 3个公共的自发微表情数据集整理合并而成,筛选出其中可靠性较高的样本,并将微表情的种类统一划分为消极、积极和惊讶3个大类,具体的样本分布情况如表1 所示. 其中,Full表示全数据集MEGC 2019;CASME Ⅱ和SAMM数据集标注了峰值帧的位置;SMIC数据集没有提供峰值帧的信息,因此选择起始帧与结束帧的中间位置作为每个微表情样本的峰值帧. ...
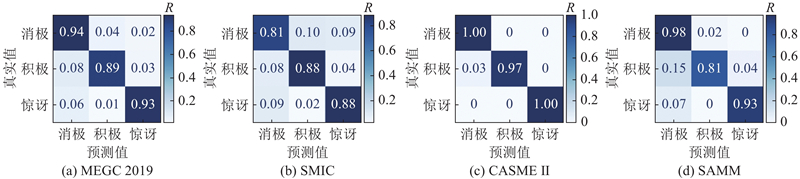
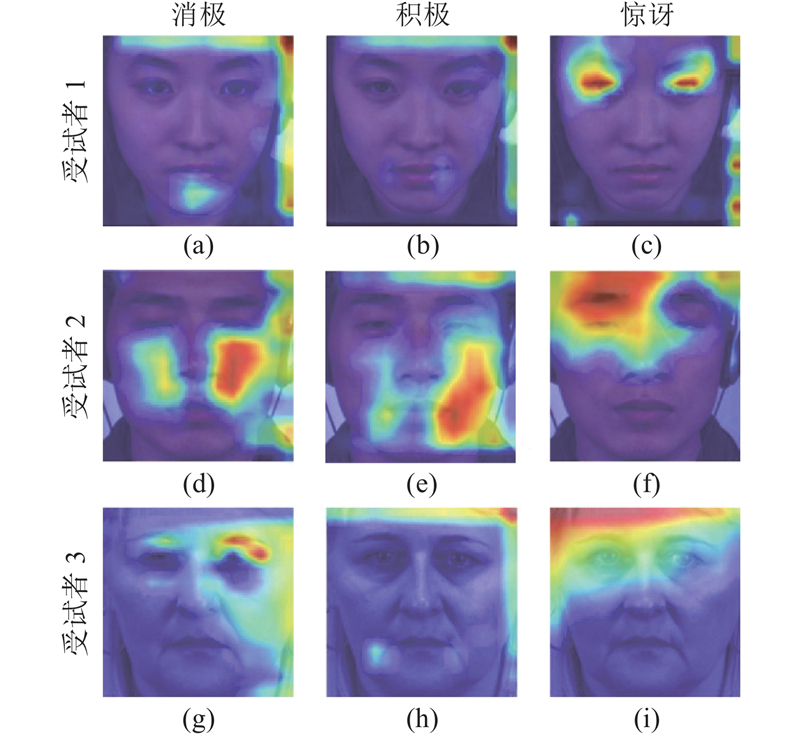
1
... 为了更直观地展现方法的有效性,借助XGrad-CAM方法[41 ] 来可视化所提方法在识别不同微表情时的注意力分布,部分样例如图7 所示. 可以看到,所提方法较为准确地捕捉到了微表情的变化,其关注重点与样本的运动单元标签基本保持一致. 其中,图7 (a)的消极微表情与面部动作编码系统[42 ] 中下唇的向上顶(AU17)强相关;图7 (d)的消极微表情与鼻子的收缩提起(AU9)和上嘴唇的抬起(AU10)强相关;图7 (g)的消极微表情与眼睛的收缩(AU7)强相关;图7 (b)的积极微表情与嘴角的上扬(AU12)强相关;图7 (e)的积极微表情与脸颊的抬起(AU6)和嘴角的上扬(AU12)强相关;图7 (h)的积极微表情与嘴角的上扬(AU12)强相关;图7 (c)的惊讶微表情与外部眉毛的抬起(AU2)强相关;图7 (f)的惊讶微表情与左侧内、外部眉毛的抬起(AU1、AU2)强相关;图7 (i)的惊讶微表情与上眼皮的抬起(AU5)强相关. ...
1
... 为了更直观地展现方法的有效性,借助XGrad-CAM方法[41 ] 来可视化所提方法在识别不同微表情时的注意力分布,部分样例如图7 所示. 可以看到,所提方法较为准确地捕捉到了微表情的变化,其关注重点与样本的运动单元标签基本保持一致. 其中,图7 (a)的消极微表情与面部动作编码系统[42 ] 中下唇的向上顶(AU17)强相关;图7 (d)的消极微表情与鼻子的收缩提起(AU9)和上嘴唇的抬起(AU10)强相关;图7 (g)的消极微表情与眼睛的收缩(AU7)强相关;图7 (b)的积极微表情与嘴角的上扬(AU12)强相关;图7 (e)的积极微表情与脸颊的抬起(AU6)和嘴角的上扬(AU12)强相关;图7 (h)的积极微表情与嘴角的上扬(AU12)强相关;图7 (c)的惊讶微表情与外部眉毛的抬起(AU2)强相关;图7 (f)的惊讶微表情与左侧内、外部眉毛的抬起(AU1、AU2)强相关;图7 (i)的惊讶微表情与上眼皮的抬起(AU5)强相关. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}