

Liu等[16]提出的基于 Kolmogorov-Arnold 定理的KAN(Kolmogorov-Arnold 网络)模型表现出了强大的非线性特征表达能力,能够有效捕捉复杂数据中的潜在模式. 卷积KAN(convolutional Kolmogorov-Arnold network,CKAN)结合卷积操作与可学习的基函数,尤其适用于图像数据的多尺度特征提取[17]. 目前,将KAN网络应用于图像分割领域已有一些初步进展. Li等[18]将KAN嵌入经典U-Net编码-解码链路,提出Tokenized KAN模块的U-KAN网络. Ma等[19]提出将DeepKAN模块用于高维特征精炼,GLKAN模块用于解码器细节恢复,构建端到端遥感分割网络DeepKANSeg网络. Agrawal等[20]融合KAN层与Mamba状态空间模型,构建轻量级3D分割的KAN-Mamba混合网络. 这进一步表明KAN网络对于图像分割领域的适用性.
本文提出基于KAN和CKAN网络的KUNet模型. 用CKAN替换传统卷积层,以增强多尺度特征提取能力. 在解码器上采样过程中,引入KAN层作为特征增强模块. 通过KAN处理编码器特征图,以优化跳跃连接. 引入基于三次样条函数的自适应基函数学习机制. 在4个多模态数据集(LiTS、CORN、DRIVE、Lungs)上的实验验证了模型的性能提升和泛化能力,为处理复杂、多模态数据提供了高效的解决方案.
1. 算法设计
1.1. 网络架构和优化模型KUNet
针对UNet模型在处理复杂特征提取及提高泛化能力方面存在一定局限性的问题,基于UNet基线模型,提出基于KAN与CKAN网络的KUNet模型. 将UNet基线中的编码器和解码器中的传统3×3卷积层替换为CKAN网络. 在解码器的每次上采样后,添加KAN层作为特征增强模块. 在跳跃链接部分,在编码器特征图上应用KAN处理后再与解码器拼接. 引入基于三次样条函数的自适应基函数学习,动态调整KAN和CKAN的基函数.
图 1
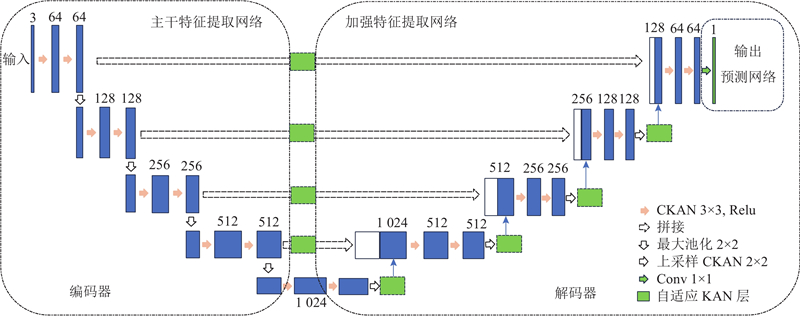
1) 用CKAN替换卷积层. 编码器和解码器中的卷积层被CKAN替换,增强了网络的非线性特性. 在每个CKAN层后,依次添加批归一化、ReLU激活函数和最大池化下采样操作,特征通道数从64逐步增加到1 024. 这样的设计使得模型更适合图像任务中的局部特征提取.
2) KAN特征增强模块. 在解码器中的每次上采样后,插入KAN特征增强模块,用于对上采样后的特征图进行非线性变换,进一步优化特征表达. KAN层的输出表达式为
式中:
3)优化跳跃连接. 传统UNet中的跳跃连接直接拼接编码器和解码器的特征图,这可能导致信息冗余. 提出在跳跃连接中引入KAN进行预处理,使得编码器特征图经过KAN处理后与解码器特征图拼接,拼接后使用3×3卷积调整通道数. 优化后的跳跃连接公式为
式中:
1.2. KAN与CKAN网络
1.2.1. KAN网络
KAN网络基于Kolmogorov-Arnold表示定理[16],核心思想是将输入变量映射到可学习的高维函数空间中,从而有效逼近复杂的非线性函数.
Kolmogorov-Arnold表示定理表明,任何连续的多变量函数
式中:
1.2.2. 卷积KAN网络
图 2
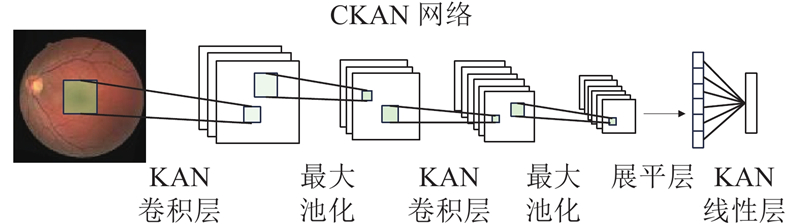
图 2 CKAN网络模型的架构图
Fig.2 Architecture diagram of convolutional Kolmogorov-Arnold network model
KAN卷积与CNN中使用的卷积的主要区别在于内核. 在CNN中,内核由权重组成,而在卷积KAN中,内核的每个元素
在KAN卷积中,内核在图像上滑动并将相应的激活函数
则KAN卷积的定义为
结合卷积操作与KAN的高维函数映射,CKAN能够在图像特征提取中实现更强的表现力和鲁棒性.
1.2.3. KAN/CKAN的计算复杂度分析
传统卷积的计算成本随输入/输出通道数和卷积核面积呈乘法增长. CKAN通过通道内基展开与1×1线性混合,主导开销与基的个数呈线性关系,基本不受空间核大小的影响. 当基数小于卷积核面积时,CKAN在参数量和乘加次数上通常显著低于标准卷积,基函数评估的固定开销在高效实现下可忽略. 例如,在2D UNet常见配置下,CKAN可将参数量和计算量降低约50%,该优势在3D分割中随核体积增大而进一步放大. 尽管基展开导致的瞬时通道放大(输入通道数×基数)会对显存和带宽造成压力,但可以通过分组混合、高分辨率阶段自适应设置更小的基数及融合算子等方式缓解.
2. 数据集及预处理
为了全面评估所提模型在多样化应用场景下的性能,选取4个具有代表性的数据集. 这些数据集涵盖医学影像(肝脏、肺部)与眼科诊断(角膜神经、眼底血管)领域,旨在测试模型在不同任务类型和数据结构下的分割能力. 利用这些数据集能够验证模型的鲁棒性和泛化能力. 各数据集的详细信息可以参照表1.
表 1 数据集的统计表
Tab.1
| 数据集 | 样本数量 | 分辨率 | 分割目标 |
| LiTS | 400 | 512×512 | 肝脏 |
| CORN | 384×384 | 角膜神经 | |
| DRIVE | 20 | 565×584 | 眼底血管 |
| Lungs | 200 | 512×512 | 肺 |
LiTS(Liver Tumor Segmentation Challenge)数据集包含400张肝脏CT/MRI图像,主要用于医学影像中的器官分割任务. 该数据集中存在器官形态变异及图像噪声,要求模型具备较强的鲁棒性和抗噪能力. 由于肝脏分割精度直接影响后续诊断和治疗方案的制定,该数据集中复杂的解剖结构和病理表现对模型的医学影像分割性能提出了显著挑战[23].
CORN数据集包含1 238张角膜神经图像[14],这些图像中的神经结构极为纤细,使得精确分割成为关键难题. 由于角膜神经的准确分割对眼科诊断,尤其是早期角膜疾病检测,具有重要的临床价值,因此要求分割模型必须具备出色的局部细节提取能力.
DRIVE数据集包含20张眼底血管图像[15]. 尽管样本数量有限,但每张图像均蕴含复杂的纹理与细节,这使得该数据集成为评估模型在小样本下性能的理想选择. 该数据集的核心挑战是如何在数据稀缺的条件下,保证分割结果的精度与稳定性.
Lungs数据集源自2017年Kaggle图像分割竞赛的2D部分,提供200张2D肺部病灶图像. 该任务专注于肺部病灶的精确分割,在肺部疾病早期诊断中具有广泛应用. 这类图像通常展现出较强的结构化特征,因此要求模型能够有效识别并精确分割不同类型的病变区域,保持较高的分割精度和召回率.
为了确保数据处理的一致性并提升模型的训练效果,对所有数据集进行统一的标准化预处理:将像素归一化至[0,1.0],图像随机裁剪至512×512分辨率,以适配模型输入并降低计算负担. 同时,为了增强模型的泛化能力和鲁棒性,实施随机水平与垂直翻转增强(概率均为0.5),有助于模型学习图像的空间变换特性. 在数据集划分方面,所有数据均严格遵循70%训练集、15%验证集和15%测试集的比例,旨在利用现有数据并确保模型在独立测试集上的泛化能力.
3. 实验与分析
3.1. 评估指标
使用Dice系数,评估模型的分割精度. Dice系数用于衡量预测区域
该指标特别适用于医学图像分割任务,尤其是在处理类不平衡问题时,Dice系数能够反映前景区域的分割质量. 当处理肝脏、肺部或眼科等医学影像时,Dice系数常被用来衡量模型的性能[26].
交并比(IoU)作为另一种常用指标,通过计算预测区域与真实区域的交集与并集的比值来衡量分割效果[27],公式为
IoU在自动驾驶、视频监控及医学影像等领域中被广泛应用,尤其在处理复杂目标和背景时,它能够提供比Dice系数更细致的性能评估.
为了更好地衡量优化模型与基线模型在相同训练周期下的性能差距,定义最大性能差异(maximum absolute performance gap,MAPG)指标:
式中:
在图像分割任务中,模型性能在经过充分训练后,常常在常规指标(如Dice系数与交并比IoU)上趋近饱和值(即接近1.0). 在这种情况下,尽管模型在优化后相较于基线模型仍有性能提升,但传统的绝对指标(如Dice增加了0.002)往往难以有效反映优化的真实效益.
为了更合理地评估在高性能区间的相对提升效果,引入归一化相对提升指标
式中:
式(10)将性能的绝对提升值(即
本次实验采用
3.2. 损失函数与模型训练
为了优化分割效果,采用Dice损失与交叉熵损失相结合的混合损失函数,以利用两者在处理类不平衡问题上的互补优势[28]. 混合损失函数的定义为
其中,
交叉熵损失的公式为
式中:Pc为当前像素属于类别c的概率;Gc表示真实标签的指示器,即表示对于当前像素,真实类别是否为c.
该损失函数的设计能够有效解决不同数据集中的类不平衡问题,通过优化预测区域
实验基于PyTorch框架开展,训练平台为NVIDIA RTX 4070Ti Super显卡(16 GB显存). 训练的超参数配置如下:初始学习率设定为10−4,采用余弦退火调度策略[29],最小学习率为10−6;批次大小设为8,以保证稳定的梯度更新;优化器选择Adam,参数设置为
3.3. 模型可视化分割结果的对比分析
图 3
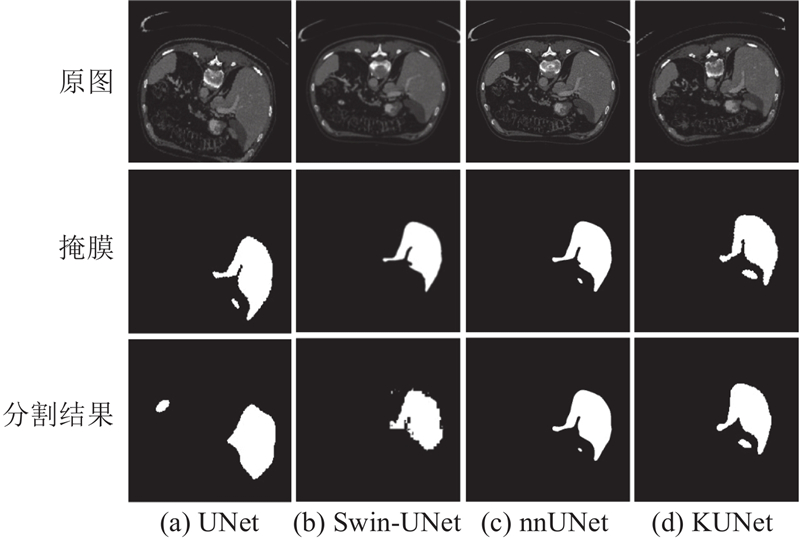
图 4
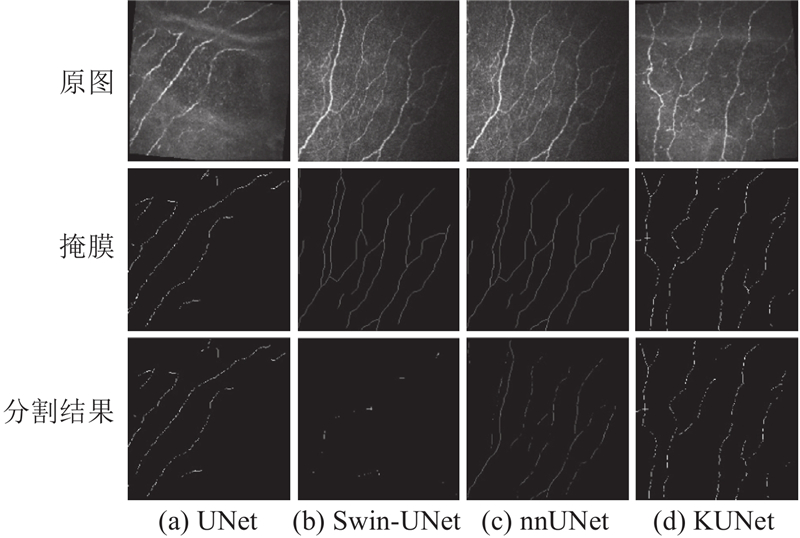
图 5
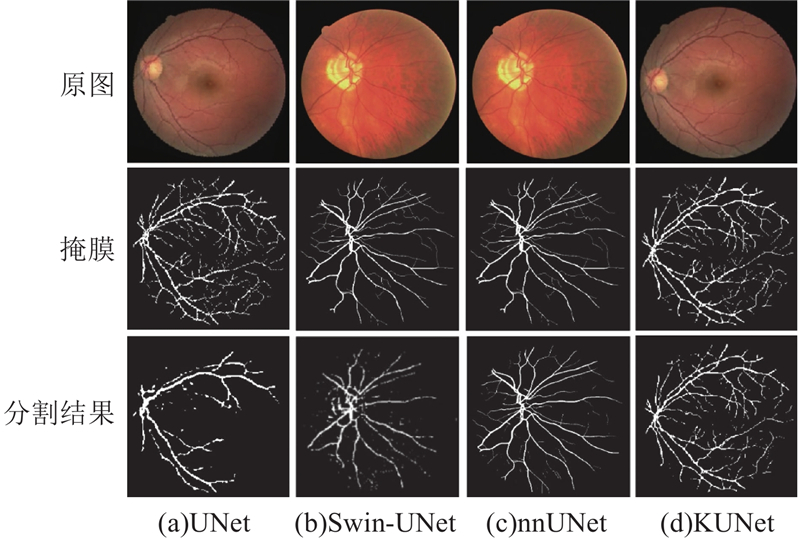
图 6
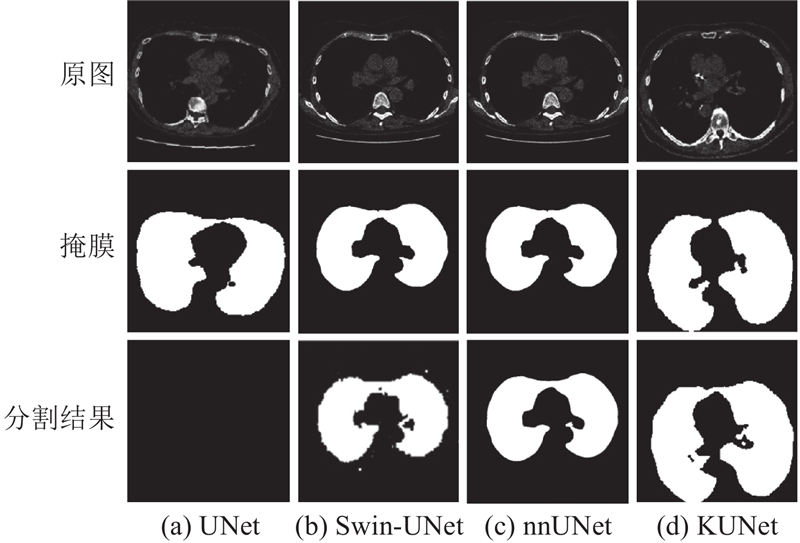
如图3所示,在LiTS数据集的分割结果中,相较于传统UNet、Swin-UNet及nnUNet,所提出的KUNet模型展现出更优的性能. 从可视化结果分析可知,UNet虽能初步定位肿瘤区域,但边界细节处理模糊,且部分微小区域存在遗漏,表明其在复杂结构特征提取方面存在局限. Swin-UNet借助自注意力机制增强了全局信息建模能力,但分割边界不平滑,并伴随一定程度的块状伪影. nnUNet在结构连续性与边缘准确性方面取得显著提升,分割区域相对完整,但在处理细微结构时存在轻微的像素偏移. KUNet在分割区域提取中展现出更优异的边界贴合度与精确的形状保持能力.
如图4所示,在CORN数据集上的分割结果对比中,各模型间的性能差异显著. UNet模型在提取角膜神经结构时存在明显的漏检现象,尤其是在图像细节部分,分割不连贯,致使部分关键细节丢失. 引入自注意力机制后,Swin-UNet在CORN数据集上的分割能力大幅下降,不能实现有效的分割. 与UNet和Swin-UNet相比,nnUNet模型具备更佳的分割边界连续性,但在处理复杂细节时,存在边界模糊和部分细微结构缺失的问题. 相较而言,KUNet模型在此任务中表现尤为出色,分割结果高度完整,边界保持连贯且细节捕捉更清晰. 尤其在角膜神经的纤细分支区域,KUNet能够更精确地捕捉到丰富的细节,有效抑制噪声干扰.
如图5所示,在DRIVE数据集上,各模型分割性能呈现显著差异. UNet虽能捕捉眼底图像中的主要血管结构,但细节处理存在模糊与遗漏,尤其在纤细血管分割精度上不足. Swin-UNet在引入自注意力机制后,虽在大范围血管结构提取上有所改善,但面对复杂交错血管区域时难以有效处理细节,导致分割边界不连续. nnUNet在血管结构分割精度上有所提升,边界更为连贯,但在处理特定复杂交错血管(尤其是图像边缘与血管分叉处)时灵活性不足. KUNet在该任务中表现最优,分割结果细节清晰且边界连贯,尤其在分支血管捕捉上展现出超越其他模型的精确性,能够高效处理纤细与复杂血管结构,有效避免遗漏与伪分割现象.
如图6所示,在Lungs数据集上各模型呈现显著性能差异. 短周期训练下,UNet甚至未能生成有效分割结果. Swin-UNet虽利用Transformer自注意力机制提升了对大范围结构的捕捉能力,但分割边界处理欠佳,尤其在细小区域分割中出现断裂,导致细节丢失. nnUNet通过结构改进实现了最精确的分割结果,尤其在整体轮廓上呈现出更强的连贯性. KUNet虽在某些方面(如整体轮廓的最高精确度)略逊于nnUNet,但展现了强大的分割性能,不仅在肺部整体区域提取上表现精准,且在细节处理上表现出色,尤其在较小或复杂形状的肺区域能够保持较高的边缘清晰度,有效避免了其他模型常见的漏检与伪分割问题.
综上所述,在4个典型医学图像分割数据集(LiTS、CORN、DRIVE及Lungs)上的实验结果表明,各模型在不同任务中展现出差异化的性能特征. UNet作为基础模型具备一定的结构识别能力,但在复杂场景中常出现边界模糊、细节缺失与小结构漏检等问题,尤其在CORN与DRIVE这类对细节要求较高的数据集上表现相对较弱. 引入Transformer后,Swin-UNet的全局建模能力有所增强,在结构复杂区域(如LiTS与Lungs数据集)能够提取更多上下文信息,但受限于高计算成本与局部连接弱化,在小尺度目标分割与边缘连续性上仍显不足. nnUNet通过自适应网络配置机制显著提升了模型泛化性,在各数据集上均表现稳定,尤其在DRIVE与CORN数据集上边界保持能力较强,但在处理高复杂度场景时存在潜在的过拟合风险或形态偏差. 所提出的KUNet模型综合了多尺度特征融合与边缘感知机制,在所有数据集上均取得最优或近最优的分割效果,尤其在肿瘤、神经与血管等复杂结构识别中展现出卓越的边界精度、细节完整性与鲁棒性,验证了该模型作为优化方案在多类型医学图像分割任务中的有效性与通用性.
3.4. 模型性能曲线的对比分析
图 7
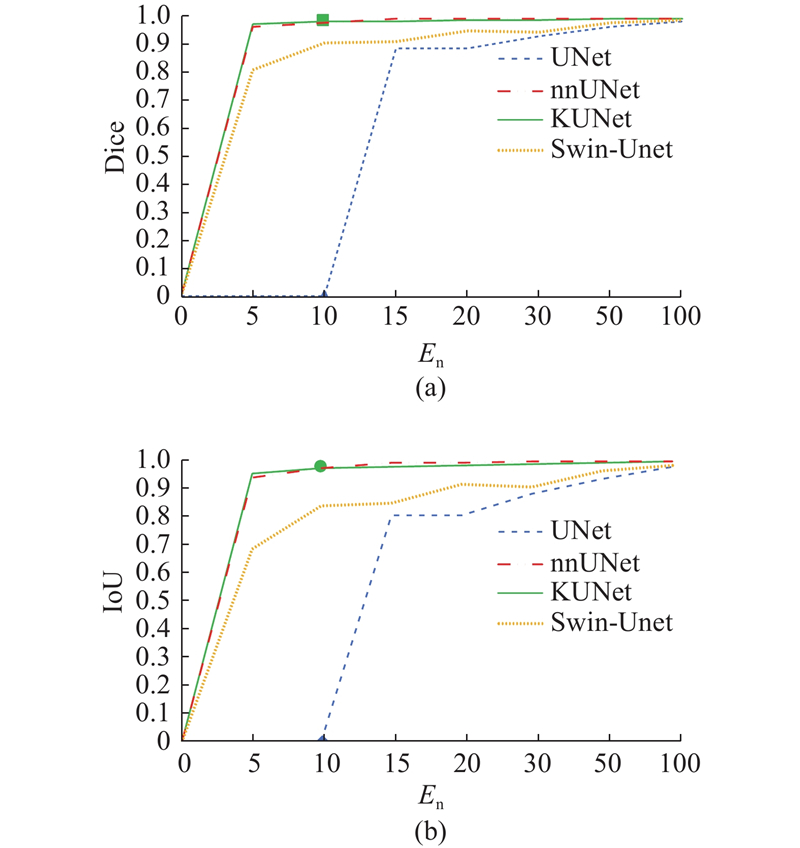
图 7 UNet、KUNet、nnUNet、Swin-UNet模型在LiTS数据集上的性能曲线
Fig.7 Performance curve of UNet, KUNet, nnUNet and Swin-UNet model on LiTS dataset
图 8
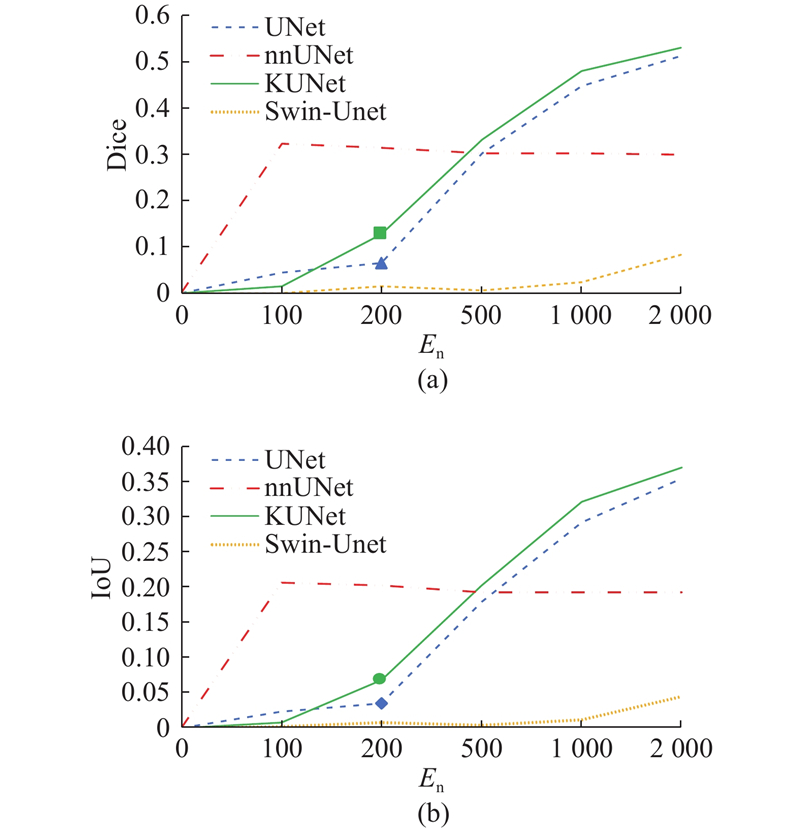
图 8 UNet、KUNet、nnUNet、Swin-UNet模型在CORN数据集上的性能曲线
Fig.8 Performance curve of UNet, KUNet, nnUNet and Swin-UNet model on CORN dataset
图 9
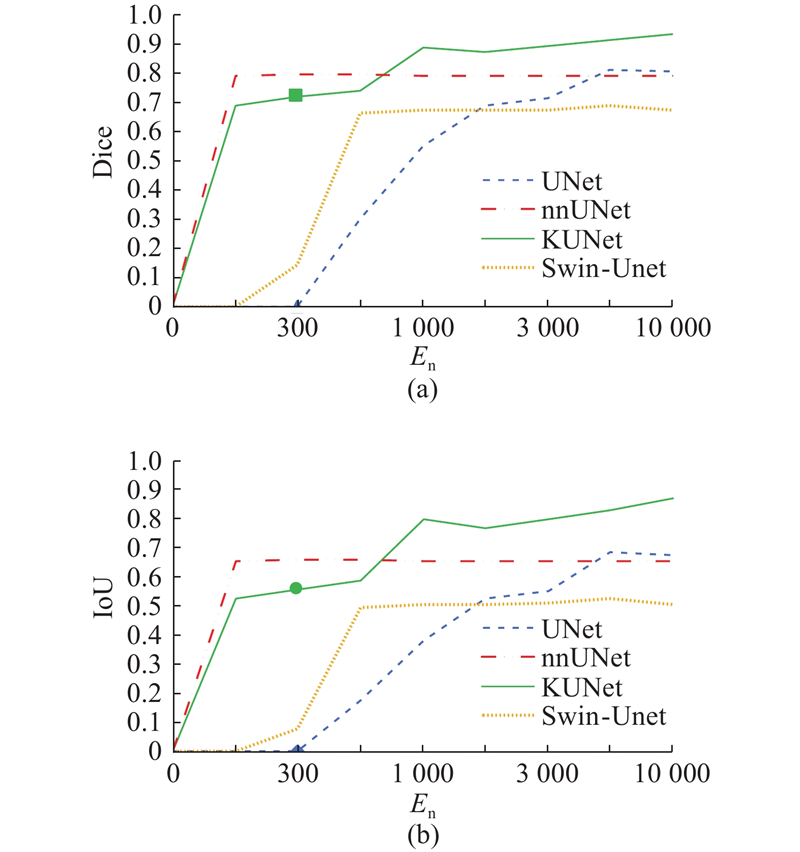
图 9 UNet、KUNet、nnUNet、Swin-UNet模型在DRIVE数据集上的性能曲线
Fig.9 Performance curve of UNet, KUNet, nnUNet and Swin-UNet model on DRIVE dataset
图 10
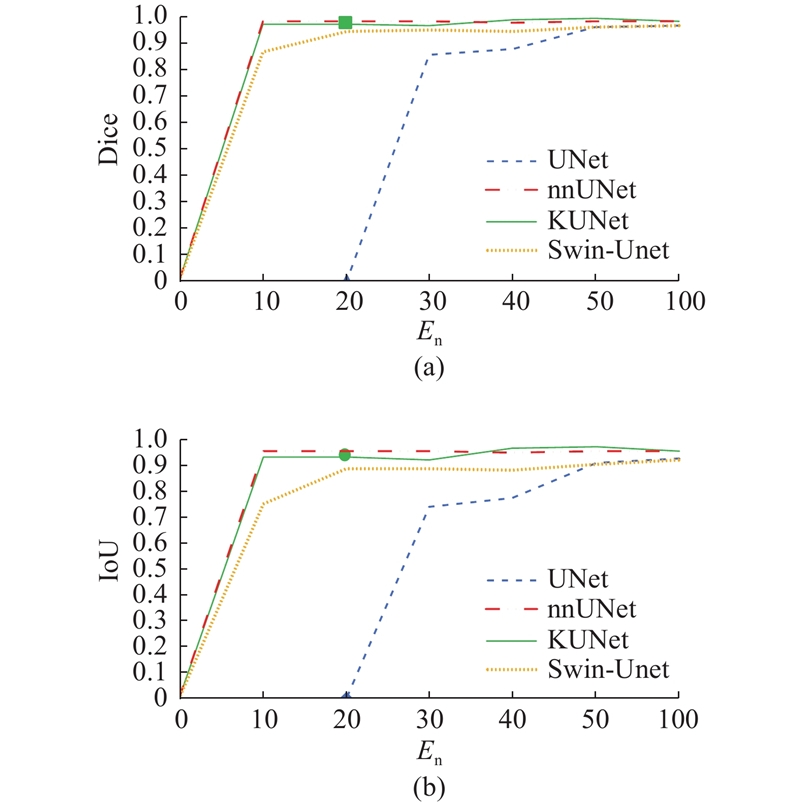
图 10 UNet、KUNet、nnUNet、Swin-UNet模型在Lungs数据集上的性能曲线
Fig.10 Performance curve of UNet, KUNet, nnUNet and Swin-UNet model on Lungs dataset
如图7所示为各模型在LiTS数据集上的性能曲线对比结果. KUNet模型在LiTS数据集上表现出优于其他对比模型的性能. Dice系数和IoU曲线表明,KUNet在训练初期便超越UNet、nnUNet和Swin-UNet,并在后续训练过程中持续保持领先优势,最终2项指标均接近1,展现出良好的拟合能力与泛化性能. UNet的性能提升缓慢,最终Dice系数和IoU均处于较低水平,表明该模型在处理复杂医学图像分割任务时存在明显的局限性. Swin-UNet虽然通过引入自注意力机制获得了一定的性能提升,但在训练过程中性能波动较大,收敛稳定性有待改善.
如图8所示为各模型在CORN数据集上的性能曲线对比结果. KUNet在Dice和IoU 2项评价指标上均展现出显著优势. 具体而言,nnUNet虽然在训练初期呈现较快的收敛特性,但最终分割性能不仅低于UNet,且与KUNet存在明显差距. Swin-UNet尽管引入Transformer架构以增强全局上下文信息的捕获能力,但在CORN数据集上的分割效果欠佳,几乎未能进行有效地分割.
如图9所示为各模型在DRIVE数据集上的性能曲线对比结果. KUNet展现出最优的分割性能,Dice系数与IoU系数均显著优于其他对比模型. 具体而言,KUNet在训练初期便实现Dice与IoU系数的快速提升,尽管在前期收敛速度略低于nnUNet,但最终两项指标均达到最高值,体现出优异的收敛特性与鲁棒性. UNet的性能提升较缓慢且波动显著,最终稳定于较低水平,暴露出该模型在此任务中的固有局限性. nnUNet前期分割性能略优于UNet,后期Dice与IoU系数虽然有所提升,但整体收敛速度不及KUNet. Swin-UNet在训练早期呈现较快上升趋势,但后续增长趋缓,最终性能未能超越KUNet与nnUNet. 综上所述,KUNet在DRIVE数据集上兼具快速收敛能力与高精度稳定性,充分验证了其在视网膜血管分割任务中的优越性.
如图10所示为各模型在Lungs数据集上的性能曲线对比结果. KUNet与nnUNet均在训练早期迅速达到较高性能水平,并在中后期保持稳定. nnUNet的最终性能略低于KUNet,验证了KUNet在分割精度与稳定性方面的优势. UNet的训练过程呈现明显的性能滞后特征:前20轮迭代内Dice与IoU系数近乎为零,直至中后期才出现显著增长,暴露出其在特征提取与边界定位方面的固有缺陷. Swin-UNet虽然依托Transformer架构展现出良好的整体收敛趋势,且早期性能提升迅速,但收敛阶段略有延迟,最终性能不及KUNet与nnUNet.
综合CORN、DRIVE、LiTS及Lungs 4个典型医学图像分割数据集上的性能曲线图可知,所提出的KUNet模型在Dice与IoU两项关键评价指标上均展现出显著优势. 从整体趋势分析,KUNet于训练初期即呈现快速收敛特性,并在中后期保持稳定增长,于全部4个数据集上均达到或接近最优性能,体现了其卓越的全局上下文建模与细节表征能力. nnUNet的性能曲线相对平稳,具备一定的泛化能力,但在收敛速度与最终精度方面均略逊于KUNet. Swin-UNet凭借自注意力机制在特定训练阶段实现了性能的快速增长,然而收敛阶段存在波动性,稳定性不足. 综上所述,KUNet在4个数据集上均实现了更快的收敛速度、更高的分割精度及更强的鲁棒性,充分验证了其在多种医学图像分割任务中的通用性与优越性.
3.5. 性能对比分析
表 2 KUNet模型与UNet基线模型在各数据集上的最大性能差距
Tab.2
| 数据集 | 周期 | Dice | MAPG1 | IoU | MAPG2 | ||
| UNet模型 | KUNet模型 | UNet模型 | KUNet模型 | ||||
| LiTS | 10 | 0 | 0 | ||||
| CORN | 200 | ||||||
| DRIVE | 300 | 0 | 0 | ||||
| Lungs | 10 | 0 | 0 | ||||
| 均值 | — | — | — | — | — | ||
表2呈现了KUNet模型相对于UNet基线模型的性能提升幅度(MAPG). 结果表明,KUNet在不同数据集上的性能增益存在显著差异. 具体而言,在LiTS数据集上,Dice系数(MAPG1)与IoU系数(MAPG2)的性能提升分别达到
综上所述,实验结果表明,KUNet模型在多个数据集上均较UNet基线模型获得了显著的性能提升,尤其是在早期训练阶段,KUNet模型能够更快地达到更高的性能水平. 尽管在部分复杂数据集(如CORN)上,KUNet的优化效果相对有限,但总体而言,KUNet模型展现出更强的适应性和更高的分割精度.
为了评估所提优化策略的有效性,在LiTS、CORN、DRIVE和Lungs4个数据集上对nnUNet、Swin-UNet、UNet及KUNet模型进行了训练与测试,并采用标准评估指标进行性能量化. 为系统化分析KUNet模型相对于对比模型的性能差异,定义相对提升指标
表 3 UNet、KUNet、nnUNet、SWin-UNet模型在各数据集上的最佳性能
Tab.3
| 网络模型 | Dice | IoU | |||||||
| LiTS | CORN | DRIVE | Lungs | LiTS | CORN | DRIVE | Lungs | ||
| UNet | |||||||||
| nnUNet | |||||||||
| Swin-UNet | 0.043 | ||||||||
| KUNet | |||||||||
表3展示了各模型在不同数据集上的最终分割性能. 结果表明,KUNet在多数数据集上均展现出显著优势,验证了所提优化策略的有效性. 具体而言,在LiTS数据集上,KUNet取得Dice系数
为了对比各模型的计算效率,统计各模型达到最佳性能时所需的训练周期数及相应的训练时间,如表4所示. 其中,
表 4 UNet、KUNet、nnUNet、Swin-UNet模型在各数据集上的计算效率
Tab.4
| 数据集 | ||||||||
| LiTS | 100 | 100 | 100 | 100 | 557.11 | 544 | 998.17 | |
| CORN | 2000 | 100 | 2000 | 2000 | ||||
| DRIVE | ||||||||
| Lungs | 100 | 100 | 100 | 50 | 262.87 | 383 | 241.84 |
从表4可以看出,不同模型在效率与性能权衡方面存在显著差异. UNet在LiTS与Lungs数据集上展现出相对较快的训练速度,尤其在Lungs数据集上仅需262.87 s. 在CORN与DRIVE数据集上,该模型需要较多的训练轮次(分别为
综上所述,KUNet在多数数据集上取得了优异性能,但在LiTS数据集上略逊于nnUNet. 经分析可知,该差异主要源于模型针对特定数据集的适配策略不同,而非主干网络表达能力不足. nnUNet的优势在于其针对腹部CT影像的自适应处理流程. 通过自动调整体素间距与重采样方案,处理各向异性分辨率. 利用强度归一化与软组织窗口化技术,增强对比度. 采用前景优先采样策略、Dice与交叉熵联合损失函数及深度监督机制,应对类别不平衡问题并提升小病灶检出率. 运用级联策略实现粗定位与精细化分割,增强对形态变异与噪声的鲁棒性. 通过优化的数据增强(强度偏移、伽马变换、弹性形变)、推理策略(滑窗预测、测试时增强、2D/3D集成)及后处理(连通域过滤、空洞填充),抑制假阳性. 上述策略对于处理LiTS数据集中形态变异显著、噪声突出、前景稀疏等问题具有关键作用,使得nnUNet在该数据集上表现出优势.
KUNet在CORN数据集上的性能提升有限,可能原因如下. 1)KAN模块的可训练基函数在处理极细目标结构时存在适应性限制,影响特征映射质量. 2)CKAN的感受野设计侧重多尺度特征提取,对于微小且密集分布的神经末梢,可能出现覆盖不足或特征稀释的现象. 3)当前模型缺乏针对角膜神经细结构的专门优化机制(如局部上下文建模或细节增强模块). 后续研究可以考虑引入轻量级局部注意力机制、基函数尺度自适应调节或基于形态学先验的细结构引导策略,提升模型在细小目标分割任务中的性能与泛化能力.
KUNet在部分任务中训练效率下降的问题主要源于CKAN与KAN模块的较高计算复杂度. CKAN虽然增强了多尺度特征提取能力,但复杂的核函数计算与多通道交互操作增加了计算开销. 编码器与解码器中引入的KAN层虽然提升了细节保留与特征融合能力,但基于可训练基函数的非线性表达机制导致计算量显著增加. 针对该问题,可以采用以下优化策略:通道剪枝、低秩分解(用于压缩CKAN卷积核与KAN参数矩阵)、KAN模块稀疏化或知识蒸馏等轻量化方法;或将CKAN替换为深度可分离卷积结构,以降低推理与训练成本.
3.6. 消融实验
为了评估KUNet模型中各优化模块的具体贡献,在LiTS数据集上设计消融实验. KUNet在UNet基线模型的基础上引入3项关键改进:在跳跃连接中嵌入KAN层,在解码器上采样后引入KAN层,以及采用CKAN替代传统卷积层. 实验采用控制变量法,每组实验仅变更单一模块,其余配置均与完整的KUNet模型保持一致. 在与主实验相同的训练配置下,对以下4种变体模型进行评估,结果如表5所示. 1)变体A:移除跳跃连接中的KAN层. 2)变体B:移除解码器上采样后的KAN层. 3)变体C:将所有CKAN层替换为传统的双卷积模块. 4)变体D:将自适应基函数(三次样条函数)替换为固定基函数,即冻结基函数参数(线性层权重),仅学习共享系数.
表 5 不同模块配置下的消融实验结果比较
Tab.5
| 模型 | Dice | IoU |
| 完整KUNet | ||
| 变体A | ||
| 变体B | ||
| 变体C | ||
| 变体D |
变体A的Dice系数与IoU分别下降
上述消融实验结果定量验证了各优化模块对KUNet性能的贡献程度. 其中,CKAN层贡献最显著,证实了其在多尺度特征提取中的核心作用. 跳跃连接中的KAN层次之,验证了其在特征融合阶段的有效性. 自适应基函数机制表现出明显的优势,体现了数据自适应学习的必要性. 解码器上采样后的KAN层贡献相对有限,但保留了一定的性能提升潜力. 综上所述,4项优化模块的协同作用共同构成了KUNet的性能优势.
4. 结 语
提出基于KAN与CKAN的UNet优化模型KUNet. 该模型采用CKAN模块替代传统卷积层,结合特征增强机制、优化的跳跃连接与自适应基函数策略,有效提升了模型的非线性表达能力与细节还原能力. 在4个多模态数据集上的实验表明,该模型在Dice和IoU等评价指标上均优于对比模型,尤其在小样本和短周期训练条件下展现出更高的分割精度与泛化能力. 尽管训练时间有所增加,但考虑到性能的显著提升,该计算开销在可接受范围内. 后续研究将重点关注模型的轻量化设计,以提升性能并推动模型在实际应用场景中的部署.
参考文献
Image segmentation using deep learning: a survey
[J].
A survey on deep learning in medical image analysis
[J].DOI:10.1016/j.media.2017.07.005 [本文引用: 1]
Towards label-free 3D segmentation of optical coherence tomography images of the optic nerve head using deep learning
[J].DOI:10.1364/BOE.395934 [本文引用: 1]
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J].DOI:10.1109/TPAMI.2017.2699184 [本文引用: 1]
nnU-NET: a self-configuring method for deep learning-based biomedical image segmentation
[J].DOI:10.1038/s41592-020-01008-z [本文引用: 1]
Ridge-based vessel segmentation in color images of the retina
[J].DOI:10.1109/TMI.2004.825627 [本文引用: 3]
U-KAN makes strong backbone for medical image segmentation and generation
[J].DOI:10.1609/aaai.v39i5.32491 [本文引用: 1]
Road extraction by deep residual U-Net
[J].DOI:10.1109/LGRS.2018.2802944 [本文引用: 1]
The Liver tumor segmentation benchmark (LiTS)
[J].DOI:10.1016/j.media.2022.102680 [本文引用: 2]
A smoothest curve approximation
[J].DOI:10.1090/s0025-5718-1957-0093894-6 [本文引用: 1]
The pascal visual object classes (VOC) challenge
[J].DOI:10.1007/s11263-009-0275-4 [本文引用: 1]
Combo loss: handling input and output imbalance in multi-organ segmentation
[J].DOI:10.1016/j.compmedimag.2019.04.005 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}