[1]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]//Proceedings of the International Conference on Machine Learning . Vienna: PMLR, 2021: 8748–8763.
[本文引用: 2]
[2]
LI J, LI D, XIONG C, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation [C]//Proceedings of the International Conference on Machine Learning . Baltimore: PMLR, 2022: 12888–12900.
[本文引用: 2]
[3]
李志欣, 魏海洋, 张灿龙, 等 图像描述生成研究进展
[J]. 计算机研究与发展 , 2021 , 58 (9 ): 1951 - 1974
DOI:10.7544/issn1000-1239.2021.20200281
[本文引用: 1]
LI Zhixin, WEI Haiyang, ZHANG Canlong, et al Research progress on image captioning
[J]. Journal of Computer Research and Development , 2021 , 58 (9 ): 1951 - 1974
DOI:10.7544/issn1000-1239.2021.20200281
[本文引用: 1]
[4]
XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]//Proceedings of the International Conference on Machine Learning . Lille: JMLR, 2015: 2048–2057.
[本文引用: 7]
[5]
LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 3242–3250.
[本文引用: 2]
[6]
RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1179–1195.
[本文引用: 6]
[7]
JIANG H, MISRA I, ROHRBACH M, et al. In defense of grid features for visual question answering [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10264–10273.
[本文引用: 1]
[8]
WU M, ZHANG X, SUN X, et al. DIFNet: boosting visual information flow for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 17999–18008.
[本文引用: 10]
[9]
HUANG L, WANG W, CHEN J, et al. Attention on attention for image captioning [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 4633–4642.
[本文引用: 6]
[10]
PAN Y, YAO T, LI Y, et al. X-linear attention networks for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10968–10977.
[本文引用: 3]
[11]
CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10575–10584.
[本文引用: 4]
[12]
JI J, LUO Y, SUN X, et al Improving image captioning by leveraging intra- and inter-layer global representation in transformer network
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2021 , 35 (2 ): 1655 - 1663
DOI:10.1609/aaai.v35i2.16258
[本文引用: 3]
[13]
ZHANG X, SUN X, LUO Y, et al. RSTNet: captioning with adaptive attention on visual and non-visual words [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 15460–15469.
[本文引用: 2]
[14]
LUO Y, JI J, SUN X, et al Dual-level collaborative transformer for image captioning
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2021 , 35 (3 ): 2286 - 2293
[本文引用: 8]
[15]
LI X, YIN X, LI C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks [C]//Proceedings of the 16th European Conference on Computer Vision . Cham: Springer, 2020: 121–137.
[16]
KUO C W, KIRA Z. Beyond a pre-trained object detector: cross-modal textual and visual context for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 17948–17958.
[本文引用: 13]
[17]
KUO C W, KIRA Z. HAAV: hierarchical aggregation of augmented views for image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 11039–11049.
[本文引用: 4]
[18]
LIU Z, LIU J, MA F Improving cross-modal alignment with synthetic pairs for text-only image captioning
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2024 , 38 (4 ): 3864 - 3872
DOI:10.1609/aaai.v38i4.28178
[本文引用: 2]
[19]
QIU L, NING S, HE X Mining fine-grained image-text alignment for zero-shot captioning via text-only training
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2024 , 38 (5 ): 4605 - 4613
DOI:10.1609/aaai.v38i5.28260
[本文引用: 1]
[20]
LEE J R, SHIN Y, SON G, et al. Diffusion bridge: leveraging diffusion model to reduce the modality gap between text and vision for zero-shot image captioning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2025: 4050–4059.
[本文引用: 2]
[21]
WANG Y, XU J, SUN Y End-to-end transformer based model for image captioning
[J]. Proceedings of the AAAI Conference on Artificial Intelligence , 2022 , 36 (3 ): 2585 - 2594
DOI:10.1609/aaai.v36i3.20160
[本文引用: 11]
[22]
ASHISH V, NOAM S, NIKI P, et al. Attention is all you need [C]// Annual Conference on Neural Information Processing Systems . Long Beach: NeurIPS Foundation, 2017: 5998–6008.
[本文引用: 3]
[23]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]//Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2022: 9992–10002.
[本文引用: 3]
[24]
XIONG Y, LIAO R, ZHAO H, et al. UPSNet: a unified panoptic segmentation network [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2020: 8810–8818.
[本文引用: 1]
[25]
KRISHNA R, ZHU Y, GROTH O, et al Visual genome: connecting language and vision using crowdsourced dense image annotations
[J]. International Journal of Computer Vision , 2017 , 123 (1 ): 32 - 73
DOI:10.1007/s11263-016-0981-7
[本文引用: 1]
[26]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]//Proceedings of the 13th European Conference on Computer Vision . Cham: Springer, 2014: 740–755.
[本文引用: 1]
[27]
KARPATHY A, LI F F Deep visual-semantic alignments for generating image descriptions
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (4 ): 664 - 676
DOI:10.1109/TPAMI.2016.2598339
[本文引用: 1]
[28]
PAPINENI K, ROUKOS S, WARD T, et al. Bleu: a method for automatic evaluation of machine translation [C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics . Philadelphia: ACL, 2002: 311–318.
[本文引用: 1]
[29]
LAVIE A, AGARWAL A. Meteor: an automatic metric for MT evaluation with high levels of correlation with human judgments [C]//Proceedings of the 2nd Workshop on Statistical Machine Translation . Prague: ACL, 2007: 228–231.
[本文引用: 1]
[30]
LIN C Y. ROUGE: a package for automatic evaluation of summaries [C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics . Barcelona: ACL, 2004.
[本文引用: 1]
[31]
VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: consensus-based image description evaluation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 4566–4575.
[本文引用: 1]
[32]
ANDERSON P, FERNANDO B, JOHNSON M, et al. SPICE: semantic propositional image caption evaluation [C]//Proceedings of the 14th European Conference on Computer Vision . Cham: Springer, 2016: 382–398.
[本文引用: 1]
[34]
LI J, VO D M, SUGIMOTO A, et al. Evcap: retrieval-augmented image captioning with external visual-name memory for open-world comprehension [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 13733–13742.
[本文引用: 2]
[35]
WANG J, WANG W, WANG L, et al Learning visual relationship and context-aware attention for image captioning
[J]. Pattern Recognition , 2020 , 98 : 107075
DOI:10.1016/j.patcog.2019.107075
[本文引用: 1]
[36]
李志欣, 魏海洋, 黄飞成, 等 结合视觉特征和场景语义的图像描述生成
[J]. 计算机学报 , 2020 , 43 (9 ): 1624 - 1640
DOI:10.11897/SP.J.1016.2020.01624
[本文引用: 1]
LI Zhixin, WEI Haiyang, HUANG Feicheng, et al Combine visual features and scene semantics for image captioning
[J]. Chinese Journal of Computers , 2020 , 43 (9 ): 1624 - 1640
DOI:10.11897/SP.J.1016.2020.01624
[本文引用: 1]
2
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... [1 -2 ],基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
2
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... -2 ],基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
图像描述生成研究进展
1
2021
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
图像描述生成研究进展
1
2021
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
7
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... [4 ]或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... 早期基于编码器-解码器模型的图像描述研究主要集中在解码器结构的设计上[4 -6 ] ,而往往将基于CNN的视觉特征提取器充当编码器使用. Xu等[4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... [4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... [4 -8 ]作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
... [
4 ]
66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6 从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
2
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
6
... 早期基于编码器-解码器模型的图像描述研究主要集中在解码器结构的设计上[4 -6 ] ,而往往将基于CNN的视觉特征提取器充当编码器使用. Xu等[4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... [6 ]提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
1
... 采用冻结的预训练ResNet[7 -8 ] 模型来提取给定图像的网格层特征:$ {\boldsymbol{V}}_{\mathrm{grid}}\in {\bf{R}}^{49\times 2048} $ . 其中,网格的数量为$ 7\times 7 $ . 采用冻结的预训练Faster R-CNN[11 ,16 ] 模型来提取图像的区域特征:$ {\boldsymbol{V}}_{\mathrm{reg}}\in {\bf{R}}^{50\times 2\;048} $ . 其中,识别的对象(区域)数量为50. 采用冻结的预训练Swin Transformer模型来提取Swin视觉特征,$ {\boldsymbol{V}}_{\mathrm{Swin}}\in {\bf{R}}^{144\times 1\;536} $ . ...
10
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... -8 ]来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... 早期基于编码器-解码器模型的图像描述研究主要集中在解码器结构的设计上[4 -6 ] ,而往往将基于CNN的视觉特征提取器充当编码器使用. Xu等[4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... [8 ]提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... 采用冻结的预训练ResNet[7 -8 ] 模型来提取给定图像的网格层特征:$ {\boldsymbol{V}}_{\mathrm{grid}}\in {\bf{R}}^{49\times 2048} $ . 其中,网格的数量为$ 7\times 7 $ . 采用冻结的预训练Faster R-CNN[11 ,16 ] 模型来提取图像的区域特征:$ {\boldsymbol{V}}_{\mathrm{reg}}\in {\bf{R}}^{50\times 2\;048} $ . 其中,识别的对象(区域)数量为50. 采用冻结的预训练Swin Transformer模型来提取Swin视觉特征,$ {\boldsymbol{V}}_{\mathrm{Swin}}\in {\bf{R}}^{144\times 1\;536} $ . ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison of computational complexity, parameter quantity and inference time between MVCMFAF model and other model
Tab.5 模型 FLOPs/109 N p /MBt /msXmodal-Ctx[16 ] 127.614 35.439 137.107 DIFNet[8 ] 137.412 28.395 98.244 PureT[21 ] 882.301 224.201 238.937 MVCMFAF (本文) 137.461 175.769 446.157
从表5 可以看出,在计算量方面,4个模型中Xmodal-Ctx 模型需要的计算量最少,DIFNet模型次之,提出的MVCMFAF模型基本与DIFNet模型持平,而与Xmodal-Ctx 模型相差不大. PureT模型的计算量达到882.3×109 ,原因是该模型使用预训练Swin Transformer来提取图像的视觉特征,但采用在线处理(on-line)的方式,导致处理量很大. 本文尽管也使用Swin视觉特征,但采用不同的处理方式:对4个视图的特征提取全部采用离线(off-line)处理的方式. 采用该处理方式,有效降低了模型的计算量和参数量. 在线处理与离线处理各有优劣. 前者灵活性高,适用于数据或模型动态变化的场景,且无须预处理特征提取,但须在训练时重复计算图像特征. 后者则只须进行一次特征提取,能够显著降低训练与推理的计算开销、提升速度,但代价是增加了磁盘存储与I/O负担. ...
6
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... 早期基于编码器-解码器模型的图像描述研究主要集中在解码器结构的设计上[4 -6 ] ,而往往将基于CNN的视觉特征提取器充当编码器使用. Xu等[4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
3
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
4
... 采用冻结的预训练ResNet[7 -8 ] 模型来提取给定图像的网格层特征:$ {\boldsymbol{V}}_{\mathrm{grid}}\in {\bf{R}}^{49\times 2048} $ . 其中,网格的数量为$ 7\times 7 $ . 采用冻结的预训练Faster R-CNN[11 ,16 ] 模型来提取图像的区域特征:$ {\boldsymbol{V}}_{\mathrm{reg}}\in {\bf{R}}^{50\times 2\;048} $ . 其中,识别的对象(区域)数量为50. 采用冻结的预训练Swin Transformer模型来提取Swin视觉特征,$ {\boldsymbol{V}}_{\mathrm{Swin}}\in {\bf{R}}^{144\times 1\;536} $ . ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
Improving image captioning by leveraging intra- and inter-layer global representation in transformer network
3
2021
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
2
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
Dual-level collaborative transformer for image captioning
8
2021
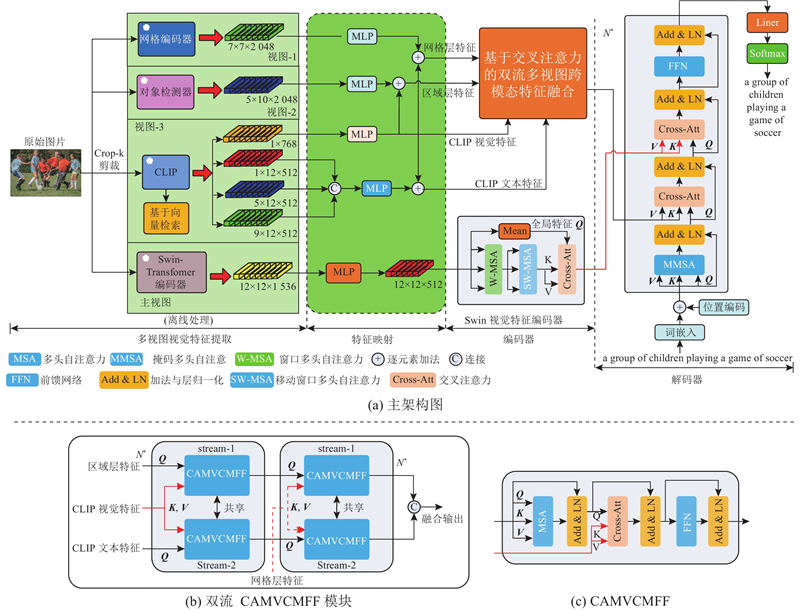
... 尽管图像区域层特征表示方法普遍优于网格层特征方法,但仍然存在区域层特征可能无法完全覆盖图像的某些区域,导致局部视觉信息缺失的问题[14 , 17 , 21 ] . 基于多模态预训练模型的图像描述研究尽管采用了统一的图像-文本特征表示,但受限于多模态模型的训练方法,图像特征与文本特征会存在一定的模态差距(modality gap)[18 -19 ] . 综上所述,由于单一的图像视觉特征提取方法本质上是有损压缩,不可避免地会损失一定程度的视觉信息. 研究如何充分利用不同视觉特征之间的互补性,对于图像描述研究具有重要意义. 为此,本文提出了一个新的基于多视图跨模态特征增强与融合(multiple views cross-modal feature augmentation and fusion, MVCMFAF)的图像描述生成方法,其动机为:尽可能融合来自不同视图的图像视觉特征,使得编码器能够利用不同视图间的互补性,协同生成多视图跨模态的视觉融合特征,减少编码过程中的视觉信息损失. 利用高效语言解码器进行图像视觉特征与文本特征对齐,生成更加丰富和准确的图像文本描述,从而显著提升图像描述系统的性能. ...
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... [14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
13
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... [16 -20 ],并取得了很好的效果. ...
... 早期基于编码器-解码器模型的图像描述研究主要集中在解码器结构的设计上[4 -6 ] ,而往往将基于CNN的视觉特征提取器充当编码器使用. Xu等[4 ] 设计基于RNN的编码器-解码器模型,在解码器端引入注意力机制,显著提升了图像描述生成的性能. Rennie等[6 ] 提出自批评序列训练(SCST)方法,使用强化学习中的策略梯度方法,直接对CIDEr指标进行优化,实验结果超过了之前最先进的方法. 以上这些代表性研究的一个共同特点是均采用网格层特征[4 -8 ] 作为图像的视觉特征. 随着基于CNN的图像对象检测方法的发展,出现了一系列使用区域层特征作为图像视觉特征的图像描述研究[9 -16 ] . ...
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... [16 ]采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... [16 ,18 -20 ,25 ]. ...
... 采用冻结的预训练ResNet[7 -8 ] 模型来提取给定图像的网格层特征:$ {\boldsymbol{V}}_{\mathrm{grid}}\in {\bf{R}}^{49\times 2048} $ . 其中,网格的数量为$ 7\times 7 $ . 采用冻结的预训练Faster R-CNN[11 ,16 ] 模型来提取图像的区域特征:$ {\boldsymbol{V}}_{\mathrm{reg}}\in {\bf{R}}^{50\times 2\;048} $ . 其中,识别的对象(区域)数量为50. 采用冻结的预训练Swin Transformer模型来提取Swin视觉特征,$ {\boldsymbol{V}}_{\mathrm{Swin}}\in {\bf{R}}^{144\times 1\;536} $ . ...
... 遵循文献[16 ]的方法,对原始图像进行剪裁处理. 采用CLIP模型对裁剪后的子图像进行变换,得到各子图像的多模态特征向量. 在FAISS向量数据库中对该向量进行基于相似度的检索,得到关于原始图像增强的全局和局部文本特征表示: ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison of computational complexity, parameter quantity and inference time between MVCMFAF model and other model
Tab.5 模型 FLOPs/109 N p /MBt /msXmodal-Ctx[16 ] 127.614 35.439 137.107 DIFNet[8 ] 137.412 28.395 98.244 PureT[21 ] 882.301 224.201 238.937 MVCMFAF (本文) 137.461 175.769 446.157
从表5 可以看出,在计算量方面,4个模型中Xmodal-Ctx 模型需要的计算量最少,DIFNet模型次之,提出的MVCMFAF模型基本与DIFNet模型持平,而与Xmodal-Ctx 模型相差不大. PureT模型的计算量达到882.3×109 ,原因是该模型使用预训练Swin Transformer来提取图像的视觉特征,但采用在线处理(on-line)的方式,导致处理量很大. 本文尽管也使用Swin视觉特征,但采用不同的处理方式:对4个视图的特征提取全部采用离线(off-line)处理的方式. 采用该处理方式,有效降低了模型的计算量和参数量. 在线处理与离线处理各有优劣. 前者灵活性高,适用于数据或模型动态变化的场景,且无须预处理特征提取,但须在训练时重复计算图像特征. 后者则只须进行一次特征提取,能够显著降低训练与推理的计算开销、提升速度,但代价是增加了磁盘存储与I/O负担. ...
4
... 尽管图像区域层特征表示方法普遍优于网格层特征方法,但仍然存在区域层特征可能无法完全覆盖图像的某些区域,导致局部视觉信息缺失的问题[14 , 17 , 21 ] . 基于多模态预训练模型的图像描述研究尽管采用了统一的图像-文本特征表示,但受限于多模态模型的训练方法,图像特征与文本特征会存在一定的模态差距(modality gap)[18 -19 ] . 综上所述,由于单一的图像视觉特征提取方法本质上是有损压缩,不可避免地会损失一定程度的视觉信息. 研究如何充分利用不同视觉特征之间的互补性,对于图像描述研究具有重要意义. 为此,本文提出了一个新的基于多视图跨模态特征增强与融合(multiple views cross-modal feature augmentation and fusion, MVCMFAF)的图像描述生成方法,其动机为:尽可能融合来自不同视图的图像视觉特征,使得编码器能够利用不同视图间的互补性,协同生成多视图跨模态的视觉融合特征,减少编码过程中的视觉信息损失. 利用高效语言解码器进行图像视觉特征与文本特征对齐,生成更加丰富和准确的图像文本描述,从而显著提升图像描述系统的性能. ...
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
Improving cross-modal alignment with synthetic pairs for text-only image captioning
2
2024
... 尽管图像区域层特征表示方法普遍优于网格层特征方法,但仍然存在区域层特征可能无法完全覆盖图像的某些区域,导致局部视觉信息缺失的问题[14 , 17 , 21 ] . 基于多模态预训练模型的图像描述研究尽管采用了统一的图像-文本特征表示,但受限于多模态模型的训练方法,图像特征与文本特征会存在一定的模态差距(modality gap)[18 -19 ] . 综上所述,由于单一的图像视觉特征提取方法本质上是有损压缩,不可避免地会损失一定程度的视觉信息. 研究如何充分利用不同视觉特征之间的互补性,对于图像描述研究具有重要意义. 为此,本文提出了一个新的基于多视图跨模态特征增强与融合(multiple views cross-modal feature augmentation and fusion, MVCMFAF)的图像描述生成方法,其动机为:尽可能融合来自不同视图的图像视觉特征,使得编码器能够利用不同视图间的互补性,协同生成多视图跨模态的视觉融合特征,减少编码过程中的视觉信息损失. 利用高效语言解码器进行图像视觉特征与文本特征对齐,生成更加丰富和准确的图像文本描述,从而显著提升图像描述系统的性能. ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
Mining fine-grained image-text alignment for zero-shot captioning via text-only training
1
2024
... 尽管图像区域层特征表示方法普遍优于网格层特征方法,但仍然存在区域层特征可能无法完全覆盖图像的某些区域,导致局部视觉信息缺失的问题[14 , 17 , 21 ] . 基于多模态预训练模型的图像描述研究尽管采用了统一的图像-文本特征表示,但受限于多模态模型的训练方法,图像特征与文本特征会存在一定的模态差距(modality gap)[18 -19 ] . 综上所述,由于单一的图像视觉特征提取方法本质上是有损压缩,不可避免地会损失一定程度的视觉信息. 研究如何充分利用不同视觉特征之间的互补性,对于图像描述研究具有重要意义. 为此,本文提出了一个新的基于多视图跨模态特征增强与融合(multiple views cross-modal feature augmentation and fusion, MVCMFAF)的图像描述生成方法,其动机为:尽可能融合来自不同视图的图像视觉特征,使得编码器能够利用不同视图间的互补性,协同生成多视图跨模态的视觉融合特征,减少编码过程中的视觉信息损失. 利用高效语言解码器进行图像视觉特征与文本特征对齐,生成更加丰富和准确的图像文本描述,从而显著提升图像描述系统的性能. ...
2
... 当前,多模态学习问题,如视觉语言模型已受到业界的广泛关注[1 -2 ] . 图像描述(image captioning)任务从给定的图像自动生成关于图像准确、流利的文本描述,该任务属于计算机视觉与自然语言处理交叉的研究领域,因此成为当前多模态学习研究的热点之一[3 ] . 当前的图像描述研究主要采用2种类型的图像视觉特征:网格层特征(grid-level features)[4 -8 ] 和区域层特征(region-level features)[9 -16 ] . 网格层特征主要采用基于预训练的卷积神经网络(convolutional neural network,CNN),如VGGNet[4 ] 或ResNet[5 -8 ] 来提取图像的特征,但缺点是无法描述更高层次的图像语义信息,比如图像中的对象类别、对象位置及对象属性. 区域层特征采用基于预训练的图像对象检测方法,如Faster R-CNN来提取图像中的区域(对象)特征,克服了网格层特征存在的缺点. 随着多模态预训练模型的出现,如对比语言-图像预训练(contrastive language-image pre-training,CLIP)模型等[1 -2 ] ,基于跨模态图像-文本特征的图像描述研究开始受到关注[16 -20 ] ,并取得了很好的效果. ...
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
End-to-end transformer based model for image captioning
11
2022
... 尽管图像区域层特征表示方法普遍优于网格层特征方法,但仍然存在区域层特征可能无法完全覆盖图像的某些区域,导致局部视觉信息缺失的问题[14 , 17 , 21 ] . 基于多模态预训练模型的图像描述研究尽管采用了统一的图像-文本特征表示,但受限于多模态模型的训练方法,图像特征与文本特征会存在一定的模态差距(modality gap)[18 -19 ] . 综上所述,由于单一的图像视觉特征提取方法本质上是有损压缩,不可避免地会损失一定程度的视觉信息. 研究如何充分利用不同视觉特征之间的互补性,对于图像描述研究具有重要意义. 为此,本文提出了一个新的基于多视图跨模态特征增强与融合(multiple views cross-modal feature augmentation and fusion, MVCMFAF)的图像描述生成方法,其动机为:尽可能融合来自不同视图的图像视觉特征,使得编码器能够利用不同视图间的互补性,协同生成多视图跨模态的视觉融合特征,减少编码过程中的视觉信息损失. 利用高效语言解码器进行图像视觉特征与文本特征对齐,生成更加丰富和准确的图像文本描述,从而显著提升图像描述系统的性能. ...
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... [21 ]利用Swin Transformer模型进行图像描述生成. ...
... Swin视觉特征编码器用于编码特征主视图:Swin视觉特征. 如图1 所示,该编码器包含3个核心组件: W-MSA层、SW-MSA层和交叉注意力(Cross-Att)层. 其中,Cross-Att层的原理如前所述,W-MSA[21 ,23 ] 层的处理过程可以表示为 ...
... SW-MSA[21 ,23 ] 层与W-MSA层的处理过程基本相同,区别如下: ...
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... 遵循图像描述相关研究的标准做法[6 ,8 -14 ,16 -17 ,21 ] ,使用交叉熵(XE)损失函数对模型进行训练,采用强化学习策略对交叉熵损失下的最优模型进行基于CIDEr指标的最优化. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in ensemble-model setting
% Tab.2 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 35.4 27.1 56.6 117.5 — AoANet[9 ] 81.6 40.2 29.3 59.4 132.0 22.8 X-Transformer[10 ] 81.7 40.7 29.9 59.7 135.3 23.8 M2 Transformer[11 ] 82.0 40.5 29.7 59.5 134.5 23.5 GET[12 ] 82.1 40.6 29.8 59.6 135.1 23.8 DLCT[14 ] 82.2 40.8 29.9 59.8 137.5 23.3 PureT[21 ] 83.4 42.1 30.4 60.8 141.0 24.3 MVCMFAF (本文) 83.5 42.7 30.6 61.1 142.3 24.5
3) 在Flickr30k数据集上的评估结果. ...
... 消融实验模型主要分为以下2类. a) 基于双流CAMVCMFF模块的修改. 第1个模型为在CAMVCMFF模块中移除网格层特征,其余结构不变. 以此类推:第2个模型为在CAMVCMFF模块中移除区域层特征,第3个模型移除了所有CLIP跨模态特征,第4个模型仅移除CLIP跨模态特征中的CLIP文本特征,第5个模型仅移除CLIP跨模态特征中的CLIP视觉特征. b) 基于Swin Encoder的修改. 第6个模型为在Swin Encoder模块中移除全局特征,结构修改为W-MSA层、SW-MSA层和W-MSA层,这与PureT模型[21 ] 的编码器结构非常类似. 第7个模型为将Swin Encoder模块修改为采用3层普通的Transformer结构. 第8个模型为本文提出的原始方法,未作任何修改. ...
... Comparison of computational complexity, parameter quantity and inference time between MVCMFAF model and other model
Tab.5 模型 FLOPs/109 N p /MBt /msXmodal-Ctx[16 ] 127.614 35.439 137.107 DIFNet[8 ] 137.412 28.395 98.244 PureT[21 ] 882.301 224.201 238.937 MVCMFAF (本文) 137.461 175.769 446.157
从表5 可以看出,在计算量方面,4个模型中Xmodal-Ctx 模型需要的计算量最少,DIFNet模型次之,提出的MVCMFAF模型基本与DIFNet模型持平,而与Xmodal-Ctx 模型相差不大. PureT模型的计算量达到882.3×109 ,原因是该模型使用预训练Swin Transformer来提取图像的视觉特征,但采用在线处理(on-line)的方式,导致处理量很大. 本文尽管也使用Swin视觉特征,但采用不同的处理方式:对4个视图的特征提取全部采用离线(off-line)处理的方式. 采用该处理方式,有效降低了模型的计算量和参数量. 在线处理与离线处理各有优劣. 前者灵活性高,适用于数据或模型动态变化的场景,且无须预处理特征提取,但须在训练时重复计算图像特征. 后者则只须进行一次特征提取,能够显著降低训练与推理的计算开销、提升速度,但代价是增加了磁盘存储与I/O负担. ...
3
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... CAMVCMFF模块使用Transformer模型[22 ] 作为基本结构,该模块的核心组件如下. ...
... Transformer模型采用多层堆叠的方式[22 ] ,在图1 相应的框图边使用N *来表示. 以图1 (b)的双流CAMVCMFF模块为例,第1次调用时,上部处理流stream-1第i 层的处理过程可以表示为 ...
3
... 随着Transformer模型[22 ] 开始流行,近年来图像描述研究基本上都采用基于Transformer模型的架构[9 -14 ,16 -17 ,21 ] . 为了解决Transformer模型的多头自注意力机制(MSA)计算复杂度高的问题, Swin Transformer模型[23 ] 引入窗口多头自注意力(W-MSA)机制和移动窗口多头自注意力(SW-MSA)机制,使得在保证模型具有良好图像视觉特征表示能力的前提下,极大地降低了Transformer模型带来的计算复杂度. 目前已有研究者[21 ] 利用Swin Transformer模型进行图像描述生成. ...
... Swin视觉特征编码器用于编码特征主视图:Swin视觉特征. 如图1 所示,该编码器包含3个核心组件: W-MSA层、SW-MSA层和交叉注意力(Cross-Att)层. 其中,Cross-Att层的原理如前所述,W-MSA[21 ,23 ] 层的处理过程可以表示为 ...
... SW-MSA[21 ,23 ] 层与W-MSA层的处理过程基本相同,区别如下: ...
1
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
Visual genome: connecting language and vision using crowdsourced dense image annotations
1
2017
... 当前也有一些研究尝试利用多个图像视觉特征协同来提高图像描述系统的性能[8 ,14 ,16 -17 ] . 如Wu等[8 ] 提出双信息流网络,融合了图像的网格层特征和分割特征[24 ] . Luo等[14 ] 探究使用网格层特征和区域层特征协同的图像描述方法. Kuo等[16 ] 采用结合区域层特征与跨模态图像-文本特征的方法进行图像描述生成. 此外,随着多模态预训练模型的广泛应用,出现了一些使用跨模态图像-文本特征进行图像描述生成的研究[16 ,18 -20 ,25 ] . ...
1
... 与主流的研究方法类似,在MSCOCO 2014数据集[26 ] 上对提出的基于MVCMFAF的图像描述模型进行训练与评估,验证提出方法的有效性. 该数据集共包含123 287个图像数据,其中每个图像数据包含1个图像和5个手工标注的参考描述. 遵照Karpathy等[27 ] 提出的“Karpathy”split方法,对原始的MSCOCO 2014数据集进行处理,得到训练集、验证集和测试集3个子集,样本数量分别为113 287、5 000、5 000. ...
Deep visual-semantic alignments for generating image descriptions
1
2017
... 与主流的研究方法类似,在MSCOCO 2014数据集[26 ] 上对提出的基于MVCMFAF的图像描述模型进行训练与评估,验证提出方法的有效性. 该数据集共包含123 287个图像数据,其中每个图像数据包含1个图像和5个手工标注的参考描述. 遵照Karpathy等[27 ] 提出的“Karpathy”split方法,对原始的MSCOCO 2014数据集进行处理,得到训练集、验证集和测试集3个子集,样本数量分别为113 287、5 000、5 000. ...
1
... 沿用多个相关研究的做法,采用5个基于自动评价的度量指标,评估图像描述的性能:BLEU-n [28 ] 、METEOR[29 ] 、ROUGE-L[30 ] 、CIDEr[31 ] 、SPICE[32 ] 等指标. ...
1
... 沿用多个相关研究的做法,采用5个基于自动评价的度量指标,评估图像描述的性能:BLEU-n [28 ] 、METEOR[29 ] 、ROUGE-L[30 ] 、CIDEr[31 ] 、SPICE[32 ] 等指标. ...
1
... 沿用多个相关研究的做法,采用5个基于自动评价的度量指标,评估图像描述的性能:BLEU-n [28 ] 、METEOR[29 ] 、ROUGE-L[30 ] 、CIDEr[31 ] 、SPICE[32 ] 等指标. ...
1
... 沿用多个相关研究的做法,采用5个基于自动评价的度量指标,评估图像描述的性能:BLEU-n [28 ] 、METEOR[29 ] 、ROUGE-L[30 ] 、CIDEr[31 ] 、SPICE[32 ] 等指标. ...
1
... 沿用多个相关研究的做法,采用5个基于自动评价的度量指标,评估图像描述的性能:BLEU-n [28 ] 、METEOR[29 ] 、ROUGE-L[30 ] 、CIDEr[31 ] 、SPICE[32 ] 等指标. ...
基于视觉关联与上下文双注意力的图像描述生成方法
3
2022
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
基于视觉关联与上下文双注意力的图像描述生成方法
3
2022
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
2
... 为了验证提出方法的有效性,采用12种具有代表性的图像描述生成方法作为基线模型,与提出的MVCMFAF模型进行对比实验. 根据所采用解码器的不同,可以大致将图像描述生成方法分为以下2种类型. 1) 基于RNN的模型:SCST[6 ] 、AoANet[9 ] 、VRCDA[33 ] . 2) 基于Transformer的模型:X-Transformer[10 ] 、 $ {{{\mathrm{M}}}}^{2} $ [11 ] 、GET [12 ] 、RSTNet [13 ] 、DLCT [14 ] 、Xmodal-Ctx[16 ] 、DIFNet[8 ] 、PureT[21 ] 、EVCap[34 ] . 以上基线模型的实验结果均采用原始论文中所给出的数据. ...
... Comparison with other state-of-the-art model on MSCOCO test dataset in single-model setting
% Tab.1 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr SPICE SCST[6 ] — 34.2 26.7 55.7 114.0 — AoANet[9 ] 80.2 38.9 29.2 58.8 129.8 22.4 X-Transformer[10 ] 80.9 39.7 29.5 59.1 132.8 23.4 M2 Transformer[11 ] 80.8 39.1 29.2 58.6 131.2 22.6 GET[12 ] 81.5 39.5 29.3 58.9 131.6 22.8 RSTNet[13 ] 81.8 40.1 29.8 59.5 135.6 23.3 DLCT[14 ] 81.4 39.8 29.5 59.1 133.8 23.0 Xmodal-Ctx[16 ] 81.5 39.7 30.0 59.5 135.9 23.7 DIFNet[8 ] 81.7 40.0 29.7 59.4 136.2 23.2 PureT[21 ] 82.1 40.9 30.2 60.1 138.2 24.2 VRCDA[33 ] 80.6 37.9 28.4 58.2 123.7. 21.8 EVCAP[34 ] — 41.5 31.2 — 140.1 24.7 MVCMFAF (本文) 83.2 41.6 30.4 60.5 140.6 24.4
1) 基于单一模型的评估结果. ...
Learning visual relationship and context-aware attention for image captioning
1
2020
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
结合视觉特征和场景语义的图像描述生成
1
2020
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...
结合视觉特征和场景语义的图像描述生成
1
2020
... Comparison with other state-of-the-art model on Flickr30k dataset
Tab.3 % 模型 BLEU-1 BLEU-4 METEOR ROUGE-L CIDEr Soft-Attention[4 ] 66.7 19.1 18.5 — — Hard-Attention[4 ] 66.9 19.9 18.5 — — Adaptive-Attention[5 ] 67.7 25.1 20.4 — 53.1 A_R_L[35 ] 69.8 27.7 21.5 48.5 57.4 IVAIC[36 ] 70.8 30.6 22.5 49.8 63.0 VRCDA[33 ] 73.2 30.6 22.7 50.6 66.0 MVCMFAF (本文) 75.2 33.7 34.2 52.1 75.6
从总体上看,提出的MVCMFAF模型优于现有的先进方法,该模型能够有效地提高图像描述系统生成的性能. 提出的方法采用专门设计的编码器-解码器架构,并引入4个视觉特征视图作为输入. 该设计旨在利用不同视图间的特征互补性,有效减少编码过程中的视觉信息损失,提升图像描述生成的总体质量. ...



{kind=link}
{kind=link}