基于多视图跨模态特征融合的图像描述生成
Image captioning generation based on multiple-view cross-modal feature fusion
基于多视图跨模态特征融合的图像描述生成 |
| 张乃洲,赵云超,曹薇,张啸剑 |
|
Image captioning generation based on multiple-view cross-modal feature fusion |
| Naizhou ZHANG,Yunchao ZHAO,Wei CAO,Xiaojian ZHANG |
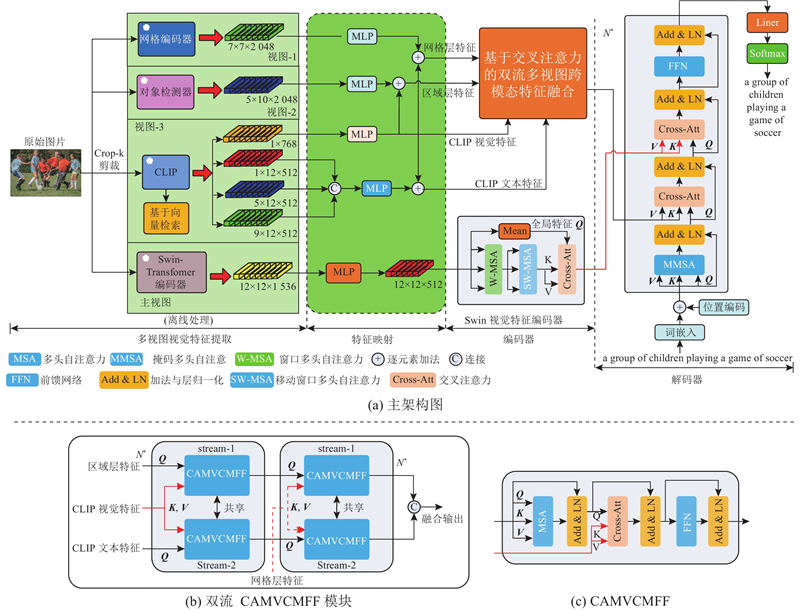
| 图 1 MVCMFAF图像描述生成模型的总体架构图 |
| Fig.1 Overall architecture of MVCMFAF image captioning model |
|
|