

随着城市扩张和交通网络的复杂化,交通管理部门在应急响应中面临效能提升的挑战. 智能交通系统通过交通流预测技术分析道路运行与异常情况,为管理决策者提供预警信息,推动交通应急管理的信息化升级.
交通流预测方法经历了统计学[1]、机器学习[2]和深度学习3个发展阶段. 深度学习因能建模复杂非线性关系而被广泛应用,如循环神经网络(RNN)[3]、长短时记忆网络(LSTM)[4]及注意力机制(Self Attention)[5]等,但这类方法忽视节点间的空间依赖关系. 近年来,结合卷积神经网络(CNN)、图神经网络(GNN)及图卷积网络(GCN)[6]等时空预测方法,解决了该问题. Li等[7]提出结合GCN与LSTM混合模型,通过联合建模时空特征来预测流量. Kong等[8]通过识别道路网络中的重要节点,融合余弦相似度和地理邻接关系构建邻接矩阵,捕捉时空依赖. 这2种基于预定义拓扑结构和相似性度量的方法难以适应不同区域交通流模式及不同时间片变化规律的差异,复杂的时空异质性限制了模型的适应性和通用性.
现有方法在复杂路网的交通流预测中面临捕捉时空异质性特征与考虑预测序列内部依赖关系两大挑战. 为此,本文提出CFHD-Former模型. 通过自适应高频异质化模块提取时间序列高频特征,增强不同时间片段的可区分性,采用渐进调优策略,增强异质特征的识别能力. 利用核心流动点识别模块评估节点的流入流出能力,实现核心与非核心流动点差异化建模. 引入频域自相关MAE损失函数,将预测序列转换至频域,避免时间步之间的依赖,提高直接预测范式的精度.
1. 交通流时空异质性与预测序列自相关性的分析
1.1. 交通流时空异质性分析
交通流具有显著的时空异质性,具体分为空间异质性和时间异质性. 空间异质性是指同一时期不同空间位置的交通流变化模式存在差异. 如图1所示,选取洛杉矶市中心和住宅区的代表性节点,市中心与住宅区的流量时变特征如图2所示. 其中,t为时间步,v为交通流量,虚线左侧为工作日,虚线右侧为休息日. 市中心早晚高峰流量显著增长至峰值,反映出通勤需求集中;住宅区流量变化平稳,峰值特征不显著. 不同功能区交通流量的异质性突出;时间异质性体现在不同时间段交通数据的不一致性和变化规律的差异. 如图2所示,早晚高峰的交通流量高度集中,非高峰时段相对平稳;工作日和休息日的流量时变特征差异显著,表明不同时间片段的交通流变化模式存在明显的异质化.
图 1
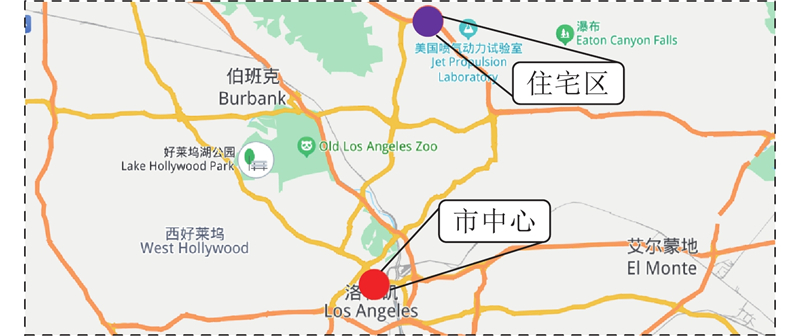
图 2
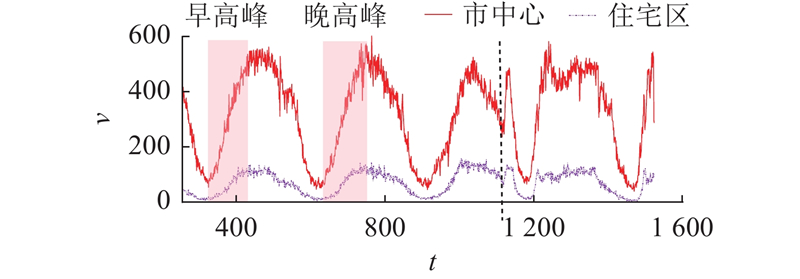
图 2 市中心与住宅区的流量时变特征对比
Fig.2 Comparison of time-varying flow characteristic between downtown and residential area
1.2. 预测序列的自相关性分析
交通时间序列具有高度的自相关性,不同时间步间存在依赖关系,且该特性同时存在于输入序列和预测序列中. 在实际路网中,各节点交通流量数据的每个时刻仅有1个观测值,自相关性的计算依赖于特定时刻间的关系. 节点在
式中:
根据式(1),对PEMS08数据集中随机选择的6 个节点进行时间自相关性分析,结果如图3所示. 所有节点的自相关系数(ACF)均超过0.3,其中节点3和节点6的输入序列和预测序列ACF都大于0.7. 输入序列与预测序列在各节点均呈现出显著的自相关特征.
图 3
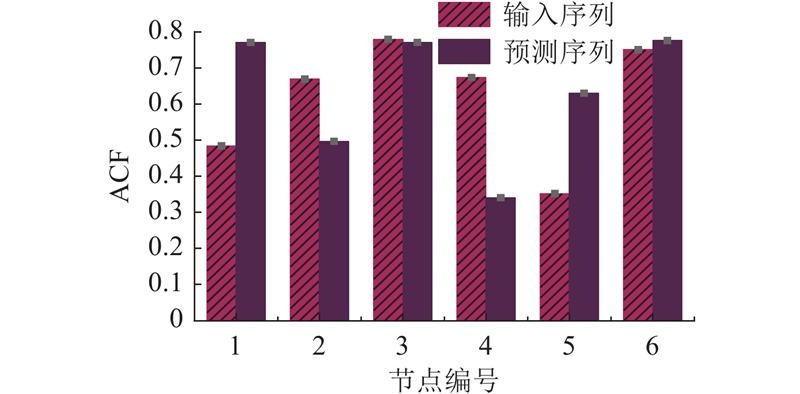
图 3 输入-预测序列的自相关性分析
Fig.3 Autocorrelation analysis of input-prediction sequence
2. 问题定义
基于图结构理论构建路网节点关系模型,定义
式中:
3. CFHD-Former模型的构建
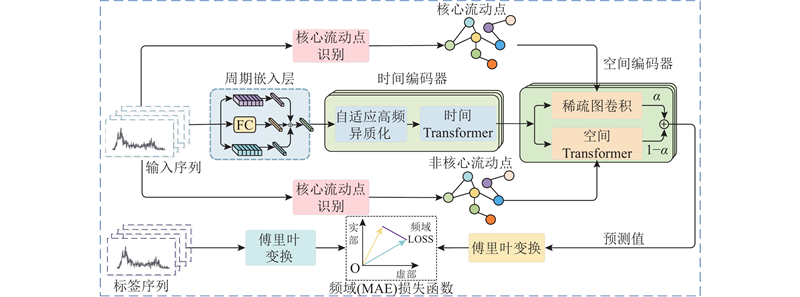
提出高频动态交通流预测模型CFHD-Former,该模型的架构如图4所示. 为了解耦时空依赖性,避免联合训练中的时空特征耦合干扰,模型采用时间与空间维度依次建模的串联架构. 分别捕捉时空异质性与相关性,以实现特征的有效分离. 在时间维度,通过周期嵌入层编码周期性特征,经自适应高频异质化模块增强高频特征,由时间Transformer提取时间依赖特征. 空间维度建模提出特征差异化分层方法. 通过核心流动点识别模块解析交通网络拓扑,将路网节点划分为核心与非核心流动点. 针对核心流动点的强关联性,构建稀疏邻接矩阵,采用GCN建模显式空间依赖. 针对非核心流动点的潜在复杂空间关联,引入空间注意力机制,捕捉空间相关性. 通过自适应融合,实现2类节点表征的层级聚合. 此外,在模型训练中引入频域自相关MAE损失函数,通过频域变换将预测值与真实值从时域映射到频域,并从频域视角训练预测. 借由特征维度转换有效消除时域内时间步间的依赖关系,解决多步预测中无法考虑预测序列时间步间依赖关系的问题.
图 4
3.1. 时间特征提取
3.1.1. 周期嵌入层
在时间维度,为了更好地捕捉路网不同时间尺度的动态特征,结合当前交通流数据,构建包含日周期
式中:
3.1.2. 自适应高频异质化模块
交通时间序列表现出显著的时间异质性,即不同时间段的交通模式及变化规律存在差异. 如早晚高峰与非高峰时段、白天与夜晚、工作日与休息日之间的交通流模式不同,导致模型难以有效地捕捉不同时段间的差异化特征.
提出自适应高频异质化模块,通过细化时间序列的高频成分和抑制低频成分,增强时间片段之间的差异性,提高模型对不同时间段的区分能力. 该模块的提出基于如下2个假设.
假设1. 时间序列可以解耦为高频分量与低频分量,表示为
式中:
假设2. 低频分量的变化速率远远低于高频分量的变化速率,故低频分量在一段时间内可以近似为常数.
基于假设2,得出高频分量提取模块的推导式:
式中:
式中:
为了进一步增强模型对不同时间片段的适应性,提高时间异质性的感知能力,提出渐进调优机制. 从式(5)可知,高频特征提取主要受时间片均值和方差的影响,故该机制主要通过在训练过程中动态调整各时间段的均值和方差,以更有效地捕捉不同时间段的统计特性,实现模型的动态适应. 训练时的均值和方差更新公式为
式中:
通过上述更新方式,模型在训练阶段能够有效捕捉数据的动态变化特性,并在推理阶段利用更新后的统计量实现对时间序列异质性的动态建模.
3.1.3. 时间transformer层
采用时间Transformer,捕捉时间序列的自相关性. 模型主要包含时间注意力模块、归一化模块以及前馈网络层,结构如图5所示. 首先获得查询
图 5
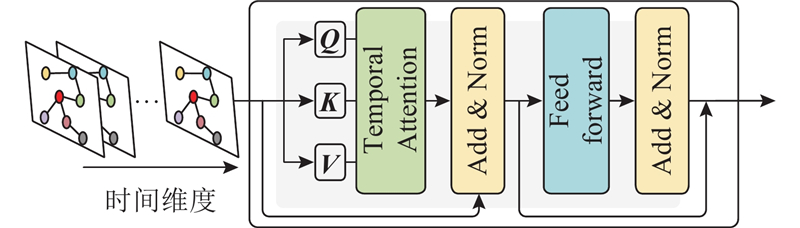
式中:
式中:
此外,时间注意力机制集成了层归一化和残差连接机制,增强模型的稳定性与关键特征的传递效果,从而更有效地提取时间依赖关系.
3.2. 空间特征提取
3.2.1. 核心流动点识别模块
空间异质性主要表现为特定区域(如学校、商场)在特定时段出现流量剧烈波动和显著的流入流出量变化. 将此类区域定义为“核心流动点”. 有效建模核心流动点与周边区域的复杂依赖关系是应对空间异质性的关键.
如图6所示为核心流动点流入流出能力的计算示意图. 其中心节点表示节点
图 6
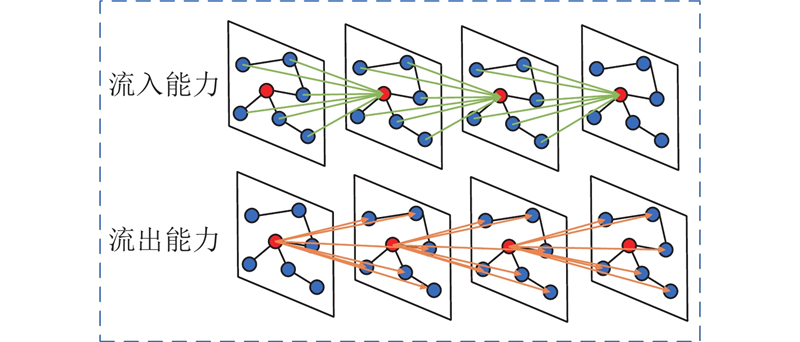
图 6 节点流入流出能力计算的示意图
Fig.6 Schematic diagram of node inflow and outflow capacity calculation
相似度计算公式为
式中:
节点
式中:
3.2.2. 空间特征建模
基于已识别的核心流动点与非核心流动点,设计双分支空间特征提取框架,采用差异化建模策略. 对于核心流动点,因其流量大、关联范围广、拓扑结构稳定且具有代表性,采用图卷积方法建模空间依赖关系,以有效捕捉空间结构特征. 对于非核心流动点,流量较小,空间依赖关系更具有局部性和多样性,采用空间Transformer的自注意力机制灵活刻画复杂的依赖关系,捕捉更细粒度的空间交互特征,从而更准确地描述非核心流动点的局部依赖特性.
空间Transformer有着与时间Transformer相似的架构,主要包含空间注意力模块、归一化模块以及前馈网络层,结构如图7所示.
图 7
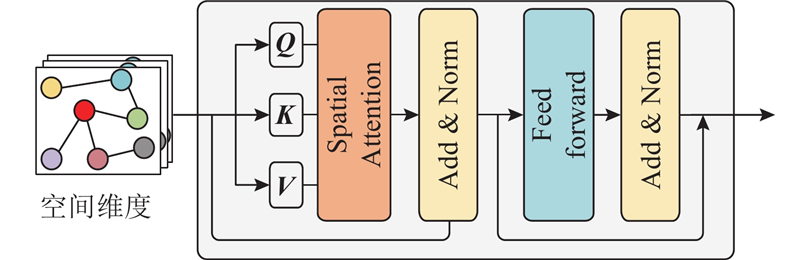
计算注意力时,与时间注意力不同的是,空间注意力主要针对节点特征间的注意力. 对输入张量进行维度互换,将
式中:
此外,空间注意力机制集成了层归一化和残差连接机制,增强模型的稳定性与关键特征的传递效果,从而更有效地提取空间依赖关系.
对于核心流动点,依据节点之间的相似度构建稀疏邻接矩阵. 该矩阵反映的是核心流动点与其他节点间的依赖关系. 计算表达式如下:
式中:
图卷积网络由于仅对核心流动点与其他节点之间的依赖关系进行建模,计算复杂度为
式中:
在得到由稀疏图卷积提取的核心流动点的特征
式中:
3.3. 频域自相关MAE损失函数
图 8
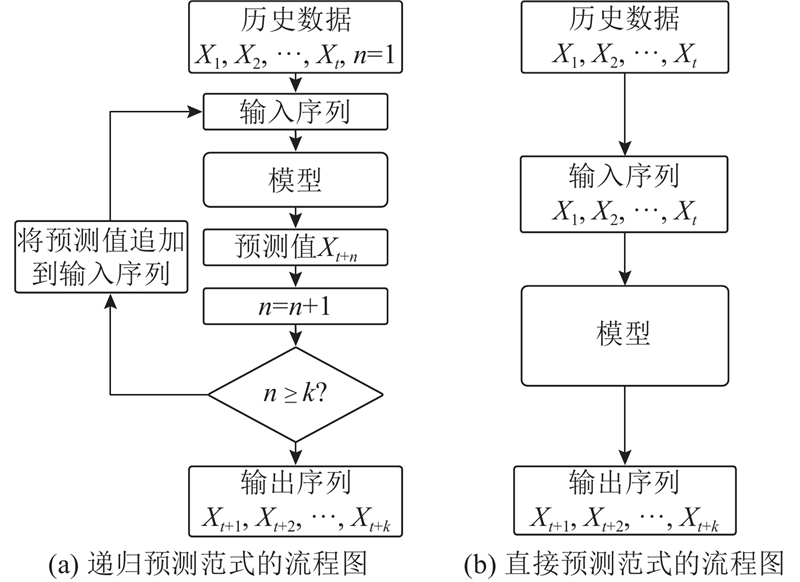
直接预测范式如图8(b)所示,将历史序列
图 9
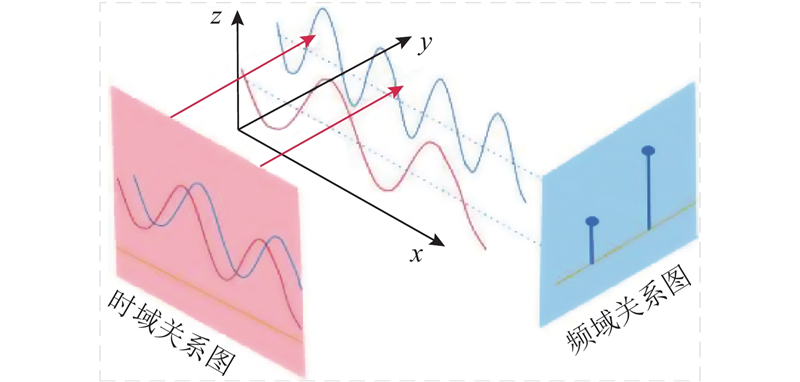
模型的损失函数定义为
式中:
式中:
4. 实验分析
4.1. 数据初始配置与基准模型
采用Caltrans PeMS数据系统的3个交通路网数据集:PEMS04、PEMS08和METRLA. 数据集中,各个交通路网节点隔5 min记录一次车流量数据. 以6∶2∶2的比例来划分训练集、验证集和测试集. 数据集的详细信息如表1所示.
表 1 Caltrans PeMS数据集的基本信息
Tab.1
| 数据集 | 地区 | 节点 | 长度 | 日期 |
| PeMS04 | 旧金山湾区 | 307 | 2018.01—02 | |
| PeMS08 | 圣贝纳迪诺区 | 170 | 2016.07—09 | |
| METRLA | 洛杉矶县 | 207 | 2012.03—06 |
实验基于Python3.9.1和Pytorch2.0.1,硬件环境是RTX 4060. 时间序列预测的历史窗口和预测窗口均设为12 个时间步. 优化器是Adam. 为了客观评估CFHD-Former模型的性能,采用3个广泛使用的评价指标:平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE). MAE、RMSE、MAPE的计算公式如下:
式中:
4.2. 实验结果分析
如表2所示为各模型在未来一小时交通流预测中的性能对比. 可知,CFHD-Former在3个数据集的所有评估指标上均优于基线模型. 传统模型ARIMA的表现最差,常被视为下限基准. 时间序列模型SCINet和ST-Norm仅建模时间相关性,忽略空间依赖,性能明显落后. 在PEMS04上,SCINet和ST-Norm的RMSE分别为31.28和30.98,较CFHD-Former高4.16%和3.23%. 此外,虽然SCINet通过下采样和交互机制能够有效地捕捉时间序列的多分辨率特征,但无法有效地建模交通流的时空异质特性. ST-Norm受限于静态的归一化策略,无法动态适应不同时间段和区域的异质性特征. 基于图神经网络的GWNet和DGCRN在METRLA数据集上的RMSE分别为6.61、6.38,表现出较强的竞争力,这归因于它们分别通过自适应邻接矩阵和动态图机制来应对空间异质性. GWNet难以捕捉稀疏连接节点间的隐含关系,DGCRN在极端异质性(如节点行为模式的差异巨大或孤立节点)场景下的建模能力受限. 相比之下,CFHD-Former通过分别对核心与非核心流动点进行异质化建模,实现更精细的空间特征提取,在METRLA数据集上,RMSE较DGCRN和GWNet分别降低1.92%和5.59%. 基于注意力机制的模型整体表现更优. PDFormer在多个数据集上显著领先,在METRLA数据集上的MAE为3.15,体现出PDFormer在捕捉长期依赖关系方面的优势. CFHD-Former进一步将MAE降至3.03,相较于PDFormer提升了3.96%. CFHD-Former的性能主要得益于自适应高频异质化模块和渐进调优机制,增强了对不同时间片段交通状态的适应性. CFHD-Former模型在PeMS08数据集上的性能最显著,MAE较次优模型提升了4.58%,这归因于PEMS08数据集的路网结构较复杂,核心流动点与非核心流动点的差异更明显,使得异质化建模方法在该数据集上发挥出更大的优势.
表 2 基于PEMS04、PEMS08、METRLA数据集的不同基准线模型的预测准确度对比
Tab.2
| 模型 | PEMS04 | PEMS08 | METRLA | ||||||||||
| MAE | RMSE | MAPE/% | MAE | RMSE | MAPE/% | MAE | RMSE | MAPE/% | |||||
| ARIMA | 28.55 | 40.36 | 19.55 | 31.23 | 33.47 | 19.25 | 6.08 | 11.37 | 14.62 | ||||
| ST-Norm | 18.96 | 30.98 | 12.69 | 15.41 | 24.77 | 9.76 | 3.14 | 6.45 | 8.60 | ||||
| SCINet | 19.30 | 31.28 | 12.05 | 15.76 | 24.65 | 10.01 | 3.46 | 6.62 | 9.25 | ||||
| STGCN | 19.57 | 31.28 | 13.44 | 16.08 | 25.39 | 10.60 | 3.16 | 6.38 | 8.69 | ||||
| DCRNN | 19.63 | 31.26 | 13.59 | 16.22 | 25.17 | 10.81 | 3.24 | 6.47 | 8.92 | ||||
| GWNet | 18.83 | 30.01 | 12.94 | 14.98 | 23.99 | 10.21 | 3.17 | 6.61 | 9.21 | ||||
| DGCRN | 19.01 | 30.51 | 12.19 | 14.80 | 23.75 | 9.46 | 3.18 | 6.38 | 8.76 | ||||
| GMAN | 19.14 | 31.60 | 13.19 | 15.31 | 24.92 | 10.13 | 3.25 | 6.52 | 8.76 | ||||
| ASTGNN | 18.60 | 30.91 | 12.36 | 15.00 | 24.75 | 9.50 | 3.30 | 6.64 | 8.78 | ||||
| PDFormer | 18.51 | 30.24 | 12.38 | 14.34 | 23.68 | 9.88 | 3.15 | 6.54 | 8.71 | ||||
| CFHD-Former | 18.32 | 29.98 | 12.01 | 13.74 | 23.28 | 9.03 | 3.03 | 6.26 | 8.35 | ||||
4.3. 模型消融实验
为了评估模型中各组件的有效性,在PEMS08与METRLA数据集上,将CFHD-Former与以下变体进行比较. 1)移除自适应高频异质化模块;2)移除渐进调优机制;3)移除核心流动点识别模块,即使用全局邻接矩阵替换稀疏邻接矩阵;4)移除频域自相关MAE损失函数,即使用普通MAE损失函数. 将这4个变体分别命名为CFHD-Former-HF、CFHD-Former-PT、CFHD-Former-CP、CFHD-Former-FL.
如图10所示,在移除自适应高频异质化模块与渐进调优机制后,模型在METRLA数据集上的RMSE分别增加了12.5%和11.14%. 这验证了两者在解决时间异质性问题上的有效性. 在移除核心流动点识别模块后,PEMS08数据集上的MAE、RMSE、MAPE分别增加了5.08%、5.21%、6.31%. 基于稀疏邻接矩阵的关键节点提取能够有效地降低噪声干扰,提升模型性能. 采用全局邻接矩阵使得模型失去了对关键节点的选择能力,验证了核心流动点的识别与建模对提升模型在捕捉交通网络的空间依赖性具有重要作用.
图 10
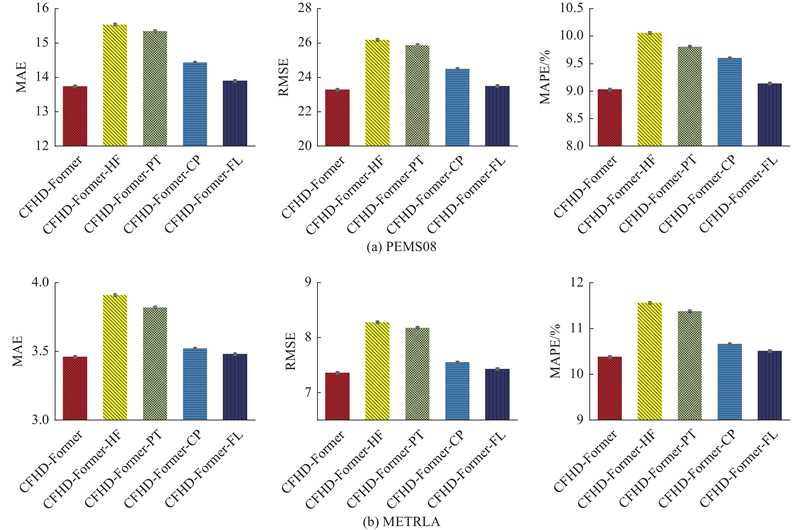
图 10 不同消融模型的预测性能分析
Fig.10 Analysis of predictive performance of different ablation model
如表3所示为各消融模型在15、30和60 min预测时间下的性能对比. 其中,tp为预测时间. 从图3可知,与CFHD-Former-FL相比,CFHD-Former在15 min预测中MAE、RMSE及MAPE分别降低了0.9%、0.8%和0.85%,平均降幅为0.85%. 当预测时间为30 min时,上述指标分别下降了3%、3.2%和2.9%,平均降幅达到3.03%. 当预测时间为60 min时,平均降幅进一步扩大至6.63%. 随着预测步长的增加,频域自相关MAE损失函数带来的性能提升更加显著,而其他消融模型带来的性能提升没有受到预测时间步长短的影响. 这表明该损失函数考虑到了预测序列内各时间步间的依赖关系,有效增强了模型在多步预测中的表现.
表 3 消融模型在不同时间步下的预测性能
Tab.3
| tp/min | MAE | ||||
| CFHD-Former-HF | CFHD-Former-PT | CFHD-Former-CP | CFHD-Former-FL | CFHD-Former | |
| 15 | 12.85 | 12.25 | 12.41 | 12.05 | 11.94 |
| 30 | 15.85 | 15.17 | 14.21 | 14.08 | 13.67 |
| 60 | 18.98 | 16.93 | 15.86 | 16.17 | 15.25 |
| tp/min | RMSE | ||||
| CFHD-Former-HF | CFHD-Former-PT | CFHD-Former-CP | CFHD-Former-FL | CFHD-Former | |
| 15 | 20.36 | 19.39 | 20.33 | 19.71 | 19.55 |
| 30 | 26.24 | 25.98 | 24.34 | 24.16 | 23.41 |
| 60 | 31.25 | 28.96 | 27.13 | 27.94 | 26.09 |
| tp/min | MAPE/% | ||||
| CFHD-Former-HF | CFHD-Former-PT | CFHD-Former-CP | CFHD-Former-FL | CFHD-Former | |
| 15 | 8.36 | 7.91 | 8.20 | 7.96 | 7.89 |
| 30 | 10.20 | 9.93 | 9.30 | 9.21 | 8.95 |
| 60 | 12.46 | 11.18 | 10.47 | 10.75 | 10.07 |
4.4. 关键超参数的敏感性分析
为了全面评估模型的性能,对关键超参数进行敏感性分析,实验结果如图11所示. 其中,p为核心流动点所占比例,BS为批大小.
图 11
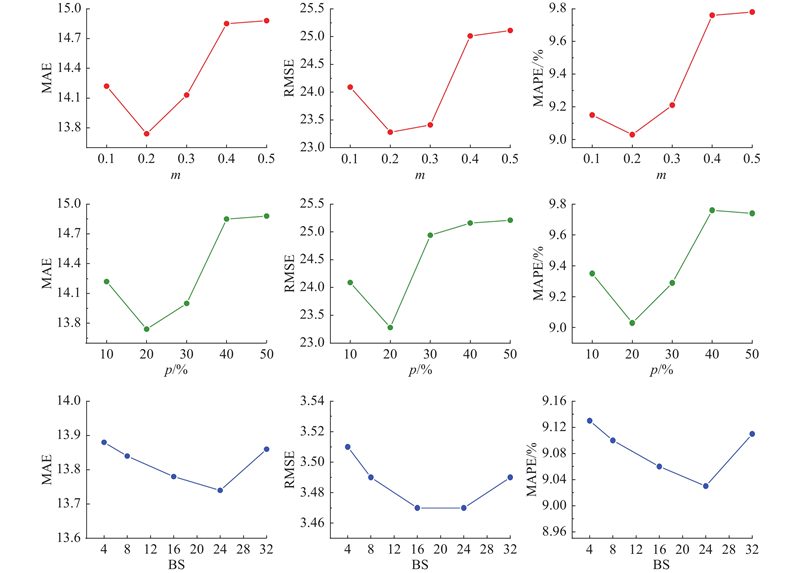
在渐进调优机制中,调优参数m控制历史与当前时间片段特征的融合比例,影响方差和均值的更新幅度. 当m从0.1增至0.2时,模型性能提升,并在m = 0.2时达到最优. 继续增大m,则性能下降. 适度赋予当前时间片权重有助于捕捉实时交通状态,而过高的权重可能导致模型过度依赖短期信息,削弱对历史模式的利用.
在核心流动点识别模块中,核心流动点比例是构建稀疏邻接矩阵的关键参数. 当比例为10%~20%时,MAE从14.1降至13.8,性能显著提升;在比例超过20%后,MAE升至14.8,性能下降. 比例过低会丢失关键信息,比例过高会引入冗余信息. 实验确定20%是最优的核心流动点比例.
模型对批大小的敏感度较低. 在测试范围内,MAE的波动不超过0.1,当批大小为24时性能略优,但优势不显著. 模型在不同的批大小下均能够保持稳定的预测性能.
4.5. 过程性仿真
通过特征可视化系统分析模型学习的表征,以增强模型的可解释性,揭示模型与现实环境中关键因素的关联.
图 12
如图13所示为核心与非核心流动点的流量特征对比. 非核心流动点(1、2、3号节点)显示出较小的流量波动和较低的峰谷差异. 核心流动点(1、2、3号节点)表现出更大的流量波动和明显的峰谷差异,这归因于他们位于主要交通干道、道路交汇处或城市中心. 此外,核心流动点间存在高度相似的流量模式,具有明显的一致趋势和周期性,反映了核心流动点群内部的同质性. 次要交通路网中的非核心流动点呈现出相对稳定、波动幅度较小的低强度同质化流量模式.
图 13
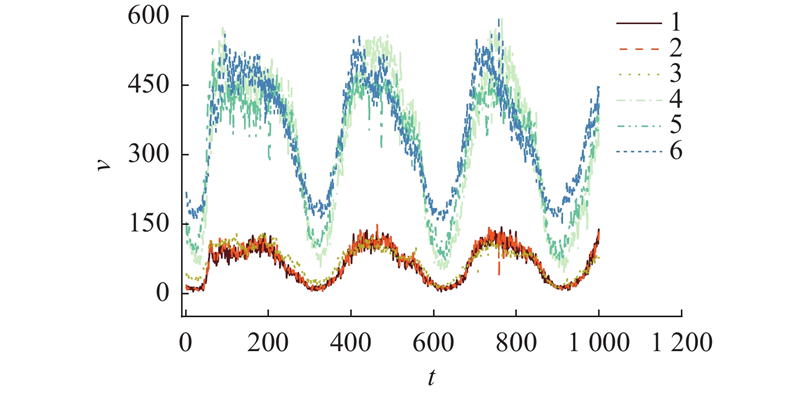
图 13 核心与非核心流动点的流量时变模式对比
Fig.13 Comparison of flow time-varying pattern between core and non-core flow point
如图14所示为使用t-SNE降维的不同日期数据在低维空间中的分布. 通过自适应高频异质化模块,模型有效聚合了同期数据点,不同日期的数据簇明显分离. 工作日的数据簇呈现出高度内聚而又相互分离的特征,反映出工作日交通模式的相似性与差异性. 休息日(周六和周日)数据形成独立簇,其特征与工作日显著不同,呈现低流量的特征. 这验证了模型能够有效地捕获交通流的时间异质性.
图 14

图 14 基于不同日期数据的t-SNE降维可视化
Fig.14 Dimensionality reduction visualization of t-SNE based on data from different date
如图15所示为PEMS08数据集中某随机节点的交通流量真实值与CFHD-Former及基线模型DGCRN的预测结果对比. 结果表明,CFHD-Former在捕捉局部波动方面精度更高,能够更准确地追踪流量的细微变化. 该模型对高频特征具有更强的敏感性及识别短时域动态模式的能力. DGCRN的预测结果较平滑,捕捉高频特征的能力较弱.
图 15
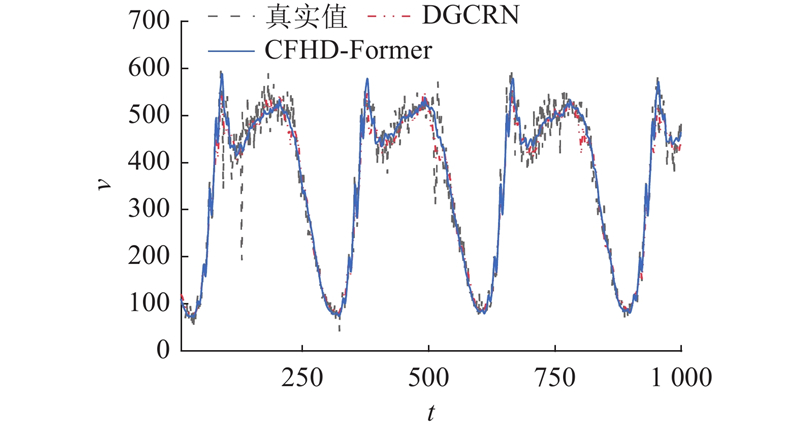
图 15 CFHD-Former与DGCRN拟合真实值的对比
Fig.15 Comparison of CFHD-Former and DGCRN fitting true value
4.6. 鲁棒性实验
交通流预测易受传感器误差、数据传输、通信干扰及少数极端天气等噪声的影响,故模型的抗干扰能力会直接影响预测精度. 为了评估CFHD-Former模型的稳健性,设计扰动实验. 标准化训练数据,随机丢弃10%的传感器节点数据以模拟数据缺失,对各节点分别叠加10%~50%比例、服从标准正态分布的高斯噪声,模拟不同程度的数据污染. 实验在PEMS08数据集上开展,以多步预测的平均均方根误差作为评估指标. 实验结果如图16所示. 其中,rp为数据扰动比例.
图 16
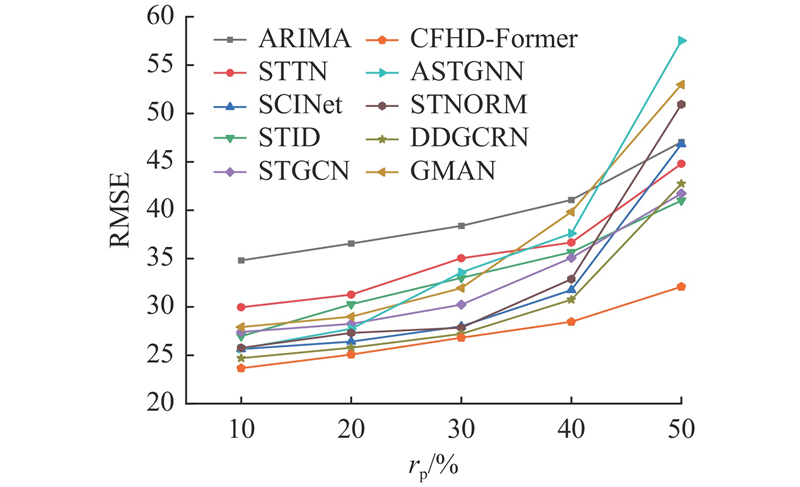
图 16 CFHD-Former与基线模型在不同扰动比例噪声下的预测误差对比
Fig.16 Comparison of prediction error between CFHD-Former and baseline model under different perturbation ratio noise
实验显示,当噪声比例从10%增至50%时,所有基准模型的RMSE均持续上升. 在低扰动(10%~30%)下,性能衰退相对平缓. 当扰动比例超过40%时,多数模型的误差显著增大,特别是ASTGNN和GMAN的RMSE在50%扰动比例下显著升高. CFHD-Former的RMSE始终最低,且性能衰减最平缓,展现出了优异的稳健性,即使在高噪声环境下也能保持相对稳定的预测性能.
5. 结 语
提出新型的交通流预测模型CFHD-Former,旨在解决复杂路网中的时空异质性问题. 研究的主要成果如下. 1)通过自适应高频异质化模块与渐进调优机制,有效捕捉交通流的动态时间特征. 2)提出核心流动点识别模块,对核心与非核心路网进行分层建模,精准捕捉空间异质特征. 3)引入频域自相关MAE损失函数,通过规避预测序列的内部依赖性,提升多步预测的精度. 实验结果表明,CFHD-Former在多个公开数据集上的预测精度和鲁棒性均优于现有的基线模型. 未来的研究可以致力于模型的轻量化以降低计算开销,从而提升在真实交通系统中的部署与应用效率.
参考文献
Passenger flow prediction of subway transfer stations based on nonparametric regression model
[J].
Sequence to sequence learning with attention mechanism for short-term passenger flow prediction in large-scale metro system
[J].DOI:10.1016/j.trc.2019.08.005 [本文引用: 1]
Spatio-temporal pivotal graph neural networks for traffic flow forecasting
[J].DOI:10.1609/aaai.v38i8.28707 [本文引用: 1]
Mode decomposition based deep learning model for multi-section traffic prediction
[J].DOI:10.1007/s11280-020-00791-1 [本文引用: 1]
Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: theoretical basis and empirical results
[J].DOI:10.1061/(ASCE)0733-947X(2003)129:6(664) [本文引用: 1]
SCINet: Time series modeling and forecasting with sample convolution and interaction
[J].
Dynamic graph convolutional recurrent network for traffic prediction: benchmark and solution
[J].
GMAN: a graph multi-attention network for traffic prediction
[J].DOI:10.1609/aaai.v34i01.5477 [本文引用: 1]
PDFormer: propagation delay-aware dynamic long-range transformer for traffic flow prediction
[J].DOI:10.1609/aaai.v37i4.25556 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}