(10) $ {\boldsymbol{\mu }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t|\boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}},s)={\boldsymbol{\mu }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t,{\boldsymbol{\varepsilon }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t|\boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}},s)), $
[1]
王永生, 关世杰, 刘利民, 等 基于XGBoost扩展金融因子的风电功率预测方法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (5 ): 1038 - 1049
[本文引用: 1]
WANG Yongsheng, GUAN Shijie, LIU Limin, et al Wind power prediction method based on XGBoost extended financial factor
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (5 ): 1038 - 1049
[本文引用: 1]
[2]
YAO Q, ZHU H, XIANG L, et al A novel composed method of cleaning anomy data for improving state prediction of wind turbine
[J]. Renewable Energy , 2023 , 204 : 131 - 140
DOI:10.1016/j.renene.2022.12.118
[本文引用: 1]
[3]
PANG G, SHEN C, CAO L, et al Deep learning for anomaly detection: a review
[J]. ACM Computing Surveys , 2022 , 54 (2 ): 1 - 38
[本文引用: 1]
[4]
魏泰, 贺少雄, 胡子武, 等 基于改进孤立森林算法的风电机组异常数据清洗
[J]. 科学技术与工程 , 2024 , 24 (9 ): 3691 - 3699
DOI:10.12404/j.issn.1671-1815.2302642
[本文引用: 1]
WEI Tai, HE Shaoxiong, HU Ziwu, et al Wind turbine abnormal data cleaning based on an improved isolation forest algorithm
[J]. Science Technology and Engineering , 2024 , 24 (9 ): 3691 - 3699
DOI:10.12404/j.issn.1671-1815.2302642
[本文引用: 1]
[5]
XIANG L, YANG X, HU A, et al Condition monitoring and anomaly detection of wind turbine based on cascaded and bidirectional deep learning networks
[J]. Applied Energy , 2022 , 305 : 117925
DOI:10.1016/j.apenergy.2021.117925
[本文引用: 1]
[6]
刘宇璐. 物理模型与数据驱动融合的风电机组功率数据异常辨识和插补方法 [D]. 北京: 华北电力大学, 2024.
[本文引用: 1]
LIU Yulu. A physics-guided and data-driven integration of wind turbine power data anomaly identification and interpolation method. [D]. Beijing: North China Electric Power University, 2024.
[本文引用: 1]
[7]
罗朗川, 李汝辉, 曾东, 等 基于RANSAC-DBSCAN的风速功率曲线异常数据清洗方法
[J]. 太阳能学报 , 2025 , 46 (4 ): 445 - 453
DOI:10.19912/j.0254-0096.tynxb.2023-2072
[本文引用: 2]
LUO Langchuan, LI Ruhui, ZENG Dong, et al Abnormal data cleaning method of wind speed-power curve based on RANSAC-DBSCAN
[J]. Acta Energiae Solaris Sinica , 2025 , 46 (4 ): 445 - 453
DOI:10.19912/j.0254-0096.tynxb.2023-2072
[本文引用: 2]
[8]
DU W, GUO Z, LI C, et al From anomaly detection to novel fault discrimination for wind turbine gearboxes with a sparse isolation encoding forest
[J]. IEEE Transactions on Instrumentation and Measurement , 2022 , 71 : 2512710
DOI:10.1109/tim.2022.3187737
[本文引用: 1]
[9]
ZHANG S, WANG F. B-LSTM ultra-short-term wind power prediction based on LOF data anomaly detection [C]// Proceedings of the Second International Conference on Physics, Photonics, and Optical Engineering . Kunming: SPIE, 2024: 22.
[本文引用: 2]
[10]
柳源, 李忠虎, 王金明, 等 风电机组SCADA“风速-功率”数据处理方法研究
[J]. 太阳能学报 , 2025 , 46 (7 ): 353 - 360
DOI:10.19912/j.0254-0096.tynxb.2024-0383
[本文引用: 1]
LIU Yuan, LI Zhonghu, WANG Jinming, et al Research on data processing methods for “wind speed-power” in wind turbine scada systems
[J]. Acta Energiae Solaris Sinica , 2025 , 46 (7 ): 353 - 360
DOI:10.19912/j.0254-0096.tynxb.2024-0383
[本文引用: 1]
[11]
CHEN H, LIU H, CHU X, et al Anomaly detection and critical SCADA parameters identification for wind turbines based on LSTM-AE neural network
[J]. Renewable Energy , 2021 , 172 : 829 - 840
DOI:10.1016/j.renene.2021.03.078
[本文引用: 1]
[12]
SUI J, YU J, SONG Y, et al Anomaly detection for telemetry time series using a denoising diffusion probabilistic model
[J]. IEEE Sensors Journal , 2024 , 24 (10 ): 16429 - 16439
DOI:10.1109/JSEN.2024.3383416
[本文引用: 1]
[13]
HU R, YUAN X, QIAO Y, et al. Unsupervised anomaly detection for multivariate time series using diffusion model [C]// 2024 IEEE International Conference on Acoustics, Speech and Signal Processing . Seoul: IEEE, 2024: 9606–9610.
[本文引用: 2]
[14]
CHEN Y, ZHANG C, MA M, et al ImDiffusion: imputed diffusion models for multivariate time series anomaly detection
[J]. Proceedings of the VLDB Endowment , 2023 , 17 (3 ): 359 - 372
DOI:10.14778/3632093.3632101
[本文引用: 2]
[15]
苗长新, 周志伟, 杨千禧, 等 基于分布特征的风电异常数据检测方法
[J]. 太阳能学报 , 2025 , 46 (7 ): 395 - 402
DOI:10.19912/j.0254-0096.tynxb.2024-0443
[本文引用: 1]
MIAO Changxin, ZHOU Zhiwei, YANG Qianxi, et al Anomaly detection method for wind power based on distribution characteristics
[J]. Acta Energiae Solaris Sinica , 2025 , 46 (7 ): 395 - 402
DOI:10.19912/j.0254-0096.tynxb.2024-0443
[本文引用: 1]
[17]
FENG C, LIU C, JIANG D Unsupervised anomaly detection using graph neural networks integrated with physical-statistical feature fusion and local-global learning
[J]. Renewable Energy , 2023 , 206 : 309 - 323
DOI:10.1016/j.renene.2023.02.053
[本文引用: 1]
[18]
LIU Y, HU T, ZHANG H, et al. iTransformer: inverted transformers are effective for time series forecasting [EB/OL]. (2024–05–14)[2025–05–30]. https://arxiv.org/pdf/2310.06625.
[本文引用: 1]
[19]
LI X, XIAO C, FENG Z, et al Controlled graph neural networks with denoising diffusion for anomaly detection
[J]. Expert Systems with Applications , 2024 , 237 : 121533
DOI:10.1016/j.eswa.2023.121533
[本文引用: 1]
[20]
缑泽华. 基于扩散模型的时间序列数据填充与检测方法 [D]. 开封: 河南大学, 2024.
[本文引用: 1]
GOU Zehua. Time-series data imputation and detection method based on diffusion model [D]. Kaifeng: Henan University, 2024.
[本文引用: 1]
[21]
ZHANG Y, CHEN Y, WANG J, et al Unsupervised deep anomaly detection for multi-sensor time-series signals
[J]. IEEE Transactions on Knowledge and Data Engineering , 2023 , 35 (2 ): 2118 - 2132
DOI:10.1109/tkde.2021.3102110
[本文引用: 1]
[22]
姚禹, 张志厚, 石泽玉, 等 基于支持向量回归的一维频率域航空电磁反演
[J]. 浙江大学学报: 工学版 , 2022 , 56 (1 ): 202 - 212
DOI:10.3785/j.issn.1008-973X.2022.01.023
[本文引用: 1]
YAO Yu, ZHANG Zhihou, SHI Zeyu, et al Airborne electromagnetic inversion in one-dimensional frequency-domain based on support vector regression
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (1 ): 202 - 212
DOI:10.3785/j.issn.1008-973X.2022.01.023
[本文引用: 1]
[23]
TULI S, CASALE G, JENNINGS N R TranAD: deep transformer networks for anomaly detection in multivariate time series data
[J]. Proceedings of the VLDB Endowment , 2022 , 15 (6 ): 1201 - 1214
DOI:10.14778/3514061.3514067
[本文引用: 1]
[24]
林立栋. 基于概率统计方法的风电机组异常数据识别方法研究 [D]. 北京: 华北电力大学, 2023.
[本文引用: 1]
LIN Lidong. Research on wind turbine abnormal data identification method based on probability and statisties method [D]. Beijing: North China Electric Power University, 2023.
[本文引用: 1]
基于XGBoost扩展金融因子的风电功率预测方法
1
2023
... 风能的随机性和波动性对风电场调度构成挑战[1 ] . 在基于监控与数据采集系统(supervisory control and data acquisition, SCADA)进行风电数据采集时,受设备故障和测量误差的影响,常出现异常值,降低风能评估和数据分析的准确性. ...
基于XGBoost扩展金融因子的风电功率预测方法
1
2023
... 风能的随机性和波动性对风电场调度构成挑战[1 ] . 在基于监控与数据采集系统(supervisory control and data acquisition, SCADA)进行风电数据采集时,受设备故障和测量误差的影响,常出现异常值,降低风能评估和数据分析的准确性. ...
A novel composed method of cleaning anomy data for improving state prediction of wind turbine
1
2023
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
Deep learning for anomaly detection: a review
1
2022
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
基于改进孤立森林算法的风电机组异常数据清洗
1
2024
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
基于改进孤立森林算法的风电机组异常数据清洗
1
2024
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
Condition monitoring and anomaly detection of wind turbine based on cascaded and bidirectional deep learning networks
1
2022
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
1
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
1
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
基于RANSAC-DBSCAN的风速功率曲线异常数据清洗方法
2
2025
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
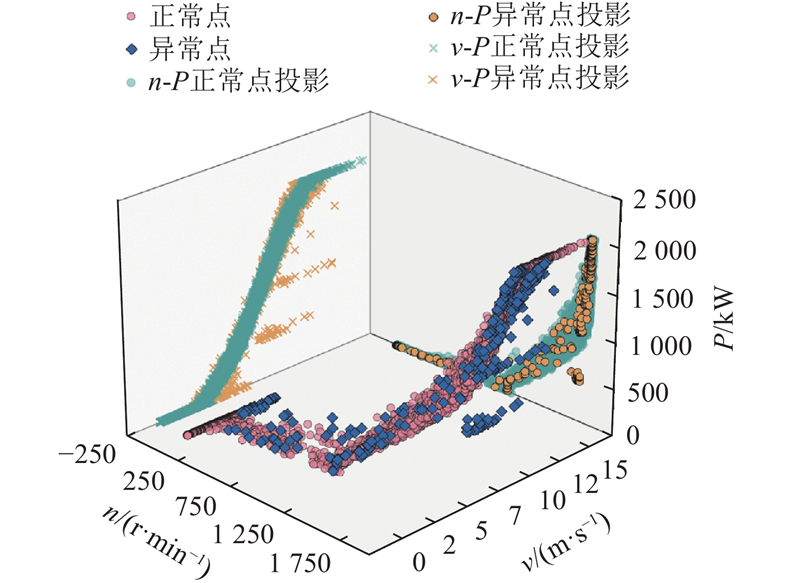
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
基于RANSAC-DBSCAN的风速功率曲线异常数据清洗方法
2
2025
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
From anomaly detection to novel fault discrimination for wind turbine gearboxes with a sparse isolation encoding forest
1
2022
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
2
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
风电机组SCADA“风速-功率”数据处理方法研究
1
2025
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
风电机组SCADA“风速-功率”数据处理方法研究
1
2025
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
Anomaly detection and critical SCADA parameters identification for wind turbines based on LSTM-AE neural network
1
2021
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
Anomaly detection for telemetry time series using a denoising diffusion probabilistic model
1
2024
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
2
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
ImDiffusion: imputed diffusion models for multivariate time series anomaly detection
2
2023
... 为了真实反映风电机组的运行状态,亟须对风电数据进行清洗[2 ] . 常用数据清洗方法主要包括:基于物理模型[3 ] 、机器学习[4 ] 和时序建模[5 ] 的方法. 基于物理模型的方法通过拟合风功率曲线识别风速-功率关系异常,具有较强可解释性,但在风机状态频繁变化时拟合精度下降. 例如,刘宇璐[6 ] 提出融合风速变化与湍流效应的动态功率曲线建模方法,虽能提升响应性,但对模型误差和控制器调参较为敏感,泛化能力有限. 基于机器学习的方法,如基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN)[7 ] 、孤立森林(isolation forest, IF)[8 ] 及局部异常因子(local outlier factor, LOF)[9 ] 等,适用于处理高维风电数据,对超参数较为敏感. 例如,柳源等[10 ] 采用DBSCAN算法剔除额定功率数据附近的噪声数据点,在密度差异较大的区域易发生误判或漏检. 基于时序建模的方法,如长短期记忆网络(long short-term memory, LSTM)[11 ] 和去噪扩散概率模型(denoising diffusion probabilistic models, DDPM)[12 ] ,可建模时间依赖性,在风电数据清洗研究中广泛应用. Hu等[13 ] 提出基于扩散模型的无监督异常检测方法TimeADDM,Chen等[14 ] 提出融合时间填充与扩散模型的ImDiffusion框架. 将扩散机制引入异常检测,虽然为复杂时序建模与无标签高质量异常重建提供了新思路,但异常点往往只占很小比例,扩散模型在学习过程中主要拟合“正常分布”,可能导致模型在异常稀疏条件下的判别能力不足. ...
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
基于分布特征的风电异常数据检测方法
1
2025
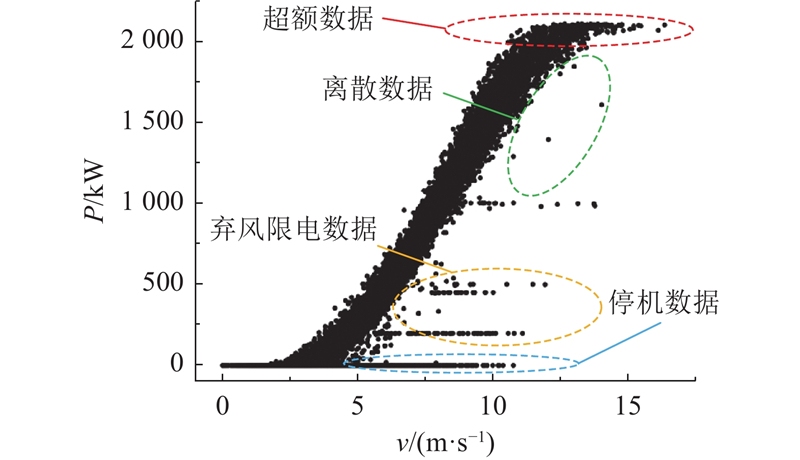
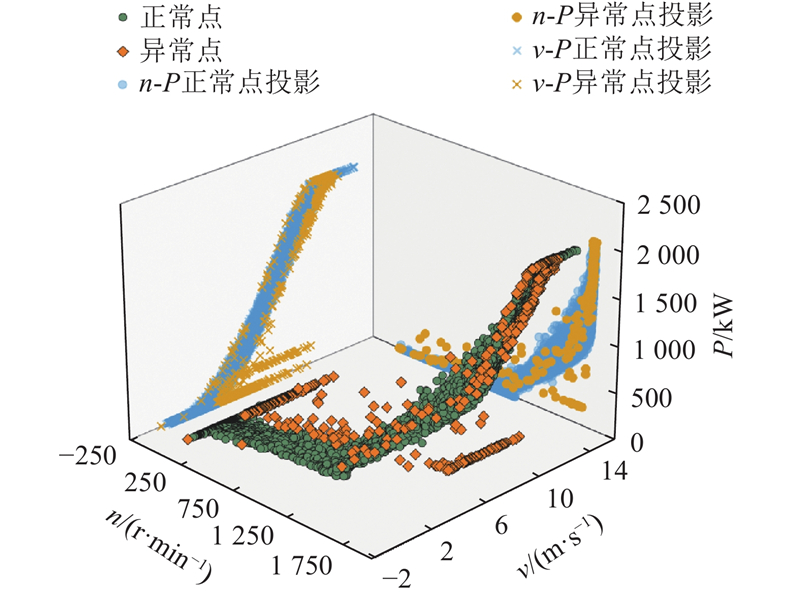
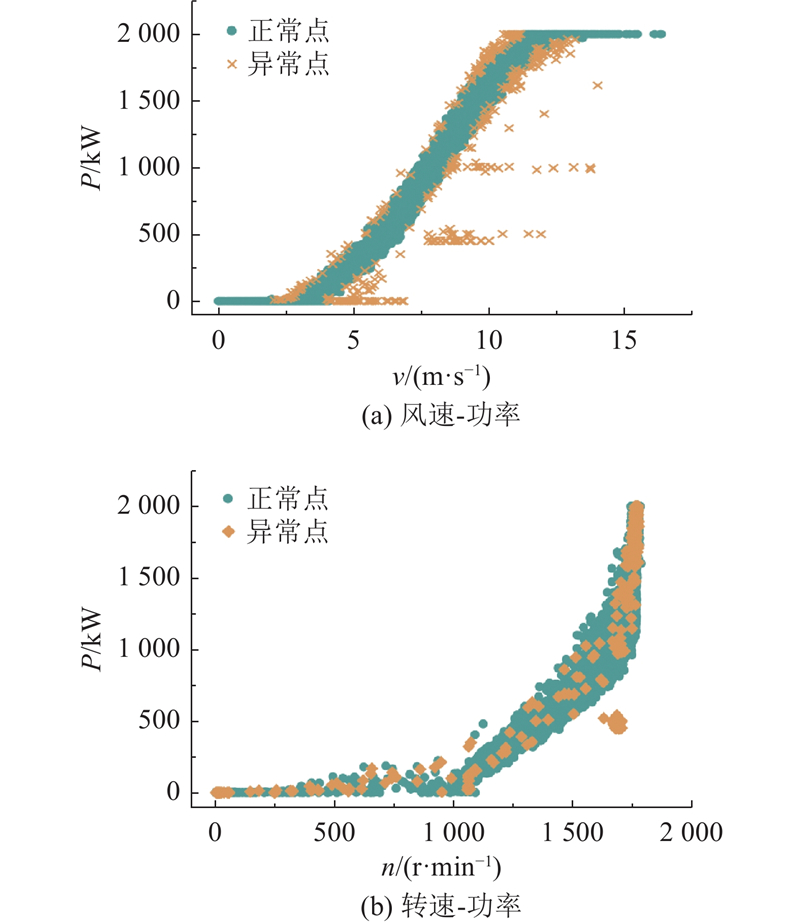
... 如图1 所示为某风电场一号风机2021年1月1日至10月1日的风速-功率数据分布,P 为功率,v 为风速. 异常数据分为4类[15 ] :1)超额数据,即功率超出额定值的离群点;2)离散数据,即偏离风速-功率曲线的无规律孤立点;3)弃风限电数据,表现为风速曲线附近的横向密集带;4)停机数据,指在风速大于切入风速时功率为零的点. ...
基于分布特征的风电异常数据检测方法
1
2025
... 如图1 所示为某风电场一号风机2021年1月1日至10月1日的风速-功率数据分布,P 为功率,v 为风速. 异常数据分为4类[15 ] :1)超额数据,即功率超出额定值的离群点;2)离散数据,即偏离风速-功率曲线的无规律孤立点;3)弃风限电数据,表现为风速曲线附近的横向密集带;4)停机数据,指在风速大于切入风速时功率为零的点. ...
基于加速扩散模型的缺失值插补算法
1
2025
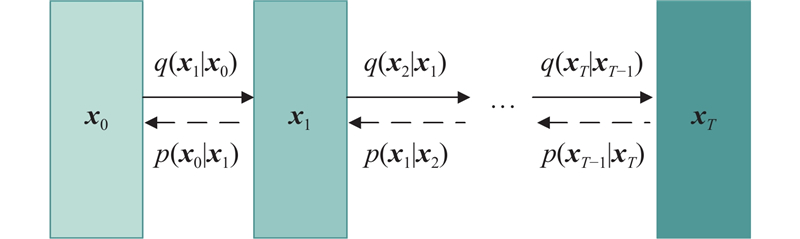
... DDPM的核心思想是通过前向扩散向原始数据中加入高斯噪声,使其演化为纯噪声;再通过反向去噪,还原出原始数据[16 ] . 如图2 所示为前向扩散与反向生成过程,$ {\boldsymbol{x}}_{0} $ $ {\boldsymbol{x}}_{1},{\boldsymbol{x}}_{2},\cdots,{\boldsymbol{x}}_{T} $ $ T $ $ q(\cdot ) $ $ p(\cdot ) $ $ q({\boldsymbol{x}}_{t}|{\boldsymbol{x}}_{t-1})= N({\boldsymbol{x}}_{t}; \sqrt{1-{\beta }_{t}}{\boldsymbol{x}}_{t-1},\;{\beta }_{t}\boldsymbol{I}) $ $ {\beta }_{t} $ $ \boldsymbol{I} $ $ {\boldsymbol{x}}_{t} $ $ {\boldsymbol{x}}_{0} $ $ \boldsymbol{\varepsilon }\sim N(0,\boldsymbol{I}) $
基于加速扩散模型的缺失值插补算法
1
2025
... DDPM的核心思想是通过前向扩散向原始数据中加入高斯噪声,使其演化为纯噪声;再通过反向去噪,还原出原始数据[16 ] . 如图2 所示为前向扩散与反向生成过程,$ {\boldsymbol{x}}_{0} $ $ {\boldsymbol{x}}_{1},{\boldsymbol{x}}_{2},\cdots,{\boldsymbol{x}}_{T} $ $ T $ $ q(\cdot ) $ $ p(\cdot ) $ $ q({\boldsymbol{x}}_{t}|{\boldsymbol{x}}_{t-1})= N({\boldsymbol{x}}_{t}; \sqrt{1-{\beta }_{t}}{\boldsymbol{x}}_{t-1},\;{\beta }_{t}\boldsymbol{I}) $ $ {\beta }_{t} $ $ \boldsymbol{I} $ $ {\boldsymbol{x}}_{t} $ $ {\boldsymbol{x}}_{0} $ $ \boldsymbol{\varepsilon }\sim N(0,\boldsymbol{I}) $
Unsupervised anomaly detection using graph neural networks integrated with physical-statistical feature fusion and local-global learning
1
2023
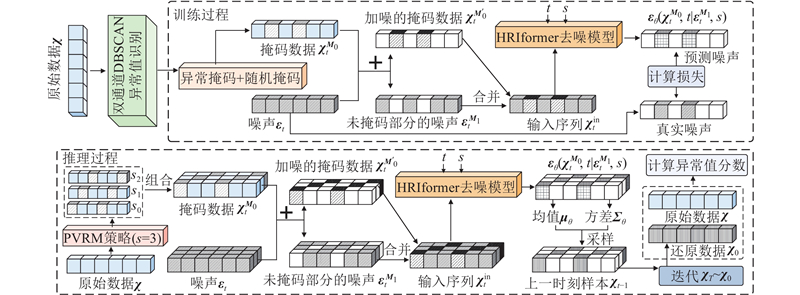
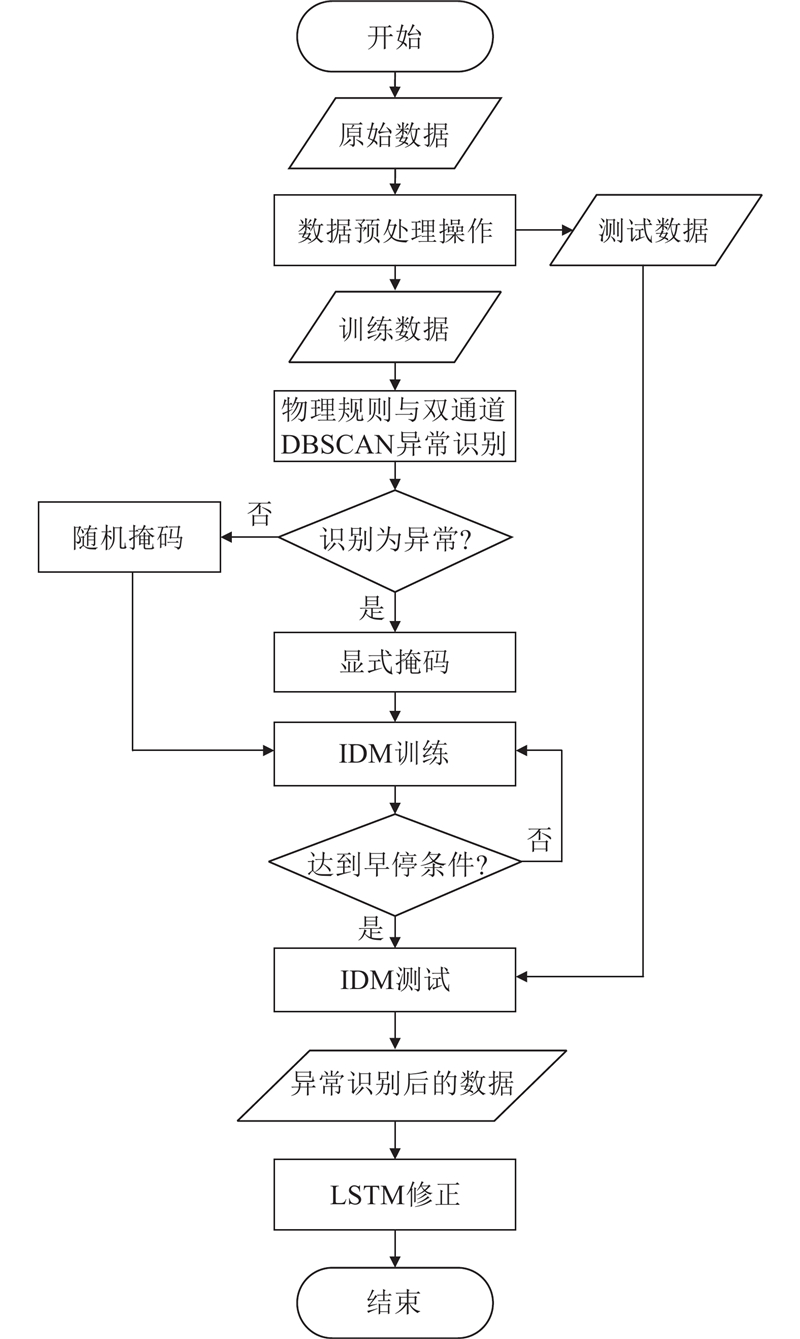
... 风电场SCADA数据通常缺乏异常值标签,难以直接采用有监督的方法进行异常识别[17 ] . 本研究结合SCADA数据特点,提出自监督异常数据识别方法与有监督的修正方法,即IDM-LSTM. ...
1
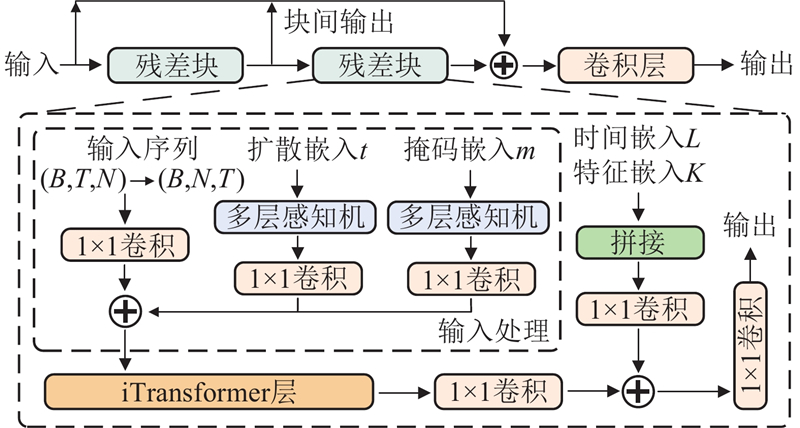
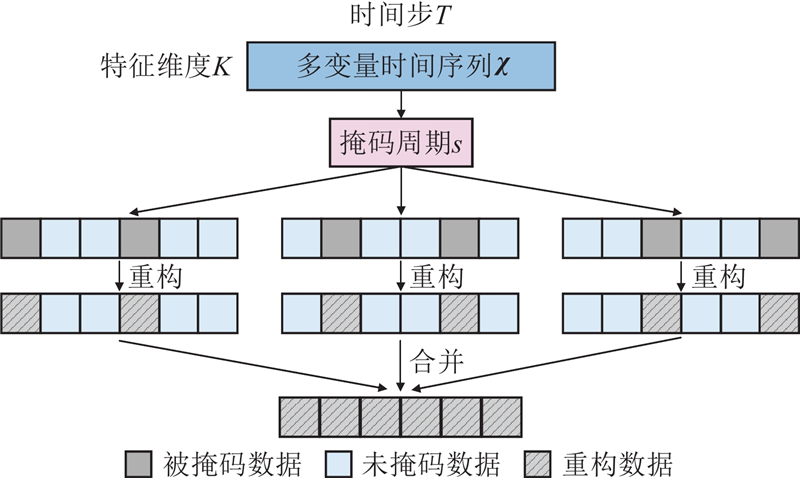
... HRIformer结合倒置Transformer (inverted Transformer, iTransformer)模型[18 ] 与分层残差结构. iTransformer通过自注意力机制捕捉长时依赖,利用前馈网络提取时序特征. 残差结构则缓解深层特征退化问题. HRIformer结构如图4 所示,其中B 为批次大小,T 为序列长度,N 为特征维度,L 为时间嵌入维度,K 为特征嵌入维度. 每个残差块由输入处理模块、特征增强模块和iTransformer模块组成. 输入处理模块将原始数据转化为适合iTransformer的输入维度,通过多层感知机和卷积层嵌入扩散步骤与掩码信息,生成含多重嵌入的张量. 特征增强模块将时间嵌入与特征嵌入作为外部信息,优化最终输出. iTransformer采用倒置结构,将每个特征视作独立整体,通过自注意力建模变量相关性,并结合前馈网络提取序列信息,避免多维度量差异带来的干扰. ...
Controlled graph neural networks with denoising diffusion for anomaly detection
1
2024
... 式中:$ {\boldsymbol{\mu }}_{\theta }(\cdot ) $ $ {\boldsymbol{\varSigma }}_{\theta }(\cdot ) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta } $ . 式(12)将扩散模型中原始损失函数[19 ] 的$ {\boldsymbol{\varepsilon }}_{\theta }({\boldsymbol{\chi }}_{t},t) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t|\boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}},s) $ . 推理过程中的异常分数利用残差进行计算[20 ] ,残差反映原始数据与预测数据之间的差异: ...
1
... 式中:$ {\boldsymbol{\mu }}_{\theta }(\cdot ) $ $ {\boldsymbol{\varSigma }}_{\theta }(\cdot ) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta } $ . 式(12)将扩散模型中原始损失函数[19 ] 的$ {\boldsymbol{\varepsilon }}_{\theta }({\boldsymbol{\chi }}_{t},t) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t|\boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}},s) $ . 推理过程中的异常分数利用残差进行计算[20 ] ,残差反映原始数据与预测数据之间的差异: ...
1
... 式中:$ {\boldsymbol{\mu }}_{\theta }(\cdot ) $ $ {\boldsymbol{\varSigma }}_{\theta }(\cdot ) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta } $ . 式(12)将扩散模型中原始损失函数[19 ] 的$ {\boldsymbol{\varepsilon }}_{\theta }({\boldsymbol{\chi }}_{t},t) $ $ \boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}} $ $ s $ $ {\boldsymbol{\varepsilon }}_{\theta }(\boldsymbol{\chi }_{t}^{{\boldsymbol{M}}_{0}},t|\boldsymbol{\varepsilon }_{t}^{{\boldsymbol{M}}_{1}},s) $ . 推理过程中的异常分数利用残差进行计算[20 ] ,残差反映原始数据与预测数据之间的差异: ...
Unsupervised deep anomaly detection for multi-sensor time-series signals
1
2023
... 式中:$ \text{AS}\;({\boldsymbol{x}}_{i}) $ $ i $ $ {\boldsymbol{x}}_{i} $ $ \widehat{{\boldsymbol{x}}_{i}} $ $ K $ $ \boldsymbol{\chi }$ $ {\boldsymbol{x}}_{i} $ [21 ] : ...
基于支持向量回归的一维频率域航空电磁反演
1
2022
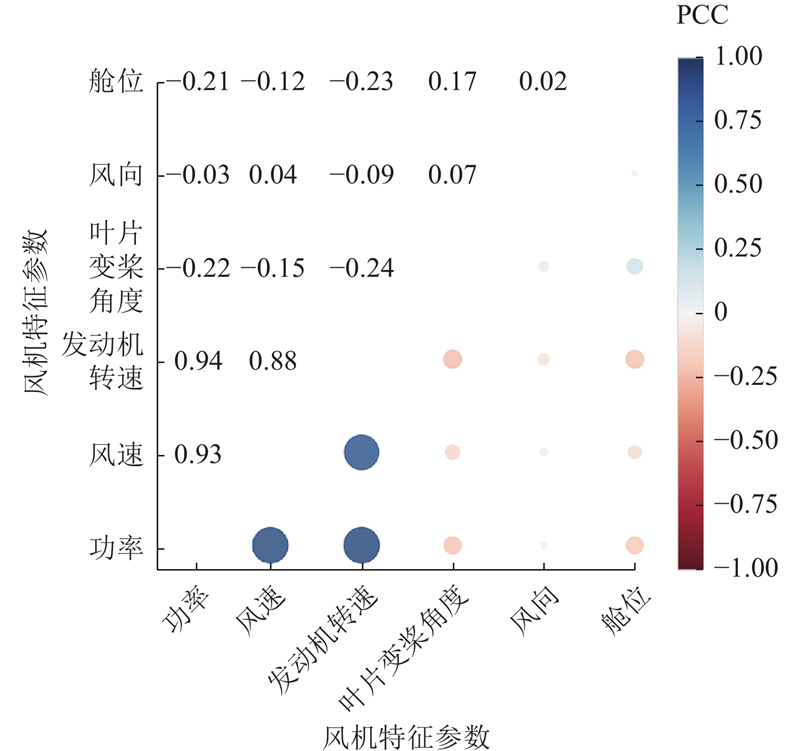
... 预处理后的数据按照7∶3的比例划分为训练集与测试集,对训练数据采用双重掩码协同策略处理. 2次DBSCAN算法的邻域半径$ \text{Eps}1 $ $ \text{Eps}2 $ $ \text{MinPts}1 $ $ \text{MinPts}2 $ [22 ] ,寻优结果如表1 所示. ...
基于支持向量回归的一维频率域航空电磁反演
1
2022
... 预处理后的数据按照7∶3的比例划分为训练集与测试集,对训练数据采用双重掩码协同策略处理. 2次DBSCAN算法的邻域半径$ \text{Eps}1 $ $ \text{Eps}2 $ $ \text{MinPts}1 $ $ \text{MinPts}2 $ [22 ] ,寻优结果如表1 所示. ...
TranAD: deep transformer networks for anomaly detection in multivariate time series data
1
2022
... 异常检测为自监督学习,缺乏精确标签,难以直接评估准确性,因此从定性与定量两方面验证效果. 如图10 所示为风速-功率和转速-功率的二维投影,可见大部分异常值已被识别,数据分布边缘更为平滑,表明方法有效. 对比原始数据、LOF[9 ] 、DBSCAN[7 ] 、DBSCAN+IF、IMDiffusion[14 ] 、TranAD[23 ] 、TimeADDM[13 ] 以及IDM的风速-功率和转速-功率的皮尔森相关性系数和异常值识别率,不同方法的识别效果汇总如表3 所示. 皮尔森相关性系数衡量剔除异常前后风速-功率与转速-功率的相关性强度: ...
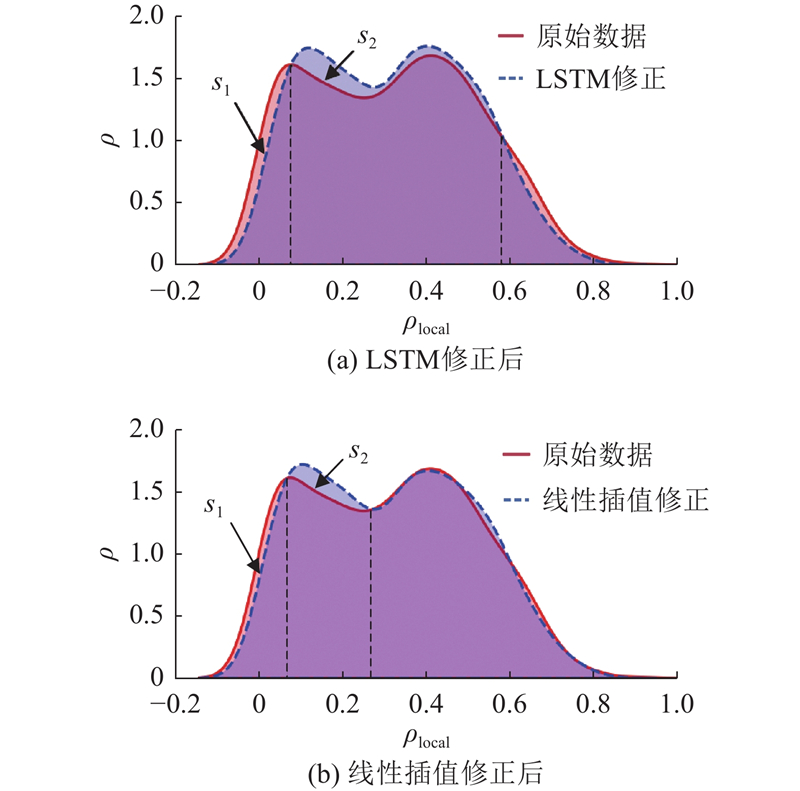
1
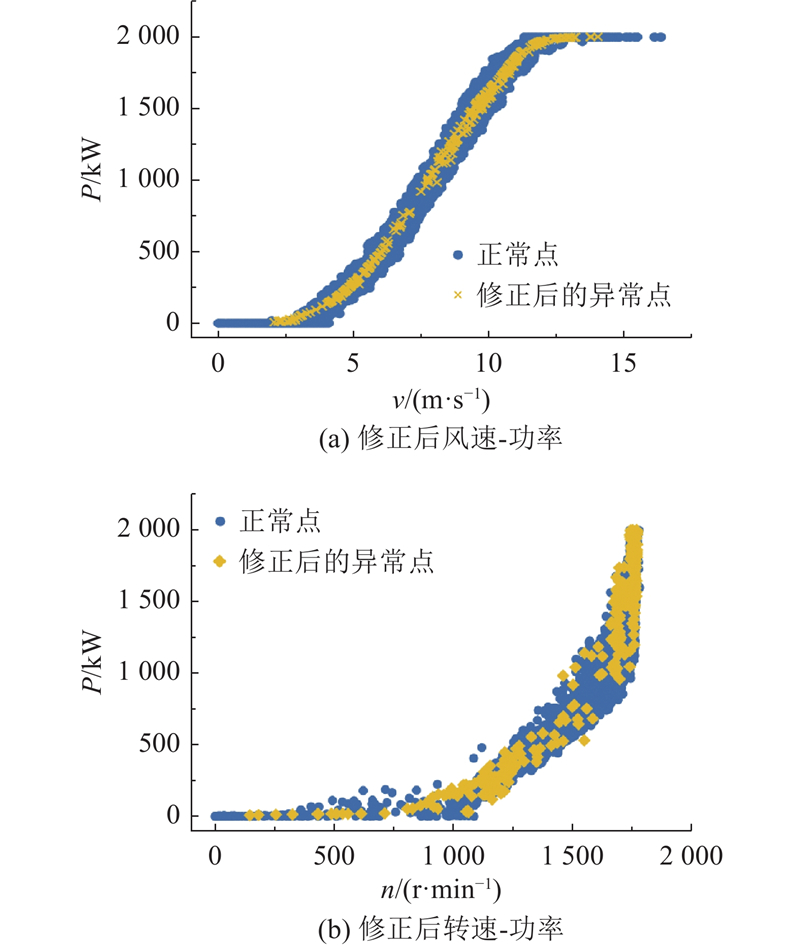
... 为了进一步验证深度学习方法在数据修正中的优势,对比LSTM与线性插值方法修正后数据的概率密度曲线[24 ] ,如图13 所示. 样本局部密度为$ {\rho }_{\text{local}} $ $ \rho $ $ {s}_{1} $ $ {s}_{2} $ . 2种修正方法均有效改变了数据的分布,显著降低了低密度样本的比例. 如表6 所示,相较于线性插值法,LSTM修正后的$ {s}_{1} $ $ {s}_{2} $
1
... 为了进一步验证深度学习方法在数据修正中的优势,对比LSTM与线性插值方法修正后数据的概率密度曲线[24 ] ,如图13 所示. 样本局部密度为$ {\rho }_{\text{local}} $ $ \rho $ $ {s}_{1} $ $ {s}_{2} $ . 2种修正方法均有效改变了数据的分布,显著降低了低密度样本的比例. 如表6 所示,相较于线性插值法,LSTM修正后的$ {s}_{1} $ $ {s}_{2} $



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}