

随着烟草行业的持续发展,烟草制品的消费需求逐渐向更多元化和分散化的趋势发展. 在某些地广人稀、零售户分布不均衡的地区,由于地理位置和空间环境的限制,人工进行配送路径规划存在货物无法及时送达、配送成本极高的问题,造成零售户经营受影响以及物流中心成本过高的问题. 为了满足偏远地区分布不均衡的客户的需求,研究卷烟的配送路径. 提高配送效率、降低配送成本是卷烟配送过程中亟待解决的问题. 在地广人稀、烟草零售户分布不均的特定环境下,配送距离从1公里至数百公里不等,若按照现有的配送方案一一为客户进行配送,配送距离较长、配送次数较多,导致效率低下、配送成本增加. 现有配送主要通过货车公路运输,会导致汽车尾气排放增加. 因此,本研究引入快递行业的自提点模式,以期降低物流中心配送成本. 不仅给予零售户选择的权利、提高了配送的灵活性,也能降低配送成本、减少对环境的污染. 因此,本研究开展了针对地广人稀、零售户分布不均衡区域卷烟自提点选址及配送路径规划的研究. 自提点选址决定了客户从何处取货,而路径规划则决定了如何高效地将货物送到各个自提点. 两者结合研究有助于大幅度地降低运输成本.
近年来,车辆路径规划(vehicle routing problem,VRP)在卷烟配送领域的应用研究取得了显著进展. 在VRP问题的求解方面,与传统精确算法相比,启发式算法通过局部优化、邻域搜索和概率性跳出局部最优等机制,能够有效兼顾解的质量与计算效率. Archetti等[1]针对分体配送车辆路径问题,提出变体的分体配送车辆路径,改进了启发式算法的精确性;范文兵等[2]针对启发式算法收敛速度慢、配送成本高的问题,改进了传统的启发式规划算法,以跳出局部最优,在求解过程中取得了良好的效果;方文婷等[3]针对蚁群算法初始阶段由于信息素不足导致收敛速度慢的问题,将A*算法与蚁群算法相结合,利用A*算法的全局收敛性和蚁群算法的正反馈性构造了一种混合蚁群算法. TAN等[4]提出混合多目标进化算法,该算法在进化搜索中融入了多种启发式算法以进行局部开发,并引入帕累托最优性的概念来解决VRPTW中的多目标优化问题. 方昕[5]提出的引入惯性权重的新型粒子群算法在都市圈多站点配送中表现优异,但其节点数太少. 上述研究多聚焦于零售户分布密集或半密集区域如城市商圈,对地广人稀、零售户分布高度不均衡区域的适配性不足. 快递行业通过引入自提点来降低物流中心的配送成本[6]. 为了降低偏远区域配送成本,烟草公司也可借鉴该方式. 李谊等[7]提出基于多视角聚类的配送中心选址模型,但其聚焦于宏观物流网络,未细化至零售户优先级;Zhu等[8]的ZK-means算法与Lin等[9]的密度峰值改进方法,虽然提升了聚类稳定性,但其距离度量仍以物理空间维度为主,未融合实际配送中的经济指标. 在卷烟实际配送过程中,还应考虑零售户的实际经济效益、历史经营情况. 因此,需要符合卷烟配送实际情况的自提点选址方法. 此外,尽管部分学者利用改进启发式算法求解卷烟配送问题,但其优化目标仍以单一成本或时间窗约束为主,缺乏对多目标协同优化的系统考量. 例如,Archetti等[1]的分体配送模型虽能降低车辆空载率,却未考虑时间窗违约与零售户优先级惩罚成本的耦合效应;Li等[10]与张平莉[11]的研究在客户优先级建模上取得进展,但其优先级定义多依赖静态指标如订单量,未结合零售户的历史经营动态与区域经济特征,可能会导致稀疏分布场景下的配送灵活性不足. 上述局限性导致现有选址方案在稀疏区域易出现自提点覆盖不足或运营成本过高的问题. 多目标路径规划研究近年来逐步深入,但在地广人稀场景下的协同优化方面仍面临挑战.
现有研究方法在地广人稀、零售户分布不均衡的烟草物流场景中存在系统性局限. 选址问题的传统数学模型为P-中值数学模型[12],依赖均匀分布假设,与本研究的地广人稀“孤岛式”零售网络会产生冲突. K-means类梯度算法是解决选址问题的经典算法,但其单纯依赖物理距离的聚类方式更易忽视低密度区域的经济效益与优先级需求,造成选址决策偏差. VRP的数学模型是混合整数规划模型,节点数增长会增加求解难度. 在偏远区域长距离的实际配送中,单次服务零售户数量增加会显著增加车辆运输成本,且在分布不均衡的场景下,高优先级零售户与低优先级零售户在时间窗要求上可能会存在冲突.
本研究以最小化车辆总成本、优先级成本以及自提点总成本为目标,构建带时间窗的多目标卷烟选址-配送路径规划模型. 主要创新点如下. 通过物流水平得分改进距离函数,提出经济K均值聚类(economic K-means,EKM)算法,引入自提点补贴机制,构建自提点选址模型,结合多阶段聚类与补贴机制实现经济效益与历史经营数据的综合优化,得到合理的卷烟自提点位置. 引入零售户优先级的概念,提出优先级模拟退火(priority simulated annealing,PSA)算法,将时间窗约束转化为优先级惩罚成本的软性目标,构建兼顾优先级成本最小化与车辆总成本最小化的多目标VRP模型. 最后,通过对Z地市区域进行卷烟配送路径规划,验证卷烟带时间窗的多目标选址-配送路径规划模型的有效性,并通过对比实验验证算法的优越性.
1. 问题描述与假设
卷烟配送,即车辆从配送中心出发,按预设路线完成零售户送货后再返程的闭环作业. 卷烟公司基于需求量将零售户划分为不同的等级. 高等级客户因需求量大需优先配送以降低时效损失. 针对配送过程中配送效率低、成本高的问题,以及根据Z地市区域现有状况,构建自提点选址模型和带时间窗的多目标车辆配送路径规划模型. 问题描述如下.
(a)基本信息:零售户坐标、需求量、订单价格、车辆等信息均已知.
(b)距离函数:计算物流水平得分,得出新的距离函数.
(c)自提点位置:提出EKM聚类算法进行多次聚类,得到最优自提点位置,提出自提点补贴机制.
(d)配送方式:1-N类型,即一个配送中心为多个目标零售户点以及自提点提供配送服务.
(e)惩罚成本:在整体配送过程中,如果未按照优先级进行配送,就会产生惩罚成本,惩罚成本用时间窗来定义. 本研究的时间窗类型为软时间窗,若车辆未在规定时间内到达,则会产生相应的早到或晚到的优先级惩罚成本.
为了方便分析和研究,做出如下假设.
(a)配送车辆对每个顾客点只访问一次,且最终返回配送中心;
(b)配送车辆和自提车辆的型号均相同,并且车辆在运输过程中的速度始终保持不变,忽略运输过程中的堵车、天气恶劣的情况;
(c)车辆固定成本周期内不变,车辆每公里运输费用已知且保持不变;
(d)零售户群可选择送货上门或用户自提服务,同一零售户仅能选择一种服务方式,不存在自提的零售户临时改为要求送货上门的情况;
(e)零售户优先级的评定仅考虑需求量,不受其他因素影响;
(f)自提补贴仅针对距离自提点特定范围内的顾客生效,大于指定配送范围时无补贴.
2. 关键指标定义
2.1. 经济指标定义
为了得到合理的自提点位置,通过物流水平得分对每个零售户计算其经济效益. 其物流水平指标涵盖需求量、经理评分及信用等级等. 采用熵权法进行客观赋权:基于指标数据离散度,通过信息熵计算初始权重并修正,形成兼顾数据分布特性的综合权重体系. 具体表达式如下.
1)利用极差法,得到归一化判断矩阵. 令
正向指标、逆向指标表达式分别如下:
2)计算第
3)通过
4)得到第
5)计算第
6)根据各项指标权重
2.2. 优先级指标
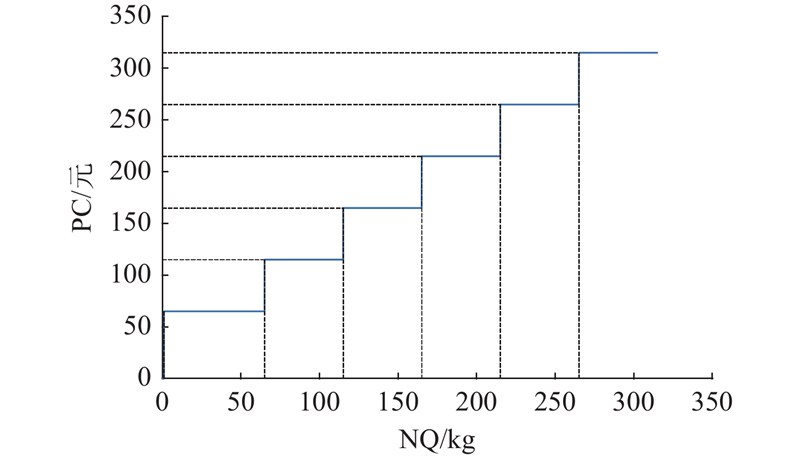
由于零售户的级别存在差异,优先服务高需求客户可提升整体满意度. 若配送时未按照零售户优先级的顺序配送,会导致提前送达或超时配送,则会产生一定的优先级惩罚成本. 单位时间优先级惩罚成本是指车辆未在限定时间内送到零售户点,每个单位时间会产生额外的优先级惩罚成本.
假定单位时间优先级惩罚成本由分段函数表示,表达式如下:
零售户优先级级别由零售户过去的评级和现有的评级共同构成,具体表达式如下:
式中:
2.3. 自提点补贴机制
为了进一步激励商家选择自提[6],提出补贴机制. 补贴机制是指在零售户选择自提的情况下,通过提供一定金额的补贴,鼓励商家积极选择自提,从而减少物流成本并提升整体效率. 本研究补贴机制根据卷烟企业历史订单和配送情况,与企业讨论后开展试点工作,补贴金额以客户订购金额的一定比例为基础,且规定补贴金额不超过订购金额的0.6%. 由于卷烟零售户的订购卷烟量都存在一定限额,故在自提点范围内用户可以选择步行或者骑电瓶车前往自提. 根据实际情况,零售户一般一周订购一次,一次平均50条烟,订购金额约0.5万元至1.0万元,补贴金额约为零售户购买金额的0.3%~0.6%. 针对距离自提点
式中:
3. 自提点选址问题
3.1. 数学模型
建立自提点总成本最低的卷烟选址模型,考虑自提点建设及运营成本、自提点补贴成本,提出EKM聚类算法求解,得到最优自提点位置. 数学模型表达式如下:
式(12)为目标函数
3.2. 算法设计
K-means聚类算法是一种无监督学习算法,有收敛速度较快、聚类效果较好的优点. 但传统K-means聚类算法按距离的相似性进行聚类,例如欧氏距离、曼哈顿距离,其仅仅是物理空间上的距离,未考虑零售户实际经营情况带来的影响. 因此,提出经济效益距离函数,表达式如下:
式中:
如图1所示为融合经济效益指标的EKM算法流程图. 针对分散的零售户点,通过EKM聚类算法进行区域划分,通过多阶段聚类得到每个区域最合理的自提点位置,作为后续配送过程中待配送点之一. 零售户可就近选择自提,减少无法及时送达的情况.
图 1
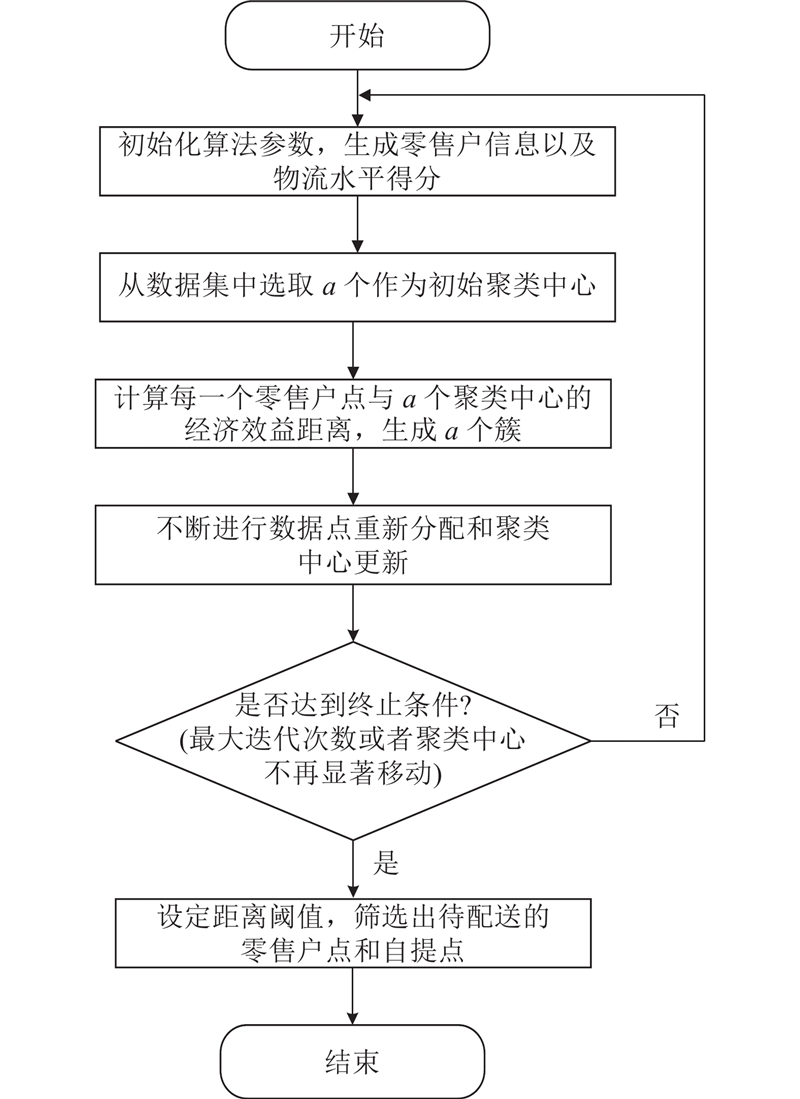
3.3. 算法验证
轮廓系数是常用的聚类评估指标,用于衡量聚类的紧密度和分离度. EKM聚类算法应当能够生成更加紧密且更好分离的聚类结果. 因此,通过引入轮廓系数进行评估. 轮廓系数的取值范围为[−1.0, 1.0],其计算方法如下.
1)对于每一个样本
2)对于每一个样本
3)样本
整个数据集最终的轮廓系数是通过计算所有样本轮廓系数的均值得到的. 轮廓系数越大越好,接近1.0表示较好的聚类效果,而接近−1.0表示较差的聚类效果.
表 1 K-means算法与EKM算法对比
Tab.1
| 聚类簇数 | 轮廓系数 | |
| K-means算法 | EKM算法 | |
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
4. 车辆路径规划问题
4.1. 数学模型
建立考虑零售户优先级成本、车辆总成本以及自提点总成本最低的带时间窗的多目标卷烟配送路径规划模型.
1)目标函数.
本研究根据不同零售户和自提点的需求量设定优先等级,并将其转化为单位时间优先级惩罚成本,同时基于惩罚时间窗,得到最终的优先级惩罚成本. 总成本由车辆的固定成本
车辆固定成本表达式如下:
式中:
车辆运输成本表达式如下:
式中:
优先级惩罚成本表达式如下:
式中:
自提点建设成本及运营成本表达式如下:
式中:
自提点补贴成本表达式如下:
式中:
2)数学模型.
式(23)为目标函数,
4.2. 算法设计
模拟退火算法(simulated annealing,SA)是基于Monte-Carlo迭代实现全局最优的一种算法[13]. 本研究对SA进行如下改进:
1)路径构造. 对于n个零售户点,直接产生n个1~n间互不重复的自然数排列,表示优先级配送顺序,并依约束划分配送路径.
2)增加记忆函数. 记忆函数可帮助算法更好地记忆过去的状态,并根据这些信息来指导搜索过程,从而提高收敛速度和搜索效率,减少算法的运行时间. 增加记忆函数可以防止概率性的最优解错失,因此在算法运行中,不断地会产生并接受新解. 记忆函数可以基于过去的状态和性能来更新当前状态的选择. 其更新规则可以根据过去状态的性能和记忆程度来进行. 假设每次迭代都会得到一个新的候选状态,就可根据以下规则更新记忆函数.
(a)计算候选状态
(b)如果
(c)将当前状态
式中:
在SA中,通过评价函数的值来判断新状态
3)增加判断函数. 引入判断函数可以增强新状态的随机性,同时也有利于提高算法的效率. 在初始状态的处理过程中,引入判断函数到不同种群. 针对小规模,采取随机全排列的方式;针对大规模,可以协作不同的变化算法. 判断函数通过优化Metropolis接受准则来实现:
(a)计算新状态
(b)计算当前状态
(c)根据
通过增加判断函数,可以更灵活地在搜索过程中进行状态接受与拒绝的决策,从而更有效地探索搜索空间并逐步收敛到全局最优解.
4)确定迭代步长. 本研究采用固定的迭代步长,即针对每个温度均迭代相同的步数.
4.2.1. 编码方式
采用整数编码的形式对路线进行编码. 算法采用该编码方式能直观地体现零售户的优先级别,如示例:0表示配送中心,如有2个零售户点,1个自提点,1辆车,零售户1的优先级惩罚成本为50,自提点z2的优先级惩罚成本为80,零售户3的优先级惩罚成本为35,则解可表示为0-z2-1-3-0.
4.2.2. 初始解生成
初始解
1)以配送中心为起点和终点,随即生成初始路径,分别计算所有零售户和自提点的优先级惩罚成本以规定其配送顺序.
2)计算每条路径的总距离,保证总距离不超过车辆的最远行驶距离.
3)判断每条路径所需配送的所有零售户以及自提点的总需求重量与车辆剩余装载量的比值
4)基于步骤1)的零售户配送序列,在考虑车辆行驶距离和载重量的基础上,依次计算每个零售户和自提点插入该路径前后所产生的成本,同时,分别计算所有零售户和自提点的优先级惩罚成本,最终选取成本最小的位置. 若零售户没有合适的插入位置,就建立一条新的路径.
5)重复以上步骤直至全部零售户的需求都被满足,增加记忆函数,基于过去状态的性能和记忆程度来进行,在搜索过程中引导状态的选择,最终输出最优解P,得到最优函数值f(P0).
4.2.3. 路径内邻域构造
选择3种邻域构造方法,分别对路径内邻域和路径间邻域进行构造. 路径内邻域构造是指仅对单条路径的零售户需求节点进行变换,路径内邻域构造分为路径内2-opt法、路径内点插入法和路径内点交换法.
1)路径内2-opt法:随机选择同一路径上任意2个零售户点,将2个配送点之间的所有配送点进行逆序,如图2(a)所示.
图 2
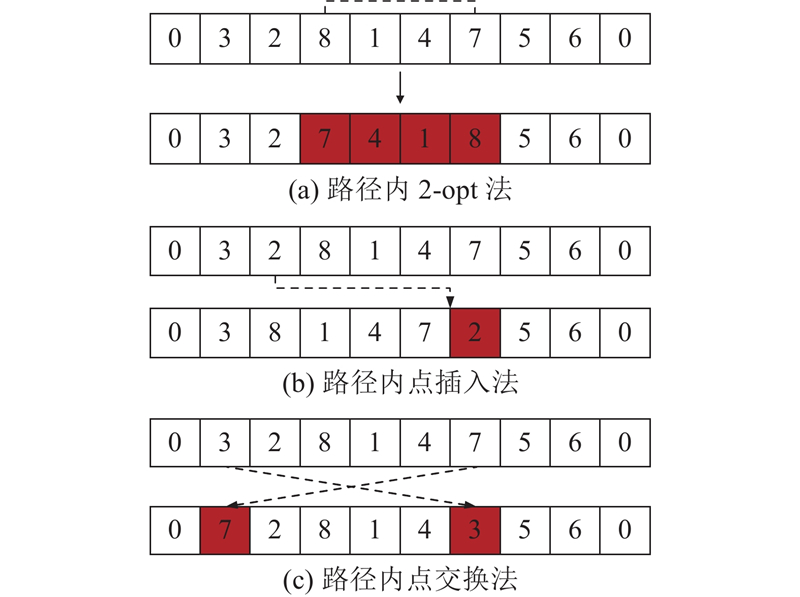
2)路径内点插入法:随机删除某条路径上的某个配送点,将该配送点插入该路径的其他任何一个位置,如图2(b)所示.
3)路径内点交换法:随机选取同一路径上的任意2个配送点,将这2个配送点互换位置,如图2(c)所示.
4.2.4. 路径间邻域构造
路径间的邻域构造是指对2条路径的节点进行变换. 通过扩大邻域搜索空间来提高解的质量,对可行解进行局部优化. 路径间邻域构造方法同路径内邻域构造相同.
1)路径间2-opt法:随机选取任意2条路径中任意2个零售户点,将2个零售户点之间的所有点进行逆序,如图3(a)所示.
图 3
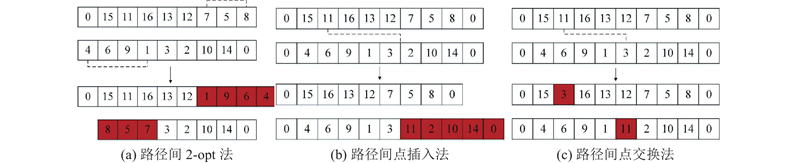
2)路径间点插入法:随机删除某条路径上的某个零售户点,将该零售户点插入另一条路径的任何一个位置,如图3(b)所示.
3)路径间点交换法:随机选取任意2条路径中任意2个零售户点,将2个零售户点互换位置,如图3(c)所示.
通过编码、初始解生成和邻域构造,车辆从配送中心出发,依据各零售户的优先级惩罚成本,可以得到多条配送路线,具体如下:配送中心-自提点/零售户-配送中心.
4.2.5. 算法流程
PSA算法流程如图4所示.
图 4
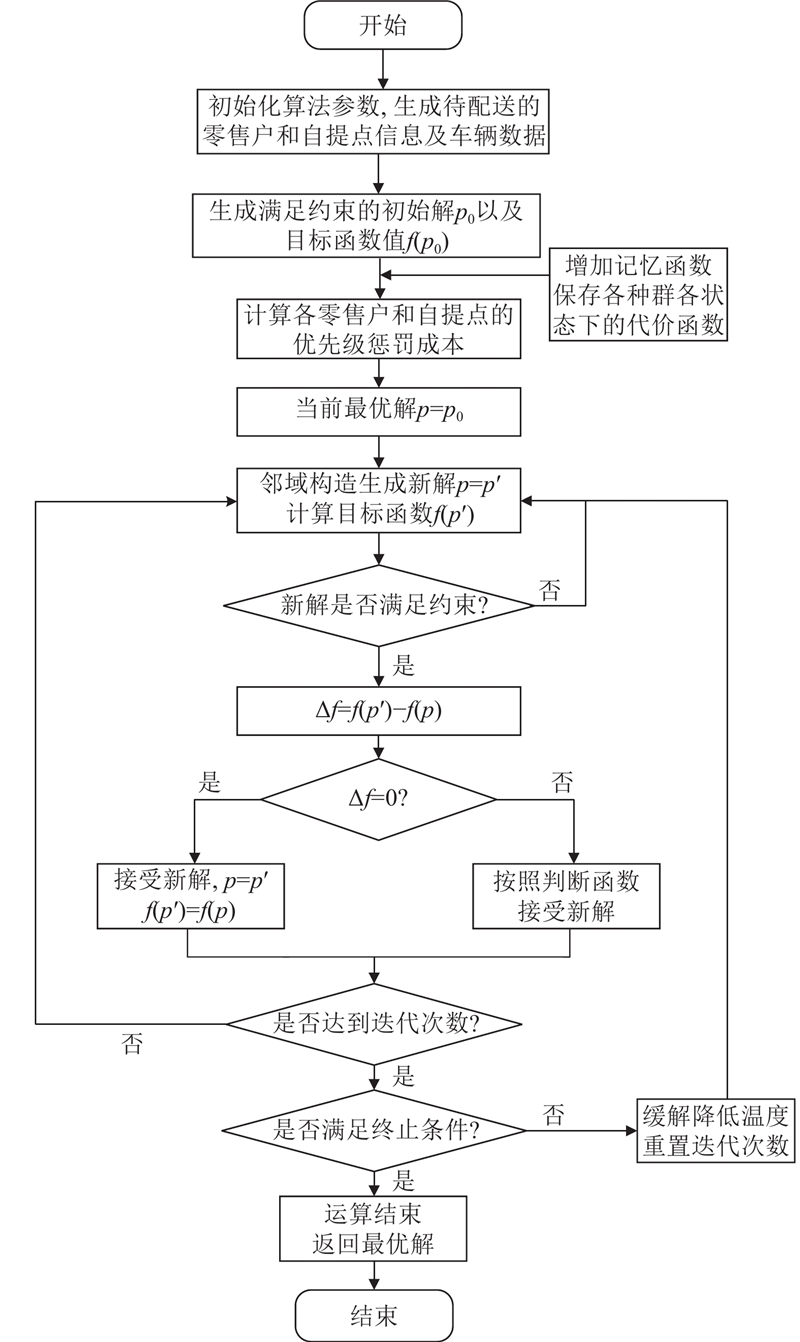
本研究提出的PSA算法在传统SA框架基础上进行了如下改进. 1)记忆函数增强全局搜索:引入记忆函数式(39)、(40),通过衰减系数平衡历史状态与当前解的性能差异. 该机制在迭代中记录优质解的特征,避免因随机扰动丢失潜在最优解. 2)多维度邻域构造策略:设计了3种邻域生成规则,路径内和路径间的2-opt优化与点插入和点交换. PSA兼顾收敛速度与解质量,解的表示直观且计算效率较高,在迭代过程中产生的解大多为可行解,算法收敛速度加快.
4.2.6. 标准算例验证
在VRPTW问题中,通常选用Solomon算例进行数值实验. Solomon算例中的R类数据集的点的坐标位置是随机生成的;C类数据集的点的坐标位置有明显的聚簇;而RC类数据集中点则同时具有随机和聚簇的特点,数据点分布较不均衡,符合文章研究问题的特点. 初始温度和温度下降系数是SA算法中须测试的关键参数. 故设置初始温度和下降速率的正交实验,每个参数设计3个因子级别,其值如表2所示. 其中,
表 2 正交实验表
Tab.2
| 实验编号 | 因子级别 | 最低成本 | ||
| RC101 | ||||
| 1 | 300 | 0.995 | 604 | |
| 2 | 300 | 0.997 | 611 | |
| 3 | 300 | 0.999 | 609 | |
| 4 | 500 | 0.995 | 574 | |
| 5 | 500 | 0.997 | 598 | |
| 6 | 500 | 0.999 | 601 | |
| 7 | 800 | 0.995 | 596 | |
| 8 | 800 | 0.997 | 604 | |
| 9 | 800 | 0.999 | 599 | |
以最小化总成本为目标,选取50个顾客规模,利用 PSA、SA、TS、GA这4种算法针对6个算例进行求解. 4种算法的求解性能结果如表3所示. 其中,RC101、RC102、RC103、RC201、RC202、RC203均为RC类算例,C表示最优成本,R表示最短路径. PAS的成本最低且运行时间最少,故PSA改进是有效的.
表 3 基于Solomon标准算例的实验结果
Tab.3
| 算例 | PSA | SA | TS | GA | |||||||
| C | R | C | R | C | R | C | R | ||||
| RC101 | 574 | 513 | 680 | 607 | 693 | 620 | 682 | 620 | |||
| RC102 | 624 | 520 | 688 | 573 | 723 | 628 | 694 | 714 | |||
| RC103 | 579 | 483 | 882 | 735 | 863 | 594 | 732 | 649 | |||
| RC201 | 582 | 485 | 671 | 559 | 812 | 597 | 713 | 572 | |||
| RC202 | 580 | 434 | 1033 | 861 | 732 | 662 | 722 | 639 | |||
| RC203 | 575 | 493 | 629 | 524 | 698 | 592 | 685 | 585 | |||
5. 案例分析
5.1. 数据采集与预处理
对Z地市区域内所有配送点的经纬度坐标、卷烟配送时间、订单需求量等数据进行规范化处理. 文中所有的经维度均指东经、北纬. 根据经纬度-公里转换规则,将零售户坐标经度和纬度均转化为公里数,纬度差1度或经度差1度对应的实际距离均约为111 km,例如经度39.84°和纬度98.57°可以表示为经度
表 4 实际算例数据示例
Tab.4
| 编号 | X/km | Y/km | 卷烟配送时间 | 订单需求量 |
| 1 | 9:00 | 3.0 | ||
| 2 | 10:10 | 45.5 | ||
| 3 | 12:20 | 20.0 | ||
| 4 | 14.20 | 7.5 |
在案例参数中,自提点建设成本为
5.2. 实例分析
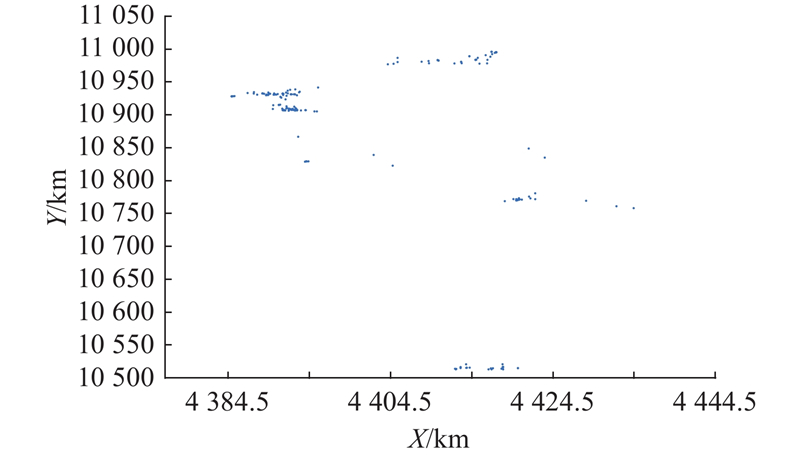
文章以Z地市区域所负责的200个点为案例进行研究,验证本算法模型的实际应用情况. 零售户现实的坐标分布见图5.
图 5
5.2.1. 实验结果
图 6
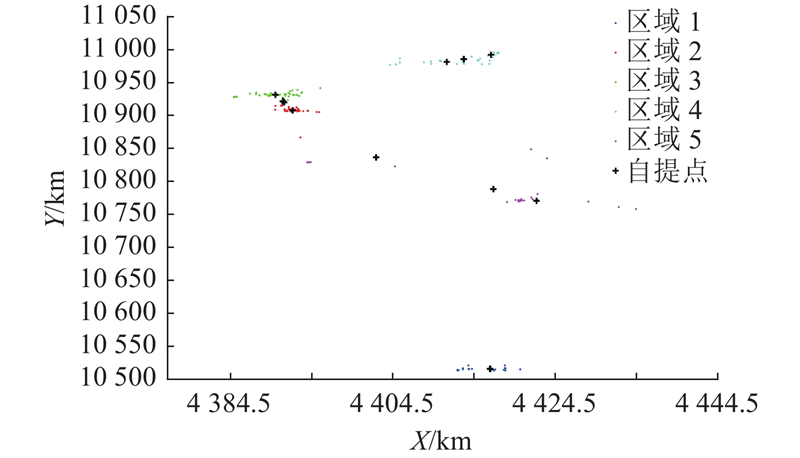
表 5 自提点位置
Tab.5
| 编号 | X/km | Y/km | |
| 1 | 2.337 | ||
| 2 | 3.336 | ||
| 3 | 2.154 | ||
| 4 | 2.699 | ||
| 5 | 4.158 | ||
| 6 | 5.215 | ||
| 7 | 5.221 | ||
| 8 | 4.112 | ||
| 9 | 6.123 | ||
| 10 | 5.158 | ||
| 11 | 8.332 | ||
| 12 | 6.215 | ||
| 13 | 6.213 |
表 6 待配送到户的零售户和自提点
Tab.6
| 编号 | X/km | Y/km | 编号 | X/km | Y/km | |||
| 1 | 15 | 22 | 37 | |||||
| 2 | 30 | 23 | 110 | |||||
| 3 | 25 | 24 | 29 | |||||
| 4 | 118 | 25 | 21 | |||||
| 5 | 21 | 26 | 29 | |||||
| 6 | 35 | 27 | 35 | |||||
| 7 | 113 | 28 | 43 | |||||
| 8 | 20 | 29 | 25 | |||||
| 9 | 12 | 30 | 98 | |||||
| 10 | 17 | 31 | 155 | |||||
| 11 | 10 | 32 | 207 | |||||
| 12 | 4 | 33 | 236 | |||||
| 13 | 24 | 34 | 101 | |||||
| 14 | 49 | 35 | 127 | |||||
| 15 | 18 | 36 | 223 | |||||
| 16 | 18 | 37 | 207 | |||||
| 17 | 36 | 38 | 102 | |||||
| 18 | 12 | 39 | 197 | |||||
| 19 | 31 | 40 | 335 | |||||
| 20 | 7 | 41 | 320 | |||||
| 21 | 30 | 42 | 299 |
图 7
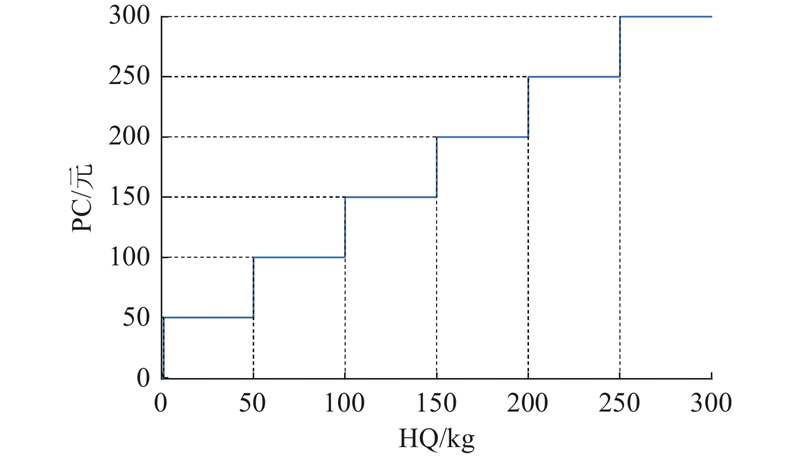
图 8
3)最优配送路线图:待配送点编号表示为1、2、3、
图 9
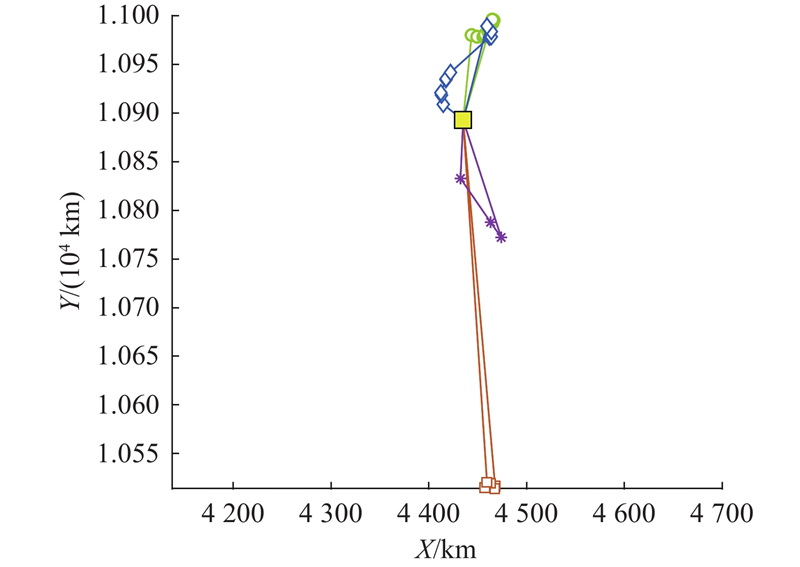
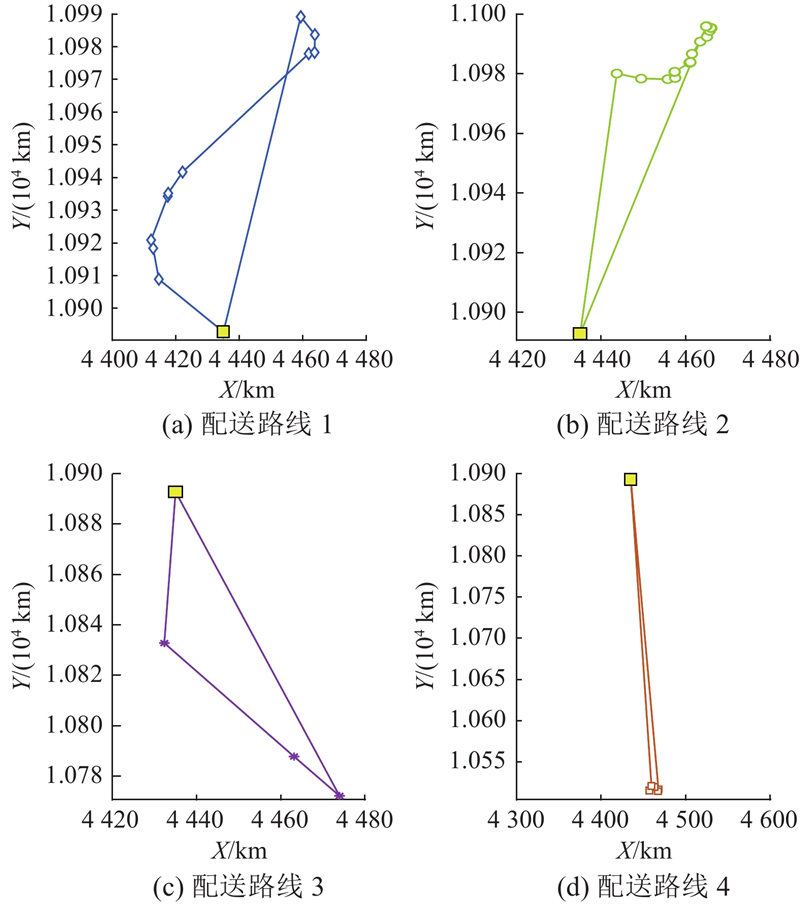
通过50次随机重复实验[14],得到实验结果如下. 最优配送方案如表7所示,其中配送路线1需要配送4个自提点和10个零售户点,最优公里数为141.95 km,路径最优成本为158元,如图10(a)所示. 配送路线2需要配送2个自提点和16个零售户点,最优公里数为147.32 km,路径最优成本为165元,如图10(b)所示. 配送路线3需要配送3个自提点,最优公里数为202.68 km,路径最优成本为227元,如图10(c)所示. 配送路线4需要配送4个自提点和3个零售户点,最优公里数为725.00 km,路径最优成本为812元,如图10(d)所示. 总公里数为
表 7 最优配送方案
Tab.7
| 路径编号 | 路径 | R/km | C/元 |
| 1 | 0-z4-z3-z2-z1-18-16-10- 5-21-9-20-13-17-19-0 | 141.95 | 158 |
| 2 | 0-z6-4-7-23-z5-28-22-15-29- 11-25-27-1-6-8-26-3-16-24-0 | 147.32 | 165 |
| 3 | 0-z8-z9-z7-0 | 202.68 | 227 |
| 4 | 0-z12-z13-z10-2-z11-12-11-0 | 725.00 | 812 |
图 10
5.2.2. 算法对比
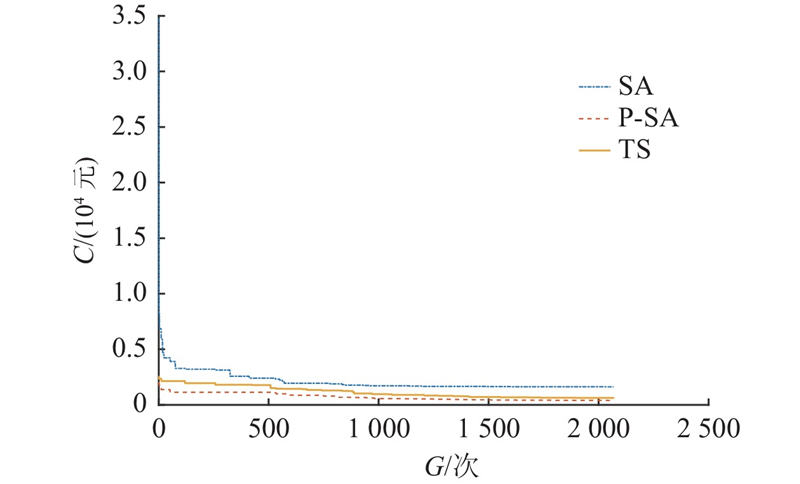
禁忌搜索算法(TS)的局部搜索能力较强,且不易陷入循环,广泛应用于路径规划问题[15]. 因此,针对带时间窗的多目标选址-配送路径规划模型,对SA、TS与PSA进行对比. PSA算法得出总公里数为
表 8 SA路径结果
Tab.8
| 路径编号 | 路径 | R/km | C/元 |
| 1 | 0-20-13-17-z5-28-22-26-3- 16-24-z4-z3-0 | 219.64 | 245 |
| 2 | 0-4-7-23-15-29-11-25-27-1-6-8- 18-16-10-5-21-9-z6-19-z2-z1-0 | 315.17 | 353 |
| 3 | 0-z8 -z13-11-z7-0 | 901.25 | |
| 4 | 0-z9-z12-12-z10-2-z11-0 | 673.21 | 754 |
表 9 TS路径结果
Tab.9
| 路径编号 | 路径 | R/km | C/元 |
| 1 | 0-20-13-17-19-1-6-8-26- 3-16-24-z4-18-16-10-5-21-9-0 | 212.68 | 238 |
| 2 | 0-z3-z2-z1-4-7-23-28- 22-15-29-11-25-27-0 | 245.54 | 275 |
| 3 | 0-z6 -z5-z8-0 | 290.18 | 325 |
| 4 | 0-z9-z7-z12-2-z13-z10-12- 11-z11-0 | 900.90 |
表 10 多算法性能指标对比
Tab.10
| 算法 | R/km | C/元 | G/次 | T/s |
| PSA | 341.0 | |||
| SA | 410.4 | |||
| TS | 1847 | 388.0 |
图 11
6. 结 语
在地广人稀、分布不均衡区域的配送过程中,存在配送成本高、效率低、配送路径规划不合理的问题,因此,本研究提出自提点补贴机制鼓励零售户自提,提出零售户优先级定义,构造优先级惩罚成本,建立考虑零售户优先级成本、车辆总成本及自提点总成本最低的带时间窗的多目标卷烟选址-配送路径规划模型,并提出EKM-PSA算法进行求解,得到最优自提点位置和最优路径规划. 对实验案例进行50次随机重复实验验证了所建立的带时间窗的多目标选址-配送路径规划模型是可行有效的. 但是本研究缺乏对临时插单、路网实时变化的考虑,未来将针对动态路网下的配送进一步研究.
参考文献
Vehicle routing problems with split deliveries
[J].
混合遗传算法的带时间窗卷烟物流车辆路径优化
[J].DOI:10.16652/j.issn.1004-373x.2018.11.027 [本文引用: 1]
Hybrid genetic algorithm based cigarette logistics vehicle routing optimization with time window
[J].DOI:10.16652/j.issn.1004-373x.2018.11.027 [本文引用: 1]
基于混合蚁群算法的冷链物流配送路径优化研究
[J].DOI:10.16381/j.cnki.issn1003-207x.2019.11.011 [本文引用: 1]
Research on cold chain logistics distribution path optimization based on hybrid ant colony algorithm
[J].DOI:10.16381/j.cnki.issn1003-207x.2019.11.011 [本文引用: 1]
A hybrid multiobjective evolutionary algorithm for solving vehicle routing problem with time windows
[J].DOI:10.1007/s10589-005-3070-3 [本文引用: 1]
一种新型启发式PSO算法求解市区最优路径规划研究
[J].DOI:10.3969/j.issn.1672-9722.2018.02.013 [本文引用: 1]
Plan research on a new heuristic PSO to solving urban optimal path
[J].DOI:10.3969/j.issn.1672-9722.2018.02.013 [本文引用: 1]
卷烟配送中心选址优化研究与应用
[J].DOI:10.16472/j.chinatobacco.2021.t0073 [本文引用: 1]
Research and application of tobacco distribution center location optimization
[J].DOI:10.16472/j.chinatobacco.2021.t0073 [本文引用: 1]
An effective partitional clustering algorithm based on new clustering validity index
[J].DOI:10.1016/j.asoc.2018.07.026 [本文引用: 1]
Improving density peak clustering by automatic peak selection and single linkage clustering
[J].DOI:10.3390/sym12071168 [本文引用: 1]
A discrete multi-objective grey wolf optimizer for the home health care routing and scheduling problem with priorities and uncertainty
[J].DOI:10.1016/j.cie.2022.108256 [本文引用: 1]
考虑居民选择行为的应急避难场所选址问题研究
[J].DOI:10.12005/orms.2019.0193 [本文引用: 1]
Emergency shelter location problem considering residents’ choice behavior
[J].DOI:10.12005/orms.2019.0193 [本文引用: 1]
Multi-fleet feeder vehicle routing problem using hybrid metaheuristic
[J].DOI:10.1016/j.cor.2022.105696 [本文引用: 1]
Vehicle routing problems with drones equipped with multi-package payload compartments
[J].DOI:10.1016/j.tre.2022.102757 [本文引用: 1]
Vehicle routing with cumulative objectives: a state of the art and analysis
[J].DOI:10.1016/j.cie.2022.108054 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}