[1]
岳喜申. 基于改进YOLOv5s的葡萄叶片病害识别方法研究 [D]. 阿拉尔: 塔里木大学, 2024.
[本文引用: 1]
YUE Xishen. A study on grape leaf disease identification method based on improved YOLOv5s [D]. Alar: Tarim University, 2024.
[本文引用: 1]
[2]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[3]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]//14th European Conference on Computer Vision . Cham: Springer, 2016: 21–37.
[本文引用: 1]
[4]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[5]
姜晟, 曹亚芃, 刘梓伊, 等 基于改进Faster RCNN的茶叶叶部病害识别
[J]. 华中农业大学学报 , 2024 , 43 (5 ): 41 - 50
[本文引用: 1]
JIANG Sheng, CAO Yapeng, LIU Ziyi, et al Recognition of tea leaf disease based on improved Faster RCNN
[J]. Journal of Huazhong Agricultural University , 2024 , 43 (5 ): 41 - 50
[本文引用: 1]
[6]
PAN P, SHAO M, HE P, et al Lightweight cotton diseases real-time detection model for resource-constrained devices in natural environments
[J]. Frontiers in Plant Science , 2024 , 15 : 1383863
DOI:10.3389/fpls.2024.1383863
[本文引用: 1]
[7]
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need
[J]. Advances in Neural Information Processing Systems , 2017 , 30 : 5998 - 6008
[本文引用: 1]
[8]
ZHAO Y, LV W, XU S, et al. DETRs beat YOLOs on real-time object detection [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 16965–16974.
[本文引用: 1]
[9]
HUANGFU Y, HUANG Z, YANG X, et al HHS-RT-DETR: a method for the detection of citrus greening disease
[J]. Agronomy , 2024 , 14 (12 ): 2900
DOI:10.3390/agronomy14122900
[本文引用: 1]
[10]
YANG H, DENG X, SHEN H, et al Disease detection and identification of rice leaf based on improved detection transformer
[J]. Agriculture , 2023 , 13 (7 ): 1361
DOI:10.3390/agriculture13071361
[本文引用: 1]
[11]
FU Z, YIN L, CUI C, et al A lightweight MHDI-DETR model for detecting grape leaf diseases
[J]. Frontiers in Plant Science , 2024 , 15 : 1499911
DOI:10.3389/fpls.2024.1499911
[本文引用: 2]
[12]
MA X, DAI X, BAI Y, et al. Rewrite the stars [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 5694–5703.
[本文引用: 1]
[13]
REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2020: 658–666.
[本文引用: 1]
[14]
NI Z, CHEN X, ZHAI Y, et al. Context-guided spatial feature reconstruction for efficient semantic segmentation [C]//European Conference on Computer Vision . Cham: Springer, 2024: 239–255.
[本文引用: 1]
[15]
LIU C, WANG K, LI Q, et al Powerful-IoU: more straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism
[J]. Neural Networks , 2024 , 170 : 276 - 284
DOI:10.1016/j.neunet.2023.11.041
[本文引用: 1]
[16]
ZHANG H, XU C, ZHANG S. Inner-IoU: more effective intersection over union loss with auxiliary bounding box [EB/OL]. (2023-11-06)[2025-03-16]. https://arxiv. org/pdf/2311.02877.
[本文引用: 1]
[17]
CHEN J, KAO S H, HE H, et al. Run, don’t walk: chasing higher FLOPS for faster neural networks [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 12021–12031.
[本文引用: 1]
[18]
LIU X, PENG H, ZHENG N, et al. EfficientViT: memory efficient vision transformer with cascaded group attention [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 14420–14430.
[本文引用: 1]
[19]
WANG A, CHEN H, LIN Z, et al. Rep ViT: revisiting mobile CNN from ViT perspective [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 15909–15920.
[本文引用: 1]
[20]
QIN D, LEICHNER C, DELAKIS M, et al. MobileNetV4: universal models for the mobile ecosystem [C]// European Conference on Computer Vision . Cham: Springer, 2024: 78–96.
[本文引用: 1]
[21]
ZHANG Y F, REN W, ZHANG Z, et al Focal and efficient IOU loss for accurate bounding box regression
[J]. Neurocomputing , 2022 , 506 : 146 - 157
DOI:10.1016/j.neucom.2022.07.042
[本文引用: 1]
[22]
GEVORGYAN Z. SIoU loss: more powerful learning for bounding box regression [EB/OL]. (2022-05-25)[2025-03-16]. https://arxiv.org/abs/2205.12740.
[本文引用: 1]
[23]
TONG Z, CHEN Y, XU Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism [EB/OL]. (2023-01-24)[2025-03-16]. https://arxiv.org/ abs/2301.10051.
[本文引用: 1]
[24]
ZHANG H, ZHANG S. Shape-IoU: more accurate metric considering bounding box shape and scale [EB/OL]. (2023-12-29)[2025-03-16]. https://arxiv.org/abs/ 2312.17663.
[本文引用: 1]
[25]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10778–10787.
[本文引用: 1]
[26]
ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection [EB/OL]. (2020-10-08)[2025-03-16]. https://arxiv.org/ abs/2010.04159.
[本文引用: 1]
[27]
ZHANG H, LI F, LIU S, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection [EB/OL]. (2022-03-07)[2025-03-16]. https://arxiv.org/abs/2203.03605.
[本文引用: 1]
[28]
ZHAO C, SUN Y, WANG W, et al. MS-DETR: efficient DETR training with mixed supervision [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 17027–17036.
[本文引用: 1]
[29]
WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 7464–7475.
[本文引用: 1]
[30]
WANG C Y, YEH I H, MARK LIAO H Y. YOLOv9: learning what you want to learn using programmable gradient information [C]//European Conference on Computer Vision . Cham: Springer, 2024: 1–21.
[本文引用: 1]
[31]
WANG A, CHEN H, LIU L, et al YOLOv10: real-time end-to-end object detection
[J]. Advances in Neural Information Processing Systems , 2024 , 37 : 107984 - 108011
[本文引用: 1]
[32]
KHANAM R, HUSSAIN M. YOLOv11: an overview of the key architectural enhancements [EB/OL]. (2024-10-23)[2025-03-16]. https://arxiv.org/abs/2410.17725.
[本文引用: 1]
[33]
SELVARAJU R R, COGSWELL M, DAS A, et al Grad-CAM: visual explanations from deep networks via gradient-based localization
[J]. International Journal of Computer Vision , 2016 , 128 : 336 - 359
[本文引用: 1]
1
... 葡萄是我国重要的经济作物,在全球农业生产和农业经济中占据重要地位. 在葡萄的生长过程中,植株易受多种不利因素影响,进而制约产量与品质. 其中,葡萄叶片病害是限制生产的关键因素之一[1 ] . 常见病害达十余种,可导致叶片脱落、枯萎、变色,并削弱光合作用与养分吸收,降低抗逆性与产量,严重时甚至造成植株死亡. 快速准确地识别病害类型并及时采取有效防控措施,对保障葡萄产业的稳定发展至关重要. ...
1
... 葡萄是我国重要的经济作物,在全球农业生产和农业经济中占据重要地位. 在葡萄的生长过程中,植株易受多种不利因素影响,进而制约产量与品质. 其中,葡萄叶片病害是限制生产的关键因素之一[1 ] . 常见病害达十余种,可导致叶片脱落、枯萎、变色,并削弱光合作用与养分吸收,降低抗逆性与产量,严重时甚至造成植株死亡. 快速准确地识别病害类型并及时采取有效防控措施,对保障葡萄产业的稳定发展至关重要. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
1
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
1
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
基于改进Faster RCNN的茶叶叶部病害识别
1
2024
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
基于改进Faster RCNN的茶叶叶部病害识别
1
2024
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
Lightweight cotton diseases real-time detection model for resource-constrained devices in natural environments
1
2024
... 传统的病害识别主要依赖人工观察和经验判断,存在工作量大、主观性强、准确率低且易受环境干扰等问题. 此外,病害种类繁多且症状高度相似,当缺乏专业知识时极易造成误判,导致防治延迟,最终影响产量. 近年来,深度学习方法在植物病害识别中得到广泛的应用. 目前,主流的目标检测框架包括以Faster R-CNN[2 ] 为代表的二阶检测器和以SSD[3 ] 、YOLO[4 ] 等为代表的一阶检测器. 研究表明,两类方法在农业病害检测中均取得显著进展. 姜晟等[5 ] 提出改进的Faster R-CNN的茶叶叶部病害识别方法,结合特征金字塔网络与Rank&Sort损失函数,大幅提升了复杂背景下的识别精度. Pan等[6 ] 提出CDDLite-YOLO模型,引入GSCONV模块重构颈部网络,在棉花病害检测中实现90.6%的mAP与222.22 帧/s,验证了轻量化模型在农业边缘计算中的潜力. ...
Attention is all you need
1
2017
... 尽管卷积神经网络(convolutional neural network, CNN)在农业病害检测中应用广泛,但锚框机制复杂、后处理繁琐与鲁棒性不足等问题限制性能的进一步提升. 随着Transformer[7 ] 在自然语言处理中的广泛应用,研究者开始探索无锚框检测方法的可行性. Zhao等[8 ] 提出Real-Time Detection Transformer(RT-DETR),无需候选框生成与NMS后处理,直接预测目标数量、位置及类别,有效抑制冗余预测框,从而提高检测性能与运行效率. 近年来,Transformer架构的目标检测模型已被广泛用于农作物病害检测. Huangfu等[9 ] 提出改进的HHS-RT-DETR模型,结合HS-FPN、HWD下采样与ShapeIoU优化,在柑橘黄龙病检测中精度提升了7.9%,召回率提升了9.9%. Yang等[10 ] 将DHLC-FPN与DETR融合,通过多尺度特征融合与小目标优化,在水稻病害数据集上实现97.44%的准确率. Fu等[11 ] 在改进RT-DETR的基础上提出轻量级葡萄叶片病害检测模型,采用MobileNetV4与Light-SFPN,将模型参数量压缩至8.76×106 ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
1
... 尽管卷积神经网络(convolutional neural network, CNN)在农业病害检测中应用广泛,但锚框机制复杂、后处理繁琐与鲁棒性不足等问题限制性能的进一步提升. 随着Transformer[7 ] 在自然语言处理中的广泛应用,研究者开始探索无锚框检测方法的可行性. Zhao等[8 ] 提出Real-Time Detection Transformer(RT-DETR),无需候选框生成与NMS后处理,直接预测目标数量、位置及类别,有效抑制冗余预测框,从而提高检测性能与运行效率. 近年来,Transformer架构的目标检测模型已被广泛用于农作物病害检测. Huangfu等[9 ] 提出改进的HHS-RT-DETR模型,结合HS-FPN、HWD下采样与ShapeIoU优化,在柑橘黄龙病检测中精度提升了7.9%,召回率提升了9.9%. Yang等[10 ] 将DHLC-FPN与DETR融合,通过多尺度特征融合与小目标优化,在水稻病害数据集上实现97.44%的准确率. Fu等[11 ] 在改进RT-DETR的基础上提出轻量级葡萄叶片病害检测模型,采用MobileNetV4与Light-SFPN,将模型参数量压缩至8.76×106 ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
HHS-RT-DETR: a method for the detection of citrus greening disease
1
2024
... 尽管卷积神经网络(convolutional neural network, CNN)在农业病害检测中应用广泛,但锚框机制复杂、后处理繁琐与鲁棒性不足等问题限制性能的进一步提升. 随着Transformer[7 ] 在自然语言处理中的广泛应用,研究者开始探索无锚框检测方法的可行性. Zhao等[8 ] 提出Real-Time Detection Transformer(RT-DETR),无需候选框生成与NMS后处理,直接预测目标数量、位置及类别,有效抑制冗余预测框,从而提高检测性能与运行效率. 近年来,Transformer架构的目标检测模型已被广泛用于农作物病害检测. Huangfu等[9 ] 提出改进的HHS-RT-DETR模型,结合HS-FPN、HWD下采样与ShapeIoU优化,在柑橘黄龙病检测中精度提升了7.9%,召回率提升了9.9%. Yang等[10 ] 将DHLC-FPN与DETR融合,通过多尺度特征融合与小目标优化,在水稻病害数据集上实现97.44%的准确率. Fu等[11 ] 在改进RT-DETR的基础上提出轻量级葡萄叶片病害检测模型,采用MobileNetV4与Light-SFPN,将模型参数量压缩至8.76×106 ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
Disease detection and identification of rice leaf based on improved detection transformer
1
2023
... 尽管卷积神经网络(convolutional neural network, CNN)在农业病害检测中应用广泛,但锚框机制复杂、后处理繁琐与鲁棒性不足等问题限制性能的进一步提升. 随着Transformer[7 ] 在自然语言处理中的广泛应用,研究者开始探索无锚框检测方法的可行性. Zhao等[8 ] 提出Real-Time Detection Transformer(RT-DETR),无需候选框生成与NMS后处理,直接预测目标数量、位置及类别,有效抑制冗余预测框,从而提高检测性能与运行效率. 近年来,Transformer架构的目标检测模型已被广泛用于农作物病害检测. Huangfu等[9 ] 提出改进的HHS-RT-DETR模型,结合HS-FPN、HWD下采样与ShapeIoU优化,在柑橘黄龙病检测中精度提升了7.9%,召回率提升了9.9%. Yang等[10 ] 将DHLC-FPN与DETR融合,通过多尺度特征融合与小目标优化,在水稻病害数据集上实现97.44%的准确率. Fu等[11 ] 在改进RT-DETR的基础上提出轻量级葡萄叶片病害检测模型,采用MobileNetV4与Light-SFPN,将模型参数量压缩至8.76×106 ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
A lightweight MHDI-DETR model for detecting grape leaf diseases
2
2024
... 尽管卷积神经网络(convolutional neural network, CNN)在农业病害检测中应用广泛,但锚框机制复杂、后处理繁琐与鲁棒性不足等问题限制性能的进一步提升. 随着Transformer[7 ] 在自然语言处理中的广泛应用,研究者开始探索无锚框检测方法的可行性. Zhao等[8 ] 提出Real-Time Detection Transformer(RT-DETR),无需候选框生成与NMS后处理,直接预测目标数量、位置及类别,有效抑制冗余预测框,从而提高检测性能与运行效率. 近年来,Transformer架构的目标检测模型已被广泛用于农作物病害检测. Huangfu等[9 ] 提出改进的HHS-RT-DETR模型,结合HS-FPN、HWD下采样与ShapeIoU优化,在柑橘黄龙病检测中精度提升了7.9%,召回率提升了9.9%. Yang等[10 ] 将DHLC-FPN与DETR融合,通过多尺度特征融合与小目标优化,在水稻病害数据集上实现97.44%的准确率. Fu等[11 ] 在改进RT-DETR的基础上提出轻量级葡萄叶片病害检测模型,采用MobileNetV4与Light-SFPN,将模型参数量压缩至8.76×106 ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
... ,并保持96.3%的检测精度. 文献[11 ]方法侧重轻量化,但对检测速度、小目标识别与复杂背景适应性的系统性评估仍显不足. ...
1
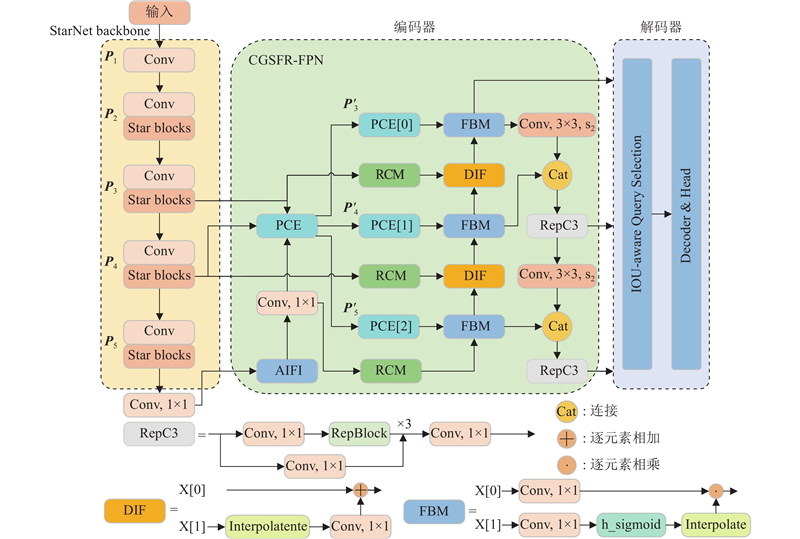
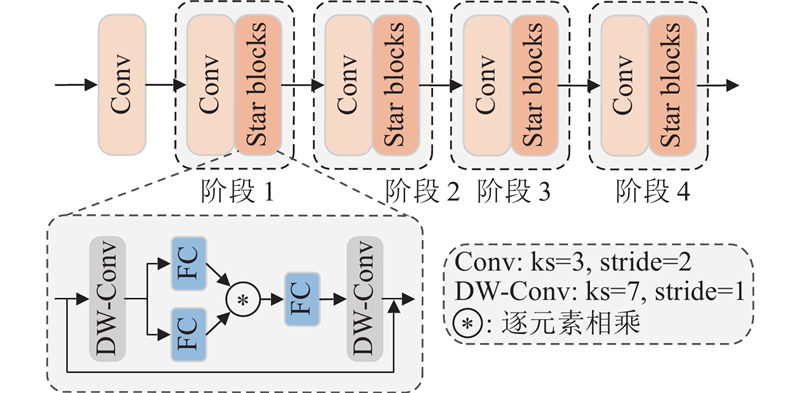
... 尽管相关研究的进展显著,Transformer检测仍受到计算与存储开销大、小目标识别不足及复杂背景适应性欠佳等限制. 本文提出基于改进RT-DETR的SCGI-DETR(StarNet context-guided integrated detection Transformer)算法,旨在解决葡萄叶片病害检测任务中精度不高且参数量较大而难以部署在边缘设备上的问题. 本文的主要贡献如下. 1)在RT-DETR中采用StarNet[12 ] 作为特征提取主干网络,提升计算效率,实现模型的轻量化. 2)设计基于上下文引导的空间特征重建特征金字塔网络(context-guided spatial feature reconstruction feature pyramid network, CGSFR-FPN),增强复杂背景与多尺度病害的感知能力,提高检测精度与召回率. 3)构建Inner-PowerIoU v2(inner powerful intersection over union v2)损失函数,优化原广义交并比[13 ] (generalized intersection over union, GIoU)损失,提高模型对小目标的检测能力. ...
1
... 尽管相关研究的进展显著,Transformer检测仍受到计算与存储开销大、小目标识别不足及复杂背景适应性欠佳等限制. 本文提出基于改进RT-DETR的SCGI-DETR(StarNet context-guided integrated detection Transformer)算法,旨在解决葡萄叶片病害检测任务中精度不高且参数量较大而难以部署在边缘设备上的问题. 本文的主要贡献如下. 1)在RT-DETR中采用StarNet[12 ] 作为特征提取主干网络,提升计算效率,实现模型的轻量化. 2)设计基于上下文引导的空间特征重建特征金字塔网络(context-guided spatial feature reconstruction feature pyramid network, CGSFR-FPN),增强复杂背景与多尺度病害的感知能力,提高检测精度与召回率. 3)构建Inner-PowerIoU v2(inner powerful intersection over union v2)损失函数,优化原广义交并比[13 ] (generalized intersection over union, GIoU)损失,提高模型对小目标的检测能力. ...
1
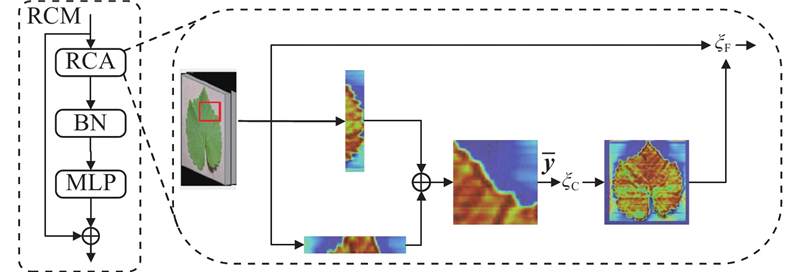
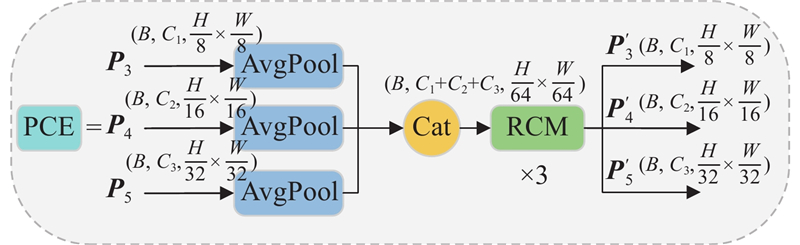
... 受CGRSeg[14 ] 的启发,CGSFR-FPN颈部含4个模块:矩形自校准模块(rectangular self-calibration module, RCM)、金字塔上下文提取模块(pyramid context extraction module, PCE)、多特征融合模块(feature blending module, FBM)及动态插值融合模块(dynamic interpolation fusion, DIF). ...
Powerful-IoU: more straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism
1
2024
... RT-DETR使用的GIoU虽然能够有效地度量预测框与真实框的重叠,但对微小偏差较敏感,因而不利于小目标回归的准确性与优化效率. 引入PIoU v2[15 ] (增强型交并比v2,Powerful-IoU v2)损失,以改进上述问题. 相较原始PIoU,PIoU v2采用非单调聚焦机制强化对中等质量预测框的关注,并结合目标尺度的自适应惩罚因子与基于框质量的梯度调节函数,引导预测框沿更优路径回归,加速收敛并提升精度. PIoU v2的计算公式为 ...
1
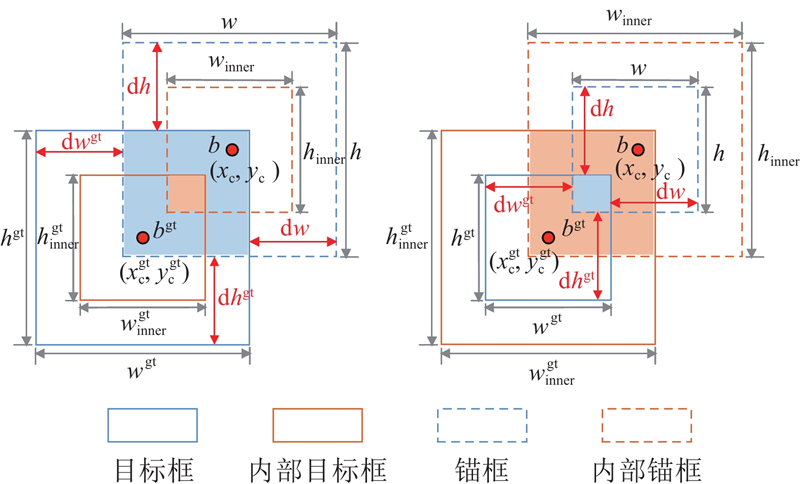
... 尽管PIoU v2提升了边界框回归的效率与鲁棒性,但在小尺度、边界不规则的病斑场景中,仅依赖整体重叠度(IoU)难以稳定刻画细微偏差,定位仍受限. PIoU v2的优化目标仍以$ {L_{{\mathrm{IoU}}}} $ [16 ] (inner intersection over union, Inner-IoU),通过度量预测框与真实框在内部区域的加权重叠,弱化边界处微小偏差的影响,更适配于小尺度与不规则病斑的精准定位. Inner-IoU的计算公式为 ...
1
... 为了验证StarNet主干网络的有效性,选取4种主流轻量级主干进行对比:FasterNet[17 ] 、EfficientViT[18 ] 、RepViT[19 ] 和MobileNetV4[20 ] . 实验结果见表3 . 结果显示,StarNet在保持较低参数量与计算量的同时,各项精度指标均最优. 与基线ResNet-18相比,StarNet的精确率提升了1.3%,mAP@0.5提升了1.1%. StarNet的推理速度达到72.2 帧/s,高于ResNet-18的67.2 帧/s,体现了更强的特征提取能力与推理效率. 与其他轻量级主干相比,FasterNet和EfficientViT的参数量与FLOPs更低,但mAP分别降至91.0%与90.8%,推理速度仅为66.3与43.5 帧/s,表明二者以牺牲精度换取轻量化. RepViT的参数量与FLOPs均高于StarNet,检测精度和速度明显落后. MobileNetV4的mAP@0.5略高,但是在参数量、计算复杂度和推理速度上均不及StarNet. 综合来看,StarNet在保证轻量化的同时实现更优的检测精度与推理速度,证明了其作为RT-DETR主干网络的综合优势. ...
1
... 为了验证StarNet主干网络的有效性,选取4种主流轻量级主干进行对比:FasterNet[17 ] 、EfficientViT[18 ] 、RepViT[19 ] 和MobileNetV4[20 ] . 实验结果见表3 . 结果显示,StarNet在保持较低参数量与计算量的同时,各项精度指标均最优. 与基线ResNet-18相比,StarNet的精确率提升了1.3%,mAP@0.5提升了1.1%. StarNet的推理速度达到72.2 帧/s,高于ResNet-18的67.2 帧/s,体现了更强的特征提取能力与推理效率. 与其他轻量级主干相比,FasterNet和EfficientViT的参数量与FLOPs更低,但mAP分别降至91.0%与90.8%,推理速度仅为66.3与43.5 帧/s,表明二者以牺牲精度换取轻量化. RepViT的参数量与FLOPs均高于StarNet,检测精度和速度明显落后. MobileNetV4的mAP@0.5略高,但是在参数量、计算复杂度和推理速度上均不及StarNet. 综合来看,StarNet在保证轻量化的同时实现更优的检测精度与推理速度,证明了其作为RT-DETR主干网络的综合优势. ...
1
... 为了验证StarNet主干网络的有效性,选取4种主流轻量级主干进行对比:FasterNet[17 ] 、EfficientViT[18 ] 、RepViT[19 ] 和MobileNetV4[20 ] . 实验结果见表3 . 结果显示,StarNet在保持较低参数量与计算量的同时,各项精度指标均最优. 与基线ResNet-18相比,StarNet的精确率提升了1.3%,mAP@0.5提升了1.1%. StarNet的推理速度达到72.2 帧/s,高于ResNet-18的67.2 帧/s,体现了更强的特征提取能力与推理效率. 与其他轻量级主干相比,FasterNet和EfficientViT的参数量与FLOPs更低,但mAP分别降至91.0%与90.8%,推理速度仅为66.3与43.5 帧/s,表明二者以牺牲精度换取轻量化. RepViT的参数量与FLOPs均高于StarNet,检测精度和速度明显落后. MobileNetV4的mAP@0.5略高,但是在参数量、计算复杂度和推理速度上均不及StarNet. 综合来看,StarNet在保证轻量化的同时实现更优的检测精度与推理速度,证明了其作为RT-DETR主干网络的综合优势. ...
1
... 为了验证StarNet主干网络的有效性,选取4种主流轻量级主干进行对比:FasterNet[17 ] 、EfficientViT[18 ] 、RepViT[19 ] 和MobileNetV4[20 ] . 实验结果见表3 . 结果显示,StarNet在保持较低参数量与计算量的同时,各项精度指标均最优. 与基线ResNet-18相比,StarNet的精确率提升了1.3%,mAP@0.5提升了1.1%. StarNet的推理速度达到72.2 帧/s,高于ResNet-18的67.2 帧/s,体现了更强的特征提取能力与推理效率. 与其他轻量级主干相比,FasterNet和EfficientViT的参数量与FLOPs更低,但mAP分别降至91.0%与90.8%,推理速度仅为66.3与43.5 帧/s,表明二者以牺牲精度换取轻量化. RepViT的参数量与FLOPs均高于StarNet,检测精度和速度明显落后. MobileNetV4的mAP@0.5略高,但是在参数量、计算复杂度和推理速度上均不及StarNet. 综合来看,StarNet在保证轻量化的同时实现更优的检测精度与推理速度,证明了其作为RT-DETR主干网络的综合优势. ...
Focal and efficient IOU loss for accurate bounding box regression
1
2022
... 为了评估Inner-PowerIoU v2的有效性,选取7种主流边界框回归损失函数进行对比,包括EIoU[21 ] 、SIoU[22 ] 、PIoU、PIoU v2、Inner-IoU、Wise-IoU[23 ] 和Shape-IoU[24 ] . 从表4 可以看出,Inner-PowerIoU v2在mAP@0.5、精确率和召回率3项核心指标上均表现优异,其中mAP@0.5达到91.8%,较基线GIoU提升0.7个百分点;精确率和召回率分别提升1.3个百分点和1.0个百分点. 相比之下,PIoU v2与Wise-IoU的整体性能较好,mAP@0.5分别为91.7%与91.5%,但召回率低于Inner-PowerIoU v2,说明在小目标检测上存在一定程度的漏检问题. Shape-IoU强调预测框与真实框间的几何一致性,在形状匹配上具有一定的优势,但葡萄病斑的形态多样,泛化能力受限. 传统方法如EIoU和SIoU的计算效率较高,但在多尺度目标尤其是小目标与复杂背景下鲁棒性较弱,难以保持稳定的检测性能. ...
1
... 为了评估Inner-PowerIoU v2的有效性,选取7种主流边界框回归损失函数进行对比,包括EIoU[21 ] 、SIoU[22 ] 、PIoU、PIoU v2、Inner-IoU、Wise-IoU[23 ] 和Shape-IoU[24 ] . 从表4 可以看出,Inner-PowerIoU v2在mAP@0.5、精确率和召回率3项核心指标上均表现优异,其中mAP@0.5达到91.8%,较基线GIoU提升0.7个百分点;精确率和召回率分别提升1.3个百分点和1.0个百分点. 相比之下,PIoU v2与Wise-IoU的整体性能较好,mAP@0.5分别为91.7%与91.5%,但召回率低于Inner-PowerIoU v2,说明在小目标检测上存在一定程度的漏检问题. Shape-IoU强调预测框与真实框间的几何一致性,在形状匹配上具有一定的优势,但葡萄病斑的形态多样,泛化能力受限. 传统方法如EIoU和SIoU的计算效率较高,但在多尺度目标尤其是小目标与复杂背景下鲁棒性较弱,难以保持稳定的检测性能. ...
1
... 为了评估Inner-PowerIoU v2的有效性,选取7种主流边界框回归损失函数进行对比,包括EIoU[21 ] 、SIoU[22 ] 、PIoU、PIoU v2、Inner-IoU、Wise-IoU[23 ] 和Shape-IoU[24 ] . 从表4 可以看出,Inner-PowerIoU v2在mAP@0.5、精确率和召回率3项核心指标上均表现优异,其中mAP@0.5达到91.8%,较基线GIoU提升0.7个百分点;精确率和召回率分别提升1.3个百分点和1.0个百分点. 相比之下,PIoU v2与Wise-IoU的整体性能较好,mAP@0.5分别为91.7%与91.5%,但召回率低于Inner-PowerIoU v2,说明在小目标检测上存在一定程度的漏检问题. Shape-IoU强调预测框与真实框间的几何一致性,在形状匹配上具有一定的优势,但葡萄病斑的形态多样,泛化能力受限. 传统方法如EIoU和SIoU的计算效率较高,但在多尺度目标尤其是小目标与复杂背景下鲁棒性较弱,难以保持稳定的检测性能. ...
1
... 为了评估Inner-PowerIoU v2的有效性,选取7种主流边界框回归损失函数进行对比,包括EIoU[21 ] 、SIoU[22 ] 、PIoU、PIoU v2、Inner-IoU、Wise-IoU[23 ] 和Shape-IoU[24 ] . 从表4 可以看出,Inner-PowerIoU v2在mAP@0.5、精确率和召回率3项核心指标上均表现优异,其中mAP@0.5达到91.8%,较基线GIoU提升0.7个百分点;精确率和召回率分别提升1.3个百分点和1.0个百分点. 相比之下,PIoU v2与Wise-IoU的整体性能较好,mAP@0.5分别为91.7%与91.5%,但召回率低于Inner-PowerIoU v2,说明在小目标检测上存在一定程度的漏检问题. Shape-IoU强调预测框与真实框间的几何一致性,在形状匹配上具有一定的优势,但葡萄病斑的形态多样,泛化能力受限. 传统方法如EIoU和SIoU的计算效率较高,但在多尺度目标尤其是小目标与复杂背景下鲁棒性较弱,难以保持稳定的检测性能. ...
1
... 为了全面评估各检测模型在葡萄叶片病害数据集上的表现并验证所提算法的有效性,选取主流架构开展对比:一阶段(SSD、YOLO系列、EfficientDet[25 ] )、二阶段(Faster R-CNN)与端到端Transformer架构(Deformable DETR[26 ] 、DINO[27 ] 、MS-DETR[28 ] ). 所有模型均在相同的葡萄病害图像数据集和评估指标下进行测试,实验结果见表6 . ...
1
... 为了全面评估各检测模型在葡萄叶片病害数据集上的表现并验证所提算法的有效性,选取主流架构开展对比:一阶段(SSD、YOLO系列、EfficientDet[25 ] )、二阶段(Faster R-CNN)与端到端Transformer架构(Deformable DETR[26 ] 、DINO[27 ] 、MS-DETR[28 ] ). 所有模型均在相同的葡萄病害图像数据集和评估指标下进行测试,实验结果见表6 . ...
1
... 为了全面评估各检测模型在葡萄叶片病害数据集上的表现并验证所提算法的有效性,选取主流架构开展对比:一阶段(SSD、YOLO系列、EfficientDet[25 ] )、二阶段(Faster R-CNN)与端到端Transformer架构(Deformable DETR[26 ] 、DINO[27 ] 、MS-DETR[28 ] ). 所有模型均在相同的葡萄病害图像数据集和评估指标下进行测试,实验结果见表6 . ...
1
... 为了全面评估各检测模型在葡萄叶片病害数据集上的表现并验证所提算法的有效性,选取主流架构开展对比:一阶段(SSD、YOLO系列、EfficientDet[25 ] )、二阶段(Faster R-CNN)与端到端Transformer架构(Deformable DETR[26 ] 、DINO[27 ] 、MS-DETR[28 ] ). 所有模型均在相同的葡萄病害图像数据集和评估指标下进行测试,实验结果见表6 . ...
1
... Comparison experimental result of different models
Tab.6 模型 P /%R /%mAP@0.5/% ${N_{\text{P}}}$ 6 $v$ −1 )FLOPs/109 SSD(2016) 80.7 76.7 83.1 26.2 32.5 62.6 Faster R-CNN(2016) 81.6 75.3 82.8 41.3 12.9 212.8 EfficientDet(2020) 83.7 78.6 84.5 33.4 13.4 260.7 YOLOv7[29 ] (2022) 89.8 88.7 92.6 36.4 82.8 103.2 YOLOv8s(2023) 91.0 89.5 93.0 11.1 122.3 28.4 YOLOv9s[30 ] (2024) 89.4 88.1 92.1 9.6 98.7 38.7 YOLOv10s[31 ] (2024) 90.6 87.7 92.5 8.1 130.2 24.5 YOLOv11s[32 ] (2024) 91.2 88.6 93.1 9.4 124.2 21.3 Deformable DETR(2020) 89.1 88.0 91.0 39.9 10.8 179.6 DINO(2022) 89.4 87.9 92.3 46.7 7.3 279.2 MS-DETR(2023) 89.6 88.5 92.3 53.5 30.59 117.1 RT-DETR(2023) 89.0 87.4 91.1 19.9 67.2 57.0 SCGI-DETR(本文方法) 91.6 89.8 93.4 10.7 66.7 20.5
结果显示,SCGI-DETR的检测精度最优,且在参数量与计算复杂度上具有显著的优势. 与YOLOv8s、YOLOv10s和YOLOv11s相比,SCGI-DETR的mAP@0.5分别提升了0.4%、0.9%和0.3%,且召回率更高,表明SCGI-DETR在复杂背景下对小目标与边缘病斑的检测能力更强. 在复杂度与推理效率方面,SCGI-DETR的参数量为10.7×106 ,计算量为20.5×109 ,体现了优良的轻量化特性. 与参数更冗余的Transformer模型如MS-DETR、DINO与Deformable DETR相比,SCGI-DETR在显著降低资源消耗的同时保持更高的精度. 另外,YOLOv10s与YOLOv11s的推理速度分别达到130.2和124.2 帧/s,具备一定的实时优势,但精度略低于SCGI-DETR. 相较之下,SCGI-DETR在保证93.4% mAP的同时,推理速度达到66.7帧/s,在精度与实时性间取得了更优的平衡,适用于精度要求高且算力受限的农业场景. ...
1
... Comparison experimental result of different models
Tab.6 模型 P /%R /%mAP@0.5/% ${N_{\text{P}}}$ 6 $v$ −1 )FLOPs/109 SSD(2016) 80.7 76.7 83.1 26.2 32.5 62.6 Faster R-CNN(2016) 81.6 75.3 82.8 41.3 12.9 212.8 EfficientDet(2020) 83.7 78.6 84.5 33.4 13.4 260.7 YOLOv7[29 ] (2022) 89.8 88.7 92.6 36.4 82.8 103.2 YOLOv8s(2023) 91.0 89.5 93.0 11.1 122.3 28.4 YOLOv9s[30 ] (2024) 89.4 88.1 92.1 9.6 98.7 38.7 YOLOv10s[31 ] (2024) 90.6 87.7 92.5 8.1 130.2 24.5 YOLOv11s[32 ] (2024) 91.2 88.6 93.1 9.4 124.2 21.3 Deformable DETR(2020) 89.1 88.0 91.0 39.9 10.8 179.6 DINO(2022) 89.4 87.9 92.3 46.7 7.3 279.2 MS-DETR(2023) 89.6 88.5 92.3 53.5 30.59 117.1 RT-DETR(2023) 89.0 87.4 91.1 19.9 67.2 57.0 SCGI-DETR(本文方法) 91.6 89.8 93.4 10.7 66.7 20.5
结果显示,SCGI-DETR的检测精度最优,且在参数量与计算复杂度上具有显著的优势. 与YOLOv8s、YOLOv10s和YOLOv11s相比,SCGI-DETR的mAP@0.5分别提升了0.4%、0.9%和0.3%,且召回率更高,表明SCGI-DETR在复杂背景下对小目标与边缘病斑的检测能力更强. 在复杂度与推理效率方面,SCGI-DETR的参数量为10.7×106 ,计算量为20.5×109 ,体现了优良的轻量化特性. 与参数更冗余的Transformer模型如MS-DETR、DINO与Deformable DETR相比,SCGI-DETR在显著降低资源消耗的同时保持更高的精度. 另外,YOLOv10s与YOLOv11s的推理速度分别达到130.2和124.2 帧/s,具备一定的实时优势,但精度略低于SCGI-DETR. 相较之下,SCGI-DETR在保证93.4% mAP的同时,推理速度达到66.7帧/s,在精度与实时性间取得了更优的平衡,适用于精度要求高且算力受限的农业场景. ...
YOLOv10: real-time end-to-end object detection
1
2024
... Comparison experimental result of different models
Tab.6 模型 P /%R /%mAP@0.5/% ${N_{\text{P}}}$ 6 $v$ −1 )FLOPs/109 SSD(2016) 80.7 76.7 83.1 26.2 32.5 62.6 Faster R-CNN(2016) 81.6 75.3 82.8 41.3 12.9 212.8 EfficientDet(2020) 83.7 78.6 84.5 33.4 13.4 260.7 YOLOv7[29 ] (2022) 89.8 88.7 92.6 36.4 82.8 103.2 YOLOv8s(2023) 91.0 89.5 93.0 11.1 122.3 28.4 YOLOv9s[30 ] (2024) 89.4 88.1 92.1 9.6 98.7 38.7 YOLOv10s[31 ] (2024) 90.6 87.7 92.5 8.1 130.2 24.5 YOLOv11s[32 ] (2024) 91.2 88.6 93.1 9.4 124.2 21.3 Deformable DETR(2020) 89.1 88.0 91.0 39.9 10.8 179.6 DINO(2022) 89.4 87.9 92.3 46.7 7.3 279.2 MS-DETR(2023) 89.6 88.5 92.3 53.5 30.59 117.1 RT-DETR(2023) 89.0 87.4 91.1 19.9 67.2 57.0 SCGI-DETR(本文方法) 91.6 89.8 93.4 10.7 66.7 20.5
结果显示,SCGI-DETR的检测精度最优,且在参数量与计算复杂度上具有显著的优势. 与YOLOv8s、YOLOv10s和YOLOv11s相比,SCGI-DETR的mAP@0.5分别提升了0.4%、0.9%和0.3%,且召回率更高,表明SCGI-DETR在复杂背景下对小目标与边缘病斑的检测能力更强. 在复杂度与推理效率方面,SCGI-DETR的参数量为10.7×106 ,计算量为20.5×109 ,体现了优良的轻量化特性. 与参数更冗余的Transformer模型如MS-DETR、DINO与Deformable DETR相比,SCGI-DETR在显著降低资源消耗的同时保持更高的精度. 另外,YOLOv10s与YOLOv11s的推理速度分别达到130.2和124.2 帧/s,具备一定的实时优势,但精度略低于SCGI-DETR. 相较之下,SCGI-DETR在保证93.4% mAP的同时,推理速度达到66.7帧/s,在精度与实时性间取得了更优的平衡,适用于精度要求高且算力受限的农业场景. ...
1
... Comparison experimental result of different models
Tab.6 模型 P /%R /%mAP@0.5/% ${N_{\text{P}}}$ 6 $v$ −1 )FLOPs/109 SSD(2016) 80.7 76.7 83.1 26.2 32.5 62.6 Faster R-CNN(2016) 81.6 75.3 82.8 41.3 12.9 212.8 EfficientDet(2020) 83.7 78.6 84.5 33.4 13.4 260.7 YOLOv7[29 ] (2022) 89.8 88.7 92.6 36.4 82.8 103.2 YOLOv8s(2023) 91.0 89.5 93.0 11.1 122.3 28.4 YOLOv9s[30 ] (2024) 89.4 88.1 92.1 9.6 98.7 38.7 YOLOv10s[31 ] (2024) 90.6 87.7 92.5 8.1 130.2 24.5 YOLOv11s[32 ] (2024) 91.2 88.6 93.1 9.4 124.2 21.3 Deformable DETR(2020) 89.1 88.0 91.0 39.9 10.8 179.6 DINO(2022) 89.4 87.9 92.3 46.7 7.3 279.2 MS-DETR(2023) 89.6 88.5 92.3 53.5 30.59 117.1 RT-DETR(2023) 89.0 87.4 91.1 19.9 67.2 57.0 SCGI-DETR(本文方法) 91.6 89.8 93.4 10.7 66.7 20.5
结果显示,SCGI-DETR的检测精度最优,且在参数量与计算复杂度上具有显著的优势. 与YOLOv8s、YOLOv10s和YOLOv11s相比,SCGI-DETR的mAP@0.5分别提升了0.4%、0.9%和0.3%,且召回率更高,表明SCGI-DETR在复杂背景下对小目标与边缘病斑的检测能力更强. 在复杂度与推理效率方面,SCGI-DETR的参数量为10.7×106 ,计算量为20.5×109 ,体现了优良的轻量化特性. 与参数更冗余的Transformer模型如MS-DETR、DINO与Deformable DETR相比,SCGI-DETR在显著降低资源消耗的同时保持更高的精度. 另外,YOLOv10s与YOLOv11s的推理速度分别达到130.2和124.2 帧/s,具备一定的实时优势,但精度略低于SCGI-DETR. 相较之下,SCGI-DETR在保证93.4% mAP的同时,推理速度达到66.7帧/s,在精度与实时性间取得了更优的平衡,适用于精度要求高且算力受限的农业场景. ...
Grad-CAM: visual explanations from deep networks via gradient-based localization
1
2016
... 为了考察SCGI-DETR对叶片关键区域的关注能力,采用Grad-CAM[33 ] 技术,对4类病害的注意力分布进行可视化分析. 如图9 所示,SCGI-DETR的注意力更集中,显著激活区主要位于病斑及其边缘过渡带. 以叶枯病与健康叶片为例,RT-DETR的注意力较分散,部分激活误落在叶片边缘、叶脉或背景,易导致定位偏差. SCGI-DETR更精准地聚焦病斑,能够更准确地提取关键特征,从而提升检测的稳定性. 上述可视化与检测结果表明,SCGI-DETR不仅在结构层面强化了特征提取与融合,而且在实际应用中表现出更强的语义关注与判别能力,尤其适用于小目标密集、背景干扰复杂的农业病害检测. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}