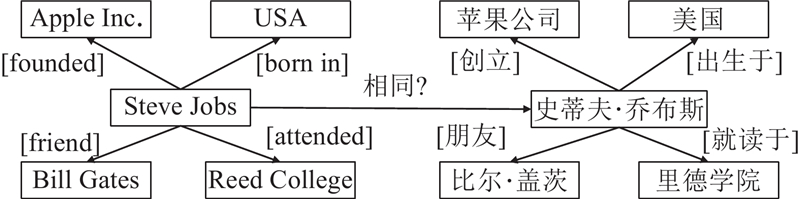
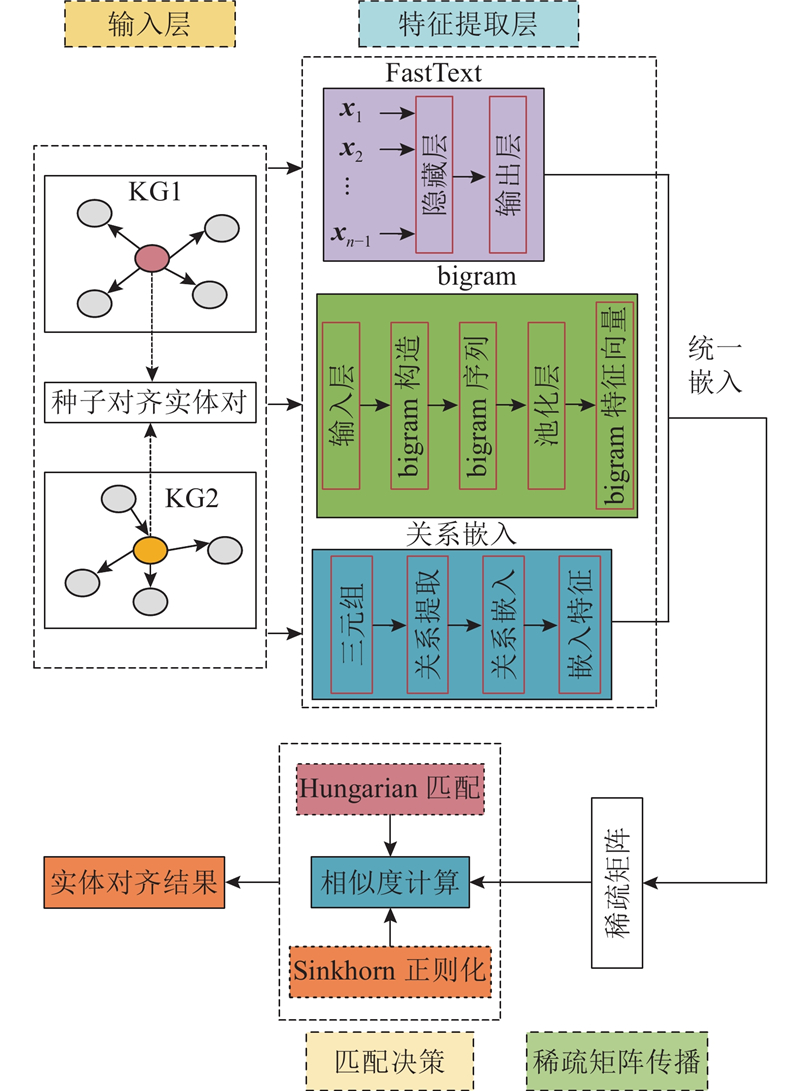
Entity alignment for multilingual knowledge fusion suffers from insufficient granularity in feature modeling and limited exploitation of structural information. An entity alignment method was proposed that integrated multi-level embedding features with a sparse matrix propagation mechanism. Entities were represented through a unified embedding that fused character-level features, word-level embeddings, and neighborhood relational information, enabling fine-grained semantic and structural expression. To promote efficient knowledge propagation, a sparse adjacency matrix was constructed based on relation embeddings, and a normalization-based mechanism was introduced to stabilize feature transmission across graphs. To enhance global consistency during alignment, Sinkhorn regularization was applied to refine the similarity matrix, followed by the Hungarian algorithm to obtain optimal one-to-one matching. Stable performance was achieved on multiple cross-lingual knowledge graph datasets in terms of evaluation metrics such as hit rate and mean reciprocal rank. Compared with representative methods such as SNGA and EAMI, the proposed approach demonstrated strong competitiveness, validating its accuracy and robustness.
FENG Chaowen, GENG Chengchen, LIU Yingli. Entity alignment method based on embedding features and sparse matrices. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(2): 379-387 doi:10.3785/j.issn.1008-973X.2026.02.016
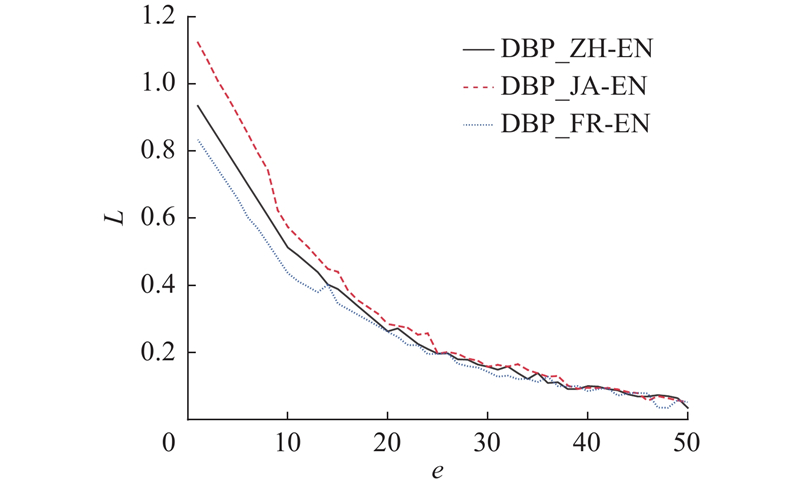
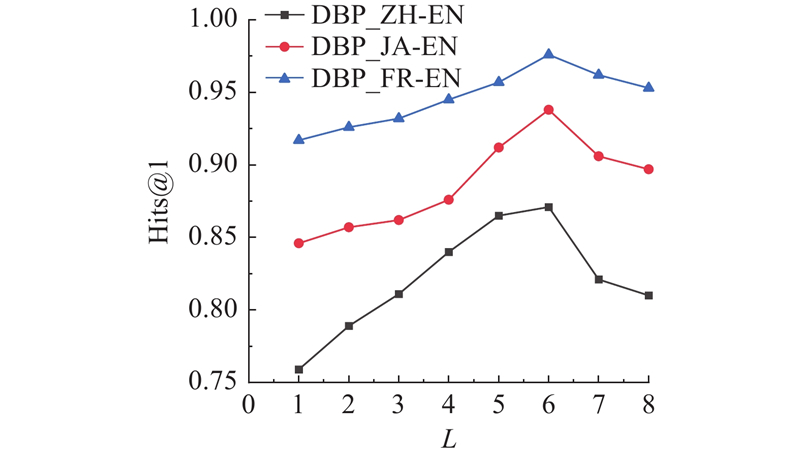
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性.
COHEN W W, RICHMAN J. Learning to match and cluster large high-dimensional data sets for data integration [C]// Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton: ACM, 2002: 475–480.
SARAWAGI S, BHAMIDIPATY A. Interactive deduplication using active learning [C]// Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton: ACM, 2002: 269–278.
ARASU A, GÖTZ M, KAUSHIK R. On active learning of record matching packages [C]// Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. Indianapolis: ACM, 2010: 783–794.
JEAN-MARY Y R, SHIRONOSHITA E P, KABUKA M R. ASMOV: results for OAEI 2010 [C]// Proceedings of the 5th International Workshop on Ontology Matching (OM 2010). Shanghai: [s.n.], 2010: 114−121.
SUCHANEK F M, ABITEBOUL S, SENELLART P. PARIS: probabilistic alignment of relations, instances, and schema [EB/OL]. (2011−11−30)[2025−03−05]. https://arxiv.org/pdf/1111.7164.
LACOSTE-JULIEN S, PALLA K, DAVIES A, et al. SiGMa: simple greedy matching for aligning large knowledge bases [C]// Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago: ACM, 2013: 572−580.
CHEN M, TIAN Y, YANG M, et al. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment [EB/OL]. (2017−05−17)[2025−03−05]. https://arxiv.org/pdf/1611.03954.
CAO Y, LIU Z, LI C, et al. Multi-channel graph neural network for entity alignment [EB/OL]. (2019−08−26)[2025−03−05]. https://arxiv.org/pdf/1908.09898.
SUN Z, HU W, ZHANG Q, et al. Bootstrapping entity alignment with knowledge graph embedding [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: ACM, 2018: 4396–4402.
MAO X, WANG W, WU Y, et al. Are negative samples necessary in entity alignment? An approach with high performance, scalability and robustness [C]// Proceedings of the 30th ACM International Conference on Information and Knowledge Management. [S.l.]: ACM, 2021: 1263−1273.
MAO X, WANG W, XU H, et al. MRAEA: an efficient and robust entity alignment approach for cross-lingual knowledge graph [C]// Proceedings of the 13th International Conference on Web Search and Data Mining. Houston: ACM, 2020: 420−428.
LIU Z, CAO Y, PAN L, et al. Exploring and evaluating attributes, values, and structures for entity alignment [EB/OL]. (2021−01−02)[2025−03−05]. https://arxiv.org/pdf/2010.03249.
WU Y, LIU X, FENG Y, et al. Relation-aware entity alignment for heterogeneous knowledge graphs [EB/OL]. (2019−08−22)[2025−03−05]. https://arxiv.org/pdf/1908.08210.
WU Y, LIU X, FENG Y, et al. Jointly learning entity and relation representations for entity alignment [EB/OL]. (2019−09−20)[2025−03−05]. https://arxiv.org/pdf/1909.09317.
CHEN M, SHI W, ZHOU B, et al. Cross-lingual entity alignment with incidental supervision [EB/OL]. (2021−01−26)[2025−03−05]. https://arxiv.org/pdf/2005.00171.
WANG Z, YANG J, YE X. Knowledge graph alignment with entity-pair embedding [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. [S.l.]: ACL, 2020: 1672−1680.
TANG J, ZHAO K, LI J. A fused Gromov-Wasserstein framework for unsupervised knowledge graph entity alignment [EB/OL]. (2023−05−11)[2025−03−05]. https://arxiv.org/pdf/2305.06574.
ZHAO Y, WU Y, CAI X, et al. From alignment to entailment: a unified textual entailment framework for entity alignment [C]// Findings of the Association for Computational Linguistics. Toronto: ACL, 2023: 8795−8806.
SUN Z, HU W, LI C. Cross-lingual entity alignment via joint attribute-preserving embedding [C]// Proceedings of the Semantic Web – ISWC 2017. [S.l.]: Springer, 2017: 628–644.
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...
... Performance comparison of different entity alignment methods on DBP15K dataset Tab.2
方法
DBP_ZH-EN
DBP_JA-EN
DBP_FR-EN
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
Hits@1
Hits@10
MRR
MTransE[16]
0.209
0.512
0.310
0.250
0.572
0.360
0.247
0.577
0.360
GCN-Align[17]
0.434
0.762
0.550
0.427
0.762
0.540
0.411
0.772
0.530
MuGNN[18]
0.494
0.844
0.611
0.501
0.857
0.621
0.495
0.870
0.621
BootEA[19]
0.629
0.847
0.703
0.622
0.853
0.701
0.653
0.874
0.731
PSR[20]
0.802
0.935
0.851
0.803
0.938
0.852
0.828
0.952
0.874
MRAEA[21]
0.757
0.930
0.827
0.758
0.934
0.826
0.781
0.948
0.849
AttrGNN[22]
0.796
0.929
0.845
0.783
0.920
0.834
0.919
0.979
0.910
RDGCN[23]
0.697
0.842
0.750
0.763
0.897
0.810
0.873
0.950
0.901
HGCN[24]
0.720
0.857
0.760
0.766
0.897
0.812
0.892
0.961
0.910
JEANS[25]
0.719
0.895
0.791
0.737
0.914
0.798
0.769
0.940
0.827
EPEA[26]
0.885
0.953
0.911
0.924
0.969
0.942
0.955
0.986
0.967
SNGA[27]
0.987
0.997
0.991
0.991
0.998
0.994
0.998
1.000
0.999
EAMI[28]
0.935
0.982
0.950
0.939
0.978
0.950
0.987
0.996
0.990
本研究
0.871
0.950
0.900
0.938
0.982
0.955
0.976
0.995
0.984
3.6. 训练过程收敛性分析
如图3所示为所提方法在DBP15K3个子集中的训练阶段的损失函数收敛曲线,其中$ e $为训练轮数,$ L $为损失值. 可以看出,3条曲线在初始阶段均呈现出较快的下降趋势,表明模型在前几轮训练中能够迅速学习到有效特征. 随着训练轮数的增加,损失值逐步收敛并在第40轮后趋于平稳,说明模型已达到较为稳定的最优状态. 从整体趋势看,DBP_ZH-EN子集的损失下降幅度略快,DBP_JA-EN和DBP_FR-EN子集在中后期收敛性较强,表明所提方法在多语种异构图谱下具备良好的适应性与泛化能力. 此外,各曲线中存在的轻微扰动反映出训练过程中的自然波动,但不影响整体收敛效果,进一步印证本研究构建的特征融合与传播机制在不同数据场景下的稳定性与鲁棒性. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}