[1]
ZHAO Z, LIU B, LU Y, et al Joint identity-aware mixstyle and graph-enhanced prototype for clothes-changing person re-identification
[J]. IEEE Transactions on Multimedia , 2023 , 26 : 3457 - 3468
[本文引用: 2]
[2]
SUN Y, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline) [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 501–518.
[本文引用: 3]
[3]
闫禹铭, 何剑锋, 李殊昭, 等 现实场景下行人身份识别
[J]. 浙江大学学报: 工学版 , 2021 , 55 (11 ): 2022 - 2032
[本文引用: 1]
YAN Yuming, HE Jianfeng, LI Shuzhao, et al Identity recognition under real scenes
[J]. Journal of Zhejiang University: Engineering science , 2021 , 55 (11 ): 2022 - 2032
[本文引用: 1]
[4]
HE W, DENG Y, TANG S, et al. Instruct-ReID: a multi-purpose person re-identification task with instructions [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 17521–17531.
[本文引用: 3]
[5]
YE M, SHEN J, LIN G, et al Deep learning for person re-identification: a survey and outlook
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (6 ): 2872 - 2893
DOI:10.1109/TPAMI.2021.3054775
[本文引用: 4]
[6]
HE S, LUO H, WANG P, et al. TransReID: Transformer-based object re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 14993–15002.
[本文引用: 4]
[7]
DING Y, MAO R, ZHU H, et al. Discriminative pedestrian features and gated channel attention for clothes-changing person re-identification [C]// Proceedings of the IEEE International Conference on Multimedia and Expo . Niagara Falls: IEEE, 2024: 1–6.
[本文引用: 2]
[8]
HUANG Y, WU Q, XU J, et al. Clothing status awareness for long-term person re-identification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 11875–11884.
[本文引用: 1]
[9]
YANG Z, ZHONG X, ZHONG Z, et al Win-win by competition: auxiliary-free cloth-changing person re-identification
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 2985 - 2999
DOI:10.1109/TIP.2023.3277389
[本文引用: 2]
[10]
WANG L, ZHANG Y, LU T, et al Multi feature fusion attention learning for clothing-changing person re-identification
[J]. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences , 2022 , 105 (8 ): 1170 - 1174
[本文引用: 1]
[11]
YANG S, KANG B, LEE Y Sampling agnostic feature representation for long-term person re-identification
[J]. IEEE Transactions on Image Processing , 2022 , 31 : 6412 - 6423
DOI:10.1109/TIP.2022.3207024
[本文引用: 2]
[12]
GU X, CHANG H, MA B, et al. Clothes-changing person re-identification with RGB modality only [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1060–1069.
[本文引用: 3]
[13]
WANG Q, QIAN X, FU Y, et al. Co-attention aligned mutual cross-attention for cloth-changing person re-identification [C]// Proceedings of the Asian Conference on Computer Vision . Macau: Springer, 2022: 2270–2288.
[本文引用: 1]
[14]
LIU X, LIU K, GUO J, et al Pose-guided attention learning for cloth-changing person re-identification
[J]. IEEE Transactions on Multimedia , 2023 , 26 (8 ): 5490 - 5498
[本文引用: 3]
[15]
GUO P, LIU H, WU J, et al. Semantic-aware consistency network for cloth-changing person re-identification [C]// Proceedings of the 31st ACM International Conference on Multimedia . Ottawa: ACM, 2023: 8730–8739.
[本文引用: 3]
[16]
ZHU K, GUO H, LIU Z, et al. Identity-guided human semantic parsing for person re-identification [C]// Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 346–363.
[本文引用: 1]
[17]
LIU F, YE M, DU B Dual level adaptive weighting for cloth-changing person re-identification
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 5075 - 5086
DOI:10.1109/TIP.2023.3310307
[本文引用: 1]
[18]
MU J, LI Y, LI J, et al. Learning clothes-irrelevant cues for clothes-changing person re-identification [C]// Proceedings of the 33rd British Machine Vision Conference . London: BMVA, 2022: 337.
[本文引用: 2]
[19]
ZHANG G, LIU J, CHEN Y, et al. Multi-biometric unified network for cloth-changing person re-identification [C]// Proceedings of the IEEE International Conference on Multimedia and Expo . Taipei: IEEE, 2022: 1–6.
[本文引用: 2]
[20]
LI Y Utilizing silhouette and head information for improved cloth-changing person re-identification
[J]. Advances in Engineering Technology Research , 2024 , 11 (1 ): 614
DOI:10.56028/aetr.11.1.614.2024
[本文引用: 1]
[21]
NGUYEN V D, KHALDI K, NGUYEN D, et al. Contrastive viewpoint-aware shape learning for long-term person re-identification [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2024: 1030–1038.
[本文引用: 2]
[22]
JIANG J, XIA N A dual-channel network based on occlusion feature compensation for human pose estimation
[J]. Image and Vision Computing , 2024 , 151 : 105290
DOI:10.1016/j.imavis.2024.105290
[本文引用: 1]
[23]
JIANG J, XIA N, YU X A feature matching and compensation method based on importance weighting for occluded human pose estimation
[J]. Journal of King Saud University: Computer and Information Sciences , 2024 , 36 (5 ): 102061
DOI:10.1016/j.jksuci.2024.102061
[本文引用: 1]
[24]
TU Z, ZHANG J, LI H, et al Joint-bone fusion graph convolutional network for semi-supervised skeleton action recognition
[J]. IEEE Transactions on Multimedia , 2022 , 25 : 1819 - 1831
[本文引用: 1]
[25]
SUN R, CHEN L, ZHANG L, et al Robust visible-infrared person re-identification based on polymorphic mask and wavelet graph convolutional network
[J]. IEEE Transactions on Information Forensics and Security , 2024 , 19 : 2800 - 2813
DOI:10.1109/TIFS.2024.3354377
[本文引用: 1]
[26]
HUANG M, HOU C, YANG Q, et al Reasoning and tuning: graph attention network for occluded person re-identification
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 1568 - 1582
DOI:10.1109/TIP.2023.3247159
[本文引用: 1]
[27]
LIAN Y, HUANG W, LIU S, et al Person re-identification using local relation-aware graph convolutional network
[J]. Sensors , 2023 , 23 (19 ): 8138
DOI:10.3390/s23198138
[本文引用: 1]
[28]
WANG J, SUN K, CHENG T, et al Deep high-resolution representation learning for visual recognition
[J]. IEEE transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (10 ): 3349 - 3364
DOI:10.1109/TPAMI.2020.2983686
[本文引用: 1]
[29]
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248–255.
[本文引用: 1]
[30]
LI P, XU Y, WEI Y, et al Self-correction for human parsing
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (6 ): 3260 - 3271
DOI:10.1109/TPAMI.2020.3048039
[本文引用: 1]
[31]
HOSSAIN S, UMER S, ROUT R K, et al Fine-grained image analysis for facial expression recognition using deep convolutional neural networks with bilinear pooling
[J]. Applied Soft Computing , 2023 , 134 : 109997
DOI:10.1016/j.asoc.2023.109997
[本文引用: 1]
[32]
YANG Q, WU A, ZHENG W S Person re-identification by contour sketch under moderate clothing change
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (6 ): 2029 - 2046
DOI:10.1109/TPAMI.2019.2960509
[本文引用: 1]
[33]
SHU X, WANG X, ZANG X, et al Large-scale spatio-temporal person re-identification: algorithms and benchmark
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2022 , 32 (7 ): 4390 - 4403
[本文引用: 1]
[34]
HUANG Y, WU Q, XU J, et al. Celebrities-ReID: a benchmark for clothes variation in long-term person re-identification [C]// Proceedings of the International Joint Conference on Neural Networks . Budapest: IEEE, 2019: 1–8.
[本文引用: 2]
Joint identity-aware mixstyle and graph-enhanced prototype for clothes-changing person re-identification
2
2023
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
3
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
现实场景下行人身份识别
1
2021
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
现实场景下行人身份识别
1
2021
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
3
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Comparison of Rank-
n metrics of different methods on PRCC dataset
Tab.3 方法 Rank-1/% Rank-5/% Rank-10/% AGW[5 ] 39.7 45.8 48.5 TransReID[6 ] 42.9 47.7 50.4 SCNet[15 ] 61.3 68.1 70.2 IRM[4 ] 54.2 60.5 64.2 PGNet 63.7 70.8 73.7
2.4. 实验结果可视化分析 基线模型仅采用HRNet进行特征提取,并利用由BN层生成的特征表示进行身份预测. 图5 为PGNet、基线模型和IRM在PRCC数据集上的可视化测试效果对比图. 为了全面评估算法性能,从待检测集query中选择4张行人图像,分别代表正面、侧面、背面以及光线较暗环境这4种典型场景. 从检索结果中选取与待检测图像相似度排前5的图像,虚线边框表示检索结果与待检测图像的行人ID一致,实线边框则为不一致. 可以看出,基线模型的检索性能存在显著局限性. 在多个场景的检索图像中,行人着装与待检索行人的服装相似,这表明基线模型在应对因服装相似导致的检索失败问题时,处理能力存在不足. 尤其在面对不同姿态变化,如行人转身等情况时,其表现出明显缺陷. 相比之下,PGNet的检索效果明显优于基线模型. PGNet运用双分支特征提取融合策略,在服装变化的情况下,能够有效提取与服装无关的判别特征,大幅减少了因服装相似导致的错误检索. 相较于IRM算法,PGNet方法在首位命中率方面表现更优. 特别是在正面视角和低光照环境下,PGNet展现出更高的识别准确率,表明其对光照变化的鲁棒性更强. 然而,在行人侧身姿态下,PGNet的检索性能受到一定影响. 即便如此,相比于IRM算法,PGNet在排序前2的高相似度检索结果的平均准确率上仍然具有优势. 例如,在图5 展示的侧身姿态检索示例中,PGNet的前2个检索结果中正确匹配的数量相对更多,体现了其在该场景下的相对优势. ...
Deep learning for person re-identification: a survey and outlook
4
2022
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
... Comparison of Rank-
n metrics of different methods on PRCC dataset
Tab.3 方法 Rank-1/% Rank-5/% Rank-10/% AGW[5 ] 39.7 45.8 48.5 TransReID[6 ] 42.9 47.7 50.4 SCNet[15 ] 61.3 68.1 70.2 IRM[4 ] 54.2 60.5 64.2 PGNet 63.7 70.8 73.7
2.4. 实验结果可视化分析 基线模型仅采用HRNet进行特征提取,并利用由BN层生成的特征表示进行身份预测. 图5 为PGNet、基线模型和IRM在PRCC数据集上的可视化测试效果对比图. 为了全面评估算法性能,从待检测集query中选择4张行人图像,分别代表正面、侧面、背面以及光线较暗环境这4种典型场景. 从检索结果中选取与待检测图像相似度排前5的图像,虚线边框表示检索结果与待检测图像的行人ID一致,实线边框则为不一致. 可以看出,基线模型的检索性能存在显著局限性. 在多个场景的检索图像中,行人着装与待检索行人的服装相似,这表明基线模型在应对因服装相似导致的检索失败问题时,处理能力存在不足. 尤其在面对不同姿态变化,如行人转身等情况时,其表现出明显缺陷. 相比之下,PGNet的检索效果明显优于基线模型. PGNet运用双分支特征提取融合策略,在服装变化的情况下,能够有效提取与服装无关的判别特征,大幅减少了因服装相似导致的错误检索. 相较于IRM算法,PGNet方法在首位命中率方面表现更优. 特别是在正面视角和低光照环境下,PGNet展现出更高的识别准确率,表明其对光照变化的鲁棒性更强. 然而,在行人侧身姿态下,PGNet的检索性能受到一定影响. 即便如此,相比于IRM算法,PGNet在排序前2的高相似度检索结果的平均准确率上仍然具有优势. 例如,在图5 展示的侧身姿态检索示例中,PGNet的前2个检索结果中正确匹配的数量相对更多,体现了其在该场景下的相对优势. ...
4
... 行人重识别是计算机视觉领域的重要任务,旨在对不同监控视角下的目标行人进行关联匹配[1 -2 ] ,相关技术被广泛应用于智能监控[3 ] 、安防[4 ] 等领域. 现有研究大多关注于短时间跨度[5 -6 ] 内行人不改变自身着装的情况下的匹配,所用方法通常以目标外观特征为主要判别依据. 然而,当进行时间跨度大的行人检索时,季节更替、气候变化或者特定情况下的人为换装等因素导致外观特征不稳定,这使得过度依赖外观特征信息进行判别的模型可能会产生错误匹配的情况. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
... Comparison of Rank-
n metrics of different methods on PRCC dataset
Tab.3 方法 Rank-1/% Rank-5/% Rank-10/% AGW[5 ] 39.7 45.8 48.5 TransReID[6 ] 42.9 47.7 50.4 SCNet[15 ] 61.3 68.1 70.2 IRM[4 ] 54.2 60.5 64.2 PGNet 63.7 70.8 73.7
2.4. 实验结果可视化分析 基线模型仅采用HRNet进行特征提取,并利用由BN层生成的特征表示进行身份预测. 图5 为PGNet、基线模型和IRM在PRCC数据集上的可视化测试效果对比图. 为了全面评估算法性能,从待检测集query中选择4张行人图像,分别代表正面、侧面、背面以及光线较暗环境这4种典型场景. 从检索结果中选取与待检测图像相似度排前5的图像,虚线边框表示检索结果与待检测图像的行人ID一致,实线边框则为不一致. 可以看出,基线模型的检索性能存在显著局限性. 在多个场景的检索图像中,行人着装与待检索行人的服装相似,这表明基线模型在应对因服装相似导致的检索失败问题时,处理能力存在不足. 尤其在面对不同姿态变化,如行人转身等情况时,其表现出明显缺陷. 相比之下,PGNet的检索效果明显优于基线模型. PGNet运用双分支特征提取融合策略,在服装变化的情况下,能够有效提取与服装无关的判别特征,大幅减少了因服装相似导致的错误检索. 相较于IRM算法,PGNet方法在首位命中率方面表现更优. 特别是在正面视角和低光照环境下,PGNet展现出更高的识别准确率,表明其对光照变化的鲁棒性更强. 然而,在行人侧身姿态下,PGNet的检索性能受到一定影响. 即便如此,相比于IRM算法,PGNet在排序前2的高相似度检索结果的平均准确率上仍然具有优势. 例如,在图5 展示的侧身姿态检索示例中,PGNet的前2个检索结果中正确匹配的数量相对更多,体现了其在该场景下的相对优势. ...
2
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
1
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
Win-win by competition: auxiliary-free cloth-changing person re-identification
2
2023
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
Multi feature fusion attention learning for clothing-changing person re-identification
1
2022
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
Sampling agnostic feature representation for long-term person re-identification
2
2022
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
3
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
1
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
Pose-guided attention learning for cloth-changing person re-identification
3
2023
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
3
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
... Comparison of Rank-
n metrics of different methods on PRCC dataset
Tab.3 方法 Rank-1/% Rank-5/% Rank-10/% AGW[5 ] 39.7 45.8 48.5 TransReID[6 ] 42.9 47.7 50.4 SCNet[15 ] 61.3 68.1 70.2 IRM[4 ] 54.2 60.5 64.2 PGNet 63.7 70.8 73.7
2.4. 实验结果可视化分析 基线模型仅采用HRNet进行特征提取,并利用由BN层生成的特征表示进行身份预测. 图5 为PGNet、基线模型和IRM在PRCC数据集上的可视化测试效果对比图. 为了全面评估算法性能,从待检测集query中选择4张行人图像,分别代表正面、侧面、背面以及光线较暗环境这4种典型场景. 从检索结果中选取与待检测图像相似度排前5的图像,虚线边框表示检索结果与待检测图像的行人ID一致,实线边框则为不一致. 可以看出,基线模型的检索性能存在显著局限性. 在多个场景的检索图像中,行人着装与待检索行人的服装相似,这表明基线模型在应对因服装相似导致的检索失败问题时,处理能力存在不足. 尤其在面对不同姿态变化,如行人转身等情况时,其表现出明显缺陷. 相比之下,PGNet的检索效果明显优于基线模型. PGNet运用双分支特征提取融合策略,在服装变化的情况下,能够有效提取与服装无关的判别特征,大幅减少了因服装相似导致的错误检索. 相较于IRM算法,PGNet方法在首位命中率方面表现更优. 特别是在正面视角和低光照环境下,PGNet展现出更高的识别准确率,表明其对光照变化的鲁棒性更强. 然而,在行人侧身姿态下,PGNet的检索性能受到一定影响. 即便如此,相比于IRM算法,PGNet在排序前2的高相似度检索结果的平均准确率上仍然具有优势. 例如,在图5 展示的侧身姿态检索示例中,PGNet的前2个检索结果中正确匹配的数量相对更多,体现了其在该场景下的相对优势. ...
1
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
Dual level adaptive weighting for cloth-changing person re-identification
1
2023
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
2
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on PRCC and VC-Clothes datasets
Tab.1 方法 PRCC常规场景 PRCC换衣场景 VC-Clothes常规场景 VC-Clothes换衣场景 mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 97.0 99.8 38.7 41.8 74.6 87.4 62.2 62.0 AGW[5 ] 89.0 97.8 37.1 39.7 89.7 91.1 82.1 92.0 CAL[12 ] 99.2 100. 0 55.8 55.2 95.3 95.1 87.2 92.9 TransReID[6 ] 97.0 98.2 45.0 42.9 93.8 92.4 81.0 90.4 CRE+BSGA[18 ] 97.3 99.6 58.7 61.8 88.2 94.4 84.3 84.5 SCNet[15 ] 97.8 100. 0 59.9 61.3 89.6 94.9 84.4 90.1 IMS-GEP[1 ] 99.8 99.7 65.8 57.3 94.9 94.7 81.7 81.8 CDM+GCA[7 ] 94.3 99.3 61.3 64.8 92.8 93.1 82.7 83.7 IRM[4 ] — — 52.3 54.2 — — 80.1 90.1 PGAL[14 ] — — 58.7 59.5 — — — — PGNet 99.2 99.8 60.5 63.7 91.3 95.4 84.7 93.3
在VC-Clothes数据集上,所提方法在换衣场景中表现优异,Rank-1为93.3%,优于其他对比方法,相较于次优方法CAL提升了0.4个百分点,验证了其在应对换衣场景时的表征能力. 在常规场景中,所提方法测得的Rank-1指标为95.4%,较次优方法SCNet提升了0.5个百分点;在mAP指标上,测得结果为91.3%,体现了模型在无着装变化场景下的高检索准确率. 总体而言,提出的PGNet在涉及复杂服装变化的行人重识别任务中具有较大的优势,同时在常规场景下也保持了较高的准确率. 此外,所提方法在PRCC常规数据集和换装数据集上的结果相差较大,而在VC-Clothes数据集中两者差距并不明显,这种现象可以从2个方面进行分析. 从场景复杂度来看,PRCC数据集场景相对单一且简洁,因此模型在PRCC常规数据集中的结果比在VC-Clothes数据集中的结果略好;但是从更换服装样式的角度来对比时,PRCC数据集中行人更换的服装样式差异大,且不同行人可能穿着相同颜色或相似款式的服装,导致测试难度增大,而VC-Clothes数据集中服装更换样式相对固定,因此模型在其换装数据集与常规数据集上的性能差距较小. ...
2
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets
Tab.2 方法 Celeb-reID Celeb-reID-light mAP/% Rank-1/% mAP/% Rank-1/% PCB[2 ] 8.7 45.1 12.7 23.9 AGW[5 ] 11.2 47.1 13.8 22.0 TransReID[6 ] 9.3 45.7 12.9 21.2 RCSANet[8 ] 11.9 55.6 16.7 29.5 CAL[12 ] 13.7 59.2 18.5 33.6 ACID[9 ] 11.4 52.5 15.8 27.9 MBUNet[19 ] 12.8 55.5 21.5 35.5 SirNet[11 ] 14.2 56.0 20.0 36.0 PGAL[14 ] 15.3 60.9 23.3 40.4 PGNet 15.7 59.5 22.6 41.2
此外,在PRCC数据集上进行不同方法在Rank-n 指标下的对比实验. 如表3 所示,PGNet在PRCC数据集上的Rank-1、Rank-5、Rank-10指标分别为63.7%、70.8%、73.7%,均高于其余对比方法,充分证明了在换装行人重识别任务中,PGNet不仅在首位匹配时展现高准确率,而且在扩大检索范围至前5位或前10位匹配时依然优于其他对比方法,验证了所提方法的有效性. ...
Utilizing silhouette and head information for improved cloth-changing person re-identification
1
2024
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
2
... 为了解决上述问题,引入换装行人重识别任务,专注于应对换装场景下的行人检索[7 -9 ] . 主要采用特征解耦和多特征融合2类方法. 在第1类方法中,Wang等[10 ] 利用生成对抗网络生成服装变化图像,引导模型学习与服装无关的特征;由于这种方法可能在生成过程中引入无关的噪声特征,通过特征重构的方法解耦服装特征,即分离出服装相关特征并重建与服装无关的特征表示. Yang等[11 ] 提出与采样无关的鲁棒特征表示网络,从样本中学习解耦的特征嵌入. Gu等[12 ] 通过抑制模型对服装的预测能力,削弱服装相关信息的干扰. 第2类方法通过引入与服装无关的显式特征,如人体骨架结构[13 ] 、行走姿态[14 ] 、面部特征[15 ] 等,削弱对服装特征的依赖,增强模型在不同换装场景下的鲁棒性. Zhu等[16 ] 通过生成人体部位的伪标签,在特征图上进行分组学习,以强调人体部位等不变特征. Liu等[17 ] 通过对服装以外的局部区域特征进行相关性计算,对不变特征进行加权以削弱服装敏感性. Mu等[18 ] 提出身体形状引导模块,利用空间注意力机制引导模型聚焦于身体形状区域. Zhang等[19 ] 通过引入多生物特征分支,提取人脸、颈部、肩部等部位的特征来抵抗着装变化的影响. Li[20 ] 利用轮廓和人脸特征信息提取与服装无关的特征. Nguyen等[21 ] 构建关系形状嵌套分支,结合人体姿态关键点和图注意力网络来提取局部和全局的身体形状信息. 然而,上述对于局部区域相关性的计算方法忽略了全局特征的整合,可能导致其判别能力受限;而仅针对单一局部或整体骨架特征建模的方法未能充分挖掘骨架节点间的关联性. ...
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
A dual-channel network based on occlusion feature compensation for human pose estimation
1
2024
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
A feature matching and compensation method based on importance weighting for occluded human pose estimation
1
2024
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
Joint-bone fusion graph convolutional network for semi-supervised skeleton action recognition
1
2022
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
Robust visible-infrared person re-identification based on polymorphic mask and wavelet graph convolutional network
1
2024
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
Reasoning and tuning: graph attention network for occluded person re-identification
1
2023
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
Person re-identification using local relation-aware graph convolutional network
1
2023
... 受Nguyen等[21 ] 工作的启发,进一步关注人体关键点之间的拓扑结构关系. 通过提取人体骨架信息,挖掘潜在的结构特征,并引入图卷积网络(graph convolutional network, GCN),利用其强大的建模能力对人体姿态特征进行深层次表征,增强模型对人体骨架信息的表达能力. 图卷积网络因其能够有效捕捉数据中节点间的复杂关系,已被广泛应用于姿态估计[22 -23 ] 、动作识别[24 ] 等任务. 许多研究尝试将其应用于行人重识别任务. Sun等[25 ] 提出基于小波函数的图卷积模块,利用从图像中提取的语义局部特征,结合图卷积模块聚合高阶特征,从而在受污染的图像中增强人体结构信息的鲁棒性. Huang等[26 ] 为了解决遮挡问题,设计推理调优图注意网络,通过计算特征相似性生成注意力得分,指导图卷积网络抑制遮挡区域的噪声干扰. Lian等[27 ] 基于图结构进行局部特征建模,构建重叠图和相似度图,以整合行人图像间的局部特征关系. 尽管这些方法在捕捉人体关键点拓扑关系方面有一定优势,但是在处理复杂的关键点关系时仍然存在不足,且未能充分利用人体骨架中关键点之间的全局空间关联性. 因此,选择以行人骨架为图节点,结合与行人动作相关的拓扑结构构建邻接矩阵,通过图卷积网络自适应建模关键点之间的空间关联性,削弱着装变化的干扰,进一步提升模型的判别能力. ...
Deep high-resolution representation learning for visual recognition
1
2021
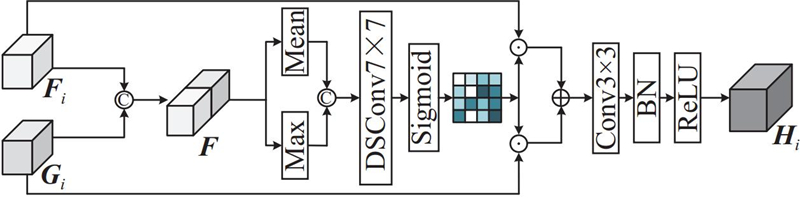
... 为了弱化服装特征对模型的干扰,在PGNet中引入人体骨架结构特征,通过辅助建模提取与服装无关的判别信息. 考虑到高分辨率网络(high-resolution network, HRNet)[28 ] 在高分辨率特征提取,特别是多尺度分支融合和人体关键点检测方面的突出表现,选择ImageNet[29 ] 预训练的HRNet作为2个分支的主干网络. HRNet在高分辨率特征学习过程中,能够保留关键点和边缘等人体结构信息,从而引导模型关注与服装无关的判别特征. 在数据预处理阶段,使用在LIP(look in to person)数据集上预训练的人体解析自矫正(self-correction for human parsing, SCHP)[30 ] 模型对行人图像进行语义分割,将解析区域分为着装区和着装无关区域,并对着装区域进行擦除操作. 将处理后的图像输入到外观特征分支中,通过HRNet进行特征提取,提取着装无关区域的判别特征如头、手、脚等,同时将原始行人图像输入到姿态特征引导分支中,提取人体的17个关键点信息,并通过基于图卷积网络的姿态特征增强模块,强化骨架节点间的结构关联性. 在特征提取阶段,设计多层次特征融合模块AFFM,实现姿态与外观特征的联合表达,有效补充因服装区域擦除而缺失的深层特征信息. 最终,采用双线性多特征池化方法对2个分支的融合特征进行深度关联建模,并在预测阶段利用批归一化(batch normalization, BN)层输出的特征表示进行身份识别. ...
1
... 为了弱化服装特征对模型的干扰,在PGNet中引入人体骨架结构特征,通过辅助建模提取与服装无关的判别信息. 考虑到高分辨率网络(high-resolution network, HRNet)[28 ] 在高分辨率特征提取,特别是多尺度分支融合和人体关键点检测方面的突出表现,选择ImageNet[29 ] 预训练的HRNet作为2个分支的主干网络. HRNet在高分辨率特征学习过程中,能够保留关键点和边缘等人体结构信息,从而引导模型关注与服装无关的判别特征. 在数据预处理阶段,使用在LIP(look in to person)数据集上预训练的人体解析自矫正(self-correction for human parsing, SCHP)[30 ] 模型对行人图像进行语义分割,将解析区域分为着装区和着装无关区域,并对着装区域进行擦除操作. 将处理后的图像输入到外观特征分支中,通过HRNet进行特征提取,提取着装无关区域的判别特征如头、手、脚等,同时将原始行人图像输入到姿态特征引导分支中,提取人体的17个关键点信息,并通过基于图卷积网络的姿态特征增强模块,强化骨架节点间的结构关联性. 在特征提取阶段,设计多层次特征融合模块AFFM,实现姿态与外观特征的联合表达,有效补充因服装区域擦除而缺失的深层特征信息. 最终,采用双线性多特征池化方法对2个分支的融合特征进行深度关联建模,并在预测阶段利用批归一化(batch normalization, BN)层输出的特征表示进行身份识别. ...
Self-correction for human parsing
1
2022
... 为了弱化服装特征对模型的干扰,在PGNet中引入人体骨架结构特征,通过辅助建模提取与服装无关的判别信息. 考虑到高分辨率网络(high-resolution network, HRNet)[28 ] 在高分辨率特征提取,特别是多尺度分支融合和人体关键点检测方面的突出表现,选择ImageNet[29 ] 预训练的HRNet作为2个分支的主干网络. HRNet在高分辨率特征学习过程中,能够保留关键点和边缘等人体结构信息,从而引导模型关注与服装无关的判别特征. 在数据预处理阶段,使用在LIP(look in to person)数据集上预训练的人体解析自矫正(self-correction for human parsing, SCHP)[30 ] 模型对行人图像进行语义分割,将解析区域分为着装区和着装无关区域,并对着装区域进行擦除操作. 将处理后的图像输入到外观特征分支中,通过HRNet进行特征提取,提取着装无关区域的判别特征如头、手、脚等,同时将原始行人图像输入到姿态特征引导分支中,提取人体的17个关键点信息,并通过基于图卷积网络的姿态特征增强模块,强化骨架节点间的结构关联性. 在特征提取阶段,设计多层次特征融合模块AFFM,实现姿态与外观特征的联合表达,有效补充因服装区域擦除而缺失的深层特征信息. 最终,采用双线性多特征池化方法对2个分支的融合特征进行深度关联建模,并在预测阶段利用批归一化(batch normalization, BN)层输出的特征表示进行身份识别. ...
Fine-grained image analysis for facial expression recognition using deep convolutional neural networks with bilinear pooling
1
2023
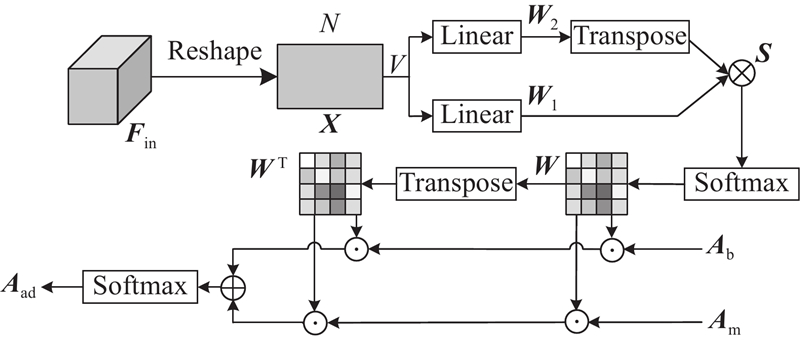
... 为了有效融合姿态特征${{\boldsymbol{F}}_{{\text{gcn}}}}$ ${{\boldsymbol{F}}_{\text{s}}}$ [31 ] 融合特征,充分挖掘2种特征的联合表示. 为了确保特征维度对齐,首先采用双线性插值法将姿态特征${{\boldsymbol{F}}_{{\text{gcn}}}}$ ${{\boldsymbol{F}}_{\text{s}}}$ $ {\boldsymbol{F}}'_{{\text{gcn}}} \in {{\mathbf{R}}^{H \times W \times V}} $ . 随后对调整后的姿态特征与外观特征进行逐元素外积运算,获得联合特征表示: ...
Person re-identification by contour sketch under moderate clothing change
1
2021
... 分别在数据集PRCC[32 ] 、VC-Clothes[33 ] 、Celeb-reID[34 ] 以及Celeb-reID-light[34 ] 上对PGNet进行性能验证. PRCC数据集包含221个行人身份的33 698张图像,涵盖A、B、C共3个摄像视角,包含2次着装变化,并涉及光线变化、图像模糊等挑战,适合用于全面评估换装行人重识别模型的鲁棒性. VC-Clothes数据集中有512个行人身份,提供4个视角,其中第2、3视角中的图像保持同一套服装,第1、4视角下行人更换2套不同服装. 相较于PRCC数据集,VC-Clothes数据集的场景更加多样化,每个行人身份包含4种不同环境的图像. Celeb-reID数据集包含1 052个行人身份,其中更换服装的图像占比为70%. 该数据集中不仅行人数量多而且服装更换较为频繁,同一行人的换衣风格差距大,使得模型在识别过程中需要有效区分不同服装特征下的行人身份. Celeb-reID-light数据集为Celeb-reID的子集,训练和测试图像均涉及服装变化. 相比于前2个数据集,其环境更复杂,如人群密集的街道场景,增加了模型准确识别行人的难度. ...
Large-scale spatio-temporal person re-identification: algorithms and benchmark
1
2022
... 分别在数据集PRCC[32 ] 、VC-Clothes[33 ] 、Celeb-reID[34 ] 以及Celeb-reID-light[34 ] 上对PGNet进行性能验证. PRCC数据集包含221个行人身份的33 698张图像,涵盖A、B、C共3个摄像视角,包含2次着装变化,并涉及光线变化、图像模糊等挑战,适合用于全面评估换装行人重识别模型的鲁棒性. VC-Clothes数据集中有512个行人身份,提供4个视角,其中第2、3视角中的图像保持同一套服装,第1、4视角下行人更换2套不同服装. 相较于PRCC数据集,VC-Clothes数据集的场景更加多样化,每个行人身份包含4种不同环境的图像. Celeb-reID数据集包含1 052个行人身份,其中更换服装的图像占比为70%. 该数据集中不仅行人数量多而且服装更换较为频繁,同一行人的换衣风格差距大,使得模型在识别过程中需要有效区分不同服装特征下的行人身份. Celeb-reID-light数据集为Celeb-reID的子集,训练和测试图像均涉及服装变化. 相比于前2个数据集,其环境更复杂,如人群密集的街道场景,增加了模型准确识别行人的难度. ...
2
... 分别在数据集PRCC[32 ] 、VC-Clothes[33 ] 、Celeb-reID[34 ] 以及Celeb-reID-light[34 ] 上对PGNet进行性能验证. PRCC数据集包含221个行人身份的33 698张图像,涵盖A、B、C共3个摄像视角,包含2次着装变化,并涉及光线变化、图像模糊等挑战,适合用于全面评估换装行人重识别模型的鲁棒性. VC-Clothes数据集中有512个行人身份,提供4个视角,其中第2、3视角中的图像保持同一套服装,第1、4视角下行人更换2套不同服装. 相较于PRCC数据集,VC-Clothes数据集的场景更加多样化,每个行人身份包含4种不同环境的图像. Celeb-reID数据集包含1 052个行人身份,其中更换服装的图像占比为70%. 该数据集中不仅行人数量多而且服装更换较为频繁,同一行人的换衣风格差距大,使得模型在识别过程中需要有效区分不同服装特征下的行人身份. Celeb-reID-light数据集为Celeb-reID的子集,训练和测试图像均涉及服装变化. 相比于前2个数据集,其环境更复杂,如人群密集的街道场景,增加了模型准确识别行人的难度. ...
... [34 ]上对PGNet进行性能验证. PRCC数据集包含221个行人身份的33 698张图像,涵盖A、B、C共3个摄像视角,包含2次着装变化,并涉及光线变化、图像模糊等挑战,适合用于全面评估换装行人重识别模型的鲁棒性. VC-Clothes数据集中有512个行人身份,提供4个视角,其中第2、3视角中的图像保持同一套服装,第1、4视角下行人更换2套不同服装. 相较于PRCC数据集,VC-Clothes数据集的场景更加多样化,每个行人身份包含4种不同环境的图像. Celeb-reID数据集包含1 052个行人身份,其中更换服装的图像占比为70%. 该数据集中不仅行人数量多而且服装更换较为频繁,同一行人的换衣风格差距大,使得模型在识别过程中需要有效区分不同服装特征下的行人身份. Celeb-reID-light数据集为Celeb-reID的子集,训练和测试图像均涉及服装变化. 相比于前2个数据集,其环境更复杂,如人群密集的街道场景,增加了模型准确识别行人的难度. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}