式中:$\boldsymbol{F}_{\mathrm{v}}^x $ x 层(x =1, 2, 3, 4, 5)的特征图; ϕ backbone 表示骨干网络,I v 、I i 为其参数,表示可见光影像和红外影像,λ v 表示卷积神经网络的相关参数. 引入具有良好稳定性的主干网络CSPDarknet[22 ] ,并采用由卷积下采样方法与新设计的特征提取方法所获取的特征图相结合的方式进行特征融合,当x =1, 2, 3, 4时,特征提取方法为卷积下采样模块;当x =5时,特征提取方法为提出的DBSConv模块,只在第5层采用DBSConv模块,从而达到训练精度与资源消耗的平衡. I i 之所以会成为可见光分支的参数之一,是因为采用的融合模块[22 ] 须利用2个分支的互补信息进行迭代.
[1]
SUN X, TIAN Y, LU W, et al From single- to multi-modal remote sensing imagery interpretation: a survey and taxonomy
[J]. Science China Information Sciences , 2023 , 66 (4 ): 140301
[本文引用: 1]
[2]
李树涛, 李聪妤, 康旭东 多源遥感图像融合发展现状与未来展望
[J]. 遥感学报 , 2021 , 25 (1 ): 148 - 166
DOI:10.11834/jrs.20210259
[本文引用: 1]
LI Shutao, LI Congyu, KANG Xudong Development status and future prospects of multi-source remote sensing image fusion
[J]. National Remote Sensing Bulletin , 2021 , 25 (1 ): 148 - 166
DOI:10.11834/jrs.20210259
[本文引用: 1]
[3]
WU Y, GUAN X, ZHAO B, et al Vehicle detection based on adaptive multimodal feature fusion and cross-modal vehicle index using RGB-T images
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2023 , 16 : 8166 - 8177
[本文引用: 1]
[4]
GÜNTHER A, NAJJAR H, DENGEL A Explainable multimodal learning in remote sensing: challenges and future directions
[J]. IEEE Geoscience and Remote Sensing Letters , 2024 , 21 : 1 - 5
[5]
ZANG Y, WANG S, GUAN H, et al VAM-Net: vegetation-Attentive deep network for Multi-modal fusion of visible-light and vegetation-sensitive images
[J]. International Journal of Applied Earth Observation and Geoinformation , 2024 , 127 : 103642
[6]
JIANG C, REN H, YANG H, et al M2FNet: multi-modal fusion network for object detection from visible and thermal infrared images
[J]. International Journal of Applied Earth Observation and Geoinformation , 2024 , 130 : 103918
[本文引用: 1]
[7]
KULKARNI S C, REGE P P Pixel level fusion techniques for SAR and optical images: a review
[J]. Information Fusion , 2020 , 59 : 13 - 29
[本文引用: 1]
[8]
WU J, HAO F, LIANG W, et al Transformer fusion and pixel-level contrastive learning for RGB-D salient object detection
[J]. IEEE Transactions on Multimedia , 2023 , 26 : 1011 - 1026
[本文引用: 1]
[9]
FENG P, LIN Y, GUAN J, et al. Embranchment cnn based local climate zone classification using sar and multispectral remote sensing data [C]// IEEE International Geoscience and Remote Sensing Symposium . Yokohama: IEEE, 2019: 6344–6347.
[本文引用: 1]
[10]
曹琼, 马爱龙, 钟燕飞, 等 高光谱-LiDAR多级融合城区地表覆盖分类
[J]. 遥感学报 , 2019 , 23 (5 ): 892 - 903
[本文引用: 1]
CAO Qiong, MA Ailong, ZHONG Yanfei, et al Urban classification by multi-feature fusion of hyperspectral image and LiDAR data
[J]. Journal of Remote Sensing , 2019 , 23 (5 ): 892 - 903
[本文引用: 1]
[11]
LI W, GAO Y, ZHANG M, et al Asymmetric feature fusion network for hyperspectral and SAR image classification
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2022 , 34 (10 ): 8057 - 8070
[本文引用: 1]
[12]
YE Y, ZHANG J, ZHOU L, et al Optical and SAR image fusion based on complementary feature decomposition and visual saliency features
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2024 , 62 : 1 - 15
[本文引用: 1]
[13]
LI L, HAN L, DING M, et al Multimodal image fusion framework for end-to-end remote sensing image registration
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 1 - 14
[本文引用: 1]
[14]
董红召, 林少轩, 佘翊妮 交通目标YOLO检测技术的研究进展
[J]. 浙江大学学报: 工学版 , 2025 , 59 (2 ): 249 - 260
[本文引用: 1]
DONG Hongzhao, LIN Shaoxuan, SHE Yini Research progress of YOLO detection technology for traffic object
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (2 ): 249 - 260
[本文引用: 1]
[15]
宋耀莲, 王粲, 李大焱, 等 基于改进YOLOv5s的无人机小目标检测算法
[J]. 浙江大学学报: 工学版 , 2024 , 58 (12 ): 2417 - 2426
[本文引用: 2]
SONG Yaolian, WANG Can, LI Dayan, et al UAV small target detection algorithm based on improved YOLOv5s
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (12 ): 2417 - 2426
[本文引用: 2]
[16]
ZHANG J, LEI J, XIE W, et al SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 1 - 15
[本文引用: 4]
[17]
LI W, LI A, KONG X, et al. MF-YOLO: multimodal fusion for remote sensing object detection based on YOLOv5s [C]// 27th International Conference on Computer Supported Cooperative Work in Design . Tianjin: IEEE, 2024: 897–903.
[本文引用: 4]
[18]
ULTRALYTICS. YOLOv5 [EB/OL]. (2024−04−01) [2025−01−16]. https://github.com/ultralytics/yolov5.
[本文引用: 1]
[19]
MA X, DAI X, BAI Y, et al. Rewrite the Stars [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 5694–5703.
[本文引用: 3]
[20]
ZHENG M, SUN L, DONG J, et al. SMFANet: a lightweight self-modulation feature aggregation network for efficient image super-resolution [C]// European Conference on Computer Vision . Cham: Springer, 2024: 359–375.
[本文引用: 2]
[21]
SHEN J, CHEN Y, LIU Y, et al ICAFusion: iterative cross-attention guided feature fusion for multispectral object detection
[J]. Pattern Recognition , 2024 , 145 : 109913
[本文引用: 10]
[22]
BOCHKOVSKIY A, WANG C, LIAO H Y. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020−04−23) [2024−12−11]. https://arxiv.org/ abs/2004.10934.
[本文引用: 2]
[23]
RAZAKARIVONY S, JURIE F Vehicle detection in aerial imagery: a small target detection benchmark
[J]. Journal of Visual Communication and Image Representation , 2016 , 34 : 187 - 203
[本文引用: 1]
[24]
FLIR ADA Team. FREE Teledyne FLIR Thermal Dataset for Algorithm Training [EB/OL]. (2024−05−01) [2025−01−21]. https://www.flir.com/oem/adas/adasdatasetform/.
[本文引用: 1]
[25]
HWANG S, PARK J, KIM N, et al. Multispectral pedestrian detection: benchmark dataset and baseline [C]// IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 1037–1045.
[本文引用: 1]
[26]
SHARMA M, DHANARAJ M, KARNAM S, et al YOLOrs: object detection in multimodal remote sensing imagery
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2020 , 14 : 1497 - 1508
[本文引用: 3]
[27]
FANG Q, WANG Z Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery
[J]. Pattern Recognition , 2022 , 130 : 108786
[本文引用: 5]
[28]
DEVAGUPTAPU C, AKOLEKAR N, SHARMA M M, et al. Borrow from anywhere: pseudo multi-modal object detection in thermal imagery [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Long Beach: IEEE, 2019: 1029–1038.
[本文引用: 2]
[29]
ZHANG H, FROMONT E, LEFEVRE S, et al. Multispectral fusion for object detection with cyclic fuse-and-refine blocks [C]// IEEE International Conference on Image Processing . Abu Dhabi: IEEE, 2020: 276–280.
[本文引用: 2]
[30]
KIEU M, BAGDANOV A D, BERTINI M Bottom-up and layerwise domain adaptation for pedestrian detection in thermal images
[J]. ACM Transactions on Multimedia Computing, Communications, and Applications , 2021 , 17 (1 ): 1 - 19
[本文引用: 2]
[31]
ZHOU K, CHEN L, CAO X. Improving multispectral pedestrian detection by addressing modality imbalance problems [C]// Computer Vision–ECCV 2020: 16th European Conference . Cham: Springer, 2020: 787–803.
[本文引用: 2]
[32]
KIM J, KIM H, KIM T, et al MLPD: multi-label pedestrian detector in multispectral domain
[J]. IEEE Robotics and Automation Letters , 2021 , 6 (4 ): 7846 - 7853
[本文引用: 2]
[33]
LI C, SONG D, TONG R, et al. Multispectral pedestrian detection via simultaneous detection and segmentation [EB/OL]. (2024−05−01) [2025−01−21]. https://arxiv.org/abs/1808.04818.
[本文引用: 2]
From single- to multi-modal remote sensing imagery interpretation: a survey and taxonomy
1
2023
... 随着遥感平台和传感器的升级,配备多种传感器的遥感卫星带来更丰富的数据源,多源遥感成为当下热门的研究课题. 与单源相比,多源提供了更多的传感器、角度、分辨率和时间信息[1 ] . 由于多源遥感影像既具有互补性,又具有冗余性,其融合能够综合利用不同模态的信息,实现更精准、更全面的遥感对地观测[2 ] ,得到了广泛的应用与推广[3 -6 ] . ...
多源遥感图像融合发展现状与未来展望
1
2021
... 随着遥感平台和传感器的升级,配备多种传感器的遥感卫星带来更丰富的数据源,多源遥感成为当下热门的研究课题. 与单源相比,多源提供了更多的传感器、角度、分辨率和时间信息[1 ] . 由于多源遥感影像既具有互补性,又具有冗余性,其融合能够综合利用不同模态的信息,实现更精准、更全面的遥感对地观测[2 ] ,得到了广泛的应用与推广[3 -6 ] . ...
多源遥感图像融合发展现状与未来展望
1
2021
... 随着遥感平台和传感器的升级,配备多种传感器的遥感卫星带来更丰富的数据源,多源遥感成为当下热门的研究课题. 与单源相比,多源提供了更多的传感器、角度、分辨率和时间信息[1 ] . 由于多源遥感影像既具有互补性,又具有冗余性,其融合能够综合利用不同模态的信息,实现更精准、更全面的遥感对地观测[2 ] ,得到了广泛的应用与推广[3 -6 ] . ...
Vehicle detection based on adaptive multimodal feature fusion and cross-modal vehicle index using RGB-T images
1
2023
... 随着遥感平台和传感器的升级,配备多种传感器的遥感卫星带来更丰富的数据源,多源遥感成为当下热门的研究课题. 与单源相比,多源提供了更多的传感器、角度、分辨率和时间信息[1 ] . 由于多源遥感影像既具有互补性,又具有冗余性,其融合能够综合利用不同模态的信息,实现更精准、更全面的遥感对地观测[2 ] ,得到了广泛的应用与推广[3 -6 ] . ...
Explainable multimodal learning in remote sensing: challenges and future directions
0
2024
VAM-Net: vegetation-Attentive deep network for Multi-modal fusion of visible-light and vegetation-sensitive images
0
2024
M2FNet: multi-modal fusion network for object detection from visible and thermal infrared images
1
2024
... 随着遥感平台和传感器的升级,配备多种传感器的遥感卫星带来更丰富的数据源,多源遥感成为当下热门的研究课题. 与单源相比,多源提供了更多的传感器、角度、分辨率和时间信息[1 ] . 由于多源遥感影像既具有互补性,又具有冗余性,其融合能够综合利用不同模态的信息,实现更精准、更全面的遥感对地观测[2 ] ,得到了广泛的应用与推广[3 -6 ] . ...
Pixel level fusion techniques for SAR and optical images: a review
1
2020
... 根据融合数据形式的不同,多源遥感影像融合方法主要分为3种策略,即像素级融合、特征级融合和决策级融合[7 ] . 像素级融合针对多源影像本身进行处理,直接对影像中的像素进行融合. Wu等[8 ] 采用像素级融合策略,设计跨模态交互并行转换模块,实现长距离多源交互,生成更全面的融合特征. Feng等[9 ] 采用高通滤波法,根据不同波段的物理特性,实现多源遥感数据的融合. 决策级融合从深层语义的角度出发,对特征的高维度信息进行融合. 曹琼等[10 ] 利用点云数据提取掩膜进行建筑物分类,并将使用掩膜和未使用掩膜的分类结果进行决策级融合,达到平滑图像去除噪声点的目的. ...
Transformer fusion and pixel-level contrastive learning for RGB-D salient object detection
1
2023
... 根据融合数据形式的不同,多源遥感影像融合方法主要分为3种策略,即像素级融合、特征级融合和决策级融合[7 ] . 像素级融合针对多源影像本身进行处理,直接对影像中的像素进行融合. Wu等[8 ] 采用像素级融合策略,设计跨模态交互并行转换模块,实现长距离多源交互,生成更全面的融合特征. Feng等[9 ] 采用高通滤波法,根据不同波段的物理特性,实现多源遥感数据的融合. 决策级融合从深层语义的角度出发,对特征的高维度信息进行融合. 曹琼等[10 ] 利用点云数据提取掩膜进行建筑物分类,并将使用掩膜和未使用掩膜的分类结果进行决策级融合,达到平滑图像去除噪声点的目的. ...
1
... 根据融合数据形式的不同,多源遥感影像融合方法主要分为3种策略,即像素级融合、特征级融合和决策级融合[7 ] . 像素级融合针对多源影像本身进行处理,直接对影像中的像素进行融合. Wu等[8 ] 采用像素级融合策略,设计跨模态交互并行转换模块,实现长距离多源交互,生成更全面的融合特征. Feng等[9 ] 采用高通滤波法,根据不同波段的物理特性,实现多源遥感数据的融合. 决策级融合从深层语义的角度出发,对特征的高维度信息进行融合. 曹琼等[10 ] 利用点云数据提取掩膜进行建筑物分类,并将使用掩膜和未使用掩膜的分类结果进行决策级融合,达到平滑图像去除噪声点的目的. ...
高光谱-LiDAR多级融合城区地表覆盖分类
1
2019
... 根据融合数据形式的不同,多源遥感影像融合方法主要分为3种策略,即像素级融合、特征级融合和决策级融合[7 ] . 像素级融合针对多源影像本身进行处理,直接对影像中的像素进行融合. Wu等[8 ] 采用像素级融合策略,设计跨模态交互并行转换模块,实现长距离多源交互,生成更全面的融合特征. Feng等[9 ] 采用高通滤波法,根据不同波段的物理特性,实现多源遥感数据的融合. 决策级融合从深层语义的角度出发,对特征的高维度信息进行融合. 曹琼等[10 ] 利用点云数据提取掩膜进行建筑物分类,并将使用掩膜和未使用掩膜的分类结果进行决策级融合,达到平滑图像去除噪声点的目的. ...
高光谱-LiDAR多级融合城区地表覆盖分类
1
2019
... 根据融合数据形式的不同,多源遥感影像融合方法主要分为3种策略,即像素级融合、特征级融合和决策级融合[7 ] . 像素级融合针对多源影像本身进行处理,直接对影像中的像素进行融合. Wu等[8 ] 采用像素级融合策略,设计跨模态交互并行转换模块,实现长距离多源交互,生成更全面的融合特征. Feng等[9 ] 采用高通滤波法,根据不同波段的物理特性,实现多源遥感数据的融合. 决策级融合从深层语义的角度出发,对特征的高维度信息进行融合. 曹琼等[10 ] 利用点云数据提取掩膜进行建筑物分类,并将使用掩膜和未使用掩膜的分类结果进行决策级融合,达到平滑图像去除噪声点的目的. ...
Asymmetric feature fusion network for hyperspectral and SAR image classification
1
2022
... 特征级融合对不同分支提取的多源特征进行融合,既保留了不同模态各自的信息,又能够获取更细致的地物特征. Li等[11 ] 采用特征级融合策略,设计不对称特征融合网络,利用多源特征的空间依赖性,提高细节的鉴别能力;Ye等[12 ] 设计了基于互补特征的SAR和光学影像融合方法,通过重建多源影像的视觉显著性特征图,实现最佳信息传递. Li等[13 ] 结合SAR和光学影像的特性,将两者转化为点位移参数,利用自注意力融合网络来描述多源影像的特征关系,实现端到端的匹配. 这些研究取得了良好的成果,但仍难以提取特征,并且没有针对多尺度互补信息捕获进行改进. ...
Optical and SAR image fusion based on complementary feature decomposition and visual saliency features
1
2024
... 特征级融合对不同分支提取的多源特征进行融合,既保留了不同模态各自的信息,又能够获取更细致的地物特征. Li等[11 ] 采用特征级融合策略,设计不对称特征融合网络,利用多源特征的空间依赖性,提高细节的鉴别能力;Ye等[12 ] 设计了基于互补特征的SAR和光学影像融合方法,通过重建多源影像的视觉显著性特征图,实现最佳信息传递. Li等[13 ] 结合SAR和光学影像的特性,将两者转化为点位移参数,利用自注意力融合网络来描述多源影像的特征关系,实现端到端的匹配. 这些研究取得了良好的成果,但仍难以提取特征,并且没有针对多尺度互补信息捕获进行改进. ...
Multimodal image fusion framework for end-to-end remote sensing image registration
1
2023
... 特征级融合对不同分支提取的多源特征进行融合,既保留了不同模态各自的信息,又能够获取更细致的地物特征. Li等[11 ] 采用特征级融合策略,设计不对称特征融合网络,利用多源特征的空间依赖性,提高细节的鉴别能力;Ye等[12 ] 设计了基于互补特征的SAR和光学影像融合方法,通过重建多源影像的视觉显著性特征图,实现最佳信息传递. Li等[13 ] 结合SAR和光学影像的特性,将两者转化为点位移参数,利用自注意力融合网络来描述多源影像的特征关系,实现端到端的匹配. 这些研究取得了良好的成果,但仍难以提取特征,并且没有针对多尺度互补信息捕获进行改进. ...
交通目标YOLO检测技术的研究进展
1
2025
... 遥感影像目标检测是遥感影像解译的重要研究方向,许多研究对最新算法进行改进,取得了显著成果. 董红召等[14 ] 总结目前基于YOLO系列算法的遥感影像目标检测用于城市交通的最新应用,将检测目标分为“人”、“车”和“路”3个类别,讨论了不同YOLO算法针对各类目标所进行的改进,并进行了总结与展望. 宋耀莲等[15 ] 为了解决当前目标检测算法对无人机影像小目标的错检漏检问题,设计了基于YOLOv5s的小目标检测算法,通过优化特征融合网络、改进损失函数和引入注意力机制的方式,提高了目标检测精度. 这些研究虽然在目标检测精度上有所提升,但没有结合多源影像进行特征提取,存在改进的空间. ...
交通目标YOLO检测技术的研究进展
1
2025
... 遥感影像目标检测是遥感影像解译的重要研究方向,许多研究对最新算法进行改进,取得了显著成果. 董红召等[14 ] 总结目前基于YOLO系列算法的遥感影像目标检测用于城市交通的最新应用,将检测目标分为“人”、“车”和“路”3个类别,讨论了不同YOLO算法针对各类目标所进行的改进,并进行了总结与展望. 宋耀莲等[15 ] 为了解决当前目标检测算法对无人机影像小目标的错检漏检问题,设计了基于YOLOv5s的小目标检测算法,通过优化特征融合网络、改进损失函数和引入注意力机制的方式,提高了目标检测精度. 这些研究虽然在目标检测精度上有所提升,但没有结合多源影像进行特征提取,存在改进的空间. ...
基于改进YOLOv5s的无人机小目标检测算法
2
2024
... 遥感影像目标检测是遥感影像解译的重要研究方向,许多研究对最新算法进行改进,取得了显著成果. 董红召等[14 ] 总结目前基于YOLO系列算法的遥感影像目标检测用于城市交通的最新应用,将检测目标分为“人”、“车”和“路”3个类别,讨论了不同YOLO算法针对各类目标所进行的改进,并进行了总结与展望. 宋耀莲等[15 ] 为了解决当前目标检测算法对无人机影像小目标的错检漏检问题,设计了基于YOLOv5s的小目标检测算法,通过优化特征融合网络、改进损失函数和引入注意力机制的方式,提高了目标检测精度. 这些研究虽然在目标检测精度上有所提升,但没有结合多源影像进行特征提取,存在改进的空间. ...
... 式中:${\boldsymbol{F}}^x_{{\mathrm{v+i}}{\mathrm{}}} $ x 层的融合特征图(x =3, 4, 5),φ fusion 为多源特征融合模块,λ f 表示卷积神经网络的相关参数. 在深度卷积网络中,浅层特征图感受野较小,具有较高的分辨率和丰富的细节信息,能够更好地捕捉小目标和复杂背景. 随着网络层数的增加,特征图感受野增大,分辨率降低,语义信息增多,细节信息减少,不再适合小目标的特征提取. 在多源遥感影像的特征提取中,细节信息的提取更为重要. 第1、2层特征图语义信息不足,会导致过多噪声被引入,影响融合效果;而第4、5层特征细节信息不足,只融合第4、5层的特征会导致检测效果较差. 因此,本研究选择从第3层开始进行融合. 根据文献[15 ]的研究,在若干卷积层之后进行融合的策略优于其他融合策略,文献[21 ]在此基础上进行实验,从5个卷积层的第3层开始进行多源融合,取得了良好的融合效果,因此将其作为默认设置,只对主干网络中的第3、4、5层进行融合. 当x =3, 4, 5时,采用GLAFF模块作为特征融合方法来取代基线模型所采用的NINfusion[21 ] 融合方法. ...
基于改进YOLOv5s的无人机小目标检测算法
2
2024
... 遥感影像目标检测是遥感影像解译的重要研究方向,许多研究对最新算法进行改进,取得了显著成果. 董红召等[14 ] 总结目前基于YOLO系列算法的遥感影像目标检测用于城市交通的最新应用,将检测目标分为“人”、“车”和“路”3个类别,讨论了不同YOLO算法针对各类目标所进行的改进,并进行了总结与展望. 宋耀莲等[15 ] 为了解决当前目标检测算法对无人机影像小目标的错检漏检问题,设计了基于YOLOv5s的小目标检测算法,通过优化特征融合网络、改进损失函数和引入注意力机制的方式,提高了目标检测精度. 这些研究虽然在目标检测精度上有所提升,但没有结合多源影像进行特征提取,存在改进的空间. ...
... 式中:${\boldsymbol{F}}^x_{{\mathrm{v+i}}{\mathrm{}}} $ x 层的融合特征图(x =3, 4, 5),φ fusion 为多源特征融合模块,λ f 表示卷积神经网络的相关参数. 在深度卷积网络中,浅层特征图感受野较小,具有较高的分辨率和丰富的细节信息,能够更好地捕捉小目标和复杂背景. 随着网络层数的增加,特征图感受野增大,分辨率降低,语义信息增多,细节信息减少,不再适合小目标的特征提取. 在多源遥感影像的特征提取中,细节信息的提取更为重要. 第1、2层特征图语义信息不足,会导致过多噪声被引入,影响融合效果;而第4、5层特征细节信息不足,只融合第4、5层的特征会导致检测效果较差. 因此,本研究选择从第3层开始进行融合. 根据文献[15 ]的研究,在若干卷积层之后进行融合的策略优于其他融合策略,文献[21 ]在此基础上进行实验,从5个卷积层的第3层开始进行多源融合,取得了良好的融合效果,因此将其作为默认设置,只对主干网络中的第3、4、5层进行融合. 当x =3, 4, 5时,采用GLAFF模块作为特征融合方法来取代基线模型所采用的NINfusion[21 ] 融合方法. ...
SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery
4
2023
... 近年来,大量研究设计了多源遥感影像融合与目标检测一体化网络,取得了较好的目标检测结果. Zhang等[16 ] 提出快速的多源遥感融合影像目标检测方法,利用辅助超分辨率学习进行多尺度目标检测,兼顾了目标检测精度和计算成本. Li等[17 ] 针对小目标检测精度不佳和遥感影像噪声过大的问题,设计改进的YOLOv5目标检测框架,将可见光与红外影像融合,获取更高的目标检测精度. 这些研究为多源遥感影像的目标检测奠定了基础,但对特征提取模块缺乏改进,并且没有充分考虑到多尺度特征对多源数据的影响. ...
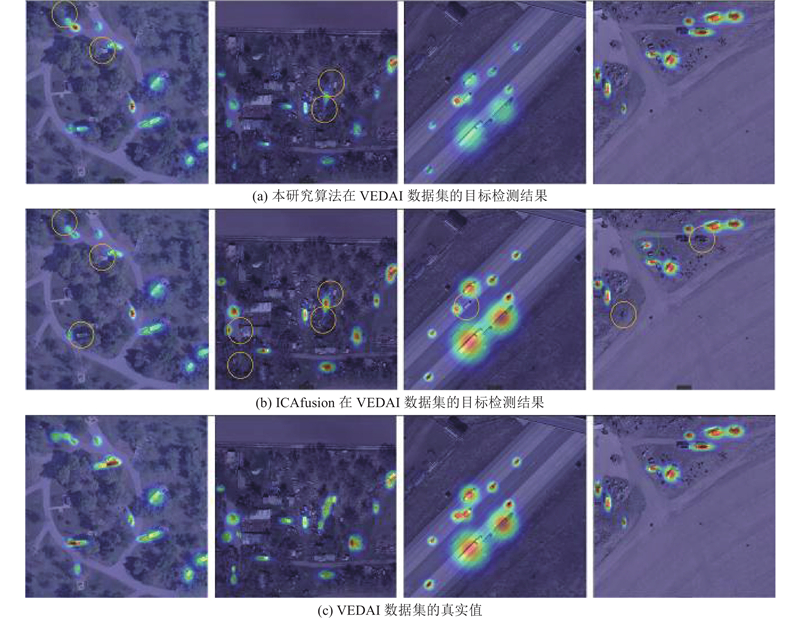
... 为了验证本研究算法的优越性,将其与目前主流的和较为先进的多源遥感融合影像目标检测算法在VEDAI数据集上进行对比,这些算法包括YOLOrs[26 ] 、YOLOfusion[27 ] 、SuperYOLO[16 ] 、MF-YOLO[17 ] 和本研究的基线算法ICAfusion[21 ] ,结果如表2 所示. 其中,GFLOPs为每秒浮点运算次数,Params为参数量,FPS为每秒帧数. 可以看出,本研究算法的平均目标检测精度比基线算法ICAfusion的平均目标检测精度高出2.00个百分点,同时高于其他先进算法. 然而,本研究算法虽然精度高于其他先进算法,但浮点数、参数量、推理速度均落后于其他先进算法,这是由于本研究算法引入了较为复杂的特征提取和特征融合模块,增加了参数量和浮点数,从而使得推理速度降低. ...
... Comparison of object detection results between proposed algorithm and state of arts on VEDAI dataset
Tab.2 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz YOLOrs[26 ] 58.97 46.4 20.2 23.9 YOLOfusion[27 ] 78.60 27.3 12.5 18.2 SuperYOLO[16 ] 79.49 4.8 16.6 12.7 MF-YOLO[17 ] 76.62 — — — ICAfusion[21 ] 80.80 58.2 120.2 28.4 本研究算法 82.80 60.7 139.3 30.2
如表3 所示为本研究算法在VEDAI数据集上与其他主流算法的目标检测精度对比. 可以看出,本研究算法对cars、pickup、camping、truck、tractor和其他交通工具类别的目标检测精度均高于其他方法,然而,对truck类别的目标检测精度略低于基线模型的,对boat和van类别的目标检测精度较差,只达到了59.43%和32.04%. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on VEDAI dataset
Tab.3 类别 AP50 /% cars pickup camping truck tractor boat van 其他 YOLOrs[26 ] 83.48 76.96 65.69 53.51 69.07 22.28 56.88 43.88 YOLOfusion[27 ] 91.72 85.91 78.94 78.15 71.96 71.14 75.23 54.77 SuperYOLO[16 ] 91.61 86.80 79.25 89.33 86.39 54.26 81.51 68.79 MF-YOLO[17 ] 92.03 86.61 78.19 72.58 82.88 64.64 78.66 57.36 ICAfusion[21 ] 97.05 96.21 89.64 92.66 94.50 64.53 28.33 83.40 本研究算法 97.31 96.82 93.21 87.03 98.17 59.43 32.04 88.25
为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
4
... 近年来,大量研究设计了多源遥感影像融合与目标检测一体化网络,取得了较好的目标检测结果. Zhang等[16 ] 提出快速的多源遥感融合影像目标检测方法,利用辅助超分辨率学习进行多尺度目标检测,兼顾了目标检测精度和计算成本. Li等[17 ] 针对小目标检测精度不佳和遥感影像噪声过大的问题,设计改进的YOLOv5目标检测框架,将可见光与红外影像融合,获取更高的目标检测精度. 这些研究为多源遥感影像的目标检测奠定了基础,但对特征提取模块缺乏改进,并且没有充分考虑到多尺度特征对多源数据的影响. ...
... 为了验证本研究算法的优越性,将其与目前主流的和较为先进的多源遥感融合影像目标检测算法在VEDAI数据集上进行对比,这些算法包括YOLOrs[26 ] 、YOLOfusion[27 ] 、SuperYOLO[16 ] 、MF-YOLO[17 ] 和本研究的基线算法ICAfusion[21 ] ,结果如表2 所示. 其中,GFLOPs为每秒浮点运算次数,Params为参数量,FPS为每秒帧数. 可以看出,本研究算法的平均目标检测精度比基线算法ICAfusion的平均目标检测精度高出2.00个百分点,同时高于其他先进算法. 然而,本研究算法虽然精度高于其他先进算法,但浮点数、参数量、推理速度均落后于其他先进算法,这是由于本研究算法引入了较为复杂的特征提取和特征融合模块,增加了参数量和浮点数,从而使得推理速度降低. ...
... Comparison of object detection results between proposed algorithm and state of arts on VEDAI dataset
Tab.2 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz YOLOrs[26 ] 58.97 46.4 20.2 23.9 YOLOfusion[27 ] 78.60 27.3 12.5 18.2 SuperYOLO[16 ] 79.49 4.8 16.6 12.7 MF-YOLO[17 ] 76.62 — — — ICAfusion[21 ] 80.80 58.2 120.2 28.4 本研究算法 82.80 60.7 139.3 30.2
如表3 所示为本研究算法在VEDAI数据集上与其他主流算法的目标检测精度对比. 可以看出,本研究算法对cars、pickup、camping、truck、tractor和其他交通工具类别的目标检测精度均高于其他方法,然而,对truck类别的目标检测精度略低于基线模型的,对boat和van类别的目标检测精度较差,只达到了59.43%和32.04%. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on VEDAI dataset
Tab.3 类别 AP50 /% cars pickup camping truck tractor boat van 其他 YOLOrs[26 ] 83.48 76.96 65.69 53.51 69.07 22.28 56.88 43.88 YOLOfusion[27 ] 91.72 85.91 78.94 78.15 71.96 71.14 75.23 54.77 SuperYOLO[16 ] 91.61 86.80 79.25 89.33 86.39 54.26 81.51 68.79 MF-YOLO[17 ] 92.03 86.61 78.19 72.58 82.88 64.64 78.66 57.36 ICAfusion[21 ] 97.05 96.21 89.64 92.66 94.50 64.53 28.33 83.40 本研究算法 97.31 96.82 93.21 87.03 98.17 59.43 32.04 88.25
为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
1
... 针对这些问题,本研究设计了采用改进深度可分离卷积的多源融合遥感影像目标检测方法,采用特征级融合策略,即先分别提取单源特征再进行特征融合,以YOLOv5[18 ] 为基础,结合自主设计的特征提取和特征级融合模块,实现多源遥感影像目标检测. 主要创新点和贡献如下:1)针对如何有效提取遥感影像特征的问题,受文献[19 ]的启发,设计双分支可分离卷积模块(dual branch separable convolution module, DBSConv). 该模块与卷积相结合,旨在通过深度卷积和残差连接提取更深层次的特征信息,从而增强卷积的特征提取能力. 2)针对如何充分利用多源数据的优势,实现信息互补的问题,受文献[20 ]的启发,设计全局-局部自适应特征融合模块(global-local adaptive feature fusion module, GLAFF). 有别于传统的张量拼接,GLAFF模块采用新的空间特征处理和融合方法,旨在通过分离式卷积将特征图进行拆分处理,分别提取全局和局部的细粒度特征以及捕捉不同区域的变化信息,并融合各自的互补信息. ...
3
... 针对这些问题,本研究设计了采用改进深度可分离卷积的多源融合遥感影像目标检测方法,采用特征级融合策略,即先分别提取单源特征再进行特征融合,以YOLOv5[18 ] 为基础,结合自主设计的特征提取和特征级融合模块,实现多源遥感影像目标检测. 主要创新点和贡献如下:1)针对如何有效提取遥感影像特征的问题,受文献[19 ]的启发,设计双分支可分离卷积模块(dual branch separable convolution module, DBSConv). 该模块与卷积相结合,旨在通过深度卷积和残差连接提取更深层次的特征信息,从而增强卷积的特征提取能力. 2)针对如何充分利用多源数据的优势,实现信息互补的问题,受文献[20 ]的启发,设计全局-局部自适应特征融合模块(global-local adaptive feature fusion module, GLAFF). 有别于传统的张量拼接,GLAFF模块采用新的空间特征处理和融合方法,旨在通过分离式卷积将特征图进行拆分处理,分别提取全局和局部的细粒度特征以及捕捉不同区域的变化信息,并融合各自的互补信息. ...
... 受文献[19 ]的启发,改进深度可分离卷积,采用双分支策略,分别获取特征图后进行分离、深度卷积和特征卷积的方法,最后再进行一次特征提取,将双分支卷积层与特征提取卷积层相结合以替代卷积下采样. 如图2 所示为双分支可分离卷积模块的结构,主要包括3个部分:深度卷积层(depthwise convolution,DWConv)、特征提取层(feature extraction,FE)和特征卷积(feature convolution,FC). 深度卷积层通过分组卷积减少计算量,特征提取层通过扩展因子增强特征表达能力,特征卷积通过特征交互增强特征表达能力. 在运行机制上,DBSConv模块通过深度卷积和残差连接,能够捕获更深层次的特征信息,与传统的卷积下采样方法相比,能够更好地处理细粒度遥感影像信息,增强特征提取能力. ...
... 2次深度卷积都没有进行激活函数计算,这是因为在使用ReLU和GELU这样常用的激活函数时会有均值偏移之类的缺点,而去除激活函数后,精度几乎没有受到影响[19 ] . ...
2
... 针对这些问题,本研究设计了采用改进深度可分离卷积的多源融合遥感影像目标检测方法,采用特征级融合策略,即先分别提取单源特征再进行特征融合,以YOLOv5[18 ] 为基础,结合自主设计的特征提取和特征级融合模块,实现多源遥感影像目标检测. 主要创新点和贡献如下:1)针对如何有效提取遥感影像特征的问题,受文献[19 ]的启发,设计双分支可分离卷积模块(dual branch separable convolution module, DBSConv). 该模块与卷积相结合,旨在通过深度卷积和残差连接提取更深层次的特征信息,从而增强卷积的特征提取能力. 2)针对如何充分利用多源数据的优势,实现信息互补的问题,受文献[20 ]的启发,设计全局-局部自适应特征融合模块(global-local adaptive feature fusion module, GLAFF). 有别于传统的张量拼接,GLAFF模块采用新的空间特征处理和融合方法,旨在通过分离式卷积将特征图进行拆分处理,分别提取全局和局部的细粒度特征以及捕捉不同区域的变化信息,并融合各自的互补信息. ...
... 由于多源信息的互补性,融合更依赖多尺度信息来结合细粒度的全局和局部特征,然而,传统的基于特征图拼接的融合算法没有考虑到这一点. 此外,遥感影像的目标检测也需要丰富的局部信息作为支持. 因此,受文献[20 ]的启发,本研究设计了全局-局部自适应特征融合模块,其结构如图3 所示. 其中,+表示拼接运算,×表示卷积运算,G 表示GELU激活函数运算,var表示空间维度的方差运算,$ {{\mathbf{R}}^{W \times H \times C}} $
ICAFusion: iterative cross-attention guided feature fusion for multispectral object detection
10
2024
... 如图1 所示为所提方法的网络总体框架,所提方法建立在YOLOv5的基础框架之上,其中,骨干网络被拆分为双分支路线,分别处理输入的单源影像对. 主要分为3个部分:单源特征提取、多源特征融合和检测头. 为了保证检测结果对比的公平性,采用5层卷积的价格,与基准方法ICAfusion[21 ] 保持一致. 由于没有额外的超参数,模型具有较高的灵活性,可以被拆分并插入到其他的框架中. ...
... 式中:${\boldsymbol{F}}^x_{{\mathrm{v+i}}{\mathrm{}}} $ x 层的融合特征图(x =3, 4, 5),φ fusion 为多源特征融合模块,λ f 表示卷积神经网络的相关参数. 在深度卷积网络中,浅层特征图感受野较小,具有较高的分辨率和丰富的细节信息,能够更好地捕捉小目标和复杂背景. 随着网络层数的增加,特征图感受野增大,分辨率降低,语义信息增多,细节信息减少,不再适合小目标的特征提取. 在多源遥感影像的特征提取中,细节信息的提取更为重要. 第1、2层特征图语义信息不足,会导致过多噪声被引入,影响融合效果;而第4、5层特征细节信息不足,只融合第4、5层的特征会导致检测效果较差. 因此,本研究选择从第3层开始进行融合. 根据文献[15 ]的研究,在若干卷积层之后进行融合的策略优于其他融合策略,文献[21 ]在此基础上进行实验,从5个卷积层的第3层开始进行多源融合,取得了良好的融合效果,因此将其作为默认设置,只对主干网络中的第3、4、5层进行融合. 当x =3, 4, 5时,采用GLAFF模块作为特征融合方法来取代基线模型所采用的NINfusion[21 ] 融合方法. ...
... [21 ]融合方法. ...
... 为了验证本研究算法的优越性,将其与目前主流的和较为先进的多源遥感融合影像目标检测算法在VEDAI数据集上进行对比,这些算法包括YOLOrs[26 ] 、YOLOfusion[27 ] 、SuperYOLO[16 ] 、MF-YOLO[17 ] 和本研究的基线算法ICAfusion[21 ] ,结果如表2 所示. 其中,GFLOPs为每秒浮点运算次数,Params为参数量,FPS为每秒帧数. 可以看出,本研究算法的平均目标检测精度比基线算法ICAfusion的平均目标检测精度高出2.00个百分点,同时高于其他先进算法. 然而,本研究算法虽然精度高于其他先进算法,但浮点数、参数量、推理速度均落后于其他先进算法,这是由于本研究算法引入了较为复杂的特征提取和特征融合模块,增加了参数量和浮点数,从而使得推理速度降低. ...
... Comparison of object detection results between proposed algorithm and state of arts on VEDAI dataset
Tab.2 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz YOLOrs[26 ] 58.97 46.4 20.2 23.9 YOLOfusion[27 ] 78.60 27.3 12.5 18.2 SuperYOLO[16 ] 79.49 4.8 16.6 12.7 MF-YOLO[17 ] 76.62 — — — ICAfusion[21 ] 80.80 58.2 120.2 28.4 本研究算法 82.80 60.7 139.3 30.2
如表3 所示为本研究算法在VEDAI数据集上与其他主流算法的目标检测精度对比. 可以看出,本研究算法对cars、pickup、camping、truck、tractor和其他交通工具类别的目标检测精度均高于其他方法,然而,对truck类别的目标检测精度略低于基线模型的,对boat和van类别的目标检测精度较差,只达到了59.43%和32.04%. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on VEDAI dataset
Tab.3 类别 AP50 /% cars pickup camping truck tractor boat van 其他 YOLOrs[26 ] 83.48 76.96 65.69 53.51 69.07 22.28 56.88 43.88 YOLOfusion[27 ] 91.72 85.91 78.94 78.15 71.96 71.14 75.23 54.77 SuperYOLO[16 ] 91.61 86.80 79.25 89.33 86.39 54.26 81.51 68.79 MF-YOLO[17 ] 92.03 86.61 78.19 72.58 82.88 64.64 78.66 57.36 ICAfusion[21 ] 97.05 96.21 89.64 92.66 94.50 64.53 28.33 83.40 本研究算法 97.31 96.82 93.21 87.03 98.17 59.43 32.04 88.25
为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... [21 ]. 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on FLIR dataset
Tab.4 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz MMTOD-UNIT[28 ] 61.50 — — — CFR[29 ] 72.40 — — — BU-LTT[30 ] 73.20 73.5 149.3 28.0 CFT[27 ] 78.30 224.4 206.0 32.3 ICAfusion[21 ] 79.20 58.2 120.2 27.7 本研究算法 80.16 60.7 139.3 27.9
表 5 本研究算法在KAIST数据集上与其他主流算法的目标检测精度对比 ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on KAIST dataset
Tab.5 类别 MR/% FPS/Hz MBNet[31 ] 8.40 14.3 MLPD[32 ] 7.58 — MSDS-RCNN[33 ] 8.23 4.6 ICAfusion[21 ] 7.17 38.9 本研究算法 7.14 34.3
2.4. 消融实验 2.4.1. DBSConv模块和GLAFF模块的影响 为了进一步验证本研究创新点是否对目标检测的精度产生了正面影响,在基线模型的基础上分别添加DBSConv模块和GLAFF模块在VEDAI数据集上进行实验,结果如表6 所示. ...
2
... 式中:$\boldsymbol{F}_{\mathrm{v}}^x $ x 层(x =1, 2, 3, 4, 5)的特征图; ϕ backbone 表示骨干网络,I v 、I i 为其参数,表示可见光影像和红外影像,λ v 表示卷积神经网络的相关参数. 引入具有良好稳定性的主干网络CSPDarknet[22 ] ,并采用由卷积下采样方法与新设计的特征提取方法所获取的特征图相结合的方式进行特征融合,当x =1, 2, 3, 4时,特征提取方法为卷积下采样模块;当x =5时,特征提取方法为提出的DBSConv模块,只在第5层采用DBSConv模块,从而达到训练精度与资源消耗的平衡. I i 之所以会成为可见光分支的参数之一,是因为采用的融合模块[22 ] 须利用2个分支的互补信息进行迭代. ...
... [22 ]须利用2个分支的互补信息进行迭代. ...
Vehicle detection in aerial imagery: a small target detection benchmark
1
2016
... 采用VEDAI数据集[23 ] 作为多源遥感影像数据来源,并利用FLIR数据集[24 ] 和KAIST数据集[25 ] 来验证本节算法的泛化性. ...
1
... 采用VEDAI数据集[23 ] 作为多源遥感影像数据来源,并利用FLIR数据集[24 ] 和KAIST数据集[25 ] 来验证本节算法的泛化性. ...
1
... 采用VEDAI数据集[23 ] 作为多源遥感影像数据来源,并利用FLIR数据集[24 ] 和KAIST数据集[25 ] 来验证本节算法的泛化性. ...
YOLOrs: object detection in multimodal remote sensing imagery
3
2020
... 为了验证本研究算法的优越性,将其与目前主流的和较为先进的多源遥感融合影像目标检测算法在VEDAI数据集上进行对比,这些算法包括YOLOrs[26 ] 、YOLOfusion[27 ] 、SuperYOLO[16 ] 、MF-YOLO[17 ] 和本研究的基线算法ICAfusion[21 ] ,结果如表2 所示. 其中,GFLOPs为每秒浮点运算次数,Params为参数量,FPS为每秒帧数. 可以看出,本研究算法的平均目标检测精度比基线算法ICAfusion的平均目标检测精度高出2.00个百分点,同时高于其他先进算法. 然而,本研究算法虽然精度高于其他先进算法,但浮点数、参数量、推理速度均落后于其他先进算法,这是由于本研究算法引入了较为复杂的特征提取和特征融合模块,增加了参数量和浮点数,从而使得推理速度降低. ...
... Comparison of object detection results between proposed algorithm and state of arts on VEDAI dataset
Tab.2 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz YOLOrs[26 ] 58.97 46.4 20.2 23.9 YOLOfusion[27 ] 78.60 27.3 12.5 18.2 SuperYOLO[16 ] 79.49 4.8 16.6 12.7 MF-YOLO[17 ] 76.62 — — — ICAfusion[21 ] 80.80 58.2 120.2 28.4 本研究算法 82.80 60.7 139.3 30.2
如表3 所示为本研究算法在VEDAI数据集上与其他主流算法的目标检测精度对比. 可以看出,本研究算法对cars、pickup、camping、truck、tractor和其他交通工具类别的目标检测精度均高于其他方法,然而,对truck类别的目标检测精度略低于基线模型的,对boat和van类别的目标检测精度较差,只达到了59.43%和32.04%. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on VEDAI dataset
Tab.3 类别 AP50 /% cars pickup camping truck tractor boat van 其他 YOLOrs[26 ] 83.48 76.96 65.69 53.51 69.07 22.28 56.88 43.88 YOLOfusion[27 ] 91.72 85.91 78.94 78.15 71.96 71.14 75.23 54.77 SuperYOLO[16 ] 91.61 86.80 79.25 89.33 86.39 54.26 81.51 68.79 MF-YOLO[17 ] 92.03 86.61 78.19 72.58 82.88 64.64 78.66 57.36 ICAfusion[21 ] 97.05 96.21 89.64 92.66 94.50 64.53 28.33 83.40 本研究算法 97.31 96.82 93.21 87.03 98.17 59.43 32.04 88.25
为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery
5
2022
... 为了验证本研究算法的优越性,将其与目前主流的和较为先进的多源遥感融合影像目标检测算法在VEDAI数据集上进行对比,这些算法包括YOLOrs[26 ] 、YOLOfusion[27 ] 、SuperYOLO[16 ] 、MF-YOLO[17 ] 和本研究的基线算法ICAfusion[21 ] ,结果如表2 所示. 其中,GFLOPs为每秒浮点运算次数,Params为参数量,FPS为每秒帧数. 可以看出,本研究算法的平均目标检测精度比基线算法ICAfusion的平均目标检测精度高出2.00个百分点,同时高于其他先进算法. 然而,本研究算法虽然精度高于其他先进算法,但浮点数、参数量、推理速度均落后于其他先进算法,这是由于本研究算法引入了较为复杂的特征提取和特征融合模块,增加了参数量和浮点数,从而使得推理速度降低. ...
... Comparison of object detection results between proposed algorithm and state of arts on VEDAI dataset
Tab.2 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz YOLOrs[26 ] 58.97 46.4 20.2 23.9 YOLOfusion[27 ] 78.60 27.3 12.5 18.2 SuperYOLO[16 ] 79.49 4.8 16.6 12.7 MF-YOLO[17 ] 76.62 — — — ICAfusion[21 ] 80.80 58.2 120.2 28.4 本研究算法 82.80 60.7 139.3 30.2
如表3 所示为本研究算法在VEDAI数据集上与其他主流算法的目标检测精度对比. 可以看出,本研究算法对cars、pickup、camping、truck、tractor和其他交通工具类别的目标检测精度均高于其他方法,然而,对truck类别的目标检测精度略低于基线模型的,对boat和van类别的目标检测精度较差,只达到了59.43%和32.04%. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on VEDAI dataset
Tab.3 类别 AP50 /% cars pickup camping truck tractor boat van 其他 YOLOrs[26 ] 83.48 76.96 65.69 53.51 69.07 22.28 56.88 43.88 YOLOfusion[27 ] 91.72 85.91 78.94 78.15 71.96 71.14 75.23 54.77 SuperYOLO[16 ] 91.61 86.80 79.25 89.33 86.39 54.26 81.51 68.79 MF-YOLO[17 ] 92.03 86.61 78.19 72.58 82.88 64.64 78.66 57.36 ICAfusion[21 ] 97.05 96.21 89.64 92.66 94.50 64.53 28.33 83.40 本研究算法 97.31 96.82 93.21 87.03 98.17 59.43 32.04 88.25
为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on FLIR dataset
Tab.4 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz MMTOD-UNIT[28 ] 61.50 — — — CFR[29 ] 72.40 — — — BU-LTT[30 ] 73.20 73.5 149.3 28.0 CFT[27 ] 78.30 224.4 206.0 32.3 ICAfusion[21 ] 79.20 58.2 120.2 27.7 本研究算法 80.16 60.7 139.3 27.9
表 5 本研究算法在KAIST数据集上与其他主流算法的目标检测精度对比 ...
2
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on FLIR dataset
Tab.4 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz MMTOD-UNIT[28 ] 61.50 — — — CFR[29 ] 72.40 — — — BU-LTT[30 ] 73.20 73.5 149.3 28.0 CFT[27 ] 78.30 224.4 206.0 32.3 ICAfusion[21 ] 79.20 58.2 120.2 27.7 本研究算法 80.16 60.7 139.3 27.9
表 5 本研究算法在KAIST数据集上与其他主流算法的目标检测精度对比 ...
2
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on FLIR dataset
Tab.4 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz MMTOD-UNIT[28 ] 61.50 — — — CFR[29 ] 72.40 — — — BU-LTT[30 ] 73.20 73.5 149.3 28.0 CFT[27 ] 78.30 224.4 206.0 32.3 ICAfusion[21 ] 79.20 58.2 120.2 27.7 本研究算法 80.16 60.7 139.3 27.9
表 5 本研究算法在KAIST数据集上与其他主流算法的目标检测精度对比 ...
Bottom-up and layerwise domain adaptation for pedestrian detection in thermal images
2
2021
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on FLIR dataset
Tab.4 类别 mAP50 /% GFLOPs/106 Params/106 FPS/Hz MMTOD-UNIT[28 ] 61.50 — — — CFR[29 ] 72.40 — — — BU-LTT[30 ] 73.20 73.5 149.3 28.0 CFT[27 ] 78.30 224.4 206.0 32.3 ICAfusion[21 ] 79.20 58.2 120.2 27.7 本研究算法 80.16 60.7 139.3 27.9
表 5 本研究算法在KAIST数据集上与其他主流算法的目标检测精度对比 ...
2
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on KAIST dataset
Tab.5 类别 MR/% FPS/Hz MBNet[31 ] 8.40 14.3 MLPD[32 ] 7.58 — MSDS-RCNN[33 ] 8.23 4.6 ICAfusion[21 ] 7.17 38.9 本研究算法 7.14 34.3
2.4. 消融实验 2.4.1. DBSConv模块和GLAFF模块的影响 为了进一步验证本研究创新点是否对目标检测的精度产生了正面影响,在基线模型的基础上分别添加DBSConv模块和GLAFF模块在VEDAI数据集上进行实验,结果如表6 所示. ...
MLPD: multi-label pedestrian detector in multispectral domain
2
2021
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on KAIST dataset
Tab.5 类别 MR/% FPS/Hz MBNet[31 ] 8.40 14.3 MLPD[32 ] 7.58 — MSDS-RCNN[33 ] 8.23 4.6 ICAfusion[21 ] 7.17 38.9 本研究算法 7.14 34.3
2.4. 消融实验 2.4.1. DBSConv模块和GLAFF模块的影响 为了进一步验证本研究创新点是否对目标检测的精度产生了正面影响,在基线模型的基础上分别添加DBSConv模块和GLAFF模块在VEDAI数据集上进行实验,结果如表6 所示. ...
2
... 为了验证本研究算法的泛化性,采用FLIR和KAIST多源数据集进行训练和测试,并与同样采用该数据集的其他主流算法进行对比. FLIR数据集的实验结果如表4 所示,对比算法包括MMTOD-UNIT[28 ] 、CFR[29 ] 、BU-LTT[30 ] 、CFT[27 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的平均目标检测精度高于其他算法,但在浮点数、参数量、推理速度方面稍微落后于其他先进算法,这是由于本研究算法相较于其他先进算法计算复杂度有所提升. KAIST数据集的实验结果如表5 所示,对比算法包括MBNet[31 ] 、MLPD[32 ] 、MSDS-RCNN[33 ] 和本研究基线算法ICAfusion[21 ] . 可以看出,本研究算法的MR低于其他算法,而且在推理速度上只低于ICAfusion,高于其他先进算法,这是由于本研究算法在ICAfusion的基础上做了改进,增加了算力消耗. 综上实验结果,本研究算法在2个数据集上的目标检测结果良好,证明本研究方法具有较好的泛化性. ...
... Comparison of object detection accuracy between proposed algorithm and state of arts on KAIST dataset
Tab.5 类别 MR/% FPS/Hz MBNet[31 ] 8.40 14.3 MLPD[32 ] 7.58 — MSDS-RCNN[33 ] 8.23 4.6 ICAfusion[21 ] 7.17 38.9 本研究算法 7.14 34.3
2.4. 消融实验 2.4.1. DBSConv模块和GLAFF模块的影响 为了进一步验证本研究创新点是否对目标检测的精度产生了正面影响,在基线模型的基础上分别添加DBSConv模块和GLAFF模块在VEDAI数据集上进行实验,结果如表6 所示. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}