

现有的高光谱与激光雷达(HSI-LiDAR)分类方法在特征建模策略上主要可分为2类. 一类采用对称建模策略,即为不同模态构建结构对称或相似的深度网络,用以提取各自特征,典型方法包括ENDNet[4]和S2ENet[5]. 此类策略有助于在后续阶段实现模态间特征的自然协同与融合,然而由于未充分考虑模态之间的特性差异,容易导致冗余建模及信息特性与结构设计之间的不匹配,从而限制了模型性能的进一步提升. 另一类则采用非对称建模策略,针对信息主导模态(HSI)引入更复杂的结构设计,而对辅助模态(LiDAR)则采用轻量建模方法,如MFT[6]和HCTNet[7]. HSI具有丰富的光谱与空间信息,具备更强的特征表达能力;相比之下,LiDAR数据相对简单,主要提供高程与结构信息,对建模结构的需求较低. 非对称建模策略正是基于这类信息差异,通过为不同模态设计差异化的建模结构,有效缓解冗余建模问题,并缓和信息特性与结构设计间的冲突. 基于上述分析,本研究采用以HSI为主导的非对称建模策略,对高光谱与激光雷达数据进行联合建模与分类,以充分发挥各模态在信息表达上的优势互补.
在以HSI为主导的非对称建模方法中,融合卷积神经网络(convolutional neural network, CNN)与视觉transformer(vision transformer, ViT)的结构受到了广泛关注,并在多模态遥感分类任务中表现出良好的性能[8-9]. 这种结构融合得益于CNN在局部空间特征提取方面的优势,以及ViT在全局上下文建模方面的能力. 当前主流方法普遍采用CNN-ViT串联结构[10-11],先由CNN提取局部特征,再由ViT建模全局关系,使得全局建模能够在局部特征空间中展开. 然而,该结构在感知特定区域方面存在不足,缺乏对关键区域的关注能力. 因此,在以中心像素分类为目标的HSI-LiDAR联合分类任务中,CNN-ViT结构在实现中心区域的有效建模与感知上有所不足[12].
针对上述问题,本研究提出强调中心感知的非对称建模策略. 在HSI分支中,构建了ViT-CNN结构:在特征建模初期引入ViT,以融合全局上下文信息,不仅通过差异化的上下文编码增强了对中心区域的感知能力,也为后续CNN的特征学习提供了全局先验,丰富了特征表达空间. 在LiDAR分支中,采用轻量级卷积模块(simple convolution, SimpleConv),专注于高程与结构信息的提取. 该策略通过为2个模态设计差异化的特征提取结构,不仅提升了对各自建模需求的适配性,从而缓解了建模冗余与冲突问题;同时强化了高光谱分支的特征表达能力,增强了对中心区域的感知能力,从而有效提升了分类性能.
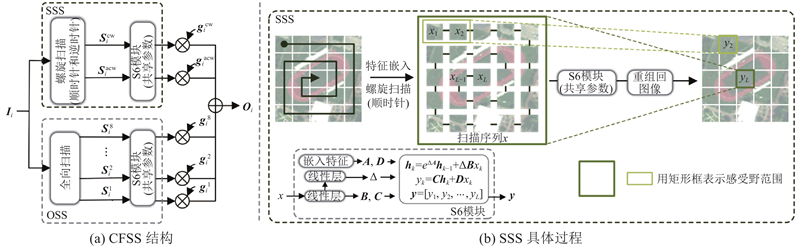
为了实现差异化上下文编码,在ViT的设计中引入中心聚焦Mamba模块(central-focus Mamba, CFMamba),其核心机制为中心聚焦选择性扫描机制(central-focus selective scan, CFSS),由全向扫描(omnidirectional selective scan, OSS)[13]与螺旋扫描(spiral selective scan, SSS)组成,兼顾全局感知能力与对中心区域的重点关注. 在此基础上,进一步提出基于CNN的空间-光谱细化模块(spatial-spectral refinement module, SSRM),通过多维度的细粒度优化,提升特征表达的质量与最终分类性能.
1. 方法论
1.1. 整体架构与分支模块
本研究构建了非对称双分支架构(见图1),分别对HSI与LiDAR图像进行建模,突出对不同模态的差异化特征提取策略. HSI作为语义主导模态,包含高维光谱信息与细粒度空间结构,是实现精确分类的核心依据;LiDAR主要提供结构与高程信息,作为辅助模态,用于补充场景特征. 因此,本研究针对2类模态设计了表达能力各异的特征提取模块.
图 1
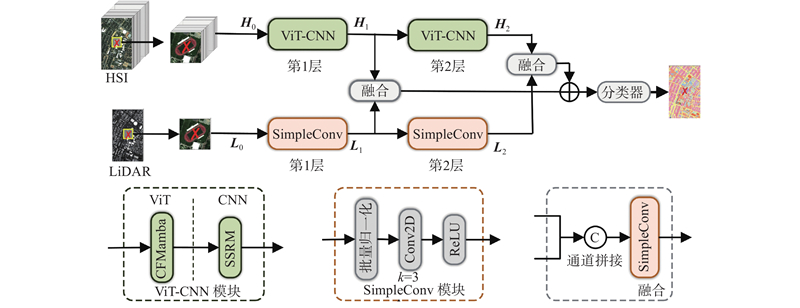
图 1 基于非对称结构的整体框架(高光谱模态采用ViT-CNN结构建模)
Fig.1 Overall framework based on asymmetric structure with hyperspectral modality modeled by ViT-CNN structure
考虑到CNN-ViT结构(见图2(a))在辨别性特征方面提取能力的不足,在HSI分支中,提出ViT-CNN结构(见图2(b)),首先由ViT建模全局语义,再由CNN细化局部细节. 该结构有助于在建模初期引入全局上下文信息,为后续的局部特征学习提供丰富的信息支撑,从而实现更具判别性的特征表达. 其中,ViT部分引入CFMamba模块,结合中心像素分类任务的特点,通过差异化的上下文建模增强对中心区域的表征能力,同时捕捉像素间的全局依赖关系,提升对复杂空间结构的感知能力;CNN部分则引入SSRM,从空间与光谱2个维度细化特征,增强对边缘与细节信息的感知能力. LiDAR分支采用SimpleConv结构,使用
图 2
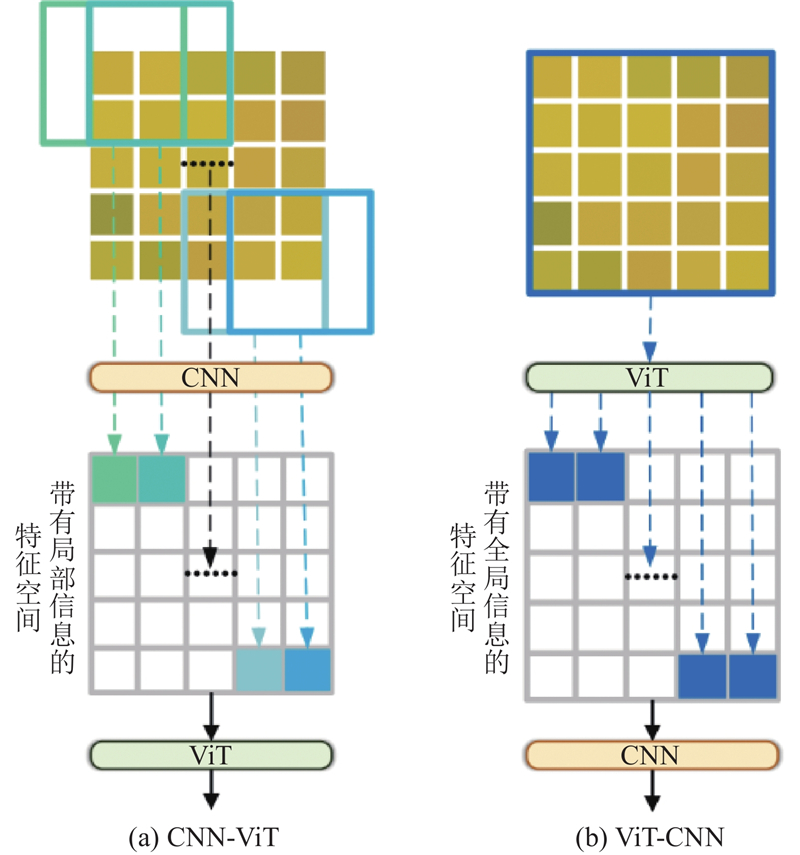
图 2 CNN-ViT结构与ViT-CNN结构对比
Fig.2 Comparison between CNN-ViT and ViT-CNN architectures
在多模态融合方面,采用多层通道拼接的方式对2类模态的特征进行对齐与融合[14],以充分整合来自HSI与LiDAR的数据信息,为最终分类提供更具判别性的联合特征表示.
1.2. CFMamba及其核心模块CFSS
图 3
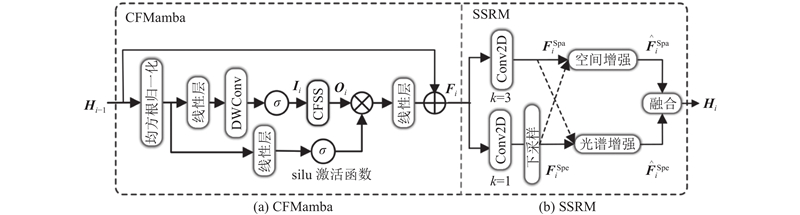
图 3 HSI分支(第i层)中ViT-CNN结构的具体实现
Fig.3 Detailed implementation of ViT-CNN in HSI branch of layer i
图 4
具体而言,对于第i层(i=1, 2)的输入图像块
式中:
1.3. SSRM
在空间分支中,采用
式中:
由于2分支在语义信息上的互补性,SSRM引入相互增强的融合策略融合空间与光谱特征. 为2分支引入不同的相互增强方式,具体增强融合过程可以表示为
式中:
2. 实验与分析
2.1. 数据集与实验设置介绍
表 1 实验数据集概览
Tab.1
| 数据集 | 图像尺寸 | HSI波段数 | 空间分辨率 |
| Houston2013 | 144 | 2.5 m | |
| Augsburg | 180 | 30 m | |
| MUUFL | 64 | 0.54 m |
实验在基于PyTorch的平台上进行,硬件为配备NVIDIA RTX A6 000 GPU的服务器. 训练使用AdamW优化器,初始学习率为
为了全面评估模型性能,分别从定量与定性2个层面与多种先进方法进行对比分析. 定量分析部分采用4种常用指标:每类精度、整体精度(OA)、平均精度(AA)以及Kappa 系数;定性分析部分则通过可视化全图预测结果,直观展示所提方法的分类表现. 为了节省篇幅并突出本研究方法的有效性,仅呈现3个数据集在OA、AA、Kappa指标上的定量实验结果,以及在Houston2013数据集上的定性可视化结果.
2.2. 实验结果分析
2.2.1. 对比方法介绍
为了全面验证所提方法的有效性,选取多种具有代表性的先进方法进行对比,涵盖对称与非对称结构,以及CNN、ViT和CNN-ViT这3类架构. 基于CNN的方法如下:1)ENDNet[4],采用编码器-解码器结构并引入重构损失以增强特征表达能力;2)S2ENet[14],在融合前分别强化HSI的空间特征与LiDAR的光谱信息;3)HybridSN[19],先通过三维卷积提取局部光谱-空间特征,再使用二维卷积以降低计算复杂度. 基于ViT的方法如下:1)SpectralFormer[20]通过通道嵌入构建ViT tokens,以建模光谱维度的全局依赖关系;2)MFT[6]将HSI映射为一系列tokens,将LiDAR作为class token引入非对称建模机制. 基于CNN-ViT的方法如下:1)S2EFT[5]在SpectralFormer的基础上引入空间注意力模块以提升空间建模能力;2)HCTNet[7]对HSI与LiDAR分别采用三维和二维卷积提取特征,随后通过ViT进一步建模;MHST[9]并行设置CNN与ViT分支,以融合多尺度的局部与全局特征. 其中,MFT、S2EFT和HCTNet采用非对称结构,其余方法均为对称建模策略.
2.2.2. 对比实验结果的定量与定性分析
在3个数据集上的定量实验结果(见表2)表明,本研究提出的方法对分类性能具有显著提升作用. 现有对比方法在不同空间分辨率与地物复杂度条件下表现差异较大,而本方法通过为HSI分支引入ViT模块增强语义建模、为LiDAR分支保留轻量CNN提取结构特征,既提升了主模态特征的判别能力,又充分利用了辅助模态的信息补充,从而在各数据集上均取得最优且稳定的结果. 另一方面,本研究提出的ViT-CNN方法显著优于对比方法. ViT在特征提取初期引入全局上下文,为后续CNN提供丰富的建模空间;SSRM模块进一步从空间与光谱维度细化特征,构建更全面、更鲁棒的多维表示. 在定性分析方面,如图5所示,本研究在空间连续性和边界刻画方面同样展示出明显的优势:不仅有效抑制了“椒盐”噪声,还能更准确地描绘地物边界,实现对复杂区域的精准感知.
表 2 3个数据集上不同方法的定量对比分析
Tab.2
| 模型结构 | 模型名称 | Houston2013 | MUUFL | Augsburg | ||||||||
| OA/% | AA/% | Kappa/% | OA/% | AA/% | Kappa/% | OA/% | AA/% | Kappa/% | ||||
| CNN | ENDNet | 88.05 | 87.86 | 87.07 | 80.75 | 80.33 | 75.24 | 65.83 | 54.14 | 55.14 | ||
| HybridSN | 86.22 | 87.40 | 85.17 | 62.46 | 58.36 | 54.25 | 58.73 | 53.85 | 46.63 | |||
| S2ENet | 94.59 | 95.40 | 94.16 | 79.23 | 79.72 | 73.57 | 74.75 | 66.20 | 66.14 | |||
| ViT | SpectralFormer | 69.33 | 70.66 | 66.89 | 76.34 | 76.12 | 69.94 | 39.76 | 53.09 | 28.94 | ||
| MFT | 92.31 | 93.42 | 91.70 | 73.04 | 73.46 | 66.53 | 71.54 | 65.81 | 62.61 | |||
| CNN-ViT | S2EFT | 86.94 | 86.30 | 85.82 | 79.19 | 75.13 | 73.07 | 62.57 | 57.19 | 49.63 | ||
| HCTNet | 94.72 | 95.68 | 94.30 | 74.52 | 73.42 | 67.93 | 73.94 | 66.64 | 65.29 | |||
| MHST | 94.22 | 95.18 | 93.75 | 76.85 | 77.25 | 70.71 | 66.54 | 66.55 | 56.95 | |||
| ViT-CNN | 本研究方法 | 97.60 | 97.97 | 97.41 | 83.95 | 84.83 | 79.47 | 75.47 | 67.97 | 67.18 | ||
图 5

图 5 Houston2013数据集上不同方法生成的分类图
Fig.5 Classification maps generated by different methods on Houston2013 dataset
2.3. 消融实验
在Houston2013数据集上开展消融实验,以验证所提出模块与方法的有效性.
2.3.1. 非对称策略和ViT-CNN结构
表 3 非对称策略消融实验
Tab.3
| HSI分支 | LiDAR分支 | OA/% | AA/% | Kappa/% |
| ViT-CNN | ViT-CNN | 96.56 | 97.19 | 96.29 |
| CNN | ViT-CNN | 95.85 | 96.64 | 95.51 |
| ViT-CNN | CNN | 97.60 | 97.97 | 97.41 |
表 4 HSI分支架构(ViT-CNN架构)消融实验
Tab.4
| HSI分支架构 | OA/% | AA/% | Kappa/% |
| 先CNN后ViT | 93.36 | 94.43 | 92.82 |
| CNN与ViT并行 | 95.75 | 96.44 | 95.41 |
| 先ViT后CNN | 97.60 | 97.97 | 97.41 |
2.3.2. CFMamba模块与SSRM
表 5 CFMamba与SSRM模块消融实验
Tab.5
| CFMamba | SSRM | OA/% | AA /% | Kappa /% | |
| 空间分支 | 光谱分支 | ||||
| × | √ | √ | 95.35 | 96.17 | 94.98 |
| √ | × | × | 94.51 | 95.41 | 94.08 |
| √ | √ | × | 97.02 | 97.56 | 96.78 |
| √ | × | √ | 96.09 | 96.78 | 95.78 |
| √ | √ | √ | 97.60 | 97.97 | 97.41 |
3. 结 语
针对HSI-LiDAR融合分类中模态差异显著的问题,提出基于非对称双分支结构的特征建模方法. HSI分支采用ViT-CNN结构,引入CFMamba模块实现全局建模与中心感知,结合SSRM模块进行空间-光谱细化;LiDAR分支采用轻量卷积结构SimpleConv,提取结构特征并保持尺度一致性. 实验证明,该方法在多个数据集上均取得优异且稳定的分类性能,消融实验进一步验证了各模块的有效性. 总体而言,本方法实现对多模态差异特征的精准建模与中心区域感知,能有效提升遥感图像分类性能,为解决HSI-LiDAR联合分类难题提供了一种有效的新思路. 不过,模型当前的复杂度仍有进一步优化的空间,后续将重点研究如何平衡性能与效率.
参考文献
BS2T: bottleneck spatial–spectral transformer for hyperspectral image classification
[J].
A center-masked transformer for hyperspectral image classification
[J].
RS-mamba for large remote sensing image dense prediction
[J].
S2ENet: spatial–spectral cross-modal enhancement network for classification of hyperspectral and LiDAR data
[J].
MS2CANet: multiscale spatial–spectral cross-modal attention network for hyperspectral image and LiDAR classification
[J].
HybridSN: exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification
[J].DOI:10.1109/LGRS.2019.2918719 [本文引用: 1]
SpectralFormer: rethinking hyperspectral image classification with transformers
[J].
More diverse means better: multimodal deep learning meets remote-sensing imagery classification
[J].DOI:10.1109/TGRS.2020.3016820 [本文引用: 1]
Attention-guided fusion and classification for hyperspectral and LiDAR data
[J].
Hyperspectral and LiDAR fusion using deep three-stream convolutional neural networks
[J].DOI:10.3390/rs10101649 [本文引用: 1]
Deep encoder-decoder networks for classification of hyperspectral and LiDAR data
[J].
S2EFT: spectral-spatial-elevation fusion transformer for hyperspectral image and LiDAR classification
[J].DOI:10.1016/j.knosys.2023.111190 [本文引用: 2]
Multimodal transformer network for hyperspectral and LiDAR classification
[J].
Joint classification of hyperspectral and LiDAR data using a hierarchical CNN and transformer
[J].
Deep hierarchical vision transformer for hyperspectral and LiDAR data classification
[J].DOI:10.1109/TIP.2022.3162964 [本文引用: 1]
MHST: multiscale head selection transformer for hyperspectral and LiDAR classification
[J].DOI:10.1109/JSTARS.2024.3366614 [本文引用: 2]
Convolution transformer mixer for hyperspectral image classification
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}