[1]
JAVED S, DANELLJAN M, KHAN F S, et al Visual object tracking with discriminative filters and Siamese networks: a survey and outlook
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (5 ): 6552 - 6574
[本文引用: 1]
[2]
孙训红, 都海波, 陈维乐, 等 基于移动机器人机载视觉云台的有限时间目标跟踪控制
[J]. 控制与决策 , 2023 , 38 (10 ): 2875 - 2880
[本文引用: 1]
SUN Xunhong, DU Haibo, CHEN Weile, et al Finite-time target tracking control based on mobile robot’s onboard PanTilt-Zoom camera system
[J]. Control and Decision , 2023 , 38 (10 ): 2875 - 2880
[本文引用: 1]
[3]
江佳鸿, 夏楠, 李长吾, 等 基于多尺度增量学习的单人体操动作中关键点检测方法
[J]. 电子学报 , 2024 , 52 (5 ): 1730 - 1742
[本文引用: 1]
JIANG Jiahong, XIA Nan, LI Changwu, et al Keypoint detection method for single person gymnastics actions based on multi-scale incremental learning
[J]. Acta Electronica Sinica , 2024 , 52 (5 ): 1730 - 1742
[本文引用: 1]
[4]
MARVASTI-ZADEH S M, CHENG L, GHANEI-YAKHDAN H, et al Deep learning for visual tracking: a comprehensive survey
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (5 ): 3943 - 3968
DOI:10.1109/TITS.2020.3046478
[本文引用: 1]
[5]
卢湖川, 李佩霞, 王栋 目标跟踪算法综述
[J]. 模式识别与人工智能 , 2018 , 31 (1 ): 61 - 76
[本文引用: 1]
LU Huchuan, LI Peixia, WANG Dong Visual object tracking: a survey
[J]. Pattern Recognition and Artificial Intelligence , 2018 , 31 (1 ): 61 - 76
[本文引用: 1]
[6]
DU S, WANG S An overview of correlation-filter-based object tracking
[J]. IEEE Transactions on Computational Social Systems , 2022 , 9 (1 ): 18 - 31
DOI:10.1109/TCSS.2021.3093298
[本文引用: 1]
[7]
张津浦, 王岳环 融合检测技术的孪生网络跟踪算法综述
[J]. 红外与激光工程 , 2022 , 51 (10 ): 1 - 14
[本文引用: 1]
ZHANG Jinpu, WANG Yuehuan A survey of Siamese networks tracking algorithm integrating detection technology
[J]. Infrared and Laser Engineering , 2022 , 51 (10 ): 1 - 14
[本文引用: 1]
[8]
LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8971–8980.
[本文引用: 2]
[9]
XU Y, WANG Z, LI Z, et al. SiamFC++: towards robust and accurate visual tracking with target estimation guidelines [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020: 12549–12556.
[本文引用: 2]
[10]
CHEN D, TANG F, DONG W, et al SiamCPN: visual tracking with the Siamese center-prediction network
[J]. Computational Visual Media , 2021 , 7 (2 ): 253 - 265
DOI:10.1007/s41095-021-0212-1
[本文引用: 1]
[11]
ZHANG L, GONZALEZ-GARCIA A, VAN DE WEIJER J, et al. Learning the model update for Siamese trackers [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 4009–4018.
[本文引用: 1]
[12]
SARIBAS H, CEVIKALP H, KÖPÜKLÜ O, et al TRAT: tracking by attention using spatio-temporal features
[J]. Neurocomputing , 2022 , 492 (1 ): 150 - 161
[本文引用: 1]
[13]
MAYER C, DANELLJAN M, PANI PAUDEL D, et al. Learning target candidate association to keep track of what not to track [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 13424–13434.
[本文引用: 2]
[14]
王蒙蒙, 杨小倩, 刘勇 利用时空特征编码的单目标跟踪网络
[J]. 中国图象图形学报 , 2022 , 27 (9 ): 2733 - 2748
DOI:10.11834/jig.211157
[本文引用: 2]
WANG Mengmeng, YANG Xiaoqian, LIU Yong A spatio-temporal encoded network for single object tracking
[J]. Journal of Image and Graphics , 2022 , 27 (9 ): 2733 - 2748
DOI:10.11834/jig.211157
[本文引用: 2]
[15]
HAN K, WANG Y, CHEN H, et al A survey on vision Transformer
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (1 ): 87 - 110
DOI:10.1109/TPAMI.2022.3152247
[本文引用: 1]
[16]
CHEN X, YAN B, ZHU J, et al. Transformer tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 8122–8131.
[本文引用: 2]
[17]
YAN B, PENG H, FU J, et al. Learning spatio-temporal Transformer for visual tracking [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10428–10437.
[本文引用: 2]
[18]
GAO S, ZHOU C, MA C, et al. AiATrack: attention in attention for Transformer visual tracking [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 146–164.
[本文引用: 2]
[19]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[20]
WANG N, ZHOU W, WANG J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 1571–1580.
[本文引用: 2]
[21]
LING L T, FAN H, ZHANG Z P, et al. SwinTrack: a simple and strong baseline for Transformer tracking [C]// Conference on Neural Information Processing Systems . New Orleans: [s. n.], 2022: 16743–16754.
[本文引用: 2]
[22]
侯志强, 杨晓麟, 马素刚, 等 基于特征增强和历史帧选择的Transformer视觉跟踪算法
[J]. 控制与决策 , 2024 , 39 (10 ): 3506 - 3512
[本文引用: 2]
HOU Zhiqiang, YANG Xiaolin, MA Sugang, et al Feature enhancement and history frame selection based Transformer visual tracking
[J]. Control and Decision , 2024 , 39 (10 ): 3506 - 3512
[本文引用: 2]
[23]
CUI Y, JIANG C, WU G, et al MixFormer: end-to-end tracking with iterative mixed attention
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2024 , 46 (6 ): 4129 - 4146
DOI:10.1109/TPAMI.2024.3349519
[本文引用: 2]
[24]
LIU C, ZHAO J, BO C, et al LGTrack: exploiting local and global properties for robust visual tracking
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2024 , 34 (9 ): 8161 - 8171
DOI:10.1109/TCSVT.2024.3390054
[本文引用: 2]
[25]
SHI L, ZHONG B, LIANG Q, et al. Explicit visual prompts for visual object tracking [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 4838–4846.
[本文引用: 2]
[26]
YE B, CHANG H, MA B, et al. Joint feature learning and relation modeling for tracking: a one-stream framework [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 341–357.
[本文引用: 2]
[27]
WANG Y, DENG L, ZHENG Y, et al Temporal convolutional network with soft thresholding and attention mechanism for machinery prognostics
[J]. Journal of Manufacturing Systems , 2021 , 60 (1 ): 512 - 526
[本文引用: 1]
[28]
FAN H, LIN L T, YANG F, et al. LaSOT: a high-quality benchmark for large-scale single object tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5369–5378.
[本文引用: 1]
[29]
HUANG L, ZHAO X, HUANG K GOT-10k: a large high-diversity benchmark for generic object tracking in the wild
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (5 ): 1562 - 1577
DOI:10.1109/TPAMI.2019.2957464
[本文引用: 1]
[30]
CUI Y, ZENG C, ZHAO X, et al. SportsMOT: a large multi-object tracking dataset in multiple sports scenes [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 9887–9897.
[本文引用: 1]
[31]
HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 15979–15988.
[本文引用: 1]
[32]
WU Y, LIM J, YANG M Object tracking benchmark
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1834 - 1848
DOI:10.1109/TPAMI.2014.2388226
[本文引用: 1]
Visual object tracking with discriminative filters and Siamese networks: a survey and outlook
1
2023
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
基于移动机器人机载视觉云台的有限时间目标跟踪控制
1
2023
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
基于移动机器人机载视觉云台的有限时间目标跟踪控制
1
2023
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
基于多尺度增量学习的单人体操动作中关键点检测方法
1
2024
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
基于多尺度增量学习的单人体操动作中关键点检测方法
1
2024
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
Deep learning for visual tracking: a comprehensive survey
1
2022
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
目标跟踪算法综述
1
2018
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
目标跟踪算法综述
1
2018
... 目标跟踪[1 ] 是指在视频序列的首帧确定目标跟踪对象后,持续对其位置和状态进行估计的过程,被广泛应用于视频分析、自动驾驶、交通监控以及行为检测等多种场景[2 -3 ] . 在复杂跟踪任务中,跟踪目标常表现出快速的尺度和方位变化,跟踪效果容易受到行为变化和背景干扰的影响. 因此,如何提升复杂场景中目标跟踪算法的鲁棒性和实时性仍然是亟待解决的难题[4 ] . 根据视觉跟踪原理的不同,单目标跟踪算法[5 ] 主要可以分为2类:基于相关滤波的跟踪算法和基于孪生架构的跟踪算法. ...
An overview of correlation-filter-based object tracking
1
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
融合检测技术的孪生网络跟踪算法综述
1
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
融合检测技术的孪生网络跟踪算法综述
1
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
2
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
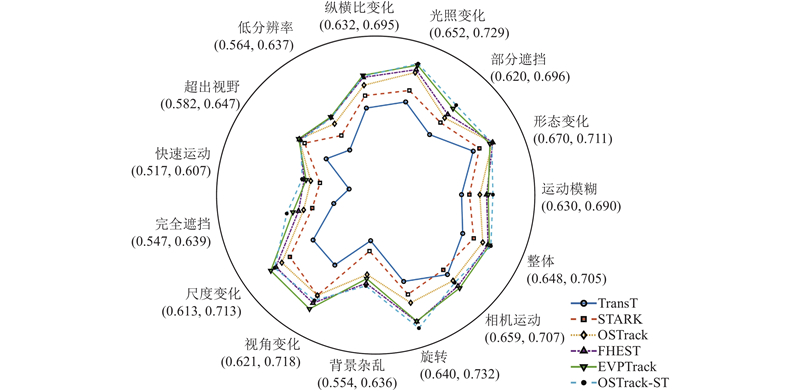
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
2
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
SiamCPN: visual tracking with the Siamese center-prediction network
1
2021
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
1
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
TRAT: tracking by attention using spatio-temporal features
1
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
2
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
利用时空特征编码的单目标跟踪网络
2
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
利用时空特征编码的单目标跟踪网络
2
2022
... 基于相关滤波的跟踪算法[6 ] 利用频域特征的相关性和持续更新策略优化跟踪模型,但容易因背景和特征变化的干扰而引入冗余信息,导致跟踪漂移问题频发. 基于孪生架构的跟踪算法[7 ] 持续对模板区域和搜索区域进行相似性特征匹配,以实现目标跟踪.孪生跟踪算法虽然兼具较高的精度和运行速度,但是依赖于模型的特征学习和匹配能力. 算法SiamRPN[8 ] 融合区域候选网络,有效缓解了目标状态变化带来的性能损失. 算法SiamFC++[9 ] 和SiamCPN[10 ] 利用高效的无锚框方法预测目标的边界框,显著提高了模型的跟踪效率. 同时期,其他模型开始关注于对时序信息[11 ] 的利用,完善模板更新机制[12 ] . KeepTrack[13 ] 融合外观特征和位置得分,利用图神经网络建立时空特征关联,评估模板更新效果. 算法TAN[14 ] 聚合时间编码和多帧模板特征信息,实现了有效的时空建模. 由于缺失模板区域和搜索区域之间有效的特征关联,且无法维持长时序的时空建模,该模型在复杂场景中难以维持长时间的鲁棒性. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
A survey on vision Transformer
1
2023
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
1
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
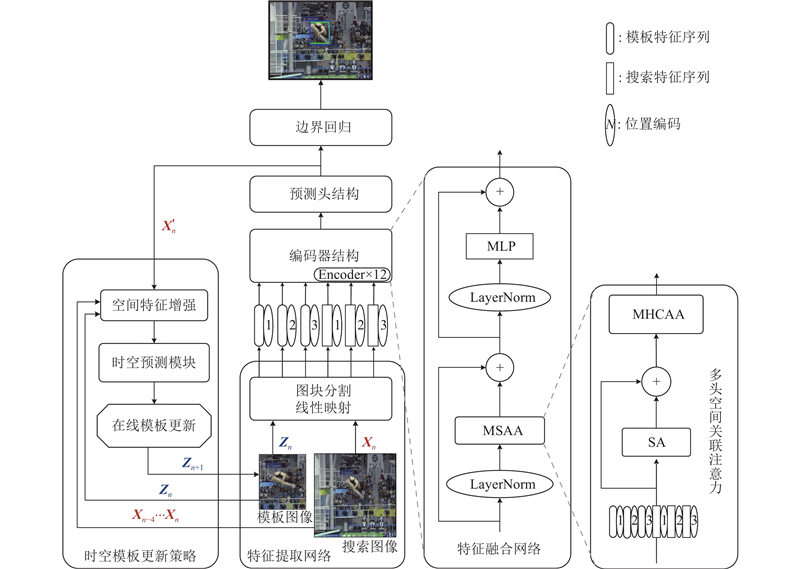
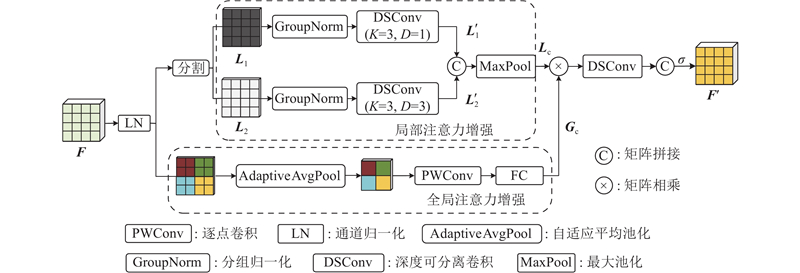
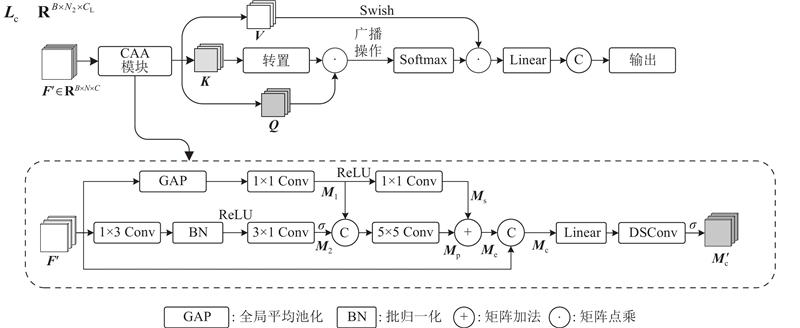
... 提出基于时空特征增强的单目标跟踪算法OSTrack-ST,算法框架如图1 所示. 整体网络结构包含基于ViT[20 ] 的特征提取网络、基于注意力机制的特征融合网络、预测头结构和时空模板更新策略4个部分,其中特征提取网络和预测头结构均与OSTrack保持一致. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
基于特征增强和历史帧选择的Transformer视觉跟踪算法
2
2024
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
基于特征增强和历史帧选择的Transformer视觉跟踪算法
2
2024
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
MixFormer: end-to-end tracking with iterative mixed attention
2
2024
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
LGTrack: exploiting local and global properties for robust visual tracking
2
2024
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
2
... Transformer[15 ] 模型利用高效的注意力机制,能够增强模型对判别性特征的表达能力. 基于孪生架构的Transformer跟踪模型起初专注于提升模板区域与搜索区域的特征关联,仅在特征融合过程中使用相关注意力机制. 算法TransT[16 ] 利用残差形式的交叉注意力机制,实现了相关特征的自适应捕获与建模. 算法STARK[17 ] 通过显式建模目标与跟踪区域之间的全局时空依赖关系,直接预测目标的空间位置. AiATrack[18 ] 增强残差相关性计算,有效抑制了模型对无关区域的关注. 然而,上述模型均受限于ResNet[19 ] 特征提取网络,难以充分利用空间和通道特征,跟踪精度的提升空间有限. 近年来,基于Vision Transformer[20 ] 的特征提取网络被广泛应用于跟踪模型. SwinTrack[21 ] 通过共享模板区域与搜索区域的权重,加强不同特征之间的交互. FEHST[22 ] 通过分层增强并融合深、浅层特征,显著增强对全局特征的利用. 在时序特征利用方面,算法MixFormer[23 ] 在相似度匹配过程中加入更新编码,通过预测模板分数来判断模板更新状态. LGTrack[24 ] 融合不同模板的特征编码,分析特征状态,提出自适应模板更新策略. 此外,利用目标运动轨迹特征,也能有效提升长时序跟踪精度. EVPTrack[25 ] 训练多帧时空编码器,利用反馈时空编码来实现目标运动建模,并进行长时序的时空建模. 由于依赖于时空同步更新机制,上述算法在训练难度上远超其他算法. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
2
... 算法OSTrack[26 ] 直接融合模板和搜索特征,省略了二者之间的关系建模,并采取静态模板更新策略,有效简化了特征学习和计算过程,提高了跟踪效率和推理速度.然而,在复杂场景中,宽泛性特征融合和静态模板更新策略容易将背景干扰信息引入目标特征,导致关键特征的丢失,且丢失特征难以恢复. ...
... Comparison of tracking results of different algorithms on LaSOT and GOT-10k test sets
Tab.1 算法 LaSOT GOT-10k AUC/% P norm /%P /%AO/% SR50 /% SR75 /% SiamRPN[8 ] 43.7 47.8 41.5 40.8 46.4 19.8 TAN[14 ] 47.4 53.5 45.3 — — — SiamFC++[9 ] 54.1 62.2 54.6 59.4 69.3 47.1 TransT[16 ] 64.8 73.7 69.0 66.9 76.7 60.8 STARK[17 ] 67.2 76.9 — 68.9 78.0 64.2 KeepTrack[13 ] 67.3 77.4 70.4 68.3 79.3 61.0 MixViT[23 ] 68.7 78.4 74.3 70.4 79.8 67.9 OSTrack[26 ] 69.0 78.6 75.1 70.9 80.2 68.2 SwinTrack[21 ] 69.2 78.3 74.0 69.4 78.0 64.3 AiATrack[18 ] 69.3 79.2 73.5 69.9 80.1 63.5 FEHST[22 ] 70.1 78.8 75.1 71.4 81.7 68.3 LGTrack[24 ] 70.2 80.4 76.4 72.4 82.3 69.6 EVPTrack[25 ] 70.4 80.6 77.4 73.3 83.6 70.7 OSTrack-ST 70.5 80.8 77.1 73.7 84.1 71.4
选取的先进算法包括各类基于深度学习的单目标跟踪算法,其中SiamRPN、SiamFC++和TAN是完全不使用Transformer架构的跟踪算法,在参数量和推理速度方面优于其他同类算法,但是在各项基准测试中均难以体现性能优势;KeepTrack、TransT、STARK、AiATrack、SwinTrack、FEHST和LGTrack均为优秀的双流双阶段跟踪算法,通过分别对搜索区域和模板区域进行特征提取和融合并建立特征关联来实现目标跟踪;MixViT、EVPTrack和OSTrack均为单流单阶段跟踪算法,通过直接对搜索区域和模板区域进行特征融合与提取,建立直接高效的特征关联,从而完成目标跟踪. ...
Temporal convolutional network with soft thresholding and attention mechanism for machinery prognostics
1
2021
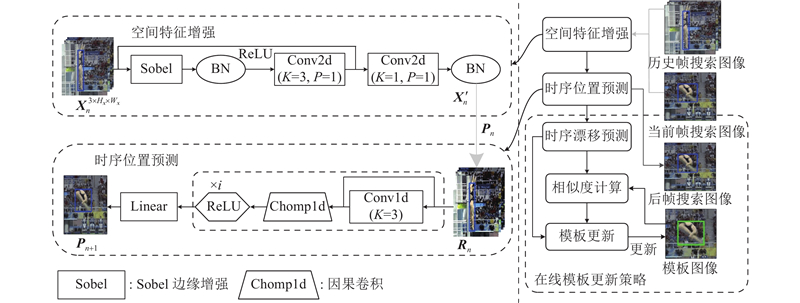
... 在跟踪目标短暂消失或周围相似目标数量较多的场景中,模型容易积累无关特征,干扰有效特征的判别,长久可能导致跟踪漂移现象. 针对因跟踪目标短暂消失而出现的跟踪漂移现象,提出基于时序漂移预测的时空模板更新策略. 通过时域卷积网络[27 ] 完成运动轨迹建模,预测时序上可能出现的漂移现象,并结合特征匹配的相似度,评估模板在当前时刻的更新状态.该策略的基本结构如图4 所示. ...
1
... 为了验证所提算法的有效性和泛化性,先进行消融实验和横向对比实验,然后分别在LaSOT[28 ] 、GOT-10k[29 ] 数据集和自建的快速运动数据集SportsSOT上,对OSTrack-ST与目前先进跟踪算法开展定性和定量分析实验. ...
GOT-10k: a large high-diversity benchmark for generic object tracking in the wild
1
2021
... 为了验证所提算法的有效性和泛化性,先进行消融实验和横向对比实验,然后分别在LaSOT[28 ] 、GOT-10k[29 ] 数据集和自建的快速运动数据集SportsSOT上,对OSTrack-ST与目前先进跟踪算法开展定性和定量分析实验. ...
1
... SportsSOT基于SportsMOT[30 ] 数据集制作,通过将MOT格式的多目标数据集转换为COCO格式的单目标跟踪数据集,并弱化标签信息以适应单目标跟踪任务. SportsSOT针对体育场景中的目标跟踪任务,选取了足球、篮球和排球3项体育项目,场景中包含大量特征相似的目标及其快速运动. 本研究对场景中每个球员进行了密集注释. SportsSOT由120个视频序列组成,平均帧数超过300帧,用于评估跟踪算法在快速变化的场景中的跟踪性能. SportsSOT参考LaSOT进行分类与标注,评价指标与LaSOT数据集一致,包含AUC、$ {{{P}}_{{\text{norm}}}} $ P ,但是难以对运动场景的属性进行定性分析,缺少对复杂场景的评估基准. ...
1
... 网络设置如下. 模板区域为128×128像素,搜索区域为256×256像素. 预测头的分类分支采用高斯权重的焦点损失,回归分支选择L 1损失和GIoU损失来计算总损失. 整个模型采用离线训练方式,将掩码自编码器MAE[31 ] 预训练后的ViT-base模型作为骨干网络. 训练数据集为LaSOT、GOT-10k、SportsSOT和OTB100[32 ] .使用水平翻转和亮度抖动方法增强数据. 训练总周期数为240,每个周期训练60 000对图像,批次大小为32. 优化器选择Adam-W,权值衰减为10−4 ,初始化学习率为10−5 ,在训练周期数达到200后学习率降低10倍. 在测试和验证方面,选择LaSOT、GOT-10k和SportsSOT数据集的测试集作为测试样本,使用汉明窗作为评判标准,即选择得分最高的预测框与边界框进行匹配,分析模型在多种场景下的鲁棒性.其他相关参数设置均参考OSTrack. ...
Object tracking benchmark
1
2015
... 网络设置如下. 模板区域为128×128像素,搜索区域为256×256像素. 预测头的分类分支采用高斯权重的焦点损失,回归分支选择L 1损失和GIoU损失来计算总损失. 整个模型采用离线训练方式,将掩码自编码器MAE[31 ] 预训练后的ViT-base模型作为骨干网络. 训练数据集为LaSOT、GOT-10k、SportsSOT和OTB100[32 ] .使用水平翻转和亮度抖动方法增强数据. 训练总周期数为240,每个周期训练60 000对图像,批次大小为32. 优化器选择Adam-W,权值衰减为10−4 ,初始化学习率为10−5 ,在训练周期数达到200后学习率降低10倍. 在测试和验证方面,选择LaSOT、GOT-10k和SportsSOT数据集的测试集作为测试样本,使用汉明窗作为评判标准,即选择得分最高的预测框与边界框进行匹配,分析模型在多种场景下的鲁棒性.其他相关参数设置均参考OSTrack. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}