[1]
王凌, 吴楚格, 范文慧, 等 边缘计算资源分配与任务调度优化综述
[J]. 系统仿真学报 , 2021 , 33 (3 ): 509 - 520
[本文引用: 1]
WANG Ling, WU Chuge, FAN Wenhui, et al A survey of edge computing resource allocation and task scheduling optimization
[J]. Journal of System Simulation , 2021 , 33 (3 ): 509 - 520
[本文引用: 1]
[2]
施巍松, 张星洲, 王一帆, 等 边缘计算: 现状与展望
[J]. 计算机研究与发展 , 2019 , 56 (1 ): 69 - 89
DOI:10.7544/issn1000-1239.2019.20180760
[本文引用: 1]
SHI Weisong, ZHANG Xingzhou, WANG Yifan, et al Edge computing: state-of-the-art and future directions
[J]. Journal of Computer Research and Development , 2019 , 56 (1 ): 69 - 89
DOI:10.7544/issn1000-1239.2019.20180760
[本文引用: 1]
[4]
ERMOLENKO D, KILICHEVA C, MUTHANNA A, et al. Internet of things services orchestration framework based on Kubernetes and edge computing [C]//IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering . Moscow: IEEE, 2021: 12-17.
ERMOLENKO D, KILICHEVA C, MUTHANNA A, et al. Internet of things services orchestration framework based on Kubernetes and edge computing [C]//IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering . Moscow: IEEE, 2021: 12-17.
[5]
VARGHESE B, WANG N, BARBHUIYA S, et al. Challenges and opportunities in edge computing [C]//IEEE International Conference on Smart Cloud . New York: IEEE, 2016: 20-26.
[本文引用: 1]
VARGHESE B, WANG N, BARBHUIYA S, et al. Challenges and opportunities in edge computing [C]//IEEE International Conference on Smart Cloud . New York: IEEE, 2016: 20-26.
[本文引用: 1]
[6]
SHI W, CAO J, ZHANG Q, et al Edge computing: vision and challenges
[J]. IEEE Internet of Things Journal , 2016 , 3 (5 ): 637 - 646
[本文引用: 1]
[7]
BHARDWAJ A, KRISHNA C R Virtualization in cloud computing: moving from hypervisor to containerization: a survey
[J]. Arabian Journal for Science and Engineering , 2021 , 46 (9 ): 8585 - 8601
[本文引用: 1]
[8]
QIU T, CHI J, ZHOU X, et al Edge computing in industrial internet of things: architecture, advances and challenges
[J]. IEEE Communications Surveys and Tutorials , 2020 , 22 (4 ): 2462 - 2488
[本文引用: 1]
[9]
NING H, LI Y, SHI F, et al Heterogeneous edge computing open platforms and tools for internet of things
[J]. Future Generation Computer Systems , 2020 , 106 : 67 - 76
[本文引用: 1]
[10]
SATYANARAYANAN M, BAHL P, CACERES R, et al The case for vm-based cloudlets in mobile computing
[J]. IEEE Pervasive Computing , 2009 , 8 (4 ): 14 - 23
[本文引用: 1]
[11]
ZHANG M, CAO J, YANG L, et al. Ents: an edge-native task scheduling system for collaborative edge computing [C]//IEEE/ACM 7th Symposium on Edge Computing . Seattle: IEEE, 2022: 149-161.
[本文引用: 1]
[12]
ZHANG M, CAO J, SAHNI Y, et al. Eaas: a service-oriented edge computing framework towards distributed intelligence [C]//IEEE International Conference on Service-Oriented System Engineering . Newark: IEEE, 2022: 165-175.
[本文引用: 1]
[13]
HAN R, WEN S, LIU C H, et al. EdgeTuner: fast scheduling algorithm tuning for dynamic edge-cloud workloads and resources [C]//IEEE Conference on Computer Communications . London: IEEE, 2022: 880-889.
[本文引用: 1]
[14]
SHAN C, GAO R, HAN Q, et al KCES: a workflow containerization scheduling scheme under cloud-edge collaboration framework
[J]. IEEE Internet of Things Journal , 2024 , 12 (2 ): 2026 - 2042
[本文引用: 1]
[15]
SAHNI Y, CAO J, YANG L Data-aware task allocation for achieving low latency in collaborative edge computing
[J]. IEEE Internet of Things Journal , 2018 , 6 (2 ): 3512 - 3524
[本文引用: 1]
[16]
SHAN C, WANG G, XIA Y, et al. Containerized workflow builder for Kubernetes [C]//IEEE 23rd International Conference on High Performance Computing and Communications; 7th International Conference on Data Science and Systems; 19th International Conference on Smart City; 7th International Conference on Dependability in Sensor, Cloud and Big Data Systems and Application . Haikou: IEEE, 2021: 685-692.
[本文引用: 1]
SHAN C, WANG G, XIA Y, et al. Containerized workflow builder for Kubernetes [C]//IEEE 23rd International Conference on High Performance Computing and Communications; 7th International Conference on Data Science and Systems; 19th International Conference on Smart City; 7th International Conference on Dependability in Sensor, Cloud and Big Data Systems and Application . Haikou: IEEE, 2021: 685-692.
[本文引用: 1]
[17]
SHAN C, XIA Y, ZHAN Y, et al KubeAdaptor: a docking framework for workflow containerization on Kubernetes
[J]. Future Generation Computer Systems , 2023 , 148 : 584 - 599
[本文引用: 1]
[18]
BADER J, THAMSEN L, KULAGINA S, et al. Tarema: adaptive resource allocation for scalable scientific workflows in heterogeneous clusters [C]//IEEE International Conference on Big Data . Orlando: IEEE, 2021: 65-75.
[本文引用: 1]
[19]
GAREFALAKIS P, KARANASOS K, PIETZUCH P, et al. Medea: scheduling of long running applications in shared production clusters [C]//European Conference on Computer Systems . New York: ACM, 2018: 1-13.
[本文引用: 1]
[20]
HAO Y, JIANG Y, CHEN T, et al iTaskOffloading: intelligent task offloading for a cloud-edge collaborative system
[J]. IEEE Network , 2019 , 33 (5 ): 82 - 88
[本文引用: 1]
[21]
GUO K, YANG M, ZHANG Y, et al Joint computation offloading and bandwidth assignment in cloud-assisted edge computing
[J]. IEEE Transactions on Cloud Computing , 2019 , 10 (1 ): 451 - 460
[本文引用: 1]
[22]
YANG L, YANG D, CAO J, et al QoS guaranteed resource allocation for live virtual machine migration in edge clouds
[J]. IEEE Access , 2020 , 8 : 78441 - 78451
[23]
TAN B, MA H, MEI Y, et al A cooperative coevolution genetic programming hyper-heuristics approach for on-line resource allocation in container-based clouds
[J]. IEEE Transactions on Cloud Computing , 2020 , 10 (3 ): 1500 - 1514
[本文引用: 1]
[24]
VERMA A, PEDROSA L, KORUPOLU M, et al. Large-scale cluster management at Google with Borg [C]//Proceedings of the 10th European Conference on Computer Systems . New York: ACM, 2015: 1-17.
[本文引用: 1]
[25]
XIONG Y, SUN Y, XING L, et al. Extend cloud to edge with Kubeedge [C]//IEEE/ACM Symposium on Edge Computing . Seattle: IEEE, 2018: 373-377.
[本文引用: 1]
XIONG Y, SUN Y, XING L, et al. Extend cloud to edge with Kubeedge [C]//IEEE/ACM Symposium on Edge Computing . Seattle: IEEE, 2018: 373-377.
[本文引用: 1]
[26]
DUPONT C, GIAFFREDA R, CAPRA L. Edge computing in IoT context: horizontal and vertical Linux container migration [C]//Global Internet of Things Summit . Geneva: IEEE, 2017: 1-4.
[本文引用: 1]
[27]
GOETHALS T, DE TURCK F, VOLCKAERT B. Fledge: Kubernetes compatible container orchestration on low-resource edge devices [C]//International Conference on Internet of Vehicles . Cham: Springer, 2019: 174-189.
[本文引用: 1]
[28]
LIU N, LI Z, XU J, et al. A hierarchical framework of cloud resource allocation and power management using deep reinforcement learning [C]//IEEE 37th International Conference on Distributed Computing Systems . Atlanta: IEEE, 2017: 372-382.
[本文引用: 1]
[29]
MAO H, ALIZADEH M, MENACHE I, et al. Resource management with deep reinforcement learning [C]//Proceedings of the 15th ACM Workshop on Hot Topics in Networks . New York: ACM, 2016: 50-56.
[本文引用: 1]
[30]
YI D, ZHOU X, WEN Y, et al Efficient compute-intensive job allocation in data centers via deep reinforcement learning
[J]. IEEE Transactions on Parallel and Distributed Systems , 2020 , 31 (6 ): 1474 - 1485
[本文引用: 1]
[31]
MAO H, SCHWARZKOPF M, VENKATAKRISHNAN S B, et al. Learning scheduling algorithms for data processing clusters [C]//Proceedings of the ACM Special Interest Group on Data Communication . New York: ACM, 2019: 270-288.
[本文引用: 1]
MAO H, SCHWARZKOPF M, VENKATAKRISHNAN S B, et al. Learning scheduling algorithms for data processing clusters [C]//Proceedings of the ACM Special Interest Group on Data Communication . New York: ACM, 2019: 270-288.
[本文引用: 1]
[32]
邝祝芳, 陈清林, 李林峰, 等 基于深度强化学习的多用户边缘计算任务卸载调度与资源分配算法
[J]. 计算机学报 , 2022 , 45 (4 ): 812 - 824
DOI:10.11897/SP.J.1016.2022.00812
[本文引用: 1]
KUANG Zhufang, CHEN Qinglin, LI Linfeng, et al Multi-user edge computing task offloading scheduling and resource allocation based on deep reinforcement learning
[J]. Chinese Journal of Computers , 2022 , 45 (4 ): 812 - 824
DOI:10.11897/SP.J.1016.2022.00812
[本文引用: 1]
[33]
周陈静, 骆淑云 基于深度强化学习的实时视频边缘卸载策略
[J]. 智能计算机与应用 , 2024 , 14 (8 ): 32 - 39
[本文引用: 1]
ZHOU Chenjing, LUO Shuyun Computation offloading decision in video edge computing based on deep reinforcement learning
[J]. Intelligent Computer and Applications , 2024 , 14 (8 ): 32 - 39
[本文引用: 1]
[34]
张斐斐, 葛季栋, 李忠金, 等 边缘计算中协作计算卸载与动态任务调度
[J]. 软件学报 , 2023 , 34 (12 ): 5737 - 5756
[本文引用: 1]
ZHANG Feifei, GE Jidong, LI Zhongjin, et al Cooperative computation offloading and dynamic task scheduling in edge computing
[J]. Journal of Software , 2023 , 34 (12 ): 5737 - 5756
[本文引用: 1]
[35]
ZHANG Q, ZHANG Q, SHI W, et al Firework: data processing and sharing for hybrid cloud-edge analytics
[J]. IEEE Transactions on Parallel and Distributed Systems , 2018 , 29 (9 ): 2004 - 2017
[本文引用: 1]
边缘计算资源分配与任务调度优化综述
1
2021
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
边缘计算资源分配与任务调度优化综述
1
2021
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
边缘计算: 现状与展望
1
2019
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
边缘计算: 现状与展望
1
2019
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
Edge computing: a survey
1
2019
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
1
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
1
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
Edge computing: vision and challenges
1
2016
... 物联网设备和应用的快速发展使得大量数据产生于终端设备. 基于传统的云计算模式,这些数据需要通过网络传输到云服务器进行处理,然后返回终端设备. 这种模式不仅消耗大量的网络资源,还增加了任务的延迟[1 -2 ] . 云边协同计算应运而生,它利用边缘节点和云服务器协同处理数据,将计算资源推近数据源,有效减少了数据传输时间,降低了任务延迟. 这种模式具有低延迟和高传输速率的优势,尤其适用于实时处理或大量数据传输的物联网应用[3 -5 ] . 采用边缘节点辅助云端处理任务,可以显著缩短响应时间并节约带宽[6 ] . 目前,边缘计算已广泛应用于视频处理,随着大语言模型的兴起,相关的语料处理任务值得关注. ...
Virtualization in cloud computing: moving from hypervisor to containerization: a survey
1
2021
... 尽管Kubernetes为代表的分布式计算管理框架已广泛采用容器化策略,有效解决了边缘环境的异构性问题[7 -8 ] ,但它们并没有对边缘计算环境进行优化. 边缘计算平台是边缘计算范式的关键组成部分[9 ] . 例如KubeEdge是基于Kubernetes为边缘计算场景定制的,并针对云边通信和协作进行了优化. KubeEdge虽然实现了简化设备通信、边缘自治、云边协同等功能,但未包含节点间网络带宽资源的管理,因此在网络资源受限的场景下表现不足. ...
Edge computing in industrial internet of things: architecture, advances and challenges
1
2020
... 尽管Kubernetes为代表的分布式计算管理框架已广泛采用容器化策略,有效解决了边缘环境的异构性问题[7 -8 ] ,但它们并没有对边缘计算环境进行优化. 边缘计算平台是边缘计算范式的关键组成部分[9 ] . 例如KubeEdge是基于Kubernetes为边缘计算场景定制的,并针对云边通信和协作进行了优化. KubeEdge虽然实现了简化设备通信、边缘自治、云边协同等功能,但未包含节点间网络带宽资源的管理,因此在网络资源受限的场景下表现不足. ...
Heterogeneous edge computing open platforms and tools for internet of things
1
2020
... 尽管Kubernetes为代表的分布式计算管理框架已广泛采用容器化策略,有效解决了边缘环境的异构性问题[7 -8 ] ,但它们并没有对边缘计算环境进行优化. 边缘计算平台是边缘计算范式的关键组成部分[9 ] . 例如KubeEdge是基于Kubernetes为边缘计算场景定制的,并针对云边通信和协作进行了优化. KubeEdge虽然实现了简化设备通信、边缘自治、云边协同等功能,但未包含节点间网络带宽资源的管理,因此在网络资源受限的场景下表现不足. ...
The case for vm-based cloudlets in mobile computing
1
2009
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
KCES: a workflow containerization scheduling scheme under cloud-edge collaboration framework
1
2024
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
Data-aware task allocation for achieving low latency in collaborative edge computing
1
2018
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
KubeAdaptor: a docking framework for workflow containerization on Kubernetes
1
2023
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
iTaskOffloading: intelligent task offloading for a cloud-edge collaborative system
1
2019
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
Joint computation offloading and bandwidth assignment in cloud-assisted edge computing
1
2019
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
QoS guaranteed resource allocation for live virtual machine migration in edge clouds
0
2020
A cooperative coevolution genetic programming hyper-heuristics approach for on-line resource allocation in container-based clouds
1
2020
... 研究者们提出多种调度算法,以应对不同场景. Cloudnet[10 ] 是部署于网络边缘的主机,旨在为移动设备提供低延迟计算资源. ENTS[11 ] 作为专为协作边缘计算设计的调度系统,通过纳入数据局部性与网络资源因素,提高了视频分析任务的吞吐量. EaaS[12 ] 是边缘计算框架,可以跨多个维度增强性能,并克服Kubernetes在边缘计算方面的局限性. EdgeTuner[13 ] 利用强化学习调度策略,加速模型收敛. KCES[14 ] 是为KubeEdge设计的云边协同工作流调度框架,提出任务水平漫游和垂直卸载算法. MSGA[15 ] 通过对数据源位置和网络资源建模,有效缩短了任务完成时间. CWB[16 ] 与KubeAdaptor[17 ] 均实现了工作流调度与Kubernetes实际调度顺序的一致性. Tarema[18 ] 通过实时监控硬件差异,动态分配资源. Medea [19 ] 针对长、短期容器采取不同的调度策略,降低了部署延迟,展现出弹性优势. iTaskOffloading[20 ] 是针对个性化、细粒度需求的调度算法. 此外,针对虚拟机调度,有大量的研究[21 -23 ] . ...
1
... Kubernetes 是类似于 Borg [24 ] 的集群管理平台,它启发了多种边缘计算解决方案,例如 KubeEdge[25 ] 、Cloud4IoT[26 ] 和 Fledge[27 ] . 这些解决方案主要解决边缘计算中的服务编排、资源管理和节点通信,但缺乏边缘计算场景下的任务调度和资源利用率的优化. ...
1
... Kubernetes 是类似于 Borg [24 ] 的集群管理平台,它启发了多种边缘计算解决方案,例如 KubeEdge[25 ] 、Cloud4IoT[26 ] 和 Fledge[27 ] . 这些解决方案主要解决边缘计算中的服务编排、资源管理和节点通信,但缺乏边缘计算场景下的任务调度和资源利用率的优化. ...
1
... Kubernetes 是类似于 Borg [24 ] 的集群管理平台,它启发了多种边缘计算解决方案,例如 KubeEdge[25 ] 、Cloud4IoT[26 ] 和 Fledge[27 ] . 这些解决方案主要解决边缘计算中的服务编排、资源管理和节点通信,但缺乏边缘计算场景下的任务调度和资源利用率的优化. ...
1
... Kubernetes 是类似于 Borg [24 ] 的集群管理平台,它启发了多种边缘计算解决方案,例如 KubeEdge[25 ] 、Cloud4IoT[26 ] 和 Fledge[27 ] . 这些解决方案主要解决边缘计算中的服务编排、资源管理和节点通信,但缺乏边缘计算场景下的任务调度和资源利用率的优化. ...
1
... Kubernetes 是类似于 Borg [24 ] 的集群管理平台,它启发了多种边缘计算解决方案,例如 KubeEdge[25 ] 、Cloud4IoT[26 ] 和 Fledge[27 ] . 这些解决方案主要解决边缘计算中的服务编排、资源管理和节点通信,但缺乏边缘计算场景下的任务调度和资源利用率的优化. ...
1
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
1
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
Efficient compute-intensive job allocation in data centers via deep reinforcement learning
1
2020
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
1
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
1
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
基于深度强化学习的多用户边缘计算任务卸载调度与资源分配算法
1
2022
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
基于深度强化学习的多用户边缘计算任务卸载调度与资源分配算法
1
2022
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
基于深度强化学习的实时视频边缘卸载策略
1
2024
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
基于深度强化学习的实时视频边缘卸载策略
1
2024
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
边缘计算中协作计算卸载与动态任务调度
1
2023
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
边缘计算中协作计算卸载与动态任务调度
1
2023
... 深度强化学习在资源调度研究中得到了广泛的应用. Liu等[28 ] 构建直接从经验中学习的调度决策模型. Mao等[29 ] 将强化学习应用于资源分配和电源管理. Yi等[30 ] 采用深度 Q 网络,降低集群功耗和 CPU 温度. Mao等[31 ] 利用强化学习和神经网络,针对不同任务采用不同的调度策略. 邝祝芳等[32 ] 在移动边缘计算场景中以最小化延迟和耗能为目标,提出面向多用户的任务调度算法. 周陈静[33 ] 使用深度强化学习对视频处理任务进行调度,加速了视频处理,降低了系统时延,为实时视频处理提供了解决方案. 张斐斐等[34 ] 使用深度Q学习算法和组合多臂赌博机的在线学习方法,设计边缘协作计算的任务调度算法,减少了系统的整体开销. ...
Firework: data processing and sharing for hybrid cloud-edge analytics
1
2018
... 云边协同场景中受限的计算与网络资源使得任务调度变得复杂[35 ] . 鉴于大语言模型在边缘计算领域的兴起,选取典型的视频与文本语料处理任务,验证提出的调度方法的有效性. ...


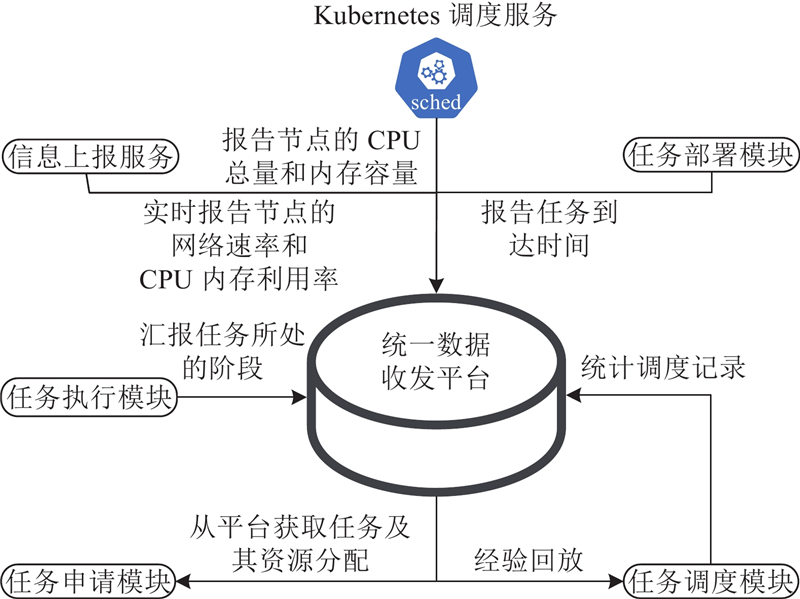
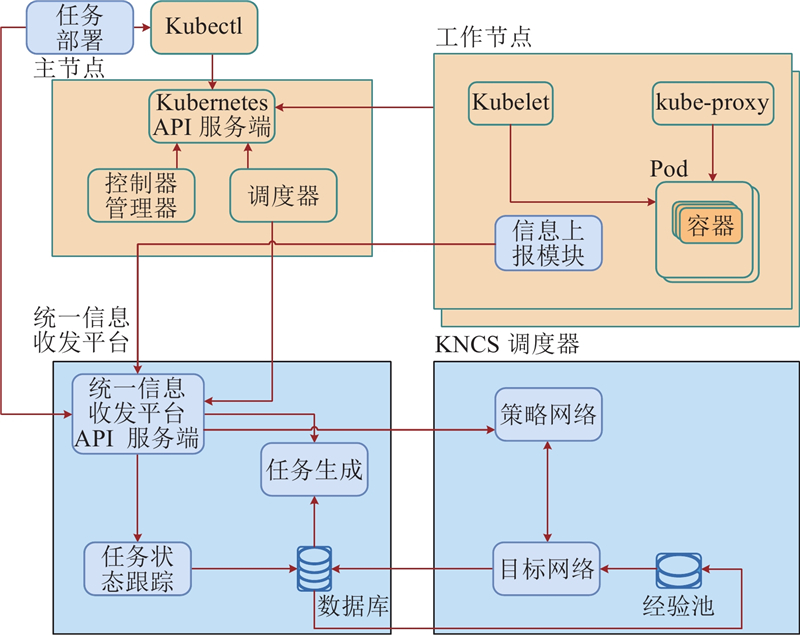
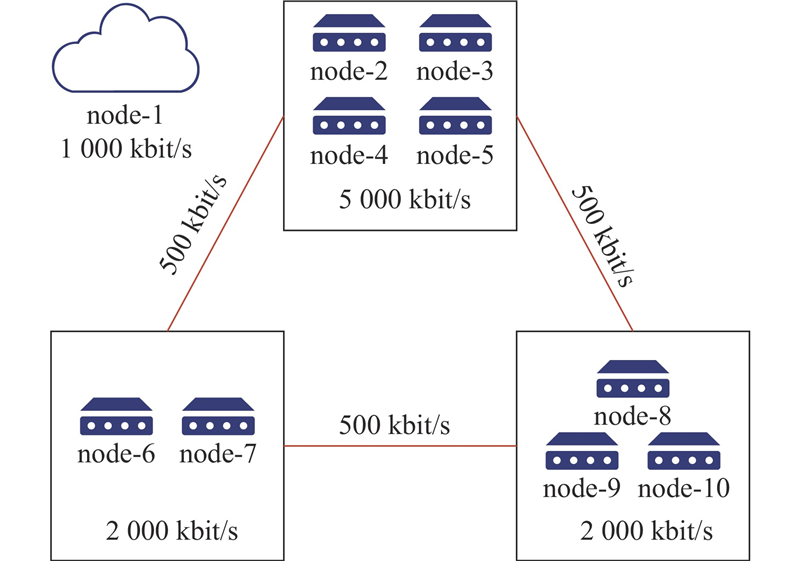
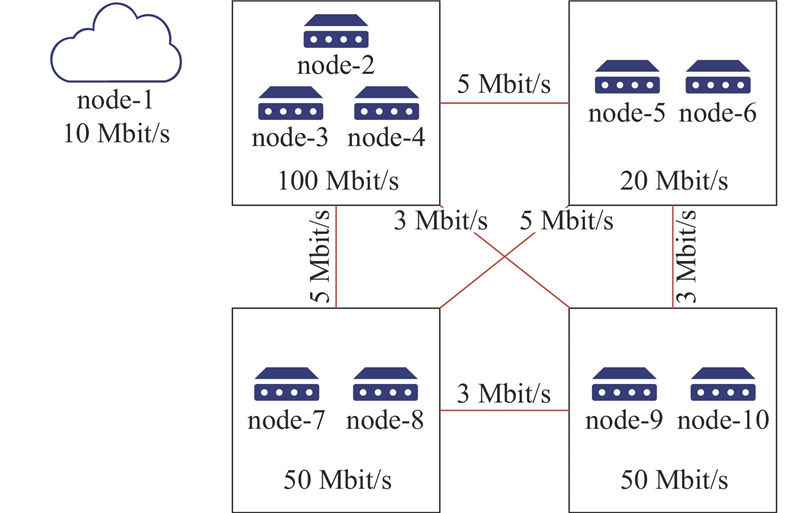
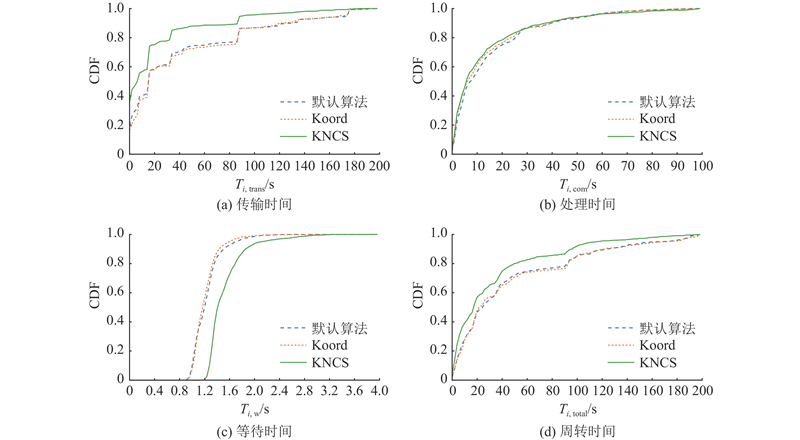
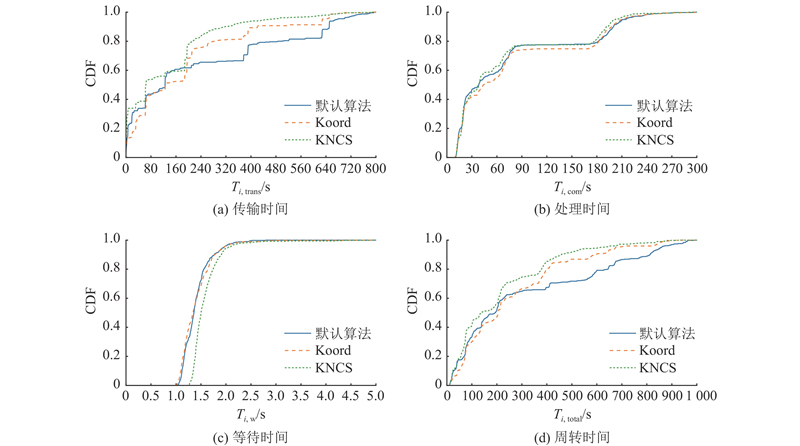

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}