

合成孔径雷达(synthetic aperture radar,SAR)在海洋监测、灾害管理、环境保护和智能驾驶等领域应用广泛,尤其在船舶目标检测中. 尽管SAR图像受散斑噪声和复杂海岸线的影响,但其全天候特性在弱光和高云量的条件下优于可见光和红外图像,仍在港口实时监测、船舶识别和跟踪中发挥重要的作用.
基于CNN的目标检测算法通常分为单阶段和两阶段方法. 常见的两阶段检测算法如区域卷积神经网络(region-based convolutional neural network,R-CNN)[3]算法,通过候选区域生成与分类回归实现检测,精度高,但计算复杂. 相比之下,单阶段检测算法如YOLO(you only look once,YOLO)[4]通常具有较低的计算复杂度,更适合实时应用. YOLO系列模型通过高效的检测方法、轻量化架构、多尺度特征融合和注意力机制,在复杂背景和高噪声环境下,显著提升了SAR船舶图像的检测速度和精度. Li等[5]提出基于YOLOv5的轻量化方法,采用通道剪枝、知识蒸馏和双向特征金字塔网络,提升了精度,但存在特征丢失的问题. Tang等[6]提出基于YOLOv7的改进模型,通过多尺度感受域卷积块提高检测精度,但计算开销较大,影响推理速度和资源利用.
为了显著增强复杂SAR图像环境中的船舶探测能力,结合SAR图像中船舶密度高、背景不平衡及目标尺寸变化大等问题,本文提出基于改进YOLOv8模型的算法,研究创新贡献详述如下.
(1)为了解决目标尺寸变化大及提取多尺度上下文信息能力不足的问题,设计双膨胀残差(contextual feature fusion with double dilated module,C2f-DD)模块,显著提高多尺度特征的提取效率,增强卷积核层的特征提取能力.
(2)为了提升模型精度并增强该模型在复杂背景下的鲁棒性,设计可变形注意力(spatial pyramid pooling fast attention,SPA)模块. 通过引入可变形注意机制,使得模型能够专注于图像中的关键区域.
(3)为了降低计算开销和模型复杂性,并有效解决背景噪声复杂和细节丢失的问题,使用轻量级上采样模块.
(4)为了提升对关键特征提取的敏感性,增强模型对复杂背景中各种目标特征和变换的适应性,设计轻量动态检测头模块,显著提高了多种背景中目标检测的准确性.
1. 网络设计
DD-YOLO模型的整体设计架构如图1所示. DD-YOLO基于YOLOv8,主要由3个部分组成:多尺度提取骨干网络、颈部网络和检测网络.
图 1
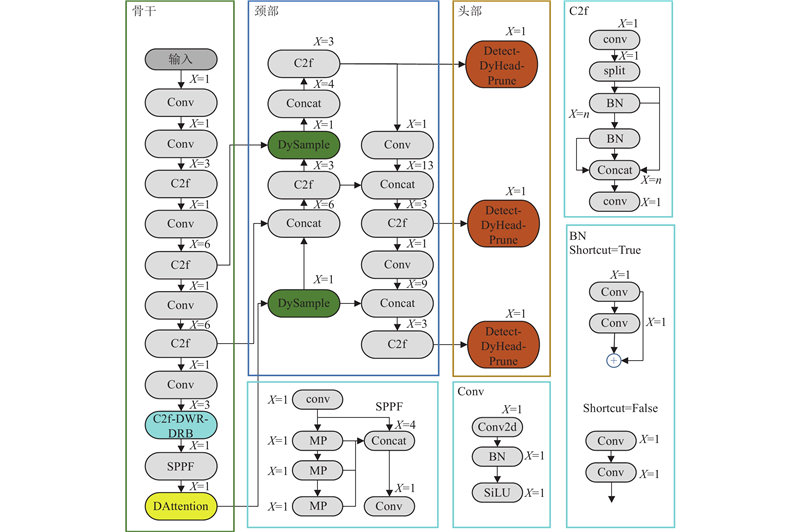
多尺度提取骨干网络具有增强的特征提取和多尺度语义感知能力,该骨干网络包括Conv(Convolution)模块、C2f(Concatenate Cross Stage Partial Fusion)、C2f-DD和SPA模块. C2f-DD模块结合了扩展膨胀卷积(dilated weighted residual,DWR)[9]和扩展重参数卷积(dilated weighted residual dilated reparam block,DRB)[10]的动态调整和增强特征的优点. 可变形注意力模块是在快速空间金字塔池化模块(spatial pyramid pooling–fast,SPPF)中加入可变形注意力机制[11]. 骨干网络通过增强特征提取能力、多尺度语义融合以及引入可变形注意力机制,有效丰富了梯度流信息.
在颈部部分,将YOLOv8原始的上采样替换为动态上采样(dynamic sampling upsampler,Dysample)[12],以增强低分辨率图像和小目标的检测能力,并进一步提升模型在复杂背景中的特征提取能力.
检测头部分使用轻量动态检测头(dynamic head prune,DyHead-Prune),通过轻量优化和多维度注意力机制,在保持高检测精度的同时,有效地提高了模型性能.
1.1. C2f-DD
SAR船舶图像中目标的形状、位置和尺寸差异较大,YOLOv8原有的C2f模块在提取这些目标特征时存在不足,无法有效地提取多尺度上下文信息. 为了增强网络在SAR船舶图像数据集上的多尺度特征提取能力,设计全新的C2f-DD模块.
C2f-DD通过使用DWR_DRB(dilated weighted residual with dilated reparam block)模块替代Bottleneck模块,优化残差连接结构. 这一改变增强了C2f-DD在处理输入张量时的特性,提升了多尺度特征的提取与融合能力. C2f-DD模块的结构如图2所示.
图 2
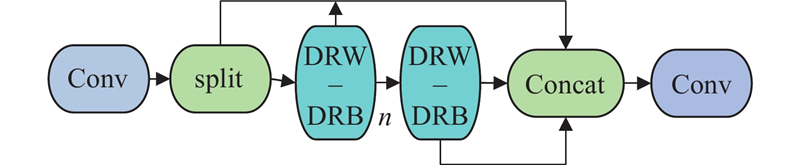
图 3
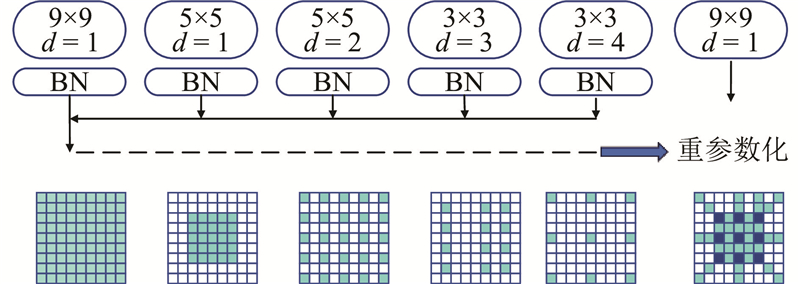
大卷积核层通过结合批量归一化(batch normalization,BN)、调整膨胀率和零填充卷积核构建,膨胀层将模块转化为稀疏卷积核,增强特征提取. 并行的小卷积核捕捉小尺度模式,输出在BN层后相加,通过重参数化合并,推理时将大卷积核和小卷积核等效结合,提升特征质量.
DWR模块的工作原理分为2个阶段. 第1阶段通过3×3卷积、BN层和ReLU激活生成特征图;第2阶段通过不同膨胀率的深度卷积进行形态学过滤,增强特征的多样性. DWR模块采用固定膨胀率的卷积,无法应对复杂任务中的多样化特征,尤其在处理形状和尺度差异大的目标时,表达能力不足.
为了弥补这一不足,提出DWR_DRB模块,结合DBR模块和DWR模块的优势. DBR模块通过重参数化膨胀卷积来增强DWR模块的灵活性,能够并行使用不同膨胀率的卷积和小卷积核,动态调整感受野,捕捉更多尺度的特征. DWR_DRB模块在第1阶段通过3×3卷积和ReLU激活,生成简洁特征图;第2阶段通过DBR模块的多种膨胀率深度卷积进行形态学过滤,提升了特征的多样性和细节捕捉能力.
DWR_DRB模块的结构如图4所示. 其中,C为通道数. 在第1个分支中,输入特征通过3×3卷积、修正线性单元(rectified linear unit,ReLU)和BN层配对生成关联的残差特征. 3×3卷积用于初步特征提取.
图 4
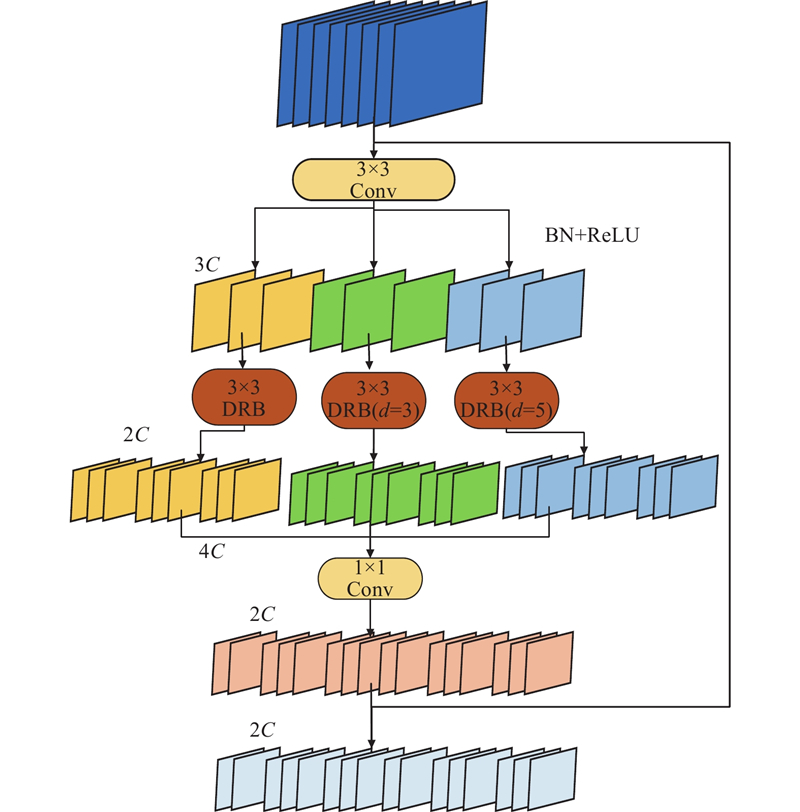
第2个分支通过DRB模块,对船舶目标的区域特征进行形态学过滤. 在该过程中,每个通道特征仅使用1个预定的感受野,避免了多余的感受野覆盖问题,提高了特征提取的针对性. 特征图通过1×1的卷积层,进一步处理并融合特征,生成最终的输出特征图.
1.2. SPA
在SPPF模块后引入可变形注意力机制,组成SPA模块. 可变形注意力通过引入可变形注意力和动态采样点,聚焦于图像中的一小部分关键区域,提高模型的性能.
图 5
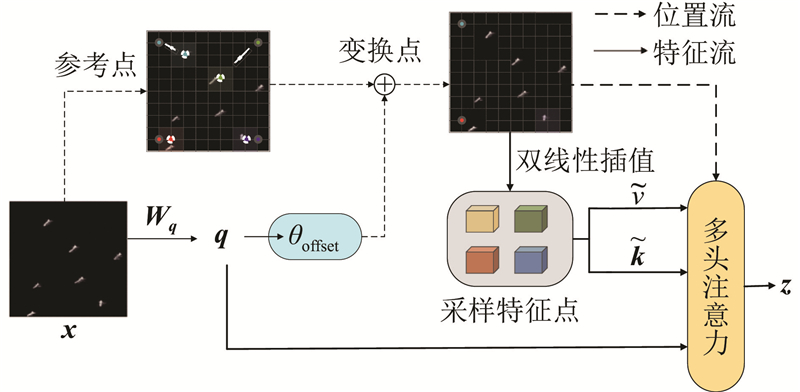
输入特征图的尺寸为x∈RH×W×C,其中H为高度,W为宽度. 将特征图线性投影到查询标记q上,表示为q=xWq. 上路径的参考点使用缩放系数
式中:Wq、Wv、Wk、Wo为投影矩阵,Wq、Wv、Wk、Wo∈RC×C. 多头注意力可以通过添加相对位置编码来计算,如下所示.
式中:
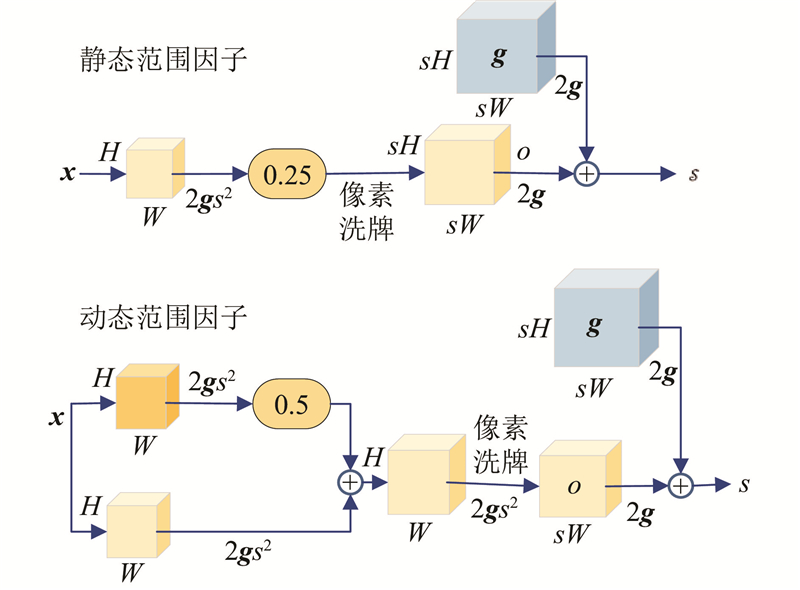
1.3. Dysample
在目标检测任务中,上采样用于调整特征图大小以匹配原始图像,从而有效地检测各种物体. 传统的双线性插值方法可能导致图像细节丢失,且基于卷积核的上采样计算量大,不利于轻量级网络. 针对SAR船舶检测图像背景噪声复杂、细节丢失的问题,引入轻量且有效的动态上采样器Dysample. Dysample通过基于点的采样方法和学习采样视角进行上采样,避免了动态卷积操作,减少了计算资源,提高了图像分辨率和模型性能.
图 6
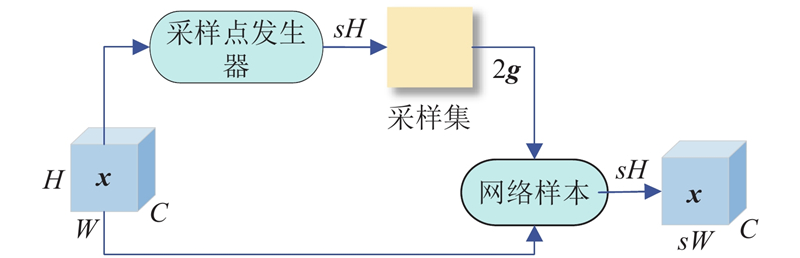
图 7
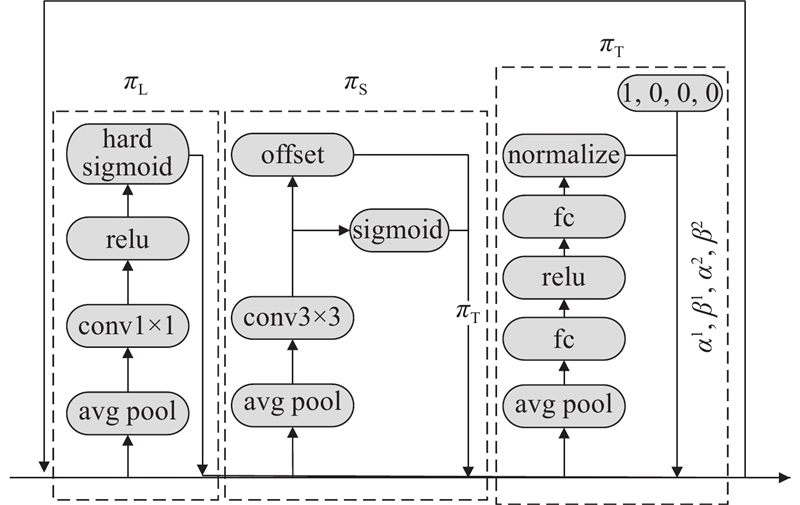
1.4. DyHead-Prune
动态检测头(dynamic head,DyHead)通过引入注意力机制,整合尺度
为了解决以上问题,DyHead-Prune应运而生. DyHead-Prune对原始DyHead进行以下多方面优化. 采用轻量化动态卷积代替复杂模块.
DyHead-Prune的结构如图8所示.
图 8
式中:特征张量
式中:G为稀疏采样位置的个数,
式中:
这种逐层处理方式确保了不同尺度、空间和通道的特征得到充分的优化. 与未轻量化的DyHead相比,轻量化后的DyHead-Prune参数量减少,内存占用降低,显著提高了模型效率和适应性,保证了较高的检测精度.
2. 实验结果及分析
在2种不同规模的SAR图像数据集上进行实验,验证了该方法的有效性和先进性.
2.1. 数据集
SSDD(ship-SAR ship detection)数据集[13]是SAR船舶探测领域第一个公开可用的数据集. 它包括来自Sentinel-1、TerraSAR-X和RadarSat-2的1 160张图像. 图像覆盖了多种不同的海洋环境和条件.
HRSID(high resolution ship detection)数据集[14]是更复杂和高分辨率的集合. 它包括来自TerraSAR-X、TanDEM-X和Sentinel-1B 3个卫星平台拍摄的5 604张图像. 这些图像经过精细处理和过滤,提供了更详细和精确的目标信息.
2.2. 评价指标
为了公平地比较算法性能,实验使用COCO(Microsoft common objects in context)数据集的评估指标,主要指标是平均精度AP(average precision),由精确率p(precision)-召回率r(recall)曲线下的面积得出. 在IoU(intersection over union)≥0.5的条件下,计算平均精度,此时的AP称为mAP50. 同样地,计算mAP55、mAP60、mAP65、mAP70、mAP80、mAP85、mAP90和mAP95,mAP50-95表示这10个值的平均值,通常表示为AP,用于评估方法的整体性能. p和r的计算如下:
式中:TP为正确检测到的船舶目标数量,FN为漏检的船舶目标数量,FP为非船舶目标被错误检测为船舶目标的数量.
参数量表示模型中权重和偏差的数量,参数越少,模型越轻,占用空间和计算资源也越少.
实验中使用每秒浮点运算次数(floating point operations per second, FLOPs)作为辅助的评估指标,测试模型的效率. 作为辅助指标,评估模型每次前向推理的计算量. FLOPs 越低,说明模型的计算复杂度越低,运行更快,对硬件资源的需求更小. 通过比较不同模型的 FLOPs,可以更好地权衡性能与计算成本,辅助在实际应用中选择更高效的模型.
2.3. 实验配置
实验设置包括一台Intel Core i5-12600KF Processor、16 GB RAM、NVIDIA GeForce RTX 4060Ti GPU(16 GB内存)的计算机,配备Ubuntu 18.04操作系统,网络结构基于Pytorch1.9.0构建,编程语言为Python3.8,使用CUDNN 8.0和CUDA 11.1加速训练. 将2个数据集随机分为训练集、验证集和测试集,比例为7∶2∶1. 该模型用300个轮次进行训练,模型的输入图像大小为640×640像素,批处理大小设置为8.
2.4. DD-YOLO消融实验
为了验证所设计的基础模块的有效性,开展消融实验. 由于HRSID数据集包含更多样本和更高的复杂度,有助于更全面地评估模块的性能,保证实验结果的可靠性和稳定性,选择在HRSID数据集上进行消融实验.
实验A~G在基线模型YOLOv8的基础上逐步引入C2f-DD、SPA、Dysample和检测头等模块,验证它们对模型性能的贡献. 实验A为基线模型,实验H为最终的DD-YOLO模型,包含所有优化模块,所有指标相对于基线模型均有提升.
表1中,Np为参数量. 从表1可知,实验B在基线算法的基础上加入C2f-DD模块,模型在各项指标上均有所提升,p增加了0.6%,r提高了1.1%,mAP50和mAP50-95都增加了0.8%. 这些提升表明C2f-DD模块增强了多尺度上下文信息提取,特别是在不同尺度目标下,模型能够更好地融合特征,提升检测精度. 在实验C中引入SPA模块,p增加了0.6%,r提高了1.4%,mAP50增加了0.5%,SPA模块通过空间注意力机制聚焦重要区域,显著提升了r. 在实验D中,用Dysample模块替换上采样模块,Dysample模块在保持高检测性能的同时减少了参数量. 在实验E中,替换了检测头模块. 该模块的替换使得p提升了0.5%,r提升了1.4%,mAP50提高了1.2%,mAP50-95提高了2.1%. 检测头优化后,模型能够对不同尺度的目标进行多重预测,增强了检测能力,特别是在mAP50-95上表现显著. 在实验F中同时加入Dysample和检测头模块,p提高了0.6%,r提升了1.4%,mAP50和mAP50-95均有所提升. 这表明2个模块在联合使用时进一步增强了模型的检测能力. 在实验G中,进一步引入C2f-DD模块后,p提升了1.4%,r增加了1.5%,mAP50和mAP50-95分别提高了1.8%和2.7%. 结合这些模块,提升了模型的整体性能,特别是在高精度目标检测任务中表现更加出色. 实验H为本文算法,DD-YOLO模型在p上提升了1.5%,r增加了2.5%,mAP50增加了2.0%,mAP50-95提升了3.4%,与YOLOv8相比,整体性能有了显著的提升. 各模块的协同作用使得模型能够更好地处理多尺度目标,提高了对小目标的检测精度,有效地降低了计算开销.
表 1 HRSID上的DD-YOLO消融实验
Tab.1
| 编号 | YOLOV8 | C2f-DD | SPA | Dysample | Detect | p/% | r/% | mAP50/% | mAP50-95/% | Np/106 | FLOPs/109 |
| A | √ | — | — | — | — | 90.5 | 82.5 | 90.2 | 64.0 | 11.46 | 8.1 |
| B | √ | √ | — | — | — | 91.1 | 83.6 | 91.0 | 64.8 | 12.27 | 8.0 |
| C | √ | — | √ | — | — | 91.1 | 83.9 | 90.7 | 64.7 | 12.49 | 8.3 |
| D | √ | — | — | √ | — | 90.4 | 83.8 | 90.6 | 64.1 | 11.42 | 8.1 |
| E | √ | — | — | — | √ | 91.0 | 83.9 | 91.4 | 66.1 | 13.30 | 9.6 |
| F | √ | — | — | √ | √ | 91.1 | 83.9 | 91.6 | 66.4 | 13.24 | 9.6 |
| G | √ | √ | — | √ | √ | 91.9 | 84.0 | 92.0 | 66.7 | 13.42 | 9.6 |
| H | √ | √ | √ | √ | √ | 92.0 | 85.0 | 92.2 | 67.4 | 13.94 | 9.8 |
2.5. C2f-DD消融实验
提出具有新残差连接结构的C2f-DD. 为了验证该结构的特性,将DD-YOLO其他模块保持不变,主干部分的C2f从最后一个开始,逐次替换为C2f-DD,共做了4组实验,分别记为实验1、2、3、4,对应替换C2f的数量,实验结果如表2所示. 综合考虑模型复杂度和检测精度,只在整体模型中替换主干部分的最后一个C2f模块,在降低计算开销和模型复杂性的同时,显著提升了检测能力.
表 2 HRSID上的C2f-DD消融实验
Tab.2
| C2f-DD数量 | p/% | r/% | mAP50/% | mAP50-95/% | Np/106 | FLOPs/109 |
| 1 | 92.0 | 85.0 | 92.2 | 67.4 | 13.94 | 9.8 |
| 2 | 91.2 | 84.5 | 91.1 | 66.6 | 20.36 | 11.7 |
| 3 | 89.4 | 84.6 | 88.6 | 53.4 | 25.80 | 13.0 |
| 4 | 91.9 | 84.9 | 92.4 | 67.8 | 30.10 | 28.4 |
图9中的可视化对比结果验证了DD-YOLO模型的性能优势. 与YOLOv8模型相比,DD-YOLO在小目标船舶检测方面表现更优:YOLOv8会出现明显的漏检和误检情况,DD-YOLO的误检率和漏检率都更低.
图 9
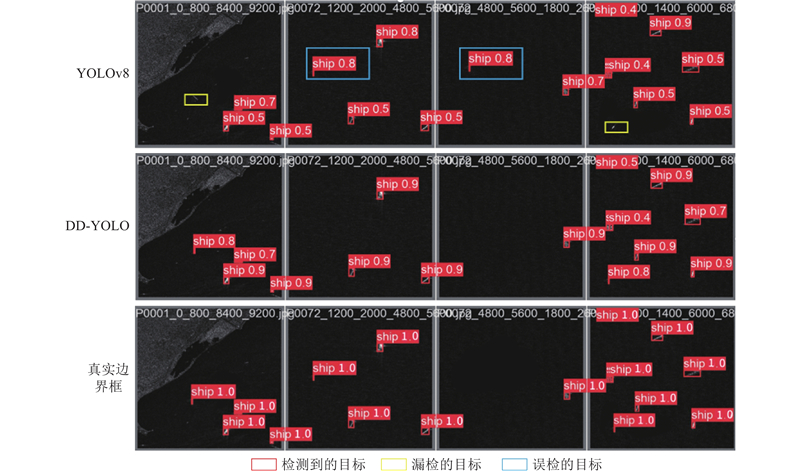
图 9 YOLOv8与DD-YOLO模型的可视化对比
Fig.9 Visualization comparison between YOLOv8 and DD-YOLO model
图10的热力图分析进一步验证了DD-YOLO在复杂背景噪声下检测密集多尺度目标的优势. 实验结果表明,该模型能够有效识别和区分密集目标,这主要得益于C2f-DD模块和SPA模块的多尺度特征提取与融合能力,显著提升了复杂环境下的检测性能. 此外,Dysample模块在计算效率上的优化以及DyHead-Prune模块对复杂场景适应性的增强,共同提高了模型的检测精度和召回率. 这种模块组合不仅优化了检测性能,而且保持了较低的参数量和计算复杂度.
图 10

图 10 YOLOv8与DD-YOLO模型的热力对比
Fig.10 Comparison of thermal force of YOLOv8 and DD-YOLO model
2.6. 对比实验
为了验证本文算法的优越性,开展如下训练和测试,将其与其他目标检测算法进行比较. 评价指标主要选取p、r、mAP50、参数量及FLOPs,衡量各个测试算法模型的检测精度与速度.
如表3所示,在SSDD数据集上的实验结果表明,尽管模型r低于Key-PointEstimation+Channnel Attion、TWC-Net及ADERLNet-CW,但是DD-YOLO的p和mAP50都优于其他模型. 模型的参数量和FLOPs分别为13.94×106和9.8×109,低于其他模型,能够大大地降低计算开销和模型复杂性.
表 3 SSDD 数据集的不同目标检测模型的比较
Tab.3
如图11所示,对Key-Point Estimation+Channel Attention、TWC-Net、ADELMNet-CW和DD-YOLO 4种方法进行可视化对比. 如图11(a)所示为复杂场景下密集大型船舶的检测结果,如图11(b)所示为复杂场景中的中小型船舶检测结果. 对比可知,Key-Point Estimation+Channel Attention在复杂背景下存在明显的漏检和误检问题,表现不稳定;TWC-Net未能解决复杂背景下的误检和漏检的难题;ADELMNet-CW的平均检测精度低于DD-YOLO. 相比之下,DD-YOLO的平均检测精度表现最优,尤其在复杂背景和多尺度目标共存的场景中,能够保持高效、稳定的检测性能.
图 11

如表4所示,在HRSID数据集上的实验结果表明,DD-YOLO模型的p略低于PPA-Net及Context-aware network,r低于Center Net、PPA-Net及Context-aware network,但是DD-YOLO的mAP50都优于其他经典模型. 模型的参数量和FLOPs分别为13.94×106和9.8×109,远远低于其他经典模型. 总之,DD-YOLO模型实现了显著的检测准确性,在多个数据集上的检测结果验证了该方法的精细泛化能力.
表 4 HRSID 数据集不同目标检测模型的比较
Tab.4
如图12所示为HRSID数据集的可视化对比. 如图12(a)所示为复杂场景下密集船舶的检测结果,如图12(b)所示为复杂场景中的中小型船舶检测结果. 通过对CenterNet、PPA-Net、Context-aware network和DD-YOLO的可视化对比可以看出,CenterNet能够检测大多数船舶目标,但存在一定的误检;PPA-Net在检测密集船舶时会出现漏检的问题;Context-aware network虽然不存在误检和漏检的问题,但平均检测精度明显低于DD-YOLO. 相比之下,DD-YOLO表现最优,平均检测精度最高,尤其在复杂背景和多尺度目标场景中能够保持高效、稳定的检测能力. 这体现了DD-YOLO的综合优势,使其成为高效、可靠的目标检测方案,在复杂背景和多尺度目标共存的环境中具有显著优势.
图 12

3. 结 语
针对SAR图像船舶检测任务中存在的船舰目标体积小、目标尺寸变化大及背景噪声复杂等挑战,C2f-DD模块通过结合DWR和DRB模块,增强了多尺度特征提取与融合的能力,从而改善对多目标的检测效果. SPA模块通过动态偏移和多头注意机制,提升了模型在复杂背景下对关键区域的关注,增强了检测精度. Dysample模块在优化上采样过程的同时,有效平衡了计算资源的消耗和对中小型目标的检测性能. DyHead-Prune模块通过轻量化和多维度注意力机制,提升了检测准确性,保证了模型的高效运行. 在极端环境下,当面对噪声和伪目标时,模型的鲁棒性有待进一步的加强. 未来研究将重点优化实时性能,探索多模态融合框架并开发自适应特征增强网络,以进一步提高模型在复杂环境中的适应性和实用性.
参考文献
Improving ship detection based on decision tree classification for high frequency surface wave radar
[J].DOI:10.3390/jmse11030493 [本文引用: 1]
SAR image ship detection in complex scenarios using modified YOLOv5
[J].
A lightweight SAR Image ship detection method based on improved convolution and YOLOv7
[J].DOI:10.3390/rs16030486 [本文引用: 1]
MSFA-YOLO: a multi-scale SAR ship detection algorithm based on fused attention
[J].
DML-YOLOv8-SAR image object detection algorithm
[J].DOI:10.1007/s11760-024-03361-4 [本文引用: 1]
SAR ship detection dataset (SSDD): official release and comprehensive data analysis
[J].DOI:10.3390/rs13183690 [本文引用: 1]
HRSID: a high-resolution SAR images dataset for ship detection and instance segmentation
[J].
An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images
[J].DOI:10.1109/TGRS.2020.3005151 [本文引用: 1]
TWC-Net: a SAR ship detection using two-way convolution and multiscale feature mapping
[J].DOI:10.3390/rs13132558 [本文引用: 1]
Multiscale and dense ship detection in SAR images based on key-point estimation and attention mechanism
[J].
ADERLNet: adaptive denoising enhancement representation learning for low-latency and high-accurate target detection on SAR sensors
[J].
Objects as points
[J].
Dense attention pyramid networks for multi-scale ship detection in SAR images
[J].DOI:10.1109/TGRS.2019.2923988 [本文引用: 1]
A robust one-stage detector for multiscale ship detection with complex background in massive SAR images
[J].
PPA-Net: pyramid pooling attention network for multi-scale ship detection in SAR images
[J].DOI:10.3390/rs15112855 [本文引用: 1]
Context-aware SAR image ship detection and recognition network
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}